
Привет! Меня зовут Павел Лакосников. Я тимлид команды SLA в Авито, которая работает с надёжностью сайта и приложения.
Авито рос и развивался, и продолжает развиваться сейчас. У нас вырос сайт, нагрузка, увеличилось количество объявлений до 150 млн! По мере развития продукта у нас начали появляться процессы инцидент-менеджмента. Сначала мы внедрили их для быстрой и качественной починки инцидентов, оценки влияния на бизнес и понимания скорости их роста. Но со временем одного процесса стало не хватать: он по природе своей- реактивный, и слабо способствует предотвращению нового. Он не отображал реальной ситуации и не помогал понять, хватает ли его усилий. Мы стали замерять, насколько инцидент-менеджмент качественный, какие общие тренды он имеет, хватает ли его. Решили вложится не только в реактивную, но и в проактивную починку.
Для этого мы определили собственные критерии надёжности сервиса, отвязанные от абсолютных чисел нагрузки и числа инцидентов.

Что входит в понятие надёжности сервиса: SLO, SLI и SLA
Каждая компания по-разному определяет критерии надёжности своих сервисов. Их описывают внутренние соглашения: SLO, SLI и SLA.
SLO (Service Layer Objective) — декларируемый уровень надёжности сервиса. Это желаемая цель, тот уровень качества, который хочет видеть наш клиент.
К примеру, мы хотим обеспечить:
время ответа не больше 100 мс на 95 %%;
количество ответов с кодом 500 не больше 0,2% от общего числа ответов сервера;
время обработки критического тикета не больше 20 минут.
Эти три метрики и будут нашим SLO.
SLI (Service Layer Indicator) — фактическое состояние метрик. Это то, как работает сервис в реальности.
Мы измеряем метрики и узнаём, что наши SLI:
время ответа — 730 мс;
0,01% ответов с кодом 500;
22 минуты на обработку критического тикета.
SLA (service layer agreement) — договорённости или контракты о том, что делать, если SLI отличаются от SLO в худшую сторону. То есть, если сервис работает не так, как мы обещали.
В контракте SLA можно прописать штрафные санкции. Это может быть возврат денег, дополнительные услуги, особый приоритет в будущем.

Когда разработчики говорят о надёжности сервиса, чаще всего они вспоминают AWS от Amazon. Как люди думаю - он обеспечивает 99,99% доступности и надёжности.
Надёжность можно определять по-разному. Сервер AWS считается недоступным только в случае, если за пять минут не дает никаких ответов на запросы, кроме 500 или 503. Эти коды ответов обозначают две ошибки: Internal Server Error и Service Unavailable. Все остальные ответы сервера не учитываются при расчёте надёжности.
То есть, представьте, что у вас в Amazon успешен только один запрос в 5 минут. Тогда, по их мнению, это 100%-я доступность! Можно сказать иначе: у вас могут быть до 21 минуты полной деградации, и неограниченное число частичных деградаций. И, что Амазон не нарушит свои условия о 99,95% доступности. Или в крайнем случае - 8640 успешных запросов (по 1му раз в 5 минут) и неограниченное число неуспешных.
А в документации AWS прописаны условия, по которым пользователь может вернуть 100% оплаты, ТОЛЬКО если сервис доступен меньше, чем 95% времени. Это 36 часов в месяц!

В классическом понимании SLA — это юридический документ с обязательствами. Ещё это удобный термин, который применим и внутри компании. Мы в Авито стремимся давать гарантии на внутренние компоненты. Они работают как договоренности между командами разработки.
Как определяем SLO в Авито
SLO каждого микросервиса Авито определяют нефункциональные требования (non-functional requirements, NFR). Это описание того, как должен работать микросервис, как быстро отвечать, какие ответы сервиса считаются ошибками в контексте надёжности системы. Все NFR хранятся в одном репозитории с микросервисом, в файле nfr.toml.
Пример простого описания NFR в файле:
[default.handlers]
error_codes = [503, 504]
[[handlers]]
name = "/wordCounter_GET"
type = "REST"
latency = "100ms"
error_codes = [500, 400]Кроме вышеперечисленного, можно описать:
MaxRPM,
Размер очереди,
Скорость прохождения или обработки события,
Freshness данных.
Все эти и другие аспекты мы описываем в nfr.toml как нефункциональные требования к системе.
Эти NFR - и есть требования к системе, SLO. Мы следим какой процент операций в сервисе удовлетворял NFR.
По метрикам из NFR мы визуализируем, какие проблемы есть в каждой операции микросервиса.

