
N-граммы
N-граммы – это статистические модели, которые предсказывают следующее слово после N-1 слов на основе вероятности их сочетания. Например, сочетание I want to в английском языке имеет высокую вероятностью, а want I to – низкую. Говоря простым языком, N-грамма – это последовательность n слов. Например, биграммы – это последовательности из двух слов (I want, want to, to, go, go to, to the…), триграммы – последовательности из трех слов (I want to, want to go, to go to…) и так далее.
Такие распределения вероятностей имеют широкое применение в машинном переводе, автоматической проверке орфографии, распознавании речи и умном вводе. Например, при распознавании речи, по сравнению с фразой eyes awe of an, последовательность I saw a van будет иметь большую вероятность. Во всех этих случаях мы подсчитываем вероятность следующего слова или последовательности слов. Такие подсчеты называются языковыми моделями.
Как же рассчитать P(w)? Например, вероятность предложения P(I, found, two, pounds, in, the, library). Для этого нам понадобится цепное правило, которое определяется так:

А если переменных больше, то вот так:
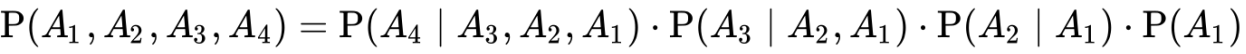
В общем виде правило выглядит следующим образом:
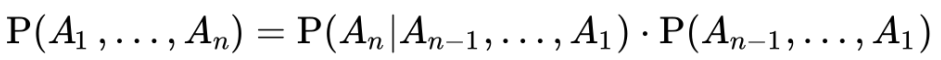
Вероятность нашего предложения будет рассчитываться так:

Таким образом, мы можем оценить совместную вероятность всей цепочки, перемножив условные вероятности. Однако мы не можем рассчитать точную вероятность слова при условии длинной последовательности предшествующих слов, как в этом примере:

Это потому, что возможных последовательностей очень много, а в наших данных просто может не оказаться этих выражений. Поэтому, вместо того, чтобы рассчитывать вероятность слова с учетом всех предшествующих слов, мы можем аппроксимировать вероятность, упростив ее. В этом заключается смысл цепей Маркова, с помощью которых мы можем предсказать вероятность элемента последовательности, не учитывая слишком широкий контекст.
Например, марковская модель первого порядка:

И марковская модель второго порядка:

Ведь мы встретим в наших данных the library или in the library с гораздо большей вероятностью, чем I found two pounds in the.
В общем виде марковская цепь k-ого порядка (когда мы учитываем контекст только последних k слов) будет выглядеть так:
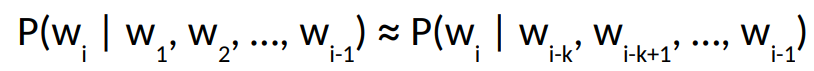
Допустим, у нас есть следующие предложения для обучения моделей:

Используя марковскую цепь первого порядка можно легко посчитать вероятность выражения you found:

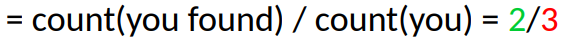
Таким образом мы можем рассчитывать биграммы, триграммы, квадрограммы и т.д., причем чем длиннее цепь, тем более детализированной является наша модель, т.е. более длинные предложения включают больше грамматики, чем короткие. В то же время, чем длиннее цепь, тем меньше у нас случаев употребления, а это значит что многие наблюдения будут попадаться всего один раз.
Стоит отметить, что языковые модели – не всегда идеальное решение. Возьмем, к примеру, следующее предложение:

В этом случае маловероятно, что approved относится к month, хоть они и расположены близко, и более вероятно – к request, однако n-граммы эту связь не обнаруживают.
Оценка вероятностей n-грамм
Самый простой и интуитивно понятный способ оценки вероятностей – это метод максимального правдоподобия (Maximum Likelihood Estimate, или MLE).

