
Существует проблема?
Проведём эксперимент - возьмём небольшую чёткую картинку, на ней всё понятно (скрытых деталей мельче разрешения не наблюдается):

Увеличим быстрыми стандартными способами:
")
 и Бикубическая интерполяция")
Проблемы видны невооружённым глазом: сильное размытие, проявляется сеточная структура
А если мы вооружимся, то увидим куда более сложную проблему. Для начала уменьшим изображения обратно теми же методами и получим:

Они и тут теперь размытые, кроме бикубической интерполяции, хотя мы лишь увеличивали размер файла (то есть потерь могло бы и не быть).
Сравним более тщательно (красным показано, где ошибки):

Поэтому при работе с изображениями используйте хотя бы бикубическую интерполяцию при изменении размера слоёв и редактор, который это может. В чём проблема, спросите Вы – просто не надо два раза применять интерполяцию. Но почему вообще ошибка возникает, даже пусть незначительная?
А потому что интерполяция решает вообще другую задачу и никоим образом не относится к увеличению изображений, она даёт приблизительный результат, но быстро, поэтому её принято использовать для этих целей (даже там, где скорость не критична):
А задача интерполяции – угадать неизвестные значения точек, стоящих между точками, значения которых известны. Мы же изначально не знаем точное значение ни одной точки, а лишь среднее значение точек в области пикселя (пиксель имеет размер, точка - нет) и пытаемся угадать среднее значение точек в более малом пикселе, входящем в исходный пиксель. Кому удобнее визуально воспринимать информацию – есть в виде видео
Условие средних значений
Почему среднее?
Во-первых, сглаживание или супер-семплинг. Оно везде:

Со сглаживанием всё выглядит красивее и натуральнее (обратите внимание, что разрешение одинаковое, хотя кажется, что со сглаживанием больше), поэтому куда ни ткни, оно там будет. И с этим надо считаться. Исключение составляют только пиксель-арты и небольшой процент видеоигр без включенного сглаживания и непрофессиональных цифровых рисунков.
А что с фото? А там оно тоже есть, только по другой причине:

Проблема использования интерполяции
Допустим, мы имеем средние значения точек на 5 пикселях и нам надо увеличить масштаб в 8 раз до 40 пикселей:

Что будет, если попробуем воспользоваться интерполяцией?

Кривая интерполяции проходит ровно через средние значения, но сами значения при этом меняются, причём в сторону сближения друг с другом, поэтому результирующее изображение будет размытым. А самое главное – нам не нужно проходить через средние значения, точное значение по центру может быть почти каким угодно, учитывая минимальную и максимальную границу яркости. Кстати, интерполяции плевать на эти границы:

Так причём тут вообще интерполяция? А мы до сих пор её везде применяем.
Разве что она даёт скорость, необходимую при обработке в реальном времени, как например, при воспроизведении видео. Кстати, поэтому видео в 144p сейчас смотреть невозможно – не потому, что не хватает каких-то деталей, а просто, потому что всё размыто или в сеточку или и то и другое вместе.

Эх, были бы у нас мощности для точных, а не приблизительных алгоритмов, пусть даже и без восстановления мелких деталей (распознавания номеров машин и лиц по размазне в этом цикле статей не будет)…
Как повысить точность?
Ну, допустим, будут у нас бесконечные мощности на каких-нибудь позитронно-квантовых компьютерах. А что это за алгоритмы-то?
Самый банальный способ отказа от интерполяции, раз она такая проблемная – метод ближайшего соседа. Он, кстати, ещё быстрее интерполяции, но

Ок, что у нас есть ещё? Что насчёт нейросетей?

