
Привет! Сегодня расскажем большую историю: как мы разработали корпоративную платформу отчётности и решили сделать её общедоступной и бесплатной.

Что мы сделали?
Свою собственную систему корпоративной отчётности с блэкджеком и... возможностью быстро создавать отчёты на основе вьюшек в БД, выгружать их в Excel в формате, нужном получателю, взаимодействовать с корпоративными сервисами шифрования данных и управлять разграничением доступа как на уровне объектов системы, так и данных.
Зачем мы это сделали?
Потому что захотели сделать лучше, чем было! Расскажем, как было у нас и наверняка до сих пор продолжается в других крупных компаниях.
Анализ данных и системы отчётности в нашей компании развивались больше десяти лет по трём направлениям:
Суровый SQL. В бизнес-подразделениях давно существуют команды специалистов со знанием SQL. У них есть права в корпоративном хранилище данных, выделенные там зоны — «песочницы» и собственные небольшие сервера БД. С этим богатством ребята пишут запросы, получают и анализируют результаты, выгружают их в Excel и передают коллегам или руководству. Классика!
Массовая отчётность. Тысячи сотрудников компании ежедневно используют отчётность фиксированной формы для решения повседневных бизнес-задач. Выгружают данные из корпоративного хранилища данных в Excel и некоторые платные или бесплатные системы отчётности и BI.
Настоящий BI. Данные на лету фильтруются, агрегируются и визуализируются с разной степенью интерактивности и взаимозависимости форм. Как сказали бы лет 15 назад: «Полный фарш!», мечта всех аналитиков, выполненная на развитых BI-платформах.
Что делать с первым направлением примерно понятно: вы анализируете запросы пользователей, создаёте таблицы-агрегаты, решаете вопрос управления конкурентной нагрузкой на СУБД. С хорошей промышленной СУБД под хранилищем (кстати, у нас такая) вы можете эффективно решить последнюю задачу стандартными механизмами СУБД. Правда, если хранилище начнёт расползаться по нескольким системам с разной архитектурой, возникнут новые проблемы. Спросите о них у ребят из любой крупной компании. Но об этом в другой раз.
С развитием BI всё тоже понятно. Пусть мы и не делали на него большой фокус, но план действий всегда представляли твёрдо и чётко: покупаете современные и дорогие BI-системы, внедряете их, собираете обратную связь от пользователей, подстраиваете инструментарий под их задачи, и всё будет супер.
А вот развитие массовой отчётности нас не радовало.
Но сначала — не о плохом. У этого вида анализа данных есть ряд особенностей, которые нужно учитывать при планировании его развития:
Максимальная массовость. Тысячи пользователей из всевозможных подразделений компании и самых далёких филиалов.
Сложившиеся практики. За пару десятков лет эволюции этого направления в нём выработались подходы и практики, которые нужно учитывать. Резать обычные рабочие бизнес-процессы огромной компании категорическими изменениями — плохая идея.
Требования информационной безопасности. Один из ключевых моментов в этой теме. Тысячам сотрудников приходится работать с корпоративными данными, и должности у них самого разного уровня. Грамотно разграничить доступ к данным и обеспечить их конфиденциальность — нетривиальная задача.
По старой-доброй традиции в нашей компании, как и во множестве других, массово используется одно очень популярное средство анализа данных. Пусть нас и просили не упоминать в статье проприетарные бренды, но писать на эту тему и не говорить об Excel невозможно. Поэтому мы упоминаем его уже в четвёртый раз. Он остаётся универсальным и мощным BI-средством несмотря на развитие самых разных BI-систем. Это данность, с которой глупо бороться.
Говорят, что отчётность в Excel — это что-то из прошлого века (по факту, кстати, правы), и настало время перемен. Мы не до конца с этим согласны. Менять нужно ситуацию с файловым хаосом. Испытываете сложности с управлением массовой отчётностью и организацией доступа к ней? Лучше устраните их, а не плодите новые трудности от новых инструментов анализа.
Люди хотят и будут использовать Excel, и им нужно оставить эту возможность. Если предложить им альтернативные инструменты, помогать им в их освоении — будет совсем восхитительно. Мы это даже как-то пробовали: стали использовать дорогое BI-средство корпоративного уровня для создания массовой отчётности, вели активную просветительскую работу, но пользователи всё равно предпочитали выгрузить отчёт в Excel и работать с ним там дальше.
