
Давным-давно, ещё во времена больших сотовых телефонов и динозавров, когда PERL был перспективным языком программирования, наши инструменты были очень простыми и надежными:
PUTTY и FTP были основным способом обмена кодом и ведения совместной разработки.
Разработку вели в одиночку или малыми командами.
Хотфиксы мы катили, сразу редактируя файлы в VIM на prod машинах.
Но всё изменилось с приходом систем контроля версий: GIT, SVN, Mercurial, etc. И появление этих инструментов открыло путь к крупным проектам, большим командам и сложным продуктам.
Нам нужно было адаптироваться. Пришлось учится работать в больших и сложных командах, чтобы создавать классные продукты.

Сегодня я расскажу про свой любимый подход к разработке Trunk Base Development, сравню его с другими моделями ветвления и подсвечу его достоинства и нюансы.
Краткий обзор трёх моделей ветвления: Central Workflow, Git Flow, Trunk Based Development, с акцентом на моего фаворита — Trunk Based Development.
Central Workflow
Просто комит и сразу в мастер. А ветки для слабаков.

В итоге Central Workflow подходит:
Для небольших проектов (pet-проектов).
Для команд из 2-3 разработчиков.
Когда мастер сломан.
Git Flow
Процесс — это все! Сложный процесс со сложной моделью ветвления.

Чтобы было проще, постараюсь изложить процесс в виде цикла разработки фичи:

Для создания фичи, вы создаете ветку feature. Ветвите вы её от ветки develop:

Ветка создана, можно начинать разработку.

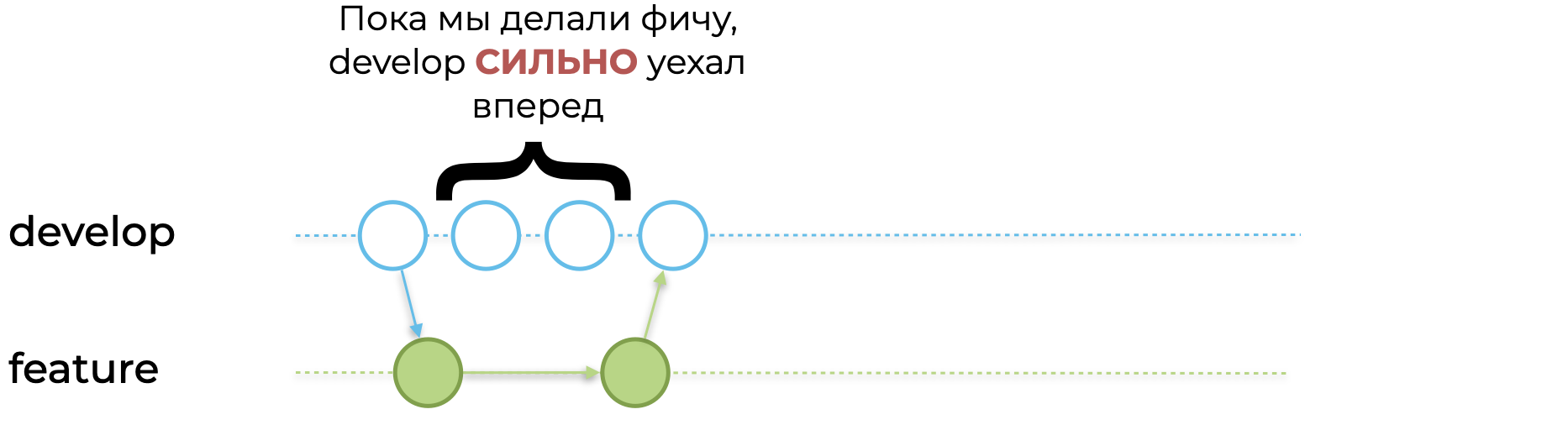
Ваша команда долго и упорно готовила фичу — теперь всё готово! Но другие команды разработки тоже делают свои проекты. Допустим, готовые фичи уже слили в develop-ветку, при этом ваша ветка сильно отстала.
[Первый раз] Вы решаете конфликты и сливаете ветку в develop:
Время релиза! Вы решили поделится своей фичей с пользователями. Создаётся ветка release от вашего комита.
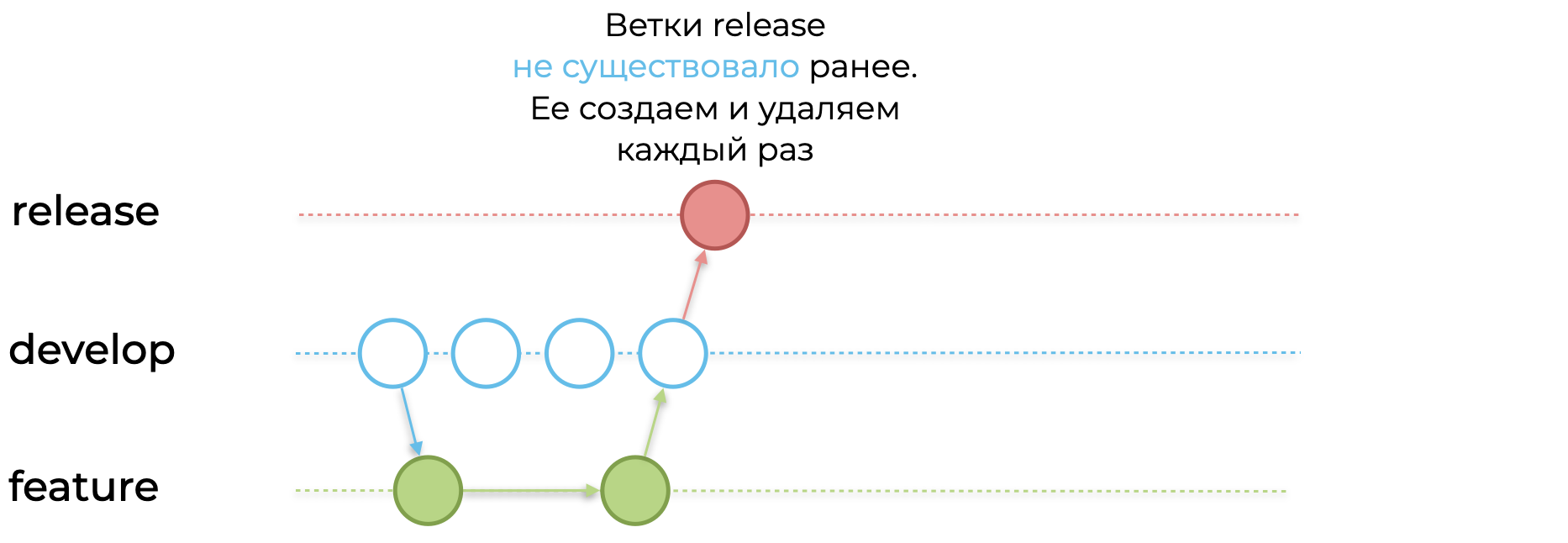
Но релиз нужно стабилизировать. В нем есть баги, и конфликтующие фичи. Для этого делаем несколько hotfix. Важно, что делаем мы их в релиз-ветке, потому что планируем выкатить именно её.

