
Привет, меня зовут Андрей, я руководитель бэкенд разработки компании Бимейстер.
Хочу поделиться опытом быстрого подсвечивания возможных проблемных зон объёмного и малознакомого кода.

Для кого эта статья?
Показанное здесь решение позволяет сэкономить до 8 часов времени на чтение документации и на путь проб и ошибок руководителю разработки любого уровня, лиду команды и просто разработчику, которому нужно быстро подсветить потенциальные проблемы в объёмной незнакомой кодовой базе.

Когда кода много, а времени мало, можно устроить анонимный опрос и узнать источники боли у коллег, для которых исследуемый код ближе.
-
Плюсы:
он, несомненно, проще (привет, KISS);
можно узнать не только о проблемах, но и их отношении к этому.
-
Минусы:
ответы будут субъективны;
они будут касаться лишь тех областей кода, с которыми конкретный человек недавно работал;
есть риск вскрыть нарыв, тем самым обрекая себя на исповедь (а по ситуации и отповедь), что может быть затратно по времени;
повторная операция потребует столько же времени.
А можно взять принятое в сообществе бесплатное решение, натравить его на код и посмотреть на результаты анализа.
-
Плюсы
будет получен более-менее объективный анализ;
мы никого не будем отвлекать;
такой прогон можно повторить по результатам сделанных исправлений почти бесплатно (привет DRY).
-
Минусы
порог вхождения выше — надо с чем-то разбираться;
понимание результата весьма смутное в самом начале пути — нет понимания, окупится ли вложенное время;
если не особо вкладываться в настройку правил анализа, будет подсвечено много нерелевантного.
Я прошёл вариант с опросом, но параллельно решил и прогнать что-то стороннее для большей объективности своих будущих запросов на исправление.
(спасибо всем, кто дочитал до этого места)

Итак, в этой статье я постараюсь исправить два первых минуса, а именно:
предоставить читателю готовую пошаговую инструкцию настройки SonarQube в контейнерах Docker Desktop;
сформировать у заинтересованных ожидания от конечного результата.
Поставленная Цель. Быстро и без последствий для локального ноутбука иметь возможность прогнать дефолтные правила одного из популярных сканеров кодовой базы.
Дисклеймер. В этой статье не будет ничего про настройки интеграции сканера в пайплайны CI/CD.

Собственно, как я спойлернул выше, решение было выбрано следующее: локально развёрнутый на Windows-ноутбуке Docker Desktop с wsl + SonarQube.
Наскоро пробежав глазами документацию c Docker Hub-а, находим требования к хосту.
Открываем консоль PowerShell, выполняем подключение к терминалу docker-desktop:
wsl -d docker-desktopВводим рекомендованные в настроечные команды (если коротко, мы делаем это потому, что elasticsearch под капотом требует ресурсов больше, чем выделено по умолчанию):
sysctl -w vm.max_map_count=524288
sysctl -w fs.file-max=131072
ulimit -n 131072
ulimit -u 8192(последняя команда вызвала у меня ошибку ‘unknown argument u’, однако, на финальный результат это не повлияло)
После настройки хоста готовим файлик sonar.yaml, очень похожий на рекомендуемый на странице вендора:
version: "3.8"
services:
sonarqube:
image: sonarqube:community
ports:
- "9000:9000"
- "9092:9092"
depends_on:
- db
environment:
SONAR_JDBC_URL: jdbc:postgresql://db:5432/sonar
SONAR_JDBC_USERNAME: sonar
SONAR_JDBC_PASSWORD: sonar
volumes:
- sonarqube_conf:/opt/sonarqube/conf
- sonarqube_data:/opt/sonarqube/data
- sonarqube_logs:/opt/sonarqube/logs
- sonarqube_extensions:/opt/sonarqube/extensions
- sonarqube_bundled-plugins:/opt/sonarqube/lib/bundled-plugins
networks:
sonar_network:
db:
image: postgres:12
ports:
- "5432:5432"
command: postgres -c 'max_connections=300'
volumes:
- postgresql:/var/lib/postgresql
- postgresql_data:/var/lib/postgresql/data
environment:
POSTGRES_DB: sonar
POSTGRES_USER: sonar
POSTGRES_PASSWORD: sonar
networks:
sonar_network:
restart: unless-stopped
volumes:
sonarqube_conf:
sonarqube_data:
sonarqube_logs:
sonarqube_extensions:
sonarqube_bundled-plugins:
postgresql:
postgresql_data:
networks:
sonar_network:Запускаем контейнеры командой:
docker-compose -f sonar.yml -p sonar up -dЕсли всё сделали правильно, у нас стартуют оба контейнера и мы получаем доступ к панели администратора SonarQube по адресу http://localhost:9000/.

