

Привет, я QA Lead в команде бэкенда по разработке биржевого ядра. Так как уже долгое время занимаюсь развитием высоконагруженной платформы в Scalable Solutions, решил написать о том, как нам удалось поставить QA-процесс с 20 000 тест-кейсов, создать гибкую инфраструктуру для автоматизированного тестирования в нескольких типах API, включая асинхронные бинарные протоколы, и пройти путь разработки от отладочных утилит до специализированных тестовых фреймворков для интеграционного и компонентного тестирования.
О биржевом ядре
Это ядро криптовалютной биржи (бэкенд), которое является ключевым компонентом платформы Scalable Exchange. Отмечу, что мы не криптобиржа, а разработчик трейдинговой инфраструктуры для создания криптобирж. Наше биржевое ядро построено на микросервисной архитектуре и состоит из 30-ти с лишним компонентов, которые смасштабированы более чем на 100 серверах в нескольких дата-центрах мира. На сегодняшний день у нас зарегистрировано более 5 млн пользователей. Средняя частота размещения заявок составляет 100т./сек.
Платформа позволяет работать с более чем шестью сотнями цифровых активов и тремя тысячами торговых пар на 120 блокчейнах. И это все работает для торговли спотового, маржинального и фьючерсного типа.

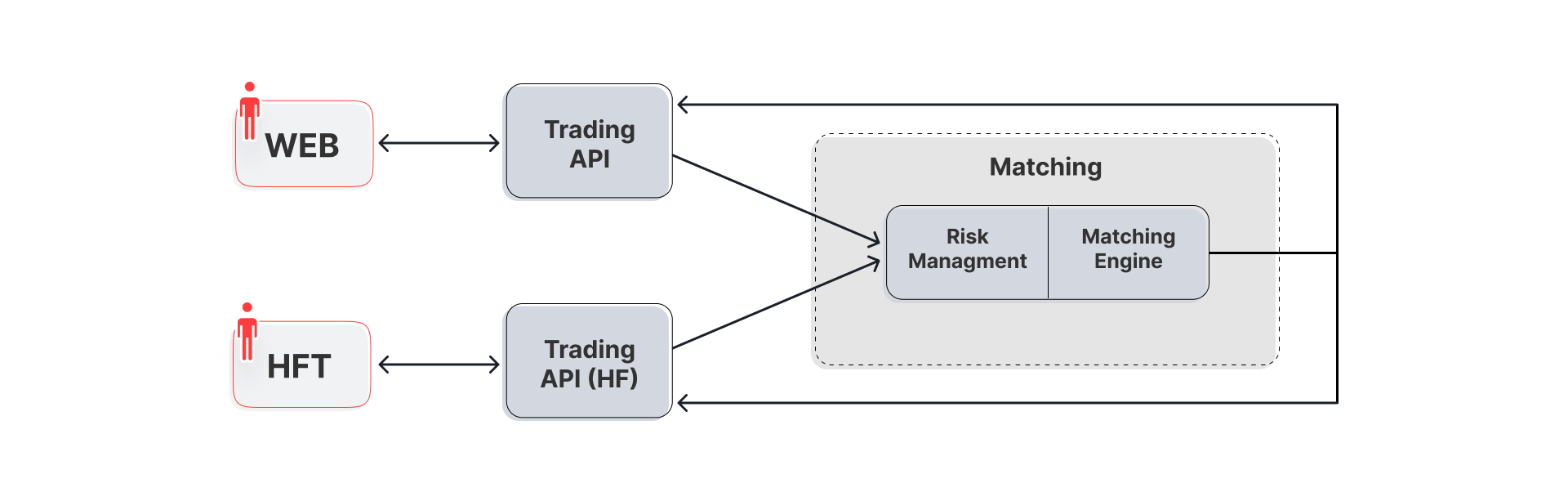
Концептуальная схема ядра
Биржевое ядро можно разделить на несколько блоков:
Торговые гейты, через которые пользователь может разместить заявку на покупку или продажу цифрового актива и получать актуальную информацию о рынке из БД.
