
Fail2ban — утилита чрезвычайно полезная во многих случаях. Думаю, многие используют её для того, чтобы в автоматическом режиме блокировать особенно назойливых «посетителей». К сожалению, если входящий поток становится слишком большим, fail2ban теряет все свои полезные свойства, потому что разбор лога безнадёжно отстаёт от реальности.
Вот, например, лог nginx из 100 тысяч строчек fail2ban при самых простых настройках (failregex='^<ADDR>') разбирает порядка 45 секунд:
$ fail2ban-regex nginx.log '^<ADDR>'
Running tests
=============
Use failregex line : ^<ADDR>
Use log file : nginx.log
Use encoding : UTF-8
Results
=======
Failregex: 100000 total
|- #) [# of hits] regular expression
| 1) [100000] ^<ADDR>
`-
Ignoreregex: 0 total
Date template hits:
|- [# of hits] date format
| [100000] Day(?P<_sep>[-/])MON(?P=_sep)ExYear[ :]?24hour:Minute:Second(?:\.Microseconds)?(?: Zone offset)?
`-
Lines: 100000 lines, 0 ignored, 100000 matched, 0 missed
[processed in 44.48 sec]Честно разделив одно на другое, получаем производительность порядка 2250 строк в секунду. Возьмём эту цифру за основу.
(По факту разбор происходит медленнее из-за того, что fail2ban банит выявленных нарушителей в том же потоке, на время останавливая чтение лога)
Теперь наступает пора оптимизации. Для начала попробуем остаться вместе с fail2ban и посмотреть, на что же он тратит время. Поскольку fail2ban написан на Python, мы можем просто подключить cProfile без всяких модификаций кода:
$ python -m cProfile -s cumtime /usr/bin/fail2ban-regex nginx.log '^<ADDR>'
...
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 52.734 52.734 fail2ban-regex:26(<module>)
1 0.000 0.000 52.640 52.640 fail2banregex.py:784(exec_command_line)
1 0.000 0.000 52.638 52.638 fail2banregex.py:719(start)
1 0.411 0.411 52.636 52.636 fail2banregex.py:571(process)
100000 0.789 0.000 50.909 0.001 fail2banregex.py:448(testRegex)
100000 0.689 0.000 49.839 0.000 filter.py:601(processLine)
100000 3.741 0.000 39.767 0.000 datedetector.py:321(matchTime)
1595350 0.945 0.000 34.731 0.000 datetemplate.py:157(matchDate)
1695573 33.933 0.000 33.933 0.000 {method 'search' of '_sre.SRE_Pattern' objects}
100000 0.205 0.000 5.583 0.000 datedetector.py:469(getTime)
100000 0.187 0.000 5.305 0.000 datetemplate.py:323(getDate)
100000 1.826 0.000 4.858 0.000 strptime.py:172(reGroupDictStrptime)
100000 1.284 0.000 3.519 0.000 filter.py:811(findFailure)
1400000 0.564 0.000 1.479 0.000 utf_8.py:15(decode)
200000/100000 0.615 0.000 1.303 0.000 strptime.py:143(zone2offset)
100000 0.154 0.000 1.100 0.000 strptime.py:124(validateTimeZone)
100000 0.422 0.000 0.965 0.000 {method 'index' of 'list' objectsи видим неутешительную картину. Большую часть времени fail2ban тратит на то, чтобы разобраться с форматом даты. К счастью, ему в этом можно помочь — нужно специфицировать, как именно эту самую дату разбирать. Сделать это можно с помощью параметра datepattern в файлах filter.d/*.conf, а для fail2ban-regex достаточно указать параметр -d.
Вывод fail2ban-regex
$ fail2ban-regex nginx.log -d '%d/%B/%Y:%H:%M:%S' '^<ADDR> - [^ ]+ '
Running tests
=============
Use datepattern : %d/%B/%Y:%H:%M:%S : Day/MONTH/Year:24hour:Minute:Second
Use failregex line : ^<ADDR> - [^ ]+
Use log file : nginx.log
Use encoding : UTF-8
Results
=======
Failregex: 100000 total
|- #) [# of hits] regular expression
| 1) [100000] ^<ADDR> - [^ ]+
`-
Ignoreregex: 0 total
Date template hits:
|- [# of hits] date format
| [100000] Day/MONTH/Year:24hour:Minute:Second
`-
Lines: 100000 lines, 0 ignored, 100000 matched, 0 missed
[processed in 8.07 sec]Итого скорость разбора выросла почти в шесть раз — до почти 12,5 тысяч строк в секунду. К сожалению, такая скорость достижима только при разборе с помощью fail2ban-regex: как уже было сказано выше, в боевом режиме при непрерывном чтении логов это происходит несколько медленнее.
Перепишем на чём-то компилируемом
Поскольку на этом возможности fail2ban исчерпались, мне пришлось искать альтернативные способы. В последнее время я начал изучать Rust и пребываю в полном восторге от этого языка, поэтому выбрал его.
Для того, чтобы эффективно банить нарушителей, нужно хранить последние N запросов (или меньше) для каждого IP-адреса и проверять, не слишком ли часто они приходят. Здесь хорошо подходит кольцевой буфер с несложной логикой: добавляем таймстампы запросов по кругу, и когда накопим ring_size значений, то при добавлении возвращаем разницу времени вновь добавленного запроса и N запросов назад.
Код кольцевого буфера
struct RingBanBuffer {
timestamps: Vec<Option<i64>>,
last_index: usize,
}
impl RingBanBuffer {
fn new(ring_size: usize) -> RingBanBuffer {
RingBanBuffer {
timestamps: vec![None; ring_size],
last_index: 0
}
}
fn add_query(&mut self, ts: i64) -> Option<i64> {
self.timestamps[self.last_index] = Some(ts);
self.last_index = (self.last_index + 1) % self.timestamps.len();
self.timestamps[self.last_index].map(|prev| ts - prev)
}
}
Собственно парсер логов тоже не слишком сложно написать: сначала выдираем интересующие нас поля (IP и дату) с помощью регулярного выражения, потом разбираем их. Если что-то не то, то возвращаем None.
Код парсера
use chrono::*;
use regex::Regex;
use std::net::IpAddr;
struct ParseResult {
ip: IpAddr,
timestamp: i64,
}
struct RegexParser {
regex: Regex,
date_format: String,
}
impl RegexParser {
fn new(regex: &str, date_format: &str) -> Self {
let re = Regex::new(regex).unwrap();
RegexParser {
regex: re,
date_format: date_format.to_string(),
}
}
fn parse_line(&self, line: &str) -> Option<ParseResult> {
let caps = self.regex.captures(line)?;
let timestamp = DateTime::parse_from_str(&caps["DT"], &self.date_format).ok()?.timestamp();
let ip: IpAddr = caps["ip"].parse().ok()?;
Some(ParseResult { ip, timestamp })
}
}Для парсинга даты понадобится крейт chrono.
Осталось всё соединить воедино. Заведём HashMap, сопоставляющий IP-адреса с кольцевыми буферами и состоянием забаненности, читаем файл по строчкам и наполняем структуру данных. Когда весь файл прочитан, то печатаем список забаненных в stdout и статистику в stderr.
Код main
fn main() {
let reader = BufReader::new(File::open("nginx.log").unwrap());
let parser = RegexParser::new(
r"^(?P<ip>[\d.]+) - [^ ]+ \[(?P<DT>[^\]]+)\]",
"%d/%B/%Y:%H:%M:%S %z",
);
let mut requests: HashMap<IpAddr, (RingBanBuffer, bool)> = HashMap::new();
let mut line_count = 0;
let start = std::time::Instant::now();
for line in reader.lines() {
line_count += 1;
if let Some(ParseResult { ip, timestamp }) = line.ok().and_then(|l| parser.parse_line(&l) ) {
let entry = requests.entry(ip).or_insert((RingBanBuffer::new(30), false));
if let Some(delta) = entry.0.add_query(timestamp) {
if delta < 30 {
entry.1 = true;
}
};
}
}
let elapsed = start.elapsed();
let banned_ips: Vec<&IpAddr> = requests.iter()
.filter(|(_, (_, banned))| *banned)
.map(|(k, _)| k)
.collect();
for ip in banned_ips.iter() {
println!("{}", ip);
}
eprintln!(
"elapsed {} ms, {} lines parsed, {} lines/s, banned = {}/{}",
(elapsed.as_micros() as f64 / 1e3),
line_count,
line_count as f64 / (elapsed.as_micros() as f64 / 1e6),
banned_ips.len(),
requests.len()
);
}Запускаем, проверяем...
elapsed 208.154 ms, 100000 lines parsed, 480413.5399752107 lines/s, banned = 565/3506480 тысяч строк в секунду, ускорение приблизительно в 38 раз, вау. Необходимую на практике скорость этот вариант уже перекрывает, но тут мне стало интересно, а насколько ещё это можно ускорить.
Разбор за линейное время
Прежде чем заниматься оптимизацией производительности, хорошо бы выяснить, а что же, собственно говоря, тормозит. Для профилирования кода можно воспользоваться прекрасным профайлером perf (у него есть целая wiki с документацией, а на Хабре есть введение в картинках).
$ perf record target/release/fast2ban > /dev/null
elapsed 206.889 ms, 100000 lines parsed, 483350.97564394434 lines/s, banned = 565/3506
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.031 MB perf.data (789 samples) ]
$ perf reportВидим вполне ожидаемую картину: большую часть времени занимает исполнение регулярного выражения, а именно — бэктрекинг.

