
Привет, Хабр! На связи команда направления прогнозирования промо в «Магните». В предыдущей статье «Магнитная аномалия: как предсказать продажи промо в ритейле» мы дали читателю общее представление о том, чем занимается наша команда. Теперь поговорим о конкретных сложностях и методах их решения, с которыми нам приходится сталкиваться в работе.
Чтобы лучше разобраться во внутренней кухне, предлагаем читателю вместе прогуляться по нашим «девяти кругам прогнозирования промо спроса».

Первый круг прогноза: масштаб
Здесь находятся грешники, которые недооценивают масштабы крупного ритейла.
Говоря о масштабе «Магнита», мы подразумеваем сразу несколько проблем и факторов, требующих внимания при прогнозировании: география, разные форматы магазинов, объём вычислительных ресурсов и производительность.
Начнём с географической составляющей. Компания представлена почти в 4 тысячах населенных пунктов, ежедневно магазины сети посещают около 14 млн человек. К началу 2022 года «Магнит» насчитывал свыше 26 тысяч торговых точек в 67 регионах России. Традиционный для моделей машинного обучения метод учёта региональных особенностей потребления (включая разные профили сезонности, локальные праздники и другое) через «навешивание» большого количества признаков не даёт ожидаемого результата. Связанно это с тем, что по отдельности они имеют достаточно слабое влияние и, зачастую, добавляют шумов в модель. Особенно явно это проявляется в прогнозе промо, который, в отличие от регулярного, обладает набором очень сильных базовых фичей (вроде скидки).
Для решения проблемы мы используем несколько вариантов кластеризации:
Разрезы обучения моделей, объединяемые по региональным или иным географическим признакам, которые строятся выше уровня магазина.
Кластеризация объектов между собой по значимым признакам при помощи отдельного алгоритма, разработке которого предшествует аналитическая работа. Например, разделение объектов с точки зрения внутригодовой миграции трафика на «Городские», «Дачные» и «Курортные». После проверки и подтверждения значимости признака кластера могут подаваться обратно в модель.
Расчёт сезонных и праздничных приростов для укрупнённых товарных категорий в разрезе малых территориальных единиц при помощи адаптированных решений на базе библиотек Prophet, Orbit.
Разберём второй фактор масштаба — разные форматы со своими особенностями в глубине и составе ассортимента, конкурентном окружении, динамике посещения, промо-механиках и прочих параметрах. На сегодняшний день у «Магнита» есть следующие форматы:
«Магнит у дома»;
«Магнит Косметик»;
Супермаркет «Магнит Семейный»;
Суперстор «Магнит Экстра»;
«Магнит Аптека»;
Дискаунтер «Моя цена» и другие.
Чтобы качественно прогнозировать промо, для каждого из форматов мы используем разный набор инструментов:
Адаптация зарекомендовавших себя в ключевых форматах моделей под новые с помощью корректировки набора параметров и изменения детализации обучения из-за разной плотности представленности объектов.
Разработка новых моделей под конкретный формат.
Например, при масштабировании прогнозной машины на формат «Магнит Косметик» мы столкнулись с новой проблемой — крайне малый объём статистики для конкретного товара. Особенности формата предполагают широкий ассортимент товаров с длительными сроками годности, каждый из которых имеет достаточно низкую частоту продажи. Созданные ранее модели значительно просели по метрикам, из-за чего нам пришлось дорабатывать подход к прогнозированию по нескольким направлениям:
Разделение прогноза на два этапа: прогнозирование вероятности совершения покупки и прогнозирование объёма.
Разработка новых моделей с альтернативным набором параметров, большим сроком обучения и иной архитектурой.
Подбор оптимальной функции потерь для моделей, которая лучше учитывает особенности формата.
И наконец третий фактор масштаба — технологии, объём вычислительных ресурсов и производительность.
Предположим, заказчику необходимо посчитать прогноз промо для линейки из десяти товаров его категории, представленной во всех форматах магазинов. Это около 26 тысяч торговых объектов. Объём уникальных записей для расчёта составит: 26 000 * 10 = 260 000. А если заказчик решил поиграть со входными параметрами акции (например, уровнем скидки или периодом проведения акции) и хочет рассчитать пять вариантов, выбрав оптимальный? Тогда объём уникальных записей для расчёта возрастает кратно количеству вариантов: 26 000 * 10 * 5 = 1 300 000. Если брать в расчёт только основные товарные категории верхнего уровня, регулярно участвующие в промо, то количество заказчиков — более 30. На выходе получаем: 26 000 * 10 * 5 * 30 = 39 000 000 записей на расчёт для каждого из production алгоритмов.