Real-ESRGAN
Выглядит приемлемо, условие среднего почти соблюдается.
Но тут другая проблема – если просто для визуального удовольствия – то это почти всегда лучший вариант. Для лучшего результата, правда, возможно, придётся вручную исправить несколько галлюцинаций – нейросети пытаются создать детали, о которых у нас нет информации, и могут угадать/придумать их совершенно неверно и вот уже любой фильм/фотография любого года в суперкачестве ну или если не повезёт – в другой стилистике. Совершенно другой случай, если апскейлинг Вам нужен для научных целей – качество – не означает точность, и тут у Вас будут большие ошибки именно из-за этих деталей. А если Вы историк – то это вообще ужас – в ходу может оказаться «улучшенная» фотография 1845 года, где вместо грязи на руке крестьянина появился пистолет.
Раз качество - это не то, что мы хотим, то, видимо, нужно искать
Сравнение по получающейся ошибке
Поэтому далее будем сравнивать методы апскейлинга по средней ошибке от оригинала:
Возьмём за оригинал полихромный цифровой рисунок клип-арт с градиентами и множеством мелких деталей 1024 х 1024 px, например, такой:

И попытаемся увеличить масштаб в 128 раз, используя разные методы, и сравним среднюю ошибку с оригиналом.
Почему мы взяли такой узкий класс изображений, только один его пример, и вычисляем среднюю ошибку, а не, например, среднеквадратичную? Это лишь моя первая статья, посвящённая этой теме, и в следующих частях (подписываемся ☺) будут рассмотрены все возможные случаи, а пока просто познакомимся с существующими методами и изобретём новые.
Новые методы
Кстати, что будет, если попытаться сгладить кривую, убрав разрывы, но сохраняя средние значения и установив границы возможных значений?

Получится метод scaleSmooth (гладкий, плавный), который я разработал специально для этого случая. Исходники и exe доступны на https://github.com/no4ni/scaleSmooth/
К сожалению, чтобы выполнить столько условий, придётся сделать много последовательных расчётов, поэтому он очень медленный и никакая видеокарта, как нейросетям, здесь не поможет. Но мы же допустили, что у нас в наличии большие мощности, в том числе огроменная тактовая частота процессора (хотя чтобы им пользоваться уже сейчас достаточно и просто наличия терпения – всё в разумных пределах – до суток на несколько изображений). Однако, если Вы можете оптимизировать или подсказать как оптимизировать алгоритм, милости просим в коммиты или комментарии.
Объяснение принципа и визуализация работы алгоритма - здесь
А если наоборот увеличить разрывы насколько это возможно, сохраняя средние значения?

Получится метод scaleRough (грубый), который я разработал специально для этого случая. Исходники и exe доступны также на гитхаб
Он также медленный и, если Вы поможете оптимизировать или подсказать как оптимизировать алгоритм, милости просим в коммиты или комментарии. Объяснение принципа и визуализация работы алгоритма - здесь
Попробуем их на этом примере?
, scaleRough выдал почти монохромный результат, но результат интересный, разве что края сильно рваные")
Можно сказать, что scaleSmooth выдаёт вероятности того, что насколько тот или иной пиксель оригинала был светлее или темнее, а scaleRough выдаёт одну реализацию из этого для монохрома (в случае с тремя каналами – 8 цветов). Можно ли угадать оригинал более точно, чем scaleSmooth, используя его вероятности?
А что, если мы возьмём несколько монохромных реализаций, соблюдающих условие средних значений, и возьмём среднее от них? По идее появится больше цветов и линии станут не такими рваными. Так появился scaleFurry (пушистый, меховой):
 и ушки сверху?")
Визуализация работы метода и наглядное сравнение с работой scaleRough - здесь Исходники и exe для «поиграться» в том же репозитории на гитхаб.
Однако, не всегда получается добиться абсолютного соблюдения условия средних значений (в частности из-за дискретности значений уменьшенного изображения, оно всегда представлено не с абсолютной точностью, а с небольшой погрешностью, обычно ±0,2% от размера границ допустимых значений). Тогда нам поможет корректировка – более подробно здесь
Как сделать границы объектов и вообще линии ровнее (не прямее, а глаже), но при этом убрать размытость? Как совместить не совместимое? Придётся отказаться от главного – условия средних значений, но если всё правильно сделать – мы потом сможем восстановить это условие. Так у меня родился contrastBoldScale:

