

Думаю, вы знакомы с графиками сравнения точности архитектур. Их применяют в задачах по классификации изображений на ImageNet.
В каждом сравнении которые я мог встретить ранее в Интернете, как правило это было сравнение небольшого количества архитектур нейросетей, произведенными разными командами, и возможно в разных условиях.
Кроме того в последнее время я наблюдаю изменения: появилось большое количество архитектур. Однако их сравнений с ранее созданными архитектурами я не встречал, либо оно было не столь масштабным.
Мне захотелось столкнуть большое количество существующих архитектур для решения одной задачи, при этом объективно посмотреть как поведут себя новые архитектуры типа Трансформер, так и ранее созданные архитектуры.

Цель исследования
Сравнить большое количество существующих архитектур предобученных сетей, и их результаты для решения задачи классификации изображений.
Содержание
Моя задача
-
Анализ результатов
Группа сетей VGG
Группа сетей DenseNet
Группа сетей ResNet
Группа сетей ResNeXt
Группа сетей ReXNet/ResNeSt/Res2Net
Группа сетей RegNet
Группа сетей Inception/Xception
Группа сетей MNASNet/NASNet/PnasNet/SelecSLS/DLA/DPN
Группа сетей MobileNet/MixNet/HardCoRe-NAS
Группа сетей трансформеров BeiT/CaiT/DeiT/PiT/CoaT/LeViT/ConViT/Twins
Группа сетей ViT (Visual Transofrmer)
Группа сетей ConvNeXt
Группа сетей ResMLP/MLP-Mixer
Группа сетей NFNet-F
Группа сетей EfficientNet
Прочие предобученные модели сетей
Результаты рейтинга архитектур
Выводы проведенного исследования
Моя задача
В качестве задачи для такого масштабного сравнения, я полностью отказался от самостоятельного дообучения нейросетей, и использовал методику сравнения близости векторов признаковых представлений с выхода предобученных нейросетей.
При этом если косинусная близость векторов с изображений одного класса максимальная, то считалось, что эта архитектура наиболее подходит, для последующего дообучения под конкретную задачу.
В используемой задачи брались изображения с 8326 различных классов. При этом многие изображения разных классов могли быть достаточно похожи между собой.
В качестве входных данных брались цветные изображения 224х224 пикселя. Если вход у нейросети отличался от указанного разрешения, то изображением предварительно масштабировались до необходимого.
В качестве метрики качества использовалась доля правильных ответов (в процентах) в топ1 (acc), и доля правильных ответов в топ5 (acc5) наиболее близких векторов.
Все представленные предобученные архитектуры сетей брались из библиотеки timm.
Анализ результатов
Так как использовалось большое количество архитектур, то для сравнения результатов я решил разбить все архитектуры на группы.
1. Группа сетей VGG
Наверное, одна из старейших архитектур в данном рейтинге.

Лидером здесь стала сеть RepVGG-B1 — это одна из моделей классификации изображений RepVGG, предварительно обученная на наборе данных ImageNet. RepVGG – это улучшенная, более глубокая модель VG, выпущенная в 2021 году.
2. Группа сетей DenseNet
Достаточно известная архитектура, которая очень хорошо себя показывает в различных задачах, не оказалась и здесь без внимания.

В это группе первое место заняла архитектура с большим количеством параметров
3. Группа сетей ResNet
Самая большая группа, одной из популярнейших сетевых архитектур. Представлена в виде двух графиков.
подгруппа “30 лучших”.
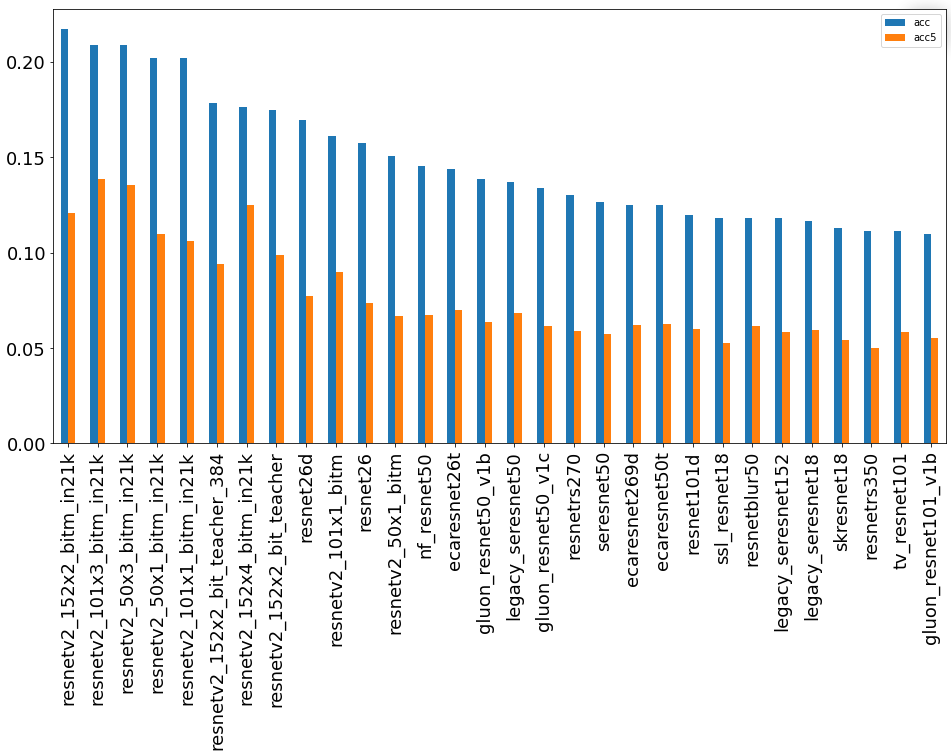
подгруппа остальных сетей.