Поначалу мы винили инерционность мышления, нежелание принимать новое, но потом пришли к выводу более простому и правильному: любая новая технология работы с массовой отчётностью должна быть удобной пользователю. Поэтому Excel и богатые возможности по предоставлению данных в этом формате обязаны быть по дефолту. Это база. Под богатыми возможностями мы имеем в виду способы формировать файл с данными в том виде, которые нужны пользователю, а не в формате плоской таблицы.
К этому фундаментальному требованию добавим ещё два:
Низкая стоимость владения.
Возможность точно реализовать любое требование, без необходимости прибегать к обходным путям.
Что мы имели на старте?
Система массовой пользовательской отчётности развивалась не один год и стала обеспечиваться несколькими системами, которые сопровождали и развивали разные подразделения компании:
Файлы Excel с интерфейсом выбора параметров отчёта, реализованным через VBA. Файлы упорядочивались в системе сетевых каталогов, доступ к которым управлялся Windows-доменом.
Отчёты на корпоративном портале, созданном на основе свободно распространяемой системы Jasper Server. Естественно, несколько доработанной: с удобными интерфейсами выбора параметров отчётов и с учётом требований информационной безопасности по разграничению доступа к данным.
Отчёты в дорогой проприетарной BI-системы промышленного класса с ограничением числа пользовательских лицензий. Сотрудники использовали её как параметризированное средство выгрузки Excel-файлов, а не как BI-систему. Хотя мы пытались объяснить, как лучше.
Сложности управления настолько разнородными системами понятны без лишних слов. Организационные трудности тоже: каждую систему поддерживало отдельное подразделение компании и понять, к кому обращаться при возникновении новой задачи — отдельный квест.
Это тяжёлое наследие нужно было унифицировать. Но просто взять и перевести всю отчётность на одну из имеющихся систем было нельзя — у каждой свои серьёзные недостатки. Нам нужно было что-то новое, и мы пришли к двум естественным вариантам: бесплатная система с ограничениями или платная. Но дорогая.
Оказалось, что платная система с нужным нам функционалом будет непозволительно дорогой. Платить за неё, чтобы люди пользовались ей как средством выгрузки Excel-файлов — печальная история. Обязательное обучение работе с новой системой — ещё более печальная.
Бесплатные системы тоже не порадовали. На этот раз широтой своих возможностей. Подстраивать рабочий процесс такой крупной компании, как Магнит, под эти ограничения было нельзя — слишком велика стоимость неудобных и рутинных операций.
Кроме того, и в бесплатных, и в платных системах не выполнялось одно из наших фундаментальных требований — возможность точно реализовать любое требование, без необходимости прибегать к обходным путям. Можно подумать, что если их не могут реализовать системы с многолетним мировым опытом, они у нас какие-то астрономические. Или надуманные, от которых и отказаться не жалко. Но нет: наши требования проистекают из нашего опыта, от которого нельзя отказаться. Вы бы отказались от всего, что много лет строили и чем пользовались в своих хранилищах данных и системах отчётности? Вот и мы не стали отказываться.
Самый простой пример такого требования: пользователь хочет фильтровать выборку по одному из бизнес-ключей (код, номер, название — текстовые поля). Он вставляет перечень этих ключей в соответствующее поле и запускает запрос. Обычно системы отчётности делают это с фильтрацией по данному полю, записывая в WHERE значения, которые указал пользователь. Для некоторых СУБД (у нас как раз такая) эффективнее, когда в запрос попадает перечень суррогатных числовых ключей, играющих важную роль в архитектуре БД. Нам всегда очень не хватало шага преобразования бизнес-ключей в суррогатные перед выполнением запроса — небольшой промежуточный шаг, сильно увеличивающий эффективность обработки запросов базой. И при высоком уровне нагрузки на СУБД это очень важная штука. Спойлер: в своей системе мы это предусмотрели.
Словом, мы пришли к третьему варианту — созданию своей системы массовой корпоративной отчётности. Несмотря на кажущееся безрассудство, это было продуманное решение. И если честно, выстраданное: его целесообразность была оправдана масштабами кампании, в которой мы собирались его реализовывать.
Что у нас получилось?
Система корпоративной отчётности, которая сегодня выступает центральным корпоративным порталом, обслуживающим тысячи пользователей практически из всех подразделений компании. Название родилось естественным образом — Магрепорт (уверены, объяснять этимологию вам не нужно ????). Мы перевели сюда ещё не всю отчётность компании, поэтому ежедневное количество выполняемых отчётов немного превышает тысячу, но этот показатель постоянно растёт. На пике мы прогнозируем до нескольких тысяч отчётов в день.

