
У вас бывало, что открываешь поиск, ищешь что-то по программированию и не находишь ответ? Тогда эта история для вас.
Меня зовут Алексей Степанов, я руковожу службой исследований машинного обучения поиска Яндекса. Сегодня я расскажу непростую историю. Она про проблему, до решения которой у нас слишком долго не доходили руки. Из поста вы узнаете, почему стандартная метрика качества поиска не учитывала интересы разработчиков и как мы её улучшили. Расскажу про новую нейросеть CS YATI, обученную понимать таких же айтишников, как и мы. Ну и про грабли на нашем пути тоже расскажу, куда без них.
Этот пост основан на моём докладе с Data Fest 2022, но не во всём (мой коллега Максим Хурсанов @Maxim2207 существенно расширил историю).
К нам в команду поиска регулярно прилетают жалобы от коллег на качество ранжирования по тем или иным запросам, специфичным для разработчиков. Например, выдача по запросу [C++ list find] ещё недавно выглядела вот так:

Однако у нас были продуктовые метрики, которые говорили: ребята, успокойтесь, у вас всё хорошо, вы как минимум не хуже коллег по индустрии. В результате у нас сложилось противоречие. С одной стороны, метрики говорили, что с качеством всё хорошо. А с другой, мы сами пользовались поиском в работе и сами регулярно были недовольны результатами. В один прекрасный день нам надоело это терпеть, и мы решили наконец-то разобраться.
Исправляем метрики
Метрики — это инструмент, с помощью которого мы ставим задачи и контролируем качество их исполнения. Невозможно что-то улучшить в такой сложной системе, как ранжирование, если у вас нет корректных метрик для измерения изменений. Поэтому наша история начинается именно с них.
Больше года назад мы собрались небольшой компанией разработчиков в переговорке, заказали пиццу, начали вводить в поиск реальные запросы пользователей по программированию и оценивать результаты, ориентируясь на свой опыт и знания в предметной области.

Итак, нам нужно было выяснить, какая из поисковых систем лучше отвечает на специфичные запросы про разработку. Что значит «лучше отвечает»? Предположили, что это означает более полезный документ (так мы называем страницы в интернете) в топ-1 результатов выдачи. Мы взяли около 30 программистских запросов и документы в топ-1 Яндекса и Google. Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.
Мы решили отмасштабировать встречу в переговорке с пиццей на всю компанию: писали посты в этушку (это такие внутренние блоги), выступили с призывом на хурале (еженедельной встрече всех сотрудников). Придумали процесс, в котором участники не только выбирали лучший ответ, но ещё и обсуждали свой выбор с другими разработчиками, если их мнения разошлись. Более того, взяли за привычку каждую пятницу созваниваться с разработчиками из других компаний. Так нам удалось за несколько недель собрать уже не 30, а 1500 попарных оценок! К сожалению, выводы остались теми же: мы отвечаем существенно хуже, чем говорят нам метрики. Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.
С оценкой качества поиска нам помогают асессоры. Это специалисты, которые умеют отвечать на сложные смысловые вопросы и делают это лучше, чем любой ML-алгоритм. В том числе они оценивают, насколько веб-документ полезен по запросу. И наш процесс разметки не гарантировал, что на вопрос, связанный с программированием, будет отвечать асессор с опытом в программировании. Главная причина в том, что мы таких асессоров-программистов просто не наняли в достаточном количестве.
Представьте, что вас просят оценить пользу от документа на китайском языке. Как вы будете это делать, не зная язык? Правильно, искать иероглифы из запроса в тексте документа. В ряде случаев это нормальная стратегия, но далеко не всегда. К примеру, просим неспециалиста, который никогда не программировал, оценить ответ по запросу [C++ find_if]. Он видит, что в документе вполне себе есть и C++, и find, и даже if. Этот документ будет отмечен как хороший.

На самом деле среди асессоров мог найтись тот, кто разбирается в программировании. Вот только каждое задание проходит через нескольких асессоров. Если вердикт асессора с опытом не совпадал с ответами других для этого же задания, то оценка просто усреднялась и качество разметки падало.
Как решить эту проблему? Нанять больше людей с опытом в программировании размечать запросы. Так мы и поступили. Непросто найти специалистов, которые смогут разобраться в специфических запросах и прочитать код на веб-страницах. Для этого мы проверили более тысячи кандидатов и наняли сотню лучших. Но оно того стоило: оценки новых асессоров не только были согласованы друг с другом, но и коррелировали с оценками яндексоидов! Метрика, построенная на новых оценках, на порядок лучше подсвечивала проблемы ранжирования. А это значило, что мы наконец-то починили «компас» и теперь знали, куда двигаться. Дальше наш взор устремился на модель, которая и отвечает за ранжирование документов.
Улучшаем ранжирование
Задача поиска в интернете довольно сложная. У нас есть сотни миллиардов документов. Нам надо найти среди них десять наиболее релевантных всего за сотню миллисекунд. Поэтому большинство документов отсеиваются простыми, но зато очень быстрыми алгоритмами. А вот дальше начинается самое интересное.
Финальное решение о релевантности каждого документа принимает модель на базе нашей опенсорсной технологии градиентного бустинга CatBoost. На вход модели подаются разные факторы о запросе и документе, на выходе получаем предсказание релевантности документов. Факторов исторически очень много. Но с 2020 года можно однозначно выделить самый главный — тот, что выдаёт текстовая нейросеть YATI. Это огромная сеть с архитектурой Transformer, для работы которой требуются наши суперкомпьютеры. Мой коллега Саша Готманов уже подробно рассказывал о ней на Хабре. Самое главное, что тут надо знать: технология YATI стала самым большим прорывом в истории поиска с момента внедрения Матрикснета в 2009-м. Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.

