
Помните, как вы были студентами, и готовились к экзаменам по ночам?
Предлагаю вашему вниманию простую шпаргалку по SQL с теорией и практикой, которой вы сможете воспользоваться в любое время.

Статья пригодится:
ИТ специалисту, которому необходимо быстро освоить минимальный уровень SQL для выполнения рабочих задач,
Системному аналитику, которому требуется освежить знания перед собеседованием или научиться, если раньше не было задач с SQL.
В статье есть:
Минимум теории для задач на работе или собеседовании (прим. операторов в SQL больше, но в своей работе использовала чаще всего эти);
Практические задания, которые можно выполнить у себя на ПК бесплатно, предварительно установив сервер баз данных.
SQL теория
SQL (structured query language) - язык структурированных запросов, который позволяет работать с данными (найти, изменить, удалить или создать) в реляционной базе данных (БД).
Реляционные БД - это базы, где связанная информация, представленная в виде двумерных таблиц (например, Postgres, Mysql, Oracle и др.).
СУБД - система управления БД, программа с помощью которой можно создавать, наполнять и просматривать БД .
ER диаграммы (Entity-Relationship model) - показывает структуру и связи таблиц в БД. Помогает в написании SQL запросов.
Для работы мозга студенту нужна энергия. Проще всего ее получить из сладкого. Значит будем учиться на примере базы данных сладостей. Изучать теорию мы с вами будем на реальном примере.
Наша БД состоит из таблиц:

(прим. показана часть БД с необходимыми таблицами для выполнения практических заданий)
sweets_types - виды сладостей
Столбец |
Тип данных |
Обязательность |
Описание |
id |
integer |
not null (должно быть значение) |
Идентификатор вида сладости. PK |
name |
character varying |
not null |
Вид сладости |
manufacturers - производители
Столбец |
Тип данных |
Обязательность |
Описание |
id |
integer |
not null |
Идентификатор производителя. PK |
name |
character varying |
not null |
Производитель |
phone |
character varying |
Телефон |
|
adress |
character varying |
Адрес |
|
city |
character varying |
not null |
Населенный пункт |
country |
character varying |
not null |
Страна |
storehouses - склады
Столбец |
Тип данных |
Обязательность |
Описание |
id |
integer |
not null |
Идентификатор склада. PK |
name |
character varying |
not null |
Название склада |
adress |
character varying |
Адрес |
|
city |
character varying |
not null |
Населенный пункт |
country |
character varying |
not null |
Страна |
manufacturers_storehouses - связь производителя со складом
Столбец |
Тип данных |
Обязательность |
Описание |
id |
integer |
not null |
Идентификатор связи. PK |
storehouses_id |
character varying |
not null |
Идентификатор склада. FK |
manufacturers_id |
character varying |
Идентификатор производителя. FK |
sweets - сладости
Столбец |
Тип данных |
Обязательность |
Описание |
id |
integer |
not null |
Идентификатор сладости. PK |
sweets_types_id |
integer |
Идентификатор вида. FK |
|
name |
character varying |
not null |
Название сладости |
cost |
character varying |
not null |
Стоимость |
weight |
character varying |
not null |
Вес |
manufacturer_id |
integer |
not null |
Идентификатор производителя. FK |
with_sugar |
boolean |
С сахаром? true - да, false - нет |
|
requires_freezing |
boolean |
Требует заморозки? true - да, false - нет |
|
production_date |
date |
not null |
Дата изготовления |
expiration_date |
date |
not null |
Срок годности |
В таблице есть:
Столбцы (поля),
Строки (записи),
Ячейки (значение поля),
Ограничения поля (constraint): PK (primary key) - первичный ключ, FK (foreign key) - внешний ключ,
Тип данных поля.

В SQL выделяют основные 4 группы операторов:
DDL (Data Definition Language) – работа со структурой БД,
DML (Data Manipulation Language) – работы с данными таблиц,
DCL (Data Control Language) – работа с правами,
TCL (Transaction Control Language) – работа с транзакциями.
DML чаще всего спрашивают на собеседовании. DCL/DML нужны в работе системного аналитика. DCL, TCL в моей практике не приходилось пользоваться ни на собеседовании, ни в работе системного аналитика, поэтому в данной статье не будем их рассматривать, так как за ночь нужно выучить или вспомнить то, что действительно могут спросить на собеседовании (экзамене) или пригодиться в работе.
А теперь шпаргалки SQL операторов
Работа со структурой БД (DDL)
CREATE. Создание таблицы.
