
Может ли студент второго курса написать JIT-компилятор Питона, конкурирующий по производительности с промышленным решением? С учётом того, что он это сделает за две недели за зачёт по программированию.
Как оказалось, может, но с нюансами.
Предисловие
Обучаясь в РТУ МИРЭА, на специальности "Программная инженерия" я попал на семестровый курс программирования на Питоне. Питон я знал до этого, поэтому не хотелось много с ним возиться. Благо творчество студентов поощряется, иногда даже "автоматами". Собственно, стимулируемый этим "автоматом" и тягой к написанию системных модулей я написал JIT-компилятор, который назвал MetaStruct.
С кодом проекта можно ознакомиться в репозитории.
Предыдущий мой опыт в написании низкоуровневых программ оказался нежизнеспособным и весьма поучительным. Но об этом сегодня речь не пойдёт.
Стандартная реализация Python - CPython - достаточно медленная. В сравнении с C++ называют замедление в 20-30 раз. Но целое сообщество программистов на Питоне готовы заплатить эту цену ради удобства синтаксиса, быстроты написания, изящности и выразительности кода.
На этой почве появляются разнообразные способы оптимизации выполнения программ на Питоне. Такие диалекты как Cython и RPython пытаются решить проблему "разгона" Питона за счёт статической типизации и компиляции модулей.
В области JIT-компиляции промышленным решением является проект Numba, спонсируемый такими технологическими гигантами как Intel, AMD и NVIDIA. Именно с этим пакетом мне предложили и посоревноваться, написав миниатюрный JIT-компилятор программ на Питоне.
В этой статье я хочу рассказать, с какими трудностями я, как программист достаточно прикладной, столкнулся при написании такой довольно низкоуровневой вещи, как миниатюрный JIT-компилятор.
Принцип работы

На схеме выше показано, какие этапы проходит функция на Питоне, становясь скомпилированным модулем на С++:
Функция, которую мы хотим оптимизировать, помечается аннотацией
@jit, примерно так:
@jit
def sum(x: int, y: int) -> int:
res: int = x + y
return resАннотация, получая объект функции, с помощью
inspect.getsource(func_object)получает текст функции в виде строки.С помощью функции
ast.parse(func_py_text)текст функции превращается в абстрактное синтаксическое дерево (AST) языка ПитонМоя программа проходится по дереву через метод
visit(), наследуясь отast.NodeVisitor, и получает на выходе текст программы на C++, который записывается в файл. Для примера выше, он будет примерно таким:
extern "C" int sum(int x, int y) {
int res = (x + y);
return res;
}Через
subprocess.run()происходит вызов компилятора g++, который выдаёт динамически подключаемую библиотеку (в зависимости от платформы файлом.dllили.so)
g++ -O2 -c source.cpp -o object.o
g++ -shared object.o -o lib.dllПри помощи вызова
ctypes.LibraryLoader(CDLL).LoadLibrary(dll_filename)Динамическая библиотека подключается к среде выполнения и даёт доступ к скомпилированному варианту исходной функции.Конечный пользователь, добавивший над функцией аннотацию
@jit, пользуется совершенно другим вариантом своего кода, ничего не подозревая.
Процесс достаточно трудоёмкий для функции сложения из примера, но при частых вызовах и большом количестве вычислений внутри функции время компиляции окупается.
Если бы это был не Питон, а какой-нибудь предметно-ориентированный язык, то пришлось бы писать парсер и обход получившегося абстрактного дерева, и решение не было бы уже таким коротким. Но в моём случае, инфраструктура Питона и его гибкость сыграли мне на руку.
Впечатляющие результаты
Наверное, стоит от технической части переходить к части визуализации и маркетинга.
Созданный алгоритм JIT-компиляции был протестирован на нескольких простых алгоритмических задачах:
Сумма двух чисел.
Хеш-функция для целых чисел.
Вычисление экспоненты через ряд Тейлора.
Числа Фибоначчи.
С расчётами и графиками можно подробнее ознакомиться в
Jupyter-блокноте
Для оценки времени выполнения использованы функции timeit() и repeat() модуля timeit. Для отрисовки графиков - модуль matplotlib
В примерах будут сравниваться четыре реализации функций:
Просто функции питона.
Оптимизированные аннотацией
@jit.Оптимизированные аннотацией
@numba.jit.Запущенные на интерпретаторе PyPy
Примечание: Я добавил к рассмотрению PyPy по просьбе одного из читателей. И этот метод оптимизации Питона действительно иногда является очень эффективным, что подтверждают графики ниже. Но при его использовании есть много нюансов.
Первый, это совершенно другая среда запуска, количество поддерживаемых библиотек которой значительно меньше, встроить в большой проект с уймой сторонних модулей просто так не получится.
Второй, версии PyPy выходят позже версий самого Питона. На момент написания статьи в PyPy не было конструкции match/case, поэтому пришлось использовать более простую и длинную реализацию обхода дерева.
Поэтому я призываю не сильно разочаровываться в jit-компиляторах, которые в отличие от PyPy не зависят от конкретной версии Питона и списка библиотек вашего проекта.
Сумма двух чисел

