
Предисловие
Начнем повествование с приевшейся, шаблонной, клишированной фразы, мотивирующей сжатие нейронных сетей:
За последние несколько лет нейронные сети достигли значительных успехов в разнообразных приложениях и сферах человеческой (и нечеловеческой) деятельности, превосходя даже человека на ряде задач. Но мощь и гибкость, способность фитировать сложные зависимости, требуют значительных вычислительных ресурсов как на этапе обучения, так и на инференсе, что ограничивает зачастую применение нейронных сетей на мобильных устройствах и при наличии ограниченных вычислительных мощностей.
Поэтому по мере бурного прогресса и развития новых архитектур параллельно идет активная разработка разнообразных подходов по сжатию и повышению эффективности нейронных сетей
Прунинг (структурированный и неструктурированный) - ссылка на самого себя :)
Квантование (или если угодно квантизация).
Дистилляция (Knowledge distillation).
Низкоранговые приближения (применительно к весам и self-attention).
и много-много всякой всячины.
Какие-то из перечисленных подходов более эффективны в прикладных приложениях - типа квантования и дистилляции, теоретический выигрыш других (в количестве параметров и вычислений) же (неструктурированный прунинг) сложнее переносится на реальные устройства и вычислители. Разные методы можно комбинировать друг с другом.
Прунинг токенов
Архитектура Transformer, основанная на механизме внимания, благодаря своей универсальности была успешно применена во всех (или почти всех) сферах глубокого обучения. Входные данные, будь то текст, картинки, звук, или состояние среды, преобразуются в последовательность токенов, к которой последовательно применяются слои attention, учитывающие глобальный контекст и взаимосвязи токенов друг с другом, и feedforward слои, применяющие нелинейное преобразование к каждому токену по отдельности.
 Схематиченое изображение операции Attention
(Центр) Аггрегация информации из различных голов трансформера
(Справа) Блок энкодера/декодера в трансформере")
Далее в тексте входная последовательность будет обозначаться как , i-ый токен -
.
соотвествуют последовательностям query, key, value.
- длина последовательности токенов.
Токен может быть словом (или частью слова) в предложении, или патчем на картинке (размера 8x8, 16x16, 32x32). Если для решения задачи важен только глобальный контекст, как в случае задачи классификации изображений или sentiment analysis, то предсказание модели часто определяется небольшой долей токенов. Например, для того, чтобы понять, какую эмоциональную окраску имеет отзыв, достаточно посмотреть на ключевые слова, и если нас интересует какое животное изображено на картинке - наличие или отсутствие дерева или куста вряд ли существенно повлияет на наш ответ.
 Пример отзыва на фильм (ключевое слово подсвечено зеленым).
(Справа) Патчи на которых расположена собака выделены красным.")
Кроме того, после обработки данных несколькими слоями трансформера часть токенов может содержать достаточное количество информации для решения поставленной задачи, и даже более того, часть из них дублировать друг друга.
Следовательно, естественным вариантом повышения эффективности трансформера является отбрасывание наименее важных токенов. Причем выигрыш от отбрасывания довольно существенный, так как применение линейных слоев для генерации query, key, value, проекция
после операции внимания и последующие feedforward слои линейно в плане вычислений по длине последовательности
, а операция attention
квадратична по
.
Далее будет рассмотрена 1 работа из NLP по прореживанию токенов, и 4 из компьютерного зрения.
Learned Token Pruning for Transformers
Применительно к задачам обработки естественного языка (NLP) способ прореживания токенов был предложен в работе Learned Token Pruning for Transformers.
 Схема прореживания последовательности и отбрасывания малоинформативных токенов для задачи Sentiment Analysis.
(Справа) Attention для токенов внутри посоедовательности. Более информативные токены выделены более темным цветом.")
В качестве критерия важности токена используется средний attention со всеми токенами по всем головам трансформера:
Выше - вектор признаков, отвечающий
-му токену,
- матрица внимания для
-ой головы и
-го блока трансформера,
- длина последовательности токенов, и
- число голов в multi-head attention.
Определение того, какие токены оставить, а какие отправить в Вальгаллу, осуществляется следующим нехитрым способом: для каждого блока задается порог
, такой что, если значение
больше порога, то токен остается, а иначе покидает этот мир. Формулируя иначе, на последовательность накладывается бинарная маска следующего вида:
Если токен в слое запрунен, то дальше с ним не проводится никаких вычислений как в слое
, так и последующих за ним.
Обучаемый порог
Однако, сразу же возникает: а каким образом определить правильный порог ? Он зависит от блока
, от поданного на вход примера, и от самой задачи. Поэтому предлагается сделать этот порог обучаемым. Но обучать порог, явным образом отбрасывая токены, не представляется возможным в связи с тем, что операция отбрасывания по порогу недифференцируема. Поэтому напрашивается замена hard pruning на soft pruning, когда вместо бинарной маски, принимающей значения только
, допустимо любое значение от 0 до 1. Естественной параметризацией для такой маски выступает сигмоида с некоторой температурой
:
Величина определяет, насколько резко происходит переход от 0 к 1. Таким образом, на этапе обучения менее информативные патчи будут подавлены по сравнению с более информативными, но их вклад не обращается точно в ноль на этапе обучения.
Обучение модели с процедурой прунинга токенов проходит в 3 этапа:
Модель обучается с soft маской
и оптимизируются параметры сети и значения порогов.
Значения порогов
фиксируются и маска становится бинарной.
Параметры самой модели дообучаются при фиксированных значениях порогов и hard прунинге токенов.
Чтобы модели не было выгодно просто брать все токены к исходной функции потерь (скажем, кросс-энтропии для задачи классификации) добавляется регуляризационный член, чтобы уменьшать значение soft маски для как можно большего количества токенов:
Величина определяет trade-off между желанием решить хорошо исходную задачу и выигрышем в производительности.
Эксперименты
Предложенный подход проверятся на ряде задач классификации последовательностей - MNLI, MNLI-m, QQP, QNLI, SST-2, SST-B, MRPC, RTE. В качестве модели используется RoBERTa-Base.

