
Нашел я недавно в закромах старый оптический диск (CD). Открыл его в проводнике и не могу зайти ни в одну папку. Протёр диск. Попробовал снова - та же оказия. Царапины на диске конечно есть, но не много и не сильные. Решил воспользоваться специальным софтом BadCopy. Половина мелких файлов восстановилась, половина нет. Большие файлы восстановились не полностью. В итоге в двух повреждённых архивах (повреждено 2% и 10%) я обнаружил один и тот же файл. При попытке его извлечь вылезала ошибка CRC. Но если в WinRAR при извлечении установить галочку "Keep broken files" (Не удалять файлы, извлечённые с ошибками), то извлекается как есть. Так как мой файл был дорог мне как воспоминание и был небольшим - всего 640 КБ, я решил заморочиться. Там же в WinRAR, кстати, можно узнать оригинальный размер файла и его CRC32.
Итак, у нас есть две повреждённые версии файла, его длина и даже его CRC32, нужно восстановить оригинал. Что может быть проще?
Спойлер: у меня на конкретно этом файле не получилось, но я определил какие должны быть условия, чтобы задача была решена, с какой вероятностью и немного о самом хэше. Оказывается, всё наоборот - это невероятно сложно.
Для начала нам потребуется допущение, что если бит в двух версиях одинаковый и находится на одном и том же месте, то в оригинале на этом же месте точно такой же бит. Вообще-то это не всегда верно: для файла уже в 3 байта с повреждением в 5% в обоих версиях вероятность что повреждённый бит окажется на одном и том же месте - те же 5%, вероятность того что биты окажутся одинаковыми 50%. Таким образом, при столь малом размере наше допущение неверно уже в 2,5%. Это недопустимо, однако иначе на эти версии вообще нельзя полагаться, а значит придётся перебирать все возможные комбинации. Но это мы тоже сделать не можем - для файла уже в 6 байт нас придётся перебрать 256^6 комбинаций, а это больше 2,8*10^14, и не просто перебрать, а вычислить для каждого хэш и сравнить с требуемым. Так что, похоже, допущение остаётся с нами, но нельзя ли его сделать строже? Можно, если учитывать одинаковые участки не по биту, а например по байту (или по несколько байт - но чем жёстче условия - тем дольше нам придётся ждать). Ок, что дальше? Перебрать просто все варианты для повреждённых участков? Нет, потому как если повреждено более 6 байт, мы опять-таки не сможем этого сделать (см. выше). Поэтому нам нужна какая-то оптимизация.
Я придумал три способа восстановления, которые оптимизируют скорость процесса, но уменьшают и без того не 100% вероятность успеха:
1. Побайтовый перебор, но перебираем не все 256 вариантов для каждого байта, а только от a до b, где а = v1 AND v2, b = v1 OR v2, где v1 и v2 - это соответствующие значения этого байта в версиях. Таким образом, если в одной версии там символ в кодировке Windows-1251 "Б", а в другой - "Ю", то мы будем перебирать не 256 вариантов, а только 32 варианта от "А" до "Я" ("Ё" идёт лесом).
2. Малый побайтовый перебор - тут мы вместо 256 вариантов для каждого повреждённого байта перебираем всегда только 2 - из первой версии или из второй
3. Поинтервальный перебор - то же, что 2., но перебор идёт не кадого байта, а для всего повреждённого интервала байтов. Например, если в 100-байтном файле повреждены байты с 70-го по 75-ый, 83-91, 96-100, то нам для всего процесса восстановления потребуется перебрать всего 8 вариантов - по 2 для каждого из трёх интервалов.
А теперь статистика по этим методам (получена эмпирически и плохо экстраполирована):
Вероятность успеха.
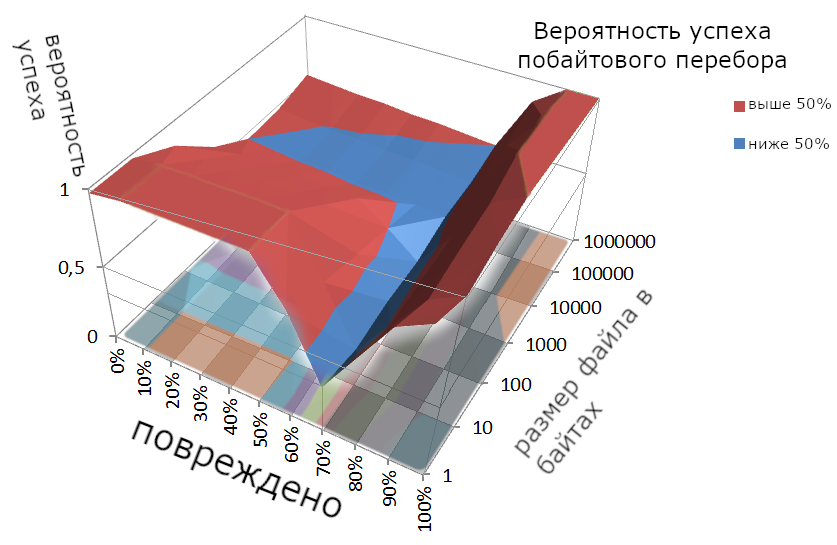
Максимум на что можно рассчитывать при первом способе - 70% вероятность успеха.