Как же так — думаю я — вроде же регулярные выражения должны отлично оптимизироваться с помощью преобразования в конечные автоматы, а здесь этого явно не происходит.
После некоторых поисков я выяснил, что преобразование регулярных выражений в конечные автоматы, конечно, возможно: это в некоторых случаях умеет и крейт regex. Есть специальный крейт regex-automata, но для регулярных выражений, которые содержат capturing groups, оно не работает.
Кроме этого, существует расширение конечных автоматов под названием Tagged DFA, и готовые решения на его основе, например, RE2C (оно даже может генерировать код и на Rust). Регулярное выражение здесь достаточно простое, поэтому нечто аналогичное здесь несложно написать и своими руками.
Заодно обратим внимание на бесполезный вызов decode_utf8 — nginx по умолчанию пишет логи в ASCII. Линейный разбор можно сделать и на сыром массиве байтов, преобразуя их в строки только для компилятора с помощью unsafe-функции from_utf8_unchecked, которая по факту делает ничего.
Всё содержимое строки до первого пробела будем считать IP-адресом, потом пропустим три байта, затем до следующего пробела, затем до [, а затем до ]. Код при этом можно писать достаточно высокоуровнево, пользуясь итераторами: компилятор эффективно их оптимизирует. Получается разбор «в лоб»:
parse_line_automata
use std::str::from_utf8_unchecked;
fn parse_line_automata(line: &[u8], date_format: &str) -> Option<ParseResult> {
let mut iter = line.iter().enumerate();
let ip_end = iter.position(|(_, &c)| c == b' ')?;
let ip_str = unsafe { from_utf8_unchecked(&line[..ip_end]) };
let ip: IpAddr = ip_str.parse().ok()?;
let mut iter = iter
.skip(3)
.skip_while(|&(_, &c)| c != b' ')
.skip_while(|&(_, &c) | c != b'[');
let (date_start, _) = iter.next()?;
let date_end = iter.position(|(_, &c)| c == b']')?;
let date = unsafe { from_utf8_unchecked(&line[date_start+1..date_start+date_end+1]) };
let timestamp = DateTime::parse_from_str(date, date_format)
.ok()?
.timestamp();
Some(ParseResult { ip, timestamp })
}Единственное необходимое изменение в main: строки нужно получать теперь не с помощью lines(), а с помощью split(b'\n'), чтобы на выходе были не String , а [u8].
Увеличиваем тестовый файл до одного миллиона строк, запускаем...
elapsed 1269.688 ms, 1000000 lines parsed, 787595.0627240709 lines/s, banned = 1375/3506Получили дополнительный выигрыш чуть больше, чем в полтора раза. Интересно, что там в профиле?

Теперь мы упёрлись в strftime, который, в общем-то, нам не нужен. Более того, для того, чтобы банить нарушителей вообще не нужно разбирать дату, а только время. При необходимости можно добавлять к отрицательным разницам 86400, но и без этого окажется потерянной максимум одна минута вокруг полуночи.
Для этого достаточно после второго пробела пропускать символы аж до :, и не нужно искать закрывающую скобку, поскольку длина времени всегда составляет восемь символов.
Разбор только времени
fn parse_line_automata_time_only(line: &[u8], time_format: &str) -> Option<ParseResult> {
let mut iter = line.iter().enumerate();
let ip_end = iter.position(|(_, &c)| c == b' ')?;
let ip_str = unsafe { from_utf8_unchecked(&line[..ip_end]) };
let ip: IpAddr = ip_str.parse().ok()?;
let mut iter = iter
.skip(3)
.skip_while(|&(_, &c)| c != b' ')
.skip_while(|&(_, &c)| c != b':');
let (date_start, _) = iter.next()?;
let time = unsafe { from_utf8_unchecked(&line[date_start + 1..date_start + 9]) };
let timestamp = NaiveTime::parse_from_str(time, time_format)
.ok()?
.num_seconds_from_midnight() as i64;
Some(ParseResult { ip, timestamp })
}Результаты запуска радуют:
elapsed 699.125 ms, 1000000 lines parsed, 1430359.3777936706 lines/s, banned = 1375/3506Ускорение ещё почти вдвое, но разбор времени всё ещё занимает почти 20% времени:

Разбор и парсинг за один проход
Если внимательно подумать над тем, что происходит в предыдущем варианте, то окажется, что при разборе строки часть с IP-адресом строки читается дважды: сначала при поиске его конца, а затем — ещё раз — при парсинге в IpAddr. Поскольку формат строки уже довольно плотно прибит к функции парсинга, почему бы не разбирать адрес и время сразу по мере просмотра строки?
Скучный код парсинга
fn parse_line_v2(line: &[u8]) -> Option<ParseResult> {
let mut ip = 0u32;
let mut cur_grp = 0u32;
let mut timestamp = 0i64;
let mut cur_time = 0i64;
let mut iter = line.iter();
for c in iter.by_ref() {
if *c == b'.' {
ip = ip * 256 + cur_grp;
cur_grp = 0;
continue;
}
if *c == b' ' {
break;
}
cur_grp = cur_grp * 10 + (*c - b'0') as u32;
}
ip = ip * 256 + cur_grp;
let iter = iter.skip(3).skip_while(|c| **c != b' ').skip_while(|c| **c != b':');
for c in iter {
if *c == b':' {
timestamp = timestamp * 60 + cur_time;
cur_time = 0;
continue;
}
if *c == b' ' {
break;
}
cur_time = cur_time * 10 + (*c - b'0') as i64;
}
timestamp = timestamp * 60 + cur_time;
let ip: IpAddr = IpAddr::V4(Ipv4Addr::from(ip));
Some(ParseResult { ip, timestamp })
}
Кода получилось, конечно, побольше, но что насчёт эффективности?
elapsed 552.038 ms, 1000000 lines parsed, 1811469.5002880236 lines/s, banned = 1375/3506
Примерно ещё на четверть быстрее. В профиле начинает заметное время занимать функция __memcpy_ssse3_back из libc, которая вызывается при чтении файла, и... подождите, мы же можем использовать SIMD для разбора!
Разбор IP и времени из строки с помощью SIMD
Решение, которое я использую, основано на ответе на StackOverflow, и, если верить совпадению никнеймов, принадлежит @stgatilov. Оно основано на том, что IP-адрес в виде строки целиком всегда помещается в 128-битный регистр, в который влезает 16 символов, а максимальная длина IP-адреса — 15 символов (12 цифр и 3 точки).
Автор достаточно подробно объяснил в комментариях механизм работы этого алгоритма, я переведу его с некоторыми сокращениями:
Сначала мы загружаем 16 байт с невыровненного адреса с помощью инструкции lddqu. <...> Последующий код будет правильно работать вне зависимости от байтов после окончания адреса. В любом случае, вам лучше убедиться, что каждый IP-адрес занимает не менее 16 байт памяти.
Затем мы вычитаем
'0'из всех символов. После этого'.'превращается в-2, а все цифры остаются неотрицательными. Теперь мы вычисляем битовую маску знаков всех байтов с помощью_mm_movemask_epi8.В зависимости от значения этой маски мы извлекаем нетривиальную 16-байтовую маску перестановки из таблицы
shuffleTable. Таблица весит целый мегабайт, и для предварительного вычисления требуется довольно много времени <...>.Интринсик
_mm_shuffle_epi8позволяет нам изменять порядок байтов в XMM-регистре с помощью маски перестановки. В результате регистр XMM содержит четыре 4-байтовых блока, каждый блок содержит цифры (в little-endian). Мы преобразуем каждый блок в 16-битное число с помощью_mm_maddubs_epi16, за которым следует_mm_hadd_epi16. Затем мы переупорядочиваем байты регистра так, чтобы весь IP-адрес занимал нижние 4 байта.Наконец, мы извлекаем младшие 4 байта из XMM-регистра с помощью
_mm_extract_epi32. Если у вас его нет, можно воспользоваться_mm_extract_epi16, но это будет работать немного медленнее.
Код разбора IP
use std::arch::x86_64::*;
fn parse_ip_simd(addr: &[u8]) -> IpAddr {
let result: u32;
unsafe {
let input = _mm_lddqu_si128(addr.as_ptr() as *const __m128i);
let input = _mm_sub_epi8(input, _mm_set1_epi8(b'0' as i8));
let cmp = input;
let mask = _mm_movemask_epi8(cmp);
let shuf = SHUFFLE_TABLE[mask as usize];
let arr = _mm_shuffle_epi8(input, shuf);
let coeffs = _mm_set_epi8(0, 100, 10, 1, 0, 100, 10, 1, 0, 100, 10, 1, 0, 100, 10, 1);
let prod = _mm_maddubs_epi16(coeffs, arr);
let prod = _mm_hadd_epi16(prod, prod);
let imm = _mm_set_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 6, 4, 2, 0);
let prod = _mm_shuffle_epi8(prod, imm);
result = transmute(_mm_extract_epi32::<0>(prod))
}
IpAddr::V4(Ipv4Addr::from(result))
}Код для подготовки таблицы перестановок
fn init_shuffle_table() {
for len0 in 1..4 {
for len1 in 1..4 {
for len2 in 1..4 {
for len3 in 1..4 {
let slen = len0 + len1 + len2 + len3 + 4;
let lens = [&len0, &len1, &len2, &len3];
let rem = 16 - slen;
for rmask in 0..(1 << rem) {
let mut mask = 0;
let mut shuf: [i8; 16] = [-1; 16];
let mut pos = 0;
for i in 0..4 {
for j in 0..*lens[i] {
shuf[((3 - i) * 4 + (lens[i] - 1 - j))] = pos;
pos += 1;
}
mask ^= (1) << pos;
pos += 1;
}
mask ^= rmask << slen;
unsafe {
_mm_store_si128(
&mut SHUFFLE_TABLE[mask],
_mm_loadu_si128(&shuf as *const i8 as *const __m128i),
);
}
}
}
}
}
}
}Аналогичным образом можно разбирать и время с помощью SIMD-инструкций. Это значительно проще, поскольку минуты, секунды и часы всегда занимают ровно по два символа, и таблица с масками перестановок здесь не нужна.
Секунды и минуты располагаются в первых двух 16-битных словах (и умножаются на 1 и 60, соответственно), а часы — в пятом (и умножаются на 3600, т. е. 14*256+16). Выполняем умножение с горизонтальным сложением и извлекаем два двойных слова результата, которые остаётся просто сложить.
Разбор времени с помощью SIMD
fn parse_time_simd(x: &[u8]) -> u32 {
unsafe {
let input = _mm_loadu_si64(x.as_ptr() as *const _);
let input = _mm_sub_epi8(input, _mm_set1_epi8(b'0' as i8));
let input = _mm_shuffle_epi8(
input,
_mm_set_epi8(7, 6, 4, 3, -1, -1, -1, -1, 1, 0, -1, -1, -1, -1, -1, -1),
);
let coeffs = _mm_set_epi8(1, 10, 1, 10, 1, 10, 0, 0, 1, 10, 0, 0, 0, 0, 0, 0);
let prod = _mm_maddubs_epi16(coeffs, input);
let prod2 = _mm_madd_epi16(
prod,
_mm_set_epi8(0, 1, 0, 60, 0, 0, 0, 0, 14, 16, 0, 0, 0, 0, 0, 0),
);
let ms: u32 = std::mem::transmute(_mm_extract_epi32::<1>(prod2));
let h: u32 = std::mem::transmute(_mm_extract_epi32::<3>(prod2));
ms + h
}
}Заодно для поиска разделителей в строке можно использовать memchr, но не из стандартной библиотеки, а из крейта memchr который имеет оптимизированные для разных процессоров версии. Заодно и код стал короче:
parse_line_simd с memchr
fn parse_line_simd(line: &[u8]) -> Option<ParseResult> {
let ip = parse_ip_simd(&line[..16]);
let first_space = memchr(b' ', &line[7..])? + 7;
let second_space = memchr(b' ', &line[(first_space + 3)..])? + first_space + 3;
let time_begin = memchr(b':', &line[second_space..])? + second_space + 1;
let timestamp = parse_time_simd(&line[time_begin..time_begin + 8]) as i64;
Some(ParseResult { ip, timestamp })
}Результаты выглядят неплохо, добавилось ещё ~10%:
elapsed 471.925 ms, 1000000 lines parsed, 2118980.77024951 lines/s, banned = 1375/3506
Осталось избавиться от копирования памяти при чтении файла (__memcpy_ssse3_back ), и для этого можно использовать mmap. Да, это накладывает определённые ограничения, но в погоне за скоростью сложно остановиться. Итак, берём крейт memmap и несколько переписываем код парсинга, чтобы он заодно возвращал, сколько байт он прочитал:
Парсинг, возвращающий количество обработанных символов
fn parse_line_simd(line: &[u8]) -> Option<(ParseResult, usize)> {
let ip = parse_ip_simd(&line[..16]);
let first_space = memchr(b' ', &line[7..])? + 7;
let second_space = memchr(b' ', &line[(first_space + 3)..])? + first_space + 3;
let time_begin = memchr(b':', &line[second_space..])? + second_space + 1;
let timestamp = parse_time_simd(&line[time_begin..time_begin + 8]) as i64;
Some((ParseResult { ip, timestamp }, time_begin + 8))
}В главном цикле, соответственно, будем искать следующий символ переноса строки с учётом этого значения, проверяя, что до конца файла осталось больше 16 байт (потому что именно столько прочитает разбор IP).
Переписанные фрагменты main
fn main() {
// ....
let reader = unsafe { MmapOptions::new().map(&File::open("nginx.log").unwrap()).unwrap() };
let mut start_pos = 0;
let mut remains = reader.len();
loop {
let line = &reader[start_pos..start_pos + min(remains, 512)];
if let Some((ParseResult { ip, timestamp }, shift)) = parse_line_simd(line) {
start_pos += shift;
remains -= shift;
let entry = requests
.entry(ip)
.or_insert((RingBanBuffer::new(30), false));
if let Some(delta) = entry.0.add_query(timestamp) {
if delta < 30 {
entry.1 = true;
}
};
}
let next_line = memchr(b'\n', &reader[start_pos..]);
if next_line.is_none() {
break;
}
let shift = next_line.unwrap() + 1;
start_pos += shift;
remains -= shift;
line_count += 1;
if remains < 16 {
break;
}
}Выигрыш от использования mmap может быть незаметен в том случае, если данные читаются с диска недостаточно быстро: в этом случае копирование памяти не становится узким местом. Файл для тестирования содержит миллион строк и занимает 260 мегабайт, таким образом, на скорости порядка 1500 мб/с чтение файла займёт приблизительно 175 мс. Но если файл уже лежит в файловом кеше системы, то использование mmap даёт заметный выигрыш:
elapsed 373.291 ms, 1000000 lines parsed, 2678875.1938835923 lines/s, banned = 1375/3506
Чтобы увидеть, сколько на самом деле занимает чтение файла, нужно запустить perf от рута с ключом -a:
# perf record -a target/release/fast2ban > /dev/null
elapsed 370.284 ms, 1000000 lines parsed, 2700629.786866297 lines/s, banned = 1375/3506
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.786 MB perf.data (2473 samples) ]
# perf report
Нормальные замеры и итоги
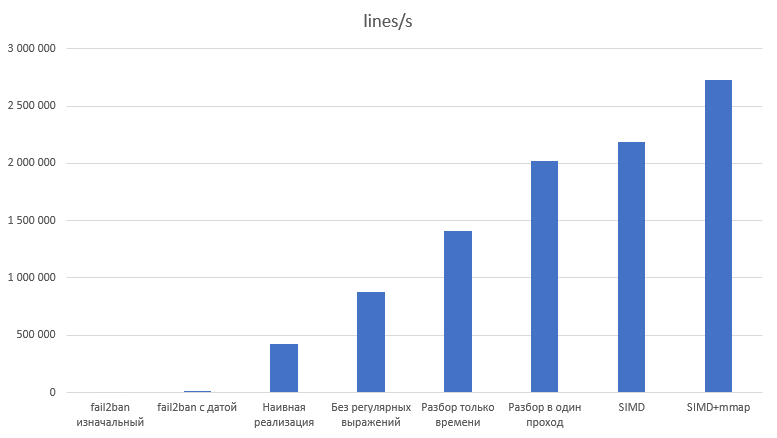
Теперь пришло время сделать более нормальные замеры скорости. Методология будет следующая: исполняем каждый вариант 100 раз, отбрасываем 10% самых быстрых и 10% самых медленных результатов, остальное усредняем по времени на строку и считаем стандартное отклонение.
lscpu виртуалки для тестов
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel Xeon Processor (Skylake, IBRS)
Stepping: 4
CPU MHz: 2294.608
BogoMIPS: 4589.21
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
L3 cache: 16384K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 arat md_clear spec_ctrlПравда, fail2ban-regex слишком медленный и я запускал его только по 10 раз. Кроме того, код на Rust разбирал по одному миллиону строк, а fail2ban-regex — по 100 тысяч. Сам fail2ban выводит замеренное время с точностью до 10мс, поэтому результаты для fail2ban округлены до 100 нс.
Вариант |
ns/line |
lines/s |
Ускорение |
Относительно предыдущего |
fail2ban изначальный |
488 600 ± 9 500 |
2 047 |
||
fail2ban с датой |
79 900 ± 2 800 |
12 514 |
6,11x |
6,11x |
Наивная реализация |
2 337,55 ± 96,66 |
427 799 |
209,04x |
34,19x |
Без регулярных выражений |
1 143,58 ± 73,79 |
874 448 |
427,29x |
2,04x |
Разбор только времени |
710,55 ± 43,93 |
1 407 366 |
687,69x |
1,60x |
Разбор в один проход |
494,64 ± 32,65 |
2 021 688 |
987,87x |
1,43x |
SIMD |
457,74 ± 30,96 |
2 184 669 |
1 067,51x |
1,08x |
SIMD+mmap |
366,22 ± 23,56 |
2 730 612 |
1 334,28x |
1,24x |
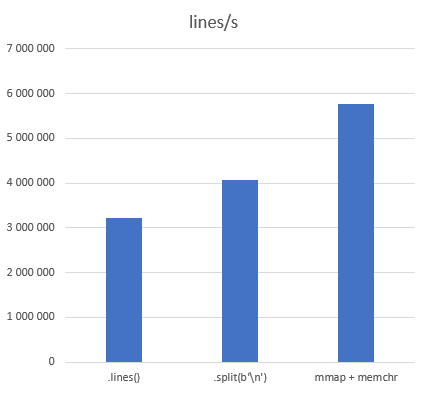
Дополнительно я измерил просто итерирование по строкам различными методами:
Метод |
ns/line |
lines/s |
Ускорение |
|
311,04 ± 12,89 |
3 214 981 |
|
.split(b'\n') |
245,63 ± 10,82 |
4 071 210 |
1,27 |
|
173,55 ± 7,15 |
5 762 122 |
1,79 |
Исходники выложены на github, код разных вариантов из статьи находится в ветке habr разными коммитами. Пулл-реквесты, как всегда, приветствуются.
P. S. Внимательные читатели могли заметить, что само использование SIMD не дало большого выигрыша — всего 8%. Тем не менее, желтоватый заголовок статьи корректен: тысячекратное ускорение было достигнуто именно на этом шаге.
Комментарии (68)

