
В компании Tecforce мы уже более 15 лет занимаемся заказной разработкой и поставкой оборудования и подбираем для заказчика сервера под разрабатываемое нами ПО. Как оказалось, в сети мало информации на эту тему, поэтому заваривайте чай и добро пожаловать под кат. В статье расскажем о разработанной нами теории, предложим методику моделирования и построим математическую модель.

Наши заказчики - крупные государственные структуры, банки и международные холдинги. Для них характерны тендерные закупки и длительный процесс согласования, поэтому важно уметь рассчитывать прогнозную нагрузку на длительный период для разрабатываемой системы и выбирать под неё “железо”. Если кратко, в своем подходе мы имитируем нагрузку на систему и фиксируем предельные значения, при которых система замирает.
Поскольку все проекты под NDA, рассмотрим задачу на абстрактном примере.
Мы разрабатываем внутренний комплекс для сотрудников заказчика. Комплекс состоит из трёх систем:
Информационный портал;
Система трекинга времени;
Система совместной работы с документами.
Ниже представлена диаграмма компонент-комплекса.

На этапе анализа оценили параметры системы:
Планируется, что с системой будут работать 10 000 сотрудников предприятия.
-
Мы проанализировали своевременность заполнения таймшитов у нас и пришли к следующему распределению:
- 20% пользователей заполняют таймшиты каждый день,
- 30% - в конце недели,
- 50% - в конце месяца.
Заказчик согласовал эту модель. Мы предположили, что 5% пользователей раз в день оставляют 1 пост - суммарно выходит по 500 постов в день.
Получилось много предположений, которые влияют на конечный результат, поэтому:
Мы попробуем оценить какое влияние каждый из них вносит;
Максимально быстро постараемся проверить гипотезу.
Мы хотим рассчитать аппаратные требования под нефункциональные требования и рассмотрим эту задачу как если бы сервисы были развернуты на выделенных серверах. Если есть прослойка в виде гипервизора или контейнеризации, задача решается аналогично.
Разбираем теорию
Вероятность падения системы зависит от аппаратных и программных параметров. Наша задача - подобрать такие минимальные аппаратные параметры, чтобы при прогнозируемых программных параметрах система падала так редко, как этого хочет заказчик.
Аппаратные параметры
То, какие аппаратные параметры стоит учитывать в том или ином случае, зависит от архитектуры решения. Рассмотрим некоторые из них на нашем примере.
ЦПУ |
Частота ядер |
Часто этот параметр можно принять за константу: обычно выбор лежит в диапазоне 3,4-3,6 ГГц. Из-за небольшой разницы в цене можно взять для анализа процессоры с максимальной доступной частотой. В редких случаях приходится выбирать между целесообразностью использования 3 ГГц процессоров вместо более дешёвых 2 ГГц. |
Количество ядер |
В большинстве систем увеличение числа ядер пропорционально ведёт к увеличению числа параллельно обрабатываемых запросов и росту производительности. |
