

Источник
Периодически у каждого возникает такая задача, когда необходимо произвести поиск в какой-либо директории, прямо внутри содержащихся там файлов, и найти нужные файлы по ключевым словам. Именно об этом мы и поговорим в этой статье.
Проблема
На самом деле, эта задача достаточно не новая и периодически встаёт перед каждым пользователем компьютера. Как правило, ничего подобного, что помогло бы в решении этой проблемы — под рукой не имеется.
Если попытаться некоторым образом усреднить ситуацию, в которой обычно приходится сталкиваться с этим вопросом, то она выглядит так: ты приходишь на новую работу, тебе дают ряд разбросанных по сети директорий и какой-либо вопрос для решения, а затем говорят: «Нужная информация для этой задачи находится где-то там...». Кроме того, задача усложняется ещё и тем, что, как правило, «всё должно быть сделано ещё вчера». И вот ты постепенно погружаешься в эти авгиевы конюшни…
Конечно, в некотором смысле проблему можно решить наличием большого количества имеющихся в сети приложений, которые осуществляют подобный поиск.
Однако, как быть, если требуется не поиск сам по себе, а анализ контента определённых файлов, парсинг информации и сборка некого производного файла?
Решение
Понятно, что в этом случае обычные поисковики использовать не получится, — необходимо некое программное решение. Тут нам на помощь приходят библиотеки от Apache: Tika и POI.
Вот на этой странице вы сможете найти связанные с POl проекты (со ссылками на них), которые позволяют гибко работать с множеством документов. Особенное внимание уделено работе с SQL-запросами, извлечению и записи в Excel-файлы, а также работе с Microsoft Word и PowerPoint; присутствует даже инструмент работы с базой данных Microsoft Access — Jackcess (он является подключаемой библиотекой, без какого-либо графического интерфейса).
POI — одна из библиотек, которую использует связанный с ней проект Tika.
Причём, если мы говорим о Tika, то она поддерживает работу с массой различных типов файлов (более тысячи, как заявляют сами разработчики), среди которых имеются и наиболее часто используемые: PowerPoint, Excel, Word, PDF.
Полный список поддерживаемых форматов вы можете найти вот здесь.
На момент написания статьи самой последней версией библиотеки была 2.4.1. Найти её можно вот на этой странице.
API библиотеки — находится тут.
Примеры
Самым простым способом использования Tika является применение так называемого «фасада», который представляет собой класс, содержащий ряд методов, позволяющих проанализировать переданный ему файл:
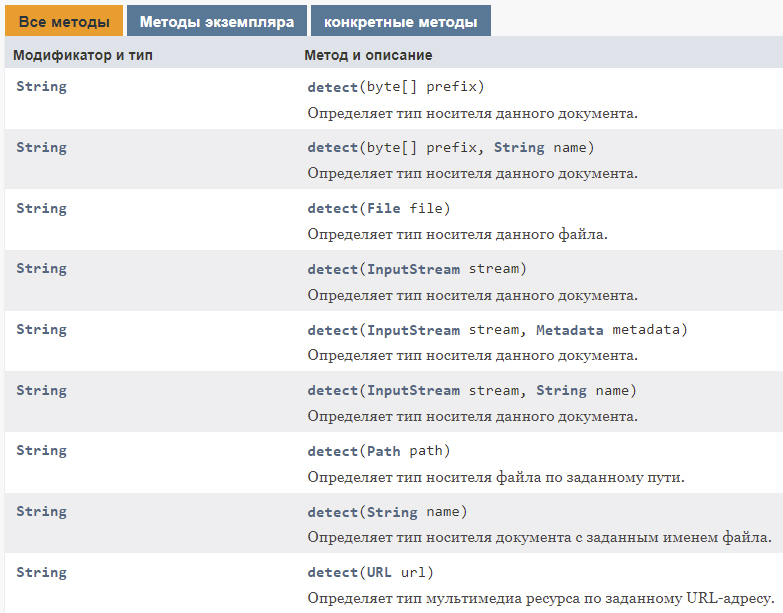
Усреднённый пример использования может выглядеть примерно так:
public String parseToStringExample() throws IOException, SAXException, TikaException {
Tika tika = new Tika();
try (InputStream stream = ParsingExample.class.getResourceAsStream("test.doc")) {
return tika.parseToString(stream);
}
}Плюс этого подхода заключается в том, что вы можете искать по ключевому слову, в нужной директории и среди множества абсолютно разных типов файлов!
