
За последние несколько лет мы видели целый ряд идей относительно архитектуры систем. Каждая из них на выходе давала:
- Независимость от фреймворка. Архитектура не зависит от существования какой-либо библиотеки. Это позволяет использовать фреймворк в качестве инструмента, вместо того, чтобы втискивать свою систему в рамки его ограничений.
- Тестируемость. Бизнес-правила могут быть протестированы без пользовательского интерфейса, базы данных, веб-сервера или любого другого внешнего компонента.
- Независимоcть от UI. Пользовательский интерфейс можно легко изменить, не изменяя остальную систему. Например, веб-интерфейс может быть заменен на консольный, без изменения бизнес-правил.
- Независимоcть от базы данных. Вы можете поменять Oracle или SQL Server на MongoDB, BigTable, CouchDB или что-то еще. Ваши бизнес-правила не связаны с базой данных.
- Независимость от какого-либо внешнего сервиса. По факту ваши бизнес правила просто ничего не знают о внешнем мире.
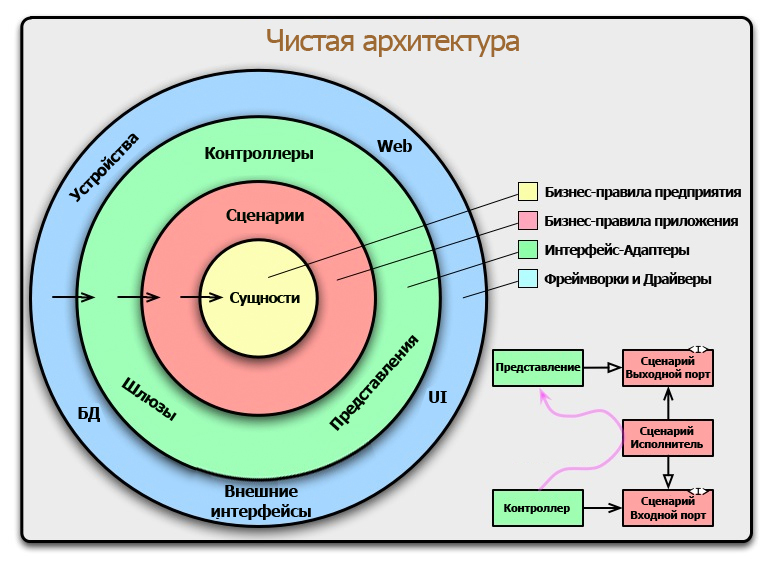
Диаграмма в начале этой статьи — попытка объединить все эти идеи в единую эффективную схему.
Правило Зависимостей
Концентрические круги на диаграмме представляют собой различные слои программного обеспечения. В общем случае, чем дальше вы идете, тем более общим становится уровень. Внешние круги — механика. Внутренние круги — политика.
Главным правилом, делающим эту архитектуру работающей является Правило Зависимостей. Это правило гласит, что зависимости в исходном коде могут указывать только во внутрь. Ничто из внутреннего круга не может знать что-либо о внешнем круге, ничто из внутреннего круга не может указывать на внешний круг. Это касается функций, классов, переменных и т.д.
Более того, структуры данных, используемых во внешнем круге не должны быть использованы во внутреннем круге, особенно если эти структуры генерируются фреймворком во внешнем круге. Мы не используем ничего из внешнего круга, чтобы могло повлиять на внутренний.
Сущности
Сущности определяются бизнес-правилами предприятия. Сущность может быть объектом с методами или она может представлять собой набор структур данных и функций. Не имеет значения как долго сущность может быть использована в разных приложениях.
Если же вы пишете просто одиночное приложение, в этом случае сущностями являются бизнес-объекты этого приложения. Они инкапсулируют наиболее общие высокоуровневые правила. Наименее вероятно, что они изменятся при каких-либо внешних изменениях. Например, они не должны быть затронуты при изменении навигации по страницам или правил безопасности. Внешние изменения не должны влиять на слой сущностей.
Сценарии
В этом слое реализуется специфика бизнес-правил. Он инкапсулирует и реализует все случаи использования системы. Эти сценарии реализуют поток данных в и из слоя Cущностей для реализации бизнес-правил.