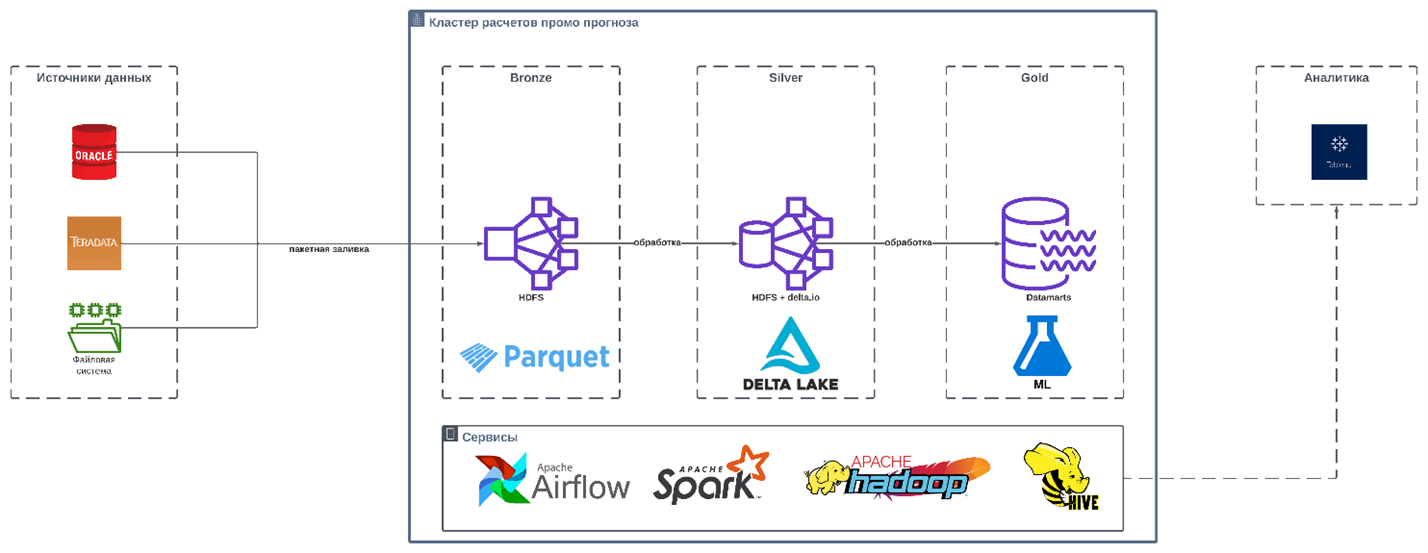
Теперь подробнее расскажем о стеке технологий, который позволяет нам обрабатывать такие объёмы вычислений.
Точкой отсчёта для нас является Teradata, где хранятся все корпоративные данные (КХД или DWH). Отсюда мы транспортируем в Hadoop необходимую нам информацию (продажи, остатки, статистика промо, календари, операции, лояльность, цены, скидки и прочее). Транспортировка (ELT) осуществляется с помощью Spark на базе Python (PySpark), а управление задачами транспортировки производится в Airflow.
Для нас Teradata — пласт RAW-данных, которые после попадают в первичный слой ODS или бронзовый уровень данных — это формат, приближенный к реляционному (по сути, табличный вид). Данные переводятся в формат .parquet и являются первой частью нашего Data Lake. Далее мы переводим их в формат .delta для использования надстройки delta.io, которая предоставляет возможность работать с данными в OLAP и OLTP-режиме. Задачи формирования этого слоя, который занимает около 250 ТБ, также управляются с помощью Airflow.
На следующем этапе данные обрабатываются также с помощью Spark, но задачи уже делятся на реализуемые с помощью модулей Scala и Python (Scala — обрабатываются быстрее, а Python — при более сложной логике обработки, например, когда нужно применить статистические методы). Этот слой мы называем DDS (или серебряный) — данные будут использованы в подготовке итогового уровня, которым питаются модели машинного обучения. Задачи формирования этого слоя, который составляет около 10 ТБ, также управляются с помощью Airflow.
Итоговый, золотой слой DM, содержит датамарты, которые мы также формируем с помощью Spark (PySpark) и используем в моделях машинного обучения в виде пользовательских функций для отдельных подгрупп данных (UDF), что хорошо ложится на концепцию MapReduce в Hadoop. Задачи формирования этого слоя также управляются с помощью Airflow.
Объемы данных при переходе от DDS к DM могут составлять от 1 до 10 ТБ, а количество итоговых моделей машинного обучения — от 1 тысячи до 10 млн штук (зависит от детализации обучения и количества подгрупп). Данные для прогноза также транспортируются с помощью Spark (PySpark), а управляются Airflow: транспортировка идет с клиентской стороны из Oracle и в рамках обработки попадает в слой DM в виде датамарта, который необходимо использовать для формирования прогноза с помощью ранее полученных моделей машинного обучения. Итоговые прогнозные данные являются источником для Hive, который в виде внешних таблиц способен транслировать реляционные данные обратно в DWH — этот блок ETL осуществляется с помощью Informatica, так как этот софт хорошо работает с Teradata.
Мы также используем Hive как источник для аналитики BI (в нашем случае, Tableau), что очень удобно для проверки различных гипотез и дебага.
На этом этапе SLA и объемы данных позволяют нам работать с ETL/ELT в режиме пакетной заливки, но вскоре мы планируем перейти на микропакетную и потоковую загрузку данных с помощью стека Spark Structured Streaming + Livy/Kafka + NiFi. Текущая нагрузка на систему предполагает формирование прогноза каждые 15 минут для матриц размером 25 млн строк на 10-60 колонок (зависит от алгоритма).
Суммарный объем мощностей, которые мы используем, — более 25 ТБ для RAM и более трех тысяч CPU.
Второй круг прогноза: плечо прогнозирования
Сюда попадают люди, которые не ценят отведённое время.
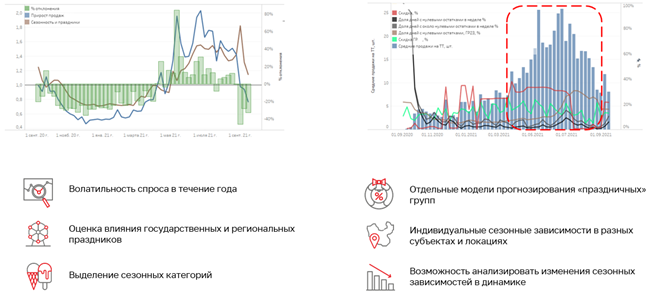
Одна из важных особенностей нашего бизнеса — длинное плечо прогнозирования. В среднем, у нас оно занимает от 40 до 70 дней, но бывают промо, которые необходимо прогнозировать за 200 и даже за 365 дней до старта акции! Причина такого длинного плеча — необходимость заранее планировать объёмы производства поставщиков под потребности такой крупной компании, как «Магнит», строить логистику, печатать каталоги, иную рекламную продукцию и проводить подготовительные процессы к промо на местах.