Релиз стабилизирован. Сливаем его в master c тегом v1.0.0 и катим на prod. Хотфиксы тоже надо слить в develop-ветку. За это время develop опять ушёл вперед.
[Второй раз] Вы решаете конфликты и сливаете ветку в develop:

На prod мы неожиданно ловим еще несколько ошибок, которые важно пофиксить. Вы делаете хотфикс на prod и ветку v1.0.1.
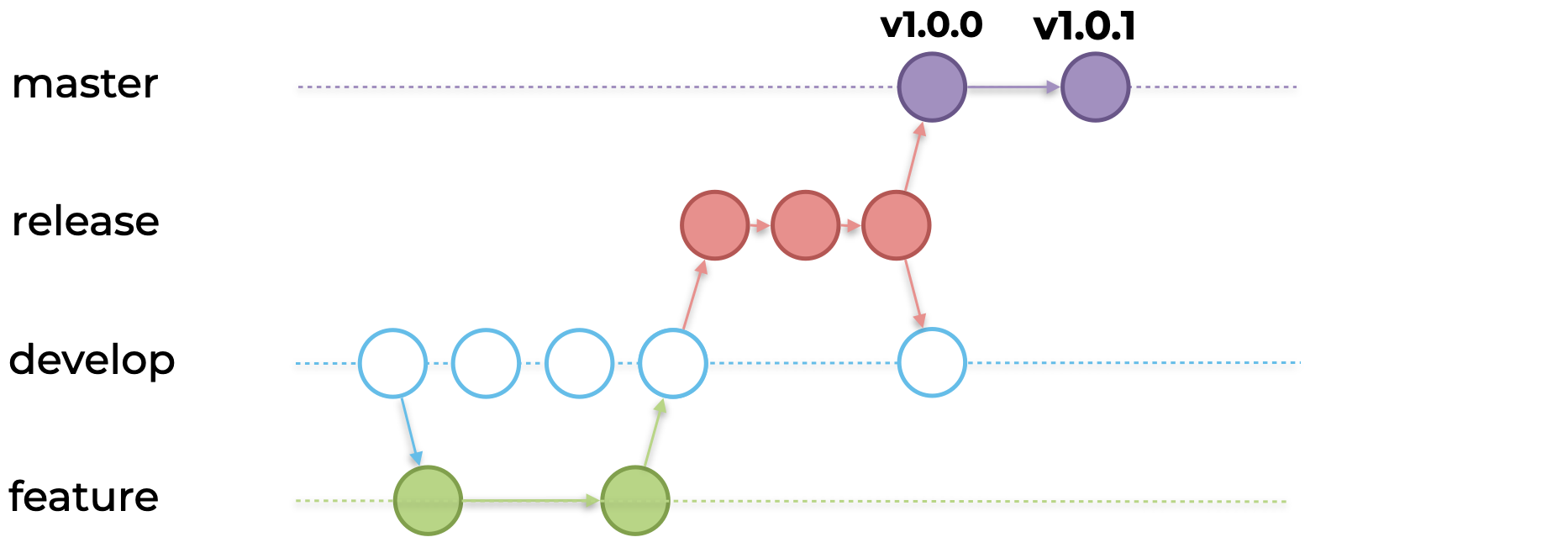
Но новый хотфикс тоже нужно положить обратно в develop-ветку. За это время develop опять ушёл вперед.
[Третий раз] Вы решаете конфликты и сливаете ветку в develop:

В итоге Git Flow:
Очень сложно и запутано.
Много конфликтов в процессе.
Долгий релизный цикл, который плохо подходит для CI\CD.
Подходит для ПО с классическим релейным циклом (параллельная работа над разными версиями, релиз раз в месяц на дискетах).
Trunk Based Development

Характеризуется всего тремя типами веток и итеративным подходом к разработке фичи (привет, Scrum).
Постараюсь изложить его в виде цикла разработки фичи:

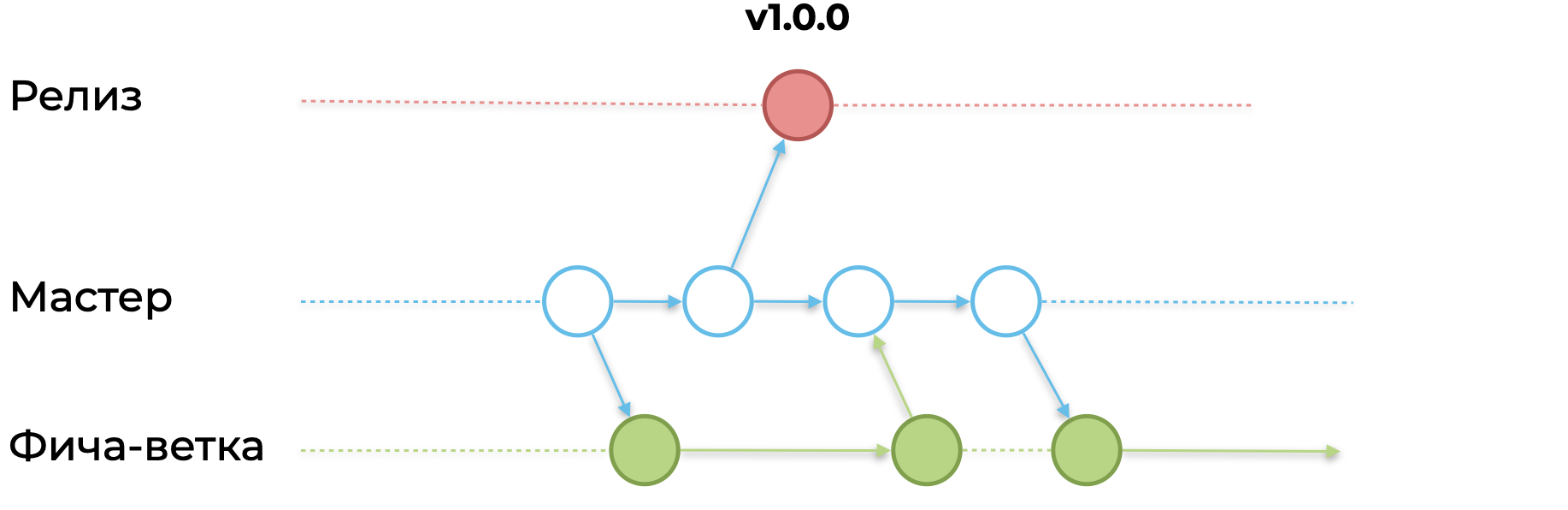
Для создания фичи, вы создаете ветку feature. Ветвите вы её от ветки master:

Делаете несколько комитов, заглушки под фичу и необходимые интерфейсы:

Сливаете фича-ветку в master. Ваш функционал может быть закрыт feature-toggle или if false { ... } — «сырой» функционал не должен быть доступен пользователю.
Важно!
Так как с момента ветвления до момента слияния вашей фича-ветки прошло очень мало времени, master не успеет далеко уйти и у вас будет минимум или полное отсутствие конфликтов при слиянии. При этом вы «застолбили» для своей фичи место, подсветили другим командам, к примеру, интерфейсы, которые планируете имплементить. И другие команды будут сразу учитывать это в своей работе.
А ещё у вас очень маленькие PR\MR, которым можно легко и быстро провести code-review. Знаете же эту классическую проблему — большие PR смотрят долго и некачественно.