Сервисные гейты, которые необходимы для настройки системы, ввода/вывода средств и выполнения других служебных операций.
Матчинг, который является группой компонентов для выполнения дополнительных проверок и сведение заявок (ордеров).
Казалось бы, объект тестирования прозрачен и понятен – есть точки входа для пользователя и администратора. Генерим тестовые данные в виде заявок на вход торговых гейтов, собираем ответы, сверяем с ожидаемым результатом. Классическая схема тестирования.
Однако заглядывая глубже в архитектуру системы выясняется, что торговать можно и нужно на различных типах гейтов, а данные о происходящем на рынке собирать различными способами.
Специфика бизнес-логики
Основная бизнес-логика разбита на 2 части:
Риск-менеджмент. Он обеспечивает оценку рисков при размещении заявки и изменении рынка.
Т.е. если вы пытаетесь купить или продать цифровой актив за сколько-нибудь долларов, то система должна проверить, хватает ли у вас средств на эту операцию с учетом всех действующих на данный момент комиссий, скидок, ограничений, прав и тп.
Если речь идет о более сложных финансовых производных, таких как фьючерсы или опционы, то система должна оценить стоит ли вообще принимать вашу заявку при текущем состоянии рынка. Проверить: какие риски несете вы, какие риски несет биржа. Если рынок качнулся, необходимо оценить, какие пользователи попали в группу риска и что с ними теперь делать: выставить нотификацию или выполнить принудительную отмену всех их заявок, ликвидировать позиции и т.д.
Matching engine, сердце криптовалютной биржи и любых других торговых систем. Непосредственно в нем выполняется регистрация и сведение заявок между собой. Это точка, в которой интересы покупателей и интересы продавцов находят друг друга, и в результате согласования заявок происходят сделки. Также матчинг содержит книгу заявок (order book), он же биржевой стакан. Это набор заявок, которые еще не совпали между собой.
Тестирование бизнес логики системы представляет собой довольно сложную задачу. Как правило, она сводится к задаче условного моделирования, где необходимо применить мат.модели и подготовить данные для тестирования, провести требуемую тестовую логику, собрать результаты с целевых компонентов, подтвердить корректность и консистентность работы всей системы в целом. Дополнительным усложнением при тестировании являются race conditions, провоцируемые как горизонтальным масштабированием системы, так и наличием проактивных компонентов.
Также к бизнес-логике биржевой системы предъявляется ряд нефункциональных требований по:
производительности,
консистентности,
прямой и обратной совместимости.
Детализация ядра
На сегодняшний день практически любая торговая система поддерживает разнообразные способы подключения для отправки запросов и сбора данных. Наша система не стала исключением.
Для постановок заявок используются три вида торговых гейтов:
ZMQ и gRPC API – они используются для взаимодействия со смежными проектами, такими как WEB и Public API сервисы.
FIX API – это специализированный торговый протокол. Он является международным стандартом для обмена данными между участниками биржевых торгов в режиме реального времени. Протокол требует соблюдение строгой спецификации и сессионной логики, отклонение от которых приводит к дисконекту клиента без объяснения причин. Пользователями FIX гейтов являются торговые роботы, которые, как правило, используют стоечные решения для получения минимального времени отклика от системы.
Маркетдатные гейты, отвечающие за публикацию рыночных данных, представлены еще большим разнообразием с аналогичной историей. Каждый маркетдатный гейт имеет свою структуру, свой протокол, свою специфику. Строгость требования между ZMQ и FIX гейтами схожа (как у торговых), а вот формат ответов будет различаться. Они делятся на два типа: L3 – где пользователю обезличенно отправляются все события по каждой заявке на рынке, и L2 – где данные отправляются с агрегацией по цене за определенный период.
Маркетдатные гейты также имеют свою специфику по транспорту. Например, помимо гейтов использующих протоколы ТСР, есть гейты раздающие маркет дату через UDP multicast.

Виды пользователей
Отдельно стоит рассказать про типы торговых пользователей в системе, так как разные пользователи дают разную нагрузку.