Итак, у нас есть модели YATI и CatBoost — два ключевых компонента, от которых зависит качество поиска. Давайте улучшим их для нашей задачи!
Мы решили обучить отдельный трансформер на базе YATI, который будет в первую очередь хорошо решать задачи по программированию. Недолго думая, назвали его CS YATI (Computer Science). Почему отдельный, а не в рамках универсального YATI? Запросов, связанных с программированием, в общем потоке очень мало. Поэтому мы можем позволить себе применять более мощную модель с бóльшим числом параметров. Кроме того, мы можем итеративно обновлять и обучать её без риска что-то поломать в основной модели.
Начали с того, что скормили трансформеру огромное число текстов, связанных с программированием. Так наша новая модель выучила все специализированные словечки и лексику из области компьютерных наук.
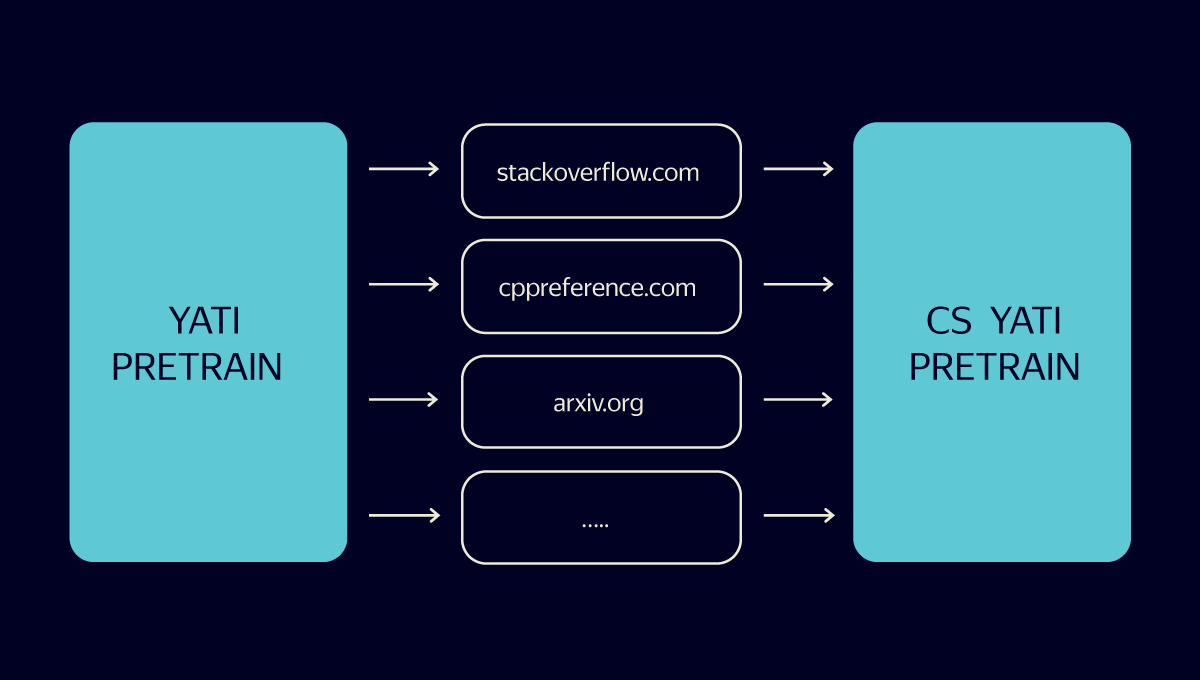
Дальше мы собрали поисковые логи программистских запросов и документов, на которые пользователи кликали по этим запросам. И обучили CS YATI именно на них. Правда, не без хитростей.
У нас была проблема: размер документов по программированию часто довольно большой. Это значит, что наша большая модель может отрабатывать на них непростительно долго. Но при этом резать тексты и терять информацию очень не хотелось. Хотелось, наоборот, выжать из неё как можно больше качества при сохранении производительности.
Мы поисследовали различные способы оптимизации модели и пришли к следующему трюку. Вместо того чтобы сокращать число слоёв нейросети, мы стали итеративно уменьшать длину входа каждого слоя. Само по себе это ухудшает качество. Но вся соль в том, что при этом и потребление ресурсов падает, а значит, мы можем подавать больше информации на вход. В результате тонкая оптимизация позволила не только не просадить качество, но и повысить его за счёт увеличения входной информации в полтора раза.
