
Предвидя проблему
Приступая к разработке прокси-сервиса на Oracle Service Bus, следует принимать во внимание условия использования этого сервиса. Например, если разрабатываемый процесс будет участвовать во множестве популярных операций или использоваться большим числом пользователей. В случае, например, запроса информации для первой страницы после логина пользователя на сайте следует сразу придерживаться соображений оптимального кода с точки зрения производительности.
В процессе написания трансформаций и всех обращений к путям внутри сообщения не поленитесь указать [1] после каждого узла в XPath
$Get_Client_Info_Output/ns1:ListOfContact[1]/ns1:Contact[1]/ns1:rName[1]
Это позволит обрабатывать выражение как обращение к единичным элементам структуры, а не к множественным, как это подразумевается в общем случае.
Если некоторые элементы, спрятанные в глубине структуры, используются в преобразованиях многократно, их значение стоит записать в переменную внутри трансформации XQuery, которой далее можно пользоваться:
let $name := $Get_Client_Info_Output/ns1:ListOfContact[1]/ns1:Contact[1]/ns1:rName[1]
В то же время в Message Flow следует избегать создания лишних переменных и желательно использовать
 , а не
, а не  , поскольку сама парадигма OSB приветствует именно трансформацию сообщения. Под каждую новую переменную будет выделяться память, что занимает время, а оптимизация ее расхода поможет и при оптимизации производительности.
, поскольку сама парадигма OSB приветствует именно трансформацию сообщения. Под каждую новую переменную будет выделяться память, что занимает время, а оптимизация ее расхода поможет и при оптимизации производительности.Базовый процесс обработки сообщения (Message Flow) с точки зрения OSB – это вызов одного бизнес-сервиса с помощью
 (или подобных действий) и передача информации запрашивающей стороне с требуемыми преобразованиями. В таком случае обработка входящего потока до вызова бизнес-сервиса идет в одном потоке (Thread), после вызова поток возвращается в пул свободных, ответ бизнес-сервиса обрабатывается в другом, новом, потоке, получаемом из пула. При таком процессе блокировок и простоя потоков не возникает.
(или подобных действий) и передача информации запрашивающей стороне с требуемыми преобразованиями. В таком случае обработка входящего потока до вызова бизнес-сервиса идет в одном потоке (Thread), после вызова поток возвращается в пул свободных, ответ бизнес-сервиса обрабатывается в другом, новом, потоке, получаемом из пула. При таком процессе блокировок и простоя потоков не возникает.Если же без дополнительных вызовов с помощью
 не обойтись, Service Callout следует отдать быстрые легковесные запросы, понимая, что каждый вызов Service Callout потребует выделения для него отдельного потока из пула, а основной поток в это время будет простаивать. При таком подходе возможны блокировки, и для их избежания можно воспользоваться отдельными пулами потоков, предоставляемыми механизмом Work Manager. О Work Manager расскажем чуть позже.
не обойтись, Service Callout следует отдать быстрые легковесные запросы, понимая, что каждый вызов Service Callout потребует выделения для него отдельного потока из пула, а основной поток в это время будет простаивать. При таком подходе возможны блокировки, и для их избежания можно воспользоваться отдельными пулами потоков, предоставляемыми механизмом Work Manager. О Work Manager расскажем чуть позже.?
Столкнувшись с бедой
В процессе эксплуатации наш идеально написанный прокси-сервис стал тормозить, люди заходят на сайт целую вечность, расстраиваются и идут громить сервисную шину.
Не всегда шина бывает виновата в медленной работе, под бизнес-сервисами лежат реальные системы, и они могут тяжело и неповоротливо обрабатывать запросы. Уличить их в таком негативе просто. Достаточно воспользоваться механизмом Pipeline Monitoring. Он включается для прокси и бизнес-сервисов во вкладке Operational Settings -> Monitoring -> Enable Pipeline Monitoring at (выберите Service) level or above
Выбор параметра Aggregation Interval отвечает периоду времени, за которое с текущего момента будут записываться и усредняться данные. Для мониторинга промышленного решения можно выбирать большие интервалы – сутки и более, для нагрузочного тестирования – сопоставимые со временем теста.