Второй способ даёт успех в два раза реже.
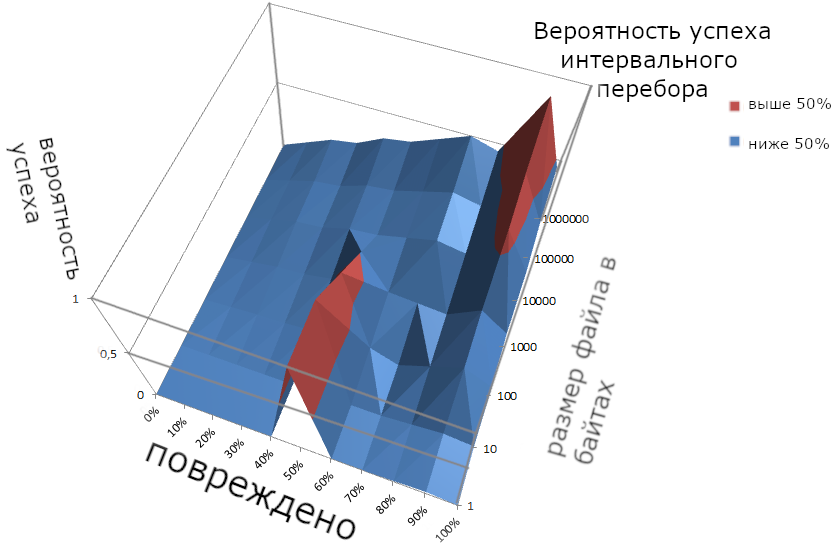
Третий способ даёт успех ещё в два раза реже.
Однако, зато "слабые" способы намного быстрее:
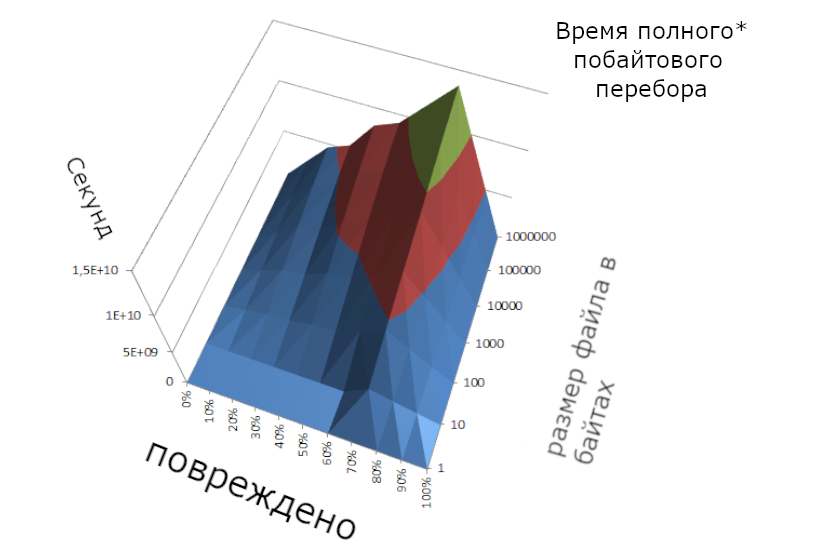
*с описанными в 1. оптимизацией. В среднем - больше 95 лет.