Исходники и exe также в том же репозитории. Наглядная работа под капотом - в этом видео
Но после корректировки контрастность приходит в норму, однако, сеточная структура стала гораздо заметнее и мелкие детали также утеряны:

Сравнение всех методов
Ну что же пришло время сравнить все методы, как с условием средних значений, так и нейросетей (видеосравнение), а также интерполяций, других оконных функций, алгоритмов для пиксель-арта и др. (видеосравнение, здесь же waifu) на этом же изображении (волк ШБ), но, я думаю, что результаты будут приблизительно такими же на любом полихромном цифровом рисунке клип-арте с градиентами и множеством мелких деталей на таком масштабе (128х):
МЕТОД |
СРЕДНЯЯ ОШИБКА |
15,64% |
|
waifu2х (Арт - Anime Style, Cliparts) |
15,72% |
обратный антиалиасинг |
16,93% |
contrastBoldScale + корректировка Ланшоцем |
16,97% |
билинейная+ интерполяц. Original + корректировка Ланшоцем |
17,02% |
бикубическая интеполяция hq + корректировка Ланшоцем |
17,13% |
2xSal + корректировка Ланшоцем |
17,19% |
окно Гаусса радиусом 1,2px + корректировка Ланшоцем |
17,26% |
билинейная интерполяция hq + корректировка Ланшоцем |
17,29% |
окно косинуса + корректировка Ланшоцем |
17,39% |
superXBR 2x |
17,51% |
окно Хэмминга + корректировка Ланшоцем |
17,69% |
прямоугольный фильтр + корректировка Ланшоцем |
17,71% |
базисный сплайн 5 степени + корректировка Ланшоцем |
17,72% |
мало гало + корректировка Ланшоцем |
17,79% |
полноцветная векторизация + корректировка Ланшоцем |
17,79% |
базисный сплайн 3 степени + корректировка Ланшоцем |
17,81% |
базисный сплайн 2 степени |
17,83% |
окно Шаума 2 степени |
17,86% |
базисный сплайн 11 степени + корректировка Ланшоцем |
17,87% |
окно o-Moms 3 степени + корректировка Ланшоцем |
17,89% |
окно Ланшоца радиусом 3px (sinc) + корректировка Ланшоцем 1 px |
17,91% |
базисный сплайн 9 + корректировка Ланшоцем |
17,91% |
нет гало + корректировка Ланшоцем |
17,93% |
окно Уэлша + корректировка Ланшоцем |
17,93% |
o-Moms 7 степени + корректировка Ланшоцем |
17,94% |
o-Moms 5 степени + корректировка Ланшоцем |
17,95% |
базисный сплайн 7 + корректировка Ланшоцем |
17,95% |
окно Ланшоца радиусом 7px (sinc) + корректировка Ланшоцем 1 px |
17,95% |
окно Ланшоца радиусом 8px (sinc) + корректировка Ланшоцем 1 px |
18,02% |
окно Ланшоца радиусом 16px (sinc) + корректировка Ланшоцем 1 px |
18,03% |
окно Шаума 3 степени + корректировка Ланшоцем |
18,05% |
бикубическая интерполяция + корректировка Ланшоцем |
18,05% |
кубическая интерполяция + корректировка Ланшоцем |
18,06% |
линейная интерполяция + корректировка Ланшоцем |
18,12% |
окно Гаусса 1,4px + корректировка Ланшоцем |
18,15% |
билинейная+ интерполяция + корректировка Ланшоцем |
18,19% |
Гаусс 1,06 + корректировка Ланшоцем |
18,20% |
XBR no blend 2x |
18,21% |
размытие Гауссом + корректировка Ланшоцем |
18,29% |
XBR no blend 4x |
18,26% |
XBR 3xm |
18,27% |
XBR 4x |
18,29% |
XBR 3x |
18,29% |
окно Митчелла + корректировка Ланшоцем |
18,32% |
треугольный фильтр + корректировка Ланшоцем |
18,33% |
окно Ланшоца радиусом 1px (sinc) |
18,36% |
img2go - нейросеть для фото |
18,37% |
окно косинуса 2 степени + корректировка Ланшоцем |
18,39% |
XBR no blend 3x |
18,40% |
HQ 2x Bold |
18,41% |
XBR no blend modified 3x |
18,41% |
XBR 2x |
18,41% |
HQ 4x Bold |
18,43% |
окно Ханна |
18,44% |
окно Бартлета-Ханна + корректировка Ланшоцем |
18,46% |
окно Эрмитта |
18,46% |
HQ 3x Bold |