Магрепорт — портал отчётности, предназначенный для получения данных из реляционных БД и предоставления информации в удобном пользователю виде. Некоторые BI-системы используют собственные внутренние хранилища данных, для доставки информации в которые требуется организовывать отдельные ETL-процессы. Другие обращаются напрямую к БД при обработке запроса пользователя, выступая как бы пользовательским интерфейсом к БД. Бывают и реализующие оба подхода. Магрепорт реализует второй подход, поскольку считаем, что он надёжнее в работе с очень большими хранилищами. Да и реализовать его проще. Взаимодействие с СУБД осуществляется через JDBC.
Поскольку Магрепорт позиционируется как удобный интерфейс получения данных из хранилища, один из его главных элементов — богатая система переиспользуемых фильтров, основанных на справочниках хранилища. Это и иерархические фильтры, и фильтры с подсказкой вариантов выбора, и календарь, и фильтры с возможностью задания списка значений, который система переводит в список суррогатных ключей при формировании запросов к БД. Под переиспользуемостью мы имеем в виду создание системы фильтров, которые можно применить в множестве отчётов. Фильтры в рамках одного отчёта можно объединять при помощи логических операций.

Центральная задача системы Магрепорт — предоставление пользователю файла с нужными ему данными в формате Excel в требуемом представлении. Система позволяет задавать специфичный для каждого отчёта шаблон файла Excel, адаптируя формат представления данных под каждый конкретный отчёт. Есть базовый шаблон, в котором при помощи макроса автоматически создаётся сводная таблица на основе выгруженных данных. Разработчик задаёт несколько вариантов шаблонов выгрузки отчёта, указав используемый по умолчанию шаблон.
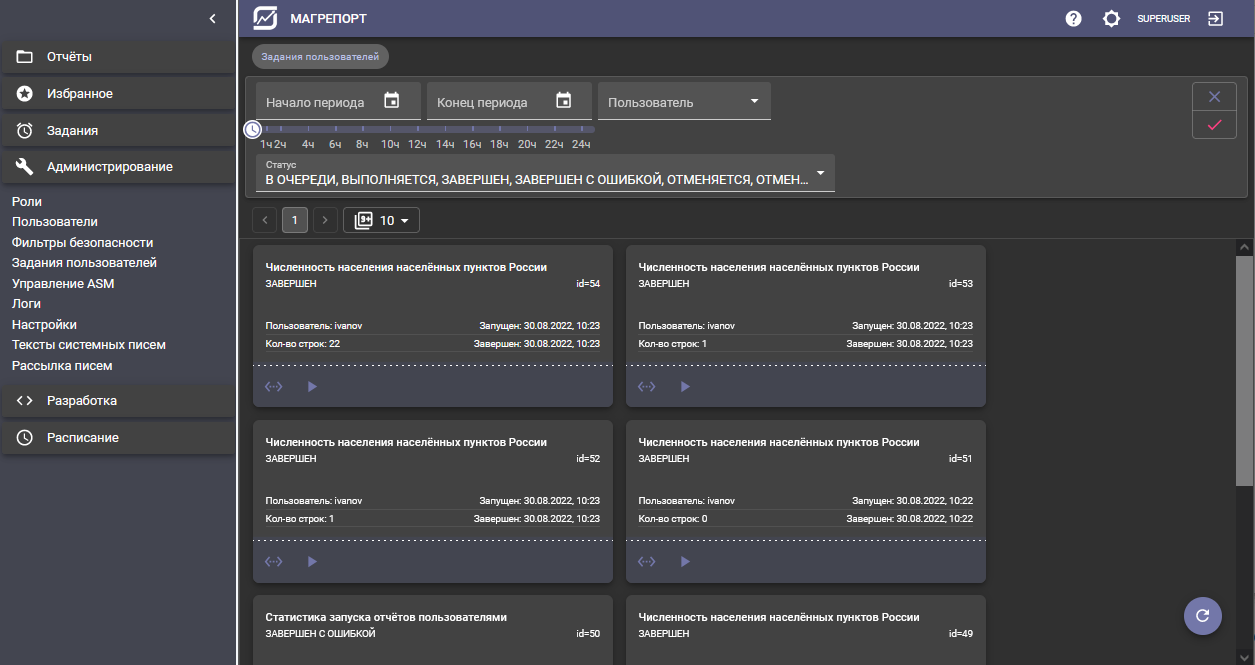
Выгруженные данные в Магрепорт хранятся в течение заданного временного интервала (указываемого администратором системы). В разделе Задания пользователю доступны ранее сделанные выгрузки. Каждое задание можно перезапустить, при этом в фильтры отчёта будут подставлены указанные для данного задания значения, которые можно скорректировать перед новым запуском. Запущенное задание выполняется вне зависимости от активности пользователя — состояние пользовательской сессии ни на что не влияет. То есть задание продолжит выполняться, даже если пользователь потеряет соединение с сервером или выключит компьютер. При следующем входе в систему после выполнения задания пользователю будут доступны результаты его выполнения.