Тут получилось более точно передать пик при больших размерах файла, поэтому среднее время вышло немного больше - 98 лет, зато точнее (по идее у первого графика должен быть тоже такой же пик - чем больше повреждений - тем больше вариантов - тем дольше). Но всё-таки этот способ гораздо быстрее - это мы увидим далее.

В среднем два года.
*Выше и нижеуказанные значения времени были получены на одном процессоре 1.8 ГГц
Понятно, что эти огромные цифры мало общего имеют с реальностью - врят ли кто-то будет ждать 2 года, чтобы восстановить файл меньше мегабайта (разве что там написано почему смысл жизни = 42, шучу, это потому что это ASCII-код джокера), а если речь идёт о более 90 лет (две жизни), то вообще может лучше просто подождать когда компьютеры станут быстрее?
Кстати - это интересный вопрос. Согласно закону Мура, количество ядер на вычислительном элементе удваивается каждые 2 года. А так как нашу программу можно полностью распараллелить (просто в начале заранее определить для какого ядра какая область перебора), то считаем, что каждые 2 года ждать нужно в 2 раза меньше, но нужно сначала подождать эти 2 года. Так что же лучше - начать как можно раньше или как можно дольше подождать?

Если наша задача решается за 100 лет, то самое оптимальное - подождать 10 лет и через 3 года и 1,5 месяца - она решится. То есть потребуется не меньше чем 13 лет! Если для Вас это неприемлемо - то Вам не повезло родиться слишком рано. Конечно, если у Вас нет сохранения промежуточного состояния программы или сети ботов, делающих всю работу за Вас.
Однако, как я уже оговаривался ранее, такие цифры у меня получились, задействуя всего лишь 1 ядро процессора. А если задействовать 8? Уже будет меньше 13 лет! А если вычисления производить на видеокарте? Смотря на какой, но порядок для современных бюджетных видеокарт среднего класса будет всего около 2 месяцев! Как это, спросите Вы? Дело в том, что ядер на видеокарте больше в 100 раз, чем в процессоре, а их частота меньше всего в 1,5 раза. Поэтому, если нужно что-то посчитать последовательно - быстрее будет на процессоре, а если множество вычислений (более 8-16 потоков) не зависят друг от друга (например, если цвет каждого пикселя напрямую не зависит от цвета других, обучение нейросети на одном примере можно производить отдельно от другого, вычисление множества хэшей как в нашем случае или в криптовалюте и т.п.), то лучше использовать видеокарту или несколько.
Итого: не меньше 2 месяцев потребуется, чтобы восстановить файл 1МБ с менее, чем 35% вероятностью успеха на среднем ПК в 2022 году. Всё равно неутешительно.
Но и это ещё не всё. Вы можете сказать: "Подожди, а зачем нам ждать полного перебора - вдруг правильный ответ ждёт нас уже на втором проценте?" Соврешенно верно, поэтому я исследовал и это:

Я ждал максимум сутки, поэтому максимальное значение здесь равно 86400 секунд и записывал результат самого быстрого способа, который всё же дал верный результат (а это 69% успеха при условии, что Вы перепробуете все три способа) - на практике это время может быть намного больше, тем более, что если с первого раза Вы не угадали самый быстрый способ, который не подведёт, но даже так видно, что есть области где пусть не всегда, но требуемый оригинальный файл достигается за гораздо меньшее время.
Таким образом, получается, что наиболее благоприятные условия (до ~ 12 часов на одном ядре или ~ 9 минут на видеокарте - если Вы думаете, что 9 минут - это мало, то вспомните, что это для размеров меньше 1 МБ - стоит добавить парочку повреждённых байт или десяток повреждённых интервалов - и вот уже вновь 12 часов), чтобы получить верный результат будут следующими:

То есть, повреждения желательно должны быть меньше 40% либо размер файла 50 байт.
Объединяя это с предыдущими графиками получаем:

Это рекомендация по выбору самого успешного способа.
Если у Вас имеется только 24 часа на одном процессоре или 18 минут на одной видеокарте, то:

Правый нижний угол ведёт себя немного странно - это потому что при таком повреждении наше изначальное не всегда верное допущение перестаёт иметь значение. Аналогично в левом нижнем углу допущение начинает играть значительную роль. Почему только в нижних? Потому что при таком отпущенном времени на поиски до верха мы просто не доберёмся.
Выкладываю здесь свою программу: ссылка на яндекс диск.