Мы не ожидаем изменения в этом слое, влияющих на Cущности. Мы также не ожидаем, что это слой может быть затронут внешними изменениями, таких как базы данных, пользовательским интерфейсом или фреймворком. Этот слой изолирован от таких проблем.
Мы, однако, ожидаем, что изменения в работе приложения повлияет на Cценарии. Если будут какие-либо изменения в поведении приложения, то они несомненно затронут код в данном слое.
Интерфейс-Адаптеры
Программное обеспечение в этом слое представляет собой набор адаптеров, которые преобразуют данные из формата наиболее удобным для Сценариев и Сущностей, в формат наиболее удобный для дальнейшего использования, например в БД. Именно это слой, например, будет полностью содержать архитектуру MVC. Модели являются скорее всего структурами данных, которые передаются от контроллеров к Сценариям, а затем обратно из Сценариев к Представлениям.
Точно так же, данные преобразуются, в этом слое, из формы наиболее удобным для Сценариев и Сущностей, в форму, наиболее удобной для постоянного хранения, например в базе данных. Код, находящийся внутри этого круга не должен знать что-либо о БД. Если БД — это SQL база данных, то любые SQL-инструкции не должны быть использованы на этом уровне.
Фреймворки и драйверы.
Наружный слой обычно состоит из фреймворков, БД, UI и т.д. Как правило, в этом слое не пишется много кода, за исключением кода, который общается с внутренними кругами.
Это слой скопления деталей. Интернет — деталь, БД — деталь, мы держим эти штуки снаружи для уменьшения их влияния.
Только четыре круга?
Нет, круги схематичны. Вы можете решить, что вам нужно больше, чем эти четыре. Нет правила, утверждающего, что вы должны всегда иметь только эти четыре. Тем не менее, Правило Зависимостей применяется всегда. Зависимости в исходном коде всегда указывают внутрь. По мере продвижения внутрь уровень абстракции возрастает. Внешний круг — уровень деталей. Внутренний круг является наиболее общим.
Пересечение границ.
В нижней правой части диаграммы показан пример того, как мы пересекаем границы круга. Контроллеры и Представления взаимодействуют со Сценариями из следующего слоя. Обратите снимание на поток управления. Она начинается в Контроллере, движется через Сценарий, а затем завершает выполнение в Представлении. Обратите внимание на зависимости в исходном коде. Каждая из них указывает внутрь к Сценарию.
Обычно мы решаем это кажущееся противоречие с помощью Принципа Инверсии Зависимостей.
Например, предположим, что из Сценария нужно обратиться к Представлению. Однако, этот вызов обязан быть не прямым, чтобы не нарушать Правило Зависимостей — внутренний круг не знает ничего о внешнем. Таким образом Сценарий вызывает интерфейс (на схеме показан как Выходной Порт) во внутреннем круге, а Представление из внешнего круга реализует его.
Та же самая техника используется, чтобы пересечь все границы в архитектуре. Мы воспользуемся преимуществами динамического полиморфизма для создания зависимостей в исходном коде так, чтобы поток управления соответствовал Правилу Зависимостей.
Как данные пересекает границы.
Обычно данные, которые пересекают границы — это просто структуры данных. Вы можете использовать базовые структуры или, если хотите, Data Transfer Objects (DTO — один из шаблонов проектирования, используется для передачи данных между подсистемами приложения). Или данные могут быть просто аргументами вызова функций. Или вы можете упаковать его в хэш-таблицу или в объект. Важно, чтобы передаваемые структуры данных были изолированными при передаче через границы. Мы не хотим жульничать и передавать Сущность или строки БД. Мы не хотим, чтобы структуры данных имели какие-либо зависимости, нарушающие Правило Зависимостей.
Например, многие фреймворки (ORM) в ответ на запрос к БД возвращают данные в удобном формате. Мы могли бы назвать это RowStructure. Мы не хотим передавать эту структуру через границу. Это было бы нарушением Правила Зависимостей поскольку в этом случае внутренний круг получает информацию о внешнем круге.
Поэтому передача данных через границу всегда должна быть в формате удобном для внутреннего круга.
Заключение
Следовать этим простым правилам не трудно и они сохранят вам много времени в будущем. Разделяя ПО на слои и следуя Правилу Зависимостей вы будете создавать систему тестируемой, со всеми вытекающими преимуществами. Когда любая из внешних подсистем устареет, будь то БД или веб-фреймворк, вы легко сможете заменить их.