amarao
02.06.2022 12:20+12Ах, да, ещё. Мне кажется, что если мы идём в сторону миллионов, то первая ошибка - это парсинг текстовых логов. Я поискал, nginx вроде, в protobuf или что-то такое не умеет, хотя задача интересная.

m03r Автор
02.06.2022 12:44+7Да, это точно. Я полагаю, что даже простое изменение формата лога (просто в виде IP/datetime) сильно бы помогло производительности. Но интересно было решать задачу именно с заданным форматом.
amarao
02.06.2022 13:47+3Я полез смотреть какие сервера умеют бинарный логгинг, и не нашёл. Что даже странно.
Из моих тестов (я проверял производительность journald) я обнаружил, что он может до 30к сообщений в секунду (однопоточный). Мой (на коленке сляпанный с помощью https://docs.rs/journald/latest/journald/index.html) код на расте генерировал эти 30к сообщений с 50% утилизацией (тоже в одно ядро).
Возможно, там все криворучки (меня включая), но я подозреваю, что ответ в другом - все эти itoa, datetime, sprintf'ы (и их эквиваленты в других языках) - очень тяжёлые функции с кучей аллокаций.
.... может быть, нас ждёт новая революция с бинарными логами. (rkyv? zero cost serialization?)

arheops
02.06.2022 13:52+2Врядли. Большинству сервисов хватает обычного текста. Тоесть писать это некому.

speshuric
02.06.2022 14:09В "управляемых" облачных сервисах, наверное, имеет смысл. Если есть 1000 экземпляров сервиса и их логи, то почему бы, например, не сэкономить десяток серверов?