Также реализована функция регулярной рассылки отчётов по почте, что традиционно для систем отчётности. Как вариант — отчёт можно не отправлять по почте, а просто добавить в выполненные задания пользователя — пользователь сможет самостоятельно получить готовый отчёт в системе.
При разработке системы мы сделали отдельный фокус на выполнение довольно высоких требований информационной безопасности. Мы, конечно, не банк, но в нашей компании уделяется высокое внимание к этой стороне информационных систем. Выполнили мы их на основе универсальных и простых в управлении решений. В итоге система выглядит следующим образом:
Есть 3 измерения предоставления прав: функциональные права (администратор, разработчик, пользователь); права на папки с объектами (отчёты, фильтры, наборы данных); права на данные. Все права предоставляются через соответствующие роли.
Они же выдаются ещё 3 способами: либо явно в системе, либо через доменную группу Active Directory, либо через специальный механизм автоматического управления безопасностью (ASM — automated security management), позволяющий импортировать информацию о правах пользователя из таблицы в реляционной БД. На последнем механизме остановимся подробнее.
Мы создали его для управления фильтрами безопасностями, позволяющими ограничить множество данных, доступных конкретному пользователю. Наше наиболее распространённое ограничение — по географическому признаку: при нём пользователю доступны данные только по географическим ареалам в зоне его ответственности. Число вариантов потенциальных ареалов велико, и управлять такими ограничениями вручную или даже через доменные группы Active Directory практически невозможно.
Однако если в компании существует разграничение зон ответственности, значит информация об этом ведётся в какой-то системе, позволяющей этим разграничением управлять. А уже из неё информация может быть получена в таблицу в БД. Именно на это и рассчитан механизм ASM — по данным из таблицы в БД он позволяет осуществить привязку пользователей к фильтрам безопасности с конкретными ограничениями. Впоследствии эти ограничения распространяются на все отчёты, в которых присутствуют фильтры из защищённых справочников.
Другим важным требованием информационной безопасности было требование криптографической обработки выгружаемых данных сторонним специализированным сервисом. Чтобы не мучаться в поисках сочетания API и архитектуры нашей системы, мы реализовали простой подход — перед отправкой пользователю файлы попадают в одну папку, а забираются уже из другой.
Вся необходимая дополнительная обработка производится на уровне стороннего сервиса, который самостоятельно забирает файлы из входящей папки и после шифрования размещает их в исходящей. Использование этого механизма позволило нам уйти от сложных, ресурсоёмких и крайне неудобных в использовании инфраструктурных решений с защищённым контуром — отдельным защищённым сегментом сети с терминальными серверами, не допускающим обмен файлами с рабочими ПК пользователей.
Наконец, мы всегда хотели сделать администрирование системы удобным и функциональным. С какими системами ни работали (даже с дорогими промышленными BI-системами), никогда не ощущали полной удовлетворённости от инструментария админа. Иногда даже самые простые вещи либо не были предусмотрены, либо выполнялись слишком сложно.
«Как посмотреть результат выполненного пользователем отчёта? Как посмотреть, с какими параметрами пользователь выполнял свой отчёт? Как посмотреть SQL ранее выполненного запроса? Как найти соответствующий запрос в базе?» — регулярные задачи администратора, вызывающие проблемы при работе с любой системой.
В нашей системе мы сделали панель администратора максимально удобной. В ней можно посмотреть выполненные пользователем задания, код запроса или параметров, с которыми выполнялся отчёт. Для быстрого поиска запросов в базе мы используем алиасы, содержащие идентификатор запроса. А при просмотре объектов можно просмотреть зависимые от него объекты. В самой же системе реализованы специальные статистические отчёты активности пользователя.
Мы понимаем: для кого-то не всё из этого актуально, а кто-то не нашёл функции, необходимые именно ему. Но по крайней мере мы надеемся, что те, чей опыт сопровождения отчётности на базе корпоративного хранилища данных напоминает наш, почувствуют тот же уровень комфорта при решении повседневных административных задач, что и мы.
А что под капотом?