CREATE TABLE public.sweets_types
(
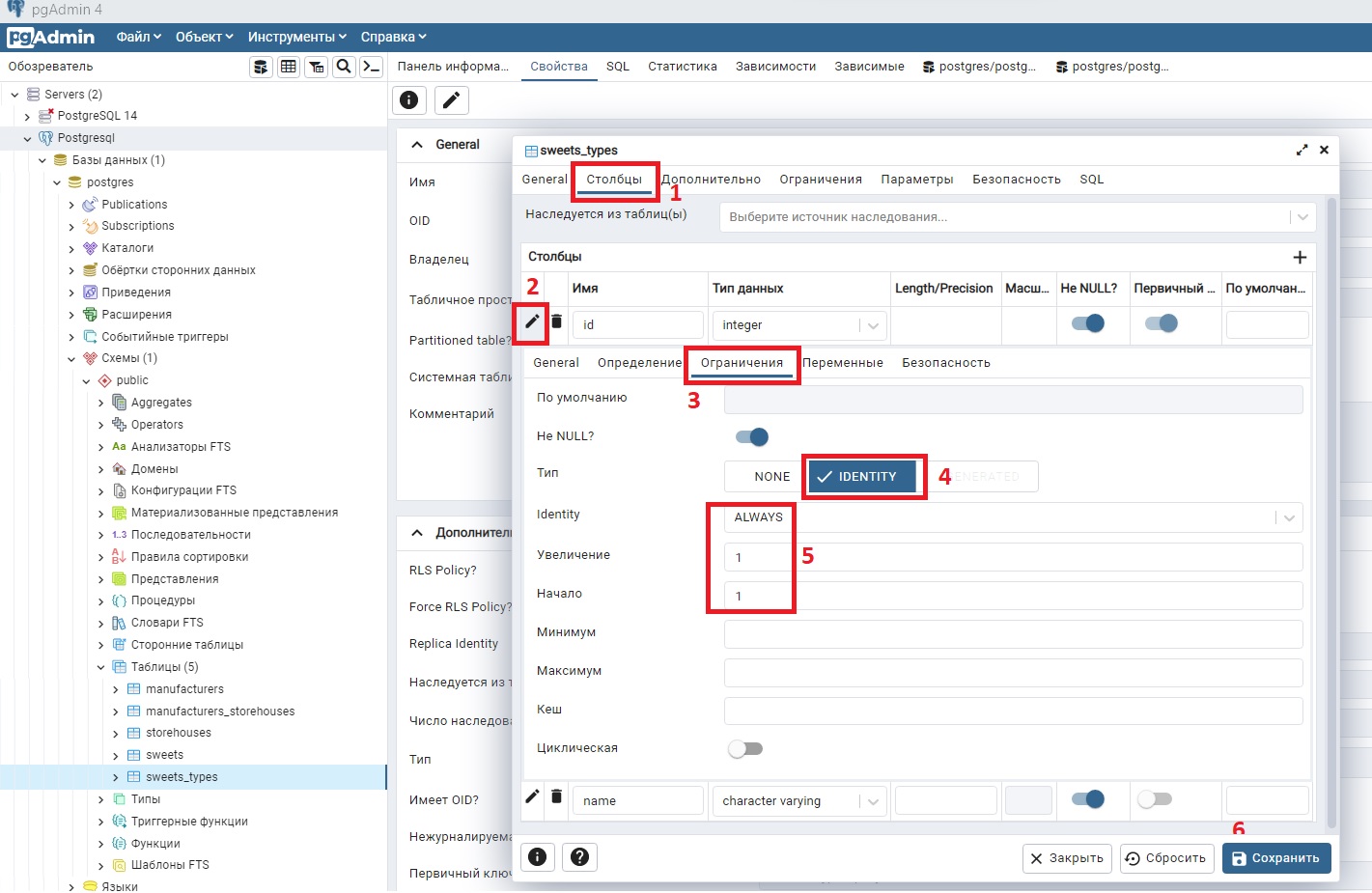
id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ),
name character varying NOT NULL,
PRIMARY KEY (id)Имя создаваемой таблицы указано в формате: Имя схемы.Имя таблицы.
Например, схема = public, имя таблицы = sweets_types, тогда имя создаваемой таблицы = public.sweets_types
Конструкция GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ) позволяет задать генерацию значения поля id от 1 с увеличением +1.
ALTER. Добавление, изменение или удаление столбцов в таблице.
Пример SQL запроса, который добавит столбец name_english с типом данных character varying в таблицу sweets_types
ALTER TABLE IF EXISTS public.sweets_types
ADD COLUMN name_english character varying;DROP. Удаление целиком таблицы из БД.
DROP TABLE public.sweets_types;TRUNCATE. Удаление всех записей из таблицы.
TRUNCATE TABLE public.sweets_types;Работа с данными таблиц (DML)
INSERT. Добавление строки в таблицу.
INSERT INTO public.sweets_types(name)
VALUES
('вафли'),
('конфеты');Столбец id в таблице sweets_types является PK и сгенерится автоматом при добавлении, поэтому в INSERT добавляем значение столбца name
UPDATE. Обновление данных строки в таблице.
UPDATE public.sweets_types SET name = 'вафли новые'
WHERE id = 1;DELETE. Удаление строки из таблицы.
DELETE FROM public.sweets_types WHERE name = 'вафли';SELECT. Просмотр данных из таблицы.
Все виды сладостей (идентификатор и имя)
SELECT * FROM public.sweets_types;Только имена видов сладостей
SELECT name FROM public.sweets_types;Другие операторы, которые можно использовать с DML (работа с данными)
Ниже приведены операторы условия, группировки, сортировки, объединения и агрегатные функции.
Структура запроса для поиска данных:
SELECT 'что' FROM 'из какой таблицы'
JOIN 'с другой таблицей'
WHERE 'условие'
ORDER BY 'сортировка'SELECT 'что' FROM 'из какой таблицы'
JOIN 'с другой таблицей'
GROUP BY 'группировка'
HAVING 'условие'DISTINCT. Возвращает уникальные значения, без повторений.
SELECT DISTINCT city FROM public.storehousesCOUNT. Количество строк (записей).
Посчитать количество сладостей, у которых вес равен 300
SELECT COUNT(id) FROM public.sweets
WHERE weight = '300';WHERE. Условие фильтрации записей при выборе данных.
Список сладостей, у которых стоимость равна 100
SELECT name FROM public.sweets
WHERE cost = '100';LIKE. Поиск значения по совпадению с выражением в столбце.
С оператором LIKE используются два подстановочных знака:
% - любое количество символов;
_ - один символ.
Найти список сладостей, которые начинаются на М.
SELECT * FROM public.sweets
WHERE name LIKE 'М%';AND, OR, BETWEEN. Оператор «И», «Или», «Между».
Список сладостей, у которых стоимость равна 100 и вес равен 100
SELECT name FROM public.sweets
WHERE cost = '100' AND weight = '100';Список сладостей, у которых стоимость от 100 до 150
SELECT name FROM public.sweets
WHERE cost BETWEEN '100' AND '150';Примечание: в выборку попадут сладости, у которых стоимость равно 100 и равна 150.