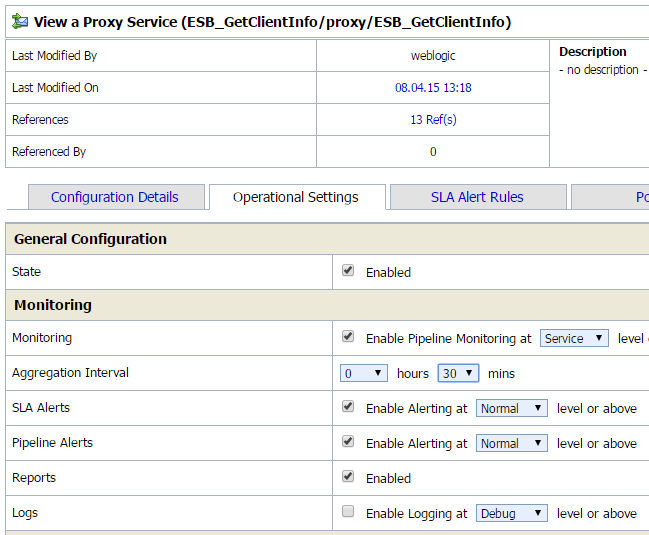
При этом для ускорения работы следует отключать логирование как внутри сервиса с использованием
 , так и внешнее – во вкладке Operational Settings. Логи не только расходуют много места в промышленной системе, но и существенно тормозят процесс и могут даже вызвать блокировки потоков.
, так и внешнее – во вкладке Operational Settings. Логи не только расходуют много места в промышленной системе, но и существенно тормозят процесс и могут даже вызвать блокировки потоков.Результаты включенного мониторинга можно увидеть в экране Operations –> Service Health
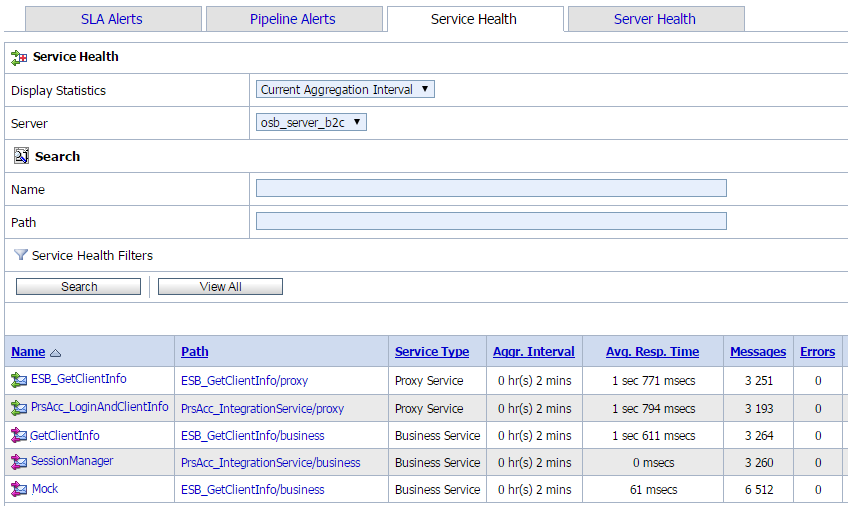
На приведенном скриншоте мы видим, что вызов SessionManager выполняется почти мгновенно, что не удивительно – ведь это небольшое Java-приложение, развернутое в том же домене WebLogic. Бизнес-сервис Mock в среднем выполняется за 61 миллисекунду, а вот GetClientInfo требует больше полутора секунд – это большое бизнес-приложение с большим количеством данных, тут придется повозиться, чтобы ускорить запрос. На фоне таких таймингов задержки, вносимые OSB, минимальны.
Но если надо быстрее
Мастер развертывания OSB спросит, устанавливать ли приложение в промышленном режиме, не будем отказываться от заводских оптимизаций, а после установки первым делом дадим OSB-серверу побольше памяти, оставив операционке гигабайт, остальным managed-серверам – по потребностям, и выставим начальную и конечную память одинаковым значением
-Xms10G -Xmx10G.
Остальные параметры – настройки MaxPermSize или Garbage Collector – не дадут существенных приростов производительности.
Второй существенный механизм, который может спасти тонущие в потоке запросов сервисы, – Work Manager. Зайдите в консоль WebLogic, выберите Environment -> Work Managers.
Создайте отдельные Work Manager для самых популярных прокси-сервисов, особенно для тех, которые используются другими сервисами в Service Callout, укажите Minimum Threads Constraint, например 40 (это число подбирается в ходе нагрузочных тестов) и поставьте галочку Ignore Stuck Threads. Это является нормальным для OSB и рекомендуется вендором.