При небольшой просадке в качестве модель удается ускорить примерно в 2 раза с точки зрения теоретических FLOPs. Однако, выигрыш в теоретических FLOPs зачастую трудно перенести на реальные устройства, поэтому более интересны цифры реального ускорения инференса на СPU/GPU. И как показывают графики ниже, за счет некоторой просадки в качестве можно добиться реального ускорения работы модели (интересно было бы сравнить с моделью той же архитектуры, но с меньшим числом каналов или структурированным прунингом).
 для задач QNLP, QQP на CPU (Intel Haswell) и GPU (Nvidia V100).")
К достоинствам предложенного подхода можно отнести простоту и интуитивность подхода, наличие реального выигрыша в производительности на практике.
К недостаткам же можно отнести невозможность задать автоматически желаемую степень ускорения модели. В зависимости от значения
ускорение будет большим или меньшим, но априори понять каким оно будет не представляется возможным. Поэтому если, скажем, стоит задача ускорить модель в 2 раза потребуется провести несколько экспериментов, чтобы определить нужное значение
. Кроме того, число прореживаемых токенов зависит от примера, от того насколько равномерно или локализовано на конкретных токенах распределен attention. То есть speedup варьируется в зависимости от того, что подается на вход.
Dynamic-ViT
В работе Dynamic-ViT (уже применительно к задачам компьютерного зрения) отбор информативных и неинформативных токенов проводится с помощью обучаемого классификатора. Каждый токен на вход небольшой полносвязной сети
выдающей некоторый промежуточный эмбеддинг
меньшей размерности, а затем вычисляется средний
по всей последовальности - глобальный эмбеддинг
, и вероятность сохранения токена
вычисляется с помощью еще одной полносвязной сети
принимающей на вход конкатенацию
и
, к выходу которой применяется
(хотя можно было и просто сигмоиду):
Затем часть токенов отбрасывается или сохраняется с вероятностями и
, cоотвественно. Но каким образом тогда обучать данную конструкцию, если отбрасывание - операция недифференцируемая? И авторы предлагают один из популярных способов сэпмлирования из категориального распределения с возможностью проброса градиента через операцию сэмплирования - GumbelSoftmax.
Функции потерь
Для того, чтобы модель с прунингом токенов эффективнее обучалась и для фиксации заданного уровня прореживания, авторы добавляют 3 дополнительных члена в исходную функцию потерь (кросс-энтропию):
-
Дистилляция с незапруненными токенами исходной модели.
Ниже
означает бинарную маску для i-го токена в
-ом блоке модели. Оставшиеся токены по замыслу должны хранить ту же самую информацию, что и при прогонке через слои исходной модели.
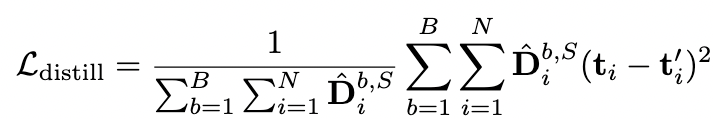
Дистилляция с логитами исходной модели (в привычном понимании).