ORDER BY ASC, DESC. Сортировка в порядке возрастания (asc) или убывания (desc).
ASC можно не указывать.
SELECT * FROM public.sweets
ORDER BY name DESC;GROUP BY. Группировка столбцов.
SELECT sweets_types_id FROM public.sweets
GROUP BY sweets_types_id;HAVING. Используется для фильтрации по условию, когда есть группировка.
Найти склады, в которых количество сладостей больше 8
SELECT s.name FROM public.storehouses s
LEFT JOIN public.manufacturers_storehouses ms ON s.id = ms.storehouses_id
LEFT JOIN public.sweets sw ON sw.manufacturer_id = ms.manufacturers_id
GROUP BY s.name
HAVING COUNT (sw.id) > 8;Сначала сгруппируем сладости по складам, а затем через условие HAVING найдем те, у которых количество сладостей больше 8
SUM, MAX, MIN, AVG. Сумма значений, максимальное, минимальное, среднее значение.
SELECT SUM(id) FROM public.sweets;
SELECT MAX(id) FROM public.sweets;
SELECT MIN(id) FROM public.sweets;
SELECT AVG(id) FROM public.sweets;JOIN или INNER JOIN, LEFT JOIN, RIGHT JOIN. Объединение двух таблиц.
JOIN или INNER JOIN - возвращает записи, имеющие в обеих таблицах
LEFT JOIN - возвращает все записи из левой таблицы и те, которые есть в левой и правой таблице
RIGHT JOIN - возвращает все записи из правой таблицы и те, которые есть в правой таблице
Подробная работа с JOIN описана в статье.
SELECT * FROM public.sweets s
JOIN public.sweets_types st ON s.sweets_types_id = st.id
WHERE st.name = 'шоколад';SQL практика
Шаг 1. Установить инструменты для работы
Для выполнения практических заданий берем базу данных - Postgres и СУБД - pgAdmin.
Скачать Postgres и pgAdmin можно по ссылке,
Поставить показано в видео по ссылке,
Настроить подключение к серверу через pgAdmin описано в статье по ссылке, раздел 2. Запуск
ШАГ 2. Создаем таблицы в БД
В pgAdmin есть форма создания таблиц: Схемы -> public -> Таблицы -> Создать.
Заполните вкладки General, Столбцы.
Посмотреть картинки как это сделать в pgAdmin
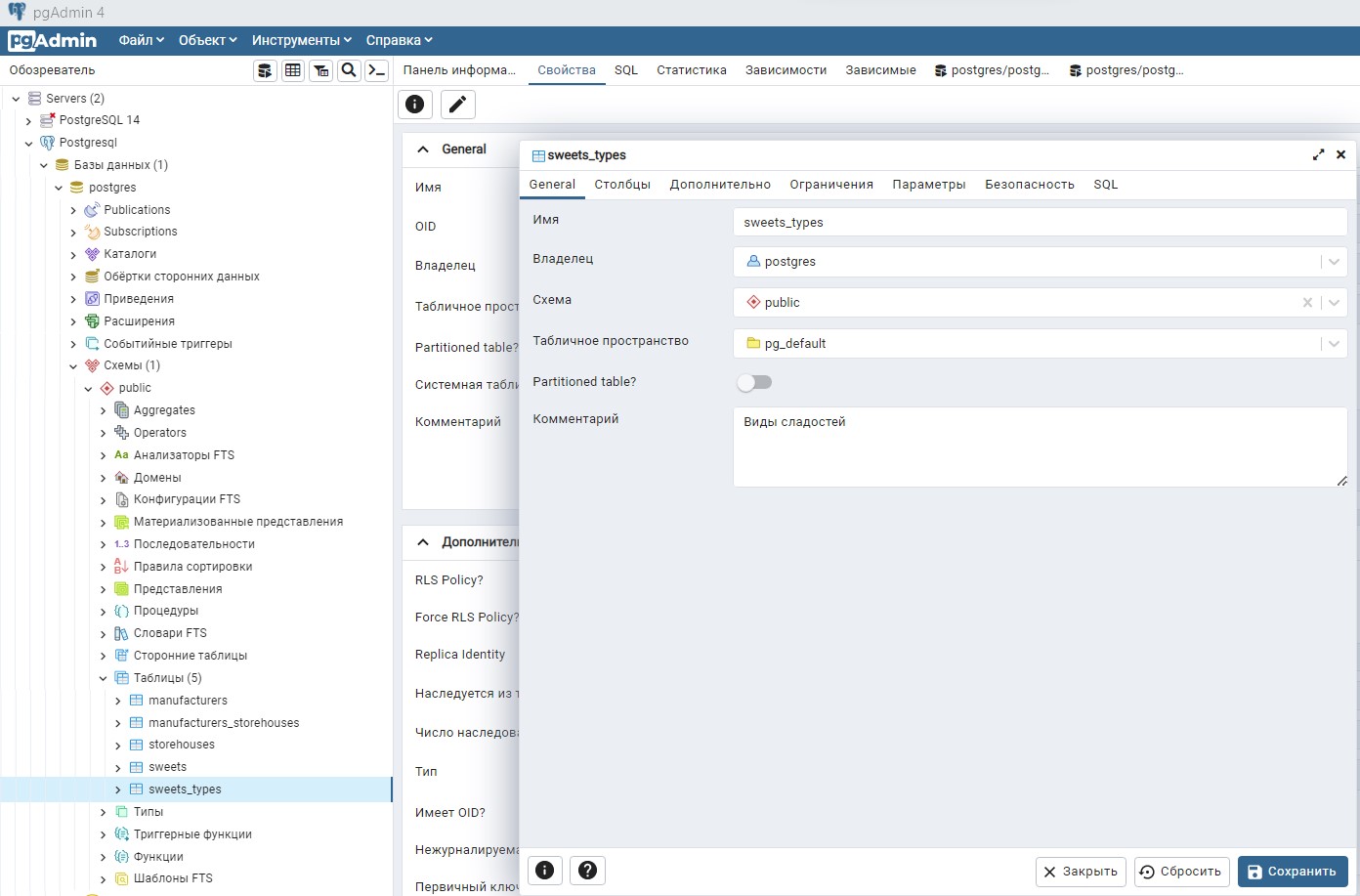
Для столбцов id в таблицах устанавливаем ограничения
Скрипт SQL на создание таблиц в БД
CREATE TABLE public.sweets_types
(
id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ),
name character varying NOT NULL,
PRIMARY KEY (id)
);
ALTER TABLE IF EXISTS public.sweets_types
OWNER to postgres;
COMMENT ON TABLE public.sweets_types
IS 'Виды сладостей';
CREATE TABLE public.sweets
(
id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ),
sweets_types_id integer,
name character varying NOT NULL,
cost character varying NOT NULL,
weight character varying NOT NULL,
manufacturer_id integer NOT NULL,
with_sugar boolean,
requires_freezing boolean,
