
Но такой способ не подходит для прямых трансляций, когда нужно переводить почти в режиме реального времени. Поэтому сегодня мы открываем для всех отдельный, более сложный механизм — потоковый перевод стримов.
Чтобы всё заработало, перезапустите Яндекс Браузер. Анонсы новых устройств, спортивные соревнования, вдохновляющие космические запуски — этот и другой контент теперь можно смотреть сразу на родном языке. Закадровый голосовой перевод сейчас доступен для некоторых каналов на YouTube, а в будущем, конечно, включить дубляж можно будет в любой YouTube-трансляции. Чтобы адаптировать механизм перевода для стримов, потребовалось переработать всю архитектуру.
Как работает потоковый перевод
Перевод потокового видео — очень сложная задача с инженерной точки зрения. Здесь сталкиваются два противоречивых требования. С одной стороны, нужно передать модели как можно больше текста за раз, чтобы нейросеть поняла контекст фразы. С другой стороны, необходимо свести задержку к минимуму, иначе «прямой эфир» перестанет быть таковым. Поэтому приходится начинать переводить как можно скорее — не в режиме синхронного перевода, но близко к нему.
Чтобы запустить быстрый и качественный перевод в потоковом режиме, мы, по сути, сделали новый сервис на основе существующих алгоритмов. Новая архитектура позволила сократить задержку, не сильно потеряв в качестве.
Если очень коротко описывать принцип работы потокового перевода, то в его основе лежат пять моделей. Одна нейросеть распознает аудиодорожку и превращает её в текст. Вторая определяет пол спикеров, третья нарезает текст на предложения — расставляет знаки препинания и выделяет из текста части, содержащие законченную мысль. Четвёртая нейросеть переводит полученные куски, а пятая синтезирует речь.
Выглядит просто, но внутри много подводных камней. Рассмотрим процесс подробнее.
Из чего состоит потоковый перевод в Браузере
На первом этапе нужно понять, что именно говорится в потоковом видео, а также определить, в какой момент произносятся слова. Дело в том, что мы не просто переводим речь, но и накладываем результат обратно на видео в нужные моменты.
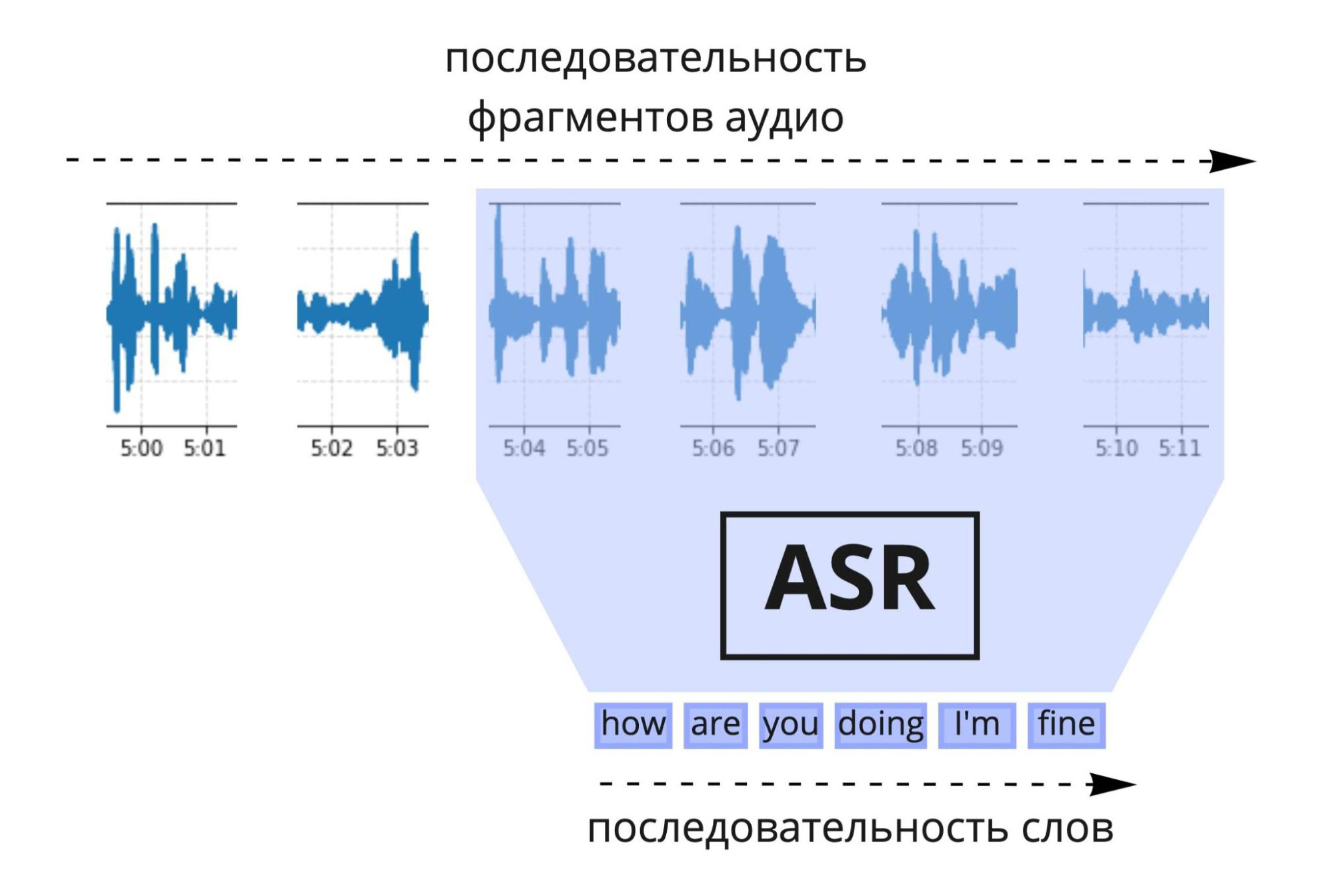
Задача распознавания речи (ASR, Automated Speech Recognition) отлично решается с использованием глубоких нейронных сетей. Архитектура нейросети должна допускать потоковый сценарий использования, то есть уметь обрабатывать аудио по мере поступления. Такое ограничение может сказаться на точности предсказания, но мы можем позволить модели смотреть на несколько секунд в будущее.
На видео могут присутствовать посторонние звуки, например, шумы и музыка, люди могут говорить с различным акцентом, скоростью и дикцией, спикеров может быть много, они могут кричать, а не говорить. Нужно помнить и про богатую лексику, поскольку тематик видео целое множество. Поэтому сбор данных для обучения играет ключевую роль.
На вход алгоритм получает последовательность кусочков аудио, берёт последние N из них, извлекает акустические признаки (мел-спектрограмму) и подает на вход нейросети. Она, в свою очередь, выдаёт множество последовательностей слов (так называемых гипотез), из которых языковая модель выбирает наиболее правдоподобную гипотезу. Когда приходит новый кусочек аудио, процесс повторяется.
Полученную последовательность слов нужно перевести. Если переводить пословно или по фразам, пострадает качество. Если ждать длительной паузы, которая гарантирует конец предложения, то появится большая задержка. Поэтому нужно группировать слова в предложения, не допуская потери смысла или слишком длинных предложений. Один из способов решить эту задачу — использовать модель восстановления пунктуации.

