
Меня зовут Якупов Азат, я дата-архитектор Quadcode, и с вами продолжение саги о типах таблиц в PostgreSQL. В этой части речь пойдёт про кластеризованные, внешние, партицированные и наследуемые таблицы. Посмотрим на примеры их создания, области применения, плюсы и минусы их использования.

В предыдущих сериях
Этот материал — часть серии, посвящённой Postgres. В прошлых материалах мы разбирали:
Clustered tables — кластеризованные таблицы
Мало кто любит хаос, всем нравится порядок. В рамках реляционных баз данных понятие хаоса тесно переплетено с хранением информации, потому что на протяжении своего жизненного цикла таблица постоянно видоизменяется.
В процессе работы с РСУБД на уровне диска происходит постоянное изменение содержимого таблицы. Например, вы обновили данные и ваша обновлённая строка попала на другую страницу таблицы (тут надо оговориться про FILLFACTOR) с появлением мёртвой записи (dead tuple) в текущей позиции. Затем autovacuum-процесс удалил мёртвую запись, и освободившийся слот заполнился вновь поступившей строкой. Простой тест, который вы сами можете провести. Сделайте следующие команды в обычную вновь созданную таблицу:
INSERT INTO test(id,name) VALUES(1, 'Петр');
INSERT INTO test(id,name) VALUES(2, 'Иван');
INSERT INTO test(id,name) VALUES(3, 'Сергей');После выполнения SQL запроса (прошу заметить, тут нет ORDER BY):
SELECT *
FROM test;Вы увидите ожидаемую картину:
id |
name |
1 |
Петр |
2 |
Иван |
3 |
Сергей |
Но сделав обновление строки
UPDATE test
SET name = 'Руслан'
WHERE id = 2;и затем выполнив тот же самый SQL, вы получите:
id |
name |
1 |
Петр |
3 |
Сергей |
2 |
Руслан |
Порядок строк изменился! Энтропия выросла.
А теперь представьте, что вы ищете в таблице данные, например, цифру 4. Как это сделать в рамках хаотической зелёной топологии, которую я нарисовал ниже слева? Только перебирая запись за записью: вы случайно тыкаете в какой-то номер и сравниваете его с нужной цифрой 4. По сути, придётся перебрать все записи, потому что цифр 4 может быть несколько. Другими словами, нужно последовательное сканирование.

Но когда у вас есть порядок, как в таблице справа, вы будете четко знать, что цифра 4 лежит между 3 и 5. В этом весь смысл организации порядка и кластеризованных таблиц: они помогают создать упорядоченную структуру из хаоса. Если вы произвольно выбираете случайную позицию в упорядоченной синей таблице в поисках цифры 4, то возможны три исхода:
Число равно нужному.
Число меньше нужного.
Число больше нужного.
Это даёт большое преимущество в скорости выполнения поиска. Если число больше 4, вы дальше пойдёте в поисках вверх по таблице. Если меньше — пойдёте вниз. Или вы сможете получить диапазон и искать цифру 4 внутри него. Это гораздо быстрее, чем поиск по всем данным, как было в неорганизованной зелёной топологии — а именно в логарифм раз быстрее.
Рассмотрим пример создания кластеризованной таблицы:
CREATE TABLE test.cluster_table
(id INTEGER,
name VARCHAR) WITH (FILLFACTOR = 90);
CREATE INDEX id_idx ON test.cluster_table (id);
CLUSTER [VERBOSE] test.cluster_table USING id_idx;Здесь я создал таблицу с названием cluster_table и установил для неё значение FILLFACTOR в 90% — это процент заполняемости. Он никак не влияет на нашу кластеризованную таблицу, это просто пример того, как можно установить свойство при создании таблицы этого типа. Дальше создаю BTree индекс на таблицу CREATE INDEX на поле id и вызываю команду CLUSTER. Команда CLUSTER делает кластеризацию таблицы, используя индекс, который мы предварительно создали.
Здесь важно знать, что пока кластеризация не пройдёт до конца, все текущие транзакции в таблице будут заблокированы. Блокировка трафика происходит потому, что Postgres пытается перестроить таблицу в том порядке, который вы требуете на основании индекса. И после создания этого порядка Postgres должен сохранить его в другой файл. По сути, это операция миграции данных на уровне диска с одного файла в другой, но только в указанном порядке. Данные должны размещаться на основании индекса, в нашем случае по полю id. Я образно показал это на рисунке ниже, обратившись к метаданным до и после выполнения кластеризации таблицы.
Изначально таблица размещалась в файле с номером 45969. После команды CLUSTER имя файла поменялось. Произошло перемещение данных из одного файла в другой. Поэтому происходит блокировка, и, соответственно, входящий трафик не может использовать эту таблицу до тех пор, пока она не станет доступна.