И если для бизнеса возможность планировать на такой горизонт —несомненный плюс, то для команды прогнозирования — это серьёзный вызов. В первую очередь, ограничение негативно влияет на качество прогноза в целом и особенно больно бьет по товарам с ярко выраженным сезонным характером потребления (как напитки или мороженое).
Подобное плечо не позволяет учитывать фактор накопленного потребления для будущих промо, ограничивает возможность оперативно реагировать на глобальные, влияющие на спрос внешние факторы (как в случае локдауна).
Эти требования стали отправной точкой создания новых решений, таких как:
Создание отдельных алгоритмов учёта короткого и длинного трендов;
Индивидуальные ветки расчёта сезонных промо, напрямую использующие суждение об аналогичных прогнозируемому периодах прошлых сезонов.
Отдельно стоит рассказать о зависимых от температуры и погоды категориях товаров. В подобных кейсах сложно держать высокое качество метрики, так как общего понимания профиля сезонности недостаточно, чтобы учитывать резкие локальные колебания погоды (например, понятие высокого сезона для мороженного в Новосибирске и Сочи имеют существенные отличия).
Очевидное решение — добавить в модели фичи, завязанные на температуру. К сожалению, нам не удалось добиться положительных результатов, так как адекватного прогноза температуры на полтора-два месяца вперёд не существует. Из-за низкого качества прогноза погоды завязанные на неё фичи скорее растили ошибку, чем сокращали её. Идея ушла «в стол», но легла в основу новой: мы совместно с бизнесом инициировали изменение процессов и начали прорабатывать логистическую возможность дозаказа товара в ограниченных объёмах ближе к старту акции. На своей стороне начали разработку корректирующей модели, учитывающей температурные колебания, осадки и накопленное потребление с плечом прогнозирования 7-14 дней. Подобная схема не исключает возможности заказа избыточного объёма товара, но минимизирует вероятность остаться без товара в промо и обнулить полку в высокий сезон для таких категорий, как мороженное, безалкогольные напитки, пиво и другое.
В итоге такая модель:
Потенциально точнее и позволяет оптимально распределять по магазинам имеющийся на складе товар.
Позволит сделать дозаказ товара на склад в процессе промокампании на основании актуализированного прогноза или поддерживать страховой запас товара для покрытия регулярной потребности по окончании промо.
Сейчас идея находится в стадии проработки.
Третий круг прогноза: методы и ограничения
Сей круг для душ, что не познали чувства меры и всё возводят в абсолют.
«Всё — яд и всё — лекарство, вопрос лишь в дозе».
IT гармонично существует в крупных компаниях до тех пор, пока оперативно и эффективно решает актуальные для бизнеса проблемы, увеличивая его общую ценность. С точки зрения постановки целей верхнего уровня, ведущую роль играет бизнес. В свою очередь, результаты нашей работы тесно связаны с реальными экономическими показателями компании. Часто на глубокий долгий research нет времени или возможности, рабочее решение требуется здесь и сейчас до окончания процесса разработки более сложных вещей. В других ситуациях отсутствует возможность оперативно получить необходимые для разработки технически сложных решений источники данных, так как это требует доработки корпоративного хранилища, изменения процессов и т. д. Также необходимо учитывать, что изменения процессов, принципов учёта и технологий, требуемые для реализации отдельных задач направления, могут быть нецелесообразны или нерентабельны для бизнеса в целом. Всё вышеперечисленное заставляет команду постоянно адаптироваться к актуальным требованиям и искать баланс между долгой разработкой космических кораблей и самокатов, позволяющих решить проблему здесь и сейчас.
Например, при появлении задачи «Учитывать новый вид рекламной коммуникации в приложении» можно уйти в разработку фичей для алгоритмов, а на финальном этапе осознать, что качественная разметка планируемых коммуникаций будет реализована лишь через полтора года. Либо проанализировать влияние прошедших коммуникаций на продажи и принять решение о необходимости исключения этой статистики из датасета.
Главным критерием истины в нашей работе является подтверждённый практикой результат, однако и здесь возникают подводные камни. Для получения объективных результатов влияния доработок или внедрения новых алгоритмов на целевые метрики требуется проведение качественного A/B-теста. Таким образом, для тестирования одной доработки необходимо пройти долгий путь: анализ — формулирование гипотезы — разработка решения — планирование теста — проведение теста — анализ результатов — разворот решения в production. Как мы помним из пункта выше, плечо прогнозирования в нашем случае может составлять 70 и более дней. В этих условиях внедрение отдельно взятой доработки может затянуться на полгода! Помимо этого, имея ограниченный аналитический ресурс, параллельные тесты будут копиться как снежный ком, если длительность каждого из них будет составлять два и более месяца.
{kind=link}
Чтобы выдерживать баланс между темпами релизов новых доработок и контролем их качества, мы используем несколько видов тестов и матрицу критериев доверия гипотезам.
Тесты можно условно разделить на группы:
Ретро-тесты* — наиболее популярные в нашем случае, т. к. наименее требовательны ко времени проведения и позволяют получить общее представление о влиянии доработки на результат; являются обязательным первым шагом для тестирования любых изменений. Обратная сторона медали — зависимость свершившегося факта от рассчитанного ранее прогноза. Таким образом, для правильной интерпретации результатов теста необходим учёт дополнительного набора параметров.
*Ретро-тест
Ретро-тест — тест, при котором оценка результатов проводится относительно уже свершившегося факта, при истории обучения, фиксированной на реальную дату расчёта модели.
Параллельный расчёт* — позволяет в процессе принимать решение о возможности внедрения в production, также выполняют функцию проверки качества реализации доработки.
