
Финансовая отчетность (ФО) — штука предельно ответственная. Получаемая от бизнеса ФО постоянно нужна банку для организации повседневной деятельности. Но процесс получения важной для нас отчётности омрачается тем, что работа с ФО — это монотонный неэффективный конвейер, на поддержание которого банковские служащие тратят тысячи человекочасов. ВТБ использует электронные инструменты получения ФО, такие как: ФНС, 1С, Коробочное решение распознавания. Это основные направления развития, но сегодня они не покрывают всю потребность в клиентской ФО.
Меня зовут Андрей Ходяков, я работаю с неструктурированными данными в управлении моделирования КИБ СМБ в банке ВТБ. И в этом материале я расскажу, как мы искали и нашли собственное решение для борьбы с рутиной ФО.
Немного о финансовой отчётности
Финансовая отчётность (ФО) — один из важных информационных ресурсов для оценки результатов активности субъектов хозяйственной деятельности. Поэтому она широко используется как источник данных в повседневной деятельности банка.
Сведения о финансовой отчётности представляют в виде набора таблиц. Формы этих таблиц определены федеральными законодательными актами. Например, приказом Минфина России № 66н, изм. от 19.04.2019. Как правило, клиент отправляет в банк копию отчётности, отсканированную или сконвертированную из различных сервисов ведения бухгалтерского учёта.
Сейчас Федеральная налоговая служба проводит работу, связанную с организацией электронного документооборота. Риск-подразделения банка уже сегодня работают над электронным потоком информации из ФНС, однако довольно существенная часть данных всё ещё поступает в виде .pdf файлов по электронной почте.
А в чём проблема?
Получив ФО клиента, работник нашего банка должен отобрать необходимые файлы отчётности из пришедшего письма, найти в этих файлах необходимые страницы и вручную или с помощью копирования перенести эти данные в нашу внутреннюю форму. Конечно, это крайне неэффективный метод.
Задача простая, но требует массы усилий о сотрудников Клиентских подразделений, Андеррайтинга и, в частности, Рисков — в целях ежеквартального мониторинга. Она занимает много операционных ресурсов и не исключает банального человеческого фактора. К тому же ее почти невозможно масштабировать
Коллеги из Рисков сказали нам о наболевшей проблеме, поэтому мы решили заняться её автоматизацией. На финальном этапе процесса стало очевидно: вместо человека искать нужные данные внутри ФО и переносить их в нашу форму может алгоритм (т. е. как раз автоматизированное решение).
Впервые мы задумались о таком решении в начале этого года. Вообще, ВТБ в последние несколько лет постепенно переходит на цифровизацию, исключая работу с бумажными документами в пользу цифровых образов. Поскольку наш отдел использует в том числе отчётность корпоративных клиентов при разработке моделей, мы и решили помочь банку воплотить это новое решение в жизнь.
Итак, что именно должен делать наш алгоритм по работе с ФО и как его создать?
Задачи для алгоритма
На этапе аналитики, который занял около месяца, мы увидели несколько преград на пути реализации нашего алгоритма. Как я уже сказал, ФО в банк присылают в двух форматах: .pdf и .tiff. Причём .pdf может хранить документ в виде нескольких разных представлений. Иногда в элементах-контейнерах для текста, в виде последовательности байт в кодировках UTF-8, CP1251 и др. Иногда внутри байтстрима скана страницы, расположенного в элементе — контейнере изображения. В таком же формате хранится документ в .tiff-файлах, только контейнера в их случае нет.

Итак, информация поступает в банк в различных представлениях.Какое из них рассмотреть как основное для работы алгоритма? У нас был выбор: либо переводить весь текст в формат изображения, либо наоборот — переводить изображения в текст. Мы выбрали второй вариант, потому что он естественнее, логичнее и проще. Чтобы его воплотить, необходимо преобразовать изображения в текст, решив задачу OCR. А поскольку результаты обработки ФО — это цифры, полученные из текста, на каком-то этапе выполнять OCR всё равно придётся.
Также возникли вопросы к самой структуре ФО. По сути, это набор показателей, сгруппированных в таблицы по разделам и проиндексированных уникальным кодом строки. Каждый раздел может быть выделен в отдельный документ, или, наоборот, все разделы могут быть сведены в один документ. Даже для одного и того же субъекта разделение может быть разным в разных ситуациях.
Как научить алгоритм справляться с этим разнообразием разделения? С помощью кодов строк показателей и статус-кодов. Они в ФО, вне зависимости от разделения, всегда одинаковые. Сочетание кода раздела и статус-кода помогает однозначно определить, какого рода информация перед нами. Выходит, что таблица как таковая нам не нужна, нет смысла располагать данные в виде матрицы столбцов и строк. Мы можем просто отобразить таблицу на иерархическую структуру со взаимоотношениями «часть-целое», чтобы размер ячеек и даже сам факт их наличия стали для нас неважны. Это позволяет нам описать отношения «мероним-холоним» внутри ФО в виде шаблона, например в формате .json. В таком шаблоне вложенность конструкций и будет означать отношение «часть-целое». Скажем, вот так:

Этот подход позволяет привести документы к единому шаблону «тег-значение_тега». В рамках шаблона тег означает конкретную информацию, которая содержится в документе, а значение тега — это выражение — синоним тега в терминологии документа ФО. Найдя необходимые теги, алгоритм может легко отобразить документ ФО на структуру данных языка программирования.
Кроме того, такая система упростит взаимодействие с новой отчётностью в будущем. Код не прибит гвоздями к какому-либо разделу отчётности, набор атрибутов и методов остаётся одинаков. Нам достаточно будет добавить новый раздел в уже существующий шаблон либо создать новый шаблон с теми же тегами, но другими значениями тегов. И алгоритм будет готов работать с новыми типами документов.
Наконец, аналитика выявила, что документы ФО у разных клиентов сильно различаются по формату таблиц. Представленный Минфином образец — не шаблон, от которого нельзя отходить, а, скорее, пример того, как сверстать подобный документ. Поступающая в ВТБ отчётность заметно варьируется в размерах и положении таблиц, а также в способах их переноса на новую страницу — с добавлением шапки или разрывом. Вот три образца одного и того же документа, свёрстанные совершенно по-разному:

Эта информация натолкнула нас на две мысли.
Первая заключалась в том, что материал для расстановки тегов должен включать в себя данные с более чем одной страницы. Вторая — положение тегов в материале не стоит связывать с границами таблиц, потому что они разные, да к тому же могут быть плохо отсканированы или вообще отсутствовать. Как на этом примере:

С этими особенностями финансовой отчётности мы снова столкнулись уже на этапе активной работы над решением.
Ищем инструменты
Построить хороший инструмент для OCR — сложная задача, она требует значительных ресурсов и трудозатрат. Чтобы ускорить разработку нашего инструмента, мы решили использовать уже готовую, широко используемую open-source-библиотеку — Tesseract. Мы выделили её в дополнительный слой абстракции, чтобы не привязываться к одной конкретной библиотеке и иметь в будущем возможность её заменить или дополнить другими популярными решениями из этой области. Таким образом мы получили возможность сосредоточиться на решении частной задачи и не распыляться на общности.
Свой алгоритм мы основывали на уже написанных в Python опенсорсных инструментах. Почему Python? Потому что это де-факто стандарт обработки данных. Есть и другие, Scala например, но в Python существует обширное и сильное комьюнити, уже решившее большое число смежных и частных вопросов обработки текста и поиска в нём информации. Python сочетает в себе разнородные области, что отлично подходит для прототипирования. Всё можно делать быстро. Порой в Python 10 строчек кода производят такую работу, на которую в другом языке понадобилось бы куда большее усилие.
Определившись с языком разработки, наша команда составила план реализации алгоритма с опорой на open-source-решения. Разделили его четыре этапа.
Сначала наше решение читает файл и анализирует его содержимое. Существует множество Python-библиотек для парсинга .pdf. Мы решили воспользоваться pdfminer.six. А для работы с .tiff использовали встроенную библиотеку PIL.
Далее необходимо собрать текст с каждой страницы документа и отделить страницы, относящиеся к ФО. Для решения задач OCR на этом этапе мы взяли всё тот же pdfminer.six, а также PyTesseract. И дополнительно для работы с изображениями взяли OpenCV.
После этого алгоритм классифицирует сгруппированные страницы и выбирает необходимый шаблон.
Следующий шаг — расставить теги по выбранному шаблону. То есть решение ищет в документе значения, связанные с заранее установленными тегами. Например, рассчитывает расположение в тексте значений бухгалтерского баланса, находит их в тексте и проставляет рядом с ними соответствующий тег. Это похоже на решение задачи NER, только в нашем случае именованные сущности — теги шаблона. Так как тексты внутри ФО на русском языке, для морфологического анализа токенов применяем pymorphy2.
Наконец, алгоритм собирает текст вокруг тегов и отбирает из него те токены, которые относятся к тегу. По сути, выполняет аналог relation prediction между токенами окружения и выражением значения тега. То есть алгоритм проверяет уже отобранные для тега значения по ряду параметров (например, есть ли сохранённое значение у предыдущего тега) и сохраняет только те токены, которые этим параметрам отвечают.
Приступаем к разработке
После месяца аналитики мы в течение двух кварталов активно занимались созданием минимально жизнеспособного продукта. При этом команда была совсем небольшая: всего двое разработчиков. Юзер-стори мы получали от сотрудников ВТБ, которые обрабатывают ФО-отчетность клиентов. А консультантами выступили бизнес-клиенты, с которыми мы и до того плотно работали.
Разработка для некоторых этапов нашего плана проходила гладко. Но на втором и четвёртом пришлось попотеть.
На втором этапе мы пользовались pdfminer.six и PyTesseract. Майнер применяли, когда нужный текст был размещён в элементах .pdf-файла. Выбранная нами библиотека использует для этого высокоуровневую функцию extract_text. Но с ФО эта функция не всегда даёт нужный результат. Формат .pdf хранит только символы и координаты их положения на странице. А внутри pdfminer.six для сборки текста реализован алгоритм анализа слоя страницы. Суть его в том, что сначала pdfminer группирует буквы в слова, слова в выражения, а затем пытается формировать строки и абзацы. И, читая ФО, наш инструмент часто группировал токены таблиц не по строкам, а по столбцам. Естественно, окружение тега в этом случае содержит совершенно не те величины, которые к нему относятся.
Почему так происходит? В .pdf-файле нет пробелов, только координаты положения символов. У pdfminer есть настройки умной группировки по словам и строкам, для пробелов даже существует особый параметр Margins, который отвечает за пробелы между словами и строками. Так вот, если расстояние между строками будет меньше чем между словами, то pdfminer будет рассматривать их как слова из одной строки.
Если бы в ФО было правило, что одна строка — это всегда один абзац, то проблемы бы не было. Но поскольку абзацев бывает много, то внутрь строки вполне может закрасться пустое значение, тогда группа сбивается. И поэтому умная авторасшифровка иногда оказывает медвежью услугу. Когда мы столкнулись с этой проблемой, то подробнее исследовали pdfminer, чтобы настроить его под наши нужды. Для устранения этого эффекта воспользовались API, которое pdfminer предоставляет для доступа к элементам страницы. При передаче custom-параметров группировки в парсер страницы появляется возможность прочитать страницу фактически построчно (слева направо / сверху вниз). Когда мы применили API и отключили умную группировку — смогли добиться необходимых результатов.