Ничего хитрого: в качестве бэкенда — Java-приложение, основанное на фреймворке Spring с собственным репозиторием для метаданных на H2 (пока вполне хватает и, что важно, очень удобна в сопровождении — база — это просто файл рядом с приложением — легко делать бэкапы и проводить тестирование). Фронтенд на React (+ Redux) с использованием библиотеки React Material UI для визуальных компонентов. Нагрузка на сам сервер Магрепорт невысока, поэтому он не требователен к производительности железа.
Что дальше?
Мы планируем внедрить OLAP-кубы и развивать BI-функциональность. Да, изначально мы не замахивались на то самое третье направление из списка в начале статьи, но сейчас, особенно с учётом возникших проблем и рисков работы с иностранными продуктами, мы решились на это. Мы уже серьёзно продвинулись в этом направлении. Функционал кубов и сводных таблиц на их основе близок к стадии внедрения. К разработке остальной BI-функциональности, в первую очередь к визуализации данных, скоро подступимся.
Также думаем о реализации возможности создания отчётов на множестве наборов данных и возможности загрузки собственных данных в отчёт.
В будущем надеемся разработать мобильный клиент.
Для успешного осуществления всех этих планов мы хотим, чтобы Магрепорт стали использовать за пределами компании — сторонний опыт очень поможет продукту. Наш опыт построения хранилищ и эксплуатации BI-систем хоть и богат, но всё же однобок. Мы ждём свежий взгляд на продукт, новые идеи и ценные комментарии. Знаем же, что вы можете!
И вывод
Мы довольны тем, что сделали и в будущее смотрим с оптимизмом. Конечно, нам хватает объективности для здоровой самокритики — многое из сделанного можно сделать лучше, и мы внедряем обновления с новыми версиями системы. Ну и конечно регулярно правим баги — куда без этого.
Но главное — компания получила инструмент, полностью закрывающий потребности в работе с массовой отчётностью. Организационная неразбериха постепенно уходит в прошлое: теперь все знают, как и где правильно решать задачи, связанные с отчётностью.
С экономической точки зрения эффект огромен — мы потратили очень скромные ресурсы, а получили решение, бесконечно масштабируемое без оглядки на стоимость лицензий и оплату технической поддержки (и независимое от иностранных поставщиков — что весьма актуально). Более того: мы получили решение, развивающееся вместе с компанией и развивающее её в своей зоне ответственности. Такие дела!
Комментарии (15)

fakedup
31.08.2022 18:36Кто у вас занимается миграцией старой и созданием новой отчётности?
С точки зрения разработки продукт наверное интересный, а вот с точки зрения пользователя - я, например, как аналитик старался избегать работодателей, использующих собственные решения или ноунейм импортозамещение, потому что усилия, потраченные на освоение этих вещей, при поиске следующей работы окажутся выкинутыми впустую.

V_Sukhov Автор
31.08.2022 19:06Важный момент! Спасибо, действительно это интересный вопрос. Постараюсь осветить. Миграцией занимаемся в частности мы же, созданием новой отчётности занимаются разные подразделения. Пользователю действительно иногда приходится переходить с инструмента на инструмент, причём даже внутри одной компании, не говоря уже о смене места работы. И, конечно, это далеко не всегда вызывает бурю радостных эмоций - мы с этим встречались и мы это понимаем. Но у нас эволюция систем отчётности выглядела так, что массовый пользователь не был избалован какими-то очень удобными инструментами - была иностранная опенсорсная система отчётности, которую мы допиливали напильником, которая была крайне скудной по возможностям и неудобной и с которой пользователь просто бегом перебежал в Магрепорт, при том что мы палками их не перегоняли :-) Если говорить о возможности покупки системы на рынке, то отвлекаясь от финансовой составляющей, всё равно должен констатировать, что это не обязательно будет лучше для пользователя - мы преследовали цель сделать в том числе интуитивно понятную и простую в использовании систему. Показателен тот факт, что за 2,5 года эксплуатации тысячами пользователей мы только сейчас впервые организовываем корпоративные курсы по системе, и то потому что она стала обрастать новым более сложным функционалом. За эти 2,5 года по пальцам одной руки я могу пересчитать письма от пользователей с вопросом, как работать с Магрепортом, и во всех этих случаях пользователи удовлетворялись ответом "там всё интуитивно понятно". Это я не к тому, какая у нас замечательная система, а к тому, что мы обслуживаем огромную Компанию и нашим приоритетом является сделать так, чтобы всё работало надёжно и по возможности просто - где простота, там, как правило, и надёжность и эффективность. Конечно, при переходе в другую Компанию пользователи столкнутся с другими инструментами и, возможно, испытают от этого некоторые трудности. Но то же самое будет и при использовании любой покупной системы - их на рынке по крайней мере десятки и вероятность попасть на ту, которую ты использовал до этого, мала. В частности поэтому этот вопрос не является для нас приоритетным.