def py_sum(x: int, y: int) -> int:
res: int = x + y
return resНа задаче сложения двух целых чисел никакой оптимизации не видно, даже наоборот. Накладные расходы на вызов функции из dll-файла и обработка результата занимает много времени по сравнению с самими расчётами. Numba обставила моего "питомца" в 3 раза на этом примере.
Модуль PyPy отработал в 30 раз (0.003 секунды против 0.1 секунды) быстрее, чем CPython.
Хеш-функция для целых чисел

Обычно, для чисел из небольшого диапазона в качестве хеша используют их самих. Однако на просторах Интернета я нашёл такую хеш-функцию:
def py_hash(x: int) -> int:
x = ((x >> 16) ^ x) * 0x45d9f3b
x = ((x >> 16) ^ x) * 0x45d9f3b
x = (x >> 16) ^ x
return xАвтором сообщения утверждается, что значение параметра 0x45d9f3b позволяет достичь наибольшей "случайности" бит внутри числа. По крайней мере, для хеш-функций такого вида.
Numba оказалась хорошо оптимизированной под битовые операции. Не совсем понятно, откуда она взялась. Оставим этот вопрос открытым, но мне кажется, спонсорство главных производителей процессоров и видеокарт не прошло даром. Мой же вариант оказался слегка быстрее простого Питона, и то не всегда.
PyPy и тут обставил оптимизаторы, выполнив прогоны за 0.002 секунды, то есть в 100 раз быстрее, чем Numba.
Вычисление экспоненты через ряд Тейлора

Странное большое время для маленького x, выяснилось, обосновано тем, что Numba делает какие-то отложенные шаги компиляции при первом запуске. На общей её производительности это почти никак не сказывается (на втором графике с методами оптимизации аномалия исчезла, потому что был произведён повторный прогон).
Питон явно показал себя неважно, поэтому посмотрим на двух оптимизаторов и PyPy отдельно.

def py_exp(x: float) -> float:
res: float = 0
threshold: float = 1e-30
delta: float = 1
elements: int = 0
while delta > threshold:
elements = elements + 1
delta = delta * x / elements
while elements >= 0:
res += delta
delta = delta * elements / x
elements -= 1
return resКому интересен матан, экспонента считается по формуле соответствующего ряда Тейлора:
Алгоритм прекращается, когда разница между дельтами двух итераций становится меньше порога, либо превращается в машинный ноль. Суммирование происходит от меньших членов к большим для уменьшения потерь точности.
Наконец-то моё творение начало соперничать с Numba. На больших объёмах вычислений однозначного лидера нет. PyPy уже потерял преимущество в два порядка и выполняется с такой же скоростью, как и jit-оптимизаторы.
Числа Фибоначчи

def fib(n: int) -> int:
if n < 2:
return 1
return fib(n - 1) + fib(n - 2)Несмотря на то, что аннотация позволяет компилировать функции по одной, в ней всё ещё можно использовать рекурсию.
На рекурсии Питон вообще перестал за себя отвечать. Что там с оптимизаторами?