Извлеките из двух повреждённых архивов один и тот же файл (с галочкой Keep broken files в WinRar) в папку с программой как 1 и 2 (без расширения), введите длину файла и CRC32 из архиватора
Но это ещё не всё! Если Вы сейчас попробуете восстановить так какой-нибудь файл (рядом с программой есть примеры, на которых можно поиграться, дайте знать если у Вас получится восстановить D82C64A7 как работающий exe), то Вы получите результат гораздо быстрее:

В среднем за 5,5 часов*.
, но, скорее всего, он будет не тот, что Вам нужен.
Проблема в том, что так как CRC32 имеет длину в 4 байта, то на каждые 256^4 (4 миллиарда) комбинаций в среднем будет приходиться одна, подходящая под один любой CRC32. Поэтому сложность не только в том, чтобы найти вариант, подходящий под длину и хэш, но и выявить нужный из всего множества таких. А это множество может быть очень большим:

В среднем 22 штуки.
Так, например:

некоторые 17 вариантов для db7d2bac и размера в 54 байта (малый побайтовый перебор)

начальные 17 вариантов и оригинал для CRC32 = 9b225956 и размера в 11 байт (побайтовый перебор). Обратите внимание на 3-й символ - первые два не меняются, и практически для каждого байта находится несколько вариантов.
Таким образом, если у Вас на сайте есть достаточное органичение на минимальную длину пароля, имеет смысл хранить и проверять не только его хэш, но и длину. Тогда подобрать или найти подходящий в радужной таблице будет в разы сложнее.
По вышеприведённой ссылке есть также исходники программы на VB6. Пробуйте перевести её на видеокарту, изобретите другой способ перебора (например, с какой-то вероятностью в каких-то байтах верить изначальному допущению, а с какой-то не верить повреждённым версиям), расширяйте её на большее количество повреждённых версий, ставьте проверку на требуемую структуру файла, оптимизируйте или как-то можно не перебирать, а вычислять варианты? - непаханное поле!
Но и это ещё не всё. Пишите комментарии - что понравилось/что нет, подписывайтесь, а если хотите поддержать такие околонаучные статьи и упоротые расчёты - можете сделать это здесь.
UPD: Скормил извлечённый .text из повреждённого exe и из такой же сигнатуры неповреждённого файла в https://www.jpeg-repair.org/ru/vg-jpeg-repair/ - показал изображения, что были внутри. Есть у кого аналог бесплатный или ещё что-то что может восстанавливать другие типы информации?
Комментарии (65)

BugM
01.09.2022 20:56+7Только не восстановить, а подобрать коллизию. К восстановлению это как правило не имеет никакого отношения.

smile_artem Автор
02.09.2022 08:42Вы про что-то конкретное или про статью в целом?
BugM
02.09.2022 14:39+2Про саму идею что-то восстанавливать по хешу.

Sklott
02.09.2022 14:44+1Ну в теории вы конечно правы. Но на практике, если у нас есть силный хэш, и CRC32, и применив восстановление одного бита по CRC32 мы видим что сильный хэш совпал. То для практических применений я думаю это можно назвать восстановлением. Потому что вероятность того что испортился не один бит, а столько и так чтобы сильный хэш совпал - ну сами понимаете какая.
Другое дело, что по CRC32 можно восстановить только 1, ну максимум несколько бит и то при условии что мы имеем способ проверить что получился правильный файл, например по сильному хэшу.
BugM
02.09.2022 15:31У вас слишком много условий стало появляться. Чисто математически легкий хеш + криптографический хеш дают возможность перебирать варианты быстрее. А просто два разных хеша уменьшают вероятность одновременной коллизии. И это все не имеет никакого отношения к восстановлению файлов на основе CRC32.
Sklott
02.09.2022 15:54Это не условия стали появляться, просто я описывал реальный случай восстановления "сбойного" бита в видеофайлах по CRC32. К данной статье имеет отношение только в смысле заголовка: Восстановление повреждённых файлов на основе CRC32.
Даже с теоретической точки зрения, вероятность того что в файле поменялся только один бит, а не кучка да еще и так что совпал сильный хэш сильно разная. А с практической только ее и можно учитывать.
BugM
02.09.2022 16:20Видеофайлы не критичны к потере не то что бит, а даже целых кусков файла. Их форматы умные люди делали. Видели разваливающуюся картинку при проигрывании или зеленую заливку? Вот это оно, кусок битый. Бит вы глазами не заметите.
Теория говорит нам что задача восстановления решается другими способами, а не через хеш от всего файла. И наоборот что задача восстановления данных через хеш от файла не решается.
smile_artem Автор
02.09.2022 20:39-1Я до сих пор не понимаю почему 1 бит-то? Мы получаем кучу вариантов, но CRC32 просто уменьшает эту кучу в 4 миллиарда раз, разве не так?