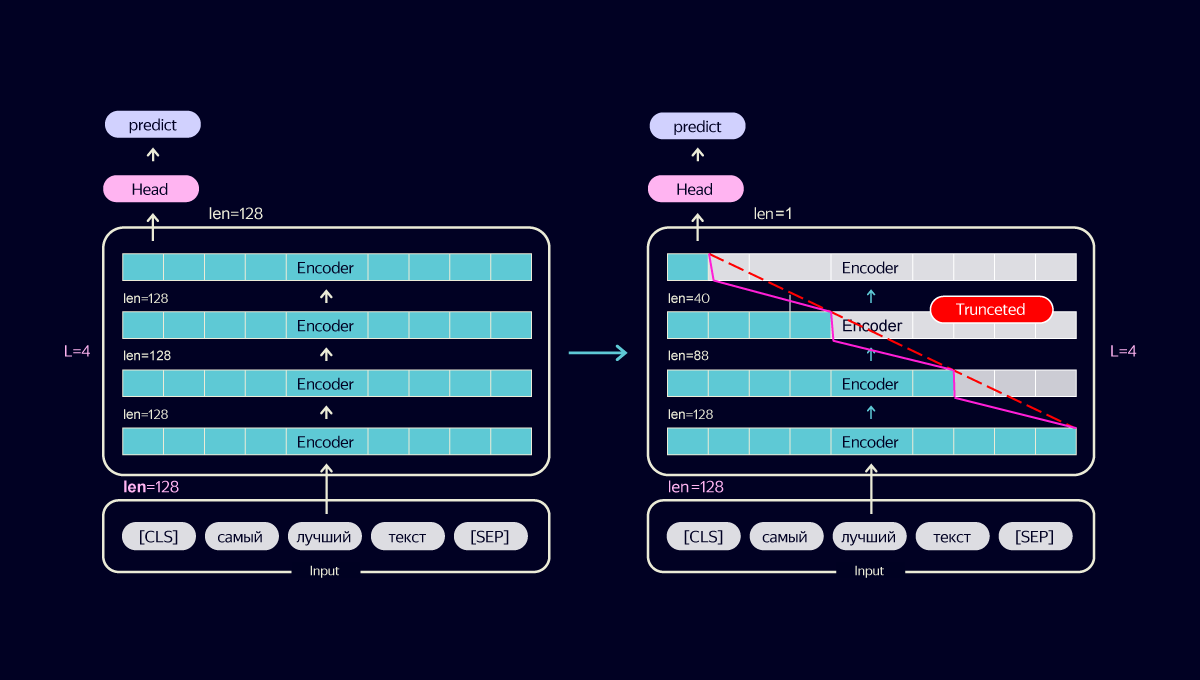
Однако некоторые документы по программированию все равно имеют слишком большой объём. Можно было бы просто брать начало текста, но это слишком грубый способ, снижающий качество. Мы начали выбирать из документов N наиболее релевантных предложений по данному запросу и уже их передавали в трансформер. Причём мера релевантности тоже оптимизировалась под программистские тексты. Финально мы зафайнтюнили CS YATI, ориентируясь на оценки асессоров с опытом в программировании.
Итак, мы создали нейросетевую модель CS YATI, которая может похвастаться пониманием языка программистов и умеет угадывать их выбор в поиске. Осталось придумать, как это всё внедрить в текущий процесс, применить на каждом запросе и не лечь под нагрузкой. Взгляните на схему:
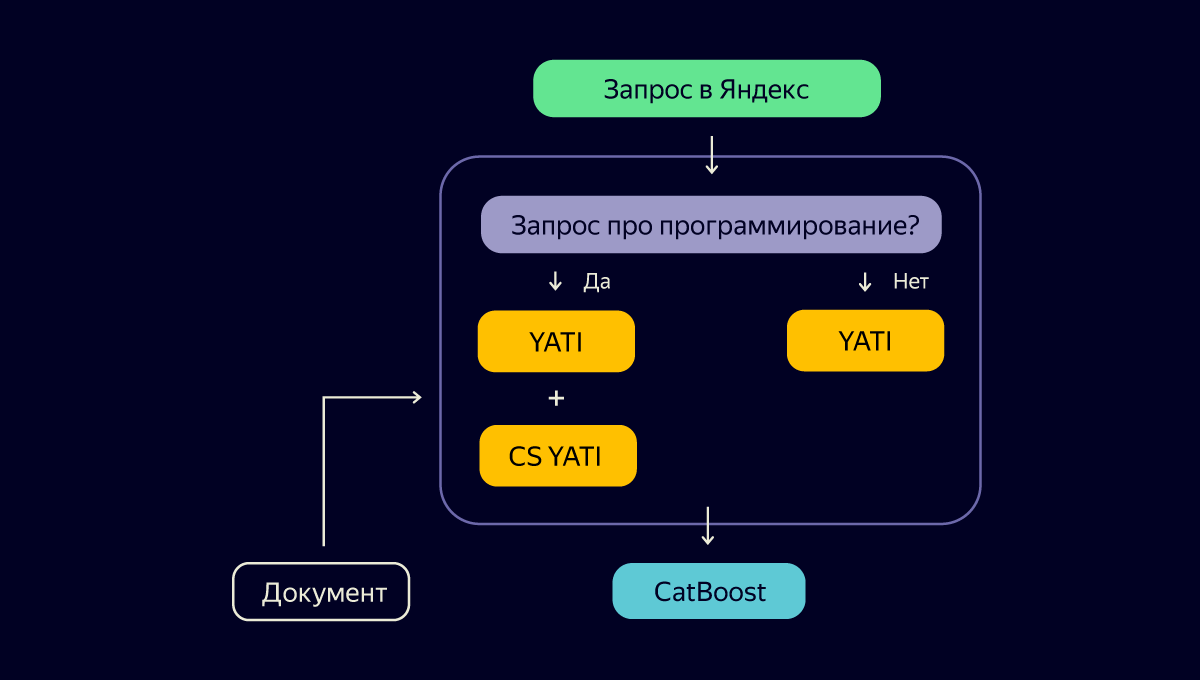
Выглядит логично. Применяем дополнительную нагрузку в виде CS YATI не всегда, а только для узкого среза программистских запросов. Но есть нюанс: кто будет классифицировать каждый запрос перед развилкой?
Решили, что и тут без CS YATI не обойтись. Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.
Мы воспользовались уже хорошо зарекомендовавшим себя способом — дистилляцией. Специалисты сразу поймут, о чём я, но для всех остальных скажу: дистилляция — это обучение более лёгкой нейросети «подражать» поведению более тяжёлой. Мы взяли лёгкую DSSM-подобную сеть и обучили её на результатах работы нашего трансформера CS YATI. Понятно, что качество классификации немного просело, но при этом мы сэкономили огромные вычислительные ресурсы и смогли внедрить модель в продакшен.
Схема стала выглядеть так:

Внимательный читатель в этот момент может спросить: если у нас появилась специальная версия YATI, то, может быть, нужна и специальная версия CatBoost, которая будет учитывать специфику? Мы тоже сначала посчитали это хорошей идеей. Но давайте обо всём по порядку.
Мы сделали отдельный CS CatBoost, который, подобно CS YATI, будет обучен ранжировать запросы и документы по программированию. А ещё он будет независим от основного компонента CatBoost — значит, мы сможем обновлять и экспериментировать с ним без оглядки на остальную часть поиска. Для его обучения мы использовали уже собранные нами оценки асессоров-программистов. Звучит хорошо, не правда ли?
Но у такого решения были и минусы. Однажды мы на этом попались. В апреле наши коллеги выпустили в опенсорс технологию YDB и очень громко пошумели об этом (в том числе на Хабре). Настолько, что пользователи пошли в поиск и стали вводить там запрос [YDB]. Наша быстрая нейросетка IS CS QUERY DSSM корректно определяла его как программистский. Дальше правильно отрабатывал трансформер CS YATI. А вот CS-версия CatBoost не показывала ни одной новости о событии.
Чтобы осознать суть беды, нужно добавить немного контекста. В поиске есть особые запросы, которые мы называем «свежими». Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными.
Мы проверили, что основная версия CatBoost, которая специально обучается на свежих запросах, хорошо справлялась с запросом [YDB]. А в обучении CS CatBoost свежих запросов не было, это и приводило к проблеме. Решение с отдельной версией CatBoost для CS, которое вначале нам показалось простым, привело к тому, что мы сломали ранжирование свежих программистских запросов. Усложнять ими обучение CS CatBoost мы не хотели, и решили, что самый простой способ — объединить две модели в одну. Сейчас это так и работает в проде.
Окей, у нас есть новые метрики, новый CS YATI, обновлённый CatBoost. Что ещё можно было сделать для улучшения качества ранжирования? Например, убедиться, что в данных для обучения моделей ранжирования есть всё, что нужно.
В последнее время я часто читаю новые посты по машинному обучению в телеграме. Часть постов мне потом хотелось перечитать, я шёл в поиск и… не находил их. На самом деле это логично, потому что посты из веб-версии мессенджера плохо оптимизированы для поисковых систем. Начали думать, что же мы можем сделать на своей стороне, чтобы помочь похожим на нас пользователям.
Мы собрались с командой и посмотрели, как асессоры оценивают посты в телеграме. Обнаружили, что в обучающей выборке таких постов почти не было. Мы решили это исправить: намайнили и разметили асессорами-программистами больше документов из телеграма.
Дообучение сработало. Наш поиск научился находить полезные посты в телеграме. Не просто каналы, а конкретные посты из каналов!
Итак, мы починили метрики, улучшили ранжирование и долили новые данные. Но на этом мы не остановились.
Добавляем быстрые ответы и сниппеты
Цель поиска — не просто ранжировать ссылки, а помогать людям быстро решать свои задачи. Поэтому, помимо работы над ранжированием, мы развиваем и другие форматы. Например, совершенствуем быстрые ответы. Это такие специальные блоки, в которых поиск сразу приводит краткий ответ на запрос. По нашим подсчётам, они экономят пользователям десятки тысяч часов в сутки.
Мы улучшили в поиске быстрые ответы для сайтов, популярных среди разработчиков. Например, теперь там можно встретить ответы на вопросы со Stack Overflow. Поначалу это был просто наиболее рейтинговый ответ с платформы, который выводился в блоке справа. Отзывы коллег помогли усовершенствовать его: появился выбор из нескольких ответов, число оценок, комментариев и даже сам вопрос.

