
Наше подразделение Agima.ai занимается проектами в области машинного обучения и анализа данных. В аналитических проектах нам нравится, когда данные для отчетов доступны пользователям в режиме self-service аналитики (то есть, аналитики самообслуживания). В этом случае любой специалист может самостоятельно собрать себе нужный отчет в BI-инструменте, без использования SQL или другого кода.
Такой подход увеличивает доступность данных, скорость и качество выводов, которые бизнес-пользователи могут сделать по данным.
В этой статье расскажем, как подойти к задаче построения сквозной маркетинговой аналитики “с нуля” таким образом, чтобы:
данные были хорошо документированы;
в полученные отчеты было легко добавлять любые фильтры и разрезы: в том числе, по новым атрибутам пользователя, по сегментам АВ-тестирования, по языкам и т.п.
при необходимости систему могли легко взять на поддержку штатные аналитики.
Рассказ будем вести на примере одного из реализованных клиентских проектов.
Задача
Если коротко — построить сквозной отчет от клика пользователя по рекламному объявлению до покупки, оценить эффективность маркетинговых кампаний.
Если подробнее:
есть несколько рекламных кабинетов, из которых нужно собрать затраты на рекламные кампании: Facebook, Yandex.Direct, Google Adwords, Vkontakte. Также есть затраты на маркетинг, которые не проходят через рекламные кабинеты, а ведутся в ручном справочнике.
пользователи, которых привлекли с помощью рекламных кампаний, совершают покупку на сайте.
на сайте установлен Google Analytics, который фиксирует id пользователей, их utm-метки и покупки.
Задача кажется стандартной, но в клиентском проекте есть несколько нюансов в бизнес-логике, из-за которых стандартные решения не подошли:
Из-за особенностей маркетинговой стратегии нужно реализовать кастомную логику атрибуции и оценить каждый канал по двум моделям: кастомной и стандартной last click;
Есть ряд особенностей бизнес-логики, которые нужно учитывать при выстраивании связи маркетинговых каналов с покупками: например, языки пользователей;
На сайте проводятся АВ-тесты, поэтому хотелось, чтобы в будущем конверсии по рекламным каналам можно было смотреть в том числе в разрезе по сегменту тестирования, в который попал пользователь.
Как мы организовали процесс
Этап 1: Скачивание «сырых» данных
Для начала нам нужно получить набор данных для анализа.
В качестве хранилища данных мы используем BigQuery. Источников данных у нас девять.

Для загрузки данных используем open source стек Singer + Meltano. Для преобразования данных используем DBT.
Этап 2: Моделирование данных
Для проектирования модели предметной области используем минимальное моделирование. Это подход к моделированию данных, который позволяет одновременно разобраться в структуре данных и задокументировать ее.
В результате анализа выделяем в данных:
⚓️Анкеры (это основные существительные предметной области, например, ⚓️Пользователь, ⚓️Визит, ⚓️Рекламная кампания и т.п.).
Атрибуты (это характеристики анкеров, например, Имя пользователя, Дата визита, Название рекламной кампании).
????Линки (связи между двумя анкерами, например, “????⚓️Пользователь сделал ⚓️Заказ”).
Найденные анкеры, атрибуты и линки сразу же документируем в excel-файле, то есть описание финальных данных появляется раньше реализации.



Теперь собираем модель предметной области. Для сквозной аналитики она вполне понятна и выглядит так:

Моделирование кастомной атрибуции
Основным понятием (анкером) в системе является ⚓️Визит (visit) пользователя.
У ⚓️Визита есть два атрибута, которые содержат информацию о кастомной маркетинговой атрибуции:
номер визита (visit_number);
ценность визита (visit_value).
Как только ⚓️Визит приводит к ⚓️Транзакции, мы делим выручку от транзакции между всеми предшествующими визитами, начиная с первого и заканчивая последним.
Рассчитанная ценность сохраняется в атрибуте “ценность визита” (visit_value).
Для оценки эффективности маркетинга, кроме ценности визита (visit_value), нас еще интересует стоимость визита (visit_cost).
Стоимость визита — это стоимость клика для рекламной кампании, которая привела пользователя. Бывает, что стоимость одного визита складывается из стоимости нескольких кампаний. Например, из стоимости клика в рекламном кабинете и стоимости промокода, который пользователю дарят в результате рекламной кампании.
Этап 3: Реализация data API
На уровне физической реализации все анкеры, атрибуты и линки независимы друг от друга. Мы их собираем в виде отдельных таблиц в базе.
Такой подход сильно упрощает тестирование данных: мы видим полный граф трансформаций каждого атрибута, если замечаем ошибку в данных, можем проверить трансформации вплоть до сырых данных.


Реализованные в виде независимых таблиц анкеры, атрибуты и линки мы называем data api. По сути это интерфейс к данным заказчика, с которым могут работать BI-отчеты, ML-модели и другие дата-приложения.
Когда данные собраны, можно приступать к сбору витрины для конечных пользователей и отчетности.
Как работает модель данных, всё в сборе:
Этап 4: Сбор витрины для self-service аналитики
Для отчетности мы используем бесплатный инструмент с открытым исходным кодом Metabase.
Для подготовки витрины для self-service аналитики в Metabase собираем все данные, доступные в data api, в несколько связанных широких таблиц:
таймлайн со всеми событиями системы собираем из всех линков, которые мы нашли на этапе моделирования данных;
широкая таблица на каждый анкер, куда собираем все атрибуты анкера.

Связи между этими таблицами мы задаем прямо в Metabase.
Этап 5: Определение метрик
Данные и витрина собраны, остается посчитать по ним бизнес-метрики.
В модели данных Metabase можно задать словарь метрик, который будет доступен бизнес-пользователям при построении отчетов.
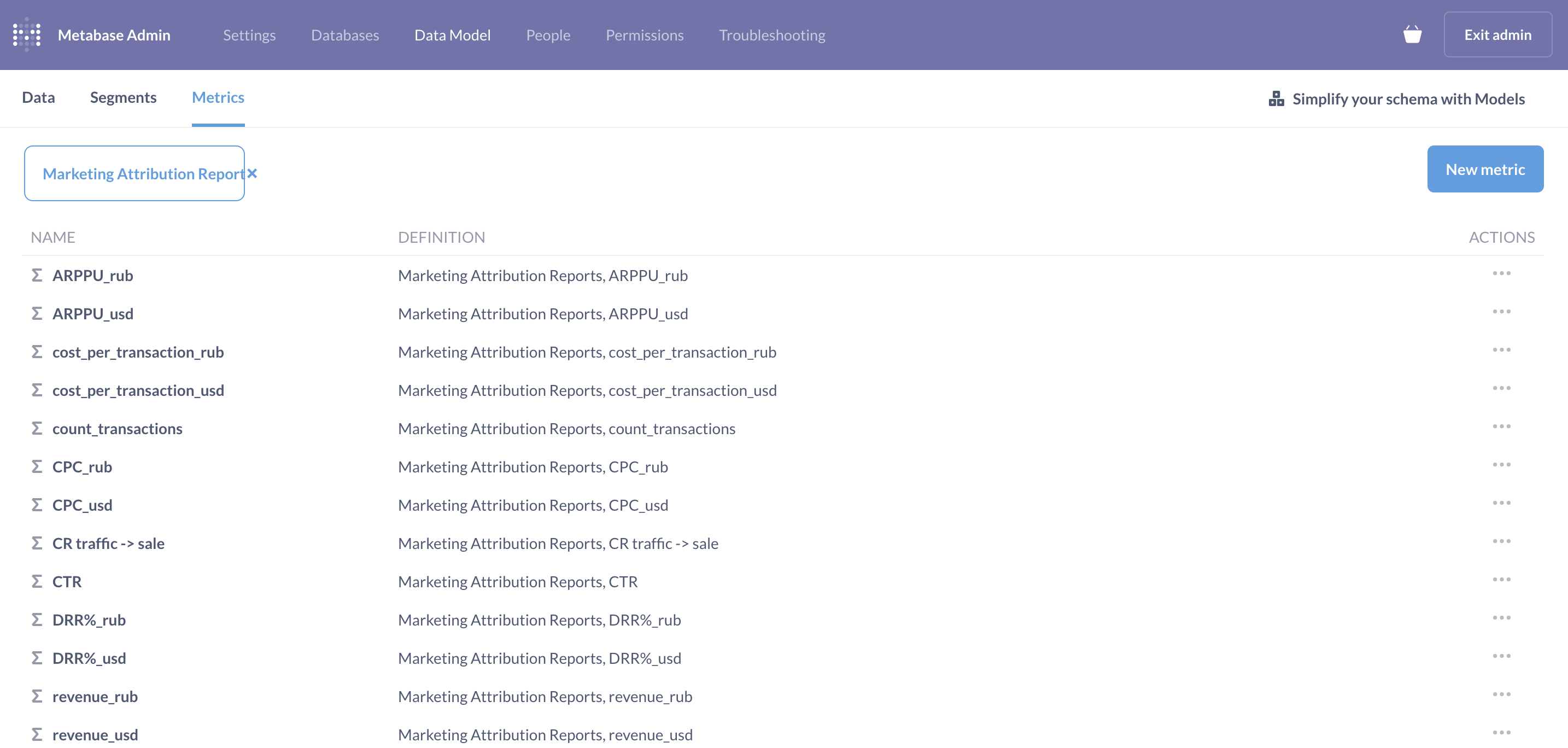
Добавление новых метрик не требует программирования и доступно всем пользователям Metabase.