Ещё, в соответствии с законодательством, в ФО могут быть строки детализации статей отчетности, уникальные для каждого клиента. Банку они чаще всего не интересны, но их нужно отфильтровывать, ведь это шум внутри строки.
Принципиально другой случай представления ФО, это когда текст документа ФО находится внутри элемента .pdf, содержащего байтстрим изображения, тут мы использовали pdfminer.six уже в связке с PyTesseract. Здесь pdfminer обеспечивает доступ к элементу страницы и его содержимому. Далее байтстрим изображения отправляется в PyTesseract, который выполняет OCR.
Однако применение PyTesseract с настройками по умолчанию к изображению, полученному от клиента, не всегда даст хорошие результаты. Внутри байтстрима может быть одна буква на изображение или, напротив, очень много плотно расположенных данных. Первое, что мы сделали для улучшения результатов решения задачи OCR, — нашли правильный параметр сегментации страницы по аналогии с pdfminer. Взяли эстиматор, придумали метрику для оценки качества, подобрали нужный результат. Сделали грид, поискали гридсёрчем локальный максимум, а когда нашли — стали его применять.

Также для хороших результатов необходимо ограничить множество символов для распознавания, чтобы потом не сталкиваться с символами, которые не встречаются в документах ФО. Отчётность — это не типичный документ, на котором обычно решаются задачи OCR, поэтому полезно облегчить своему решению работу.
В нашем случае параметр PSM (page segmentation mode) явно увеличивал количество распознанных символов в результатах. Но этого могло быть недостаточно, чтобы прочитать всё содержимое таблицы. Поэтому мы предприняли ещё один кардинальный шаг: удалили таблицы из страниц документа.
Зачем? Пиксели в таблицах часто неровные, неплотные, программа в них путается, принимает за символы. И сама таблица редко бывает одна на страницу. При этом каждый клиент их делит по-своему, это никак не регламентировано. Таблица без шапки начинается с разрыва ячейки. Человеку здесь всё понятно, а машине нет. Машина думает, что строка без шапки вообще за пределами таблицы.
А ещё часто случается, что таблицы в скане нет вообще или она пересвечена. Тут снова выбор, чтобы прийти к единому решению: либо убирать таблицы вообще из всех документов, либо во все документы их рисовать. Мы решили убрать, потому что это, во-первых, расширит в будущем список документов, которые сможет обрабатывать решение, а во-вторых, избавит нас от ненужной работы. Майнер ведь не сможет сам нарисовать таблицу — это надо будет делать отдельно.
Результаты были видны сразу. Документы без таблицы давались PyTesseract проще всего.
Как убирали таблицы? С помощью связки PIL и OpenCV выделили их контур. Каждое изображение конвертировали в grayscale image, серое изображение с диапазоном от 0 (черный) до 255 (белый) и с повышением контрастности на некоторую величину для дополнительного выделения линий. Произвели бинаризацию изображения с последующей инверсией. Используя вертикальное и горизонтальное ядра, по отдельности применили морфологическую операцию opening к инвертированному изображению и объединили результаты с использованием PIL.ImageChops.add. В результате этого шага получили инвертированное изображение контура таблицы. Поскольку этот контур имеет размеры несколько меньше исходного, мы сделали его немного более толстым, для чего выполнили эрозию контура (erosion). А потом свели первоначальное изображение и результат наших операций, используя PIL.ImageChops.lighter. В итоге получили документ без таблицы, даже без остатков линий. С таким изображением PyTesseract значительно улучшил результаты OCR.