Первым делом нас просят сменить пароль на что-то более безопасное.
Затем мы попадаем на страницу создания нового проекта. Нам предлагается выбор источников исходного кода, я выбрал "From GitLab" (ещё один дисклеймер: я шёл по шагам "мастера" добавления нового проекта, и поскольку у меня есть доступ к GitLab, я решил воспользоваться именно этим пунктом. Однако, забегая вперёд и учитывая, что весь код в итоге скачивался, собирался и анализировался локально, я не уверен, что нужно было идти именно таким путём).
Итак, я выбрал From GitLab.
Для автоматического подтягивания списка репозиториев потребуется токен доступа к GitLab. Идём в GitLab > User Settings > Access Tokens и создаём новый токен со скоупом api. Не забыв скопировать токен в буфер обмена, возвращаемся в админку SonarQube и вводим её в соответствующее поле. Получаем список репозиториев, выбираем:

Определившись с репозиторием, выбираем — как мы будем проводить анализ?
Нам представлено несколько вариантов интеграции, однако мы идём по локальному пути — жмём Locally, расположенный внизу особняком:

Далее требуется ввести существующий или выбрать генерацию нового токена на сканирование выбранного репозитория:
Важно! Сканирование любого Git-репозитория с этим токеном будет автоматически привязано к данному репозиторию в SonarQube, поэтому переиспользовать эти токены сканирования желательно только в рамках одной репы.
Генерируем, получаем что-то вроде sqp_d42feed11ed20248464f8ceb22897aec19533212.
Жмём Continue.
Далее выбираем — на что больше всего похож наш билд? В моём случае это .net core приложение, так что жмём .NET и .NET Core:

Получаем список из четырёх команд для последовательного запуска в папке с репозиторием (в моём случае, solution-файл лежал на один уровень глубже, так что открываем PowerShell и проваливаемся до папки с solution-файлом, не забыв перед сканированием обновить локальный репозиторий посредством git pull).
Копируем со странички в окно PowerShell-консоли и выполняем одну за другой 4 команды:
dotnet tool install --global dotnet-sonarscanner
dotnet sonarscanner begin /k:"common_identity_ABzn02OgsqQ2PsdJYMkV" /d:sonar.host.url="http://localhost:9000" /d:sonar.login="sqp_d42feed11ed20248464f8ceb22897aec19533212"
dotnet build
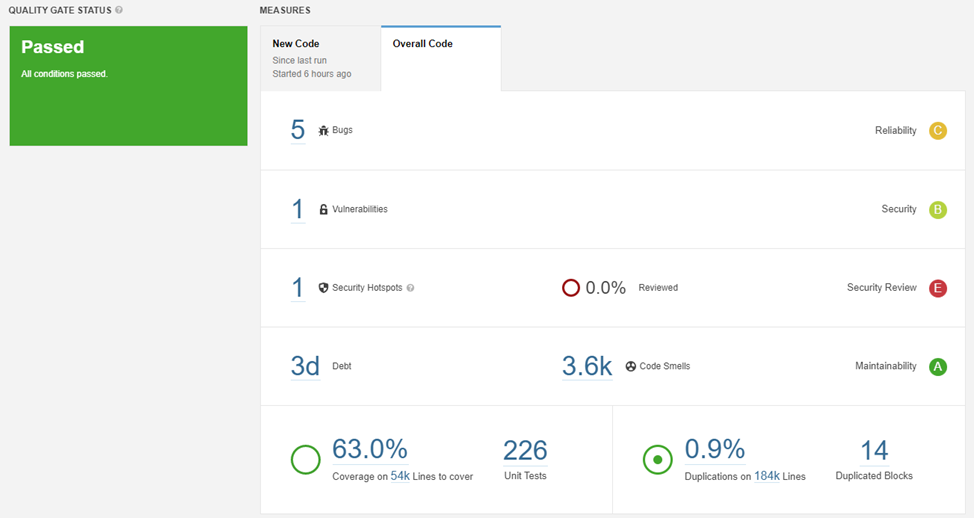
dotnet sonarscanner end /d:sonar.login="sqp_d42feed11ed20248464f8ceb22897aec19533212"Последняя команда может работать минуты на большом количестве кода. После завершения обновляем окно проекта в SonarQube и видим красивый интерактивный отчёт.