production_date date NOT NULL,
expiration_date date NOT NULL,
PRIMARY KEY (id)
);
ALTER TABLE IF EXISTS public.sweets
OWNER to postgres;
COMMENT ON TABLE public.sweets
IS 'Записи о сладостях';
CREATE TABLE public.manufacturers_storehouses
(
id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ),
storehouses_id integer NOT NULL,
manufacturers_id integer NOT NULL,
PRIMARY KEY (id)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.manufacturers_storehouses
OWNER to postgres;
COMMENT ON TABLE public.manufacturers_storehouses
IS 'Связь компании производителя и склада';
CREATE TABLE public.manufacturers
(
id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ),
name character varying NOT NULL,
phone character varying,
adress character varying,
city character varying NOT NULL,
country character varying NOT NULL,
PRIMARY KEY (id)
);
ALTER TABLE IF EXISTS public.manufacturers
OWNER to postgres;
COMMENT ON TABLE public.manufacturers
IS 'Компании производители';
CREATE TABLE public.storehouses
(
id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ),
name character varying NOT NULL,
adress character varying,
city character varying NOT NULL,
country character varying NOT NULL,
PRIMARY KEY (id)
);
ALTER TABLE IF EXISTS public.storehouses
OWNER to postgres;
COMMENT ON TABLE public.storehouses
IS 'Склады';✅ Таблицы созданы!
ШАГ 3. Добавляем записи в БД
Наполняем таблицы данными с помощью SQL скрипта. Используем оператор INSERT INTO ... VALUES
В pgAdmin заходим в таблицу sweets_types и создаем скрипт Insert: Схемы -> public -> Таблицы -> sweets_types (правая кнопка мыши) -> Scripts -> Insert.
Аналогично наполняем данными другие таблицами.
Посмотреть картинки как это сделать в pgAdmin
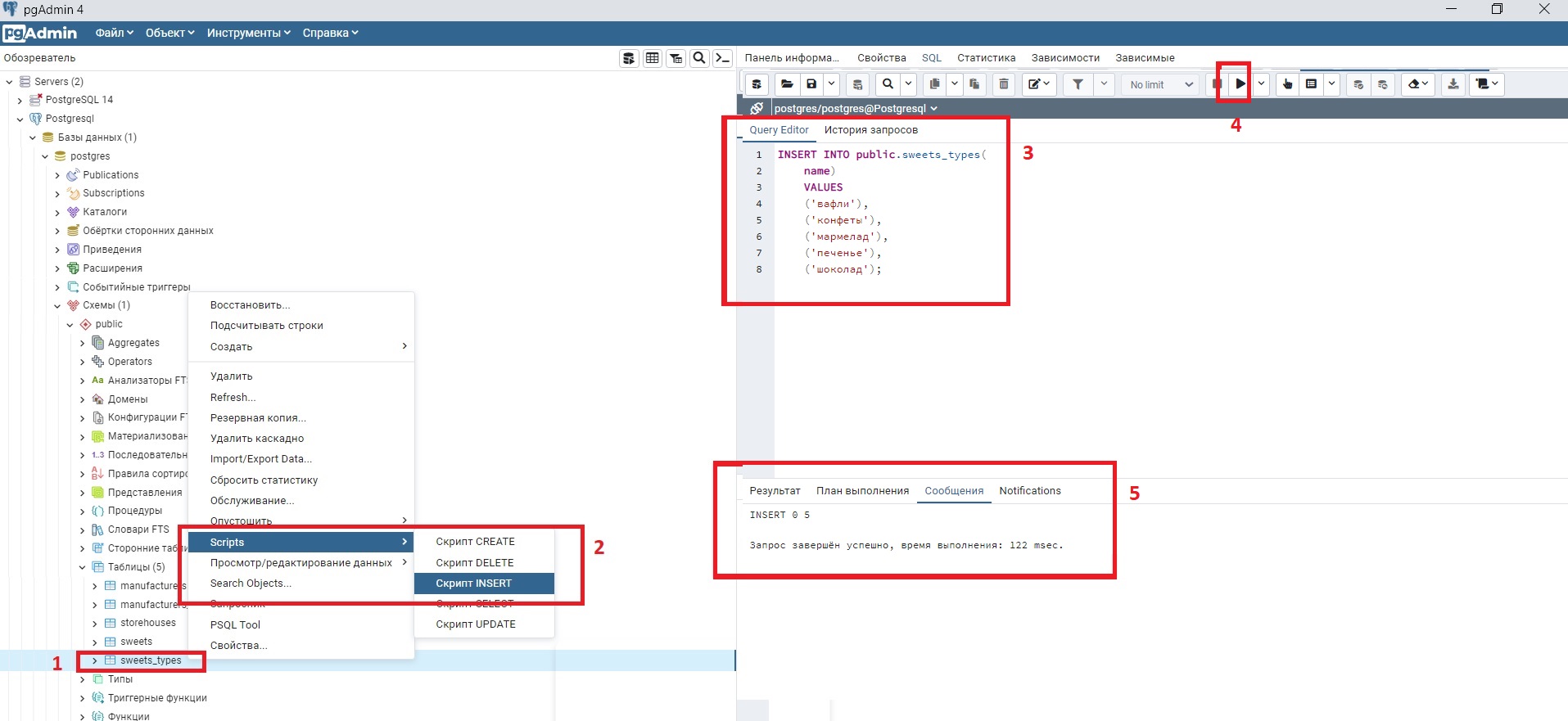
Скрипт SQL на наполнение данными таблиц
INSERT INTO public.sweets_types(
name)
VALUES
('вафли'),
('конфеты'),
('мармелад'),
('печенье'),
('шоколад');
INSERT INTO public.storehouses(
name, adress, city, country)
VALUES
('MSK-1', '109235, г. Москва, Проектируемый проезд 4386, д.8', 'Moscow', 'Russia'),
('SPB-1', '197375, г. Санкт-Петербург, Суздальское шоссе, д. 26', 'Saint-petersburg', 'Russia'),
('EKB-1', '620137, г. Екатеринбург, Шефская улица, д. 1А', 'Ekaterinburg', 'Russia'),
('EKB-2', '620137, г. Екатеринбург, Шефская улица, д. 2А', 'Ekaterinburg', 'Russia');
INSERT INTO public.manufacturers(
name, phone, adress, city, country)
VALUES
('Мишаня', '', '109235, г. Москва, Проектируемый проезд, д.15', 'Moscow', 'Russia'),
('Собакен', '78125748899', '197375, г. Санкт-Петербург, Суздальское шоссе, д. 75', 'Saint-petersburg', 'Russia'),