В данной группе в лидеры выбрались архитектуры с большим количеством параметров и обученные на большем количестве классов. В лидерах архитектура ResNetV2 обученная на 21 тысяче классов и с использованием технологии Big Transfer. При этом посмотреть на распределение очков внутри группы тоже достаточно интересно. Например resnet18 показала себя очень достойно, что для меня оказалось сюрпризом, а resnet26d попала в топ10 по группе
4. Группа сетей ResNeXt
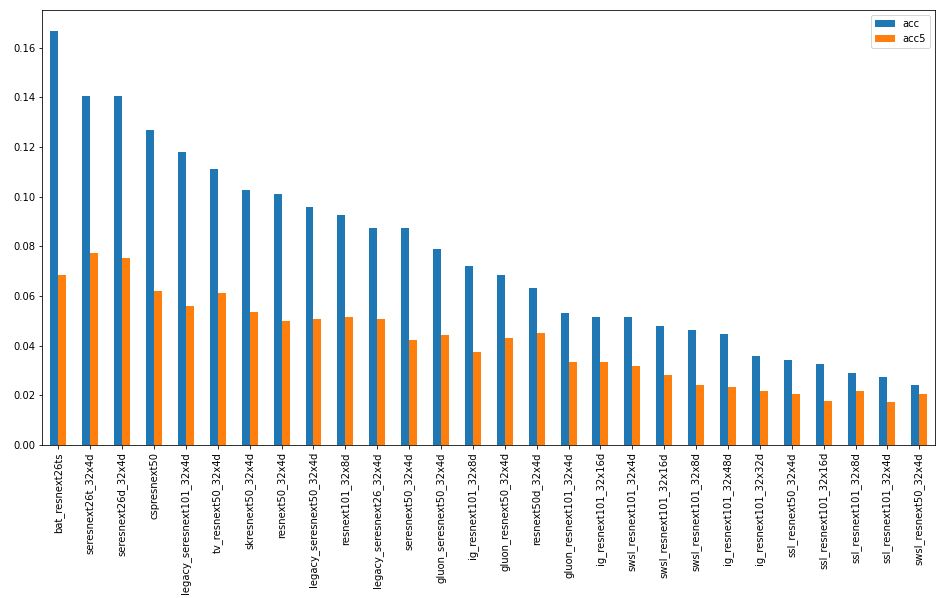
Другая реализация архитектуры ResNet с увеличенной мощностью не показала существенной разницы.
5. Группа сетей ReXNet/ResNeSt/Res2Net

ReXNet– достаточно интересная группа сетей с уменьшенным количеством параметров. Показала неплохие результаты, заняв 13 место в итоговом рейтинге архитектур. Притом, что rexnet_130 (при меньшем количествое параметров (7.5 млн) показало более высокое качество, чем rexnet_200
ResNeSt – реализация сети ResNet с блоками внимания между ветвями, показала неплохие результаты, так как результаты оказались в целом лучше чем у аналогичных архитектур ResNet без таких блоков.
Res2Net – реализация сети заточенная под задачи поиска объектов в разных масштабах и задачах сегментации, точности в приведённой задаче показала одни из худших результатов.
6. Группа сетей RegNet