18,47% |
HQ 2x Smart |
18,66% |
AdvInterp 2x |
18,69% |
HQ 4x Smart |
18,70% |
HQ 3x Smart |
18,75% |
Super Eagle 2x + корректировка Ланшоцем |
18,78% |
HQ 4x |
18,82% |
HQ 2x |
18,83% |
HQ 3x |
18,85% |
Eagle 2x |
18,89% |
ближайший сосед |
18,95% |
gimp-плагин для Scale 2x |
18,96% |
EPXC |
18,97% |
AdvInterp 3x |
18,98% |
окно гаусса радиусом 1px + корректировка Ланшоцем |
19,02% |
Eagle 3x |
19,04% |
пиксельная векторизация |
19,10% |
EPX3 |
19,19% |
Scale 3x |
19,19% |
Scale 2x |
19,20% |
EPXB |
19,20% |
LQ 2x Smart + корректировка Ланшоцем |
19,28% |
LQ 4x Smart + корректировка Ланшоцем |
19,30% |
LQ 3x Smart + корректировка Ланшоцем |
19,33% |
LQ 4x + корректировка Ланшоцем |
19,37% |
LQ 3x + корректировка Ланшоцем |
19,37% |
LQ 4x Bold + корректировка Ланшоцем |
19,59% |
LQ 2x + корректировка Ланшоцем |
19,61% |
окно Блэкмана + корректировка Ланшоцем |
19,71% |
окно Бохмана + корректировка Ланшоцем |
19,74% |
окно Хеннинга-Пуассона + корректировка Ланшоцем |
19,75% |
окно Тьюки + корректировка Ланшоцем |
19,83% |
LQ 3x Bold + корректировка Ланшоцем |
19,90% |
окно Коши + корректировка Ланшоцем |
19,96% |
окно Блэкмана-Нуттала + корректировка Ланшоцем |
19,99% |
окно Блэкмана-Харриса + корректировка Ланшоцем |
20,01% |
окно Нуттала + корректировка Ланшоцем |
20,02% |
LQ 2x Bold + корректировка Ланшоцем |
20,11% |
Real-ESRGAN + корректировка Ланшоцем |
20,23% |
монохромная векторизация + корректировка Ланшоцем |
20,38% |
super 2xSal + корректировка Ланшоцем |
20,83% |
Ultramix - Balanced + корректировка Ланшоцем |
20,88% |
Remacri |
20,93% |
окно Пуассона c корректировкой |
21,02% |
scaleFurry с корректировкой Ланшоцем |
21,14% |
UltraSharp + корректировка Ланшоцем |
21,25% |
scaleRough + корректировка Ланшоцем |
21,27% |
квадратичная гравитация + корректировка Ланшоцем |
21,75% |
окно с плоской вершиной |
21,80% |
окно Гаусса радиусом 0,5px + корректировка Ланшоцем |
21,95% |
Real-ESRGAN-anime + корректировка Ланшоцем |
23,10% |
большой дизеринг + корректировка Ланшоцем |
26,51% |
2х-цветный дизеринг + корректировка Ланшоцем |
27,01% |
«+ корректировка Ланшоцем» – значит, что метод без корректировки Ланшоцем радиусом 1 исходный пиксель выдаёт более худший результат. Если этого нет, то наоборот корректировка лишь ухудшает результат. Проанализирован пока лишь один метод корректировки, но для начала сойдёт и просто её наличие/отсутствие.
Пока немного выигрывает мой scaleSmooth – чуть меньше размытости, чуть больше точности (поправки, исправления и критика приветствуются в комментариях).
В дальнейшем будут проанализированы корректировки размытием, интерполяцией, Ланшоцем радиусом 3px, ближайшим соседом, окном Ханна, waifu, scaleSmooth и др., а также методы Preserve details (enlargement), Preserve Details 2.0, Bicubic Smoother, Bicubic Sharper, Bicubic (smooth gradients), FFTzoom, LightInterpolation, PseudoNeuroUpscale, Lanczos2, waifu2x swin_unet / photo, waifu2x swin_unet / art, waifu2x swin_unet / art scan, waifu2x cunet / art и xBR-Hybrid на разных изображениях и масштабах.
Больше примеров и наглядности - здесь и здесь
Гитхаб для тех, кто заинтересовался и/или может помочь - https://github.com/no4ni/scaleSmooth/
Я считаю, неплохой старт?
Но, конечно, прибегать к этому всему нужно только тогда, когда достать изображение большего разрешения невозможно или ошибка не так критична, как время, затраченное на получение более детальных данных:

Другие эксперименты с изображениями - здесь
Комментарии (40)

wmlab
06.05.2024 12:04+2Шансов качественно апскейлить произвольное изображение нет никаких, ибо информация там уже безвозвратно потеряна. Но если мы имеем дело с ограниченным количеством знакомых элементов (например, изображение числа или осмысленного текста или дорожного знака), то можно восстановить даже пожатое до трех-четырех пикселов изображение.

smile_artem Автор
06.05.2024 12:04Это понятно, вопрос не в том, чтобы полностью восстановить изображение, а в том насколько максимально это возможно сделать, не привнося новых структур типа сеток, а наоборот либо подчеркнуть структуры изображения, либо сделав наиболее приятное качество для восприятия глазом, либо как тут минимизировав ошибку (ясное дело, что до нуля это сделать теоретически невозможно), отбросив слишком мелкие детали, не поместившиеся в изначальное разрешение.
wmlab
06.05.2024 12:04+1Опять же, точный апскейл возможен в специфичных случаях. Например, если у нас есть априори информация о классе или стиле исходного изображения. Вот клипарт - набор сплайнов определенной толщины и цвета с однотонными заливками без мелких элементов между пикселами ужатого изображения (теорема Колмогорова). Да, тогда восстановить возможно и даже без нейросеток. При даунскейлинге теряются высокие частоты спектра. Методы AI восстанавливают их из тренировочного датасета, что часто приводит к галлюцинациям (далекие минареты в Нью-Йорке, павлины в облаках и т.п.)
smile_artem Автор
06.05.2024 12:04Да, осталось автоматом определять класс и стиль исходного изображения с максимальной точностью и применять для него метод, дающий максимальную точность для этого вида изображений (в идеале 100%, если нет мелких элементов между пикселами ужатого изображения). Может Вас смутило название статьи - здесь "точный" означает максимально точный насколько это возможно. Понятие вида "идеальный газ"
smile_artem Автор
06.05.2024 12:04Тем более, что на практике мы вряд ли будем апскейлить произвольное изображение (например, белый шум), а один из классов - рисунок, фото, трёхмерная графика, текст с их подклассами, или, применительно, к научным данным - всегда есть какая-то закономерность, а это уже накладывает некие ограничения на произвольность изображений. Всё равно ошибка будет, но это даёт нам ещё немного информации. Вопрос, как ей эффективнее воспользоваться.
smile_artem Автор
06.05.2024 12:04Например, для базы ImageNet [1000 различных классов объектов], несмотря на то, что каждое изображение содержит 224 × 224 × 3 = 150528 пикселей, оценка внутренней размерности лежит [всего] между 26 и 43
https://alphacephei.com/ru/lecture12.pdf
Что говорит о том, что у нас заранее НЕ произвольные данные (само понятие изображения - не то же самое, что данные)
smile_artem Автор
06.05.2024 12:04Качественно апскейлит Upscayl, но обсуждаемая тема - не качество, а точность. Нейросети выдают много качества за счёт галлюцинаций/допущений, снижающих точность, то есть вместо вероятности (информации у нас недостаточно для определения конкретной реализации) выдают одну реализацию, зато качественную.