('Мартыха', '74657896525', '620137, г. Екатеринбург, Шефская улица, д. 5А', 'Ekaterinburg', 'Russia'),
('Мишаня', '', '109235, г. Казань, Проектируемая улица, д.15', 'Kazan', 'Russia');
INSERT INTO public.manufacturers_storehouses(
storehouses_id, manufacturers_id)
VALUES
(1, 1),
(2, 2),
(3, 3),
(1, 2),
(2, 1);
INSERT INTO public.sweets(
sweets_types_id, name, cost, weight, manufacturer_id, with_sugar, requires_freezing, production_date, expiration_date)
VALUES
(1, 'Мильтик', '100', '200',1, false, false, '2022-05-03', '2022-05-15'),
(2, 'Микус', '150', '300', 1 , true, true, '2022-04-03', '2022-05-03'),
(3, 'Миви', '110', '100', 1 , true, false, '2022-03-03', '2022-04-14'),
(4, 'Ми', '120', '200', 1, false, true, '2022-03-04', '2022-04-04'),
(5, 'Миса', '145', '570', 1, true, false, '2021-03-03', '2021-12-03'),
(1, 'Сольтик', '115', '200', 2 , false, false, '2022-05-03', '2022-05-15'),
(2, 'Сокус', '155', '300', 2 , true, true, '2022-03-03', '2022-05-03'),
(3, 'Сови', '117', '500', 2 , true, false, '2022-03-03', '2022-04-14'),
(4, 'Со', '129', '250', 2, false, true, '2022-03-04', '2022-04-04'),
(5, 'Сор', '148', '500', 2, true, false, '2021-02-03', '2021-12-03'),
(1, 'Мальтик', '210', '200', 3 , false, false, '2022-05-03', '2022-05-15'),
(2, 'Макус', '350', '300', 3 , true, true, '2022-01-03', '2022-05-03');
✅ Таблицы наполнены!
ШАГ 4. Отрабатываем поиск данных
Предлагаю вам сначала самим написать SQL запросы, а потом смотреть решение. Так вы научитесь искать данные на практических задачах и закрепите теоретические знания

№1. Какие компании производители есть в базе?
Решение №1
SELECT * FROM manufacturers;Выгрузите все столбцы из таблицы manufacturers
№2. Найдите все виды сладостей.
Примечание: виды сладостей в таблице не повторяются
Решение №2
SELECT name FROM public.sweets_types;№3. В каких городах есть склады?
Решение №3
SELECT DISTINCT city FROM storehouses;№4. Найти сладости с истекшим срок годности.
Подсказка: используйте для условия переменную current_date.
Решение №4
SELECT name FROM public.sweets WHERE expiration_date<current_date;№5. Найти сладости, у которых стоимость от 200 до 300
Решение №5.
SELECT * FROM public.sweets WHERE cost>='200' AND cost<'300';
--или
SELECT * FROM public.sweets WHERE cost BETWEEN '200' AND '300';Так как в условии задачи не сказано нужно ли включать в выборку стоимость равную 200 и равную 300, то запрос SELECT * FROM public.sweets WHERE cost BETWEEN '200' AND '300'; даст включая стоимость 200 и 300, а запрос SELECT * FROM public.sweets WHERE cost>='200' AND cost<'300'; не включит стоимость 300.