По графику понятно, как работают разные операции сервиса. Но чтобы понять, насколько работа приемлема, мы используем подходы с бюджетами ошибок.
Что такое бюджет ошибок
Бюджет ошибок — это число ошибок, которое можно допустить за определённый период: недельный, месячный, квартальный и другие. К примеру, мы задекларировали SLO (ожидаемую надёжность) микросервиса на уровне 99,9%. За последние 30 дней он получил один миллион запросов. Значит, 1000 ошибок — это бюджет на месяц.

Бюджет ошибок можно представить в виде пустого бассейна. Каждая ошибка — это капелька, которая его заполняет. Если за 30 дней у нас уже случилось 300 ошибок, то в запасе есть ещё 70% бюджета.
Зачем считать бюджет ошибок
Микросервис становится более предсказуемым. Его работа регламентирована в NFR и пользователи понимают, чего от него ожидать. Например, вы указываете, что микросервис ответит за 300 мс в 99,9% случаев. Если к нему подключатся другие микросервисы, то они будут ожидать ответ за это время. Тогда их разработчики смогут писать бизнес-логику с опорой на эти значения.
У разработчиков появляется простор для манёвров. Думаю, большинство инженеров любят экспериментировать. Круто, когда внутри команды есть возможность тестировать не только продуктовые идеи, но и технические. Например, попробовать новую технологию. Пока есть бюджет ошибок, разработчики могут экспериментировать в его рамках и не бояться, что надёжность сервиса критически упадёт.
Как считать бюджет ошибок
Когда мы NFR-надежность, мы независимо считаем нарушение каждого аспекта NFR (у нас отдельно существует как метрика нарушений NFR в целом, так и метрики нарушения КАЖДОГО аспекта - времени ответа, ошибки etc).
В примере NFR выше, мы учитываем ошибки 400, 500, 503, 504, и Latency 100 мс. В нашем случае в бюджет ошибок входят только ситуации, когда микросервис нарушает нефункциональные требования: отдаёт ответ с одним из этих кодов или отвечает слишком медленно.

В качестве периода берём 30 суток. За это время будет достаточно запросов, чтобы метрика получилась точной. Время можно сокращать до недели, суток, часа, но на коротком периоде вы получите больше шума. Случайные скачки метрики затруднят оценку, хотя фактически число ошибок останется внутри бюджета.
Вы можете поэкспериментировать и найти свой оптимальный период для оценки. Возможно он окажется короче.
Иногда есть смысл использовать несколько разных периодов. На коротких отрезках времени метрика будет достаточно реактивной для быстрой оценки в моменте, а на длинных — более точной.


