
Что первым придет в голову, если перед нами встанет задача автоматического порождения речи по тексту? Вероятнее всего, мы позаботимся о расстановке пауз между словами, постараемся правильно выбрать интонацию фразы и расставить смысловые акценты. Обязательно построим фонетическую транскрипцию: орфография и произношение далеко не всегда однозначно соответствуют друг другу, о чем компьютер не узнает без нашей помощи. Полученную транскрипцию переведем в цифровой сигнал, который затем преобразуем в звуковые колебания.

Все перечисленные пункты являются важными и нужными. Однако они не будут выполнены корректно без предварительной подготовки: определения границ предложений, расшифровки сокращений, расстановки ударений. Эти (и многие другие) задачи объединены под общим названием нормализации или лингвистической обработки текста. В данной статье мы рассмотрим нормализацию с языковой точки зрения и приведем ее программную реализацию.
Токенизация на предложения
Для начала разделим текст на отрезки, которые впоследствии будут основными единицами синтеза, – предложения. На первый взгляд все просто: предложениями считаем части текста между точками, вопросительным и восклицательным знаками. Однако для анализа реальных текстов такого подхода недостаточно. Так, точка может не только обозначать конец предложения, но и быть элементом сокращения: например, в предложении "Матчи Евро в Санкт-Петербурге посетили более 132,7 тыс. зрителей". Нужно проанализировать контекст: с одной стороны, является ли слово перед точкой сокращением, и, с другой стороны, следует ли за точкой слово с большой буквы. Даже при учете этих факторов могут возникнуть сложные случаи. Например, если слово после точки является именованной сущностью и пишется с большой буквы, как для предложения "В 1868 г. Лев Толстой закончил «Войну и мир»". Для синтеза речи очень важно правильно разделить текст на предложения, ведь на основе этого деления затем размечаются смысловые акценты и интонация фразы.
Расшифровка сокращений
Как показывают примеры выше, текст может включать в себя не только полные слова, но и сокращения (тыс., г.). Для правильного синтеза необходимо заменить сокращения на полные слова, которые уже будут читаться по правилам русского языка. При расшифровке сокращений мы сталкиваемся с несколькими трудностями. Во-первых, сокращения зачастую неоднозначны: например, за сокращением г. могут скрываться два полных слова – как год, так и город. Во-вторых, за счет того, что в русском языке существительные склоняются по падежам (в отличие, например, от английского языка), приходится выбирать правильную падежную форму для сокращения. Так, сокращение км может расшифровываться по-разному в зависимости от цифры перед ним: 1 км = 1 километр, 2 км = 2 километра, 5 км = 5 километров, к 5 км = к 5 километрам.
Перевод цифр в слова
Впрочем, цифры сами по себе тоже представляют некоторую сложность при нормализации текста: 1 км – это один километр или первый километр? Слова естественного языка, в которые преобразуются числовые записи, называются числительными. Они могут обозначать количество обозначаемых предметов и относиться к разряду количественных числительных: один, два, три, десять, пятьдесят пять. Если же они обозначают номер следования предмета, то являются порядковыми: первый, второй, третий, десятый, пятьдесят пятый. При расшифровке числительных производится выбор между этими разрядами. Кроме того, в текстах могут встретиться стандартные последовательности цифр. Например, цифровая последовательность в предложении «Поэт М.Ю. Лермонтов родился 15.10.1814 в Москве» обозначает дату и должна быть прочитана по заданным правилами: число 15 преобразуются в порядковое числительное пятнадцатого, число 10 заменяется названием месяца в правильной форме – октября, число 1814 преобразуется в порядковое числительное тысяча восемьсот четырнадцатом, добавляется слово года.
С латиницы на кириллицу
За исключением этих нестандартных записей, мы, конечно же, ожидаем, что если в тексте встретилось обыкновенное привычное нам слово, то это слово русского языка, записанное кириллицей. Но здесь нас снова ждет разочарование – в реальных текстах часто встречаются слова, записанные латинским алфавитом: «Microsoft и Google стоят на пороге войны». Есть два способа борьбы с этой неприятной неожиданностью. Можно составить базы данных наиболее употребительных иностранных слов и их эквивалентов в русском языке: Microsoft = майкрософт, Google = гугл. Также можно составить правила дешифровки латинских символов, которые содержат русские эквиваленты каждой латинской букве. Тогда в случае, если встретившееся в тексте слово на латинице не будет найдено в базе данных, каждая буква будет преобразована по соответствующим правилам.