AlexunKo
06.05.2024 12:04Есть такая мудрость - зачем делать правильно то, что делать вообще было не нужно.
smile_artem Автор
06.05.2024 12:04Но, конечно, прибегать к этому всему нужно только тогда, когда достать изображение большего разрешения невозможно или ошибка не так критична, как время, затраченное на получение более детальных данных
К сожалению, бывают случаи когда это нужно - например, медленная скорость интернета, но желание посмотреть видео прямо сейчас и без лишнего мыла.

PereslavlFoto
06.05.2024 12:04+1Пример нужности. Вот фотография, на ней здание, на здании текст. Если увидеть текст, можно точно датировать фотографию. Чтобы прочитать текст, надо апскейлить его хотя бы в два раза. Средствами фотошопа получается слишком невнятная картинка, прочитать на ней не удаётся.

jpegqs
06.05.2024 12:04Если текст нечитаем, то нельзя полагаться на апскейлинг (любой, хоть нейросеть, хоть алгоритм), он может дорисовать буквы неправильно.
PereslavlFoto
06.05.2024 12:04Задача не в том, чтобы прочитать каждую букву, а в том, чтобы угадать лозунг.
smile_artem Автор
06.05.2024 12:04+1Может, но если это действительно необходимо какому-либо человеку и не существует более лучшей фотографии, то какой метод использовать, чтобы минимизировать ошибку? А вообще с текстами немного другая ситуация - если он не рукописный, и мы знаем язык, шрифт, кегль, кернинг, расстояние то до определённых пределов (например один символ - хотя бы 2х2 пикселя) можно достаточно точно подобрать символы
smile_artem Автор
06.05.2024 12:04+1
По моему, пока что лучше всего справляется scaleFurry, ну, у кого здесь как получится прочитать нижнюю строчку?
PereslavlFoto
06.05.2024 12:04+1Первое слово "студия", то есть 30% задачи исполнено. Дальше идут имя и фамилия, их читать не следует.
smile_artem Автор
06.05.2024 12:04Круто, это на какой картинке читается, я просто кроме ст ничего разобрать не могу, а почему имя фамилия читать не следует?
PereslavlFoto
06.05.2024 12:04+1Имя и фамилия не словарные слова, мы не можем их достаточно хорошо угадать из надписи, мы заведомо совершим ошибку. Поэтому незачем и пытаться, запутывая себя.



Error1024
06.05.2024 12:04+2
Я боюсь у вас изначально некорректный тест, при таком сильном "одномоментном" уменьшении изображения, большинство алгоритмов просто "выкидывают" большую часть пикселов. Т.е. большая часть первоначального изображения просто не приняла участие в формировании уменьшенной копии.
smile_artem Автор
06.05.2024 12:04Спасибо, в следующей части использую для уменьшения точное усреднение, как на фото - то что в фокусе, но вдалеке

kovserg
06.05.2024 12:04При уменьшении картинки свои тонкости есть:


smile_artem Автор
06.05.2024 12:04Да, но это слишком специфический случай, никак не относящийся к практическому повседневному использованию и тем более к фото