А если наши бедные популярные прокси-сервисы тонут настолько, что оказывают влияние на остальные интеграционные процессы, которым не хватает ресурсов, стоит рассмотреть использование Work Managers с параметром Capacity Constraint – они не дадут выполняться одновременным запросам больше указанного числа. Превышающие запросы будут отброшены без обработки.
Назначьте созданные Work Manager прокси-сервисам OSB. Work Manager выбирается в разделе HTTP Transport Configuration -> Dispatch Policy
Нагрузим
Вместо заключения отметим, что без нагрузочного теста тюнинг производительности провести непросто, на работающей промышленной системе не поиграешь с параметрами. Существует много продуктов для выдачи нагрузки на веб-сервисы. В качестве начального стоит порекомендовать SOAP-UI, он способен дать достаточное количество запросов для отслеживания результатов настройки. Если же нужны более продвинутые решения – HP Load Runner или Oracle Application Testing Suite – они потребуют временных затрат на то, чтобы с ними разобраться, и возможно, нужно будет попросить профессионального тестировщика написать для вас тест, пока вы проставляете [1] после каждого узла в XPath.
Мы будем рады вашим конструктивным комментариям.
Комментарии (5)

Throwable
28.10.2015 12:17Хотелось бы знать, какова реальная необходимость в решении типа «прокси-сервис на Oracle Service Bus»? Все в поверпоинтах выглядит красиво, и картинка с архитектурой ESB тоже очень понятная и логичная. Клиент ненарадуется, что не зря потратил деньги.
В реале же к корпоративным сервисам добавляется тяжелый слой ввиде дорогого софта с командой разработчиков по его обслуживанию. Помимо того, что это вносит дополнительные проблемы с взаимодействием систем, ESB делает противоположную вещь для чего изначально предназначена: команда ESB должна знать все в деталях о всех интерфейсах всех систем всех используемых версий. Где же тут обещанный decoupling? В итоге если изменился интерфейс между двумя внутренними системами, приходится еще умолять команду ESB вставить изменения.
jetinfosystems
28.10.2015 16:28Я успел сменить дважды отношение этому вопросу.
Когда только начинал работу на шине — восторг и веру в поверпоинты и картинки.
Через пару лет, оно сменилось и совпадало с Вашим!
Но еще через пару лет в результате очередного переосмысления, пришло понимание, что команды Систем всячески отказываются от принятия несколько несвойственных им функций. Так шина может приютить такие нестандартные требования, как менеджер сессий сайта к CRM системе. Или предоставить адаптер отсутствующий в Системе, например SMPP или LDAP.
Но это еще не все, часто внедрение Систем идет параллельно — и интегрировать в процессе разработки не с чем. Тут шина может дать заглушки, которые перерастут в полноценные прокси-сервисы. А так же внедренцы Систем обычно не уделяют должного внимания интеграции — в этом случае аналитик шины может играть роль двигателя и координатора процесса.
Так, что шина часто играет не только системную, а социальную роль.Throwable
29.10.2015 12:42Это хорошо, если на ESB сидит интегратор, который планирует архитектуру, интерфейсы и интеграцию между системами. В проектах, в которых я работал, ты сам разрабатываешь интерфейс и отсылаешь свой WSDL команде ESB, которые коряво его проксят и расставляют глючные меппинги и потом упираются что-либо изменить. Заглушки для локальных тестов всегда делаем сами mock-ами — так надежнее, и не надо ждать пока ESB пошевелятся.
Я работал плотно со стеком IBM Websphere, поэтому у меня такое пессиместичное мнение. Сейчас клиент пользует OSB, а вся архитектура сервисов построена на SOAP. Но методологически ситуация не изменилась: команда ESB ничего не планирует, ни за что не отвечает, и играет роль такого ненужного звена в цепочке интергации. Плюс ко всему прочему зачастую плохо владеет продуктом. От любой проблемы отнекиваются: типа ошибки в ваших системах, плохо посылаете и разбирайтесь сами между собой.
Пример: клиент долго требовал от нас логгировать SOAP-месседжи, которыми мы обмениваемся со сторонними системами. На агрументы типа, что это 120% задача ESB, он говорил, что ему будет проще видеть все в наших логах, нежели каждый раз просить ESB достать месседж.
mousus
Помимо тюннинга WorkManager ещё какой то тюннинг Java контейнера применялся? Тюннили параметры работы с сетью (неблокирующий муксер, колличество соединений)? На какой JVM и под какой ОС работаете?
jetinfosystems
Еще пробовали тюнить Garbage Collector, но не заметили разницы. Сети не касались. Работает на JRockit + Linux