Расстановка ударений
Кажется, что вот теперь-то мы точно готовы приступить к синтезу речи, ведь весь текст преобразован в последовательность слов русского языка. И вот мы сталкиваемся с первым словом в предложении: мáйкрософт. Или все-таки майкросóфт? А может быть мáйкросóфт? Расстановка ударений – вот финальный этап, о котором необходимо позаботиться при нормализации текста для генерации речи.
Для большинства слов русского языка данные об ударении хранятся в словарях. Разработчикам синтеза русской речи очень повезло: они могут использовать данные об ударении около 10 000 слов из «Грамматического словаря русского языка» знаменитого лингвиста А.А. Зализняка. Однако каким бы объемным ни был словарь, в текстах будут встречаться слова, которые не найдутся в словаре.
Зачастую такие слова могут быть правильно интерпретированы с помощью анализа слова на составляющие его элементы – основу и суффиксы. Подобный анализ позволяет связать незнакомое слово с уже известным словом, содержащимся в словаре. Например, если в словаре нет слова супервыставка, мы можем выделить в нем приставку су́пер- и основу вы́ставка, которая в словаре есть. Также при наличии достаточно большого словаря транскрипций можно обучить статистическую модель, выводящую место ударения автоматически. В случае с распространенными иностранными словами вроде Microsoft данные об ударении необходимо включить в базу наиболее употребительных иностранных слов и их эквивалентов в русском языке.
Бéлки или белки́?
Предположим, что все предыдущие этапы выполнены, и мы во всеоружии готовы встретить любые трудности, связанные с расстановкой ударения. И вот мы видим предложение: "Мои коллеги много работают и крутятся как белки в колесе. Ведь мы собаку съели на расставлении ударений и без промедления доходим до слова бéлки… или все же белки́? Как гром среди ясного неба, перед нами стала задача снятия омонимии – определения места ударения в словах, на письме похожих как две капли воды, но имеющих различное произношение. Снятие омонимии осуществляется при помощи анализа контекста. В случае примера выше поиск ключевых слов показывает, что перед нами устойчивое выражение или фразеологизм, что определяет выбор ударения: крутятся как бéлки в колесе. Разрешить омонимию могут помочь и другие ключевые слова: например, на сосне в предложении «На высокой сосне сидели бéлки».

Очень интересно, но где код?
Перечисленные проблемы могут быть решены двумя способами: либо с помощью инженерного подхода, основанного на словарях и правилах (rule-based), либо с помощью алгоритмов машинного обучения и нейронных сетей (machine learning).
Мы рассмотрим реализацию подходов на примере соревнования Kaggle «Text Normalization Challenge - Russian Language». В нем на материале русского языка решается задача нормализации текста для синтеза речи. Данные включают случаи, где последовательность чисел должна быть преобразована в текстовую строку: 12:47 → двенадцать сорок-семь, $3.16 → три доллара, шестнадцать центов. Есть и более сложные преобразования, где необходимо учитывать контекст: так, в предложении «Проверено 12 февраля 2013» числовую последовательность следует расшифровать двенадцатого февраля две тысячи тринадцатого года, а не двенадцатое февраля две тысячи тринадцатого года.
Инженерный подход
Для начала обратимся к решению на основе правил и словарей. В нем анализировались последовательности слов длиной 5: помимо целевого, также 2 предыдущих и 2 последующих слова. Во внимание не брались знаки препинания и тире. Для распознавания номеров наподобие 978-5-104935-25-2 использовался пакет num2words. Для парсинга дат вида 02.10.15 г., где месяц записан числом, создавались отдельные словари с однозначным соответствием числа и названия месяца:
mm = {"1":"января",
"2":"февраля",
"3":"марта",
"4":"апреля",
"5":"мая",
"6":"июня",
"7":"июля",
"8":"августа",
"9":"сентября",
"10":"октября",
"11":"ноября",
"12":"декабря",
"01":"января",
"02":"февраля",
"03":"марта",
"04":"апреля",
"05":"мая",
"06":"июня",
"07":"июля",
"08":"августа",
"09":"сентября"
}Для расшифровки сокращений вроде кг или км/ч задавались пользовательские словари. Сложность состояла также в том, что одна и та же расшифровка могла соответствовать нескольким сокращениям: например, величина квадратный километр могла быть записана как км2, км2 и km2, что при инженерном подходе должно быть прописано как отдельное условие:
m = {}
m['км²'] = 'квадратных километров'
m['км2'] = 'квадратных километров'
m['km²'] = 'квадратных километров'
m['км'] = 'километрах'
m['km'] = 'километрах'
m['кг'] = 'килограмма'
m['kg'] = 'килограмма'
m['m²'] = 'квадратных метров'
m['м²'] = 'квадратных метров'
m['м³'] = 'кубических метров'
m["млн"] = "миллионов"
m["м/с"] = "метров в секунду"
m["мм"] = "миллиметров"
m["м"] = "метров"Автор решения отмечает, что нестандартная транслитерация была самой большой проблемой. Сначала была попытка использовать фонетическую транслитерацию из пакета nltk.corpus.cmudict и сопоставить ее непосредственно с русским языком. Но из-за ограничений словаря (всего 134 000 слов) это не сработало. Затем был использован пакет transliterate в качестве основы, что дало 15% точности на тренировочных данных. В итоге более 40 правил были добавлены вручную, что дало 50% точности.