|
ОЗУ |
Частота |
Для серверных решений выбор частоты ОЗУ как правило зафиксирован на уровне 2666 МГц. Возможно, тактовая частота ОЗУ будет иметь критическое значение для определённого класса систем, но обычно это не так. |
Размер |
Мы будем учитывать размер ОЗУ, выделенный под сервис с учётом накладных расходов, а не всё ОЗУ системы. |
|
Настройки |
Кроме непосредственно выделенной под сервис памяти важно учитывать специфичные настройки распределения этой памяти в самом сервисе. Последние версии jvm как правило сами хорошо справляются с этой задачей, а вот для PostgreSQL мелкий тюнинг конфига может кардинально менять производительность. |
|
Диск |
Производительность |
Для большинства типовых систем достаточными параметрами при анализе производительности будут скорость чтения/записи. 2. Для файлового хранилища. |
Размер диска |
Важно не забывать про рост данных и уметь прогнозировать его. В нашем примере данные будут генерировать: Логи приложений. Их исключаем за счёт ротации. WAL лог СУБД. Файловое хранилище. |
|
Другие |
Выше описаны типовые параметры, актуальные для большинства систем, но в зависимости от решаемой задачи и способа решения могут появляться и иные параметры. Например, при создании системы работы с цифровыми контрактами может потребоваться анализ производительности GPU для вычисления хэшей. |
Программные параметры
Под программными параметрами будем понимать характеристики системы в реальном окружении.
Данные СУБД |
Количество строк в таблицах |
Связи между таблицами | |
Размер сложных структур в базе: json, xml, blob, т.п. | |
Пользовательская нагрузка |
Виды типовых сессий, если в системе есть активные пользователи с различными ролями |
Количество одновременных сессий | |
Продолжительность типовых сессий | |
Фоновые службы |
Одновременно работающие службы |
Продолжительность работы служб | |
Объём файлов на диске |
Составляем математическую модель целевой системы
Чтобы оценить аппаратные параметры, нам необходимо построить модель целевой системы и предположить программные параметры.
В нашем примере:
-
Данные в СУБД.
-
Количество строк в таблицах. Нам важно повторить структуру данных.
Самые крупные таблицы в примере - записи отработанных часов” и “посты на портале”.
Всего на текущий момент в компании 10 000 сотрудников.
В году порядка 250 рабочих дней.
Требуемая декомпозиция: задача занимает не больше 4 часов.
Дополнительно закладываем 50 % резерв на случай более мелкого дробления задач.
-
Получим 7,5 миллионов записей в год.
С постами сложнее, но аналогично будем отталкиваться от рабочих дней и предположим, что в среднем каждый двадцатый пишет 1 пост в день. Тогда получим 100 000 постов в год.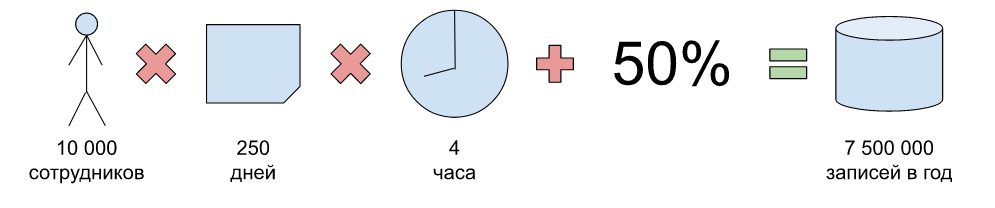
-
Связи между таблицами. Кроме количества данных в самих таблицах важно повторить статистику распределения связей между записями в таблицах.