У вас может быть организован процесс непрерывного деплоя, или деплоя по расписанию, в prod. Так как в master не сливают сложные и плохо протестированные изменения — master остаётся чистым, готовым к релизам.
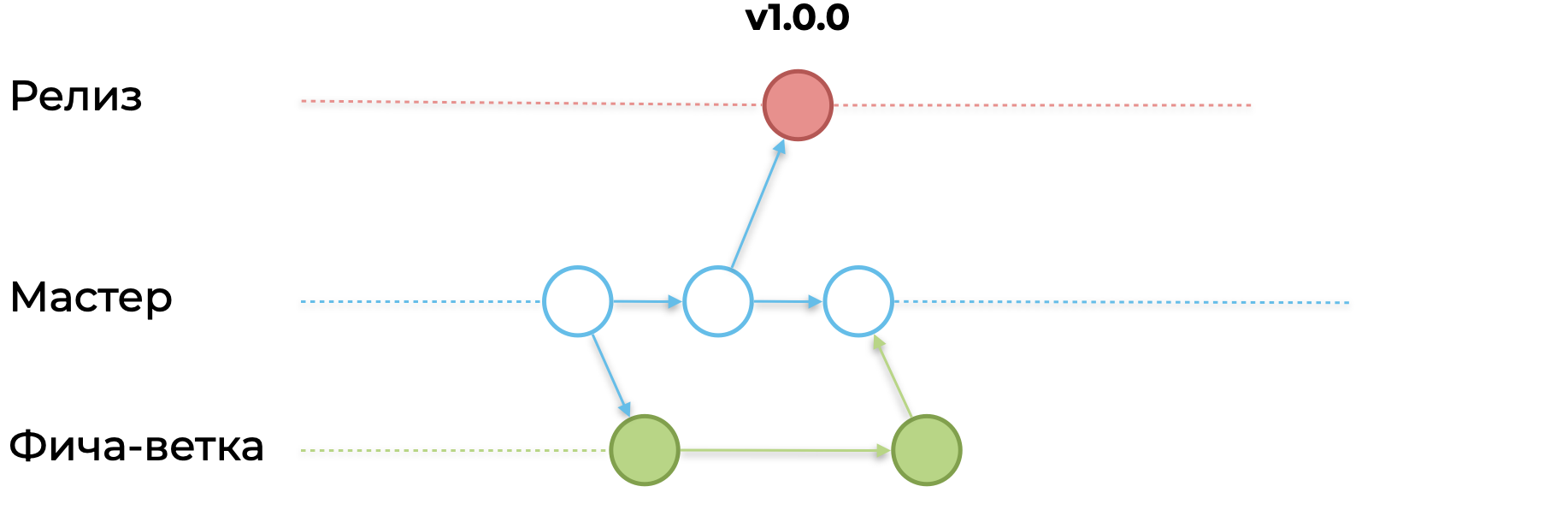
Вы продолжаете работать над своей фичей в новой итерации — продолжаете её и углубляете.
Важно, чтобы ваша новая фича-ветка оказалось очень короткоживущей, чтобы ловить минимум конфликтов при слиянии и углубить создание фичи.
В итоге, TBD — это:
Ветки, которые живут несколько дней.
Feature-flags для закрытия «сырого» функционала.
Continuous Сode Review. Код-ревью фича проходит каждую итерацию — дифф маленький, ревью делается быстро.
Чистый мастер, готовый к релизу в любой момент.
Плюсы TBD:
Минимум конфликтов при разработке.
Готовность к релизам в любой момент без подготовки.
Очень быстрая и качественная обратная связь на PR\MR.
Минусы TBD:
Не подходит, если в команде много junior-разработчиков. Ребятам гораздо легче делать\ревьювить готовую фичу целиком, чем разделить работу на этапы и держать прошлые итерации в голове.
Нужно доверять комитерам, иначе будут висеть недоделанные фичи и будет непонятно, кто и когда их доделает.
Если потребуется revert — будет больно. Мастер постоянно бежит вперед и revert функционал спустя пару дней уже тяжело. Проще исправить или удалить руками.
Кому подходит TBD:
Опытным командам с небольшим количеством junior-разработчиков.
Большим командам, которые параллельно работают над большим количеством фич.
Приложениям с долгим циклом регрессивного тестирования.
Проектам с непрерывным релизным циклом.
Для кого TBD не очень хорошо подходит:
Junior-командам.
OpenSource-проектам.
Проектам с жестким (классическим) релизным циклом с отгрузкой софта клиентам на дискетах.
Почему всё же TBD

Time To Market
Использование такого подхода дает огромный прирост к TTM метрике.
Короткоживущие ветки позволяют вам экономить время на конфликты при слиянии, а когда нет конфликтов — и нервы экономишь. Багов после решения конфликтов возникает гораздо меньше.
Фича-тогглы, которыми закрываете не протестированный функционал позволяют вам увереннее катиться в прод, потому что фичу сразу можно отключить. И времени на стабилизацию релиза тратится меньше — все новые фичи изначально под тогглом.
Чистый мастер позволяет вам делать релизы настолько часто, насколько нужно. Релизы перестают быть переполнены фичами, а ещё пропадают «ждуны», которые просят задержать релиз.

Релизы бэкенда-монолита:

Релизы приложений:

В таблицах примеры того, как ускорились релизы в Авито за несколько лет. Цифры не самые свежие, но честные.
Вывод
Все фломастеры на вкус разные, но особенно вкусные те, что цвета Trunk Based.
Для Авито эта модель ветвления подошла лучше всего: она позволила сильно ускорить разработку, внедрить быстрый релизный цикл, меньше ловить конфликтов на слиянии, упростить жизнь разработчикам.
Она гораздо проще, чем многие другие модели, но имеет свои ограничения. Выбирайте с умом!
Полезные ссылки
Комментарии (31)

dzm
07.09.2022 19:29+1Всегда было интересно, как при таком подходе решили такие задачи (упрощено для обсуждения):
1. Нужно изменить одну функцию, которая затрагивает 20 других сервисов. При этом эти в этих сервисах еще нет изменений (и текущая команда не может их сделать, делают другие команды). При этом нужна миграция данных.
Пример: хочу в БД хранить массив JSON'ов вместо одного JSON'а, аналогичные конструкции записывать в БД, это используют 20 потребителей через вычитку из БД.
2. Как делать хотфикс, если функционал из убежавшего вперед мастера еще не должен быть выпущен? Аналогично Git Flow?
3. Как при таком подходе делать рефакторинг? Или все-таки пропущен процесс управления, разрешающий, к примеру, только ATDD и не менее 99.5% покрытия?
funca
07.09.2022 20:10Нужно изменить одну функцию, которая затрагивает 20 других сервисов
Старый код не удаляется сразу. Изменение пишется рядом и закрывается фича тоглом. Тогл определяет по какому пути идёт вычисление. Его включат когда остальные будут готовы, а пока гоняют только на тестах. Через несколько итераций после включения будет задача на выпиливание ненужного кода.
Как делать хотфикс, если функционал из убежавшего вперед мастера еще не должен быть выпущен?
Фикс идёт и в master и в релизную ветку (в которой нет прочих изменений). Новый билд из релизной ветки уходит в продакшен.