BugM
02.06.2022 21:10+6Логи нужны не чтобы их писать, а чтобы их читать. Глазами обычно. Удобный поиск с grep -C практически обязателен. И хочется чтобы он работал довольно быстро.
А на самый чёрный день хочется иметь возможность зайти на прод и посмотреть лог глазами. Иногда спасает.
Итого основное железо уходит на хранение и систему работы с логами от этой тысячи серверов, а не на запись лога в файл. Да и возможность типовыми средствами почитать лог прямо на пишущем сервере терять не хочется. Бинарные логи не нужны. Минусов слишком много для такой незначительной экономии железа.

gecube
02.06.2022 21:47+2Это ваше частное мнение. Бинарные логи журналди прекрасны. Единственный их недостаток - их не открыть напрямую текстовым редактором. Но будем честны - лог файл на 1 гигабайт и более текстовым редактором вы открывать не будете. А запускать Grep или условный journalctl -u servicename | grep или напрямую условный journalgrep разницы нет. Это как для grpc сделали утилиту grpcurl и опять стало удобно отлаживаться
BugM
02.06.2022 22:56+2Это другой инструмент. С которым надо знакомиться, учиться, привыкать. И естественно этим придется заниматься срочно во время серьезной проблемы требующей чтения лога на сервере без всяких удобств, кроме утилит которые есть на том же сервере.
Логи в нормальном режиме работы едут в некое хранилище логов и там уже они бинарные и пожатые. Текст живет только на сервере пишущем логи.
Хранилища логов и все пересылки с импортами проще конфигурить когда все логи одинаковые. Понятно что сделать можно все, но зачем эта лишняя сложность?
Экономия ЦПУ и локального диска от бинарных логов будет на уровне фонового шума. Было бы там процентов 10 все уже давно переехали бы.
gecube
03.06.2022 02:10Это другой инструмент.
и что? Эластиксерч тоже другой инструмент и его ТОЖЕ надо учить отдельно, и готовить отдельно. И так с любым другим движком для хранения логов.
И естественно этим придется заниматься срочно во время серьезной проблемы требующей чтения лога на сервере без всяких удобств, кроме утилит которые есть на том же сервере.
работай на опережение!
Логи в нормальном режиме работы едут в некое хранилище логов
в этом случае как хранятся локальные логи вообще по барабану
Текст живет только на сервере пишущем логи.
или не текст. Или там вообще нет логов (потому что нефиг давать доступ на конечные сервера, или потому что они отротировались уже)
Хранилища логов и все пересылки с импортами проще конфигурить когда все логи одинаковые.
это вообще мимо. Нужно конфигурировать не на основе того - текстовые или нет логи - а на основе формата источника данных. И если у Вас десять приложений на сервере, то все равно придется писать десять конфигураций для сборщика логов. Или забить и парсить это на стороне хранилища (у того же ES есть возможность это делать на т.н. ингест ноде). Но это не столь важно.
Было бы там процентов 10 все уже давно переехали бы.
не переехали только лишь потому что проще всего писать в файл и не делать голову.
BugM
03.06.2022 02:49-1Ну мы все таки в век контейнеров живем. Можно всегда считать что есть одно приложение на сервер пишущее один лог в одно типовое место. Чаще всего stdout. И дальше все настраивать и прикидывать исходя из этого. Зоопарк тут починили, он меня тоже бесил.
не переехали только лишь потому что проще всего писать в файл и не делать голову.
Был бы там нормальный профит в железе переехали бы. И пофиг на удобство. Деньги все считать умеют.
Тот же grpc. На потоке данных от 10Гбит переезд на него окупает все затраты на более сложную поддержку, новые другие тулзы, сложность внутренней структуры и новые проблемы. А вот когда 100Мбит в прыжке поток хотят на него перевести у меня появляются вопросы. Расходы на http и прочие json настолько смешные что удобство и простота становятся важнее.
С логами тоже самое, только потоков данных таких нет. Логи занимают совсем смешной объем от общего потока данных и их оптимизация, пусть даже в два раза по любому из параметров, на общем потреблении железа никак не скажется. А типовые трудности бинарного протокола появляются сразу.
gecube
03.06.2022 10:39+1Ну мы все таки в век контейнеров живем. Можно всегда считать что есть одно приложение на сервер пишущее один лог в одно типовое место. Чаще всего stdout. И дальше все настраивать и прикидывать исходя из этого. Зоопарк тут починили, он меня тоже бесил.
12 факторов - это хорошие принципы, но они не бесспорные. С теми же логами - те кто попрошареннее - инструментируют свои приложения и шлют «логи» напрямую в эластик или тот же сентри, чтобы иметь нормальную агрегацию событий. А sentry это реально топ штука. Не разбирать же мультилайн, чтобы категорировать ошибки в софте? И внезапно выясняется, что особой ценности писать в stdout/stderr нет, это удобно только на тестовых стендах. А на проде - у разрабов все равно нет доступа к docker logs/kubectl logs. А ещё Вы явно не сталкивались с ограничением на длину лог строки, если кидать ее в stderr.
Короче - на самом деле тезис о том, что любые логи надо писать в виде текста в stderr/stdout совершенно не бесспорен.
amarao
02.06.2022 14:16+4... Рано или поздно революция случится. Потому что всем нравится софт, который быстрее в 10 или в 100 раз предыдущего.
Прокси-сервер, построенный из ebpf, io_uring и максимальном количестве zero copy (включая логгинг). Сказка? Миллион коннектов в секунду на одно ядро? (У nginx это сейчас 145k, и это при отключенном логгинге).

edo1h
03.06.2022 03:57революция случилась, https, так что нет ни 1кк rps, ни даже 145к
amarao
03.06.2022 12:07Во-первых есть куча случаев до/после ssl. Балансировка на транспортном уровне, балансировка после (тем же proxy protocol). Во-вторых, SSL ещё бывает с акселерацией, и там очень высокие показатели.
edo1h
03.06.2022 14:57Во-вторых, SSL ещё бывает с акселерацией, и там очень высокие показатели.
если речь про ktls, то ЕМНИП там хеншейк не оффлоадится.

fougasse
02.06.2022 14:12ясно, что itoa и, особенно,generic реализации sprintf сложновато обойтись без кучи аллокаций, но всегда можно подсунуть свой велосипед
amarao
02.06.2022 14:20+4На самом деле всё интереснее. Изначально я подумал про binary log в каком-нибудь protobuf'е, чтобы не возиться с записью IP в строки. Но это же раст! И есть условный rkyv, который позволяет получить сериализацию с нулевым оверхедом (на самом деле нет, потому что данные в памяти чуть менее удачно лежат, но всё равно круто). Если выбранный формат таков, что одновременно обеспечивает и быструю работу прокси, и быстрые логи (а быстрые логи - это быстрые waf'ы/ids'ы и т.д.), то это звучит как пролетарский кулак в лицо интерпретируемой мути (js/python/ruby/node).

tuxi
02.06.2022 15:00Nginx умеет /mirror, а там куда это приходит, уже можно делать что хочешь. Ну как вариант, чтобы отказаться от чтения логов.

raamid
02.06.2022 12:48+24Написано прекрасным языком, читаешь и получаешь эстетическое удовольствие и от технической части и от литературной. Спасибо!

13werwolf13
02.06.2022 13:39+5Оно основано на том, что IP-адрес в виде строки целиком всегда помещается в 128-битный регистр, в который влезает 16 символов, а максимальная длина IP-адреса — 15 символов (12 цифр и 3 точки).
я так понимаю прекрастное будущее с ipv6 не наступило? :-)
а какое решение предложите если наступит?а так статью читать приятно, хотя я у мамы не кодер а админ, но было очень интересно, спасибо.
speshuric
02.06.2022 13:56+1Пока читал, куча мыслей промелькнула: А nginx хотя бы теоретически может угнаться по скорости генерирования логов за таким разбором? А action (блокирование) как быстро станет узким местом? И (если блокировать по одному IP), то как быстро заблокируется /0? А еще стало интересно, получится ли эффективная работа fail2ban в ip6? И можно ли еще ускориться парсингом на GPU?
amarao
02.06.2022 14:21+1Скорость логгирования сложно сказать, но nginx даёт 145к коннектов в секунду на ядро (http, без логов). С логами будет кратно меньше.
m03r Автор
02.06.2022 14:27+3Кстати, логи можно собирать с нескольких серверов.
nginxумеет логировать вrsyslog, а тот умеет пересылать логи по сети.В имеющейся схеме парсер логов запускается раз в минуту, и чем меньше времени (и, соответственно, ресурсов) он будет отъедать при разборе накопившегося — тем лучше.