*Параллельный расчёт
Параллельный расчёт — единовременный с боевыми (с учётом всех правил и ограничений) расчет тестовых моделей, результаты которого не возвращаются заказчику, а копятся для дальнейшей оценки доработки
A/B-тесты — самый затратный по времени тест, дающий наиболее достоверную оценку результатов. Из сложностей, помимо фактора времени: ключевая метрика (WMAPE) является производной метрикой отношения (ratio), что накладывает набор дополнительных ограничений и проблем при планировании и проведении теста; не существует двух одинаковых магазинов, каждый магазин имеет индивидуальное распределение метрик, что приводит к росту дисперсии.
В зависимости от качества и волатильности результата в рамках предварительных тестов, охвата объёмов, важности и уровня доверия гипотезе она может попадать в одну из групп тестов или во все сразу.
Критерии применимости набора тестов для оценки гипотез (для наглядности в примере используем RICE*) в упрощённом виде представлены в таблице.

*RICE
RICE = (R * I * C) / E
R — охват доли прогнозируемых связок, на которые потенциально оказывает влияние доработка
I — потенциальный эффект (в нашем случае — рост точности и/или улучшение баланса ошибки)
C — уверенность в гипотезе
E — затраты на внедрение/сложность (включая вычислительные мощности и человеческий ресурс)
В реальных задачах существуют дополнительные критерии, от которых зависит принятие решения о подходе к тестированию. Например, срочные доработки со сроком внедрения от недели до нескольких месяцев позволяют проводить только ретро-тесты. При возникновении необходимости внедрения доработок/алгоритмов, использующих новые источники/библиотеки оптимальным решением будет запуск параллельного расчёта, чтобы убедиться в отсутствии скрытых рисков или технических ошибок в реализации.
Четвёртый круг прогноза: механики промо
Этот круг для тех, кто не умеет быстро адаптироваться к изменениям окружающей среды.
В современном ритейле существует широкий спектр механик проведения промо, оказывающих значительное влияние на прогноз. Механика акции — это набор правил и условий, выполнение которых необходимо для получения выгоды покупателем. Классическая, знакомая и понятная всем механика — прямая скидка. Она же является наиболее простой сущностью с точки зрения прогнозирования. Но промо не ограничивается прямой скидкой, существует большое количество специфических механик, число которых растёт с каждым днём. Приведём небольшую их часть:
Скидка на набор одного товара N+M (например, 1+1, 2+1, 3+2 и прочие варианты)
Скидка на чек при достижении определённой суммы покупки
Скидка при покупке двух разных товаров
Скидка по выданным ранее купонам
-
Прогрессивная скидка:
при покупке до трех штук скидка — 5%;
3-6 штук — 10%;
6 штук — 20%
Выдача дополнительных бонусов за покупку (например, «Скрепыши»)
Примеры нестандартных промомеханик, которые проходили в прошлом


Каждая из механик уникальна с точки зрения отклика покупателя (а значит, и объёма потенциальных продаж) и требует индивидуального подхода к прогнозированию. Однако трудности начинаются не в момент подбора методологии расчёта прогноза, а гораздо раньше — ещё на этапе сбора данных и подготовки датасета. Разберём проблему на отдельных примерах.
Механика «N+M». С точки зрения сухих цифр, акция «2+1» (скидка срабатывает при покупке трех товаров, один из которых покупателю достаётся бесплатно) равнозначна прямой скидке в ~33%, но в жизни всё иначе. Во-первых, в отличие от прямой скидки акция «склоняет» покупателя приобрести три товара вместо одного, чтобы получить скидку. Из этого следует, что итоговый объём продаж будет отличаться от механики прямой скидки, на которой обучались модели. Но что произойдёт, если часть покупателей проигнорирует промо и приобретёт одну единицу товара по регулярной цене? Это искажает статистику, т.к. в течение одного дня логируются продажи с разными ценами. Поэтому по факту реальная скидка, которую мы получаем в витринах данных с продажами, может варьироваться от ~10% до 33%. В редких случаях, если в магазине не было совершено ни одной покупки, отвечающей условиям механики, мы получим день продаж со скидкой 0%.
Мы решаем проблему, используя комбинацию фичей, размечающих тип акции, и подмену фактической скидки в данных на предусмотренную механикой (для 2+1, соответственно, 33%). Для части алгоритмов разрабатываем отдельные ветки расчета, в которых формируются выборки только из случаев с конкретной механикой проведения, а далее проходит несколько этапов фильтрации и агрегаций для итогового прогноза.
Механика «Купоны за покупку». Специфика: после оплаты на кассе покупатель получает купон, который сможет погасить только спустя несколько дней или недель при условии, что в чеке будет определенный товар/группа товаров. Сложность заключается в том, что мы доподлинно не знаем, какая доля покупателей, получивших купон, вернётся в каждый конкретный магазин в срок, обозначенный периодом проведения акции.
Таким образом, в случае обычной акции, все покупатели, приходя в магазин, знают о её проведении (видят жёлтый ценник/скидку), а нам необходимо спрогнозировать отклик на скидку. В случае с купонами мы сперва рассчитываем долю трафика в период их выдачи, которая к нам вернётся в период их гашения, и только потом — отклик на обозначенную в купоне скидку.
Пятый круг прогноза: рекламные коммуникации
В этот круг попадают те, кто боится столкнуться с неизведанным.
Рекламные коммуникации (РК) — мероприятия, направленные на информирование покупателей об условиях акции и дополнительное стимулирование спроса в период проведения промокампании. Существуют варианты коммуникаций, ставшие на сегодняшний день традиционными:
Баннеры на уличных щитах и остановках.
Реклама на ТВ.
Коммуникация на кассе в момент покупки.
Обложки каталога и другое.
Параллельно растёт число новых рекламных коммуникаций:
Таргетированная и нетаргетированная реклама в интернете и социальных сетях.
Коллаборация с блогерами и лидерами мнений.