Scratch
01.09.2022 21:57+2Microsoft на оригинальных образах винды раньше всегда делала чтоб crc32 был FFFFFFFF, как сейчас не знаю

{kind=link}

connected201
01.09.2022 23:17-1Интересная статья, спасибо, такой вопрос к знатокам, квантовый компьютер может восстановить файлы по такому алгоритму?

krote
01.09.2022 23:38+1Ни квантовый ни даже компьютер с бесконечным быстродействием не сможет, если нет больше другой инфы кроме этих CRC32.
В общем случае они просто нагенерят почти бесконечное количество мусорных файлов у которых CRC32 совпадает с оригиналом плюс совпадает часть файла с обеими оригиналами.
smile_artem Автор
02.09.2022 08:45-1Ну вообще-то есть ещё такая информация как минимиум как расширение файла, а предпологаемой или достоверно известной может быть намного больше - например использовавшийся компилятор для exe. Я её здесь не учитывал, но зная структуру файла можно отсеять большинство мусора.
krote
02.09.2022 11:54увы не "большинство мусора" а меньшинство, так же как и CRC32 добавление валидаторов по структуре файла лишь несущественно сократит количество вариантов. Ведь валидных вариантов останется гораздо больше чем невалидных разве нет?
(Если конечно речь идет не о повреждении всего лишь небольшого участка из нескольких байтов в исходном файле.)
smile_artem Автор
02.09.2022 12:02то есть по вашему exe файл из рандомных байтов запустится виндой без ошибки типа: "Невозможно запустить это приложение на Вашем ПК" или "Файл содержит потенциально нежелательную программу" ?

hard2018
02.09.2022 15:22В PE заголовке содержится CRC, по которому винда и определяет целостность. Так что такой файл скорее всего выдаст заглушку MS DOS.
krote
02.09.2022 19:02+1Я и написал про валидатор exe, но это не отменяет того факта что множество "валидных" вариантов будет несравненно больше множества отсеянного этими CRC32 + валидатором хоть что ты там не проверяй
connected201
02.09.2022 12:53-1А если будет хеш файла? например SHA256, то квантовый компютер сможет востановить файл?
Sklott
02.09.2022 13:22Даже чисто теоретически SHA256 может помочь восстановить не более 256 битых битов. Но нужен еще способ определить который из примерно 2^(N-256) файлов, где N - длинна файла в битах - правильный.
krote
02.09.2022 19:08SHA256 конечно уменьшит количество вариантов на (256-32)=224 двоичных порядка, что по прежнему дает огромнейшее количество валидных вариантов (коллизий), которые тоже можно отсеивать проверкой структуры файла, что все также несущественно уменьшит количество вариантов.
Так что точный ответ на ваш вопрос - нет, не сможет. При условии что количество поврежденных битов сильно превышает 256, а я напомню что файл 640кб и речь идет о потерянных десятках процентов насколько я понял.
smile_artem Автор
02.09.2022 20:41Точный ответ - скорее всего нет, но если у Вас есть квантовый компьютер и огроменное желание, то проверить несколько вариантов можно.

Nipheris
01.09.2022 23:28+1VB6, о, моя молодость. Как гляну на иконку окна, так сразу... (роняет скупую слезу)

Maccimo
02.09.2022 00:35+2Но это мы тоже сделать не можем — для файла уже в 6 байт нас придётся перебрать 256^6 комбинаций, а это больше 2,8*10^14, и не просто перебрать, а вычислить для каждого хэш и сравнить с требуемым.
Если ты не бог, то не стоит действовать по алгоритму бога. Практически у каждого типа файлов есть внутренняя структура, налагающая ограничения и сужающая диапазон допустимых значений. Даже у plain text. От этого и стоит плясать.
smile_artem Автор
02.09.2022 08:47Совершенно верно, но я поисследовал теорию, и дал исходники будущим разработчикам, которые, надеюсь, смогут правильно сплясать.