Внезапно, реализованная в проекте компиляция начала работать в 4 раза быстрее, чем Numba и в 8 раз быстрее PyPy. Получается, что с задачами разветвлённой рекурсии мой JIT-компилятор неплохо справляется.
Это одно из самых интересных мест всего исследования, которое можно было бы продолжить.
Мысли сходятся
На самом деле, такой подход к оптимизации не нов в мире программирования. Чем-то похожим занимался Владимир Макаров, оптимизируя Ruby до уровня языка передачи регистров RTL в своём проекте MJIT.
Существуют даже оптимизации сделанные поверх решения Макарова, о которых можно почитать здесь.
В частности, в исследованиях отмечается, что выбор компилятора, будь то GCC или LLVM, существенно не сказывается на производительности. В моём решении использован g++ из-за большей портируемости скомпилированного кода.
Для ускорения вычислений в проекте Ruby используются также предкомплированные заголовки. Однако, для студенческой работы такой уровень оптимизации не требуется.
Непредвиденные трудности
Конечно же, всё заработало не с первого раза. Вероятно, даже не с десятого. Поэтому хотелось бы привести здесь небольшую "работу над ошибками"
Типы данных
Питон медленный во многом из-за динамической типизации, так как довольно много времени уходит на определение типа переменной перед её использованием. Также, идеология "всё есть объект" раздувает примитивные типы данных до размера остальных объектов и классов. Чтобы ускорить вычисления, нужно использовать именно примитивы, а не объекты.
Проблема в том, что из кода на Питоне не всегда очевидно, какого типа будет переменная. Продвинутые оптимизаторы умеют определять тип переменной "на лету" из контекста. Я решил не усложнять жизнь , а усложнить код, и использовать аннотации типов.
Про использование аннотаций типов есть хорошие статьи в официальной документации или на Хабре.
Пусть нужно скомпилировать ту самую функцию сложения:
def sum(x, y):
res = x + y
return resКакой-нибудь компилируемый язык, C++ например, за такую программу спасибо не скажет. Добавим аннотации:
def sum(x: int, y: int) -> int:
res: int = x + y
return resВ этом примере явного объявления типов требуют три вещи:
Аргументов функции.
Возвращаемое из функции значение.
Локальные переменные.
В базовой реализации будет только три типа данных:
Тип данных Python |
Тип данных C++ |
|---|---|
bool |
bool |
int |
int |
float |
double |
Использование более сложных типов данных выходит за задачу миниатюрности компилятора. Но стоит отметить, что строки, коллекции и объекты Питона могут быть поддержаны с использованием Python C API
Кодирование имён функций
С++ видоизменяет названия функций согласно их сигнатуре и аргументам. Например, функцию int f(int x) компилятор может преобразовать в _Z1fi. Подробнее о соглашении именования функции при компиляции можно узнать, например, здесь
После переименования к функциям уже нельзя обратиться по первоначальному названию. Конечно, можно было бы написать свой алгоритм, который делает те же преобразования, что и компилятор. Но на самом деле, существует более простое решение, к которому мне пришлось в итоге прийти.
При добавлении к объявлению функции префикса extend "C" имена не будут кодироваться:
extern "C" int sum(int x, int y) {
int res = (x + y);
return res;
}Так происходит, потому что мы явно указываем, что имена функций должны кодироваться по соглашению языка C, то есть, никак.
Запуск DLL
Как программисту, плохо знакомому с чем-то ниже C++, мне было трудно понять, как подключить собранную dll-библиотеку к Питону. Изначально была идея использовать rundll32.exe для запуска. Почитав Википедию и ещё одно обсуждение, я немного разочаровался в прикладной применимости и портируемости этого решения.
Потом я нашёл статью с говорящим названием: What’s the guidance on when to use rundll32? Easy: Don’t use it
Только после этого я был направлен на путь истинный, а точнее, на использование модуля ctypes. В этот момент мои скомпилированные функции впервые начали возвращать мне значения прямо в Питоне.
Вызов функции из DLL
Всё шло гладко, пока я оперировал целыми числами. При попытке считать дробные... возвращались целые очень странного формата.
# просто питон
print(exp(0.1))
# >>> 1.1051709180756475
# моё чудо
print(jit_exp(0.1))
# >>> -1285947181Как оказалось, по умолчанию, все функции, импортируемые из dll работают с аргументами как с int и возвращают тоже int. Тут до меня дошло, что возвращать просто строку программы на C++ из транслятора недостаточно. Из функций необходимо ещё получить сигнатуру, чтобы потом применить нужные типы из модуля ctypes. Метод посещения объявления функции начал выглядеть вот так:
def visit_FunctionDef(self, node: FunctionDef) -> Tuple[str, dict]:
ret_type = self.visit(node.returns)
name = node.name
args, args_signature = [], []
for arg in node.args.args:
arg, arg_type = self.visit(arg)
args.append(f"{arg_type} {arg}")
args_signature.append(ctype_convert(arg_type))
args = ", ".join(args)
res = f"extern \"C\" {ret_type} {name}({args}) {{\n"
res += self.dump_body(node.body) + "}"
signature = {
"argtypes": args_signature,
"restype": ctype_convert(ret_type)
}
return res, signatureПоявился метод встраивания этих типов в сигнатуру dll:
def jit(func: Callable) -> Callable:
exec_module, signatures = compile_dll(func)
name = func.__name__
jit_func = exec_module[name]
jit_func.argtypes = signatures[name]["argtypes"]
jit_func.restype = signatures[name]["restype"]