Группа небольших по количеству параметров сетей как последовательное развитие сетей ResNet показывают очень хорошую точность, так как качество в целом оказалось лучше чем у сетей архитектуры ResNet.
7. Группа сетей Inception/Xception
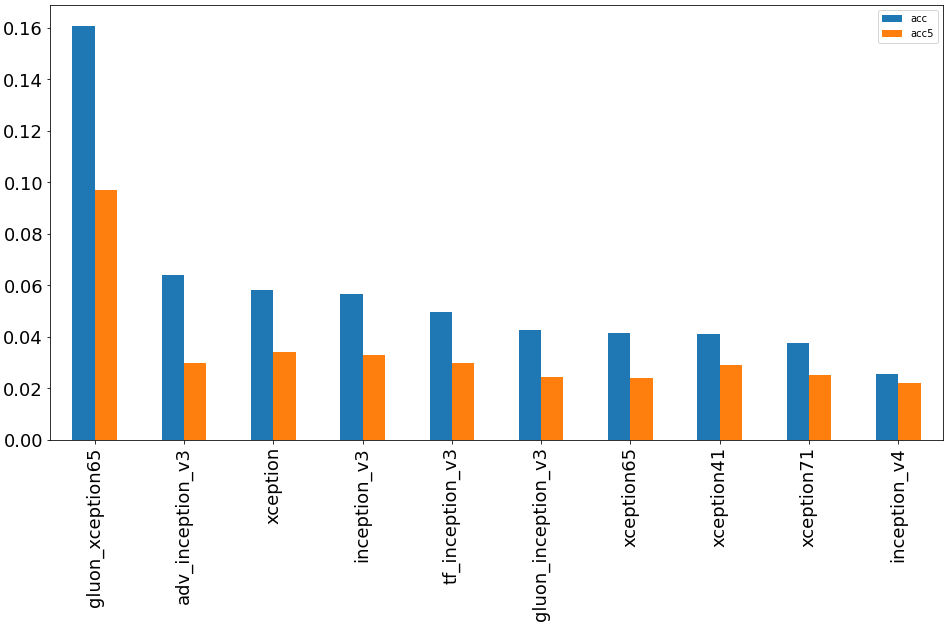
Архитектуры Inception и её модификация Xception оказались в числе отстающих в данной задаче.
Внимание привлекла сеть gluon_xception65, которая, по сравнению xception65, показала существенное улучшение качества. Веса этой модели были перенесены из Gluon.
8. Группа сетей MNASNet/NASNet/PnasNet/SelecSLS/DLA/DPN

Я объединил различные архитектуры сети в эту группу, чтобы можно было сравнить.
SelecSLS – архитектура нейронной сети, предложенная в качестве использования к задаче 3D-захвата движения людей в реальном времени. В задаче классификации показала себя на уровне сетей ResNet.
DLA – архитектура сети глубокой агрегации, имеет иерархические структуры объединения слоев, повышает распознавание объектов. Схожее качество с SelecSLS.
DPN – двойные сети классификации изображений, оказались в списке отстающих по точности.
NASNet архитектура нейронных сетей, оптимизирована с точки зрения производительности
При этом в данной группе, выиграла архитектура NASNet, с небольшим количеством параметров, лучшая в данной группе spnasnet_100, насчитывает всего 4 млн параметров, что более чем в 6 раз меньше, чем в resnet50. Полученная точность существенно выше.
9. Группа сетей MobileNet/MixNet/HardCoRe-NAS