cepera_ang
02.06.2022 14:08+1То есть итоговая скорость парсинга получается 0.25ГБ/0.373сек= 0.67ГБ/сек? Если судить по результатам других оптимизированных парсеров (simdjson, как пример), то ещё раз в десять ускорение должно быть возможно, а так как тут по сути только поиск двух значений в каждой строке идёт, то возможно и вообще пределом может быть скорость чтения из памяти.
m03r Автор
02.06.2022 15:02+3Если взять просто разделение строк по
memchr, то производительность выходит порядка 0,26Гб/0,173 с = ~1,5 Гб/с.В оригинальной статье про simdjson указано, что на Skylake@3,4GHz парсинг происходил со скоростью 2,2Гб/с. На виртуалке тоже Skylake, но на частоте 2,3GHz, что при пересчёте даёт те же 1,5 Гб/с.
Таким образом, если задействовать AVX, который использует
memchr, и делить на строки одновременно с парсингом, то, думаю, схожей производительности можно и добиться. Как-нибудь надо будет попробовать...А 12 Гб/с simdjson достигает, судя по той же таблице на с. 17, на
select, то есть выборке из уже разобранного дерева. Кстати, в этом он не чемпион, его обгоняет sajson.cepera_ang
02.06.2022 23:27+3Оригинальной статье уже три года :)
А вот тут его автор рассказывает как они на AVX-512 недавно ускорили и там поиск произвольных значений с нуля по 7Гбайт/сек шпарит или минификация (то есть поиск и удаление все пробельных символов, включая \n) на 12Гбайт/сек :)

xenon
02.06.2022 15:19+4Мне кажется, это очень частая ситуация, когда медленный скриптовый язык отлично подходит для реализации приложения, но тормозит в какой-то одной-двух маленьких деталюшках, которые бы, по-хорошему, надо реализовать на чем-то быстром (C, rust, go).
Может быть как-то регексовый парсинг (может быть с упором именно на парсинг логов) можно вынести в отдельную быструю утилиту, так чтобы ее можно было легко соединить потом и с fail2ban и с любым другим скриптовым обработчиком логов. Чтобы писать логику на удобных скриптовых языках и при этом не тормозить на парсинге. (Примерно как ни один скриптовый язык не делает zip/gzip своими силами, это было бы фантастически медленно, все используют внешние либы или утилиты).
gecube
02.06.2022 17:08+2(Примерно как ни один скриптовый язык не делает zip/gzip своими силами, это было бы фантастически медленно, все используют внешние либы или утилиты).
и ты точно так же попадаешь на дорогущий форк (если это внешняя утилита) или на сериализацию-десериализацию и вызов внешне либы (и хорошо, если она уже подтянута с диска в память)....
Может быть как-то регексовый парсинг (может быть с упором именно на парсинг логов) можно вынести в отдельную быструю утилиту
это бред, потому что в корне надо менять подход... не пытаться парсить регулярные данные (еще и через промежуточный медиатор в виде файла, капец, эффективность уровня БОГ), а сразу фигачить в протобуф тот же...

fshp
03.06.2022 12:40+3Только не в протобаф а во flatbuffers. Протобаф гонится за компактностью, поэтому там varint используется. Flatbuffers же в приоритете имеет скорость и zero copy.
gecube
02.06.2022 15:19+12Что сказать.. Статья интересная. Спасибо автору за это. Хороший пример программирования.
Но я категорически против использования fail2ban в проде.
Во-первых, это лишний компонент.
Во-вторых, это глючный компонент. А что вы думали? Я уже рассказывал байку, как правильный конфиг f2b привел к взлому телефонии из-за бага в том, что он не матчил tcp/udp порты.
В третьих, это медленно. Грепать или тейлить логи зашквар. Не понимаю, чем было бы хуже написать плагин на Lua для nginx и там трепать соединения.
В четвертых, f2b это попросту опасно. Пора привыкнуть к тому, что клиент далеко не определяется тупо айпи адресом. Запросто за одним айпи могут быть сотни пользователей. Это возможно как в мобильных сетях (привет мегафон с его натом), так и в случае корпоративных сетей (когда выход в инет делается с одного шлюза). И бан одного пользователя приводит к недоступности сервиса для всех. Повторяю. НЕЛЬЗЯ ИСПОЛЬЗОВАТЬ F2B для ПУБЛИЧНЫХ сервисов. Для частных - еще куда ни шло, но там он не нужен, потому что есть другие механизмы контроля
В пятых, если вам нальют DDoS, f2b будет последним, кто вас спасет… Вот честно - у меня не было ситуации, когда f2b был полезным инструментом….
@amarao какой бинарный логгинг, окстись. Тут энвой в ядро хотят затащить, чтобы быстрее работало, а ты journald разгонять пытаешься, который вообще НЕ ДЛЯ ЭТОЙ задачи.
Далее поговорим о технических вещах. F2b работает через айпитейблз. Это зашквар. Потому что nftables и прочее. Как там с их поддержкой? Все ок? А еще это медленно. Если хотим быстро - надо фигачить ebpf. И, удивительно, решения для этого есть.
Давайте попробуем подискутировать.

randomsimplenumber
02.06.2022 18:03Это да.. fail2ban отличный пример того, как решая одну проблему (клиент не может пройти авторизацию) можно придумать себе парочку других (вместо унылого подсчёта криптографии при установлении соединения процессор занят обработкой regexpов и заполнением таблиц в памяти ядра).
Немного более прямо было бы писать логи в изначально машиночитаемой формате (sql?).
А так, fail2ban нужен только затем чтобы админу было чем заняться ;)

Semy
03.06.2022 12:47sql - это язык запросов.
Логи можно было бы писать в JSON. Это бы сохранило и читабельность (ну хотя бы относительную в отличии от бинарных логов) и более удобный парсинг через jq вместо grep.

iig
03.06.2022 12:57json - это ещё хуже (в смысле быстродействия).
sql - это не только язык, но и изначально форматированные данные (не нужно парсить дату/время/ip) + возможность поиска/сортировки
gecube
03.06.2022 13:26sql - это не только язык, но и изначально форматированные данные (не нужно парсить дату/время/ip) + возможность поиска/сортировки
sql - это не формат
json - это ещё хуже (в смысле быстродействия).
это хоть какой-то компромисс. Но все равно все сводится к тому, что есть поле message, которое становится помойкой для всего.
еще добавлю
@BugM подумайте еще вот о чем. Бинарный формат в journald обеспечивает надежное хранение и контроль целостности логов. В случае - если мы логи пишем просто в текстовые файлы - где гарантии того, что лог будет цельный? Что какой-то Васян или программа по ошибке его наполовину не затрет ? А с json, @Semy, так вообще песня. Положили мы его в файл. А лог по какой-то причине транкейтнулся. Результат очень простой - jq просто при парсинге этого лога возьмет и сломается... Не, такой подход не годится...
iig
03.06.2022 13:41sql - это не формат
В смысле хранения данных - нет, не формат. В смысле доступа к данным - очень даже да. Данные парсить не нужно, они уже типизированные. Но я не настаиваю ;)
Semy
03.06.2022 14:53Если лог обрезался почему то не по границе строки, то text тоже будет поломан, а json упаковывается в строку. Поэтому я подразумеваю, что он "условно читаем". Визуально воспринимается он плохо, но хоть grep'нуть по нему можно. Одним словом -- компромисс.