Sergei2003
31.08.2022 22:48Решение получилось масштабируемое. Интересно, сталкивались ли вы с проблемой ограничений на число строк в excel ? Допустим, используя pivot table, пользователю надо проанализировать данные, выполняя drilldown до уровня документа и его позиции. А это означает, что такие детальные данные уже должны быть в excel-файле - ведь excel-файл не выполняет подключение к БД. Это Java backend app “набивает” файл данными из субд, и затем «отдаёт» его пользователю вместе с pivot table над ними.
Если пользователь с полномочиями на большой регион выберет ещё и большой период времени для анализа, то при ваших розничных объемах максимальный миллион строк на листе в книге excel будет легко достигнут.
V_Sukhov Автор
01.09.2022 06:11О, да! Вы смотрите в корень :-) Это действительно серьёзная проблема - в Эксель не помещается более 1 млн строк и у нас действительно пользователи очень легко этот лимит превышают в своих выгрузках, соответственно отчёт падает по превышению лимита, который у нас составляет как раз 1 млн строк, чтобы можно было отдать пользователю файл. Нашим ответом на эту проблему стало создание механизма работы со сводной внутри самого Магрепорта - наш внутренний OLAP-движок. Он пока не вошёл в релиз свободно распространяемой версии. Пользователь теперь может "крутить" свои сводные прямо в веб-интерфейсе, что гораздо удобнее, потому что иметь дело с такими "жирными" эксель-файлами - то ещё удовольствие: он и ресурсы ПК прилично ест (а у рядовых сотрудников не очень мощные ПК), и по почте его никому не пошлёшь. Правда, лимит мы ещё не подняли, но скоро сделаем это. И в заключение маленькая ремарка: когда я изучал остроту проблемы с лимитом в 1 млн строк, я выяснил, что 99% отчётов не превышают 700 тыс строк в объёме. Правда, это можно объяснить тем, что пользователи знают про лимит и вместо того, чтобы, например, сразу посмотреть все интересующие их товарные категории, смотрят сначала одну, потом другую, что, конечно, неудобно. Для нас эта проблема - некий вызов, на который мы хотим дать достойный ответ и разработать механизм, позволяющий пользователю работать с по-настоящему большими объемами данных, постепенно фильтруя их и детализируя (то есть сделать реально качественный drill down). Мы работаем над этим.
Sergei2003
01.09.2022 11:58Для преодоления 1M-limit вы не рассматривали выгрузку в MS Access с последующим подключением к файлу Access из Excel?
V_Sukhov Автор
01.09.2022 12:41Рассматривали примерно такой вариант: хотели выгружать в MS Analysis Services и предоставлять пользователю файл со сводной, настроенной на куб в нём. У этого варианта оказался ряд очень неприятных технических проблем:
1) Для создания такого файла понадобится использование какого-то екселевского API и соответственно машина с Windows, а нам очень не хотелось бы так усложнять архитектуру и вообще слишком сильно завязываться на технологии Microsoft.
2) Для работы такого файла понадобится у всех пользователей унифицировано настроить подключение к MS Analysis Services. Кроме того, что это само по себе не очень приятно зависеть от какого-то стороннего установленного и правильно настроенного ПО, так встают ещё и вопросы аутентификации и управления правами доступа на этом MS Analysis Services.
Поэтому мы решили в это не ввязываться, считая, что гораздо перспективнее сделать свой хороший OLAP и встроенные сводные таблицы, чем мы сейчас и занимаемся :-)
Johan_Palych
01.09.2022 12:49Развернул на Focal Fossa
Вопрос:
Почему выбран режим экспорта отчета в формате .xlsm(Macro-Enabled файл Excel Workbook)?