lebedec
07.09.2022 22:35+2Нужно изменить одну функцию, которая затрагивает 20 других сервисов.
По правилам разработки библиотечного кода. Через обратную совместимость. В сложных случаях у вас будет две версии функции одновременно. Устаревшую версию удаляете только когда все потребители перейдут на новую версию.
Как делать хотфикс, если функционал из убежавшего вперед мастера еще не должен быть выпущен?
Если проект большой и в него комитят хотя бы десяток человек, вы будете один и тот же фикс реализовывать столько раз, сколько релизов у вас на текущий момент.
Вообще TBD не новое изобретение. Так работали практически все системы контроля версий до эпохи git. Этот недостаток и стал одной из ключевых причин популярности git и git flow лет 10 назад.
Интерес к TBD возобновился в контексте применения непрерывной разработки и доставки сервисов. Когда вы ежедневно выкатываете новую версию сервиса, а цена ошибки не велика — в принципе теряется значение таких понятий как "hotfix" и "develop".
Если у вас есть необходимость в релизных ветках и продолжительной поддержке — это прямой сигнал что к TBD вам возвращаться не стоит.
Как при таком подходе делать рефакторинг?
Очень хорошо. Фактически у вас не должно быть старых веток. Цикл обновления очень короткий. Всё это сводит вероятность конфликтов при слиянии рефакторинга к минимуму.
Другой вопрос что рефакторинг тоже нужно уметь делать, вносить по очереди типовые изменения, а не всё в кучу одним супер коммитом. Но это уже не проблема TBD.

MMgo Автор
07.09.2022 23:50+1Пример: хочу в БД хранить массив JSON'ов вместо одного JSON'а,
аналогичные конструкции записывать в БД, это используют 20 потребителей
через вычитку из БД.В микросервисах обычно не позволяют кому-попало в базу лезть своими руками немытыми.
У сервиса есть контракт с его потребителем, и он должен его соблюдать. способ хранения данных - часть внутренней кухни сервиса.
Как делать хотфикс, если функционал из убежавшего вперед мастера еще не должен быть выпущен? Аналогично Git Flow?
тут есть несколько разных способов.
делать по аналогии с git-flow
идти в сторону ci\cd: фиксить мастер и катить уже его.
Второй подход больше отражает суть TBD - которая приводит нас к чистому мастеру, готовому к релизу в любой момент. И возможность быстро доставлять ценность клиенту
dzm
08.09.2022 03:16+1В микросервисах обычно не позволяют кому-попало в базу лезть своими руками немытыми.
Есть у меня на примете вполне рядовой и понятный пример: таблица с пользовательскими данными, которые нужны множеству потребителей. То есть одно приложение управляет данными, другие их читают, ожидая определенный формат. Как в таких случаях быть? Все 20 команд направлять делать одновременно изменения? Ни дублирование пользовательских данных, ни какая-то модификация на лету не будут правильными решениями с точки зрения управления разработкой, так как "чем больше костылей, тем громче они упадут".
MMgo Автор
08.09.2022 11:57+3Я наверное не до конца понимаю проблему.
Потребители данных не работаю с базой. Они работают с сервисом используя некий(пусть будет RPC) протокол.
Если сервис меняет внутренний способ хранения данных - НОУ ПРОБЛЕМ. Его задача - чтобы публичный контракт оставался обратно совместим.
Допустим - раньше бизнесово у клиента мог быть один адрес, а теперь их стало много. А потребители данных используют контракт где "много" не заложено.
А таком варианте - ты создаешь новые метод в сервисе, в контракте которого уже будет много адресов. И дальше - задача потребителей, ЕСЛИ у них есть изнес-необходимость работать с несколькими адресами - пусть переключаются на новый метод. Если-же задачи нет, и их устраивает один адрес - тоже норм.

zueve
07.09.2022 21:43А как стоится процесс выпиливания не живого кода? Вообще страшно представить во что может превратиться код при интенсивной разработке и большом количестве feature-toggle. Возможны же и конфликты фитч.
MMgo Автор
07.09.2022 23:22Начал отвечать, но осознал, что понятие "конфликт фич" можно понимать по-разному.
Будет здорово, если уточнишь
zueve
08.09.2022 08:11Например, так - включаем фичу 1 - все ок. Включаем фичу 2 - все ок. Включаем обе - все пропало
MMgo Автор
08.09.2022 12:02Вопрос достаточно сложный, на самом деле.
Я исхожу из предпосылок - что все сервисы имеют свои НЕ СВЯЗАННЫЕ друг с другом тогглы.
Такой подход заставляет каждый раз внутри сервиса думать - что делать если фича включена и выключена.
Так как микросервисы не большие по своей природе - тогглов там не бывает много.
Ну а дальше отталкиваемя от того - что за тоггл. Тоггл новой фичи, нужно включить в dev-середе, и прогнать цикл тестирования