Реклама и розыгрыши купонов в собственных приложениях.
Кросс-коммуникации с сервисами-партнёрами.
Сложность работы с подобными видами активностей заключается в наличии двух взаимосвязанных факторов:
Отсутствие возможности качественной оцифровки.
Уникальность каждой кампании, не позволяющая дать однозначную оценку влияния на прирост продаж.
Трудно ответить на вопросы: «Какой прирост будет во время проведения промокампании в конкретный момент времени с конкретным медийным или не медийным лицом?», «Какое количество людей посмотрит рекламу по ТВ в конкретное время и будет ли отличаться эффект при её трансляции на разных каналах?» Также оцифровке не поддаются такие субъективные параметры, как качество рекламной кампании, подобранные персонажи, музыка или видеоряд. Даже если выделить рекламу на ТВ в отдельную сущность, то её эффективность для разных товаров, размеров скидки, периодов проведения и географического охвата будет крайне неоднородной.
Исходя из описанных ограничений, работу с коммуникациями мы сперва пропускаем через аналитический блок, который оценивает степень их влияния на продажи. Достигается это путём подбора и сравнения максимально близкого (по широкому набору параметров) промо с коммуникацией/без неё и дальнейшей агрегации результатов по критериям, связанным как с характеристиками товара, так и с форматом рекламы. На выходе мы получаем набор «ключей» и соответствующих им коэффициентов прироста спроса в РК, отличающихся глубиной расчёта в зависимости от объёма статистики. Следующим этапом проводим корректировку расчётных коэффициентов под цели бизнеса, оценивая баланс ошибки на ретро-тестах, и определяя целевое смещение её вектора (при необходимости). При расчёте итогового прогноза по промо с РК мы берём за основу базовый и обогащаем его имеющимися коэффициентами.
Однако расчёт коэффициентов является лишь верхушкой айсберга, потому что, помимо получения прогноза, необходимо очистить датасет от влияния коммуникаций в прошлом. Использовать полученные ранее коэффициенты для решения этой проблемы не всегда возможно: разрез, до которого они рассчитаны, может не подходить для отдельно взятой позиции, и, как говорили ранее, сами приросты от коммуникации могут быть волатильны внутри себя относительно среднего значения. Также бывают случаи, когда по конкретной позиции в принципе отсутствует статистика проведения РК. Такой парадокс: пытаясь очистить временной ряд от аномалий, мы сами создаём аномалию.
Опытным путём мы выработали дифференцированный подход для решения проблемы. Периоды с агрессивными коммуникациями исключаем из истории обучения; для менее агрессивных используем разметку через бинарные признаки. В некоторых случаях, при высокой степени доверия рассчитанным коэффициентам мы используем информацию о РК для очистки от их влияния на продажи, что позволяет приблизиться к стационарности в наблюдениях временного ряда. Оптимальное решение индивидуально подбирается под алгоритм и тип коммуникации и проходит проверку на практике.
Шестой круг прогноза: статистика, которой нет
В этот круг попадают грешные души, впадающие в уныние при столкновении с трудностями.
Вопросы качества статистики и факта её наличия имеют первостепенное значение в прогнозировании. Несмотря на наличие огромного корпоративного хранилища, где мы храним петабайты информации обо всех операциях в виде миллионов транзакций, с вопросами о полноте и качестве данных приходится сталкиваться ежедневно.
Говоря о «Магните» как о единой сущности, мы упускаем важную деталь — каждый отдельно взятый магазин является самостоятельной живой системой, внутри которой ежеминутно происходят десятки событий, определённым образом влияющих на продажи. Персонал забыл поменять ценник или не успевает вовремя пополнить полку? А если рядом с магазином сломался светофор, и это отрезало часть трафика с противоположной стороны дороги? Все эти факторы не могут быть оцифрованы, но оказывают прямое влияние на продажи как отдельных товаров, так и магазина в целом. Существуют и более глобальные проблемы, например, проблемы с отгрузкой со стороны поставщика, при которых часть магазинов в любом случае останется без товара. Бывают обратные ситуации, когда покупатель совершает оптовую закупку, пробивая одним или несколькими чеками весь остаток промотовара в магазине. В итоге совокупность всех подобных случаев ложится в статистику продаж торгового объекта.
Возникает вопрос: нужно ли с этим бороться и какие способы подойдут лучше?
Существует стандартный набор статистических методов очистки данных от аномалий, но в нашем случае это имеет ограниченную область применения по двум причинам:
Малый объём статистики промо у отдельно взятых позиций.
Промо неоднородны внутри себя и за каждой отдельной акцией скрывается ряд причин, влияющих на результат, но неизвестных в моменте.
Со всплесками продаж мы успешно справляемся, используя несколько моделей, которые в разных разрезах видят сущность продажи, за счёт чего страхуют друг друга от высокого профицита прогноза.
А вот фактор OOS* — серьёзная головная боль:
*OOS
OOS (out of stock) — физическое отсутствие товара, который разрешён к продаже и присутствует в учётных системах, на складе или магазине
Обучение на периодах с OOS может приводить к циклическому дефициту прогноза в будущем: OOS — дефицит — OOS — ∞.
Вероятность OOS в промо всегда выше, чем в регулярных продажах (отсутствие поставок, проблемы с логистикой, дефицитный прогноз и т. д.).
Полное исключение периодов с OOS из истории обучения — спорное решение, так как сводит к минимуму и без того малый объём статистики наблюдений в промо.
Для решения этой проблемы мы создали отдельный алгоритм, целью которого является восстановление продаж для постепенного выхода из цикла, описанного выше.
А если статистика продаж полностью отсутствует?
У нас, как и в любой сети, существует ротация ассортимента, благодаря которой на полках появляется новый товар. В эту же категорию входят сезонные товары и ин-ауты*. По таким позициям также необходимо давать качественный прогноз.