Расширенным стал не только быстрый ответ, но и сниппет в результатах поиска.

Ещё один интересный пример: мы доработали сниппет Гитхаба. Теперь прямо в выдаче можно увидеть рейтинг проекта, число форков и даже дату последнего коммита. Это поможет быстрее сделать правильный выбор.

А вот, например, новый сниппет, который помогает быстро найти команду для установки пакетов из npm, brew, pip, Pub и nuget — или сразу получить основную информацию о пакете.
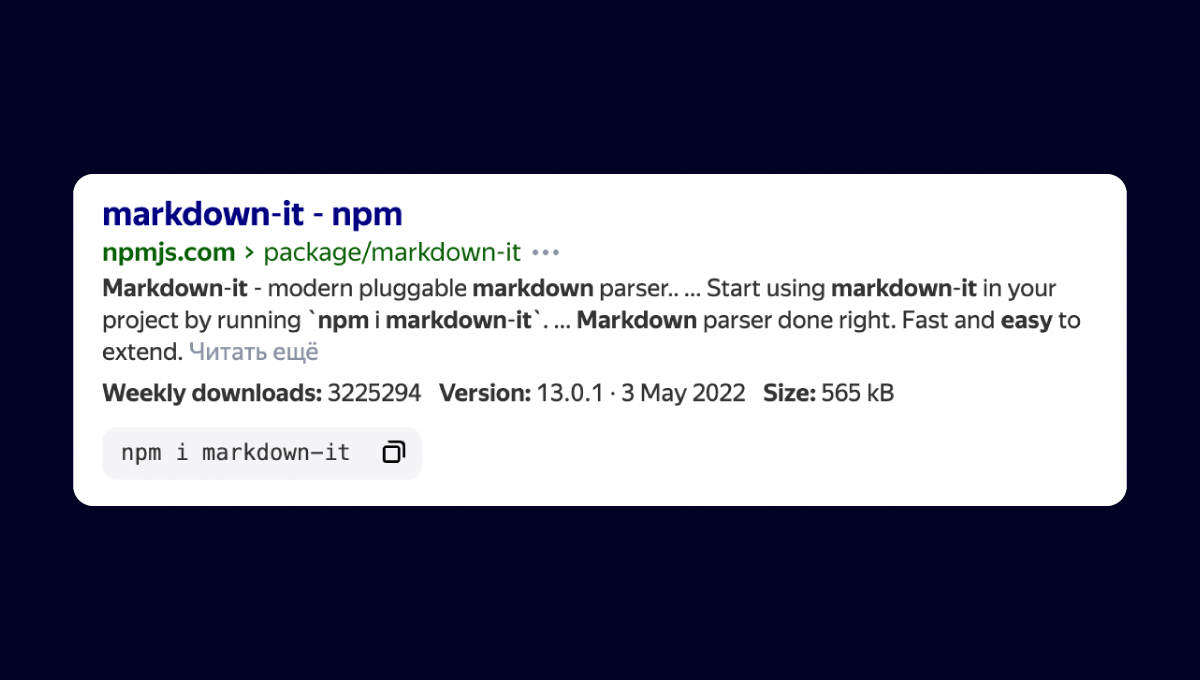
Мы продолжим развивать быстрые ответы, а также добавлять сниппеты и для других сайтов тоже.
Выученные уроки
Если метрика говорит, что мы у пользователей самые лучшие, то стоит проверить эту метрику.
На скорую руку можно только прод поломать (ну или свежие CS-запросы).
Если сделали новую метрику и по ней выиграли, то это не значит, что продукт некуда улучшать. Реальную обратную связь можно получить только от пользователей. Попробуйте наш поиск для запросов по программированию и присылайте фидбэк. Теперь поделиться отзывом просто: внизу выдачи появился пункт «Сообщить об ошибке». Вместе мы можем упростить жизнь огромному числу разработчиков. Спасибо!

Комментарии (56)

areaofdefect
20.09.2022 10:48+11Воочию застал улучшение поиска для разработчиков!
Еще полгода назад действительно плохо получалось яндексить функции из разных ЯП. Потом наконец-то появились вырезки из стековерфлоу, но код копировался в 'одну строку'. А теперь вcё идеально. Спасибо!

terraplane
20.09.2022 11:00+19У вас бывало, что открываешь поиск, ищешь что-то по программированию и не находишь ответ?
Да. Тогда я закрывал Яндекс и открывал Гугл. И всё находилось.
Savevur
20.09.2022 11:59-8Яндекс я в основном использовал для поиска во времена Dial-Up. Теперь только для тестов.


Zy2ba
20.09.2022 15:51+11Зачем закрывать яндекс и открывать гугл, если у яндекса внизу страницы есть удобные ссылки на то чтоб поискать тот же запрос в других сервисах?
Я обычно начинаю поиск с яндекса только из-за этого. Потому что гугл тоже не всегда ищет то, что может найти яндекс, а с гугла обратно так удобно не перейти.
terraplane
21.09.2022 08:34+2Потому что я пользуюсь аглоязычным google.com, а ссылки Яндекса на google.ru -- как следствие, с другим результатом выдачи.