Что делать, если вы истратили бюджет ошибок
Пересмотрите NFR. Возможно, они неправильно описаны, слишком жёсткие или требуют обновления. Например, в описание могли случайно добавить лишние коды ошибок.
Кроме того, требования часто формируются до ввода сервиса в прод и не учитывают нюансов его реализации. Допустим, сервис физически не может отвечать быстрее, чем за 500 мс, а мы заложили в NFR Latency = 100 мс. Это рабочий момент, который нужно просто уточнить и исправить.Введите временный мораторий на релизы. Чаще всего ошибки появляются, когда команда выкатывает новый релиз. Поэтому в некоторых компаниях есть правило: если бюджет закончился, больше ничего не выкатываем. Этот способ оправдывает себя, только если у микросервиса есть внешний пользователь или контрагент со своими SLA. Например, интеграция с банковским сервисом. Тогда несоблюдение бюджета ошибок может стоить очень дорого.
Запланируйте больше времени на работу с техническим долгом в следующем спринте.
Четыре подхода к подсчёту надёжности Авито
Первый — считать общий ErrorRate по всем сервисам Авито
Каждый отдельный микросервис влияет на общую надёжность всего приложения Авито. Но эффект от них может быть разным. Мы подумали, что можно определить надёжность для приложения по общему числу всех ошибок. То есть, посчитать все запросы на странице, затем все ошибки, поделить одно на другое. Очень многие компании на этом останавливаются и это единственная, основная метрика их надёжности.
Нам это не подошло, потому что трафик неравномерный: может быть сильно перегружено чтение, сильно недогружена запись. А запись для нас так же важна, как и чтение.
А еще огромный трафик приходится на картинки и статику. Если случится так, что для страницы прогрузились только картинки, мы можем не счесть это проблемой: слишком уж велика доля статики.
Или по метрикам всё надёжно работает, а оплатить покупку невозможно.
Получается, что если просто посчитать все ошибки на всех страницах, мы не получим представления о надёжности приложения. Этот подход не учитывает важность вклада для каждой отдельной страницы.
Второй — считать ошибки по отдельным, самым важным микросервисам
Мы попробовали разметить важность сервисов руками. Так можно сказать, что платежи или регистрация — это супер-важно, давайте замерять только их и общую частотность ошибок.
В платежах можно посчитать, сколько раз пользователь попытался оплатить покупку и сколько раз ему это удалось.
Но это только один этап в пути пользователя. Сбой на главной странице сайта не обязательно приведёт к ошибке платежа, но явно повлияет на их число. А для метрики останется невидимым.
Такие метрики еще могут быть очень эластичны - Например, у нас может полностью сломаться функциональность для покупателей, но продавцы какое-то времени будут продолжать пользоваться приложением и совершать оплаты.
Нет линейной зависимости от опыта пользователя. Она не учитывает косвенные потери от того, что покупатель в принципе не смог дойти до этапа покупки.
Просто цифр для таких подсчетов недостаточно, нужно системное решение. Поэтому мы обратились за помощью к аналитикам.
Третий — считать по воронке сценария, пути пользователя
Да-да, обычная классическая воронка =)
Идея простая - раз пользователи живут не в экранах и сервисах а в каких-то сценариях - давайте опишем такие сценарии и воронки. И после начнем следить за их технической надежностью.
Сначала мы попросили аналитиков построить воронку по пути пользователя. Для этого они определили последовательность действий от входа на главную страницу до целевого действия. Например, до контакта с продавцом по телефону.

Мы решили посчитать надёжность каждого этапа и рассчитать техническую надёжность пути.

Такой подход упускает три детали:
не весь трафик внутри воронки будет целевым;
не считаем конверсию между этапами;
если случится сбой на главной странице, то до поиска и целевого действия трафик вообще не дойдёт.
Мы попробовали посчитать такую воронку, и вот что получили:

Оказалось, что один заход на главную страницу порождает в среднем три перехода на поиск, и только после этого пользователь выбирает нужную ему карточку.
Иногда пользователь возвращается из карточки обратно на поиск. То есть, в воронке бывают переходы не только сверху вниз, но и в обратную сторону.
Значит, формула будет усложняться: нам нужно учитывать объём потерянного трафика на каждом из этапов вниз и вверх по воронке.
Мы попробовали усложнить формулу и учесть недополученное. То есть, если мы ошибёмся на поиске, то недополучим трафик на карточке и на кнопке с номером телефона (пользователь ведь ушел).
Для этого добавили в неё потерянные ошибки — lostError.