Публичные клиенты. Это пользователи, которые торгуют через WEB-интерфейс, мобильные приложения и REST. Таких клиентов большинство, около 5 млн. При этом одновременно торгуют обычно несколько сотен тысяч. Данный тип клиентов дает небольшую нагрузку, до нескольких тысяч RPS.
Высокочастотные трейдеры. Это, как правило, индустриальные трейдинговые платформы, которые работают по определенной стратегии – арбитраж, маркет-мейкинг, краткосрочная торговля и др. Таких пользователей существенно меньше, около сотни, но при этом каждый такой робот может генерировать десятки тысяч RPS.
Гейты для первых, как правило, находятся в облаках и не имеют строгих требований к производительности. На сегодняшний день latency (время отклика) для данных гейтов составляет 50 миллисекунд.
Гейты для высокочастотных трейдеров находятся в стойке для обеспечения минимального времени отклика. Эта часть системы имеет требования к времени отклика до 500 микросекунд. А также дополнительные требования к производительности каждого отдельного компонента, стоящего на нагруженном пайплайне.

Выбор инструментов для тестирования
Итак, количество точек входа/выхода значительно увеличилось, и появились специализированные требования к системе. Очевидно, что каждый компонент имеет свою строгую спецификацию и особенности работы.
В итоге задача, например, по проверке размещения новой заявки через торговый гейт увеличилась втрое. Так как эту заявку нужно разместить тремя способами через разные гейты. И это еще пока без какой-либо вариативности внутренних параметров самой заявки.
Как видно, система не очень дружелюбная для ручных тестов. Поэтому приоритетной целью стало закрыть весь текущий функционал автоматизированными тестами.
Три года назад в качестве инструментов QA отдела были только отладочные утилиты написанные на Python, через которые разработчики подключались к ядру для выполнения минимальных точечных ручных проверок. Поэтому в первую очередь, необходимо было определить технологический стек, на котором будет строиться тестовый проект.
Критерии были следующими:
Простота использования инструмента при разработке автотестов;
Популярность инструмента (в целях исключения дефицита будущих сотрудников);
Простота интеграции с ядром во избежание дополнительных обвязок, прокладок, хитрых конверторов между ядром и средой разработки автотестов из-за специфики работы тестового инструментария.
В результате родился привычный “джентльменский набор” Python + PyTest.
Тестовый фреймворк как агрегатор
Следующим встал вопрос, каким образом тестам работать на различных финансовых протоколах и как собирать ответы.
Каждый компонент принимает запросы в своем формате, по своей спецификации и по своему протоколу, соответственно, отдает ответы так же. Плюс к этому, в некоторых протоколах применена скрытая служебная логика обмена сообщениями с клиентом.
Получается следующая картина: тестовая дата одна, а протоколы и форматы на вход в систему разные. Аналогичная история – с получением рыночных данных от Market Data гейтов.
Для обеспечения единого формата входных и выходных данных между тестом и тестируемой системой, в независимости от протоколов и прочих условий, требуется некий конвертер, который мог бы преобразовывать запросы в требуемый формат и отправлять их.
Для этого был разработан фреймворк-коннектор. В его задачи входит:
Обеспечивать подключение клиентов из тестов ко всем типам гейтов, включая синхронный и асинхронный режим.
Отправлять запросы на размещение заявки в гейты. Из теста в формате json передается запрос в фреймворк, а он уже сам через свои кодеки сериализует его в необходимый формат и по протоколу отправляет сформированный запрос в соответствующий торговый гейт.
Получать ответы от гейтов. Десериализация ответа от гейтов во внутренние тестовые объекты.
Вся тестовая логика в дальнейшем работает через такие внутренние объекты, что позволяет тестам гибко работать с данными вне зависимости от какого гейта они были получены. Таким образом, тест на уровне фикстуры подключается к фреймворку, отправляет запрос в привычном json-формате, в ответ получает репорт в виде объекта.