Инаут
Инаут — товар вне регулярной ассортиментной матрицы, введённый с экспериментальными целями без точного понимания его дальнейшей вероятности постоянного присутствия в матрице.
Изначально проблему качества прогноза для подобных товаров мы решали при помощи отдельного алгоритма, использующего статистику продаж аналогов. Он последовательно проверяет наличие наблюдений в истории по приоритетам:
прямые аналоги, определённые сотрудниками, ответственными за ввод новых позиций в сеть (категорийный менеджер);
набор фасетных свойств товара (бренд, тип упаковки, вес, вкус) с учётом ценового сегмента и географии его представленности.
Это legacy решение, которое неплохо работает на практике. Данный подход оставался основным на протяжении длительного периода, пока мы не пришли к идее создания новой модели, состоящей из двух взаимосвязанных частей:
модель кластеризации на основании расширенного количества признаков;
модель классификации, которая присваивает соответствующий кластер новым товарам.
Эта модель находится на этапе разработки и тестирования. За счёт её внедрения мы рассчитываем повысить качество прогноза новинок и уйти от этапа аналитики и ручного присваивания приоритета для набора признаков.
Ещё одно интересное явление — выход на потенциал. Помимо того, что любая новинка заходит в сеть без истории продаж, она имеет свойство не сразу выходить на ожидаемые показатели. И это тоже относится к вопросам качества статистики. Например, на полках наших магазинов появляется новый производитель сыра. На старте продаж вместо ожидаемых продаж 10 штук в день наблюдаем всего две штуки. Напрашивается вопрос: сыр плохой? Нет, просто покупателю нужно время, чтобы привыкнуть к наличию этого сыра на полке, попробовать, понять, что больше подходит его потребительской корзине в данной категории. Этот процесс мы называем «выходом товара на потенциал» или «раскачиванием спроса».
Аналитика показывает, что обычно этот процесс для разных категорий товара занимает от двух до шести недель. Эту особенность мы учитываем. Изначально пробовали размечать его в моделях, но столкнулись с тем, что такой статистики мало и фичи разметки теряются в общей массе. Поэтому, пришли к выводу, что можем отказаться от статистики первых двух-шести недель продаж товара в датасетах, если позиция имеет достаточную накопленную историю продаж.


Седьмой круг прогноза: инфляция
Туда попадают те, кто пытается жить прошлым.
Говоря об инфляции, мы подразумеваем два разных явления, связанных с изменением цен в течение времени:
Долгосрочная инфляция и наличие в статистике цен, актуальных для рынка в конкретный период (понятие, близкое к классическому значению инфляции).
Краткосрочное изменение цен в период, сопоставимый с плечом прогнозирования. Это скорее искусственное ограничение, связанное со внутренними бизнес-процессами (см. плечо прогнозирования), но по формальным признакам отличается лишь длиной временного отрезка.
Остановимся подробнее на первом пункте — долгосрочной инфляции. Чаще всего для алгоритмов, прогнозирующих промо, связанные со скидками/ценами фичи имеют наибольшее влияние. И если скидка является относительным показателем, то цены — абсолютные величины, привязанные к конкретному моменту времени для каждого отдельного промо в истории. Когда мы подаём цены напрямую, рискуем получить искажённые результаты, если на периоде обучения алгоритмов были существенные изменения ценовой политики. Говоря простыми словами, знание, что продажи товара во время акции при цене 100 рублей растут в два раза, может являться ошибочным, если за прошедший с момента этой акции период изменилась ценовая политика как для данной позиции, так и для всей категории в целом.
Мы решаем эту проблему нормализацией фактических цен с помощью коэффициента изменения цены без скидки. В нашей гипотезе руководствуемся предположением, что цена без скидки отражает инфляцию и фактически мы выравниваем все цены до «нормальной». Так алгоритмы (например, деревянные) не затачиваются на изменения цен от инфляции.
Вторая важная проблема — изменение цен в промежутке после расчёта прогноза и до момента старта акции, что приводит к появлению скидок и цен, которые алгоритмы не видели ранее. Наиболее вероятный сценарий развития событий выглядит так: мы рассчитали прогноз за 40 дней до старта промо, исходя из имеющихся цен, а за неделю до старта промо произошло повышение, и регулярная цена на товар изменилась, при этом итоговая промоцена осталась неизменной. К моменту начала промокампании меняется итоговая скидка (в нашем примере — растёт), которую мы учитывали при прогнозировании. Далее мы можем наблюдать несколько интересных эффектов, зависящих от узнаваемости бренда и категории товара:
Спрос на товар существенно не меняется, если это товар первой необходимости или товар ежедневного потребления, для которого потребитель знает постоянный уровень цен и ориентируется в большей степени на итоговую стоимость (чем на размер скидки).
Прогноз становится дефицитным, так как размер фактической скидки выше, чем значения, которые алгоритмы видели на момент расчёта прогноза; покупатель сильнее реагирует на итоговое значение скидки относительно аналогов на полке.
Очевидно, что расчёт прогноза с сокращением плеча на актуальных данных поможет исключить негативное влияние этого фактора. Решение проблемы лежит скорее в плоскости изменения бизнес-процессов и системы пополнения магазинов, что является затратной, сложной и не быстрой в реализации задачей. В первую очередь, мы должны искать оптимальные решения на базе имеющихся вводных и требований заказчика, отталкиваясь от аксиомы «IT для бизнеса, а не бизнес для IT».