Сразу становится понятен общий уровень кода и на что нужно обратить внимание в ближайшем спринте.
Получаем, кстати, не только подсвеченные области, вызывающие вопросы, как, например, вот это использование всеми любимого класса Random():
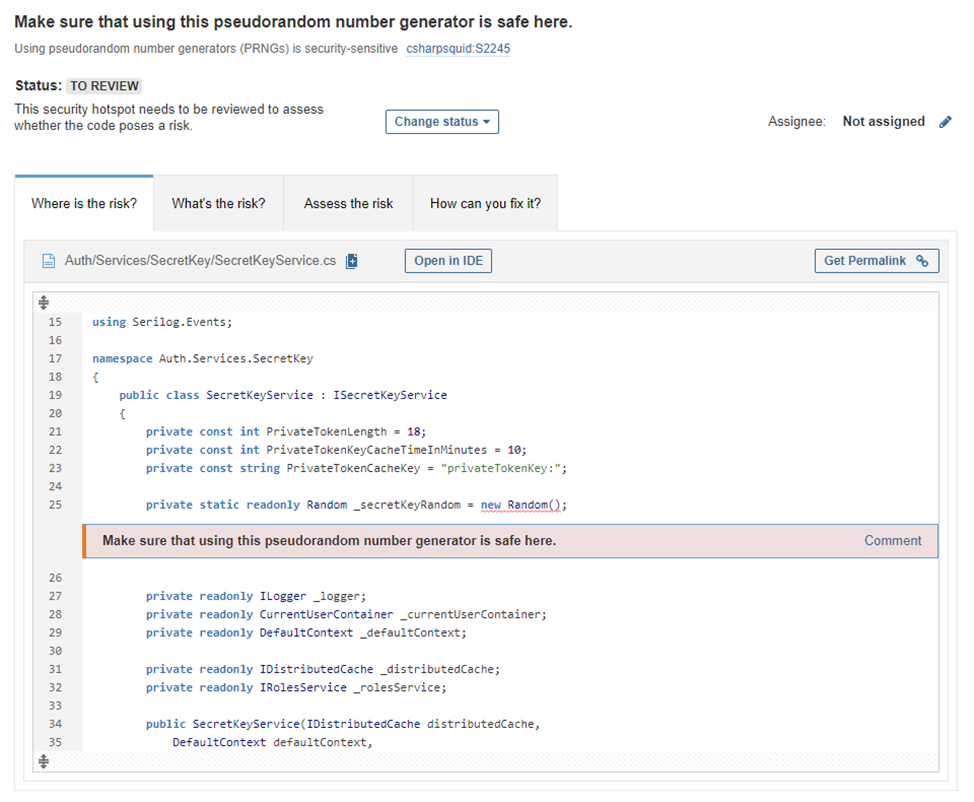
Бонусом идут готовые варианты решения (нужно перейти на вкладку «How can you fix it?»:
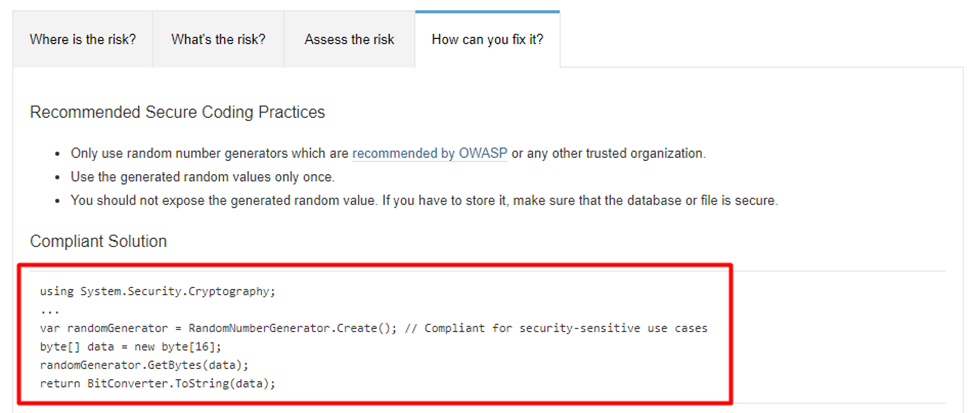
Можно идти фиксить самому или превращать в прекрасно описанные задачи.