В рамках технологического суверенитета, открывал отчет в onlyoffice-desktopeditors(r7-office) и LibreOffice Calc. Макросы не окрыляют.Запуск H2 Database server таким методом мне больше нравится.(server modes; databases)
[Unit] Description=H2 Database server [Service] Type=simple User=h2 ExecStart=/usr/bin/java -cp /usr/share/java/h2/h2.jar org.h2.tools.Server -baseDir /var/lib/h2 -tcp -web -ifNotExists -tcpPassword h2 ExecStop=/usr/bin/java -cp /usr/share/java/h2/h2.jar org.h2.tools.Server -tcpShutdown tcp://localhost -tcpPassword h2 [Install] WantedBy=multi-user.targetСкрины тестирования:
01- запуск и выгрузка отчета
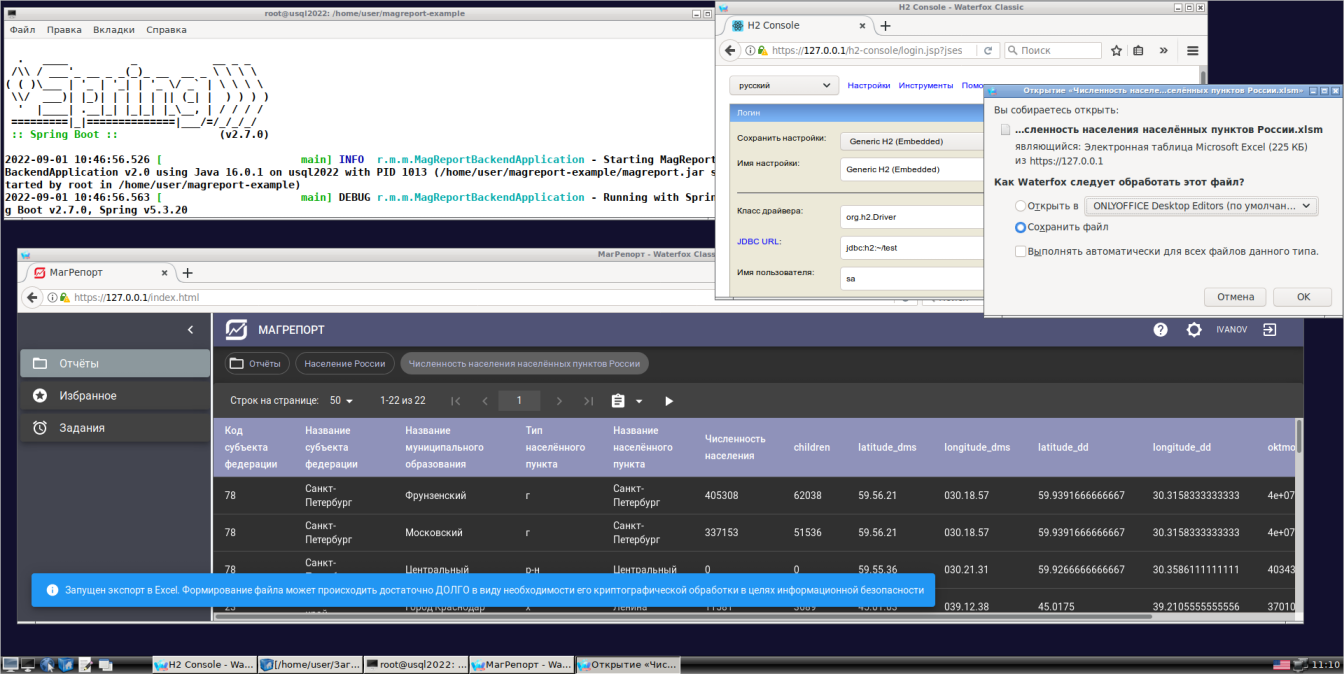
02- тест отчета

V_Sukhov Автор
01.09.2022 15:06Огромное спасибо, что протестировали и даже приложили скрины!
Почему .xlsm:
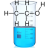
Исходный сценарий работы, на котором у нас завязаны почти все отчёты выглядит так: пользователь выгружает в Excel, в котором автоматически создаётся сводная через макрос и далее работает с ней. Именно для автоматического создания сводной по любому отчёту нужен макрос. У нас в системе предусмотрена возможность добавлять кастомизированный шаблон Excel под тот или иной отчёт, но есть "Стандартный шаблон" в котором предусмотрено создание сводной по всем выгруженным полям, какие бы они ни были - для этого нужен макрос. На момент создания первых версий Магрепорта вопрос полного ухода от Excel не стоял (честно говоря, в таком виде он и сейчас не стоит). В контексте современного понимания вопроса технологического суверенитета можно рассматривать другие форматы экспорта - мы готовы их добавить, если появится соответствующая необходимость (причем готовы рассматривать в том числе запросы внешних пользователей - мы готовы рассматривать issue в нашем публичном репозитории).