P.S. Данная статья переведена как подготовка к более поздней и чуть более практически ориентированной статье о чистой архитектуре на Go. Интересно?
Комментарии (27)

nelson
27.10.2015 13:31Очень интересует данная тема.
Никак не могу сообразить, как решить одну задачку в рамках правильной архитектуры. Есть допустим в проекте пользователи и две такие сущности: «Друзья пользователя» и «Кто онлайн». Отдельно работают замечательно, ничего друг про друга не знают. Хранятся и те и другие данные в mysql. Но если надо вывести тех друзей, которые сейчас онлайн — самое простое и быстрое решение это сделать выборку по двум таблицам (friends join users_online). Но её сделать нельзя, ибо «Друзья» ничего не знают про формат хранения онлайн-юзеров, онлайн-юзеры не знают про формат хранения друзей, а все остальные не знают ни того ни другого. Как быть?
FractalizeR
27.10.2015 14:32+3Разве «друзья пользователя» — это сущность? По-моему, это коллекция объектов «Пользователь». Как и «Кто онлайн», кстати. Даже если у вас друзья имеют какие-то дополнительные атрибуты, это все равно только характеристика связи. Или нет?
nelson
27.10.2015 14:36Да, это не сущность в плане «Модель», а скорее некий сервис. В случае друзей — у него есть методы «Отправить запрос на добавление в друзья», «Принять в друзья», «Удалить из друзей», «Получить список друзей». В случае онлайна — «Получить список тех кто онлайн», «Узнать онлайн ли данный юзер» и «Поставить отметку времени (типа пинг = я онлайн)».

iCubeDm
27.10.2015 14:37+1«Кто онлайн», по идее, должен быть статусом пользователя, а не отдельной сущностью. А друзья пользователя — это бридж-таблица many-many к юзерам. Ну это если работа идет в рамках единой БД.
nelson
27.10.2015 14:48+1Оно примерно так и хранится. Только время последнего визита лежит не в таблице пользователей, а в отдельной. А через год — может будет лежать в Редисе. Формат хранения друзей также может измениться. Поэтому хочу сделать так, чтобы класс Юзер ничего не знал про то, как хранятся его друзья, и как хранится его статус «онлайн», и он мог просто получать эти данные от двух независимых от себя сервисов. А как эти сервисы подружить между собой — вот в чем вопрос. При том что они не должны ничего друг о друге знать? Т.е. одним запрос тут никак не сделаешь, надо выбирать сначала всех друзей, потом проверять их отдельно через сервис «кто онлайн». А можно сэкономить своё время, и захардкодить более быстрое решение через один запрос с join.
iCubeDm
27.10.2015 14:53ну, ИМХО, это путь «по глубокому внутреннему миру». Всё-таки в микросервисы нужно выделять отдельные бизнес-компоненты и уже их «общать» друг с другом. А тут, получается, вы пилите самого юзера на микросервисы. Имеет ли это смысл? Возможно. Всё зависит от задач.

FiresShadow
28.10.2015 07:33nelson, а у вас ORM используется, или вы sql запросы сами формируете?
nelson
28.10.2015 08:52У нас ActiveRecord, который позволяет использовать в том числе запросы забитые вручную. ORM в свое время показался не самыми гибким для развивающегося стартапа… (много раз приходилось менять схемы, и делать это надо было быстро, принцип бережливго стартапа).
FiresShadow
28.10.2015 10:05+1Можно написать класс-джойнер. Первый сервис — СписокДрузей — содержит запрос как получать список друзей, СписокОнлайн содержит запрос как получить список пользователей онлайн: «select * from UsersOnline u {0} where u.status = 'online'». Вместо "{0}" может быть пустая строка или подстрока для джойна «join ({0}) something on u.user_id = something.user_id». И запрос и подстрока хранятся в СписокОнлайн. Ну и нужно учесть что where тут должен быть только один. Джойнер должен понимать как сджойнить данные двух сервисов: либо сгенерит на основании двух сервисов sql с джойном, или, если данные одного сервиса в кэше а другого в базе, то возьмёт айдишки из кэша и подставит их в запрос. Но предупрежу: генерация sql путём конкатенации строк — скользкая дорожка, часто чреватая труднообнаруживаемыми ошибками.