Размер сложных структур в базе: json, xml, blob, т.п.
-
-
Пользовательская нагрузка
-
Виды типовых сессий, если в системе есть активные пользователи с различными ролями.
В нашем случае все пользователи оказались схожи по нагрузке, но мы разделили пользовательскую нагрузку на типовую и “конец месяца”. Конец месяца будет отличаться активной пиковой нагрузкой на сервис учёта рабочего времени.
Количество одновременных сессий. Одновременные сессии - это неравномерный график, но для оценки аппаратных требований нас интересуют именно пиковые значения.
Продолжительность типовых сессий.
-
-
Фоновые службы.
Одновременно работающие службы.
Продолжительность работы служб.
Объём неструктурированных данных на диске.
Делаем допущение роста данных
Нам необходимо оценить такой период, чтобы мы с требуемой вероятностью успели развернуть систему на новом оборудовании и переоценить следующий период, поэтому горизонт планирования будет включать в себя:
Два периода бюджетирования: необходимо быть уверенными, что мы не только успеем получить требуемое железо, но и оставить запас на следующую итерацию роста данных.
Время на развёртывание системы на новом железе: от заявки на закупку до запуска системы после миграции данных.
Время на проведение новых замеров для актуализации требований.
Риски, обеспечивающие требуемую вероятность успеть в срок.
Оценивать больший период нецелесообразно, имеет смысл итеративно уточнять и переоценивать модель после запуска системы, поскольку теоретическая модель данных может отличаться от реальной и со временем будет накапливаться ошибка.
Для различных систем и данных могут использоваться различные методы экстраполяции. В примере мы предположили линейный рост сотрудников на основе опыта предыдущих лет.
Описываем методику моделирования данных
Разрабатываем утилиту эмуляции данных
Теперь нам необходимо разработать утилиту, которая позволит генерировать все необходимые данные в верных пропорциях. Нам важно уметь генерировать некоторый процент от целевых данных. Это удобно для экономии аппаратных ресурсов. Но важно понимать, что чем меньший процент от целевых данных используется для оценки, тем выше погрешность. Также важно понимать наличие краевых эффектов.
Например, если взять вместо целевых 10 000 сотрудников лишь 10 %, есть вероятность, что на 1000 записей оптимизатор СУБД будет использовать full scan вместо индексов.
В своих экспериментах для генерации данных мы как правило используем метод Монте-Карло. Сначала мы просто пробовали копировать одинаковые записи из продакшен базы, но в итоге число записей оказывалось в таблицах сравнимо с продом, но вот структура связей получалась либо вырожденной, либо сильно кластеризованной.
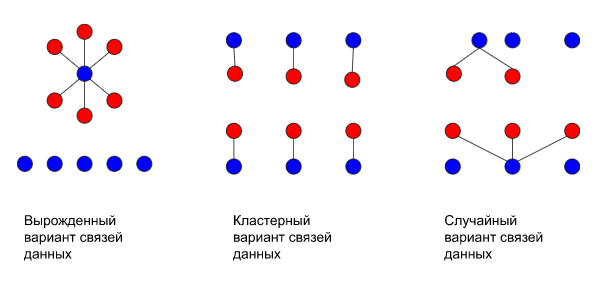
В итоге результат сильно отличался от реального и гипотеза роста данных не выдерживала проверки временем. Поэтому теперь мы случайным образом генерируем данные, и в процессе генерации данных мы измеряем количество связей на одну ссылаемую запись в таблице.
Пример: генерируя таблицы студенты и группы, мы считаем сколько студентов в одной группе.
Дальше мы получаем среднее и дисперсию такого распределения. ключевые показатели Если из-за вновь генерируемой записи показатели выходят за доверительный интервал, мы её исключаем и генерируем следующую.
Пример: продолжая тему, со студентами и группами, предположим мы выяснили, что в среднем в группе 25 студентов, а СКО равно 3. Групп для тестов необходимо 100, и соответственно 2500 студентов. Мы сразу генерируем необходимое число групп для тестов. А затем начинаем генерировать студентов случайным образом распределяя их по группам. Все студенты не попадут в таком случае в одну группу, поскольку массовое зачисление ухудшает СКО, хотя приближает среднее к целевому значению, поэтому таких студентов мы отбрасываем.
Оцениваем объём данных
В процессе тестирования нагрузки объём данных будет расти за счёт самих тестов, поэтому мы изначально наполним тестовую базу меньше чем на половину этого прироста. Таким образом в среднем объём данных во время испытаний будет целевым.
Мы оценили, что к концу года целевое значение будет 7,5 миллионов записей в таблице рабочего времени. Из них 625 000 записей будут соответствовать последнему месяцу. Поэтому для оценки ресурсов мы сгенерируем тестовую базу на 625 000 записей меньше, но при генерации нагрузки мы дважды последовательно повторим эксперимент с добавлением 625 000 записей.