MobileNet – очень популярная группа сетей, оптимизированная для мобильных устройств, показала просто выдающиеся результаты! Сеть mobilenetv2_140 с 6 млн. параметров – на уровне лучших сетей группы ResNet.
MixNet – усовершенствованный потомок от MobileNet: отличные результаты при минимальном количестве параметров сети.
HardCoRe-NAS – группа сетей, полученная в результате автоматического поиска оптимальных архитектур, с малым количеством параметров, но при этом показывающая стабильную и хорошую точность на нашей классификационной задаче.
10. Группа сетей трансформеров BeiT/CaiT/DeiT/PiT/CoaT/LeViT/ConViT/Twins
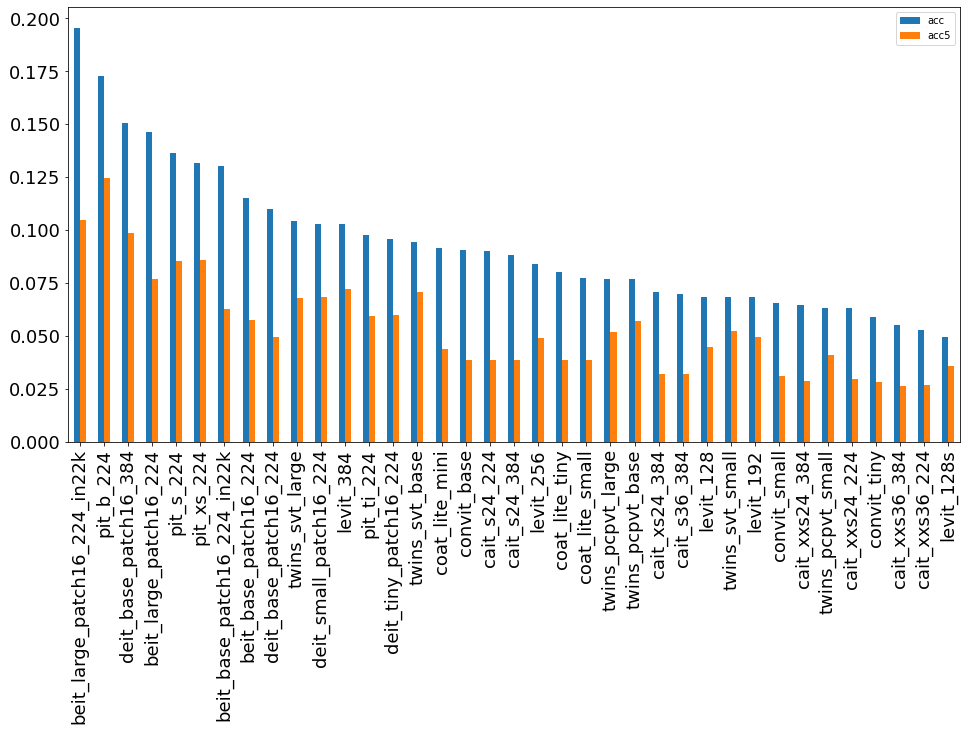
BeiT – сети класса двунаправленного кодировщика от Image Transformers, показали неплохие результаты, заняв 7ое место в данном рейтинге, но количество параметров в этих сетях, конечно, очень велико (325 млн. параметров) для лидера.
CaiT – сети классификации с блоками внимания и Image Transformers с небольшим количеством параметров показали результаты, сопоставимые с группой ResNet.
DeiT – архитектура сетей класса небольших Vision Transformer, которые не требуют долгого обучения и многомиллионных данных, проиграли BeiT архитектуре.
PiT Vision Transformer (PiT) модели с применением пулинга (Pooling) – достаточно небольшие, однако, дали хорошие результаты.
CoaT, Co-scale conv-attention Transformers - классификатор изображений на основе Transformer с небольшим количеством параметров. Несмотря не средние результаты, возможно, стоит посмотреть на эту группу сетей. Так как количество параметров в них меньше, чем в CaiT, но результаты лучше.
Twins - архитектура сетей, которая содержит в себе блоки внимания.
LeViT - гибридная нейронная сеть для быстрой классификации изображений, с блоками внимания.
ConViT — гибридная сеть, представленная как конкурент сети DeiT.
11. Группа сетей ViT (Visual Transofrmer)

ViT (Visual Transofrmer) — архитектура Трансформера, предварительно обученного на больших объемах данных. Тестировалась на различных датасетах изображений среднего и малого размера, стала лидером нашего рейтинга и заняла практически весь пьедестал в задаче Топ-5.
12. Группа сетей ConvNeXt