return jit_funcДля того чтобы функции вызывались так же хорошо, как с целыми числами, достаточно было поменять у функций внутри загруженного dll атрибуты argtypes и restype. Сами типы для подстановки были взяты из модуля ctypes:
def ctype_convert(type_str: str):
match type_str:
case "int":
return ctypes.c_int
case "double":
return ctypes.c_double
case "bool":
return ctypes.c_bool
case _:
raise Exception(f"unsupported type str {type_str}")После всех этих накручиваний костылей махинаций ответ экспоненты начал совпадать с Питоном.
Подробнее про использование функций, загруженных из DLL, можно почитать в этой статье
Немного магии
Хороший код не пишется сразу. Например, в моём проекте основные блоки пришлось переписать два раза. В крупных проектах борьба с тех. долгом вообще может уходить в бесконечность, но я пока что, к сожалению или к счастью, с этим не сталкивался.
Я хотел показать на примере функции синтаксического разбора бинарной операции ast.BinOp как можно по-разному писать код, который будет в разной степени сложно поддерживать.
Словарь с типами
Это самая первая реализация:
def dump_bin_op(module: ast.BinOp) -> str:
res = ""
left = dump_expr(module.left)
right = dump_expr(module.right)
op = module.op
bin_op_signs = {
ast.Add: "+",
ast.Sub: "-",
ast.Div: "/",
ast.Mult: "*",
# и ещё 6-8 бинарных операций
}
op_sign = bin_op_signs[type(op)]
return f"({left} {op_sign} {right})"По сравнению с блоком if-elif-elif-elif-...-else такой код кажется проще. Но тут происходит явное обращение к типу через type(), что не очень хорошо.
Match/case
Тут мне посоветовали начать уже использовать плюшки версии Питона 3.10 на полную катушку, а именно, применить сравнение по шаблону и оператор match/case
def dump_bin_op(module: ast.BinOp) -> str:
match module:
case ast.BinOp(op=ast.Add()):
op_sign = "+"
case ast.BinOp(op=ast.Sub()):
op_sign = "-"
case ast.BinOp(op=ast.Div()):
op_sign = "/"
case ast.BinOp(op=ast.Mult()):
op_sign = "*"
# и ещё 6-8 бинарных операций
case _:
raise Exception(f"unsupported bin op type {op_type}")
left = dump_expr(module.left)
right = dump_expr(module.right)
return f"({left} {op_sign} {right})"Код стал чуточку короче и выразительнее. Шаблоны после слова case можно всячески усложнять, выбирая всё более специфичные случаи. Какой-нибудь switch/case в таких языках программирования как C++ или Java такого себе не может позволить. Подробнее про возможности оператора match/case можно узнать тут
Вот ещё маленький пример, решающий проблему занижения регистра для констант True и False:
def visit_Constant(self, node: Constant) -> str:
match node:
case Constant(value=True):
return "true"
case Constant(value=False):
return "false"
case _:
return str(node.value)Выглядит покрасивее, чем if node.value == True:. Но тут уже на вкус и цвет.
ast.NodeVisitor
Вот я и пришёл к тому, что давно написали за меня, но я об этом никогда не слышал, поэтому ещё не применил.
Как ни странно, модуль, описывающий абстрактное дерево в виде структуры, предоставляет также и методы для его обхода. Этот метод называется ast.NodeVisitor.visit()
Как следует из названия, NodeVisitor реализует шаблон проектирования Посетитель, позволяющий создавать новую внешнюю функциональность с минимальным изменением уже написанного кода.
Для написания своего посетителя необходимо объявить класс-наследник класса ast.NodeVisitor:
class DumpVisitor(ast.NodeVisitor):
...
def visit_BinOp(self, node: ast.BinOp) -> str:
return f"({self.visit(node.left)} {self.visit(node.op)} {self.visit(node.right)})"
def visit_Add(self, node: ast.Add) -> str:
return "+"
def visit_Sub(self, node: ast.Sub) -> str:
return "-"
def visit_Div(self, node: ast.Div) -> str:
return "/"
def visit_Mult(self, node: ast.Mult) -> str:
return "*"
# ещё 6-8 методов обхода бинарных операций
... # и не только
Код остальных методов посетителя можно изучить в репозитории.
Код стал более модульным, названия и сигнатуры методов уже придуманы за нас, выбор нужного метода происходит без нашего участия. Вот на этом варианте я и решил остановиться.
Во время написания кода на Питоне у меня возникает чувство ощущения красоты, краткости и мощи собственного кода. В этом есть какая-то магия.
Подсчёт строк
Дабы не потерять доверие читателя, я провёл подсчёт строк кода транслятора:
Код |
Объём |
|---|---|
Аннотация и процесс компиляции |
36 |
Транслятор на NodeVisitor |
221 |
Итого |
257 |
Остальные файлы, как оказалось, к процессу исполнения напрямую не причастны. Я даже не стал исключать того большого числа пустых строк, которого требует PEP8. Получается, что даже немного наврал читателю насчёт числа строк. Пусть он меня простит.
Думаю, такой небольшой проект можно было бы легко поддерживать, если бы в этом была бы необходимость.
Итог
Хочу сказать спасибо Петру Николаевичу Советову за наставничество при написании этого проекта и этой статьи. Как оказывается, писать статьи труднее, чем писать код в ящик.
Проекту в плане функциональности есть куда расти. Поддержка строк, коллекций, объектов, классов. Правда с учётом полученного зачёта, предлагаю энтузиастам, взяв моё решение за основу, добиться большей производительности и функциональности.
Предел у этого совершенства всё равно есть. На поддержке библиотек такие решения оптимизации обычно отказываются работать либо поддерживают самые популярные и базовые, такие как Numpy или PIL.
И всё же, если очень захотеть, можно заставить Питон работать быстрее, уничтожая один из извечных аргументов программистов на C++ и Java против использования Python.
Комментарии (26)