Спасибо за внимание!
Комментарии (5)

Ndochp
17.06.2022 17:44+1ИМХО подход наивный. У меня проект перед глазами проект на 6кк строк кода.
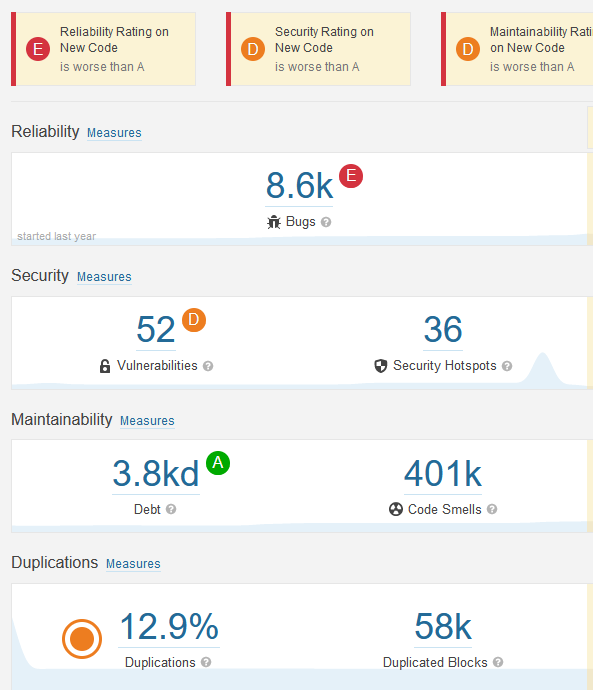
Большинство старых ошибок не стреляют. Брать их во внимание при планировании следующего спринта — прекратить разработку. Сонар раскрывается при регулярном анализе. Вот ошибка в новом коде — это потенциальная беда, так как у пользователей еще не было шансов сообщить, что она приводит к проблеме.
К счастью, окошко/фильтр "новый код" в сонаре есть. Хотя просмотреть отдельные совсем жесткие правила в которых почти не бывает ФП и они череваты серьезными травмами (типа итератор не используется в цикле, или какая еще жесть бывает в языке, на котором написан проект) при начале работы на новом проекте стоит.
golyakoff Автор
17.06.2022 18:31Спасибо, действительно, мысль очень правильная — в приоритете править новые ошибки; ведь те, что посажены давно, возможно, уже даже в глазах пользователей нашли привыкание (разумеется, это — грустно). Но, как Вы правильно заметили, на это в SonarQube есть инкрементальный отчёт.
Мне же было полезно пробежать "глазами" весь репозиторий на предмет поиска критических с точки зрения безопасности замечаний, понять актуальное состояние и пофиксить особенно пугающие проблемы перед тем, как пытаться проходить внешние тесты на безопасность (и получать соответствующие лицензии).

andToxa
что-то делали для анализа покрытия кода тестами?
анализ показывает отсутствие тестов, хотя они в проекте присутствуют.
andToxa
сам нашел ответ:
golyakoff Автор
Огонь, спасибо большое!