VBKesha
02.09.2022 00:44+1Вообще если именно CD диск не прочитался, то там количество повреждений явно завалило за 4 байта. Там в каждом секторе порядка 14% коды для восстановления.
Так как мой файл был дорог мне как воспоминание
Если правда дорог, то стоит поискать другие приводы, и пробовать прочитать на них, есть достаточно большой шанс что на другом приводе прочитается.smile_artem Автор
02.09.2022 08:49А можно подробнее, интересно как другой привод прочитает, если проблема в диске? Другие диски привод нормально читает?

HardWrMan
02.09.2022 09:23+2Там слишком много параметров. Например, у меня в начале 00х было 3 привода для CD: Acer 52x, Asus 52x и резак Asus 48x16x52. Так вот, хуже всех считывал резак. Он отлично считал новые CD (без следов деградации алюминия) и хорошие CD-R/CD-RW. Acer 52x считывал все диски, что мог считывать резак + некоторое количество дисков, которые резак уже не брал. Причём, большинство - просто с грубыми повреждениями поверхности (видимо, его оптическая система более быстрая и ей относительно сильные царапины не страшны). А вот Asus 52x мог считать такие диски, которые не читали два предыдущие. Причём, даже CD-R и CD-RW. Последние вообще в некоторых приводах считывались через раз, у меня были такие RWхи, которые не читались прямо после записи и для их восстановления приходилось периодически делать полное медленное стирание.
Так что да, смена привода вполне может повысить шансы на удачное чтения диска. И важны тут все параметры: скорость чтения (чем она выше, тем быстрее механика и на малой скорости будет легче реагировать на царапки), сама оптическая система (чем качественнее и чище линза тем проще ему считывать с повреждениями на самой подложке). И прочее, вроде прошивки или мозгов.
Помню, были ещё приводы Creative, которые с пультом шли. Они читали хуже всего, почему-то.
VBKesha
02.09.2022 12:42+1Помню, были ещё приводы Creative, которые с пультом шли. Они читали хуже всего, почему-то.
Мой первый привод был LG x48 и вот он был рекордсмен по плохому чтению, причём всего от штамповок до CD-R, RW я бы сказал он ненавидел. Пару раз приходилось брать у друга какой то очень старый x8 привод, который ооочень медленно но при этом спокойно читал всё, что не мог прочитать мой LG.
При этом был правда ещё веселый диск с UT как полагается русская+англиканская версия. И вот англиканскую версию во всем моем городе мог прочитать только TEAK.HardWrMan
02.09.2022 16:40+1TEAK
TEAC. Они да, были звери (их профессионалы юзали), просто из попсы Asus CD-ROM (и только он) был наиболее всеядный, имел честное UDMA33 (даже под DOS драйвер был) + отлично управлялся программой CD Slow. Acer у меня пару дисков внутри рванул, ещё какой-то мутный привод был в конторе (вероятно LG или Lite ON), который тоже взорвал диск, раскрутив его на максимум.