Вот пример расчета MLE:
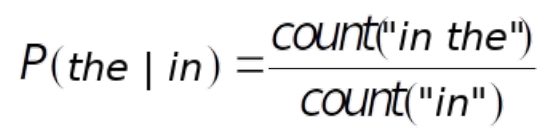
Воспользуемся для примера мини-корпусом из трех предложений:

Рассчитаем вероятности нескольких биграмм:
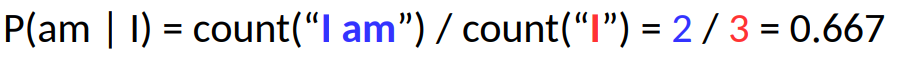


Примечательно, что, исходя из нашего маленького корпуса, получается, что после right всегда будет следовать now.
Возьмем больший корпус, состоящий из 9222 предложений. Ниже представлен образец подсчета биграмм, из которого видно, что, например, eat встречается после to 686 раз.
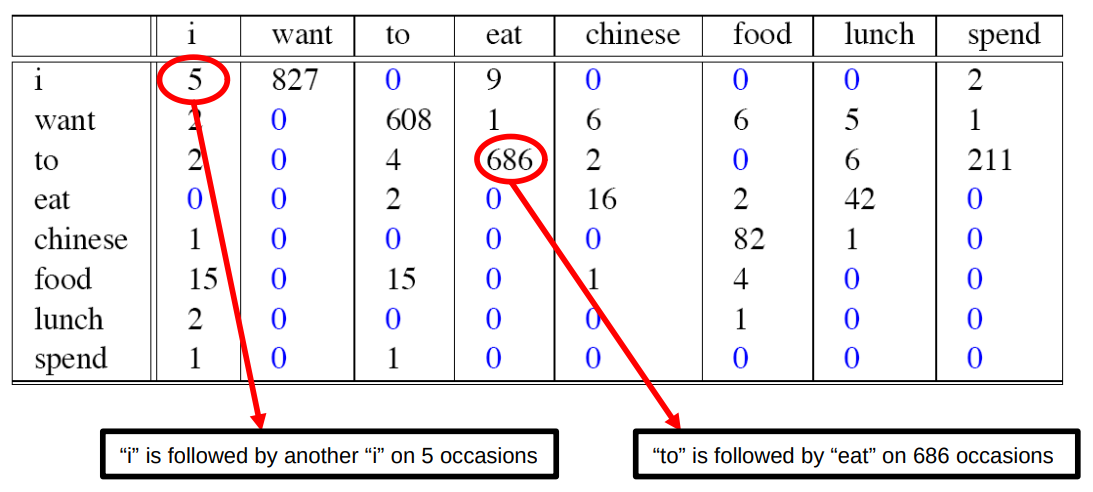
У нас также имеется информация о количестве употреблений каждого из этих слов:

Исходя из этих данных, можно подсчитать вероятности биграмм:

Чтобы рассчитать вероятность целого предложения, основываясь на информации о биграммах, нужно перемножить вероятности всех биграмм в предложении. Подсчитаем вероятность предложения I want to eat Chinese food:

Поскольку это значение крайне мало, мы можем столкнуться с проблемой потери значимости при операциях с плавающей точкой. Поэтому на практике используются логарифмы, при этом логарифм произведения равен сумме логарифмов:

В нашем случае подсчет будет выглядеть так:
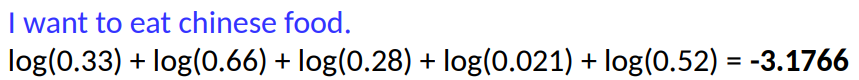
Для сравнения возьмем менее вероятное предложение:

Использование шкалы логарифмов приводит к появлению в наших расчетах отрицательных чисел, но наша основная задача – сделать так, чтобы эти числа были сопоставимы. На данных примерах сразу видно, что первое предложение гораздо более вероятно, чем второе.
Коллекции n-грамм
Самой полной коллекцией n-грамм на английском языке на данный момент является Google N-grams, содержащий частоты для более одного триллиона токенов. Данные собирались из текстов общедоступных веб-страниц. Несмотря на объем, у ресурса есть недостаток – цена в 150 долларов.

Но есть и бесплатная альтернатива, а именно Google Books N-grams – ресурс, созданный на основе наиболее полного корпуса англоязычных книг, собранного Google.
sinefag
А самой полной коллекцией n-грамм на русском языке на данный момент является Национальный корпус русского языка - https://ruscorpora.ru/