Подбираем аппаратные средства
Для подбора аппаратных средств мы воспользуемся методом дихотомии. Но сначала хотя бы примерно оценим аппаратные требования, от которых будем отталкиваться. Есть два пути для оценки:
Теоретический. Оцениваем выделяемую память под хранение типовых данных на диске и в ОЗУ методом сложения выделяемой памяти под атомарные поля, и затем умножением на объём таких данных.
Стохастический. В процессе разработки у нас накопились тестовые данные, мы берём выделяемое под них место, делим на количество данных и примерно получаем вес одной записи. Затем умножаем на нецелевое количество записей и получаем общий объём. В случае ОЗУ замеры необходимо проводить на работающей системе. При этом справедливым остаётся правило “больше данных - меньше погрешность”.
Неважно каким путём мы оценили стартовые ресурс, в итоге получился теоретический набор виртуалок с определёнными характеристиками.
Добавляем процент на гипервизор или виртуализацию и получаем теоретические аппаратные ресурсы.
Hidden text
Можно проводить замеры, кратно уменьшая нагрузку и ресурсы, чтобы сэкономить на бюджете, но это влияет на точность итоговой оценки. Поэтому мы рекомендуем это делать только когда нужно сэкономить время, ведь генерация полного объёма данных может занимать сутки и не одни. Экономить на аренде аппаратных ресурсов дороже, чем исправлять потом ошибку из-за попадания в погрешность.
-
При проведении замеров мы анализируем целевые показатели системы.Обычно это время отклика на запрос, время выполнения типовых задач. Число пользователей при эмуляции нагрузки зависит от требований к системе. Как правило мы используем правило 3 сигм, и эмулируем нагрузку для среднего числа пользователей плюс 3 величины СКО. Все показатели системы имеют стандартные предельные значения или определяются заказчиком (например, открытие web-страницы с загрузкой всего содержимого не более 2 секунд).
Превышение любого показателя говорит о несоответствии требованиям и необходимости увеличения аппаратных ресурсов.
Простой ресурсов говорит о необходимости его урезать.
Чтобы проанализировать, нужно ли увеличивать ресурсы, в процессе выполнения тестов мы смотрим:
на нагрузку на ЦПУ;
на использование ОЗУ;
на дисковые операции чтения-записи.
Мы увеличиваем ресурсы, если их использование достигло пиковых значений - нагрузка 100% держится более 10 секунд. И уменьшаем ресурсы, если они не достигали 90% своего потенциала более чем на 3 секунды.
В случае с ОЗУ стоит смотреть более детальную утилизацию. Например, jvm, отбирает память у операционной системы, а обратно отдаёт неохотно, предпочитая самостоятельно её распределять.
Для выбора шага увеличения/уменьшения мы берём половину между последними избыточным и недостаточным результатом замеров, но не менее минимальной дискретности (для ЦПУ это 1 ядро, для ОЗУ 1 ГБ и т. п.). В качестве первоначального избыточного результата мы считаем теоретически рассчитанную границу, а первоначальное недостаточное - это нулевое значение ресурса.
Hidden text
Мы посчитали, что теоретически нам необходимо 32 ГБ ОЗУ. Начинаем замеры с 16 ГБ. Если этого оказалось мало, то берём 24 ГБ и т.д.
Бывает, что первоначальная теоретическая оценка была сделана с ошибкой и этих ресурсов оказалось недостаточно. В таком случае после перепроверки расчетов мы просто увеличиваем вдвое аппаратные ресурсы в надежде, что вот теперь хватит и заново проводим испытания. Повторяем пока тесты не завершатся успешно или не кончатся ресурсы провайдера.
Таким эмпирическим путём мы получаем минимальные аппаратные ресурсы с необходимой точностью для работы системы с заданными показателями качества для случая когда система уже разработана или близка к этому. О том как оценивать аппаратные средства на этапе проектирования мы расскажем отдельно.
Комментарии (4)

JordanCpp
21.07.2022 23:14Вы занимаетесь серверами на десктопном железе? Было бы интересно почитать, об этом сегменте.

Devd
21.07.2022 23:24Десктопное железо можно поставить в серверный корпус и даже с водяным охлаждением, но не будет встроенного ipkvm

kodla Автор
22.07.2022 10:17+1Нет, поскольку десктопное железо не гарантирует необходимый уровень надёжности. Но могу поделиться смешным опытом использования серверных дисков в десктопе: не стоит, будет шумно.
JordanCpp
Понятно, что рекламная статья. Но написано хорошо. Читать интересно. Спасибо.
Недавно 1С, выдала типа статью по импортозамещению продуктов на ее платформу. Но написана была настолько отвратительно, что ее нещадно заминусили и закрыли к ней доступ. Хотел вставить ссылку для сравнения.