Sap_ru
02.09.2022 01:25+1Для CRC32 можно вычислить четыре последовательных байта изменяющие её на произвольную другую. Без всякого перебора. Поэтому много там не навосстанавливаешь. Четыре подряд битых байта на файл и всё.
А, вот, при битовом потоке можно, теоретически, без перебора узнать номер искаженного бита аж в 8 килобайтном блоке.
smile_artem Автор
02.09.2022 08:51Так надо найти не один любой подходящий, а все и отсеять из них те, что не подходят под структуру
Sklott
02.09.2022 12:41А, вот, при битовом потоке можно, теоретически, без перебора узнать номер искаженного бита аж в 8 килобайтном блоке.
Если битый бит один, то по CRC32 его надежно можно найти в 4Гб.
Sap_ru
02.09.2022 13:51Да, ошибся :) Про CRC16 подумал. Кстати, на сколько я помню, на практике там далеко не 4Гб, из-за того, что полином позволяет исправлять и детектировать ещё и какое-то количество множественных ошибок.
Sklott
02.09.2022 14:30полином позволяет исправлять и детектировать ещё и какое-то количество множественных ошибок.
Нет. Вы наверно путаете с другими кодами. CRC32 обладает следующими свойствами:
Каждому значению CRC32 соответсвует ровно один файл вида (2^32)-1 бит нулей и один бит 1. Т.е. грубо говоря в CRC32 "зашифровано" положение одного установленного бита в 4Гб.
Для любых двух файлов верно то, что XOR CRC32 этих файлов равер CRC32 файла полученного побайтным XOR-ом этих двух файлов.
Т.е. если у нас неправильный один бит, то сделав XOR корректного CRC32 и текущего CRC32 мы получим "положение" битого бита.
А если у нас 2 битых бита, то мы получим XOR этих двух положений. А для любого 32-х битного числа есть ровно 2^32 вариантов как его получить XOR-ом из двух других чисел. Т.е. по сути никакой дополнительный информации нет. Точней для короткого файла можно большую часть пар выкинуть, но все равно придется перебрать все 2^32 варианта. Для трех бит все еще хуже...
smile_artem Автор
02.09.2022 20:44-1А если есть две повреждённые версии этого файла, но +- в совокупности (комбинации) байтов первой и второй версии есть верный ответ?
smile_artem Автор
02.09.2022 14:14Вы в курсе, что кроме хеша и длины файла, у меня есть ещё и две повреждённые версии этого файла, которые наполовину побайтно совпадают? Вполне возможно, что все нужные байты есть в этих версиях на своих местах, только некоторые в первой, а некоторые для второй. Может кто-нибудь из опенсорса переписать это для видеокарты, чтобы проверить?
Sap_ru
02.09.2022 17:19+1А какие байты не совпадают между файлами и какое распределение этих байтов?
Данные на диске хранятся блоками и все повреждения локализованы в блоках. Блоки будут размером по 2КБ, помнится. Можете попробовать поперебирать не байты, а блоки между файлами - вдруг CRC сойдётся.
И главное. Там на CD два вагона информации для коррекции ошибок. Из которых сам привод использует только небольшую часть:
Первый уровень: коррекция/синхронизация на физическом уровне. Её привод всегда использует. И получает на выходе блоки по 2336 байт данных, где только 2048 байт полезных данных, а всё остальное - информация для восстановления.
Второй уровень - CRC32 этих двухкилобайтных блоков. Если она не сходится, то привод просто перечитывает блок, пока не сойдётся. Если за указанное количество попыток чуда не случилось, то привод сообщает, что блок плохой.
Но! Есть ещё и третий уровень - коды Рида-Соломона. И это аж прядка 256 байт на информации для восстановления на каждый 2048-байтный блок данных! И не это не просто CRC, это уже код для восстановления множественных блочных ошибок. На сколько я знаю, на практике сия информация приводами не используются или практически не используется, по причине сложности реализации и крайней длительности процесса восстановления. Но у некоторых приводов есть режим чтения с восстановлением ошибок и они медленно и мучительно читают битые сектора реально восстанавливая информацию. Но, опять же, на сколько я знаю, даже они не используют 100% возможностей восстановления из-за ограниченности вычислительных ресурсов привода. Вплоть до того, что на хорошем приводе, в случае царапин рекомендуется тонким чёрным маркером их закрашивать, и путь он восстанавливает 100% потерянных данных по кодам коррекции. Тем более, что повреждения носителя, как правило, точечные или радиальные, а дорожки на диске поперечные.
Для DVD/BL всё ещё намного круче. Там на хорошем приводе можно восстановить ОЧЕНЬ много потерь.
Но никто не запрещает прочитать сырые данные с привода и максимально использовать всю информацию для восстановления данных. Были даже утилиты, которые это программно делали, но давно это было, и знание, похоже, утеряно.
Я так понимаю, что вы даже CRC32 двухкилобатных блоков не используете, хотя уже только это сильно упростило бы задачу.
А ещё можно руками много раз читать блок, сравнивать отличия и выбирать в финальный результат значения байт, которые прочитались чаще всего, в надежде, что это верные значения. Либо маркировать такие нестабильные байт, чтобы потом проще было по кодам коррекции восстанавливать.Это всё, как я сейчас помню и могу, конечно, ошибаться.

axe_chita
02.09.2022 06:18+1Архив RAR? Посмотрите, может его создали с информацией для восстановления?