Либо же (для большей гибкости) вы можете воспользоваться вызовом нужного типа парсера, коих, как вы можете видеть, имеется великое множество:
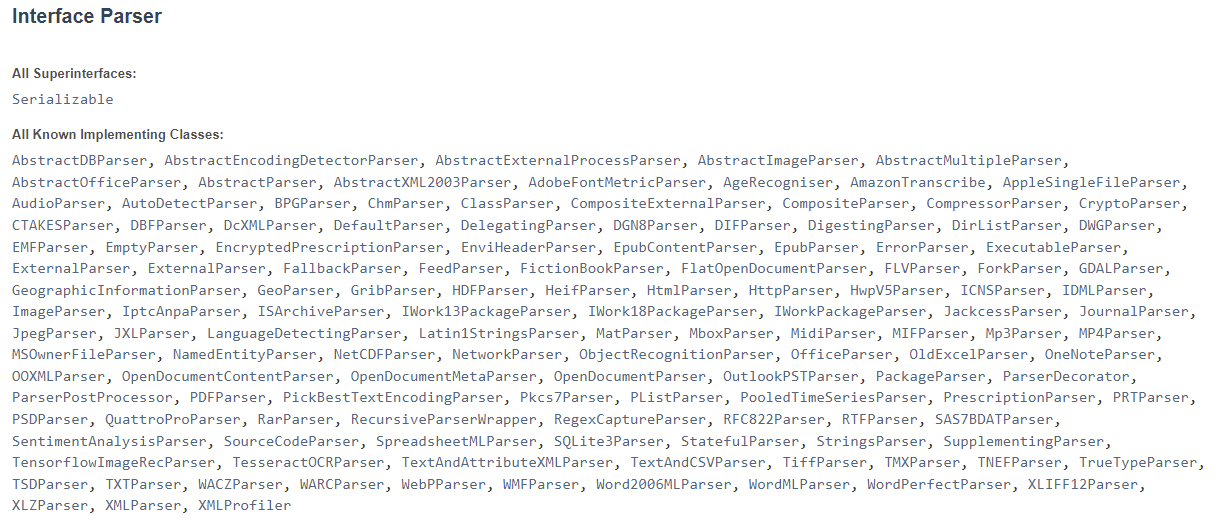
Например, использование AutoDetectParser-a выглядит следующим образом:
public String parseExample() throws IOException, SAXException, TikaException {
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
try (InputStream stream = ParsingExample.class.getResourceAsStream("test.doc")) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
}Как вы видели в приведённом выше примере, возврат прочитанного содержимого происходит в виде строки. Соответственно, далее мы можем распарсить строку и проанализировать её на содержание требующихся ключевых слов (это уже достаточно тривиальная вещь, поэтому, думаю, можно обойтись и без раскрытия этого момента).
Используя интерфейс ContentHandler, можно получать содержимое файлов в виде текста различных форматов.
Кроме того, проанализированный текст можно отправлять во внешнюю систему перевода и, соответственно, получать его в переведённом виде.
Если же вам заранее известен тип документа, который требует парсинга, то можно воспользоваться примерами вот отсюда и, например, прочитать содержимое PDF-документа:
import org.apache.tika.parser.pdf.PDFParser;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}Файла Excel:
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Текстового документа:
import org.apache.tika.parser.txt.TXTParser;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Чтение метаданных изображения:
import org.apache.tika.parser.jpeg.JpegParser;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Сценарии использования
На сайте проекта Apache POI в разделе Case Studies имеется достаточно большое количество интересных сценариев из жизни, которые разработчики собирают специально для мотивирования «новообращённых» пользователей библиотеки.
Например, показан способ использования библиотеки в стартапе, который занимается биометрическим сканированием посещаемости офиса. Данные сохраняются в виде отчёта Microsoft Excel.
Ещё одним интересным примером на эту же тему является использование библиотеки в ряде крупных торговых сетей. С её помощью они сделали более доступными данные о своих ценах. Запросы идут в базу на сервере в многопоточном режиме, благодаря чему множество пользователей могут одновременно и максимально оперативно получать самую свежую информацию прямо в браузере, в формате Excel-файла.
Также хороший пример — использование компонента POI HWPF на немецких железных дорогах, где с его помощью считывается содержимое спецификаций из устаревших ворд файлов и переводится в формат xml, благодаря чему в дальнейшем становится доступным отслеживание версий в многопользовательской среде, а также более удобное управление и обмен данными.
А что дальше?
Однако, зачастую требуется не только чтение содержимого документов, но и нечто большее. Например, развернуть настоящую поисковую систему.
И для этого мы можем воспользоваться следующим решением — Apache Solr, которое представляет из себя open source поисковую платформу, предназначенную как раз для осуществления полнотекстового поиска больших массивов текстовых данных и отличающуюся хорошей масштабируемостью и быстрым разворачиванием системы.
Более подробно об этой системе вы можете прочитать на русском языке вот здесь.
То есть пользователь может обратиться к ней через веб-интерфейс и система осуществит поиск среди индексированных данных и вернёт результаты обратно в веб-интерфейс. Причём данные могут быть возвращены в ряде форматов: JSON, XML, CSV или бинарном виде.
Также возможно обращение с помощью веб-приложений, мобильных устройств и т.д. — то есть с помощью любых способов, обладающих поддержкой HTTP.
Кстати говоря, рассмотренная выше библиотека Apache Tika также может быть использована как инструмент для предварительного извлечения содержимого документов в целях дальнейшего помещения их в Solr.
Напоследок хочется сказать, что многие программные решения покрывают большинство типовых задач, встающих перед пользователями, и для этой цели использование уже разработанного программного решения(й) или даже целой цепочки таковых видится наиболее рациональным.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Zara6502
Мне одному кажется что нужно не костыли городить, а нанять нормального руководителя способного структурировать работу подчинённых, которые будут вести базу знаний?
Я бы ушёл с такой работы в первый же день, "где-то там" XD на этой работе счастья не будет 146%.