Существует и более интересный сценарий: вследствие изменения цен на этапе прогнозирования алгоритмы получают для расчета будущей промокампании значения цен/скидок, отсутствующие в истории обучения. Для решения проблемы мы используем в пайплайне несколько типов алгоритмов (линейные модели, бустинг на деревьях, мультипликативная модель и другое), блендинг результатов расчета которых дает минимальную ошибку. Так мы играем на особенностях алгоритмов — фичи цен и скидок линейных моделей чаще всего имеют наибольшие коэффициенты и их рост приводит к росту прогноза; бустинг же, получая на вход информацию, которую не видел в обучении, не умея экстраполировать, выдаёт прогноз в пределах имеющейся статистики наблюдений. Так нам удается сбалансировать прогноз разных моделей и решить как эту проблему, так и ряд других сложностей прогнозирования.
Восьмой круг прогноза: каннибализация
Сей круг предназначен для преисполненных гордыней в собственном всезнании, отрекшихся от истины.
«Чем больше я знаю, тем больше я понимаю, что ничего не знаю».
Вот мы и добрались до самой сложной и неоднозначной сущности, связанной с прогнозированием промо. Под каннибализацией подразумевается изменение объема продаж или доли рынка одного продукта в результате появления (или изменения цен) другого.
Например, на протяжении имеющейся истории продаж Товара-1 объёмом 1,5 л со скидкой в 40% продавалась ~250 штук на магазин в неделю. Но по окончании очередного промо наш прогноз оказался сильно профицитным, а фактические продажи позиции упали до 70 штук на магазин, при неизменных вводных. Проведя аналитику по итогам прошедшего промо, обнаружили, что в этот же период проводилась акция по Товару-2 со скидкой 50% и значительная доля спроса в рамках товарной категории перетекла на эту позицию.
Только на практике (в зависимости от цены, скидки и других факторов) взаимное влияние на продажи оказывают не два товара, а всё представленное множество. Более того, каннибализация может присутствовать не только в рамках малой товарной группы, но и в пределах сущностей более высокого уровня (между газированными напитками и соками и/или минеральной водой), включающих в себя десятки разных товаров в одном магазине. Проблема напрямую или косвенно затрагивает все обозначенные явления: изменится ли влияние Товара-2 на продажи Товара-1, если по одной из позиций дополнительно запустить рекламу на ТВ и в интернете? А если изменится механика скидки на Товар-2 с прямой скидки в 50% на «1+1» или на момент старта акции ещё один товар-аналог появится на полке с уценкой в 30%?
Существуют примеры и обратной каннибализации, когда дефицит товара или резкое сокращение количества параллельного промопредложения в отдельной категории товаров значительно повышает спрос на не самый популярный ранее ассортимент. Количество возможных комбинаций даже в отдельно взятом магазине очень велико.
Для корректного учёта таких явлений в прогнозе необходимо иметь статистику и возможность расчёта всех возможных комбинаций «товар — набор условий» по всем наименованиям в рамках хотя бы одной категории, что само по себе невозможно в текущих реалиях по следующим причинам:
Ассортимент не статичен во времени, а постоянно меняется.
Для множества уникальных комбинаций отсутствует достаточный объём статистики.
Долгие расчёты всего множества комбинаций, требующие огромных вычислительных мощностей, несоразмерны получаемому эффекту.
Решение вопроса каннибализации близко к NP-полной задаче.
Несмотря на описанные сложности, существует набор методов, которые не решают проблему глобально, но позволяют приблизиться и закрыть часть ошибки, связанной с каннибализацией, но это тема для отдельной статьи.
Девятый круг прогноза: кадры решают всё
В этот круг попадают те, кто не осознал, что самый ценный капитал — это люди.
Рынок в последнее десятилетие и особенно в постпандемийный период ощущает острую нехватку IT специалистов. Мы также участвуем в гонке за возможность получить хороших специалистов. У нас современный стек технологий, большие данные, отличная команда и конкурентная оплата труда, но как показывает практика — классическая задача прогнозирования не слишком привлекательна для потенциального соискателя. Нам трудно соперничать с компаниями, вакансии которых связаны с областями компьютерного зрения, рекомендательных систем и других, более хайповых современных задач машинного обучения. Это данность, с которой приходится жить.

Кроме того, нам приходится сталкиваться и с обратной стороной медали — соискатель хорошо подкован в теории и имеет несколько завершенных проектов с предыдущих мест работы, но у него нет опыта и представления о работе с большими массивами данных. В итоге, придя к нам в «Магнит», он оказывается не готов решать задачи в рамках строгих ограничений и SLA. Это наметившийся тренд: в отрасли специалисты привыкают к тому, что data scientist работает с готовыми датасетами, а data engineer их собирает. Практика показывает, что DS без базовых знаний и навыков Spark/SQL менее эффективный и на дистанции медленнее приносит результат, нежели специалист с их наличием.
Если взглянуть на проблему шире — на рынке большое количество специалистов, способных качественно решать набор типовых задач из области ML по заранее прописанному алгоритму действий. Проблемы возникают в момент, когда они вынуждены выйти за рамки понятного сценария: будь то самостоятельный сбор и подготовка данных для моделей или необходимость поиска и разработки нестандартного решения. Часто мы сталкиваемся с такой проблемой: специалист не понимает, что результат его работы имеет прямое влияние на реальные события и бизнес-функции. То есть для качественного выполнения задач требуется навык правильной интерпретации последствий внедряемых доработок и способность нести ответственность за результат.
В ситуациях, когда трудно привлечь готового специалиста высокого уровня, владеющего необходимым стеком новых для нас технологий, мы отправляем первопроходца из «золотого фонда» команды для самостоятельного освоения. После чего организуем трансфер знаний и навыков внутри команды. Основной минус данного подхода — фактор времени и постоянная необходимость обучаться без отрыва от основной работы.
Несмотря на возникающие трудности мы с завидным упорством продолжаем набирать и обучать людей, помогаем им в освоении новых технологии. И смотрим на этот процесс с умеренным оптимизмом, так как каждый из нас начинал с малого, а многие опытные члены команды даже не имели прикладного образования. Пройдя тернистый путь становления и развития, с уверенностью можем сказать: все достижения возможны только благодаря людям, с которыми мы ежедневно встречаемся в офисе, на онлайн-конференциях и в рабочих чатах.