Вы можете также создать индекс для последующей кластеризации, который содержит много столбцов (multicolumn index), либо указать убывающий порядок по тем или иным столбцам (DESC / ASC).
Можно по желанию использовать команду CLUSTER VERBOSE, которая возвратит детализацию того, что сделал PostgreSQL, а именно сколько было страниц, какие страницы были перемещены и так далее.
Тест-кейсы и порядок в данных
Проведём небольшой тест:
CREATE TABLE test.cluster_table
(id INTEGER,
name VARCHAR) WITH (FILLFACTOR = 90);
CREATE INDEX id_idx ON test.cluster_table (id);
INSERT INTO test.cluster_table
SELECT (random( )*100)::INTEGER,
'test'
FROM generate_series(1,100) AS g(i);
SELECT id
FROM test.cluster_table;Создадим таблицу, индекс по полю id и затем сгенерируем 100 произвольных строк, используя команду generate_series. В результате получились неупорядоченные данные:
id |
26 |
71 |
20 |
... |
12 |
49 |
Чтобы добиться порядка при выводе, надо добавить ключевое слово ORDER BY. Но здесь важно помнить, что операция ORDER BY тоже требует ресурсов и за неё следует заплатить. Каждая наносекунда на счету при высоконагруженном трафике, а тут ещё сортировка.
В этом случае давайте сделаем кластеризацию таблицы командой CLUSTER VERBOSE, используя индекс, который я заранее создал:
CLUSTER VERBOSE test.cluster_table USING id_idx;
SELECT id
FROM test.cluster_table;Вуаля, данные отсортированы без сортировки:
id |
1 |
2 |
3 |
... |
98 |
99 |
Но здесь есть ловушка. Сделаем обновление всех строк — а на самом деле достаточно изменить значение у одной строки.
UPDATE test.cluster_table
SET id = id * (random( )::INTEGER);
SELECT id
FROM test.cluster_table;В нашу кластеризованную таблицу при этом вернётся хаос:
id |
34 |
0 |
51 |
... |
68 |
93 |
Чтобы вернуть порядок обратно, потребуется снова выполнить команду CLUSTER. Можно даже не указывать повторно индекс, потому что он сохранился в метаданных PostgreSQL. И база данных в следующий раз будет понимать, на основе чего вы делаете кластеризацию:
CLUSTER VERBOSE test.cluster_table;
SELECT id
FROM test.cluster_table;Вы сможете снова наблюдать порядок только после команды CLUSTER. Это ахиллесова пята кластеризованных таблиц: любое изменение ключа кластеризации может сразу принести беспорядок в данные.
Когда подойдёт кластеризованная таблица
Кластеризованные таблицы подойдут, если ваши данные — это таблицы-справочники (ну или SCD — Slowly Changing Dimension), например адресная система. Этот тип таблиц удобен в случае, если вы загружаете новые данные достаточно редко, например, раз в месяц.
Если таблица очень часто меняется и подвержена INSERT-, UPDATE- и DELETE-операциям, кластеризовать её придётся постоянно, а это не очень удобно и вообще критично. Цель кластеризации — избегать ненужных ORDER BY в постоянных запросах к таблице по кластеризованному полю или полям.
Метаданные кластеризованной таблицы
По метаданным кластеризованной таблицы можно понять, что она кластеризована:
SELECT c.oid AS "OID",
c.relname AS "Relation name"
FROM pg_class c INNER JOIN pg_index i ON i.indrelid = c.oid
WHERE c.relkind = 'r' AND
c.relhasindex AND
i.indisclustered;OID |
Relation name |
45969 |
cluster_table |
Значение “true” в поле relhasindex указывает, что есть индекс для поддержки кластеризации. Когда мы перестроим кластер в следующий командой CLUSTER, то PostgreSQL будет использовать указанный индекс из метаданных.
Foreign tables — внешние таблицы
Внешние таблицы в PostgreSQL полезны с точки зрения быстрого получения данных из другого источника, если у вас есть возможность к нему присоединиться. Кроме того, если повозиться, то можно обеспечить так называемый жизненный цикл данных — обеспечить метрику Retention Policy. Здесь вам может помочь следующий набор инструментов: VIEW ( виртуальная таблица) + набор обычных таблиц, разделённых логикой сохранения данных (POOD-дизайн) с актуальными данными + внешние таблицы, которые ориентируются на файлы, хранящие данные вне базы данных на более дешевых дисках (тут как раз старые данные, превысившие метрику Retention Policy).
Внешних таблиц и типов соединений — много, например:
CSV-файл.
Соединение со многими другими РСУБД.
Соединение с некоторыми noSQL БД.
Рассмотрим пример внешней таблицы, основанной на CSV-файле. В этом нам поможет расширение file_fdw, основанное на fdw — foreign data wrapper:
CREATE EXTENSION file_fdw;
CREATE SERVER csv_log FOREIGN DATA WRAPPER file_fdw;
CREATE FOREIGN TABLE test.csv (
id INTEGER,
name VARCHAR
) SERVER csv_log
OPTIONS (filename '/var/lib/postgresql/file.csv',
delimiter ';', format 'csv');Создаю внешнюю таблицу и описываю атрибуты, указывая сервер для fdw, который заранее создал с опциями работы с файлом.
Если я сделаю SQL-запрос к внешней таблице, то увижу данные, которые представлены в файле. Так как внешняя таблица зарегистрирована (в смысле имеется запись в метаданных PostgreSQL), то у меня возникает гипотеза: а не хранятся ли данные не во внешнем файле, а в файле данных PostgreSQL?
SELECT oid AS "OID",
pg_relation_filepath(oid) AS "File path",
pg_relation_size(oid) AS "Relation Size"
FROM pg_class
WHERE relname = 'csv';Результат выполнения:
OID |
File path |
Relation size |
46003 |
null |
0 |
Итак, внешняя таблица как объект зарегистрирована в метаданных (имеется OID идентификатор объекта), но вот соответствующего файла данных нет, то есть данные представлены только во внешнем источнике.
Запросы к внешним таблицам
Каким образом работают запросы к внешним таблицам? Посмотрим на примере CSV-файла.