Современная архитектура ConvNeXt, разработанная как конкурентная альтернатива Трансформерам, при этом не уступающая им в точности и масштабируемости.
13. Группа сетей ResMLP/MLP-Mixer
Группы сетей, полностью построенные на многоуровневых персептронах для классификации изображений.
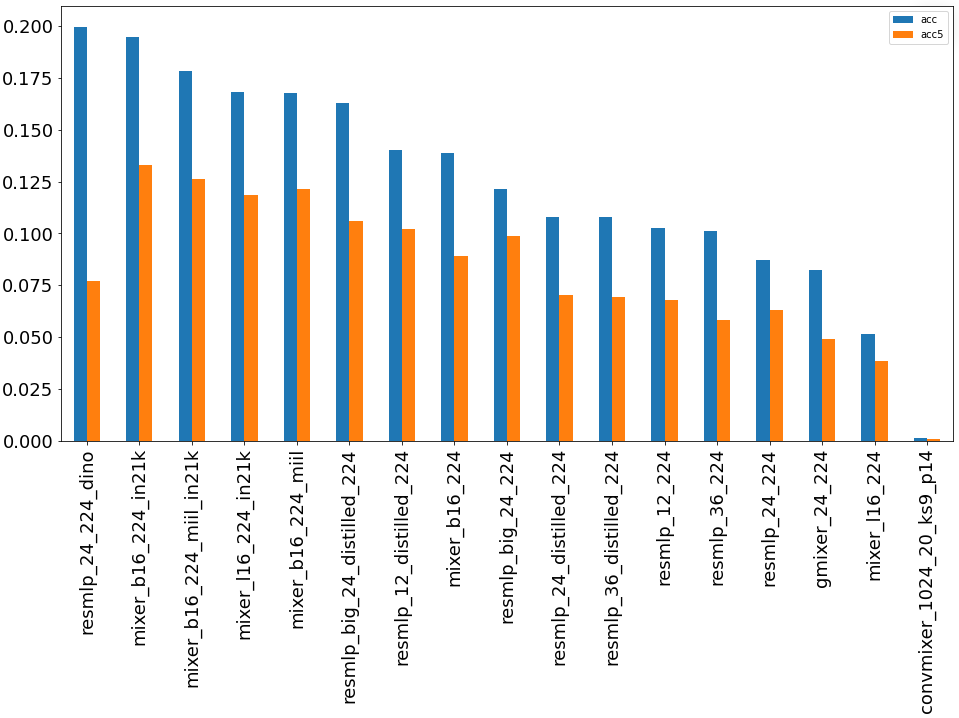
ResMLP – очень интересная архитектура сетей, при этом показала хорошие результаты в данной задаче классификации, и заняла 5 место в данном рейтинге архитектур.
MLP-Mixer – группа сетей, которая основана на многослойных персептронах и обучена на больших наборах данных, и заняла достойное место в данном рейтинге, не сильно уступив при этом ResMLP.
Результаты сопоставимы с другими группами сетей, в том числе, сетями Vision Transformer.
14. Группа сетей NFNet-F