MSE Loss, устремляющий долю сохраняемых патчей к целевому показателю
:

Итоговый лосс является взвешенной суммой всех четырех (включая исходный) лоссов:
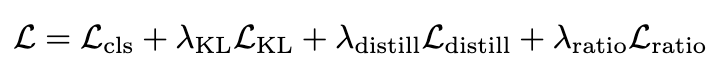
На инференсе в -ом по порядку блоке отбирается
входных пачтей с наибольшим значением вероятности сохранения
.
Вся конструкция обучается в течение 30 эпох (1/10 от времени обучения DeiT в работе Training data-efficient image transformers & distillation through attention).
Кривые Парето и выигрыш в производительности
Всякий уважающий себя метод построения эффективной модели должен быть изображен на кривой Парето священной злобой возвышаясь над дышащими в спину конкурентами. Ниже представлено качество на ImageNet против числа операций с плавающей точкой (теоретических FLOPs).

В разделе 4.1 утверждается, что предложенный подход дает выигрыш в throughput (числе обрабатывамых примеров в единицу времени) в 43-54% на инференсе при замерах на Nvidia RTX 3090 с батчом размера 32, однако для полноты картины немного не хватает кривых зависимости accuracy от throughtput для различных параметров прореживания и моделей.
Занятной и приятной особенностью данного подхода является то, что Dynamic-ViT действительно отбирает токены, содержащие сам интересующий объект.

Ablation study
Далее авторы анализируют важность отдельных компонент и ингредиентов для достижения хорошего качества. Оказывается, что дистилляция как логитов исходной модели, так и токенов, несущественно сказывается на конечном результате.

А вот сам обучаемый критерий отбора довольно важен и работает заметно лучше, чем average pooling в некотором слое (при том же самом числе FLOPs) - Structural Sparsification, и при прореживании токенов с некоторой вероятностью без обучаемого модуля - Static Sparsification (таблица (a)). Кроме того, обучаемый модуль лучше случайного и отсортированного по attention score критерия отбора (таблица (b)).

Имеет место некоторая свобода в плане выбора блоков трансформера, в которых проводится прореживание. Можно прореживать понемного во всех 12 блоках Vision трансформера (в стандартных моделях ViT/DeiT по 12 блоков энкодера и разные модели отличаются размерностью эмбеддингов), можно только в одном, или в некоторых из 12. В данной работе основной результат был получен при прореживании в трех блоках из 12, а именно -4-го, 7-го, 10-го одной и той же доли токенов. При прореживании только в одном блоке при фиксированном числе FLOPs качество заметно проседает, но уже при двух просадка становится незначительной, а прореживание более чем в трех местах практически не улучшает результат.