№6. Найти сладости, у которых название начинается на букву М
Решение №6
SELECT * FROM public.sweets WHERE name LIKE 'М%';№7. Составить список сладостей, отсортированных от А до Я
Решение №7
SELECT * FROM public.sweets ORDER BY name№8. Найти количество сладостей по каждому виду. В ответе вывести имя вида и количество
Решение №8
SELECT COUNT (s.id), st.name FROM public.sweets s
JOIN public.sweets_types st ON s.sweets_types_id = st.id
GROUP BY st.name;№9. Найти виды сладостей, у которых количество больше 2.
Решение №9
SELECT st.name FROM public.sweets s
JOIN public.sweets_types st ON s.sweets_types_id = st.id
GROUP BY st.name
HAVING COUNT (s.id) > 2;№10. Найти производителей, которые есть в более одном городе
Решение №10
SELECT name FROM public.manufacturers
GROUP BY name
HAVING COUNT (city) > 1;№11. В каких городах есть склады со сладостями Мильтик?
Решение №11
SELECT DISTINCT s.city FROM public.storehouses s
JOIN public.manufacturers_storehouses ms ON s.id = ms.storehouses_id
JOIN public.sweets sw ON sw.manufacturer_id = ms.manufacturers_id
WHERE sw.name = 'Мильтик';№12. Какое максимальное значение идентификатора у сладости?
Решение №12
SELECT MAX(id) FROM public.sweets;№13. Какое количество сладостей на каждом складе?
Решение №13
SELECT s.name, COUNT (sw.id) FROM public.storehouses s
LEFT JOIN public.manufacturers_storehouses ms ON s.id = ms.storehouses_id
LEFT JOIN public.sweets sw ON sw.manufacturer_id = ms.manufacturers_id
GROUP BY s.name;Используем LEFT JOIN, чтобы склады с нулевым количеством сладостей попали в выборку
✅ Обучился несложным запросам SQL!
Конечно за ночь весь SQL не изучить, но разобраться с необходимым минимум для несложных задач или собеседования вполне реально. Главное - желание учиться!
А какие каверзные задачки по SQL задавали вам на собеседовании или встречались в вашей работе?

Комментарии (33)

mentin
07.05.2022 05:29+4Можно придраться к решению #5, там два решения дают немного разный ответ, первый требует строго меньше 300, а between включает обе границы.
В решении #13 совсем пустые склады не попадут в результат, а надо бы их выдать с нулём сладостей. Используйте outer join и например coalesce.

jshapen
07.05.2022 08:39Скрипт наполнение данными таблиц валится с ошибкой индекса
Как в скрипте создания таблиц задать инкремент?
anna_ovzyak Автор
07.05.2022 09:15Скрипт наполнение данными таблиц валится с ошибкой индекса
Покажите скрин как запускаете и ошибку, перепроверила скрипт у себя на БД, отработал
Как в скрипте создания таблиц задать инкремент?
CREATE TABLE public.sweets_types ( id integer NOT NULL GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 ), name character varying NOT NULL, PRIMARY KEY (id) );Конструкция
GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 )позволяет задать генерацию значения поля id от 1 с увеличением +1. Добавила пояснение в статьюjshapen
07.05.2022 09:35Вот теперь все правильно.
Без этой строки «GENERATED ALWAYS AS IDENTITY ( INCREMENT 1 START 1 )»
скрипт наполнения не будет работать.

Farziev
09.05.2022 23:26если речь про Postgres то можно так же дополнительно использовать механизм sequence. Важно помнить если их "дёргать" вручную то они работают вне транзакции, поэтому откат транзакции "дыры" в нумерации не уберёт.

FanatPHP
07.05.2022 11:02+10Не хочется выглядеть ворчуном, но структура статьи напоминает содержимое дамской сумочки. Смешались в кучу кони, люди, терминология, архитектура, диалекты SQL, ненужные программы. Структуру таблицы почему-то изучаем после изучения структуры БД, а не наоборот. Аббревиатуры все перепутаны, и снабжены ремаркой "но мы это изучать не будем". AND и OR почему-то в одной куче с BETWEEN, а COUNT — наоборот отдельно от других агрегирующих функций. FK — вторичный ключ, видимо сокращение от "fecondary".
Зачем-то скачивать и устанавливать на компьютер какие-то программы, если в интернете полно онлайн инструментов для работы с БД. Достаточно было дать одну ссылку и сократить статью в два раза, избежав кучи совершенно ненужных шагов.
Но главное — засунуть SQL в DML — это надо было умудриться. То есть собственно тема, заявленная в заголовке статьи — изучение SQL — раскрыта в спойлере, который ещё и некорректно назван.
Если уж заявляемся на SQL, то вся эта премудрость с DISTINCT, WHERE и GROUP BY должна быть не свалена в кучу под спойлером "DML", а составлять основное содержание статьи и снабжена осмысленными комментариями и примерами. А не
SELECT AVG(id) FROM public.sweets;и "ну про джойны можно прочитать по ссылке".В то время как DML запросы как раз можно было бы убрать под спойлер.
anna_ovzyak Автор
07.05.2022 13:09+1Спасибо за ваше мнение.
Выбран вариант скачать и поставить программу, потому что:
1) есть возможность практиковаться без интернета. (есть населённые пункты, где интернет слабый),
2) на работе системному аналитику придётся работать именно с pgadmin, если БД postgre, поэтому удобно если ты уже видел интерфейс
Статья появилась, потому что похожей статьи с примерами я не находила для повторения sql к собеседованию. В тех, что встречала всё пишут шаблонными table_name, colum_name.
FK - foreign key, внешний ключ. Иногда называют, как вторичный ключ.
Согласна с вами, пересмотрю структуру DML спойлер и уберу оттуда агрегатные функции агрегатные функции. Не удачное название спойлера получилось.