Если в приложении не нужно джойнить таблицы пачками, то проще и надежнее будет просто сделать два запроса вместо одного, отфильтровав вторым сервисом результаты первого.
Можно просто захардкодить sql запрос со всеми джойнами, а не вычислять его динамически, но тут возникают проблемы с гибкостью и дублированием знания.
Ну а ещё лучше — переписать слой доступа к данным и не использовать ActiveRecord, но самый лучший путь не всегда самый верный :), т.к. есть ещё сроки, бюджет, возможно жёсткие требования по быстродействию.
Я бы лично сделал так: если проблема единичная, то отфильтровал бы вторым сервисом результаты первого. Если проблема повсеместная — избавился бы от ActiveRecord и использовал бы ORM. УдачиFiresShadow
28.10.2015 12:32nelson, расскажете потом что вы выбрали и что в итоге получилось?
nelson
29.10.2015 13:19Спасибо за ваш развернутый комментарий выше.
Я остановился на варианте, когда время последнего визита становится полем пользователя, а класс для работы с друзьями содержит метод «Получить друзей», которому можно передать параметр «только онлайн», и он будет делать нужный джойн. То есть — такое односторонее нарушение инкапсуляции. Теоретически это плохо — если изза растущей нагрузки мне придётся хранить список онлайн юзеров в памяти — придётся переписывать и класс работы с друзьями. Надеюсь, такое время наступит не скоро.FiresShadow
29.10.2015 14:42Как вариант, если будет высокая нагрузка, можно специально для Users_online завести отдельную базу данных на отдельном сервере и настроить репликацию в неё таблички Users из основной базы. Но это нужно по ситуации смотреть, что и как лучше оптимизировать.

VolCh
28.10.2015 10:18+1ActiveRecord по идее одна из разновидностей ORM
FiresShadow
28.10.2015 10:39Я подразумевал Repository, когда работа с данными из бд идёт почти так же, как если бы они были массивами в оперативной памяти.
Ну а вообще ActiveRecord может быть выстроена поверх простой Mini-ORM наподобие Dapper-а, тогда Dapper будет непосредственно маппить, а ActiveRecord будет слоем доступа к данным, который будет скармливать sql-ные запросы непосредственно ORM. Ну а вообще я пожалуй пропущу этот назревающий холивар по поводу терминологии.FiresShadow
28.10.2015 11:25Подумал, вроде да, Active Record можно называть ORM, если sql-ом его не кормить
xanm
27.10.2015 14:43Можно сделать сущность «Друзья Онлайн» или сделать у «Друзей» характеристику «Онлайн», в модели все будет логично а как это вытаскивается из БД это уже вопрос инфраструктуры
VolCh
27.10.2015 23:15+1По идее тут должен быть один набор сущностей «пользователь» с булевым членом «онлайн» и набором ссылок «друзья» на некоторых пользователей из основного набора. И фильтр, позволяющий извлечь из набора пользователей, только пользователей с установленным членом «онлайн». Это, максимум, два внутренних круга на диаграмме (если фильтр отнести к сценариям). А как их заполнять эффективно — это дело внешних кругов, которые не просто могут, а должны знать публичные, как минимум, интерфейсы внутренних кругов.
xanm
27.10.2015 14:46В одном из последних проектов пришел именно к такой архитектуре, но там еще основывался на DDD. Надо прочесть первоисточник. Спасибо!



mickvav
27.10.2015 21:46-1Проблема в том, что идея выносить бизнес-логику из sql при серьёзных нагрузках может приводить к проблемам с производительностью решения.
Бизнес-логика — это идея того, что должно быть сделано, а язык и уровень стека, на котором эта логика будет реализована уже зависит от требований.VolCh
27.10.2015 23:19Обычно людям приходит в голову идея вносить бизнес-логику в sql, когда встречаются с проблемами производительности, а не наоборот. С другой стороны, для sql применимі те же архитектурные правила —
mickvav
28.10.2015 18:19Ну вот я примерно про то же — архитектура и язык реализации — это ортогональные сущности.
andrewnester
Вашему предложению написать статью про чистую архитектуру для приложений на Go однозначно да, было бы лично мне интересно
trong
Ок, значит ждите go-специфики :)