Обрабатываем текст и фильтруем показатели тегов
На четвёртом этапе перед обработкой текста инструментами NLP его нужно сегментировать на предложения. Правильная сегментация позволяет сохранить синтаксические конструкции языка, чтобы потом применить их при расстановке POS tag, dependency relation, NER. Если в тексте есть синтаксические конструкции, они помогают разрешить вопросы, связанные с употреблением одного и того же слова в разных значениях и контекстах. Например, предложение: «Москва стоит на берегах реки, имя которой Москва». Топоним «Москва» используется дважды и означает разные сущности. Для того чтобы отличить их, достаточно построить дерево синтаксического разбора предложения, которое позволило бы отделить один токен «Москва» от другого по тому параметру, что одно из них подлежащее в предложении.
Но если мы посмотрим на документ ФО и результаты парсинга файлов ФО, то увидим, что предложения в них фактически отсутствуют, а границы фраз определяются вёрсткой документа.
При этом присутствуют сущности, которые выглядят одинаково, но обозначают разные вещи. Например, токен «баланс» входит в выражение «Бухгалтерский баланс», а также дважды встречается в таблице самостоятельно и означает итоговые показатели ФО за раздел. Конечно, каждый тег имеет уникальный код, но само по себе это не гарантирует отсутствие неоднозначностей уже потому, что значение статус-кода может совпасть с одним из значений показателя ФО за период.
Чтобы разрешить проблему и иметь возможность ориентироваться внутри текста документа ФО, примем допущение: идеальный парсер сегментирует некий идеальный документ ФО на элементы таким образом, что один элемент всегда содержит один тег нашего шаблона.

Конечно, распределение тегов по элементам документа, прочитанного «реальным» парсером, будет иметь случайный характер. Но случайность эта связана прежде всего с сегментированием документа, а определяется его вёрсткой и качеством решения задачи OCR.


Для отслеживания положения тега среди элементов документа нашлось очевидное решение — использовать в качестве координаты положения элемента документа с тегом его отношение element_number/total_elements_number. Эта относительная координата расположения тега никак не привязана к длине документа и даёт нам основу для разрешения неоднозначностей.
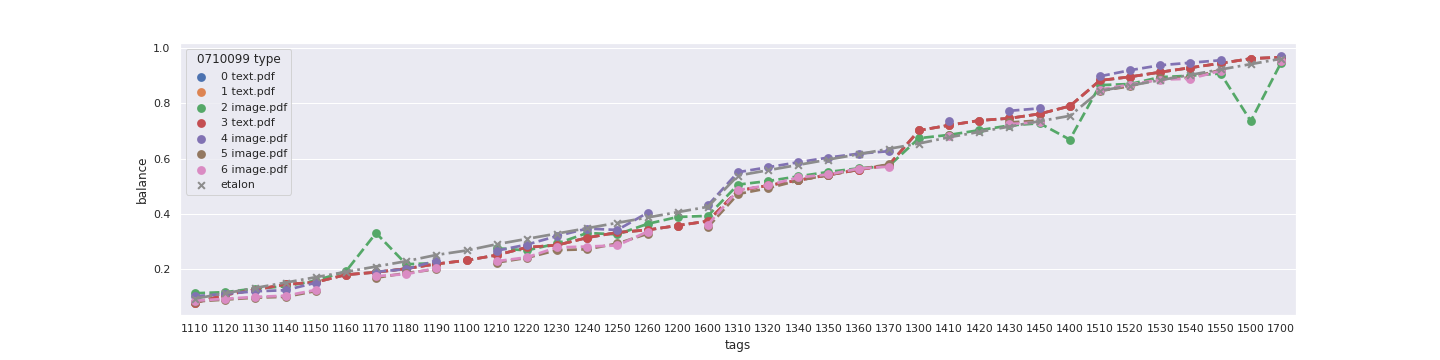
На графиках показаны кривые, отражающие относительную координату положения тегов раздела «Бухгалтерский баланс» в двух форматах — 0710099 без таблицы (верхний график) и 0710001 с таблицей (нижний график) — а также положение этих же тегов, найденных при помощи rule-based-алгоритма (полный перебор по нормальным формам токенов). Общая accuracy расстановки тегов для приведенного графика составила 0,91 для rule-based-алгоритма.