S-ViTE
В работе Chasing Sparsity in Vision Transformers: An End-to-End Exploration авторы одновременно прореживают модель (веса матриц) с помощью неструктурированного и структурированного прунинга и отбирают наиболее релеватные токены.
Для прунинга используется алгоритм RigL разреженного обучения, периодически убирающий веса с наименьшей абсолютной величиной и восстанавливающий веса с наибольшим значением градиента по ним.
Отбор токенов использует примерно тот же подход, что и Dynamic-ViT, но предсказание вероятности сохранения патча осуществляется только за счет самого токена (без конкатенации с , как в Dynamic-ViT). Отбор токенов осуществляется перед первым слоем, сразу после превращения патчей картинки в эмбеддинги.
Сам по себе результат прореживания относильно скромен, так как без существенной просадки в качестве удалось, по всей видимости, проредить модели только до уровня 40-60%, где теоретический выигрыш в FLOPs проблематично воспроизвести на практике.
Ниже
- неструктрурированный прунинг модели;
- структурированный прунинг модели;
- прунинг модели и токенов.
")

При небольшом прореживании токенов (5-10%) и умеренно прореженной модели авторам удается примерно сохранить исходное качество (а для неструктурированного будто бы немного даже и улучшить). Правда, эта доля и связанный с ней выигрыш невелики. Отбор патчей выглядит довольно случайным.

К другим недостаткам следует еще отнести дороговизну экспериментов (в обьеме вычислений). Полный цикл обучения разреженной модели использует в 2 раза больше эпох (аж 600 штук), чем само обучение с нуля исходных моделей в DeiT, что требует вычислительных ресурсов значительно превосходящих возможности google.colab. Но тем не менее, работа интересна как первая попытка обьединить model и data sparsity применительно к Vision Transformer.
IA-RED^2
В работе Interpretability-Aware Redundancy Reduction for Vision Transformers авторы предложили использовать аж целого RL-агента для отбора патчей.

Более конкретно, происходит следующее : перед каждой группой блоков трансформера (в данной работе авторы делят 12 блоков на 3 группы по 4 блока) вставляется блок отбора патчей. В этом блоке к обучаемому policy токену и токенам патчей применяются линейные слои - по типу key для policy токена и query для патчей, а затем считается скалярное произведение между полученными векторами и к этому скалярному произведению применяют сигмоиду для получения вероятности, оставить или отбросить данный токен.
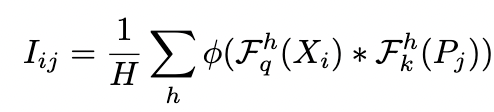
RL-aгент с policy из двух действий - сохранить токен или отбросить токен
- принимает решение на основе распределения Бернулли с определенной выше вероятностью
. За принятие удачного решения агент получает награду, растущую с числом отброшенным патчей, и некоторую отрицательную награду
в противном случае. Выбора
определяет trade-off между качеством решаемой задачи или уменьшением количества операций.

Для обучения этого хозяйства используется широко известный (в узких кругах) REINFORCE c advantage, где из награды для стохастической политики вычитается награда для политики, выбирающей
, если
, иначе
.

Данная конструкция обучается для каждой группы в течение 30 эпох на ImageNet (т.e суммарно 90). Подобно Dynamic-ViT , умеет фокусироваться на более релеватных для решения задачи регионах изображения. Карта внимания в их подходе выходит более локализованной по сравнению с attention исходной модели.