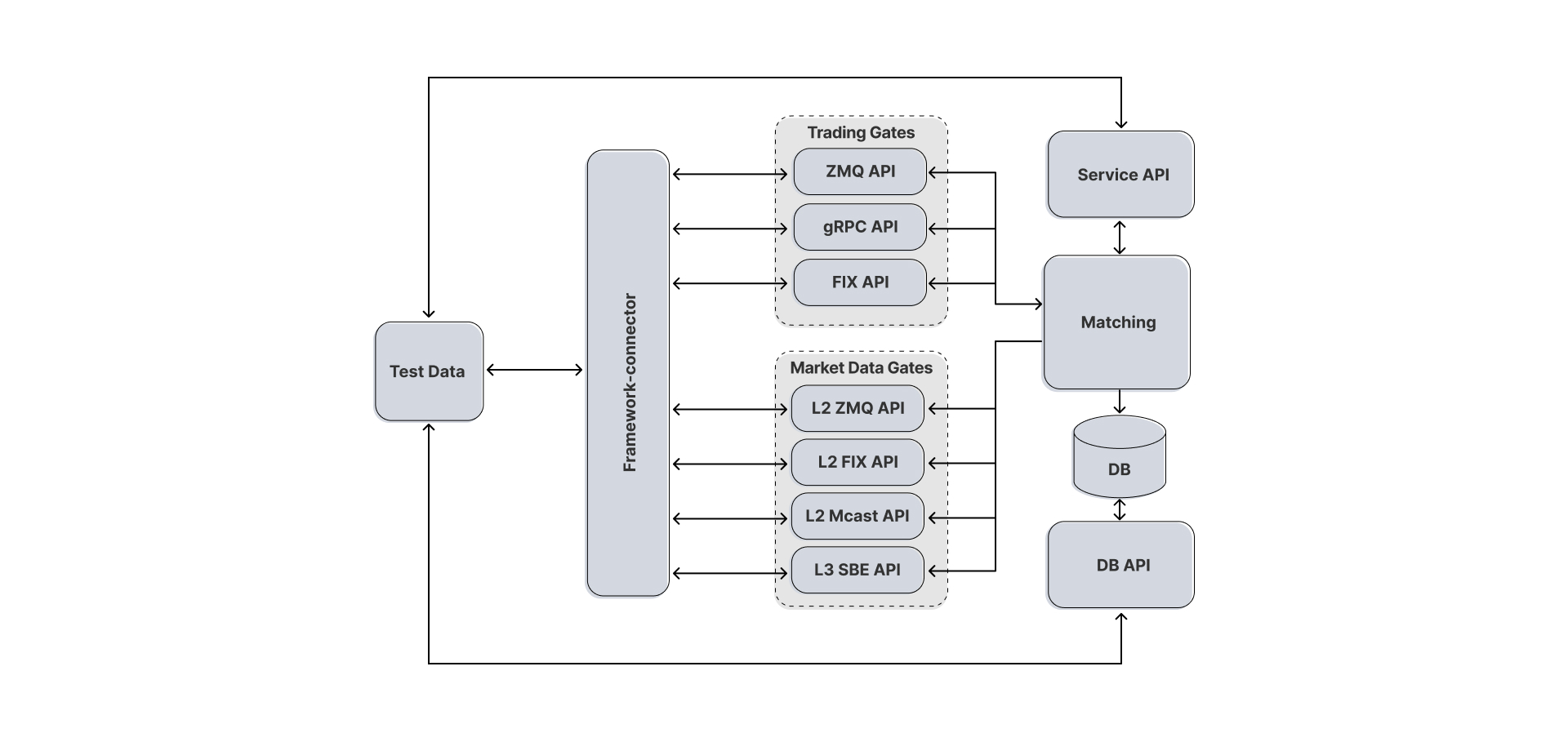
Данное решение позволило унифицировать тестовую дату на входе теста к одному виду. Под капотом спрятались низкоуровневые запросы к гейтам и обертки во внутренние типы для ответов.