Про внутреннюю БД (репозиторий) и H2:
Мы специально сделали репозиторий на H2 в режиме embedded, чтобы максимально просто была устроена архитектура приложения, развёртывание и администрирование системы. Мы предусмотрели возможность размещения репозитория на внешней БД (в том числе H2 в режиме отдельного сервера) и думали, что довольно скоро на неё перейдём. Но оказалось, что в том режиме, в котором это нужно Магрепорту H2 прекрасно справляется. Единственно, отчёт по статистике запуска отчётов стал отрабатывать чуть медленнее по мере накопления статистики. Ну и мы не стали ещё сохранять некоторые статистические вещи, которые можно было бы сохранять в базе (логи запросов пользователей), чтобы база совсем уж не распухала. Но всегда есть возможность перехода на другую БД - у нас для этого предусмотрен экспорт-импорт репозитория в текстовый формат. Но с embedded H2 работать очень удобно, поэтому мы лично пока остаёмся на ней.Ещё раз спасибо, что запустили Магрепорт и приложили скрины!
Johan_Palych
01.09.2022 17:58Да не за что. Было интересно потестировать(ldap, domain и mail-server не настраивал) Все завелось сразу и без ошибок. На установку потратил 20 мин.
скачать и распаковать magreport-3.6.0-with-example.zip sudo apt install openjdk-16-jre sudo update-alternatives --config java # все расписывать не буду sudo chmod +x run.sh && sudo ./run.shH2 Database Engine реактивная - пользовательские функции и триггеры работают очень быстро: du -h example-db.mv.db 16M - отчеты формируются за 2-3 сек. Вижу, что предусмотрели подключение к внешним БД.
Моя контора уходит от классической on-premise схемы MS: Analysis Services(SSAS) с Reporting Services(SSRS)
Года 3 использую в тесте JasperReports Server CE и Pentaho BI Server CE
V_Sukhov Автор
01.09.2022 20:28У нас как раз и был JasperReports Server CE - и именно на замену ему мы стали создавать Магрепорт. Если вы использовали MS Analysis Services, то возможно вам покажутся интересными сводные таблицы и кубы, встроенные в сам Магрепорт, которые появятся в следующем релизе.



Ivan22
"шага преобразования бизнес-ключей в суррогатные " ну как бэ это и PowerBI умеет, и имхо кто-угодно
V_Sukhov Автор
Добрый день! Да, мы не сомневаемся, что многие наши требования в каких-то системах реализованы. Нам просто требовалось сделать нечто достаточно точно соответствующее совокупности наших требований. Мы не претендуем на революционность идей :-)
V_Sukhov Автор
И ещё уточню, возможно, этот момент в тексте не был правильно понят. Допустим у вас есть ИНН людей, по которому вам нужно фильтровать отчёт. Вам нужно сделать отчёт по большому списку людей, идентифицируемых их ИНН, условно: "1234, 5678, 9101". Допустим в справочнике налогоплательщиков у этих людей есть ID: 1, 2, 3 соответственно. Вы берёте прям эту строку и подставляете в соответствующее поле фильтра. Все известные нам BI-системы сделают такой предикат запроса: WHERE TAXPAYER_INN in ('1234', '5678', '9101'), и это не очень хорошо для базы, потому что в базах могут быть индексы по сурогатным ключам, партиционирование, да и просто сравнивать числа быстрее, чем строки. Магрепорт сделает по-другому: он запросит справочник (который может лежать вообще в отдельной базе справочников и обращения к которому могут быть очень быстрыми), получит список IDшников и сформирует такой предикат: WHERE TAXPAYER_ID in (1, 2, 3). Может не слишком уж крутая оптимизация, но по опыту всё-таки увеличивает производительность и экономит ресурсы базы. Мелочь, как говорится, а приятно :-) И это не гипотетическая ситуация - у нас много лет пользователи запрашивают данные по бизнес-ключам (по огромному списку бизнес-ключей) и до внедрения Магрепорта нам всегда было неприятно, что они так делают, а сейчас - пожалуйста, милости просим :-)
Ivan22
Это не мелочь, это важная и давно известная фича.И в PowerBI и в TIBCO spotfire к примеру - они прекрасно умеют в фильтре показать дескрипшен, а данные отфильтровать по ID.
V_Sukhov Автор
Вы немного путаете. Так умеют действительно многие. То есть если у вас фильтр так устроен, что вам там что-то показывают, то такой фильтр действительно, как правило, показывает человеку описательное имя, а в запрос подставляет ключ. Я говорю о другом типе фильтров - крайне популярном у нас - когда вам ничего не показывают, а просто вы текстом можете вставить список каких-то ключей. Разыменование бизнес-ключей в суррогатные в фильтре такого типа я нигде не встречал. Возможно где-то есть, но нам этого не хватало и мы это сделали. Не великое достижение, но для нас полезная особенность.