
Название звучит как "приворот по фото", но я о чём - захотел я как-то проанализировать пару графиков, найти корреляции и столкнулся с парой сложностей:
Оцифровка аналоговых графиков
I. У меня был только график - картинка (аналоговое представление данных), самих данных (значений) не было. Принялся я по нему вычислять хотя бы наиболее важные точки - в итоге получилось ужасно долго и просто ужасно (человеский глаз и осознанный мозг не может предоставить точность больше 10% деления, а ещё случаются незамеченные ошибки):

Поэтому, я написал специальную, программу, с которой вами делюсь: скачать можно здесь
С её помощью получается почти идеальный вариант:

Рассказываю как пользоваться, чтобы оцифровать значения графика:
(Желательно предварительно подрехтовать картинку, чтобы график был тёмный, других тёмных элементов не было, рамка чтоб была серая, но это необязательно). Загружаем график, он сразу превращается в чёрно-белый
Регулируем яркость (светлее/темнее), чтобы лишние элементы с области значений ушли, а график и рамка осталась (не нужно если область значений во всю картинку).
Выделяем область значений, либо не касаясь рамки, либо повторяем пункт 2, чтобы она тоже исчезла
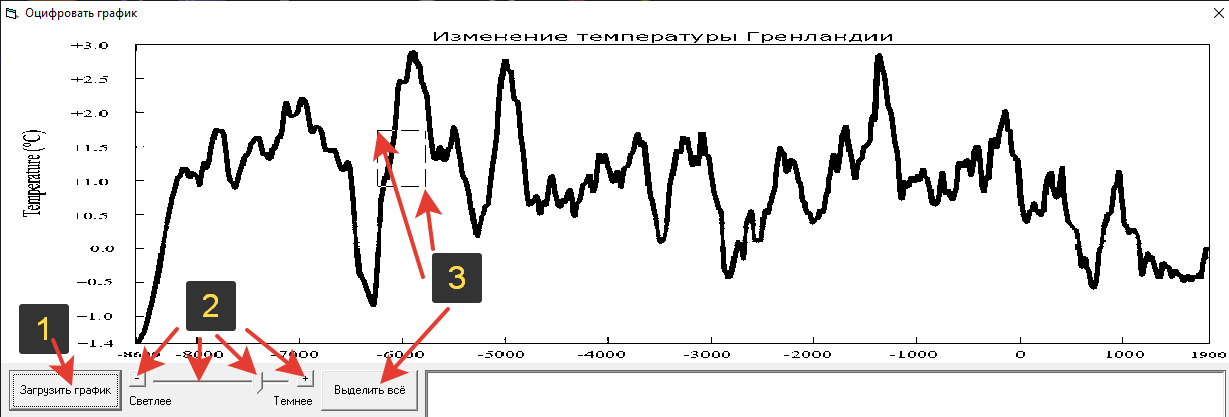

Вписываем диапазон значений для рамки и нажимаем "Получить значения"

Дожидаемся результата и копируем его куда хотите, например, в Excel.

Поиск корреляций и оценка их значимости на временных рядах
II. Вторая проблема, с которой я столкнулся - это то, что как мне подсказали, указав на эту очень важную статью - Корреляция между временными рядами: что может быть проще? - на случайных процессах (коими являются большинство графиков) по большей части не будут работать знакомые нам формулы из базовой теории вероятности (особенно на немарковских процессах.
К сожалению, при применении статистических методов на этот нюанс часто не обращают внимания. Однако, именно эта "мелочь" приводит к очень серьезным и нетривиальным следствиям с точки зрения обработки таких сигналов. Самые обычные формулы, описанные во всех учебниках, внезапно отказываются работать. А попытки их применения "в лоб" иногда дают, мягко говоря, весьма неожиданные результаты. Например, статистическая связь между числом пиратов и глобальным потеплением оказывается не просто "значимой", а "практически достоверной". Что удивительно, столкнувшись с такой ситуацией, даже достаточно грамотные исследователи не всегда понимают, где же тут "порылась собака". Данные вроде бы правильные, ... А результат – ни в какие ворота... А Вы твердо уверены, что всегда правильно оцениваете значимость таких корреляций? - Корреляция между временными рядами: что может быть проще?
Поэтому даже корреляция в 90% может быть обыденностью и ничего не значить) - её азы написаны для случайных величин (а не процессов, где Y зависит от Х), поэтому для начала нужно найти функцию распределения случайного процесса, в зависимости от которой нужно применять специальные, ей подходящие, законы. Это задача намного сложнее предыдущей, однако, моя программа, я думаю, хоть и не решит её полностью - может помочь:
Для правильного выбора доверительных интервалов, критических значений признака проверяемых гипотез - в общем чтобы результаты исследования опирались на математику, а не на первые найденные формулы в интернете - необходимо знать какое распределение у значений - нормальное, показательное, равномерное, какое-то ещё? И в зависимости от распределения пользоваться соответсвующими формулами, таблицами, ограничениями и т.д.
Для этого прежде чем приступать к анализу, первым делом желательно вычислить эмпирическую функцию распределения и сравнить её с теоретической:

Итак, для "затравки" - вычисление графика эмпирической функции распределения для случайных величин:

Вы можете спросить - это что за график такой, где Y не зависит от Х? Вот несколько примеров:
а) просто повернуть наш исходный график разницы температур от года на 90°, поменяв местами Х и Y (который будет уже не графиком, а плоской кривой) - зная год, можно узнать среднегодовую температуру, а вот зная температуру - не всегда можно однозначно сказать какой это год (этакая хеш-функция получается)
 верно показывает, что года распределены равномерно")
б) Вот следующее изображение, иллюстрирующее результаты опыта с броском игрового кубика со смещённым центром тяжести:
")
в) связать два графика через время:
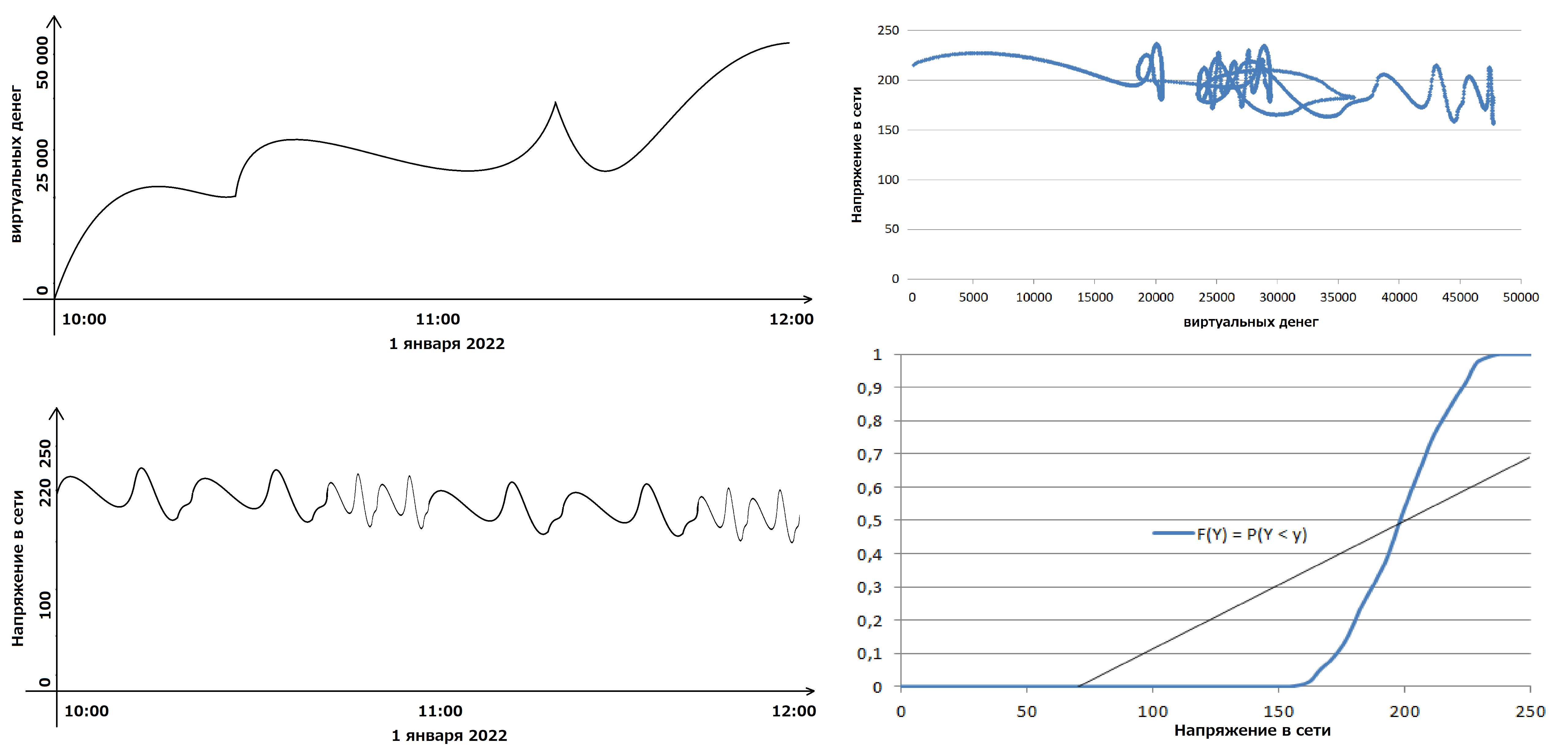
На графиках слева показаны сколько денег в игре на смартфоне, не подключенном к сети электропитания, у конкретного мальчика в Калининграде, и какое напряжение в сети в конкретном доме в Анадыре в одно и то же время. Справа получившаяся пересекающаяся кривая этого напряжения от вышеупомянутых виртуальных денег. Поскольку напряжение не зависит от виртуальных денег (хотя апофенисты могут и тут придумать связь - чем я и занимался в прошлой моей статье Взаимосвязь температуры и населения (там можно скачать данные по температуре и населению за 10 000 лет), хоть и не утверждал, что мои выводы верны -, и действительно на некоторых участках она видна), эту кривую можно считать геометрическим представлением случайной величины, а не процесса. И можно восстановить функцию распределения напряжения - последний график, который показывает, что напряжение распределено не равномерно, а имеет место быть нормальное распределение. Это можно было выяснить и из второго графика, однако, если у Вас в наличии только пересекающаяся кривая - моя программа Вам в этом поможет.
Переходим далее к функции распределения случайных процессов:

Во-первых, здесь ограничение в том, что графиков на одной картинке должно быть несколько, где каждый график представляет собой конкретную реализацию этого случайного процесса. Однако, очень часто у нас есть только одна реализация на конкретном временном отрезке (у нас пока одна планета, например). В таком случае, конечно, Вы можете проводить исследования, находить закономерности, корреляции - и математика Вам этого запретить не может. Но нужно понимать, что смысла в этом столько же, сколько в том, чтобы подбросить монетку один раз в полдень, и на основе результатов только этого эксперимента судить о том с какой вероятностью выпадает орёл, решка, монета встаёт на ребро, теряется, если её подбросить ровно в полдень. Поэтому, например, если Вы собираете данные об изменении глобальной температуры планеты за несколько тысячелетий, а они остались только в ледниках, возьмите хотя бы данные с нескольких ледников, чем больше - тем лучше, точнее и адекватнее будут результаты Ваших исследований.
Во-вторых, полная функция распределения случайного процесса многомерна: для одной реализации - она трёхмерна, для двух - уже пятимерна и так далее. Моя программа может дать значения только графика трёхмерной проекции функции распределения, поэтому это неполная информация о ней, однако и они могут дать некоторое представление. В теории, можно усовершенствовать программу и для больших измерений, но для ПК это будет чрезвычайно долго (уже трёхмерная проекция - без параллелизации, конечно, но - строится десятки минут), а также, я не представляю что могут дать только значения функции, без её формул, для больших измерений, которые мы даже посмотреть не сможем - Вы сможете представить себе хотя бы пятимерную поверхность, даже если построить всевозможные её проекции?
")