Пока данные подгружаются, происходит достаточно длительная задержка по времени, поэтому храним старые данные где-то на старых дисках. Для получения данных надо открыть дескриптор внешнего файла, потом скопировать данные в память или во временный файл и вернуть данные нам. Если мы чуть позже перевыполним тот же запрос, то ускорения не предвидится: процесс остается аналогичным.
Существует великое множество библиотек внешних таблиц для разных нужд. Например, postgres_fdw. С её помощью мы можем соединяться с PostgreSQL из PostgreSQL. Это очень сильно напоминает database link:
CREATE EXTENSION postgres_fdw;
DROP FOREIGN TABLE test.csv;
CREATE SERVER pg_log FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '192.168.56.10', port '5432', dbname 'course_db');
CREATE USER MAPPING FOR test SERVER pg_log
OPTIONS (user 'test', password 'test');
CREATE FOREIGN TABLE test.csv (
id INTEGER,
name VARCHAR
) SERVER pg_log
OPTIONS (schema_name 'test', table_name 'user');Огромное количество библиотек доступно для работы с внешними источниками. Например:
Oracle, MySQL, SQLite, MS SQL Server, Sybase.
Cassandra, MongoBD, HBase, Redis, Neo4j.
Twitter, Telegram.
JSON, XLM, GeoFiles, LDAP.
Метаданные внешней таблицы
Как мы выяснили, внешняя таблица как объект фиксируется в метаданных:
SELECT oid AS "OID",
relname AS "Relation name",
CASE
WHEN relpersistence = 'p' THEN 'Permanent'
WHEN relpersistence = 't' THEN 'Temporary'
ELSE 'Unlogged'
END AS "Type",
relkind AS "Subtype"
FROM pg_class
WHERE relname = 'csv';OID |
Relation name |
Type |
Subtype |
46003 |
csv |
Permanent |
f |
Она является постоянной таблицей (удивительно), но у неё имеется указатель “f” — это подтип отношения. И он указывает, что-то наша таблица — foreign, то есть внешняя.
Partitioned tables — партицированные таблицы
Смысл партицированных таблиц лучше всего характеризует крылатое выражение «разделяй и властвуй». Вносить изменения в большую монолитную таблицу реляционной базы данных тяжело и больно из-за ACID. Если вы хотите сделать изменения структуры, например добавить новый столбец, то вся большая таблица заблокируется, пока столбец не будет добавлен. Грубо говоря, файл, который соответствует этой таблице, должен быть перестроен.
В этом случае разделение на партиции, на части данных — это как раз механизм «разделяй и властвуй». Управлять конкретными частями легче, чем монолитом. Это пример а-ля микросервисной архитектуры на уровне баз данных: каждая часть ничего не знает о других. Партиции управляются координатором, а координатор — это мастер-таблица или хаб-таблица, которая распределяет входящие данные между частями:

Политики работы с партициями
Есть три основные политики работы с партициями в реляционных базах данных:
Партицирование по списку.
Партицирование по диапазону.
Партицирование по хешу.
Вы можете партиционировать данные по списку. Например, положить в одну партицию данные по городам Казань, Москва, Мурманск, в другую — данные по Новгороду, Петербургу и Набережным Челнам, а в третью — по Иркутску, Самаре и Новосибирску. Тем самым у вас будут разделены части данных по ключу партиции, который соответствует списку этих значений. На рисунке я указал распределение данных, потому что это очень важно в рамках нагрузок на конкретную партицию.

Партицированные таблицы — это шаг к шардированию таблицы, когда разделение данных таблицы происходит между серверами. Партиция — это разделение таблицы на уровне одной базы данных или вертикально, шардирование — это разделение между базами данных или горизонтально.
Если вы неправильно выбрали ключ партиции, другими словами неправильно в своём логическом дизайне разделили данные, то эта логика может сильно влиять на физический мир использования ваших данных. Например, большее количество записей по [Казани, Москве и Мурманску], чем записей по [Новгороду, Набережным Челнам и Петербургу]. С точки зрения работы с данными это означает, что с большей частотой будут приходить SQL-запросы, нагружающие первую партицию больше, чем остальные.
Как раз для такого уровня разделения есть понятие хеша или хеш-функции, которая равномерно «размазывает» данные по партициям. Тем самым у вас снимается вопрос по распределению данных. Но и здесь есть свой минус — при распределении по хэш-функции вы можете делать поиск на равенство по партицированному ключу, чтобы добиться оптимизации.
Есть и другие стратегии разделения данных на партиции. Они являются гибридными: либо одновременно по диапазону и хэшу, либо по списку и диапазону.

Примеры создания партицированных таблиц с разными политиками
Партицирование по диапазону. Создадим разделённую по диапазону таблицу part:

К ней я добавляю две подчинённые таблицы: part_1 и part_2, которые являются партициями для моей основной таблицы. И указываю для них диапазон хранения: от 10 до 19 или от 0 до 9. Мой ключ распределения данных — это атрибут id. Если выполнится INSERT со значением id = 2, то он попадёт в part_2, если придёт INSERT со значением id = 12, то он попадёт в part_1. Обратите внимание, что число 9 и 19 не входят в правую границу диапазона (выколотая точка).
Партицирование по списку. Другой пример — разделение партиций по списку:

Тут уже нет никаких выколотых границ, список чётко регламентирует значения поля id.
Партицирование по хешу. Можно сделать партицирование по хешу:

Я создал две хеш-таблицы. Деление по модулю 2 должно вернуть либо остаток, либо его отсутствие. Хеш у меня рассчитывается с использованием функции PostgreSQL mod(Hash(id),2). Если ответом будет 1, то данные попадут в hash_2, если будет 0 — то в hash_1.
Партицированная топология. Можно создать партицированную топологию — партиции и подпартиции:

Под основной мастер-таблицей находится другая hub-таблица, которая в свою очередь разделяет данные по подпартициям.
Обратите внимание, что в одной из подпартиций есть слово DEFAULT. Оно означает, что эта подпартиция используется для нераспознанного значения партицированного атрибута, которое не подходит ни в один из списков других партиций. DEFAULT-партиция нужна для того чтобы, например, иметь буфер для возможных ошибочных данных, не предусмотренных или забытых в логике работы, чтобы в будущем стабилизировать ваш код. В противном случае, когда к вам придёт значение, не удовлетворяющее условиям всех партиций, то на уровне бэкенда вы получите «недоумение» от базы данных: «Я не знаю, куда его сохранять». Такие записи будут сохраняться как раз в DEFAULT-партицию.
Приведу пример хеш-топологии. Я делаю таблицу hash партицированной по hash(id) и создаю десять партиций с указанием модуля 10 и остатком от 0 до 9:
CREATE TABLE test.hash (id INTEGER) PARTITION BY hash(id) ;
CREATE TABLE test.hash_1 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 0);
CREATE TABLE test.hash_2 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 1);
CREATE TABLE test.hash_3 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 2);
CREATE TABLE test.hash_4 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 3);
CREATE TABLE test.hash_5 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 4);
CREATE TABLE test.hash_6 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 5);
CREATE TABLE test.hash_7 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 6);
CREATE TABLE test.hash_8 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 7);
CREATE TABLE test.hash_9 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 8);
CREATE TABLE test.hash_10 PARTITION OF test.hash
FOR VALUES WITH (MODULUS 10, REMAINDER 9);Визуально топология зависимостей будет выглядеть как на рисунке ниже.

С точки зрения работы с данными мы можем делать запрос к конкретной партиции с помощью SELECT * FROM hash_1 или сделать запрос напрямую к мастер-таблице test.hash.
Давайте создадим 200 000 строк, и вставим их в основную хаб-таблицу:
INSERT INTO test.hash (SELECT generate_series(0, 200000));Посмотрим, сколько теперь строк в нашей таблице:
SELECT count(*) FROM test.hash;Результат — 200 000. Но если я дополню запрос ключевым словом ONLY,
SELECT count(*) FROM ONLY test.hash;то у меня возвратится 0. Основная hash-таблица не содержит никаких строк. Она является «слоем», который перенаправляет данные в партиции на основании правила распределения.
Посмотрим, сколько данных у нас лежит в каждой партиции:
SELECT count(*), 'hash 1' AS "Name" FROM test.hash_1
UNION
SELECT count(*), 'hash 2' AS "Name" FROM test.hash_2
UNION
…
SELECT count(*), 'hash 9' AS "Name" FROM test.hash_9
UNION
SELECT count(*), 'hash 10' AS "Name" FROM test.hash_10Общее количество в 200 000 строк разделено +/- равномерно. Партицирование по хеш-функции как раз помогает достичь равномерной нагрузки на каждую из партиций:

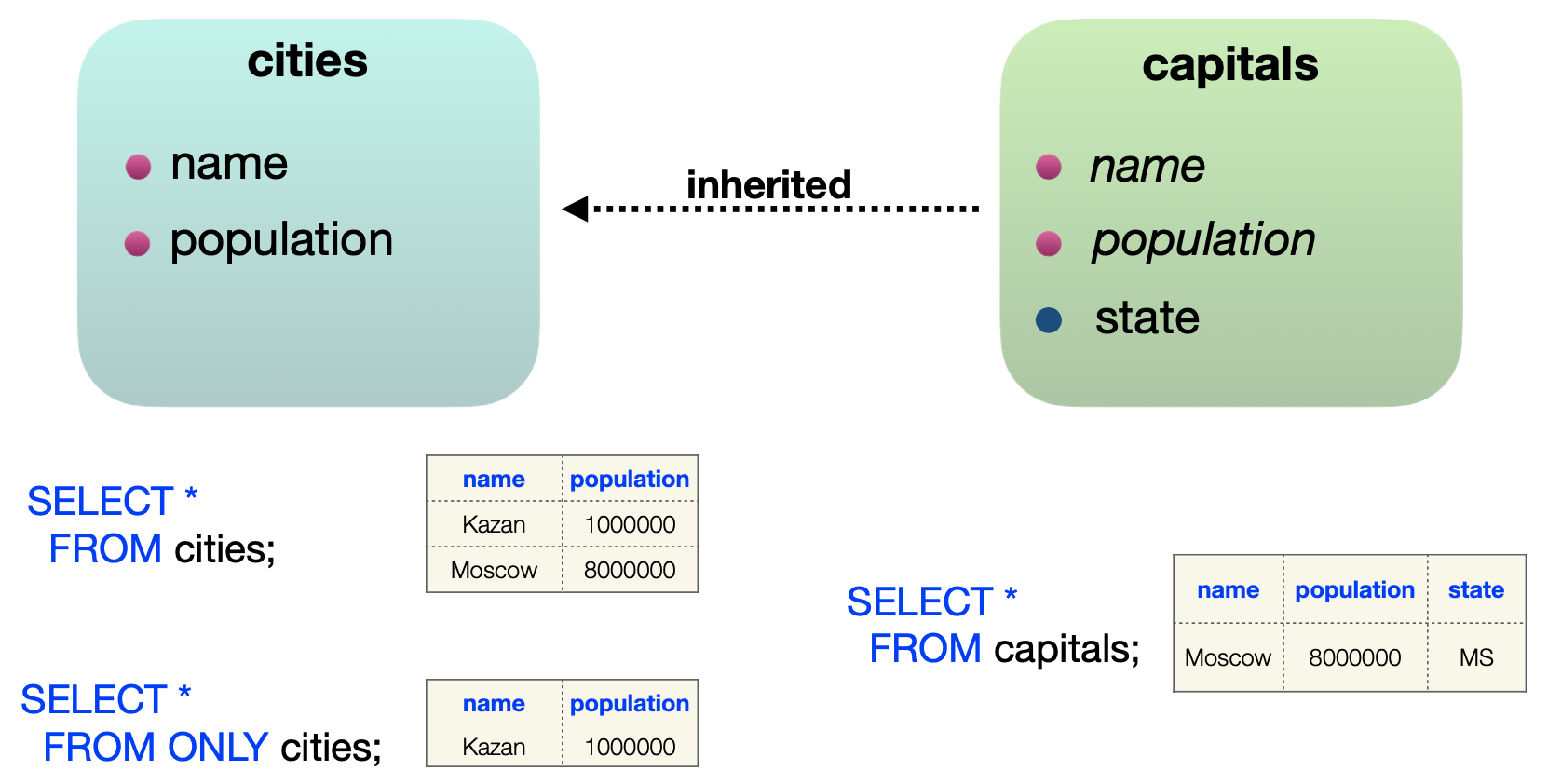
Inherited tables — наследуемые таблицы
Смысл наследуемой таблицы напрямую отражён в её названии. Например, у нас есть две таблицы: с обычными городами и со столицами. Столицы задаются тремя атрибутами: название, население и регион:
CREATE TABLE capitals (
name VARCHAR,
population INTEGER,
state CHAR(2)
);А обычные города задаются просто названием и количеством населения:
CREATE TABLE cities (
name VARCHAR,
population INTEGER
);Можно переделать данную модель в наследуемом стиле. Мы оставим таблицу «Города» без изменений и создадим обновлённую таблицу «Столицы». В «Столицах» сошлёмся на «Города», дополнив атрибут STATE:
CREATE TABLE capitals (
state CHAR(2)
) INHERITS (cities);Атрибуты, которые находятся в оригинальной таблице «Города», будут наследоваться на уровень зависимой таблицы «Столицы».
Посмотрим на INSERT. Например, вставим в обычные города Казань:
INSERT INTO cities
VALUES('Kazan', 1000000);и Москву, расширяя её дополнительным атрибутом “MS”:
INSERT INTO cities
VALUES('Moscow', 8000000, 'MS');Если я теперь обращаюсь к обычным городам, используя SELECT * FROM cities;, то в таблице будут представлены обе записи — Казань и Москва. Но если я дополню запрос словом ONLY, то мы увидим, что на самом деле в этой таблице хранится только одна строка — Казань. Вторая строка с Москвой находится в «Столицах», отдельной таблице, которая дополнена новым атрибутом.
Другой пример с распределением данных, используя наследуемые таблицы. Я создаю таблицу users и передаю все свойства этой таблицы для десяти наследуемых таблиц:
CREATE TABLE test.users (
id INTEGER,
name VARCHAR
);
CREATE INDEX idx_users ON test.users (id);
CREATE TABLE users_1 ( ) INHERITS (test.users);
CREATE TABLE users_2 ( ) INHERITS (test.users);
CREATE TABLE users_3 ( LIKE test.users INCLUDING ALL )
INHERITS (test.users);
…
CREATE TABLE users_8 ( ) INHERITS (test.users);
CREATE TABLE users_9 ( ) INHERITS (test.users);
CREATE TABLE users_10 ( ) INHERITS (test.users);У меня везде один код, кроме таблицы users_3. Для неё я написал, что нужно создать такую же таблицу, как users, но с указанием INCLUDING ALL. Эта очень полезная опция, если вы не хотите повторять атрибуты, комментарии, индексы и check constraints, которые у вас имеются на уровне таблички users. Остальные таблицы тоже созданы будут от аналога users, но индекс, например, наследовать не будут.
Получается следующая топология. В центре — таблица users, всё зелёное вокруг неё — это наследуемые таблицы. И только users_3 имеет наш индекс:

Если вы сделаете запрос:
SELECT *
FROM test.users
WHERE id = 1;то в случае, если вы не до конца настроили и оптимизировали вашу топологию хранения, у вас, по сути, получится 11 последовательных сканирований наследуемых таблиц. Последовательное сканирование начнётся с мастер-таблицы users, а затем по всем подлежащим таблицам до тех пор, пока не найдётся id = 1.
Хранение данных без оптимизации запросов — это просто обидно. Возникает вопрос: зачем мы создали всё это?
Но выход есть! Мы можем для каждой таблицы определить соответствующий диапазон хранения данных через check constraint:
ALTER TABLE test.users_1 ADD CONSTRAINT partition_check
CHECK (id >= 0 and id < 100000);
ALTER TABLE test.users_2 ADD CONSTRAINT partition_check
CHECK (id >= 100000 and id < 200000);
…
ALTER TABLE test.users_10 ADD CONSTRAINT partition_check
CHECK (id >= 900000 and id <= 1000000);И убедиться, что
SHOW constraint_exclusion = on | partitionCheck constraint задаёт правило игры для сохранения консистентности данных в рамках таблицы. В нашем случае check constraint важен также для указания базе данных диапазона хранения идентификаторов в конкретных зависимых таблицах.
PostgreSQL понимает, что существующее правило указывает диапазон данных и нет смысла ходить в users_2, users_3, … ,users_10 , так как check constraint явно указывает, что диапазон для id = 1 лежит в таблице users_1. И в поисках нужной строки оптимизатор направится туда.
Но тут надо отметить, что в процессе будут задействованы две таблицы: сканирование будет происходить по оригинальной таблице users и по наследуемой таблице users_1. PostgreSQL предполагает, что users тоже может хранить данные (зависит как вы в триггере укажете RETURN NULL; или RETURN NEW;).
Мы можем ещё больше ускорить процесс поиска, создав индекс на users_1. Это возможно потому, что вы можете контролировать каждую конкретную наследуемую таблицу, как и конкретную партицию. Можете проводить изменение структуры, создание и модернизацию индексов, добавление столбцов и всё, что удовлетворяет принципу «разделяй и властвуй».
Распределение трафика по наследуемым таблицам
Какие есть инструменты, чтобы распределять данные между подчинёнными таблицами? В партицированных таблицах это всё работает из коробки, но наследуемые таблицы нужно научить это делать.
Доступные подходы, для работы которых придётся немного повозиться:
Триггеры, которые определяются на таблицу (вернее триггер + триггерная функция).
Расширение pg_partman.
Объекты Database Rules (CREATE DATABASE RULE …).
Рекомендации по книгам
Напоследок хочу снова порекомендовать интересные книги.
“Database Internals” — Alex Petrov.
“Readings in Database Systems” — Peter Bailis, Joseph M. Hellerstein, Michael Stonebraker.
“PostgreSQL Notes for Professionals”.
“Understanding EXPLAIN”.
«Язык SQL. Базовый курс» — Е. П. Моргунов.
«Postgres изнутри» — Е. В. Рогов.
Комментарии (12)

erogov
22.08.2022 21:51+2Не писать ORDER BY, когда нужна сортировка — лютая дичь. Нельзя так делать, а тем более советовать делать.