SabMakc
07.09.2022 21:50+2Для "честного" сравнения результатов за 2017 и 2020 не хватает отчета о покрытии кода тестами. Потому как именно автоматические тесты (и их качество) - главный показатель готовности к релизу сразу с мастера.
MMgo Автор
07.09.2022 23:25Согласный!
Больше скажу - факторов влияющих на скорость просто огромное количество.
Но отделить импакт каждого из этих факторов крайне-сложно.
Но что могу точно сказать - влияние именно TBD достаточно большое, и без него результаты точно были бы хуже.

denis-isaev
07.09.2022 23:24+3Настоящие вайтишники до прихода GIT, SVN, Mercurial, не правили прод, а пользовались CVS-ом :)
По теме, не понимаю почему одни и те же фичи в TBD — короткоживущие, добавляющие TTM, а в gitflow — порождающие тонны конфликтов?
В описанных кейсах develop gitlfow — это по сути master TBD (то место, куда мы сливаем фичи). И если процессы деплоймента позволяют релизить без предварительных долгих итераций тестирования, то работа с gitflow не отличается от TBD. В gitflow у вас тоже не будет ветки release. Она может создаться где-то в недрах пайплайна и там же вмерджится в мастер. Соответственно не будет хотфиксов на релиз и всех проистекающих оттуда потенциальных конфликтов.
Время жизни фичаветки в gitflow и TBD одинаковое т.к. оно зависит от скорости реализации фичи и flow на нее не оказывает влияния. При этом методологически потенциальные конфликты при мердже фичи в мастер у TBD выглядят более бессмысленными:
К примеру, если мы возьмем фичаветку продолжительностью в три дня, тогда в gitflow мы 1,2 дни мерджим девелоп на нашу фичаветку (или ребейсим фичу на девелоп), чтобы наша ветка не сильно отставала. При этом потенциальные конфликты — это конфликты уже готовых новых фич (от других команд) из девелопа с нашей разрабатываемой фичей. На 3-й день мы финишим фичу в девелоп и 3-й раз потенциально фиксим конфликты новых готовых фич от других команд с нашей готовой.
В TBD же мы 1,2 день мерджим в мастер нашу не готовую фичу и решаем потенциальные конфликты с другими новыми не готовыми (или готовыми) фичами от других команд. Часть этих конфликтов могла и не произойти никогда если бы мы мерджили в общую ветку только готовые версии фич, как в gitflow.
Если нужна итеративная работа над фичей, то gitflow не запрещает накатывать ее на основную ветку и продолжать работать над ней в следующем спринте.
Зато gitflow позволяет делать squash коммиты фич и держать историю основной ветки в большей чистоте.
Плюс code review в gitflow легче т.к. содержит исключительно готовую фичу, а не фичу на некоторой стадии готовности, обернутую вif false, которую нужно будет ревьювить несколько раз по кругу.
А вообще, непонятно зачем "Опытным командам с небольшим количеством junior-разработчиков" смотреть в сторону каких-то готовых методик вроде gitflow или TBD, а не просто юзать гит так, как наиболее удобно для команды?MMgo Автор
07.09.2022 23:39Ух. Спасибо за комент. Мне прямо нравится!
почему одни и те же фичи в TBD — короткоживущие,
добавляющие TTM, а в gitflow — порождающие тонны конфликтов?Далеко не все фичи это 1-3 дня разработки. Как правило времени на реализацию и тестирование тратится существенно больше. (хот-фиксы и перекрашивание кнопок не берем)
Потому - подход TBD позволяет выкатить фичу в прод под флагом. И застолбить под нее место. Обозначить интерфейсы. Другие команды будут видеть код, что под фича-флагами. Будут понимать - что разработка в этом месте ведется и будут это учитывать.
В случае-же git-flow, чем дольше фича не попадает в master будет находится тем дольше и чаще надо будет решать конфликты. Тем больше шансов что появится костыльная дублирующая реализация.
Плюс code review в gitflow легче
Тут термин "легче" штука относительная. И про это я в статье тоже писал.
Отревьювить и дать грамотный фидбек на 50 строк изменений проще и быстрее, чем при 1000 строк изменений.
Но при этом требуется держать контекст предыдущих итераций.
Мое опыт говорит, что опытный разработчик имеющий понимание фичи - достаточно легко справится с поддержанием контекста от итерации к итерации. При этом времени на ревью итерации он тратить сильно не много (итерация маленькая) Ревью будет более качественным (мы когда-то даже статистику строили - зависимость времени ревью от размера PR)
А вот для новичка держать контекст прошлой итерации очень сложно, потому - ему поще делать фичу целиком
denis-isaev
08.09.2022 00:02Потому — подход TBD позволяет выкатить фичу в прод под флагом. И застолбить под нее место. Обозначить интерфейсы. Другие команды будут видеть код, что под фича-флагами. Будут понимать — что разработка в этом месте ведется и будут это учитывать.
Эти плюсы можно переформулировать в минусы — другие команды будут видеть обрывки нашей фичи в боевом коде, им будет непонятно можно ли юзать эти новые интерфейсы, когда они будут закончены и т.д. Кто-то может заюзать вашу не готовую фичу, считая, что она готова. На разруливание этих проблем нужны какие-то внекодинговые мероприятия.В случае-же git-flow, чем дольше фича не попадает в master будет находится тем дольше и чаще надо будет решать конфликты. Тем больше шансов что появится костыльная дублирующая реализация.
Почему чаще? Предыдущие решения же не надо будет заново повторять при последующих конфликтах. Чаще может получиться только если другая команда начнет пилить эту же фичу и две команды будут постоянно генерить друг другу конфликты. Но это странная ситуация, если её исключить, то по идее итоговое кол-во конфликтов при обоих подходах примерно одинаково. Просто мы их решаем в одном случае в фича ветке и потом кучей заливаем в мастер, а в другом инкреметно прям в мастере.Отревьювить и дать грамотный фидбек на 50 строк изменений проще и быстрее, чем при 1000 строк изменений.
Правильнее будет сравнивать 1000 строк изменений за одно ревью против 200 ревью по 50 строк в которых ревьювер видит обрывки фичи и должен вспомнить контекст всех предыдущих ревью. 200 раз! Ну тут спорно что легче :) Наверное, сильно зависит от продукта, предыдущего опыта команды и т.п. Но с однозначным утверждением, что легче именно 200 раз по 50, я бы поспорил :)зависимость времени ревью от размера PR
Так понятно, что мелкий PR быстрее ревьювится. Но сравнивать-то нужно не один мелкий с одним большим, а много мелких с одним большим :)
Я не то чтобы утверждаю, что gitflow — кул, а TBD — сакс. В разных случаях по разному. Но мне тяжело согласиться с безапелляционными доводами статьи почему gitflow — сакс, а TBD — кул :)MMgo Автор
08.09.2022 00:11Правильнее будет сравнивать 1000 строк изменений за одно ревью против 200 ревью по 50
Немного подушню за математику: не 200 интераций по 50 строк а 20 итераций по 50 строк.
эти итерации делаешь быстро. Учитывая современные команды и гибкие методологии разработки - это только в плюс.
Но мне тяжело согласиться с безапелляционными доводами статьи почему gitflow — сакс, а TBD — кул :)
Каждый выбирает фломастер на свой вкус, как говорится. Главное что красный вкуснее=)
Не было задачи показать что git flow - сакс. Но он действительно хуже подходит по современные процессы с ci\cd и гибкими методологиям.
Но при этом git flow хорошо ложится на более медленные циклы разработки, вида классической отгрузки продукта по версиям
denis-isaev
08.09.2022 00:14Немного подушню за математику: не 200 интераций по 50 строк а 20 итераций по 50 строк.
Был взволнован :)
Мне вот кажется, что удобство TBD для ci/cd проявляется как раз в командах с джунами, которые не очень умеют в git :) Потому что сделать «удобный» пайплайн можно и без такой спорной практики, как коммиты кусков фич обернутыеif falseв продакшен ветку.MMgo Автор
08.09.2022 19:51ничего не понял.
Аргумент - только джуны не могут в нормальный git а остальные могут и потерпеть другие флоу.
В целом - все так. Нельзя сказать (и я не говорю) что так правильно а так не правильно.
Я освещая мой любимый подход с TBD и рассказываю о его основных отличиях от других, и как он помогает большим командам эффективно гибко и быстро разрабатывать новый функционал

