
Извлечение информации означает создание структурированных данных из неструктурированного текста. На практике задача может выглядеть так: нужно автоматически создать запись в календаре исходя из текста письма, как на рисунке ниже.

Статьи Википедии, например, включают оба вида информации – окно со структурированным текстом справа и неструктурированный текст слева:

Используя техники извлечения информации, мы можем автоматически заполнить это окно необходимыми данными. При этом мы извлекаем из текста ограниченный объем его семантического содержимого. Можно рассматривать этот процесс как автоматическое заполнение опросника или шаблона (к примеру, таблицы базы данных).
Извлечение информации стало важной задачей обработки естественного языка еще в 90-е годы и сейчас делится на несколько актуальных подзадач:
Извлечение именованных сущностей (Named Entity Recognition, или NER).
Извлечение отношений.
Извлечение темпоральных выражений.
Разрешение кореференции.
Извлечение событий.
Заполнение слотов.
Связывание сущностей.
В этой статье мы рассмотрим первый пункт.
Извлечение именованных сущностей
Как правило, это имена собственные. Обычно выделяют три категории именованных сущностей – люди, места и организации, но в специализированных решениях часто рассматриваются и другие категории, такие как названия продуктов и произведений искусства. Также к именованным сущностям часто относят и численные выражения (цены, даты, время).
Вот пример расширенного списка:

Задача извлечения именованных сущностей сводится к выявлению отрезков текста, которые являются именами собственными, и их категоризации по типу сущности. Результаты решения можно в дальнейшем использовать для снижения разреженности данных при классификации текста, для выявления объекта в рамках анализа тональности и в вопросно-ответных системах.
Но вернемся к NER. Какие тут встречаются проблемы?
Первая – это неоднозначность сегментации. Например, является ли данное слово сущностью и, если да, то где границы этой сущности? Вот как здесь:

Вторая же проблема – неоднозначность типа сущности: к примеру, Georgia в английском – это имя или страна?
NER как задача разметки последовательностей
Стандартный подход к NER – использование пословной разметки последовательности слов. В этой задаче первый шаг – расставить метки по BIO-нотации: B-метка (beginning) проставляется для обозначения начала интересующей нас сущности, I (inside) – для обозначения слова внутри нее, а O (outside) – это любое слово за ее пределами. Вот предложение для примера:

А вот так выглядит разметка в нотации BIO:
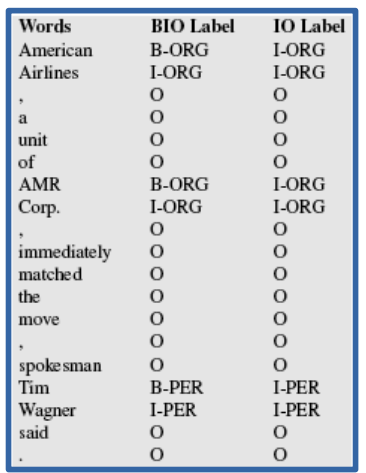
Такая нотация позволяет нам выделить в тексте границы именованных сущностей и их тип.
Модель, которая лучше всего справляется с задачей распознавания именованных сущностей, – Bi-LSTM. Это двунаправленная LSTM, которая сочетает в себе две нейронных сети, одна из которых работает справа налево, а вторая идет в обратном направлении – слева направо, захватывая таким образом весь контекст предложения.

В задаче распознавания именованных сущностей обучается модель MEMM (Maximum-Entropy Markov Model) или CRF (Conditional Random Field), которая определяет, является ли токен частью сущности или нет. Для присвоения меток этим токенам часто используются газетиры – многомиллионные готовые списки сущностей, такие как GeoNames или National Street Gazetteer (для Великобритании).
Оценка качества
Что касается оценки качества моделей, то тут используются стандартные метрики – точность, полнота и F-мера. Единицей для расчета этих метрик считается сущность, а не слово, то есть точность определяется как отношение количества правильно распознанных сущностей и количества распознанных сущностей, а полнота – как отношение правильно распознанных сущностей и количества сущностей в золотом стандарте. F-мера объединяет в себе две предыдущие метрики.
Из-за сегментации оценка качества модели осложняется, поскольку при обучении моделей мы используем слова, а для оценки – целые сущности. По этой причине если в нашем корпусе есть выражение Leamington Spa, а система определяет только Leamington – это уже ошибка.
Коммерческие системы распознавания сущностей
В научной работе обычно используются статистические модели для работы с последовательностями. Коммерческие же системы извлечения именованных сущностей часто гибридные и основаны на правилах и методах машинного обучения. Как правило, делается несколько проходов по тексту, и результаты первого прохода отражаются на следующем. Сначала для разметки однозначных сущностей в таких системах используются правила, обеспечивающие высокую точность, потом осуществляется поиск соответствий в части уже выявленных сущностей. Для идентификации прочих сущностей используются специальные списки из интересующей нас области и техники вероятностной разметки последовательностей, также использующие метки с предыдущих стадий.
philosoph
А можно скриншоты заменить на текст?..