Нейросетевой подход
Данное решение состояло в обучении сверточной нейронной сети (convolutional neural network, CNN) на основе архитектуры FAIR Sequence-to-Sequence Toolkit. Sequence-to Sequence, или сокращенно seq2seq, – это архитектура нейронных сетей для задач, где подается на вход и возвращается последовательность.
На рисунке представлена архитектура сверточной seq2seq сети для машинного перевода, которая была использована в данном решении для нормализации текста. Машинный перевод и нормализация имеют много общего: по сути, задача сводится к преобразованию одной последовательности в другую. Вначале кодируется исходное предложение (на схеме сверху), то есть предложение на исходном языке или исходная последовательность до нормализации. Далее одновременно вычисляются значения внимания для целевых слов (по центру схемы), то есть слов предложения на целевом языке или целевой последовательности после нормализации. Значения внимания являются результатом скалярного произведения между контекстными репрезентациями декодера (внизу схемы слева) и репрезентациями энкодера. Мы добавляем входные данные, вычисленные с помощью механизма внимания (в центре справа), к состояниям декодера, которые затем предсказывают целевые слова (внизу справа).
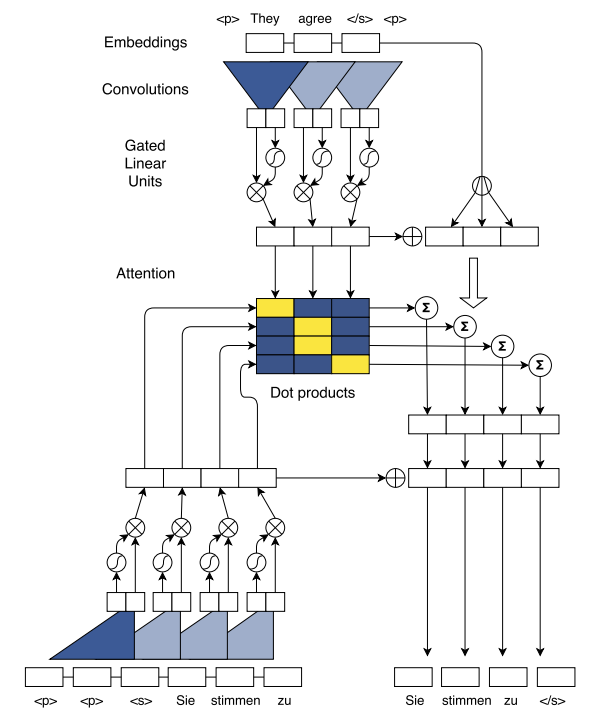
При обучении модели слова рассматривались на уровне BPE-токенов (Byte Pair Encoding). BPE-словарь строится по следующим правилам. Вначале элементы BPE-словаря – отдельные символы, при этом на каждом шаге объединяется самая частая пара символов. Так происходит, пока не будет достигнут заранее заданный размер. Лучший результат был получен для BPE-словаря объемом 20 000.
Подведем итоги
Как инженерный, так и нейросетевой подход показывают довольно высокое качество нормализации текста для русского языка: рассмотренные нами решения заняли место в первой тройке лидеров соревнования.
В то же время важно понимать, что при внедрении в продакшн сложности могут возникнуть с использованием обоих подходов. С одной стороны, написание правил и создание словарей требуют много усилий и занимают немало времени, причем их необходимо регулярно пополнять. С другой стороны, для обучения модели требуется сбор большой обучающей выборки и наличие вычислительных мощностей. Если вас это не пугает, то вы на верном пути.
Комментарии (2)

Ampiro
01.08.2022 10:48Интересная статья, лично для себя нашёл пару дополнительных проблем при работе с текстом. Плохо, что нет результатов модели seq2seq, хотя и написано, что они высокие.
PereslavlFoto
Если автор хочет написать «октября», он и пишет «октября». В данном примере автор хотел написать «пятнадцатого десятого тысяча восемьсот четырнадцатого». Автор не хотел добавлять слово «года», поэтому не добавил его.
Почему же вы предлагаете читать совсем не то, что написано?