DimPal
06.05.2024 12:04Решаемая задача кажется мне немного странной. Кто то уменьшил картинку, просто выкинув кучу пикселей не подумав о восстановлении в исходный размер. Если бы при даунскейлинге сохранялись бы дополнительная информация для апскейлига (ну скажем, какие цвета имеют чёткую границу, а какие размазанную) то картинку можно было бы восстановить качественее. Правда я только что изменил постановку задачи: как сжать картинку с потерями и максимально точно/быстро восстановить (для медленного инета, например). Допустимый размер доп-инфы это хороший вопрос, да..
smile_artem Автор
06.05.2024 12:04Думаю, ответ на вашу задачу будет тривиален - максимально точно - вместо доп инфы взять дополнительно побольше пикселей (можно разных в разное время) - быстро - ближайший сосед или интерполяция. Моя задача возникает и в реальном мире - фото/кадр с камеры низкого разрешения или объект на нём вдалеке - и вот уже уменьшенная картинка без доп. информации

yarston
06.05.2024 12:04+1Если после апскейла изображение мутное, можно немножко резкости накинуть, используя unsharp mask. AMD FidelityFX Super Resolution 1.0 так и делает, только величина резкости ещё рассчитывается по локальному градиенту яркости.
smile_artem Автор
06.05.2024 12:04Огроменное спасибо, попробую в будущих анализах, но пока что кажется, что это просто улучшает визуальное восприятие, как нейросети, и ухудшает точность

Unsharp Mask с предположительными параметрами и одинаковой величиной по всему изображению на примере кубической интерполяции
smile_artem Автор
06.05.2024 12:04
smile_artem Автор
06.05.2024 12:04+1
Наглядная демонстрация проблемы нейросетей - даже то, что можно было раньше разобрать - исковеркано, увеличилось качество, но понизилась точность




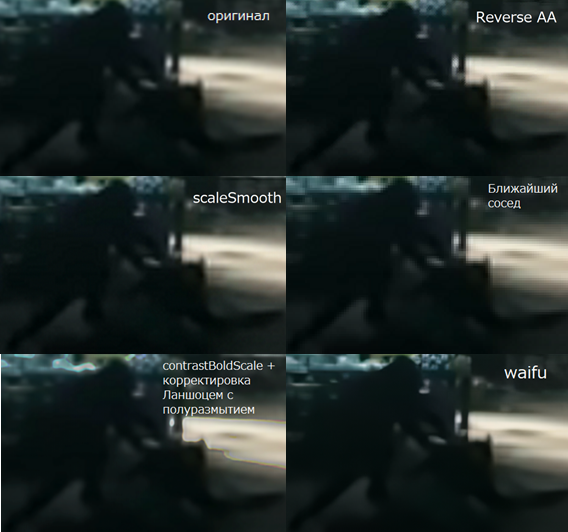
jpegqs
Разрыв в 0,08% - так выглядит однозначная победа? На одной невнятной тёмной картинке? waifu2х натренирован на артах, это для других изображений. Не говоря о том, что у waifu2х есть разные сети на разные случаи.
smile_artem Автор
Дельное замечание - рисунки тоже делятся на разные стили, немного исправил текст
jpegqs
Ну, указали вы модель waifu2х, это ничего не решило. Вы пробовали другие модели? Давайте посмотрим ваши картинки со сравнения. Почему оригинал выглядит размытым? Сравните результат waifu2х со своим, визуально у waifu2х лучше, с более чёткими деталями. Если у вас изображение ближе к фото, то и модель другую надо выбирать, модель art пытается сделать более чётко, как на рисунках. Да и, еще раз, картинка вообще не подходящая, что я должен в темноте высматривать.
smile_artem Автор
Всё верно, но другие картинки и модели waifu будут в следующей части
smile_artem Автор
Больше примеров и наглядности - здесь
smile_artem Автор