В завершении нашей прогулки по «девяти кругам прогнозирования промо» хочется сказать: надеемся, что статья будет интересна широкому кругу читателей, а наш опыт принесёт пользу коллегам. Мы хотели рассказать об «узких местах» и поделиться особенностями своей работы, среди которых каждый сможет найти для себя что-то ценное. Постараемся по мере возможности и дальше радовать вас материалами, основанными на реальных событиях.
Над статьей работали:
Ткаченко Андрей — He6puToCTb
Строганов Дмитрий — StrDA
Кравчук Дмитрий — dishkakrauch
Также авторы благодарят за помощь:
Иванченко Илью — tipprim
Покусенко Максима — remote_keeper
Хаитова Романа — KhRN
Четыркина Алексея
Ka_Wabanga
Прекрасная статья.
Всем кто работает с продажами и «stock estimation» читать обязательно. Если бы я, в начале своей работы, увидел эту статью, то сэкономил бы десятки дней на поиск нужной информации.
Главная ценность статьи в том, что это не просто теория из разряда «как бы мы сделали на примере Титаник датасета», а описание работы продакшен решения.
Читал и вспоминал все через что сами прошли и всю боль прогнозирования спроса.
Ka_Wabanga
Попробую сделать более подробный разбор, почему считаю статью хорошей.
В статье толком не говорится про технические детали, но отлично показан подход к проблеме и ее решение на высоком уровне.
"Первый круг прогноза: масштаб"
- Хорошо показан подход к разбиению моделей на подгруппы и индивидуальный подход к различным типам магазинов. В нашей работе мы делали тоже самое с поправкой на размеры сети и разницу в инвентаре - выделяли онлайн магазины и делали региональные и типовые кластеры. Такой подход дал возможность не только повысить точность предсказаний, но и дал возможность тренировать модели с меньшими ресурсами.
Объем датасета сильно раздувается за счет "intermittent" продаж и субкластеры по типам и подход к прогнозированию для каждой группы отличается (и функция потерь и фичи и горизонты итд).
В статье прекрасно показан подход к анализу того "что нужно предсказывать" и как подойти к анализу данных при существующих ограничениях в ресурсах.
Отдельные детали про ETL процесс и хранение данных великолепен.
Я не думаю, что многие "дата саентисты" представляют насколько сложно работать с таким количеством данных и через сколько "граблей" приходится пройти прежде чем "устаканить" процессы. Проблемы не только в объемах, но в консистенции исторических данных и сохранения всех изменений свойств продуктов в историческом срезе.
"Второй круг прогноза: плечо прогнозирования"
Предсказать продажи завтра и предсказать продажи на 6 месяцев вперед это совершенно разные задачи и при прогнозировании "стоков" и продаж важно понимать эту разницу. Важно понимать метрику и деградацию результатов, планировать кроссвалидацию и проведение а/б тестирования.
Если бы меня спросили - "как сделать правильно?", то я бы не смог ответить. Каждый бизнес уникален, уникальны данные и процессы - стабилизация подходов к предсказаниям и валидации разных горизонтов событий может занять годы. И это очень круто когда команда понимает что проблема существует и знает как можно попробовать ее решить.
"Третий круг прогноза: методы и ограничения"
Не знаю сколько ушло времени на подбор метрики ("ключевая метрика (WMAPE)"), но у нас это заняло месяцы . Сейчас у нас используются как минимум 4 разные метрики в "продашене" включая wMAPE, EVS, MAE и RMSLE и мы очень далеки от "консенсуса" по этому вопросу и постоянно спорим. Анализ результатов и правильная валидация - это даже более важная часть (как мне кажется) чем построение модели.
"Четвёртый круг прогноза: механики промо"
Модель будет настолько хороша, насколько хорошо понимание вами ваших данных и "фичер инжиниринг" исходящий с вашего понимания.
Пример со скидками отлично демонстрирует подход к пониманию и анализу данных и их влияния на продажи.
"Пятый круг прогноза: рекламные коммуникации"
Внешние данные могут сыграть одну из ключевых ролей в предсказании спроса и продаж. Конкурент открылся рядом, новая маркетинговая компания, Ковид, курс доллара. Очень много внешних факторов которые могу сильно сказаться на результатах и важно помнить, что они есть и замыкаться на данных, которые уже собрали.
"Шестой круг прогноза: статистика, которой нет"
Этот пункт заслуживает отдельного внимания - предсказания для новых продуктов и влияние запуска на конкурентов - это огромный обособленный мир моделей и подходов. Прекрасно, что люди, написавшие эту статью, понимают насколько это важно.
"Седьмой круг прогноза: инфляция"
Мне отдельно понравился момент понимания, что DS работает на решение реальных бизнес проблем, а не "встает в позу" и говорит "дайте нам чистые данные или не будет результата" - чистых данных не будет, всега будут расхождения, изменения и мутации и с этим приходится жить.
"Восьмой круг прогноза: каннибализация"
Нельзя выкинуть на рынок товар с 90% скидкой и ожидать, что продажи конкурентов не изменятся. Прекрасно, что есть понимание эластичности и влияния на группу товаров.
Я бы с радостью узнал какие подходы вы применяли к прогнозирования "канибализации" так как эту проблему на нашей стороне мы не решили.
"Девятый круг прогноза: кадры решают всё"
DS сейчас "тренд" и значит любой прошедший курсы на курсейре считает себя "датасаентистом", но одно дело крутить датасеты на кагле и другое дело "деплоить" модельки в продакшен. Могу сказать, что такой опыт нарабатывается болью - большой болью.
Еще раз спасибо за статью.