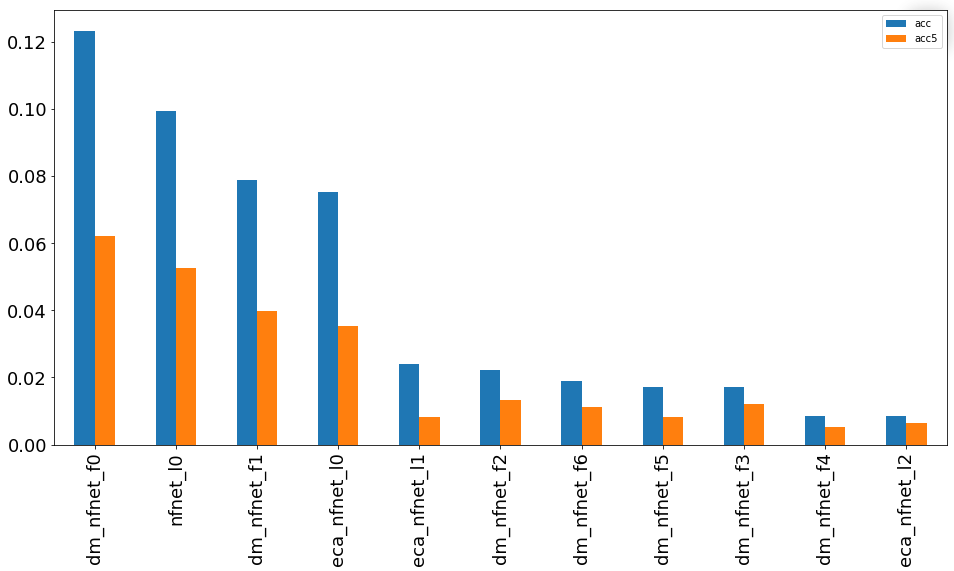
Модели для распознавания крупномасштабных изображений без необходимости нормализации показали плохие результаты по отношению к количеству используемых параметров.
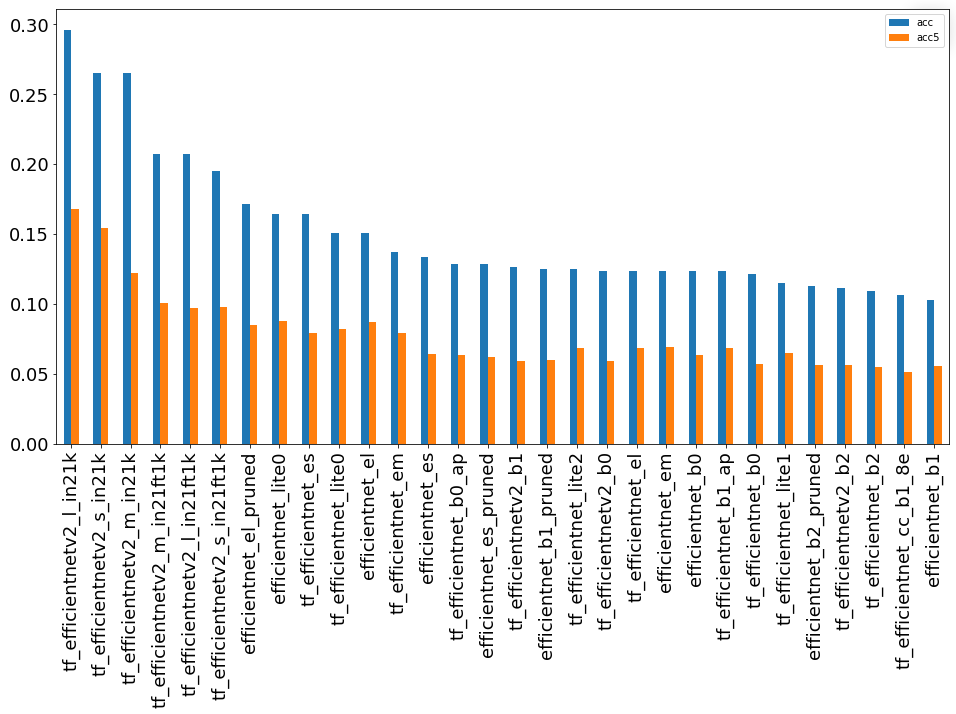
15. Группа сетей EfficientNet
Целый класс моделей, полученные с помощью автоматического поиска архитектур.
Очень популярная архитектура и представлена в виде двух графиков.
подгруппа “30 лучших”
подгруппа “Остальные”
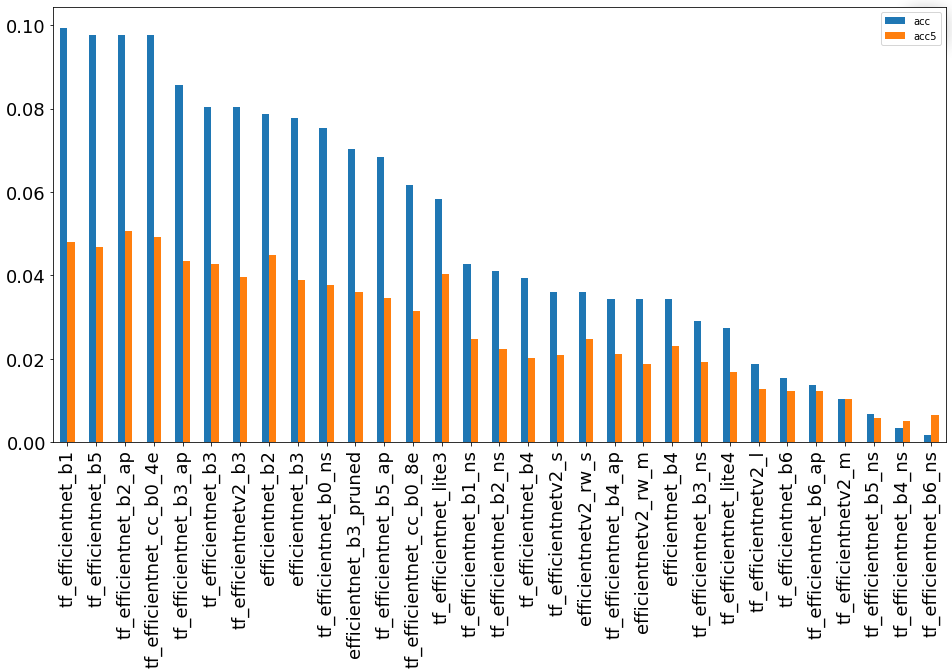
Данные модели имеют в задаче очень большой разброс по точности, однако, лучшая модель все же оказалась в этой группе. Лучшие модели также обучались на классификационных задачах с 21 тыс. классов.
16. Прочие предобученные модели сетей
VovNet – архитектура, предложенная для задач сегментации объектов.