Z55
30.06.2022 05:57+8Невероятно круто, если это реально сделано студентом и за две недели!

hyberlet Автор
30.06.2022 11:43+5Спасибо. На самом деле, это примерное время разработки. У студентов рабочий день не нормированный, поэтому я руководствовался при подсчёте датами своих коммитов. Для предмета на зачёт больше времени не нашлось)



osmanpasha
30.06.2022 11:53+4Правильно ли я понимаю, что такие особенности питона, как автоувеличение размера целочисленных переменных или истинное деление не реализованы, что приведет к отличию в результатах?
И ещё вопрос - у вас везде упоминается C++, не С, а что конкретно от С++ вам пришлось использовать?
А так круто вышло.
hyberlet Автор
30.06.2022 12:29Автоувеличение, или длинная арифметика, действительно не были реализованы, но программисты на C++, как правило, обходятся без неё. Обычно тип данных определяется задачей. Например, число дней в году рациональнее было бы кодировать типом short. Чтобы не происходило переполнения типов, необходимо правильно выбрать тип на этапе проектирования.
C++ я выбрал с заделом на будущее, так как там присутствует готовое понятие класса. Также там реализованы некоторые коллекции - прямые аналоги коллекций Питона. Конкретно в моей реализации до их использования не дошло, но в большом проекте выбор C привёл бы к тех. долгу и реализации этих фичей (классы, коллекции) вручную.

hoefling
30.06.2022 11:57+1Напомнило https://github.com/mypyc/mypyc
hyberlet Автор
30.06.2022 12:34+1Мне кажется, по ссылке находится статический компилятор. Там используется другой подход - Ahead of time, который конкурирует с Just in time. Так как оба эти подхода до сих пор существуют, выделить однозначного лидера не получается.