BigD
02.06.2022 20:06+1Так, а чем заменить-то? Пример - веб-сервер, SSH надо защитить качественно, ключи не вариант (нужны пароли).
gecube
02.06.2022 20:22+1защитить от кого или от чего? Вы всегда должны думать в первую очередь - от чего защищаемся.
ключи не вариант (нужны пароли).
не нужны. Если это не так - Вы что-то делаете не так. Либо накидывайте конкретные кейсы, можно обсудить
Понимаю, что такой вариант подходит не для всех случаев, но для бана активно долбящихся в какую-нибудь API — то, что надо. Nginx, ограничив спамера через limit_req, отправляет его айпишник в error_log, который, в свою очередь, просматривает f2b и в какой-то момент блокирует уже на сетевом уровне.
я объяснил почему это не работает. Представьте себе, что Ваши клиенты сидят на каком-нибудь таймвебе, ECS или любом другом шареном хостинге и у них РАЗНЫЕ токены для доступа к Вашему АПИ, но айпишники общие. Вы реально будете их блочить на сетевом уровне, ау?
BigD
02.06.2022 20:30Ну ОК, подумал, какой-то менеджмент ключей можно сделать. Перебор/брутфорс больше не грозит? Можно не блокировать попытки подбора?
randomsimplenumber
02.06.2022 21:31А чем грозит попытка подбора ключа?
BigD
02.06.2022 22:37-1Успешным подбором? Перегрузкой файла с логами и места для логов?
BugM
02.06.2022 22:57+1Подобрать ключ? Вы это серьезно?
Про ротацию логов по размеру вы ничего не слышали?
gecube
02.06.2022 22:57+1Перегрузкой файла с логами и места для логов?
бредовый аргумент. Кладите логи на отдельную ФС и не блокируйте выполнение основного функционала, если логирование сломалось.
Успешным подбором?
здрасьте... если пароль еще можно подобрать (так как там энтропия низкая и пользователи обычно используют или словарные пароли, или пароли кочуют от сервиса к сервису), то подобрать ключ 4096 бит... ну удачи, как говорится
Я гарантирую, что если злоумышленник вошел по ключу, то это означает не то, что он его подобрал, а то, что он его с*#^$*#$^* у владельца ключа... И это проблема гораздо более серьезная, чем подбор пароля (мало ли там еще остальные доступы этого пользователя в другие сервисы уже похеканы)...
Да и вообще сделайте наконец-то OTP вход по SSH... И, да, это возможно...
13werwolf13
03.06.2022 06:29подобрать ключ задача не реальная в текущих реалиях
особенно если админ не наркоман и сделал конфиг sshd с таймаутами и безопасными ciphers.единственное чем грозит попытка подбора ключей (логинов и паролей) в таком случае это увеличенная нагрузка на проц и сеть, и от этого обычно спасает перевесить ssh с дефолтного порта на рандомный, а ещё лучше прикрыть его vpn и/или portknocking.
и да, толку будет больше чем от f2b
относительно недавно я делал конфиг sshd для прохождения банковского аудита, там всё просто (хотя за пару строчек в нём мне стыдно, но таковы реалии работы с банками), найти его можно тут. и если уж банки это устроило вам точно хватит (есстессно с небольшими правками под себя.
randomsimplenumber
03.06.2022 07:46+1увеличенная нагрузка на проц и сеть
Fail2ban сам обеспечивает нагрузку на проц ;) С чем боролись, как говорится.

AlexanderS
03.06.2022 11:41+1не нужны. Если это не так — Вы что-то делаете не так. Либо накидывайте конкретные кейсы, можно обсудить
Стоит домашний сервер, на котором крутится Nextcloud, к которому подключен мобильный клиент, который умеет авторизацию только по паролю. Используя f2b можно разобрать логи Nextcloud и сварганить защиту от перебора паролей. В принципе Nextcloud и сам умеет защищаться от брутфорса, но только таймаутом, а тут проблема убирается в корне сразу на целый день/неделю/месяц/год) Но со всеми вытекающими рисками блокировки сети за NAT. Однако если доступ к облаку на сервере осуществляется с определённых статичных IP, то это несущественно. А есть какая-то простая и незамороченная альтернатива в подобной ситуации?gecube
03.06.2022 11:56перевесить nextcloud на нестандартный порт (не 80,443, а какой-нибуль 30200)
сделать впн, вывешивать nextcloud на приватный ip, на телефоне зафигачить vpn клиента
your choice...
Используя f2b можно разобрать логи Nextcloud и сварганить защиту от перебора паролей. В принципе Nextcloud и сам умеет защищаться от брутфорса, но только таймаутом, а тут проблема убирается в корне сразу на целый день/неделю/месяц/год)
Вы сами дали ответ на свой вопрос. f2b тут нафиг не нужен. Рейт лимит и защита от брутфорса прекрасно делается на уровне приклада или reverse proxy перед ним (nginx).
Я еще, кстати, надеюсь, что у Вас nextcloud по tls наружу торчит?
AlexanderS
03.06.2022 12:52Перевешивание сервисов на нестандартные порты, причём не «круглые» — это кажется первым пунктом вообще везде делать надо. Это закрывает кучу моментов, иначе боты одолеют.
Сервер старый, стек LAMP в котором обычный HTTPS через самоподписной SSL сделан и прочая ламповая партизанщина. Я лет 5 назад цикл мануалов на хабре делал. С тех пор никакой эволюции не было ибо как-то не до этого. Хотя поддержка Debian 9 этим летом заканчивается. Да и для локалки нормально было, а сейчас в сети торчит только потому что там ничего важного нет)
cepera_ang
03.06.2022 12:19+1А есть какая-то простая и незамороченная альтернатива в подобной ситуации?
Tailscale. Поставить на сервер, поставить на мобильник. 0 конфигурации, почти идеальная надёжность. Можно хоть вообще без пароля выставлять сервисы, уютная «локалка» для своих девайсов как в старые добрые доинтернетные времена.
AlexanderS
03.06.2022 12:54+1Это Mesh на основе WireGuard? Звучит очень привлекательно, спасибо за наводку.
cepera_ang
03.06.2022 00:12+1SSH посадить на менеджмент-интерфейс, доступный только из частной сети (с подключением по ключу, бгг). См. tailscale.
BigD
03.06.2022 00:23К сожалению, доступ к сайтам на сервере по SSH нужен куче агентств. Тут нужно что-то типа Teleport по хорошему, но он дико дорогой в Enterprise версии.
gecube
03.06.2022 00:26используйте бесплатную, она прекрасно работает.
И, да, телепорт - это по сути ssh по сертификатам.
Альтернативы:
ssh по otp
ssh по короткоживущим сертификатам - пример - https://smallstep.com/docs/tutorials/ssh-certificate-login
Если есть какие-то вопросы - я собираю русскоязычное сообщество пользователей телепорта в телеграмме для обмена опытом. Уже пару ребят подсадил на это прекрасное решение и негатива в принципе нет
edo1h
03.06.2022 03:18ключи не вариант (нужны пароли).
ну ладно, пароли так пароли,
pwgen -Bs 16, тыкаем в любой.если же у вас пароль «год канонизации святого Доминика папой Григорием IХ», то fail2ban вас никак не спасёт, перебор паролей сегодня зачастую идёт распределённо.
cepera_ang
03.06.2022 00:10+2> В третьих, это медленно. Грепать или тейлить логи зашквар. Не понимаю, чем было бы хуже написать плагин на Lua для nginx и там трепать соединения.
Да, по-настоящему оптимальный подход конечно не в том, чтобы сначала сохранять в файл (!) текстовый (!) лог через миллион системных вызовов и тонны оверхеда, а потом парсить его питоном (!), а реализовать эти счётчики прям в процессе принимающем соединения за пару десятков инструкций :)
Это кстати интересный пример того, насколько отличаются понятия о производительности у «обычных» людей и тех, кто под большой нагрузкой выжимает реально последние проценты из _системы_, не отдельных программ или функций. В первом случае «мы перестали вызывать отдельную программу интерпретирующую скрипт с диска на каждое соединение» может быть оптимизацией закрывающей все проблемы (потому что современные железки — безумные звери), во втором случае «мы парсим первые байты пакета ещё в буфере на сетевой карте и принимаем решение за N-2 SIMD инструкции» — обычный вечер пятницы. Прост у первых тысяча коннектов в секунду (у-у-у! хайлоад!), а у вторых миллион :)gecube
03.06.2022 16:00Да, по-настоящему оптимальный подход конечно не в том, чтобы сначала сохранять в файл (!) текстовый (!) лог через миллион системных вызовов и тонны оверхеда, а потом парсить его питоном (!), а реализовать эти счётчики прям в процессе принимающем соединения за пару десятков инструкций :)
внезапно, лет 5 тому назад - я решал похожую задачу. Был некий лог, который тейлился скриптом на перле. Это было не очень поддерживаемо (перл вообще как ЯП уже вроде как умер, но в то время это было прям на острие технологий). Я его переписал на python. Чтобы Вы думали - производительность упала (!). Не то, чтобы сильно, но просела. Так что я прямо на практике убедился в том, что перл реально побыстрее пайтона работает. Другой вопрос, что в общем-то никто от этого не пострадал. И, да, с одной стороны я горжусь тем, что заскриптовал и это решение крутится в проде, с другой - не горжусь, потому что такие же костыли и лучше было придумать альтернативное решение с более вменяемой архитектурой... Но не было тогда ни времени, ни бюджета на это
cepera_ang
03.06.2022 16:52Все мы делаем решения в рамках возможного для нас. Главное стремиться к лучшему и расширять пространство возможного (вчера — скрипт парсящий лог на питоне, сегодня модуль на луа для nginx, завтра — модуль WASM на расте для envoy). Плохо было бы сидеть и защищать скрипт на питоне или спорить что лучше перл или питон :)