saboteur_kiev
09.09.2022 04:19Потому что сделать «удобный» пайплайн можно и без такой спорной практики, как коммиты кусков фич обернутые
if falseв продакшен ветку.Это просто неверно практика обсуждалась. Эта практика не относится к TBD, она относится к тем случаям, когда какую-то очень большую фичу никак не могут разделить на несколько маленьких подфич, чтобы они влезли в спринт, и приходится делать фичу целиком за несколько спринтов. В этом случае надо искать какие-то варианты и feature toggle - вполне себе даже удобный, особенно для экспериментальных фич, для которых было бы полезно иметь возможность включать/выключать их на продакшене "онлайн".
В TBD, из-за короткоживущих feature-веток, чаще приходится задумываться о подобном. Но сама feature toggle это просто отдельный один из вариантов решения конфликтов, не привязанный к какому-нибудь flow
saboteur_kiev
08.09.2022 05:03Потому - подход TBD позволяет выкатить фичу в прод под флагом. И застолбить под нее место. Обозначить интерфейсы. Другие команды будут видеть код, что под фича-флагами. Будут понимать - что разработка в этом месте ведется и будут это учитывать.
Неправда. Это как раз требование TBD чтобы фича-ветки были короткие. В результате почти любую адекватную фичу приходится усложнять toggle и другими способами разделения фичи на несколько итераций, чтобы хоть как-то вывести ее в продакшен.
Никто не мешает "застолбить место", "обозначить интерфейсы", сделать feature-flags и так далее в любом другом flow.
Отревьювить и дать грамотный фидбек на 50 строк изменений проще и быстрее, чем при 1000 строк изменений.
При этом возрастает нагрузка на spring planning, и на то что каждую фичу нужно дробить на маленькие кусочки. А это значит, что надо оформить каждый кусочек отдельно, на каждый кусочек выдать и оформить техзадание и придумать как протестировать именно этот кусочек отдельно, а потом еще и фичу целиком.
Таким образом где-то убавляем, где-то добавляем и не факт что фидбек на 50 строк это эффективнее, если надо будет таких фидбеков дать много
MMgo Автор
07.09.2022 23:39+1Настоящие вайтишники до прихода GIT, SVN, Mercurial, не правили прод, а пользовались CVS-ом :)
За одно это с меня пиво!
saboteur_kiev
08.09.2022 05:02+2Настоящие вайтишники до прихода GIT, SVN, Mercurial, не правили прод, а пользовались CVS-ом :)
А до CVS - SCCS ;)
По поводу статьи:
ОЧЕНЬ, ОЧЕНЬ плохо расписан git flow. Почему-то автор указал только проблемы и сложность, но вообще не расписал что решает git flow, зачем нужны эти ветки и как прекрасно он заточен под крупные проекты и множество разработчиков.
Возможно не работал в проекте, где именно git flow решает бОльшую часть проблем.
Ваш функционал может быть закрыт feature-toggle
feature-toggle и другие штуки для выката незаконченных фич в продакшен могут использоваться в ЛЮБОМ flow, это вообще не прерогатива TBD
MMgo Автор
09.09.2022 11:37Все верно. спасибо!
это вообще не прерогатива TBD
Основной постулат TBD - не делай долгих фича-веток. А фича-тогглы лишь инструмент для достижения этой цели.
ОЧЕНЬ плохо расписан git flow.
Ну я так больше про TBD рассказываю-) даже в названии это отразил.
Для git-flow я в целом раскрыл основные свои соображения от использования именно этого подхода. Сложный. Не очень удобен для CI\CD процессов. При этом не отрицаю множества мест и сценариев, где он отлично подойдет.