KvanTTT
30.06.2022 14:52Было бы интересно сравнить результаты на какой-нибудь реально программе, думаю на ней результаты будут далеко не такими радужными.
hyberlet Автор
30.06.2022 15:03+1Согласен, что применимость jit-компиляции ограничена. Из моего исследования стало ясно, что она хорошо себя показывает на алгоритмах с глубоким перебором и вложенными циклами и на разветвлённой рекурсии. В остальных случаях применение под вопросом.
Для проверки эффективности на реальной программе проекту явно не хватает функционала, но аналогичные замеры можно провести, используя @numba.jit(nopython=False)
KvanTTT
30.06.2022 20:36У меня есть и практический интерес. Я работаю над проектом ANTLR, и у нас есть проблемы с производительностью Python. Я обнаружил, что в нем не сворачиваются константы, а такая оптимизация ускоряет код до 20 раз на синтетическом примере. Однако реальный код это ускоряет не более чем на 2% (тем не менее оптимизация все равно полезная, поскольку она значительно уменьшает размер исходников и удаляет широкие строки, которые неудобно смотреть в редакторе).

mixsture
30.06.2022 15:02+3Конечный пользователь, добавивший над функцией аннотацию jit, пользуется совершенно другим вариантом своего кода, ничего не подозревая.
зато, дойдя до отладки кода, он будет удивлен :)hyberlet Автор
30.06.2022 17:03+2Отладка стороннего модуля на другом языке - дело занятное :)
У меня был опыт работы с PyQt, где любая ошибка внутри самого Qt просто приводила к аварийному завершению программы без выяснения причин. Дебаг внутрь исходников не входил. Так что это проблема более глобальная, чем jit-компиляторы.
Функция print после каждой строчки в помощь

Helltraitor
30.06.2022 15:03+1Питон медленный во многом из-за динамической типизации, так как довольно много времени уходит на определение типа переменной перед её использованием.
Да ну? А я думал из-за того, что все в Python под капотом - хэшмапы c PyObject'ами, которые надо доставать и обрабатывать отдельно
Какой-нибудь
switch/caseв другом языке программирования такого себе не может позволить.Поосторожнее с выражениями, молодой человек. Существуют, как минимум, языки с ФП парадигмой. А если к более конкретным примерам, то вам стоит обратить внимание на
matchиз Rust (то, с чем я сам имею дело на регулярной основе).Статья интересная, но что будет, если в вашу функцию прокинуть не тот тип? Или вы не сделали (а я думаю, что нет) обертку над функцией, которая бы проверяла типы через
isinstance. К сожалению, такое иногда случаетсяhyberlet Автор
30.06.2022 20:08+1Я поправил текст статьи, под другими языками подразумевались только C++ и Java. Rust я не хотел обижать.
Про то, что все примитивы в Питоне обернуты в объект я попытался сказать в статье, но может недостаточно явно. Согласен, что это тоже замедляет работу Питона.
Проверки входных типов тоже не были реализованы, и их наличие упростило бы потенциальную отладку.

LibrarianOok
30.06.2022 23:01А нет ли желания погонять этот компилятор на рейтрейсере или реймаршере?