FanatPHP
07.05.2022 14:11+6На постгресе и pgadmin базы данных и средства работы с ними не заканчиваются. Что делает эту часть статьи слишком узкопециализированной. Становится непонятно, статья про SQL или про работу с pgadmin. Эта информация явно является второстепенной, и как раз её и можно было заутсорсить, просто дав ссылку. В отличие от джойнов, которые напрямую относятся к теме статьи, и являются краеугольным камнем SQL. От системного аналитика почему-то ожидаешь системности мышления, а не вот это вот "может не быть интернета, поэтому для начала работы скачайте два дистрибутива на пол-гигабайта".
Называть внешний ключ вторичным неграмотно. Внешний ключ — constraint, ссылка на внешнюю таблицу. Вторичный ключ — это дополнительный индекс на той же таблице, он вообще не является constraint.
Про DML я и сам ошибся, выборки тоже могут в него включаться. Но в любом случае стоит разделить запросы на выборку и на модификацию данных. Особенно учитывая, что задания даются исключительно на выборку. И не бежать с ними галопом по европам, а сделать основным контентом статьи, группируя по основным операторам. То есть LIKE должен быть в разделе, посвящённом WHERE, а ORDER BY не должен вклиниваться между группировкой и агрегатными функциями. Ну просто я именно так себе представляю структуру статьи, которая озаглавлена "Шпаргалка по SQL". А сейчас из неё вообще неясно, как все эти операторы относятся друг к другу и в каких сочетаниях могут применяться. Сейчас это просто набор слов.
В статье даже не упоминается базовая схема SELECT запроса: SELECT что FROM откуда JOIN с другой таблицей WHERE условия GROUP BY поля HAVING условия ORDER BY сортировка LIMIT сколько OFFSET откуда. То есть нет системы, по которой строится вся дальнейшая аналитика.
anna_ovzyak Автор
07.05.2022 16:15+3Спасибо за замечание, дополнила статью структурой запроса поиска и разделила DML операторы
SELECT, INSERT, DELETE, UPDATEи остальные

playermet
07.05.2022 15:48+2на работе системному аналитику придётся работать именно с pgadmin, если БД postgre
Имхо, в целях самообучения SQL намного удобней какой-нибудь GUI над SQLite (например DB Browser for SQLite), чем монструозный по размеру и возможностям Postgres.
FanatPHP
07.05.2022 11:59+4Решения заданий #9 и #10 — это один сплошной фейспалм. Мало того что HAVING тут высосан из пальца, и вообще не нужен для решения этих задач (я уверен, что любой, решивший их самостоятельно, напишет нормальный запрос с WHERE), но — главное — эти запросы выдают правильный ответ чисто случайно.

sshikov
07.05.2022 12:39+1Чистая правда. Более того, условие в HAVING накладывается на группу, поэтому содержит как правило агрегирующие функции (т.е. упрощенно, отобрать такие группы, где число строк в группе такое-то). А тут условия на строку — т.е. просто напрашивается вывод: автор не знает, что такое HAVING? Да и в условии ничего нет про группы — т.е. применение тут не по делу вообще.
anna_ovzyak Автор
07.05.2022 13:29-1В #9 задаче идёт отработка having, в #10 отработка like, где есть группировка
Какие вы задачи для текущией БД можете предложить, которые будут не высосаны из пальца на ваш взгляд?
Для #9 думаю можно Найти склады, в которых количесво сладостей больше 8, но тогда оно немного будет пересекаться с #13. Сначала сгруппируем данные и найдём количество сладостей на каждом складе, затем выберем по условию больше 8.
Решение задачи - сам запрос может быть разным, главное же получить правильную выборку в результате. Having же используется, чтобы выбрать из сгруппированных данных по некому условию.
Для #10 можно также поискать количество сладостей в складах, в городах на букву M.
FanatPHP
07.05.2022 14:18+1Если я непонятно написал выше, ваш запрос с having не выдает правильную выборку. Она получается правильной только из-за специально подогнанных данных. Ну сделайте нормальный тестовый набор данных, чтобы у товаров одного типа не был одинаковый срок годности. И посмотрите на результаты своих запросов глазами. Если уж не понимаете чисто в теории, что делает с запросом ваше GROUP BY st.name, s.expiration_date
anna_ovzyak Автор
07.05.2022 16:06+2Поправила задания №9 и №10, а также немного изменила тестовые данные в INSERT, поняла свою ошибку.
FanatPHP
07.05.2022 15:34По поводу запросов, я не вижу тут двух кейсов для having. Ну то есть like никак не связан с having, его наличие ничего не меняет. Ну просто условие во where.
Да, можно больше 8. Но я бы добавил реализма, и добавил одну строчку с дублем, одни и те же конфеты на складе два раза. И найти запросом этот дубликат

TimeCoder
07.05.2022 15:20-2Я тоже всю жизнь думал что having - это спутник группировки. Но, оказывается, не совсем. Это по сути where, работающий с алиасами. И лишь частный случай этого - использование при группировке.

Akina
07.05.2022 17:57+3Все с точностью до наоборот. Это использование HAVING без GROUP BY - расширение, существующее лишь в некоторых СУБД и в т.ч. допускающее использование алиасов выходного набора вместо соответствующих выражений в условиях отбора.
playermet
07.05.2022 18:01+1Вы что-то путаете. Цитирую стандарт SQL:1999:
7.10 <Having clause>FunctionSpecify a grouped table derived by the elimination of groups that do not satisfy a <search condition>.Format<having clause> ::= HAVING <search condition>General Rules1) The <search condition> is applied to each group of R. The result of the <having clause> is a grouped table of those groups of R for which the result of the <search condition> is true.
Akina
07.05.2022 17:47+3МнеЧастьВ таблице есть: Столбцы, Строки, Ячейки, Ограничения (constraint): PK (primary key) - первичный ключ, FK (foreign key) - внешний ключ, Тип данных.