С приходом трансформеров нейросетям стало проще понимать смысл текста, взаимосвязи между словами и закономерности языковых конструкций. Нужно только большое количество данных. Для задачи восстановления пунктуации достаточно взять текстовый корпус, подавать на вход нейросети текст без пунктуации и обучить нейросеть её восстанавливать.
На вход нейросети текст поступает в токенизированном виде, как правило, это BPE-токены. Такое разбиение не слишком мелкое, чтобы длина последовательности не сильно увеличилась, но и не слишком крупное, чтобы избежать проблемы out-of-vocabulary — когда токена нет в словаре. На выходе модели после каждого слова метка: ставить ли тот или иной символ пунктуации.
Чтобы обеспечить работу в потоке, нужно задать некоторый ограниченный контекст. Его размер — компромисс между качеством и задержкой. Если мы не уверены, нужно ли разбивать на предложения в данном месте, то можем подождать чуть дольше, пока не придут новые слова. Тогда мы либо лучше определимся с разбиением, либо превысим ограничение по контексту и будем вынуждены разбивать там, где почти уверены.

Для корректного перевода и озвучки нужно определить пол говорящего. Если использовать классификатор пола на уровне предложений, то никаких отличий в потоковом сценарии не будет. Но мы заметили, что биометрическая информация снижает ошибку классификации пола в полтора раза: то есть мы можем не просто определять пол человека по реплике, а ещё и учитывать результат классификации пола на предыдущих репликах. Для этого нам нужно «на лету» определять, кому принадлежит реплика, тем самым уточняя пол спикера.

С точки зрения машинного перевода ничего не изменилось в сравнении с переводом уже готовых роликов, поэтому на этом этапе останавливаться не будем. Подробнее о том, как работает перевод, мы писали в этом хабрапосте.

В прошлом году мы также рассказывали, как устроен речевой синтез Яндекса. Базовая технология синтеза в Алисе и переводе видео одна и та же. Разница в том, как осуществляется применение (inference) этих нейросетей. Спикер на видео может произнести реплику очень быстро или перевод предложения может оказаться в два раза длиннее оригинала. В таком случае придётся сжать синтезированное аудио, чтобы успеть в тайминг. Это можно сделать двумя способами: на уровне звуковой волны, например, при помощи PSOLA (Pitch Synchronous Overlap and Add) или внутри нейросети. При втором способе речь звучит натуральнее, но для этого нужна возможность редактирования скрытых параметров.
Важно не только привести длительности синтезированных фраз к нужной длине, но и разложить их по нужным моментам времени. Идеально получится не всегда, придётся либо ускорить запись, либо сдвинуть тайминги. За это у нас отвечает алгоритм укладки. В переводе стримов нельзя менять прошлое, поэтому может получиться ситуация, когда нужно озвучить фразу в два раза быстрее, чем она произносится в оригинальном видео. Для справки: ускорение более чем на 30% существенно влияет на восприятие.
Решение следующее: делаем некоторый запас по времени, то есть не спешим укладывать реплики, а ждём, когда придут новые, чтобы учесть их длительность, а так же позволяем немного накапливать сдвиг по времени, так как рано или поздно на видео все замолчат и сдвиг обнулится.
Результирующую аудиодорожку нарезаем на фрагменты и оборачиваем в аудиострим, который будет микшироваться на клиенте браузера.
Как архитектурно устроен сервис потокового перевода