OlegZH
20.09.2022 11:19+7Технические подробности любопытны, но "перепредумать" поиск такими частичными полу-решениями не удастся.
Здесь следует начать с самого начала. С постановки задачи. С того, что нужно пользователю. А пользователю нужен не список ссылок на сайты, а ответ на вопрос. Во времена текстового интернета всё было гораздо проще. Простой полнотекстовый расширенный поиск практически всегда давал то, что нужно. К сожалению, часто приходилось пролистывать несколько страниц поисковой выдачи, зато вероятность "пропуска цели" была чрезвычайно мала. Сегодня очень не хватает статичной среды, чего-то типа архива, где и имело бы использовать поиск. А искать что-то в динамически меняющемся пространстве гиблое дело. Для каких-то очевидных вещей "быстрые ответы" ещё помогут, а для чего-то более глубокого и хорошо структурированного требуются более изощрённые инструменты.
Во-первых, пользователю желательно представить динамически разворачивающуюся форму опроса, позволяющую максимально уточнить цель запроса, и возможность фильтровать уже полученные результаты.
Во-вторых, результат поисковой выдачи должен быть структурированным. Вы должны выводить на экран самую суть, а не ссылки на ресурсы. Ссылки нужны только для того, чтобы прочитать оригинал (при необходимости). Идеальная выдача — это что-то вроде статьи в Википедии, когда можно, "не отходя от кассы", прочитать всё, что нужно, об интересующем тебя предмете. И всё это должно опираться на модель предметной области. Нейронные сети, как я вижу, направлены на решение этой задачи, но пользователю нужна именно структура. Смысл поискового механизма заключается в том, чтобы найти точное место в этой структуре. Для этого нужно не нагружать ассессоров оценкой документов, а строить предположения о том, что такое точный (или приблизительно точный) ответ на запрос (исходя из заданной предметной области). Взять бы тот же запрос:
C++ list findРазвёрнутый ответ на этот запрос — это статья о том, что существуют списки, в этих списках можно осуществлять поиск, и что имеются реализации, в том числе, и в языке программирования C++ (включающие библиотеку шаблонов и алгоритмов). То есть — большой сниппет.
В-третьих, .... Если бы интернет изначально был сетевой распределённой семантической базой знаний, то не нужно было бы выдумывать какой-то особый поиск, всё было бы встроено в систему.

SADKO
20.09.2022 17:48Ох, что-то подобное было реализовано в замечательном поисковике Quintura...
...и googlы что-то подобное пилили, но оно так же кануло в лету, а жальhbn3
20.09.2022 18:10+1У гугла был code search, но забили на это в конце концов. Может Яндекс подхватит упавшее знамя, сейчас может получиться сильно интереснее по сравнению с 2006.

alexeibs
20.09.2022 23:24+3Во-первых, во-вторых, в-третьих... - вы описали поиск, который нужен лично вам. Почему вы считаете, что всем остальным это тоже нужно?
OlegZH
21.09.2022 12:47+1Я немного идеализирую. Но, вообще-то, я исхожу из существа задачи. То как это должно быть в целом. Почему же Вы решили, что это нужно только мне? Что Вы знаете о реальных потребностях пользователей? Вы ориентируетесь на типовые запросы, то есть — на наиболее распространённые модели поведения. Но это не значит, что, будь у пользователей соответствующий инструментарий, они не стали бы делать более сложные запросы. Ваша постановка задачи сужает поле деятельности до угадывания смысла вводимой строки. Вот пользователи и пользуются для "относительно простых" запросов. Ну да. Угадать можно. Улучшить можно. А узнать, что действительно нужно пользователю нельзя. Для этого придётся перепредумать весь поиск. С нуля.

sparhawk
20.09.2022 11:50+3Выглядит работоспособно.
Отдельный плюс: можно искать на русском — в выдаче нет «весеннего отдыха» Spring REST — мусорных автоматических переводов документации и stackoverflow (russianblogs.com и пр.). Правда, кажется блоги на русском занижаются в выдаче по сравнению с Гуглом, тот же Хабр.
Savevur
20.09.2022 11:54+2У вас бывало, что открываешь поиск, ищешь что-то по программированию и не находишь ответ?
После того как месяц назад вы отключили параметр numdoc теперь вообще кроме рекламы ничего не найдешь.
https://webmaster.yandex.ru/blog/izmenenie-v-rabote-parametra-numdoc

Kelbon
20.09.2022 12:03+11Есть одна небольшая проблема.
Это вы разработчики и увидели (т.к. обладаете знаниями в этой области), что поиск стал плохим(или был плохим) по этой области.
Но на самом деле с каждым годом поиск по ВСЕМ темам становится всё хуже и хуже. Исключение тут разве что коты и тиктоки. Поиск всё больше ориентируется на самого среднего потребителя без запросов сложнее запросов "красивый кот" и "порно".
Общий поиск для всех просто устарел. Нужны разные поисковые алгоритмы/нейросети для разных тематик и потенциально разных людей. То есть сеть обученная на том что нужно конкретному человеку.OlegZH
20.09.2022 12:45Проблема любого обучения в том, что алгоритмы обучаются на плохих данных. Всякая выборка, которая используется в промышленных реализациях, заведомо нерепрезентативна. Классическая ошибка: повышаем точность при уменьшающейся полноте. Многие просто перестали пользоваться поиском, и поиск остался на откуп относительно простым запросам. Но как только мы задаёмся вопросом о том, а что действительно хотели найти пользователи (и в каком виде), и что они могли бы найти, если бы поиск был и вправду продвинутым, то картина перестаёт быть такой впечатляющей.

alejes Автор
20.09.2022 12:48+8Спасибо за комментарий! Мы смотрим в сторону специализированных тематик. У нас уже есть эксперты по узким срезам (например медицине, финансам, играм), через какое-то время мы также расскажем что сделали в этом направлении.
OlegZH
20.09.2022 12:56-1А Вы не пробовали использовать обучение с подкреплением? Ваша первейшая задача — это индексирование страниц. Их нужно разбить на смысловые и структурные фрагменты, классифицировать и получить структурированное семантическое описание каждой страницы. Идентифицировать каждый объект на странице. Эдакий многоэтапный препроцессинг. Затем, Вы всё это "скармливаете" пользователю, но уже в категоризованном виде. А уже пользователь сообщает Вам, что объекты, попавшие в определённые категории, совсем не есть те "дроиды", который он ищет. (Специалисты потребуются только для того, чтобы выстроить некий скелет, чтобы предотвратить намеренное искажение обучения с подкреплением.)


frenzis
20.09.2022 12:43+2Яндекс, торт. Вот бы аналог Copilot, а то OpenAI вообще не Open ни разу и под каблуком санкций США, а GitHub совсем зажрался, аж 10$ в месяц за продукт, который они сделали поверх бесплатного лицензионного кода.