Позже оказалось, что форма воронки зависит еще от дня недели, времени суток и изменений в приложении:
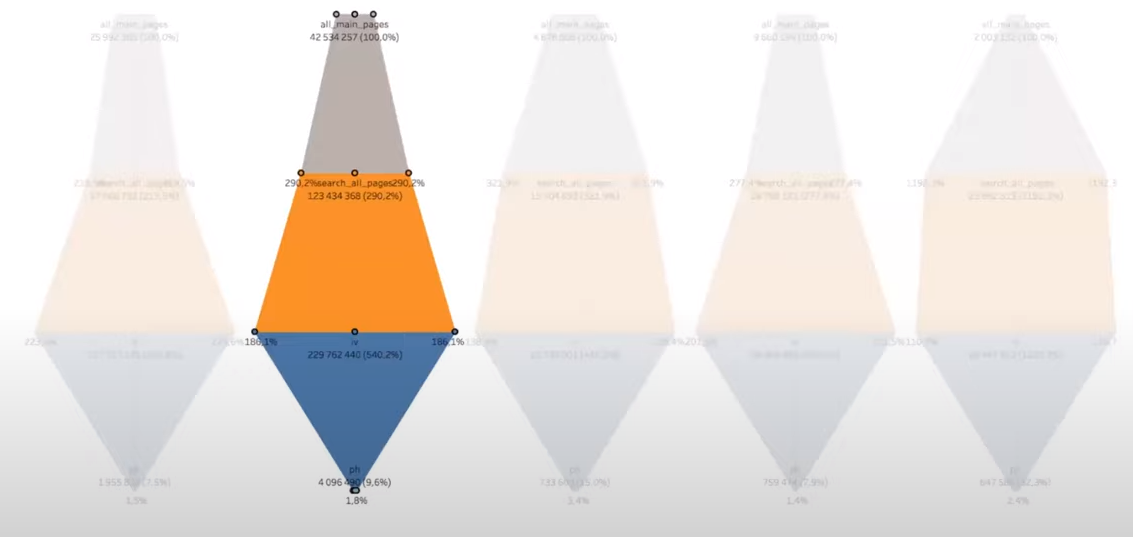
Из-за такой сложности и непредсказуемости воронки мы временно отложили это решение. Хотелось попробовать другие способы оценки, попроще.
Четвёртый — считать по точкам входа
Любой, даже незначительный сбой в работе Авито потенциально может привести к серьёзным репутационным рискам для компании и оттоку потенциальных клиентов. Ежедневно платформой пользуются миллионы людей. Простой даже в несколько минут может разлететься в соцсетях и СМИ, и продолжать «расходиться» после полного восстановления работоспособности.
Мы задумались, с какой вероятностью обычный пользователь не увидит ошибку, когда зайдёт на Авито? Точек входа при этом будет не очень много: переход из поиска (Google или Яндекс), закладки в браузере, запуск приложения. Есть и другие, но мы разберем самые нагруженные.
Чтобы посчитать вероятность, мы составили список всех точек входа, с которых пользователь может начать работу с Авито. Затем для каждой точки (страницы сайта) определили надёжность (SLI) и вклад в общую надёжность (weight, вес). Мы оценивали вес каждой точки, исходя из общего объёма трафика — 1 миллион переходов. Для каждой точки определили процент от общего числа переходов. Сумма всех весов равна 1. После этого умножили значения надёжности и веса по каждой точке и суммировали их. Так мы получили итоговую надёжность по точкам входа. В практическом смысле это и есть вероятность того, что пользователь не увидит ошибку, когда зайдёт на сайт.

, у нас остаётся 92% надёжности сайта")
Есть хорошая фраза, которая отражает реальное обывательское понимание надёжности: «Я не смог зайти на сайт».
Мы смогли подтвердить пользу этой метрики на практике. Построили в Grafana линейный и логарифмический графики, на которых видно, когда вероятность ошибки была в пределах 0,01%.


Иногда вероятность ошибки пробивала уровень 1%. То есть, случался достаточно крупный по нашим меркам сбой, который замечали пользователи. Журналисты публиковали заметки именно о таких ситуациях. Это значит, что метрика действительно отображает пользовательскую надёжность Авито.
Надёжность по точкам входа — прозрачная метрика для бизнеса. По ней легко понять, какие ошибки сильнее всего влияют на пользователей, а значит, и на финансовые показатели сайта.
Оценка по точкам входа хорошо работает как срез надёжности сайта, но показывает только один аспект — доступность для пользователей. То есть, метрика не идеальна. Кроме того, периодически появляются новые точки входа, может меняться их влияние и приходится пересчитывать веса.
Если вы хотите выпускать качественный продукт, я советую рассчитать надёжность, бюджет ошибок и поискать метрики, которые лучше всего будут отражать состояние вашего сервиса.
Мы проверили множество способов для того, чтобы научиться считать надёжность нашего приложения Авито в целом. Мы считаем надёжность каждого «кирпичика» — NFR каждого сервиса, общую надёжность по всем методам, надёжность по точкам входа. А сейчас внедряем надёжность по пользовательским сценариям, о ней расскажу в следующий раз.
Предыдущая статья: Пишем хорошие компоненты, которые захочется переиспользовать, а плохие — не пишем