HRNet – архитектура, рассчитанная на изображения с высоким разрешением и задач детекции и сегментации объектов.
Результаты рейтинга архитектур
Была составлена таблица лидеров из каждой группы сетей.
Вы можете провести самостоятельный дополнительный сравнительный анализ архитектуры. Я выложил файл с результатами сравнения в публичный репозиторий на GitFlic.
Выводы проведенного исследования
Действительно, в задачах классификации изображений в последнее время появилось очень большое количество новых архитектур, часть из которых требует пристального внимания.
Видно, что трансформеры присутствуют достаточно уверенно в задачах компьютерного зрения, при этом есть как большие сети Трансформеров с сотнями миллионов параметров, так и небольшие, по размеру сопоставимые с небольшими архитектурами.
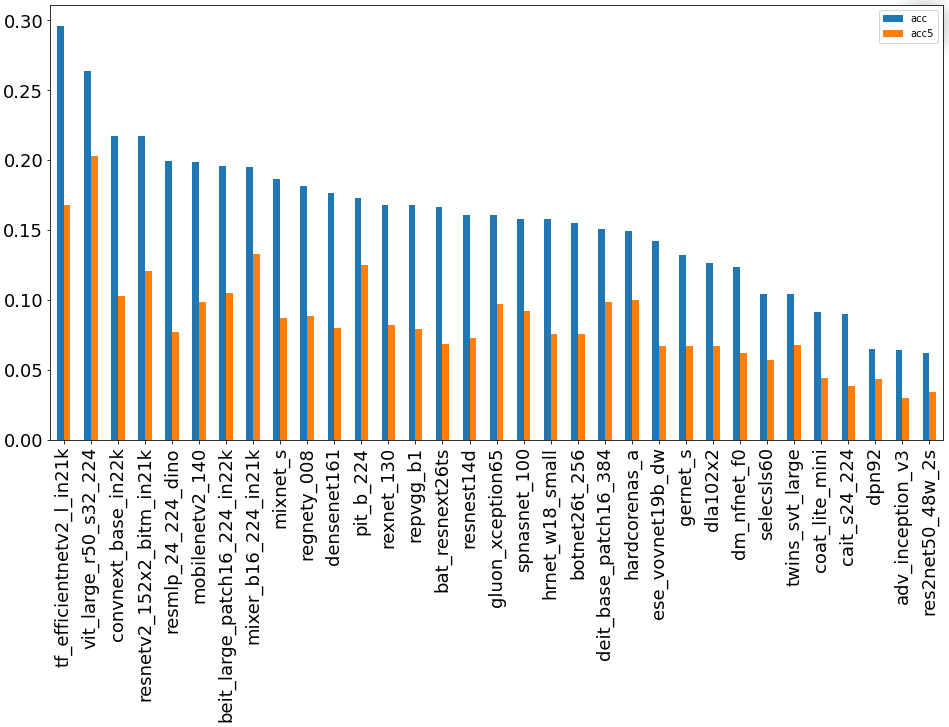
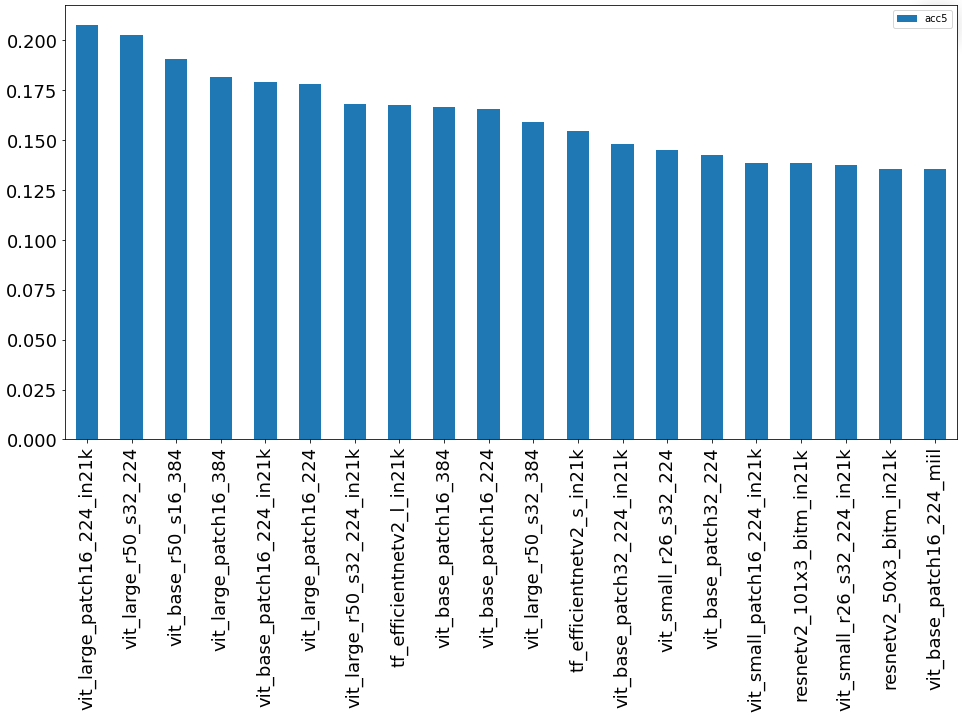
Какая же из предобученных сетей оказалась самой лучшей? Смотрим:
1) График лидеров в задаче Топ-1:

2) График лидеров в задаче Топ-5:
Из полученных данных я сделал вывод, что по точности победила предобученная модель из группы EfficientNet (Топ-1).
По полноте (Топ-5) и корректности полученных признаковых описаний первое место уверенно заняли сети из группы ViT (Visual Transformer).
На проведение данного исследования, и анализ результатов, в общем и целом у меня ушло около недели рабочего времени. Надеюсь, что данные труды будут полезны и вам!
Эксперт по Машинному обучению в IT-компании Lad.
Комментарии (12)

Arseny_Info
19.05.2022 01:35При этом если косинусная близость векторов с изображений одного класса максимальная, то считалось, что эта архитектура наиболее подходит, для последующего дообучения под конкретную задачу.
На чем основано такое утверждение?

UtrobinMV Автор
19.05.2022 12:13Спасибо за комментарий!
Да это лишь мое предположение. Вы знаете работы которые это подтверждают, или опровергают?
Но по факту мне в практической задаче хватило и косинусной близости. т.е. я полностью отказался от дообучения модели. Так как полученной точности оказалось достаточно для решения моей задачи.
segra
Почему точность результатов на ваших графиках существенно ниже опубликованных авторами сетей?
Например, по базе CoCa максимальная точность 91% для топ 1 https://paperswithcode.com/sota/image-classification-on-imagenet, а у вас меньше 30%.
red_elk
Вероятно потому что 91% это заявленная точность на ImageNet (1000 классов), а автор тестировал на другом датасете из 8000+ классов. Не очень понятно только откуда взялся этот датасет и почему top-1 accuracy выше чем top-5. По идее должно быть наоборот.
UtrobinMV Автор
Спасибо за комментарий.
Действительно, датасет использовался не ImageNet, а другой. Используемый для конкретной практической задаче классификации.
топ5 метрика в моей задаче не может быть выше топ1. Так как она разделена на 5.
топ5 - условно означает, сколько из первые 5 ближайших векторов эталонных картинок относятся к такому же классу. Где 1 - это все 5, и 0.2 если только 1 из 5.
segra
Очевидно, что при увеличении количества классов точность уменьшается, но различие очень велико. Например, если взять подмножество ImageNet из 100 наиболее частотных классов (сократить мощность в 10 раз) и сеть EfficientNet-B4, то точность по топ 1 возрастает с 83% до 89%.
UtrobinMV Автор
Спасибо, за комментарий.
На самом деле в статье, я указал, что использовалось в качестве оценки меру близости векторов. Вероятно в вашем примере, это другая оценка?
Кроме того, все зависит от данных. Метрики в данной задаче актуально сравнивать между собой в рамках одной данной задачи. На других исследованиях, и других данных, и результаты могут оказаться другими. Однако стоит сравнивать не сами конкретные значения, а их отношения между собой.
segra
Оценивалась точность по ImageNet, метод измерения такой же как на 1 графике вашей статьи.
Как сопоставлять ваши результаты с чужими?
UtrobinMV Автор
Суть исследования в том, чтобы сравнить большое количество архитектуры между собой. Данное исследования является самодостаточным, и не требует прямого сравнения с другими исследования. Хотя, кто то другой, может провести такое сравнение. Почему бы и нет!
Может являться руководством к действию, например если вам потребуется выбрать архитектуру для задачи классификации. Например можно начать новое дообучение под вашу задачу, с подбора архитектур которые являются лидерами в каждой группе, а не перебирать все 400 или более архитектур.
Кроме того, обучение нескольких архитектур удобно при использовании в ансамблях.
Я думаю вариантов много, и список далеко не исчерпывающий. Каждый сам найдет для себя, чем это может быть полезно!
segra
Просто непонятно:
Были ли ошибки при измерениях?
Почему у вас получились низкие точности при измерении Топ 1? В чём особенность тестовых данных?
Почему не коррелируют места сетей для Топ 1 и Топ 5 как в других исследованиях?
Какая версия EfficientNet?
UtrobinMV Автор
1) Я не понимаю о каких ошибках вы говорите. Весь процесс проходил автономно путём перебора, и если в процессе анализа вываливалась ошибка например из за недостаточности памяти. Сеть просто не бралась в расчет. Но тогда вы и не найдете эту Сеть в рейтинге.
2) Что значит низкие. Есть сети которые показали высокую точность, есть те которые показали низкую. Все приведено в графиках.
3) Почему же не коррелируют. Некоторые сети вполне неплохо коррелируют. Хотя да лидеры немного разные. Но сильных выпадов нет.
4) Я привел полное описание и название сетей. В статье указано из какой библиотеки взяты сети.
segra
Возможна опечатка при программировании;
Низкие по сравнению с результатами авторов сетей. В чём причины?
Для первых 3 мест этого не наблюдается на графиках лидеров в отличие от результатов на https://paperswithcode.com;
В статье по EfficientNet используются другие обозначения для вариантов сетей.