x8core
09.09.2022 09:57+1Маленький шиноби просто ищет серебряную пулю от конфликтов.
MMgo Автор
09.09.2022 11:30Жаль ни разу не находил, было бы здорово!
Ну и тут понятно - что есть пачка трейдоф.
К примеру TBD не очень подходит под классический релизный цикл: c отгрузкой инкремента раз в пол года
Или к примеру TBD не очень удобен для опенсорс продуктов (не без исключений. лишь большая или меньшая степень удобства с подходом)
SabMakc
09.09.2022 13:00Много конфликтов - сигнал о том, что сильно связанный код / архитектура. А значит есть куда стремиться )
Согласен, что в git-flow конфликтов будет больше и они будут существеннее. Но и feature-flag - тоже не лучшее решение. Потому как имея 10 флагов получаем 1024 вариантов сервиса. И для продуктовой разработки, в идеале, все эти 1024 варианта должны быть протестированы. При "внутренней" разработке сервиса с этим будет проще - набор фич более-менее фиксирован. Но все равно надо тщательно следить за чистотой кода - очень сильно сомневаюсь, что все фичи поголовно доходят до релиза и их флаги оперативно выпиливаются.
Ну и на закуску - из опыта могу сказать, что в Mercurial (hg) слияния проходят проще и с заметно меньшим числом конфликтов - просто из-за разницы подходов (git оперирует срезами состояния каталога, hg оперирует историей изменений). И лично мне очень жаль, что именно git занял лидирующую позицию, а не hg. Mercurial мне намного больше нравился... Но git сейчас практически безальтернативен...
saboteur_kiev
10.09.2022 01:10Ну и на закуску - из опыта могу сказать, что в Mercurial (hg) слияния проходят проще и с заметно меньшим числом конфликтов - просто из-за разницы подходов (git оперирует срезами состояния каталога, hg оперирует историей изменений).
А вот этого не понял. Как это влияет на конфликты?
Суть же в любом случае только в том, что текстовые файлы отличаются.Мне как раз кажется, что то, как git оперирует изменениями - идеально для того, чтобы сделать с ним что угодно. Вдобавок гит не стоял на месте последние 10 лет.
SabMakc
10.09.2022 10:50Я не знаю, как именно и почему так - но по опыту - с git проблем с слиянием гораздо больше.
А главное - если в результате рефакторинга файлы поменял свое расположение (скажем пакет в java переименовали), то при слиянии дубли этих файлов могут появиться в старом месте. И это не будет конфликтом - git посчитает, что это новые файлы.
Я эту проблему глубоко не копал, чтобы воспроизвести вручную. Но из проекта несколько раз приходилось такие дубли вычищать. Изучение истории показало, что дубли возникли после слияния.
Мне как раз кажется, что то, как git оперирует изменениями - идеально для того, чтобы сделать с ним что угодно.
Git хранит именно состояния файлов, а diff высчитывает "на лету", по мере необходимости. Впрочем, что спорить - внутреннее устройство git не является тайной за семью печатями. На Хабре были неплохие разборы внутреннего устройства git.
chemtech
Спасибо за пост. Кроме вашего поста нигде "Trunk Based Flow" никто так не называет. Называют Trunk-based Development.
TheDenis
Автор сам не определился :) В тексте много раз присутствует акроним TBD.
MMgo Автор
Спасибо. Поправлю. Изначально использовал TBD акроним, но сказали не понятно_)