Когда вы смотрите трансляцию, браузер опрашивает сервис стриминга (например, YouTube) на предмет новых фрагментов видео и аудио; если такие есть, он их скачивает, а затем последовательно воспроизводит.
Когда пользователь нажимает на кнопку перевода стрима, Яндекс Браузер запрашивает у своего бэкенда ссылку на стрим с переведенной аудиодорожкой. Эту дорожку Браузер накладывает по таймингам поверх основной.
В отличие от video-on-demand (то есть перевода уже готовых роликов), стрим обрабатывается переводом всё время своего существования. Stream Downloader читает аудиопоток и отправляет его в ML-pipeline обработки, компоненты которого мы разобрали выше.
Есть несколько способов организовать взаимодействие между компонентами. Мы остановились на варианте с очередями сообщений, где каждый компонент оформлен в виде отдельного сервиса:
- Запустить все модели в рамках одной машины проблематично — они просто не уместятся по памяти или потребуют очень специфичную конфигурацию железа.
- Требуется балансировать нагрузку и иметь возможность горизонтально масштабироваться. Например, у сервисов перевода и синтеза различные пропускные способности, поэтому количество реплик может быть разное.
- Сервисы иногда падают (out-of-memory на GPU, утечка памяти или просто отключили питание в дата-центре), и очереди предоставляют механизм retry.
Стрим не привязан к отдельно взятому инстансу, но для обработки может потребоваться некий контекст (предыстория). Например, синтезу нужно хранить записи, которые он ещё не уложил на финальную аудиодорожку. Отсюда возникает необходимость в глобальном хранилище контекстов для всех стримов. На схеме он обозначен как Global Context — по сути, это просто in-memory key-value storage.
Полученный аудиопоток нужно доставить пользователю. Здесь за дело берётся Stream Sender — он оборачивает фрагменты аудио в стриминговый протокол, и клиент читает этот стрим по ссылке.
Что дальше
Сейчас мы отдаём потоковый перевод со средней задержкой 30-50 секунд. Иногда вылетаем за этот диапазон, но не сильно: стандартное отклонение — примерно 5 секунд.
Основная сложность в переводе стримов — гарантировать стабильность задержки. Простой пример: вы запустили стрим и через 15 секунд начали получать перевод. Если продолжать просмотр, то рано или поздно одна из моделей захочет большего контекста — скажем, если спикер произносит длинное предложение без пауз, нейросеть попробует получить его целиком. Тогда задержка увеличится, возможно, на десять дополнительных секунд. Чтобы такого не происходило, лучше на старте дать чуть большую задержку.
Наша глобальная задача — уменьшить задержку примерно до 15 секунд. Это чуть больше, чем при синхронном переводе, но достаточно для стримов, где ведущие общаются с аудиторией — например, в Twitch.
Комментарии (13)

Two_Sheds
05.08.2022 14:18+1Насколько я понимаю, писать субтитры в два раза быстрее и проще чем генерировать аудио поток. А если к стриму будет еще и добавляться текстовый файл будет вообще чудесно.

HemulGM
05.08.2022 15:28+1На сколько я понял, проблема именно в скорости перевода, а не в озвучивании текста. Т.к. качество перевода зависит от полноты данных (предложения)

TonyEscobar
05.08.2022 18:49Скажем так, необходимость озвучки (что само по себе дело небыстрое, в сравнении с генерацией текста) усугубляет проблему скорости перевода. Проблема полноты данных и сохранения контекста есть в обоих случаях, если мы говорим о генерации в реальном времени.
К тому же добавляются проблемы с тем, чтобы скорость речи (и, в идеале, интонация и тональность голоса) +- совпадали, иначе в стриме с несколькими говорящими людьми начнется хаос.

Topchan
05.08.2022 18:50Супер!
Но проверил в Я браузере декстопном и в мобильном. Пока, например NASA, не включается перевод.





klirichek
06.08.2022 16:26Можно же просто стримить пользователю с задержкой. Как раз, чтобы все конвейеры прогрелись.
Если это не диалог с пользователем - ну, будет переведённое видео (со звуком) отставать, скажем, на минуту; это не прямо сильно критично.

asrtonom4ek
06.08.2022 18:29было бы круто добавить возможность увеличить задержку для поднятия качества. Например задержка в 1мин меня устроит (при условии синхронизации видео), зато перевод будет качественнее

gusev
В онлайн-видео потоке работает очень круто. Можно ли эту технологию применить для электронного переводчика? Если в двух словах почему продукты, даже от уважаемых поисковых компаний, которые есть сейчас на рынке просто хлам, в сравнении с вашим потоковым переводом?