MyWave
20.09.2022 13:00+20Это так и должно работать? В гугле я читаю первую строчку и мне жирным шрифтом выделяют правильный ответ. В яндексе я ничего не читаю, потому что жизнь слишком коротка чтобы пытаться что-то найти в этом фонтане любви, извергающегося из вашего UX дизайнера.



OlegZH
20.09.2022 13:39+2Задача поиска в интернете довольно сложная. У нас есть сотни миллиардов документов. Нам надо найти среди них десять наиболее релевантных всего за сотню миллисекунд. Поэтому большинство документов отсеиваются простыми, но зато очень быстрыми алгоритмами.
Интересно, а что значит надпись "Нашлось 499 тыс. результатов " при попытке ввести в Яндексе "YATI"? Что находится в этом полумиллионе? А если попытаться катеогоризовать? Да и ещё кластернуть каждую категорию? А потом выложить всё это пользователю в таком же ухоженном структурированном виде...

thevlad
20.09.2022 15:42+1Это уже было, к примеру такой малоизвестный поисковик Nigma. Пользователю не нужны кластеры, он готов максимум прочитать топ 10 результатов.


WASD1
20.09.2022 14:40+2К стати да для "покупок в интернете" пользовался яндексом, для гугления программерских вопросов - гуглом, что немного напрягало.
Если вы утверждаете что качество гугления по программерским вопросам улучшилось - попробую яндекс для всего.
Artima
21.09.2022 19:59Гугл давно отлично справляется с поиском покупок, вроде. Правда, это в Москве. В регионах ситуация хуже, вроде.

saege5b
20.09.2022 15:47+1Т.е. закостылили одну тему.
А поиск вообще делать будете, или метрики вас устраивают?
hbn3
20.09.2022 17:11В добавок к копированию сниппета — для языков которые это позволяют, добавьте кнопку запуска этого сниппета в онлайн плейграунде.
Ну и как выше MyWave сказал, креативность у дизайнера подрежьте — шрифты другие попробуйте. Буйство жира на странице уменьшите. Ну и цвета уберите или приглушите.
Сейчас по сравнению с гуглом как дискотека с цветомузыкой смотрится. Или добавьте пару-тройку предопределённых альтернативных тем, если изменение главного дизайна сложно протащить.
DirectoriX
20.09.2022 19:09В добавок к копированию сниппета — для языков которые это позволяют, добавьте кнопку запуска этого сниппета в онлайн плейграунде.
Чаще всего сниппеты из ответов не являются полноценно рабочими программами, их нужно будет дописывать/модифицировать перед запуском. Не думаю, что ссылка на плейграунд с нерабочим кодом хоть кого-то обрадует…hbn3
20.09.2022 20:47Зачастую, особенно те что написанны в последние пару лет, там уже есть ссылка на запуск. Так что вполне можно будет интегрировать запуск и рабочих примеров.
Ну и запустить с нерабочим кодом, чтобы можно было побыстренькому набросать пример и проверить гипотезу легче, чем самим пытаться вспомнить как завести весь этот плейграунд.
Плюс, по идее им это ничего не стоит, но можно будет посмотреть на статистику и если люди начнут пользоваться, то можно развивать и более продвинутые варианты.
WASD1
20.09.2022 21:27буйство жира на странице уменьшите
Так вроде официальная страница поисковика яндекса - ya.ru (уже больше недели как) вполне прилично смотрится в этом плане
hbn3
20.09.2022 21:34Сверху есть пример — у меня точно также выглядит. Глаза в кучу и бегают туда-сюда, не могут выхватить суть.
WASD1
20.09.2022 21:45не вижу объективных причин считать интерфейс гугла лучше на примере выше (в общем то же самое - список ответов + лучший ответ отдельно).
Для use-case "за широким монитором" яндексовский вариант даже лучше - т.к. использует всю площадь монитора (правую часть под лучший ответ).hbn3
20.09.2022 21:56Не поленился посчитал, на примерах выше — у гугла две области выделены жирным шрифтом, у яндекса за тридцать. Из них пять с жирным в заголовках (т.е. самым большим размером шрифта).
Может я конечно не понимаю чего-то, но мне кажется это перебор. Ну хотя бы шрифт подобрали бы с несколькими градациями толщины написания.
Но тут же жира прям не пожалели. От души навалили.
Зачем имена сайтов сделали жирными? Если уж так важно, ну сделайте разными оттенками цвета (лучше серого, зачем отвлекать внимание зелёным? разве ссылка это настолько важная информация которую надо в первую очередь пользователю в глаза сувать?). Плюс иконок слева насыпали — тоже отвлечение внимания, дизайнер наверное рад — удачная находка.
Лого бы подтушили, а то как бельмо в глазу. Ссылку «поиск» тоже бы как то по другому выделить, в чём волшебный смысл так сильно выделять. Ярко жёлтую каёмку и кнопку тоже как то потише бы сделать, они на странице во весь голос кричат, а зачем.
Сделали бы темы — «минимальная», «нормальная» и «дизайнерский изыск», по идее совсем немного лишнего CSS добавить для поддержки, чтобы весь этот «изыск» пофиксить.WASD1
20.09.2022 22:19Постойте яндекс оптимизирует вёрстку страницы под широкий монитор вы называете "объективными недостатками".
По-моему это как минимум "вкусовщина", а как максимум - у яндекса для программиста вёрстка лучше.Не поленился посчитал, на примерах выше — у гугла два области выделены жирным шрифтом, у яндекса за тридцать. Из них пять с жирным в заголовках (т.е. самым большим размером шрифта).
Залёш ввёл те же запросы и оценил, смотрим:
1. Яндекс выделил жирным входление слов исходной фразы в заголовок (а гугл нет)
2. Яндекс выделил жирным вхождение ссылок со StackOverflow (а гугл нет)
3. Яндекс оптимизировал выдачу под широкие мониторы, в итоге контента влезло больше - а гугл нет
4. Гугл использовал вертикальное разреживание - яндекс в тех же местах использует более "широкий" шрифт (это на самом деле 3.1 - оптимизация под широкий монитор чтобы влезло больше строк)hbn3
20.09.2022 22:51+1В результате страница яндекса выглядит как новогодняя ёлочка, очень весело, но продраться через это веселье стоит усилий.
Предположение что программисты яндекса сами своим поиском не пользуются объяснило бы подобный подход. Ну или может просто все поставили расширение браузера чтобы результаты поиска под себя оптимизировать и не видеть потуг дизайнеров.
Интересно было бы узнать у тех кто в Яндексе работал, как у них с этим дела обстоят.WASD1
20.09.2022 22:55+1
Именно поэтому я и хотел уточнить объективные претензии. Как по мне их нет, а есть привычка к дизайну гугла.
Мне (я яндексю %20 от гугленья) дизайн яндекса больше нравится - он более информативен (одно выделение слов запроса в заголовке чего стоит), но вам, вероятно по привычке, он нравится меньше.