Этап 6: Финальный отчет
Все данные собраны, метрики определены, приступаем к сборке финального отчета.
Мы это делаем без написания SQL, просто накликивая данные в Metabase.
Этап 7: Документация по проекту
Под конец проекта приводим в порядок документацию. Это просто, поскольку все данные мы описали в самом начале проекта — на этапе моделирования данных. Проверяем опечатки и возникшие расхождения при реализации.
На этом проекте мы дополнительно перенесли всю документацию в Notion (для красоты).

В процессе реализации проекта мы узнали много нового про устройство данных заказчика. Все наши находки описали в коротких заметках, которые делали в процессе разработки, их отдали заказчику вместе с результатами работы и документацией.

Таким образом, если заказчик подключит к работе собственных аналитиков, они легко разберутся в структуре данных и логике решения.
Выводы и следствия
В ходе проекта мы реализовали для заказчика отчетность по сквозной маркетинговой аналитике. Данные доступны бизнес-пользователям в режиме self-service аналитики (аналитики самообслуживания).
Благодаря использованию концепций минимального моделирования получили ряд важных следствий:
данные полностью документированы, актуальность документации поддерживается «по построению», для бизнес-пользователей данные доступны в режиме self-service аналитики;
благодаря независимой реализации каждого атрибута в отчеты легко добавлять дополнительные данные и разрезы (например, реализация альтернативной модели атрибуции — это добавление ровно одного атрибута);
аналитики, которые подключатся к проекту в будущем, смогут легко отследить логику трансформации данных и вносить изменения в проект.
ArtemKagukin
Отличный практический пример. Спасибо за статью. В какой программе строили графы (картинка с Этапа 3)?
Epoch8 Автор
https://arrows.app/ Вообще Arrows используется для визуализации labeled property graphs из домена графовых баз данных. Но выяснилось, что для визуализации моделей данных в терминах анкеров/атрибутов/линков тоже отлично подходит.
Epoch8 Автор
А, или речь идет о картинке с Lineage? Такие штуки рисует https://getdbt.com/