Предварительная проработка фичей
Перед разработкой фичи и тест-кейсов, технические требования обязательно проходят проверку на адекват – полнота, достижимость, корректность. Если фича разработана, но тестами до нее не добраться или потребуется полгода писать тест, стоит задуматься нужна ли фича в таком виде в системе. Только после получения аппрува всеми командами начинается ее разработка. Расписываются тест-кейсы, определяется перечень необходимых вспомогательных функций, описываются мат. модели для расчета параметров, используемых в новой фиче, и т.п.
Пишется код ядра, разрабатываются автотесты, после мержа выполняется прогон тестов в GitLab/CI. После прохождения всех тестов появляется релиз-кандидат, который уходит на стендовое тестирование, где проверяется производительность, миграция системы в обе стороны и дополнительные необходимые тесты(если требуется). Далее билд передается команде DevOps, которые разворачивают систему на проде.
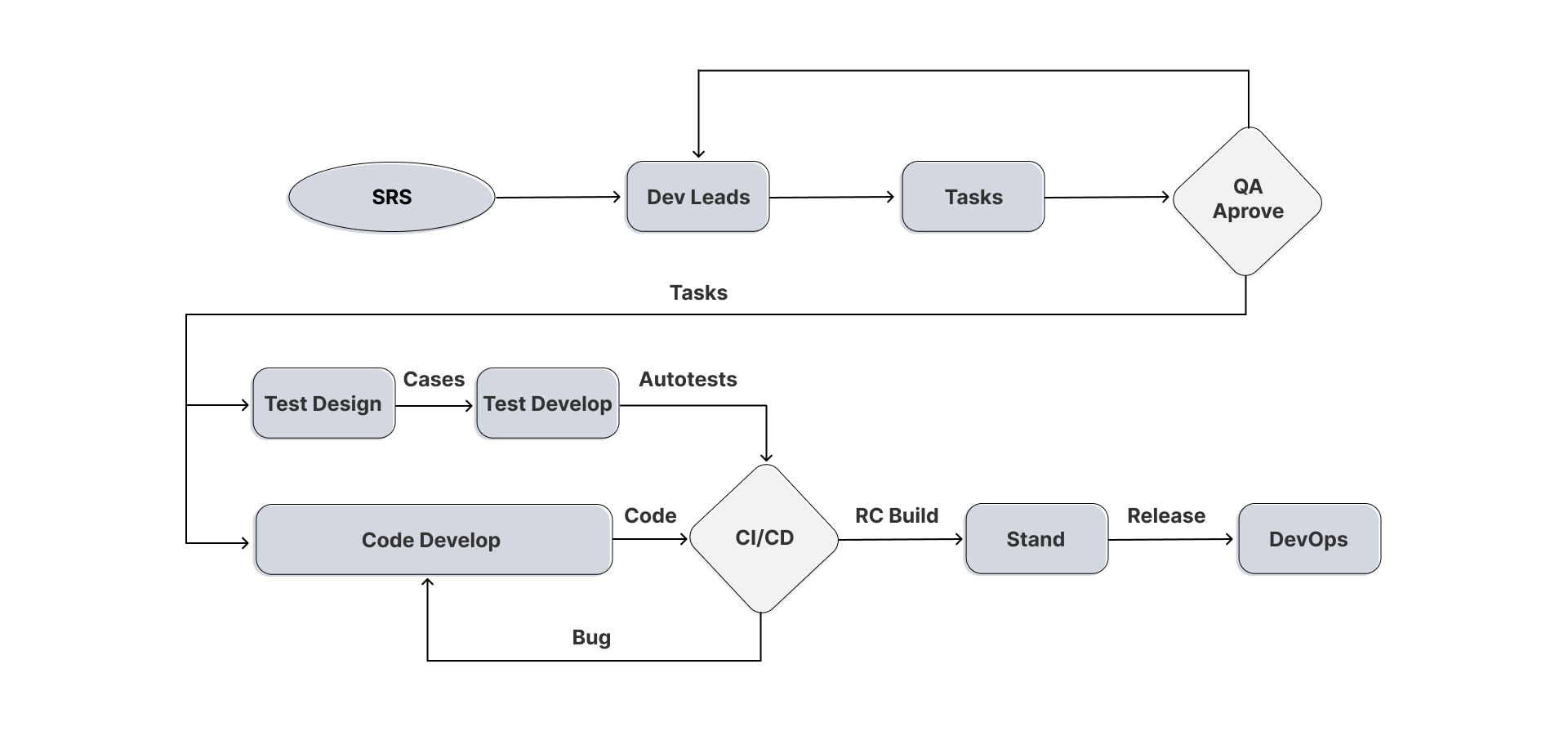
Отмечу важный этап в нашем процессе – прогон полного цикла тестов. Он автоматически выполняется перед любым мерджем в ветку Develop или Master. Успешное прохождение всех тестов обязательно как для разработчиков, так и для QA-инженеров. Выглядит это следующим образом: в GitLab/CI запускается отдельный пайплайн, на удаленных машинах под гипервизорами поднимаются 140 независимых тестовых окружений, тесты делятся на группы и запускаются параллельно.