При замерах на Nvidia-V100 подход позволяет добиться ускорения примерно в ~1.5 раза с просадкой в качестве 0.7-0.9%.
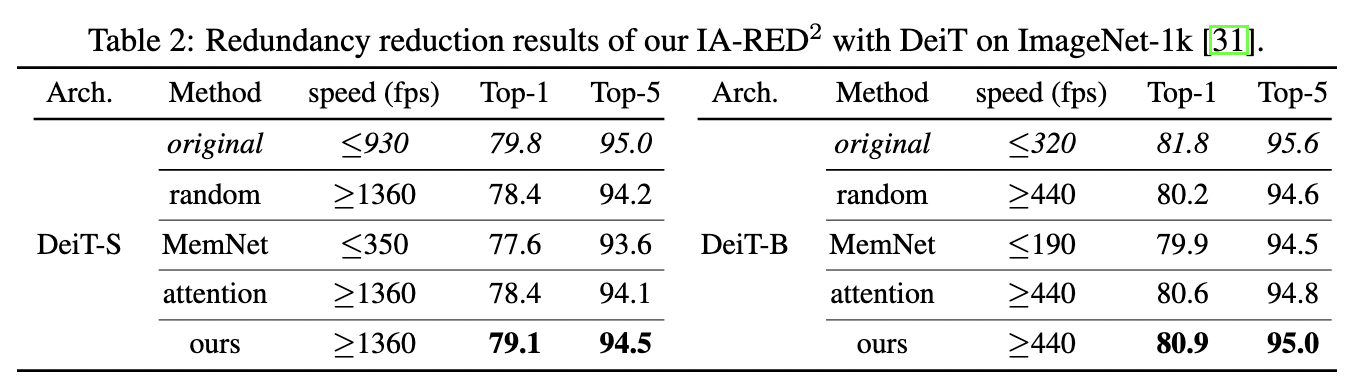
Подход выглядит довольно интересным и эффективным, но к недостаткам стоит отнести необходимость гадать на кофейной гуще, чтобы определить нужное значение для заданного ускорения (ну или провести серию экспериментов).
Evo-ViT
В работе Evo-ViT рассматривая СKA (Center Kernel Alignment) similarity между [CLS] токеном в последнем слое и токенами патчей в промежуточных слоях, авторы делают вывод о том, что представления эволюционируют постепенно и прореживание их в верхних слоях модели может негативно сказываться на качестве модели. Поэтому предлагается не избавляться полностью от патчей с меньшей информативностью, а проводить с ними меньше вычислений.
![CKA similarity между токенами в данном блоке и [CLS] токеном в последнем слое](https://habrastorage.org/getpro/habr/upload_files/2d1/59e/2de/2d159e2de9ef228164e422e716e21503.png "CKA similarity между токенами в данном блоке и [CLS] токеном в последнем слое")
 и в 10-м (ближе к концу). Картинка иллюстирует тот факт, что на промежуточных слоях модель еще не умеет аккуратно выделять целевой обьект.")
Информативность токена определяется по величине attention между
и [
CLS] токеном в данном слое трансформера. токенов с наибольшим значением внимания считаются "информативными" и их обработка происходит точно так же, как для исходной модели. А
менее информативных токенов считаются фоном
и с помощью взвешенной суммы с обучаемыми коэффициентами
аггрегируются в один токен "фона"
Затем к полученной последовательности применяются слои трансформера точно так же, как и было бы и для исходного трансформера:

Затем к "менее информативным" токенам прибавляется одна и та же добавка - токен "фона" после attention и feedforward слоев.

То есть, менее информативные токены остаются, но не участвуют в вычислениях внутри блока трансформера по отдельности (только через

Согласно таблице, Evo-ViT при примерно том же throughput немного выигрывает по качеству у и Dynamic-ViT. Модель обучается с нуля в течение 300 эпох в отличие от DynamicViT и
, использовавших преобученные модели. Разбиение на информативные/неинформативные токены тоже довольно иллюстративно и наглядно:

Из ablation авторы демонстрируют, что предложенная стратегрия разбиеная на фон/обьект работает лучше, чем случайная, или средний attention c другими токенами для данного токена:

Заключение
Таким образом, прунинг токенов - довольно интересное направление для повышения эффективности трансформеров, и его можно комбинировать вместе с другими способами сжатия модели. Кратного увеличения производительности без потери от прореживания токенов без потери качества ожидать не стоит в большинстве случаев, так как значительная часть картинки или текста является полезной для интересующей задачи, но зато небольшой, но выигрыш сравнительно легко реализовать на железе.
Дополнительные ссылки
Легендарное видео про Attention Is All You Need от Yannic Kilcher
S-ViTE (GitHub)
DynamicViT (GitHub)
Evo-ViT (GitHub)
IA-RED^2 (страница проекта)