И, завершая тему функции распределения спрошу - есть математики статанализа в этом самолёте, который без пилота вряд ли долетит куда надо?
Для математически верного доказательства значимости любых корреляций двух временных рядов между собой нужно знать ответы на некоторые вопросы. Итак, мы с @adeshere (мы не математики, а программист и физик) спрашиваем:
Пусть у нас есть случайный процесс вида x(t), где t-время. Все, что мы знаем про этот процесс — это то, что для почти любой его реализации спектр полученного временного ряда (ведь реализация случайного процесса — это временной ряд) имеет степенной вид. То есть, спектральная мощность W в первом приближении зависит от частоты f, как W(f) =Cf^(-b), где C - это некоторая константа, а степенной параметр b лежит в диапазоне от 0.5 до 2.0. То есть, чем выше частота, тем меньше спектральная мощность, и наоборот. Так вот, теперь возьмем две реализации такого случайного процесса (два временных ряда), определенные на интервале времени T. Обозначим их, как Х1 и Х2. (Задача со звёздочкой - если взять не две реализации одного процесса, а много двух разных случайных процессов Х1 и Х2, также удовлетворяющих требованиям - спектр имеет степенной вид, C - константа, b ∈ [0.5,2.0]) И посчитаем формально в пределах интервала T статистику, ПОХОЖУЮ на коэффициент корреляции: R12=cov(x1,x2)/(s1s2), где cov(x1,x2) — это аналог ковариации, а s1 и s2 — аналоги стандартных отклонений для Х1 и Х2.
Вопросы такие:
1) Можно ли найти функцию распределения R12(b1,b2), зная только степенные параметры исходных случайных процессов b1 и b2? Если да, то какая она будет? Или хотя бы для случая b1 = b2? Или зная ещё и константы C?
2) Если этих знаний недостаточно, то какие еще ограничения на случайные процессы надо наложить, чтобы вычисление этой функции распределения стало возможным?
3) Еще интересный вопрос — доказать, что функция распределения случайной величины R12 не зависит от T. Я подозреваю, что в силу автомодельности случайных процессов зависимости быть не должно. Но это надо доказывать. Или все же зависит?
Очень надеемся на ответы в Ваших комментариях или ссылкой на статью. Заранее благодарны!
А мы продолжаем с программой:
Бонусом с помощью неё можно добиться интересных (не относящихся к математике) результатов, если вместо графика загрузить скриншот текста или фото:


Комментарии (5)

vassabi
19.07.2022 14:20+1я не настоящий статистик, но по идее
если нормализовать ваши функции (спектр?), то разница в С перестанет влиять на дальнейшие расчеты. Можно еще также поиграться с дисперсией. Или взять логарифм с подходящим основанием и считать не " W(f) =Cf^(-b) " а " Wlog(f) =f(-b)*log(C)"
чем больше Т - тем лучше (меньше выбросов, выше точность)

adeshere
21.07.2022 02:23Отбеливание спектра - это довольно распространенный подход при анализе данных и поиске связей между сигналами, но у него есть изрядное количество недостатков. Во-первых, для этого надо уметь в дробное дифференцирование, а при наличии пропущенных наблюдений и прочего брака (а в геофизике и при мониторинге без них не бывает) это не так просто сделать. Я вот в своем пакете для анализа временных рядов до сих пор не смог это реализовать. А принудительно заполнять пропуски не хочу, у нас вся идеология обработки строится на том, чтобы вымышленные значения не использовать. Ведь любое заполнение пропусков требует наличия модели сигнала, по которой эти значения генерируются. А у нас одна из основных целей обработки обычно как раз и состоит в том, чтобы такую модель построить.
Во-вторых, отбеливать спектр - это намного сложнее, чем просто посчитать "квазикорреляцию" и оценить ее значимость по специально подкорректированным формулам. Если, конечно, такие формулы удастся построить (для чего как раз и нужно то самое теоретическое распределение посчитать).
В- третьих, при работе в терминах корреляций (когда имеешь дело с практическими сигналами) обычно несложно построить робастную версию алгоритма процессинга данных без слишком искусственных ухищрений. Если же анализ включает процедуру отбеливания спектра, то это гораздо сложнее (во всяком случае, для меня), и уж точно не слишком интуитивно. Я вообще предпочитаю работать во временной области, а не в частотной - это намного понятнее и результаты интерпретировать проще почти всегда. А что получится, если сделать преобразование Фурье, потом прологарифмировать спектр, потом обратное преобразование Фурье, мне сложно представить. Попробовать можно, конечно, но там же еще с фазами какие-то трюки потребуются... И шуметь такой алгоритм на неидеальных данных (а реальные данные мониторинга всегда со странностями) наверняка будет ужасно.
Исходный-то сигнал логарифмировать бесполезно. Ведь нестационарность при логарифмировании не устраняется. И степенной спектр плоским тоже не станет: если сигнал далек от нуля, то после логарифмирования его спектр так и останется степенным. Я уж не говорю о том, что операция логарифмирования чувствительна к добавлению константы - а в геофизике довольно много измерений выполняются как раз с точностью до произвольной константы. Поэтому логика здравого смысла требует, чтобы при обработке симметрия результатов относительно смещения уровня не нарушалась.

openbsod
20.07.2022 16:25Спасибо! Очень интересно. И раз уж нет исходников — рассмотрите, пожалуйста, возможность работы вашей программы под linux.

a_stafford_a
Интересный кейс, хоть половину не понял, но сохраню, чтобы перечитать и вникнуть больше.