У другой формы, выбранной для теста, общая точность rule-based-алгоритмов равна 0,88, tree-based-алгоритмов — более 0,95. Результат ожидаем: априори более мощные tree-based-алгоритмы за счёт многообразий деревьев и ансамблей, которые перестраиваются, работают лучше с большими выборками сложных данных.
Последний этап, после определения положения тегов в файле, — это сбор и фильтрация кандидатов-токенов как значений показателей ФО. По сути предсказания связи между кандидатом-токеном и тегом. Собрав токены из элементов и отобрав только те, которые имеют POS tag «NUMB», мы трансформировали каждый из них в вектор и использовали для фильтрации множество признаков, в том числе:
элемент-контейнер содержит три и менее токена или нет;
соседние токены — символы скобок или иные символы;
есть ли значения у предыдущего тега;
равен ли кандидат уникальному коду тега;
входит ли значение текущего токена во множества уникальных идентификаторов тега;
каковы координаты положения токена (спан) относительно начала словосочетания — синонима тега;
каковы координаты положения токена (спан) относительно положения уникального идентификатора тега.
С векторами такого вида rule-based-алгоритм даёт качество фильтрации величин с accuracy в диапазоне от 0,63 до 0,95. Tree-based-алгоритмы стабильно показывают результат более 0,9.
Итоги разработки
С помощью нашего подхода мы привели данные, имеющие различное представление, к единому виду и свели сложный процесс к решению двух задач из области NLP.
Этот подход ещё можно сильно улучшить, подтянув OCR и чтение .pdf-файлов. Алгоритм доказал свою работоспособность, показав уровень верной обработки качественных сканов свыше 90 %.

Большинство ошибок происходит как раз из-за низкого качества сканов, в которых машине труднее разобраться. Сейчас нас больше интересует стабильность пилота, чем эта сфера, но мы думаем над решениями и по ней. MVP нашего решения, который мы показали в середине этого года, работал с довольно ограниченным кругом документов — только с файлами .pdf бухгалтерских отчётов. Сейчас мы уже значительно расширили функционал для пилота, решение справляется с четырьмя типами документов ФО.
Его преимущество — возможность расширяться на новые типы документов ФО без сборки и разметки дополнительных данных. Для внедрения распознавания новых форм всего лишь необходимо добавить новый шаблон формы и эталонный образец для расчёта относительных координат. То есть проект легко можно заточить под различные задачи вне первоначального применения. Надеюсь, в будущем он спасёт ещё многих работников разных направлений от связанной с документацией конвейерной рутины. Делитесь мнениями в комментариях, интересно узнать, что вы думаете.
bdsmsql
Спасибо за статью! Как я понял по последнему скрину, ваш алгоритм не нашёл все 3 значения для некоторых показателей, а слева видно, что файл отсканирован не ровно(под углом), и это натолкнуло меня на интересную идею - поворачивать изображение. Думаю по наклону границ таблиц это будет легко реализовать)
cbibop Автор
Спасибо за комментарий, действительно определение и поправка на угол дополнительно повышают качество решения задачи OCR. Но не стоит ориентироваться на границы таблицы, как я уже упоминал, их может и не быть. Глобально ориентацию мы определяем при помощи tesseract, он умеет определять перевёрнутые/повернутые страницы, однако, он не чувствителен к небольшим наклонам, на подобие того, который Вы заметили. В этом случае мы ориентируемся на средний угол наклона эллипсов, вписанных в полигоны определенные горизонтальным ядром. Opencv умеет это делать практически из коробки.