Zara6502
02.09.2022 07:29я всегда так делал для дискет и для CD/DVD архивов, личных. Пригодилось раз 15 на рубеже нулевых. Думаю и сейчас есть где-то диски старые, если найду нужно попробовать прочитать...
smile_artem Автор
02.09.2022 08:49К сожалению нет
axe_chita
02.09.2022 12:14А что RAR по alt+R говорит?
smile_artem Автор
02.09.2022 12:17Определение типа архива...
---> RAR 4.x---> данные для восстановления не найдены
hard2018
02.09.2022 07:00-7Могу вам написать прогу для восстановления, гораздо более быструю за определенную плату. Пишите в телегу @vasyusha_artemov95
Sklott
02.09.2022 12:38+2Вообще, если там архив именно "заархивированный", а не просто "сложенный в один файл" (store method). То нет абсолютно никакого смысла "фиксить" разархивированный файл, т.к. с того бита который был поврежден в архиве дальше будет идти полный мусор до конца файла, а не один или несколько байт.
А насчет CRC32 - он может надежно восстановить ровно 1 бит на файлах меньше 4Гб. Лично когда-то занимался таким на видефайлах для которых были известны более "сильные" хэши.
Вообще по моему опыту, XOR "правильного CRC32" и "битого CRC32" можно рассматривать как "зашифрованную" позицию измененного бита. Точнее сказать это будет CRC32 файла состоящего из всех нулей с одним битом (битым) в единичке.
Если таких битов 2 и более эти позиции тоже складываются по XOR. Таким образом можно попробовать восстановить 2 бита для более менее коротких файлов, т.к. там для каждого бита его пара может "улетать" за пределы файла и понятно будет что это неверная пара, но и верных пар может быть очень много и чем длинней файл - тем больше. 3 и более бит - уже по сути нереально, кроме ну очень коротких файлов.
smile_artem Автор
02.09.2022 13:59Не знаю, у меня почему в двух разных повреждённых архивах, все одинаковые файлы примерно на половину совпадают
Sklott
02.09.2022 14:31Ну видимо на первую половину? После ошибки не должно совпадать практически ничего.
Sap_ru
02.09.2022 17:35+1Изначальным носителем был CD, а там независимые блоки по 2048 байт и куча информации для восстановления. Если просто деградация носителя, а не царапины, то вполне могут небольшие цепочки байт не совпадать.

IvanPetrof
02.09.2022 18:00Восстанавливать содержимое файлов по crc32 — всё равно что восстанавливать цены на продукты по чеку супермаркета в котором сохранилась только строчка «итого»
smile_artem Автор
02.09.2022 20:47именно, перебором можно подобрать правильный вариант
IvanPetrof
02.09.2022 21:20Подобрать можно. Узнать какой из них правильный — нет
smile_artem Автор
02.09.2022 21:21-1Можно попытаться
smile_artem Автор
02.09.2022 21:22тем более, если ты уже несколько раз до этого видел чек, то стоит показать тебе правильный - и ты вспомнишь - да - вот этот
IvanPetrof
02.09.2022 21:31Или этот… Или может быть вон тот…
И это просто чек. Вариантов файлов примерно чуть больше чем Гугол…
IvanPetrof
02.09.2022 21:28+2Я вам больше скажу. Для восстановления ваших файлов вам даже их crc32 не нужен. Все ваши файлы содержатся в последовательности цифр числа π. Просто загляните туда (будьте осторожны, там вы можете случайно наткнуться на секретные документы и стать невыездным..))
fedorro
Мне казалось что даже в идеальном случае кол-во коллизий = 2^((N-4)*8), где N-кол-во восстанавливаемых байтов, т.е. для 5 байтов уже 256 коллизий в идеальном случае.
smile_artem Автор
Правильно, но это теоретические расчёты, а у меня там эмпирически полученные варианты, найденные всего лишь за сутки
fedorro
Но в том то и дело, что
бесперспективность данной затеивсё это можно было теоретически легко и быстро посчитать. И мне показалось ваши эмпирические результаты как - то сильно расходятся с теорией - собственно об этом мой изначальный комментарий.smile_artem Автор
Вы понимаете разницу между всеми найденными и найденными лишь за сутки?
smile_artem Автор
Учитывая три разных способа?
smile_artem Автор
И, выложив исходники, мне интересно сможет ли кто приблизиться к практическому результату, грамотно отсеяв из множества вариантов не подходящие под структуру и какое минимальное кол-во времени для этого потребуется?