Именно в этом узле (на схеме сверху) появляется элемент параллельности или самостоятельности разработки. К примеру, разработчик ядра выполняет плановый рефакторинг системы. Он пушит свои изменения, которые никак не должны повлиять на бизнес-логику. Но после прогона в CI завалились тесты, которые проверяли компоненты, где разработчик даже не работал.
Совместимость поломана, разработчик читает асерт, уходит на штрафной круг и добивается прохождения всех тестов. Причем уходит он самостоятельно, не привлекая дополнительные трудовые ресурсы коллектива.
Разработка тест-кейсов
Накопив довольно большой пул тестов, мы обратили внимание, что он поделился на два типа. Это функциональные и use-кейсы. Причем в зависимости от фичи, перевес количества тестов часто склонялся в сторону use-кейсов. Это связано с тем, что стандартные действия с системой уже покрыты тестами. Поэтому для новой фичи первоначальные действия уже проверены, и мы доверяем этим тестам. Остается проверить только новые изменения в системе, которые принесла фича. Например, в тесте на размещение нового типа заявки QA-инженеру достаточно построить из готовых “кубиков-функций” основную логику теста, и в нужном месте написать дополнительные проверки для новой фичи.
Рекавери и миграция
Важной составляющей стали тесты на проверку восстановления системы и миграционные тесты. Если система не обеспечивает целостность накопленных данных при перезапусках, зачем вообще нужна такая система?
Первые, рекавери тесты, обеспечивают проверку корректного восстановления системы после перезапуска компонентов.
Миграционные тесты используются для проверки совместимости компонентов различных версий между собой. Также проверяется прямая миграция системы, включая все стораджи и БД, и обратная миграция в случае отката системы. Для этого вида тестирования используется специальный миграционный стенд. При подготовке релиза достаточно указать, с какой версии и на какую необходимо выполнить миграцию, далее в автоматизированном режиме в отдельном окружении разворачивается система, с помощью заранее написанных тестовых функций генерируются все возможные сущности системы. Снимаются дампы со всех стораджей, выполняется обновление версий компонентов, далее снимаются дампы уже с новой версии и сравниваются со старой.
Таким образом обеспечивается полная совместимость версий при обновлении системы.

Компонентные тесты
Проверяется ли матчинг без влияния на него периферийных компонентов? Потребность в таких тестах действительно есть.
Что будет, если от имени торгового гейта кинуть запрос на размещение новой заявки с невалидными параметрами? Сейчас вся валидация такого рода проверяется на входе торгового гейта, и в матчинг поломанный запрос попасть никак не может. Однако безопасность работы матчинга должна быть проверена, так как это главный «орган» системы. Торговый гейт и матчинг общаются между собой по внутреннему протоколу. Внешним пользователям к данному компоненту подключиться невозможно.
Для проверки подобных кейсов разработаны компонентные тесты по классической схеме.
Тестируемый компонент, матчинг, изолируется от остальных. Мокируются связанные компоненты, которые участвуют в кейсе (в нашем случае это торговый гейт). И уже как бы от его имени отправляются запросы в матчинг. Подобные тесты, как правило, короткие и не требуют много времени на разработку. Однако подготовка инфраструктуры для них весьма затратна – иногда нужно писать большие куски системы, которые бы по-настоящему имитировали общение замокируемых компонентов с тестируемым компонентом.