Keeper13
30.06.2022 16:54Что если сравнить производительность с PyPy?
hyberlet Автор
30.06.2022 23:53+2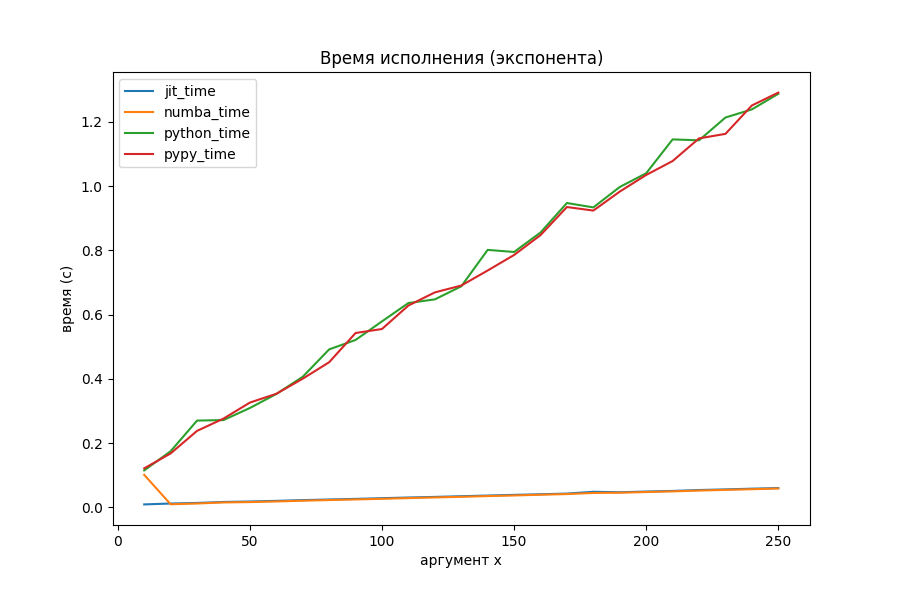
Я помучился с установкой PyPy (matplotlib не установился из-за Pillow, который не смог найти zlib, о чём я и писал в статье, но считать было можно) и вот что получил. Никакой значимой оптимизации PyPy не дал, поэтому я не хочу перегружать графики повторяющейся с Питоном линией.
Keeper13
01.07.2022 09:16Неожиданный результат. У меня в задачах типа "числодробилка" PyPy давал выигрыш раз в 5-10 по сравнению с CPython.
hyberlet Автор
01.07.2022 12:10Может быть, я просто что-то неправильно воспроизвёл. Но всё что я сделал, это поменял интерпретатор на PyPy и выполнил прогоны с теми начальными данными, записав результат в файл.
По небольшому опыту написания контестов, где предлагают на выбор Питон или PyPy, скажу, что зачастую PyPy может проигрывать Питону по памяти, а иногда и по времени. Наверное, это зависит от конкретной задачи.
Keeper13
01.07.2022 13:56У PyPy много времени уходит на собственно JIT-трансляцию перед выполнением полезных вычислений. Чем больше времени занимают собственно расчёты по сравнению с трансляцией, тем больший выигрыш даёт PyPy.
hyberlet Автор
01.07.2022 16:51Вы были правы, что PyPy ускоряет вычисления. Я добавил его рассмотрение в раздел с графиками. Теперь статья будет иметь большую ценность.
Стоило запустить код вне Jupyter-блокнота, как PyPy стал работать быстрее. Однако, на числах Фибоначчи он меня так и не перегнал.



kai3341
Очень годно. Меня гложет любопытство -- а что насчёт async/await? Что насчёт интеграций с другими сишными расширениями? Могу ли я
упоротьсязадекорировать какой-нибудь asyncpg?hyberlet Автор
Учитывая GIL в стандартной реализации Питона, перевод асинхронности в настоящую был бы очень уместен. Однако, готовых решений по реализации многопоточности с интерфейсом как в Питоне, насколько я знаю, в C++ нет. Async присутствует в стандарте C++20, но я не уверен, что это то, что нужно.
Любое сишное расширение может быть интегрировано в jit-компилятор, если имеет прямой аналог в Питоне, например, модуль cmath. В более сложных случаях поддержка модулей заключается в ручном переводе в сишные эквиваленты. Именно поэтому даже такие большие проекты, как RPython и PyPy не поддерживают всего разнообразия пакетов. Если в библиотеках встречаются вставки на других ЯП, то всё опять же усложняется, так как придётся делать целую цепочку вызовов динамических библиотек.
С оптимизацией библиотеки и так неплохо справляются, когда включают в себя модули на более производительных языках. Например Numpy содержит код на Фортране, потому что так быстрее. Ускорять Numpy с помощью jit не представляется необходимым.
В моём решении не реализовано преобразование объектов и структур данных, а без этого реализовывать многопоточность было бы проблематично. Заниматься преобразованием прикладных библиотек, таких как asyncpg, имеющих свойство менять API при каждой новой значительной версии, можно заниматься на свой страх и риск никогда не закончить.