Знаете, если бы мне кандидат на собеседовании выдал вот это, то на этом собеседование и закончилось бы.
В таблице есть поля и есть записи. Столбцы и строки - это в Экселе.
Ячеек нет - вообще. Если держаться за аналогию с Экселем, то аналогом ячейки Экселя является определённое поле определённой записи.
Тип данных - это атрибут поля. Один из атрибутов.
А констрейнт - это вообще не объект. Это правило. Правило, которое использует подсистема контроля целостности и непротиворечивости данных.
Да, кстати... Вы ещё забыли о таких жёстко связанных именно с таблицами объектах, как индексы (в случае упомянутых PK/FK - используемые как поддержка процесса контроля данных соответствующими констрейнтами-правилами с целью повышения эффективности/скорости контроля). И триггеры, бо́льшая часть которых (а в некоторых СУБД - все) также связана с таблицами.
Далее. Очень хочется узнать, с каких это пор в DDL затесался TRUNCATE. Это однозначный DML, почти алиас DELETE FROM table, который просто оптимизирован на безусловное удаление всех данных (например, вместо удаления записей может быть удалена и пересоздание сама таблица).
Дальше. "COUNT. Количество строк." А дальше - дурь, которая также будет достаточным основанием отправить кандидата учить матчасть. Количество записей - это COUNT(*), а написанный ниже COUNT(id) - это количество не-NULL значений указанного поля. И хоть в данном конкретном случае результат будет таким же, это никак не извиняет.
anna_ovzyak Автор
07.05.2022 18:13Вопрос терминологии, главное чтобы человек понимал суть. На аналогии с обычной таблицей excel, людям проще понять эту тему (проверяли на практики - обучении) . Идея статьи овладеть SQL быстро для поиска данных, предварительно создав не сложную БД с этими данными без лишних усложнений.
Да, индексы, тригерры конечно есть, но для поиска данных в работе или на собеседовании их спрашивают редко. Это уже более продвинутый уровень, я бы так сказала. А если спрашивают, то в формате: Какие объекты есть в БД.
Вопрос индексов и триггеров поднимается в процессе проектирования БД и обсуждается на уровне аналитик - разработчик/архитеетор., но всё зависит от компании, где работаешь.
Если Вы аналитик Вам часто приходилось писать индексы, триггеры?
sshikov
07.05.2022 21:42Аналитику все же редко нужны и индексы, и триггеры. Это физический уровень, а тут как правило достаточно логического, и про ключи и целостность аналитик знать обязан. А как они реализованы — это уже желательно.
>И хоть в данном конкретном случае результат будет таким же, это никак не извиняет.
Ну кстати, таким же в смысле данных. Но не факт, что таким же по быстродействию. Во всяком случае, есть такие SQL-движки, с хранением по колонкам, скажем в parquet, где запросив одну колонку вы и получите только ее, а остальные данные не будут физически прочитаны с диска. И в нашем случае аналитик такое должен бы понимать тоже.FanatPHP
08.05.2022 08:45+1Вот когда у аналитика запрос начнет выполняться по два часа, то тут-то он и пожалеет, что оставил индексы на потом :)
И в этом контексте для быстродействия никакая колоночная БД не нужна. Достаточно как раз только индекса. И колонка мало того что будет читаться одна, так ещё и не с диска, а из оперативной памяти. А добавить индекс все-же немножечко попроще, чем мигрировать всю инфраструктуру на новую БД. Так что со всех сторон как не крути, про индексы знать надо.sshikov
08.05.2022 09:03Ну, знать что индексировано, и самому их строить — все же сильно разные вещи. И потом, в моей реальности аналитику все равно не дадут их создать. Так что он пойдет к DBA и спросит про индексы. А тот ему ответит.
>никакая колоночная БД не нужна.
А память у вас резиновая что-ли? Я в общем тут клоню к тому, что производительность — это отдельная непростая тема, и ей должны заниматься люди, которые немного другую квалификацию имеют. И знают общее положение дел — а не только про один конкретный запрос. И зовут их обычно не аналитиками, и инструменты у них обычно слегка другие.
Akina
07.05.2022 18:20+1Далее. "LIKE. Поиск заданного значения в столбце по совпадению." Бред. Этот оператор выполняет проверку на соответствие шаблону. А совпадение, оно же равенство, проверяется другими операторами. Оператор равенства '=', проверка на NULL 'IS [NOT] NULL', в некоторых СУБД есть и другие операторы.
anna_ovzyak Автор
07.05.2022 18:41Здесь не согласна, в like ищем по совпадению с заданным выражение.
Проверка на is null - спасибо, добавлю. Забыла про него, а он используется

vzhicharra
08.05.2022 23:02для начинающих - отличное пособие
разве что сомнительный момент с переключением интерфейса на русский
nitrat665
Из не то чтобы сильно каверзных, но постоянно встречающихся в интервью на SQL вещей стоит помнить over (PARTITION BY ORDER BY). По сути дела, всё практически так же просто, как с груп бай, но спрашивают практически всегда, и типа ответишь - считаешься крутым чуваком почему-то. Также каждый второй раз спрашивают разницу между ROW_NUMBER, RANK и DENSE_RANK.
IvanPetrof
Кмк потому что это косвенно говорит об опыте. Можно за 10 лет работы ни разу не столкнуться с оконными функциями и «прекрасно» обходиться без них (да, что-то костыля подзапросами и пр. ). На небольших объёмах это даже не будет сильно тормозить.
Поэтому, если разработчик может ответить на эти каверзные вопросы, значит ему приходилось решать какие-то нетривиальные задачи. Причём довольно часто (т.к. логика оконных функций всё-таки иногда своеобразная и если периодически мозг ими не тренировать, то навскидку (без базы под руками) будет трудно вспомнить некоторые особенности)