azatyakupov Автор
23.08.2022 11:57Добрый день, Егор!
Спасибо за ваш комментарий!
Здесь я имею ввиду , что если таблица четко статическая (справочник) и не происходит обновление данных в ней или происходит очень нечастое контролируемое обновление (применяя CLUSTER...), то почему бы не воспользоваться физическим размещением данных в страницах в том порядке в котором нам необходимо выдать результат.
Полностью с вами согласен, если таблица обновляема часто, то без ORDER BY не обойтись.
erogov
23.08.2022 14:39+1Дело в том, что без ORDER BY порядок не гарантируется, даже если версии строк физически расположены именно так, как надо.
В случае последовательного доступа — ключевые слова для гугления: synchronized scans.
В случае индексного доступа — легко можно наступить не на тот индекс (например, построенный в обратном порядке). Ну и кроме того, при индексном доступе ORDER BY не несет никаких дополнительных расходов.
Это же азы.
azatyakupov Автор
23.08.2022 17:27да вы правы! спасибо за это уточнение! внесу корректировки в свои материалы
Позвольте здесь привести выдержку из документации относительно параметра synchronize_seqscans, отвечающий за синхронизацию обращений при последовательном сканировании больших таблиц.
В документации сказано "Когда он включён, сканирование может начаться в середине таблицы, чтобы синхронизироваться со сканированием, которое уже выполняется. По достижении конца таблицы сканирование заворачивается к началу и завершает обработку пропущенных строк. Это может привести к непредсказуемому изменению порядка строк, возвращаемых запросами, в которых отсутствует предложение ORDER BY. Когда этот параметр выключен (имеет значение
off), реализуется поведение, принятое до версии 8.3, когда последовательное сканирование всегда начиналось с начала таблицы. Значение по умолчанию —on".

onets
22.08.2022 23:03+1ООП в SQL, абалдеть…

Kuch
22.08.2022 23:57Интересно, конечно, дойдет ли до множественного наследования, интерфейсов, статических полей и т.д.

Ivan22
23.08.2022 02:22этому всему уже не первый десяток лет, массового использования нет, и не похоже что будет
azatyakupov Автор
23.08.2022 09:56добрый день!
да именно так, действительно этому подходу не первый десяток лет в PostgreSQL и лично для меня интересно продолжение этой истории. Не люблю сравнивать, но встретившись с функционалом в другой РСУБД с конструкторами / деструкторами / свойствами / членами класса и тд на промышленном проекте - действительно был впечатлен как это можно использовать.
Спасибо!
Ivan22
Кластеризованная таблица в постгресе уже лет 10 наверное существует, можно уже наконец сделать ее полноценной, как в нормальных субд. Тогда можно было бы ее использовать не только для статичных справочников, но и для супер эффективного merge join по отсортированным ключам для огромных таблиц.
azatyakupov Автор
спасибо за ваш комментарий! мне здесь нечего добавить и я с вами полностью согласен.
Portnov
Когда говорят "кластеризованная таблица" — имеют ввиду таблицу, данные в которой поддерживаются в определённом физическом порядке (сам способ хранения такой, что порядок нарушиться не может). Таких таблиц в постгресе нет и пока не предвидится. Называть то, что есть в постгресе "кластеризованной таблицей"... ну, это всё-таки слишком.
azatyakupov Автор
Добрый день!
спасибо за ваш комментарий и уточнение!
я опираюсь на команду CLUSTER TABLE ... и называю получаемую структуру - кластеризованной таблицей. С вами полностью согласен, что надо быть поосторожнее с терминами.