Нагрузочные тесты
Нагрузочные тесты, наверное, всегда вызывают боль. Поэтому стоит относиться со скептицизмом с подобным установкам:
Ваша схема нагрузки корректна. Есть много факторов, влияющих на генератор нагрузки. На каком языке он написан, на каком железе, гипере он запущен и т.д. Далеко не факт, что алгоритм нагрузки, который был задан в тестах, обеспечит необходимые требования.
Ваши показатели нагрузки корректны. Полученные метрики после отработки генератора стоит перепроверять, а лучше всего – включать их проверки в автотесты.
Оценки разработчиков верны и не требуют перепроверки. Тут, думаю, не требуется комментария.
Для проверки производительности системы написана утилита на С++, которая позволяет давать заданную нагрузку по финансовым протоколам. В процессе нагрузки снимаются ТСР дампы, по которым идет обсчет latency каждого компонента. Таким образом, отслеживается не только производительность внутренней логики, но и работа с сокетами. При внесении нового функционала показатели не должны проседать.
Оценка покрытия системы тестами
Наверное, для любого проекта важна метрика оценки качества тестирования, представляющая из себя плотность покрытия тестами требований либо исполняемого кода. Наш проект не стал исключением.
Покрытие тестами функциональных и нефункциональных требований может оставить непроверенными некоторые участки кода, потому что не учитывает конечную реализацию.
В нашем проекте мы использовали инструмент LCov, который позволяет проанализировать, в какие строки кода системы были вхождения во время проведения тестирования. Результаты анализа позволили выявить дыры в покрытии, а также избавиться от дублирующих тестов.

Результаты
Результаты нашей работы за три года выглядят так – вот-вот перешагнем 20к тест-кейсов.

Понятно, что при таком огромном количестве тестов требуется внимательно следить за тестовой документацией. Чтобы не получилось ситуация, когда тесты пишутся ради тестов. При оформлении теста обязательно соблюдается трассировка: таска – тест-кейс – тест (Allure). В Allure есть возможность актуализировать тест-кейс из исходников теста, что значительно облегчает бюрократическую работу с тестовой документацией.
Благодаря автоматизации в CI + отчетности в Allure, разработчик системы или QA-инженер легко может встать в отчете на упавший тест, из теста выйти в тест-кейс, а из него перейти к прямым требованиям к системе. В такой схеме локализация бага выполняется очень быстро.
Безусловно, были и проблемы, с которыми мы неожиданно столкнулись во время работы.
Нехватка человеческого ресурса. Не так просто найти специалиста, который умеет и составлять тест-кейсы, и программировать. Для сокращения сроков найма QA должность была разделена на QA-инженера и питон-разработчика (SDET). QA-инженер проектирует и пишет автотесты, не отвлекаясь на низкоуровневую реализацию тех или иных методов, а SDET обеспечивает инфраструктурную поддержку тестового проекта для QA команды.
-
Каким образом обеспечить независимое для каждого QA-инженера тестовое окружение для разработки и отладки автотестов? Чтобы работа QA-инженера была максимально изолирована от внешних, выделенных стендов, система помещена в Docker. Каждый компонент системы помещен в свой докер-контейнер, которые, в свою очередь, объединены в виртуальную сеть.
Данное решение хорошо вписалось в микросервисную архитектуру тестируемой системы. Все зависимости и настройки для запуска приложения уже содержатся внутри докер-контейнера. QA-инженер локально поднимает под Докером полное тестовое окружение и может сосредоточиться на разработке тестов, а не решении инфраструктурных проблем. Если есть необходимость запустить тесты на реальной системе без какой-либо виртуализации, то для этого используется общий пре-продовый стенд. Средствами CI на удаленных тестовых машинах поднимается необходимая версия тестируемой системы и запускается полный цикл тестов.
Так система постоянно находится под постоянным автоматическом регрессом и этим обеспечивается высокое качество для сложного программного продукта.