radroxx
03.06.2022 18:48-1fail2ban - отличный инструмент
Это инструмент для конкретной задачи и он с ней справляется хорошо
Если у вас кривые правила в фаерволе не какой f2b не поможет
Достаточно для большинства кейсов, я не верю что у вас на телефонии или nginx больше чем 2к rps, или больше чем 2к строк в сек. прилетает в логи. Грепать и тайлить логи это нормально так делают большинство logstash fluentd и т.д.. А хранить логи в файлах локально это в первую очередь надежно и быстро в отличии отправке по сети. Анализ трафика на лету как правило выходит дороже и опасней.
Если так хочется баньте ip+port для udp он меняется раз в 30 минут по умолчанию или не меняется вовсе днями. С tcp сложней, но даже те провайдеры кто прячет пользователей за nat как правило присваивают 1 ip на пользователя и ротейтят с какой то периодичностью, а не прячут овер +100500 узверей за 1 ip. Так что проблема в большинстве надумана. С организациями немного сложней но для этого есть белые списки.
Вас хостер первым попросит свалить с его хостинга, при хорошем ddos могут и с ДЦ попросить свалить. Если вы достаточно жирный клиент то поставщик как правило сам решает вопрос ddos-а, за отдельные деньги или уже в пакете, соответствующим оборудованием и это не как не в плоскости f2b, да и инструмент решает иные задачи.
Fail2ban - работает на python его легко править, в нем легко разобраться для него легко писать правила. В конечном итоге f2b делает ровно 2-е вещи вызывает cli командочку для того что бы забанить и cli командочку для того что бы разбанить. Что вы там будете вызывать это ваш вопрос, не нравится iptables используйте любой другой фаервол, для ускорения вполне можно юзать ipset. Не знаю что такое ebpf но если он умеет добавлять правила и удалять cli командой то f2b с этим справится. Можете на fail2ban легко сделать не добавление правила а отправку сообщеньки в тот же telegram с ip и идти руками проверять, что там происходит. Всяко лучше чем проспать и что то делать когда уже клиенты приходят.
Это в первую очередь простой инструмент закрывающий вопрос с назойливыми ботами и мамкиными кулхацкерами. В случае с asterisk это вообще маст хев, там sip обрабатывается в 1 ядро, брутить могут так что на остальных клиентов cpu не хватает и если таких не банить страдают остальные клиенты. А если у вас публичный сервис для всех и масштабы соответствующие у вас с вероятностью в 99% кластер, и там простым f2b уже не обойтись. Ну или мощности позволяют забить на вопрос борьбы с мамкиными кулхацкерами.
Мой посыл такой это инструмент закрывающий вопрос брутфорса паролей на сервисе будь то sip, ssh или что то еще, почти из коробки, требующий минимальных усилий на внедрение. И это все отлично работает пока вы вмещаетесь на 1 сервер. Когда вы не влазите на 1 сервер то и решения нужно применять соответствующие.gecube
03.06.2022 19:00не убедительно, от слова совсем.
Это инструмент для конкретной задачи и он с ней справляется хорошо
define что это за конкретная задача?
Если у вас кривые правила в фаерволе не какой f2b не поможет
проблема была не в файрволле, а в самом f2b. Может мне еще ссылку на ишью дать? Не проблема, кстати, только поискать надо будет поиском. Он (f2b) как был студенческой поделкой без каких-либо гарантий, так и остался. Это не промышленные штуки вроде nginx - которыми пользуются все, на скейле, да еще и есть коммерческая версия с поддержкой.
Знаете, уровень большинства инструкций в интернете точно такой же. Что там обычно делают? Ставим центос линукс (потому что это же почти RHEL!!!). Затем отключаем SElinux (это же сложно его настраивать, давайте сразу отключим). Потом давайте затащим nginx или апач. И в довершение подпихнем f2b...
Грепать и тайлить логи это нормально так делают большинство logstash fluentd и т.д.. А хранить логи в файлах локально это в первую очередь надежно и быстро в отличии отправке по сети. Анализ трафика на лету как правило выходит дороже и опасней.
не нормально. В том же флюенте народ прекрасно с разбега налетает на race condition и на достаточную сложность настройки (когда формат входящих логов у разных приложений разный). Я уж не говорю о гарантиях доставки (краткий спойлер - их нет, ну, потерялись логи - ничего страшного)
Если так хочется баньте ip+port для udp он меняется раз в 30 минут по умолчанию или не меняется вовсе днями. ....
я уже ничего не хочу, мне пофиг, я в состоянии дзена и без f2b и сервисы защищены.
А если у вас публичный сервис для всех и масштабы соответствующие у вас с вероятностью в 99% кластер, и там простым f2b уже не обойтись
чтд

Abyss777
02.06.2022 16:32+1А куда денутся все эти преимущества при реальном бане IP? накладные расходы на вызов iptables всё ускорение нивелируют.
m03r Автор
02.06.2022 16:39+2При реальном бане с запасом хватает скорости наивной реализации, а бан делается пачкой через
ipset, потому что добавление правил по одному вiptables, конечно же, сильно тормозит (в том числе и обработку длинной цепочки правил). Кстати, в README репозитория есть инструкции на этот счёт.

ky0
02.06.2022 18:34+2Я бы начал с того (собственно, так и делаю), что парсил не огромные access-логи, а складывал бы активность тех, кого потенциально может понадобиться забанить куда-то ещё, например, в тот же error-лог.
Понимаю, что такой вариант подходит не для всех случаев, но для бана активно долбящихся в какую-нибудь API — то, что надо. Nginx, ограничив спамера через limit_req, отправляет его айпишник в error_log, который, в свою очередь, просматривает f2b и в какой-то момент блокирует уже на сетевом уровне.

slepnoga
03.06.2022 00:52+1Как говорится, побрюзжу - у автора какие то нереальные с точки зрения админа задачи.
Похоже, что архитектуры нету,. Миллион строк логов на том же хосте, где и фронтенд ? А там еще и постфикс крутится? :) и сислог , и крон с logratade? А почему бы и нет ;). Ну если баним на апстолах на том же хосте...
-
Проблема разбора миллионов строк логов с ~40k bare-metal ( и бог знает сколько контейнеров) была решена почти 10 лет назад уже знакомыми с 6-го этажа одного бизнесцентра в моем городе и успешно применялась ( а может и сейчас применяется) в одном из 2-х двухбуквенных сайтов Рф.
Так как все равно логи льем на сервера логгирования, то именно там до записи на FS стоит мелкая незаметная крохотулька https://github.com/quadrantsec/sagan, в те времена не такая навороченная, но так же быстрая.
П.С. Забанить DDoS iptables вы все равно не сможете, т.к. DDoS - это когда в 10Г канал вам вдувают 50Г трффика...
m03r Автор
03.06.2022 08:05+2Вы совершенно правы, и именно поэтому статья располагается в разделе "ненормальное программирование". Практических целей у дальнейших оптимизаций нет, просто было интересно.
amarao
Начинается как админская байтка, но почти сразу же превращается в rusting. По админской байке, я бы начал с vector (утилита для процессинга логов на rust), но rusting требует совсем других попугаев, и байтка уже не про админские будни.
Но интересно, спасибо!