Nashev
20.09.2022 18:15+3Меня в результатах поиска больше всего бесят рекламные пиратские зеркала stackoverflow, как переводные так и на английском. Их тонны, и они замусоривают выдачу ужасно.
Верните кнопку типа "пожаловаться на сайт и убрать его из моей из выдачи навсегда", помню когда-то была такая!alejes Автор
20.09.2022 23:01+6Нас тоже эта проблема бесит! По нашей оценке, за последние несколько месяцев число пиратских зеркал stackoverflow в выдаче уже уменьшилось на 61.8%, и мы продолжаем работать над дальнейшим уменьшением их присутствия в выдаче.
Также, около каждого элемента на выдаче есть три точки, нажав на которые можно сообщить об ошибке, написав почему данный результат плохой.
Nashev
21.09.2022 09:24Три точки с тем пунктом пропадали и вернулись? Или почему я мог их не находить?

KasperGreen
20.09.2022 18:50+1Где вы были 15 лет назад, когда я учился программировать и перешёл на google с их гигабайтной почтой (на яндексе давно закончилось место и каждый день начинался с чистки) и релевантными результатами?
Я любил тебя яндекс. Очень. Но со смертью человека, под столом которого стоял весь яндекс, умерла и часть яндекса которую я любил. R.I.P..
Спасибо тебе за всё. Но теперь уже поздно.

DistortNeo
20.09.2022 20:06+3Хорошая попытка, Яндекс, но нет.
Вот запросы из моей истории:
-
memory mapped files c# get raw pointer
Google: первая же ссылка даёт ответ, Yandex: куча документации вообще не по делу.
-
python partially read tiff image
Google: всё по делу, Yandex: опять не уловил сути запроса (partially).
-
elementtree write to file
Тут оба молодцы
-
linux disable conda activate on bash
Тоже всё хорошо
-
c++ realtime clock
Google: документация по std::chrono::system_clock (то, что я ожидал), Yandex: какая-то проктология.
-
c# lambdaexpression invoke
Google: первая ссылка по делу, Yandex: опять не понял сути запроса.
-






diakin
20.09.2022 22:09Нужно чтобы пользователи имели возможность в поисковой выдаче у себя в браузере ставить плюсики и минусики. И все левые сайты в выдаче у себя в пределе блокировали или понижали. По крайней мере для личного пользования. А дальнейшем возможно получится какую-то информацию из этого извлечь для глобального использования.
alejes Автор
20.09.2022 22:54Привет! Такое должно происходить благодаря персонализации в поиске. Часто посещаемые пользователем ресурсы повышаются в выдаче персонально для него.

iipolovinkin
22.09.2022 05:02В яндекс-картах при поиске обращаю внимание на рейтинг заведения(например, кафе), который не персонализированный, а некий групповой. Разве не логично, если запросы и пользователи часто спрашивают по одной и той же тематике, то отнести их к этой группе и воспринимать рекомендации от таких пользователей как компетентный? Возможно, это поможет снизить затраты на асессоров по этой теме.
Afigan
20.09.2022 22:21главный вопрос, зачем вообще что то гуглить в яндексе про программирование. я уверен, что даже в самом яндексе большинство разработчиков тех. вопросы ищут в гугле.
alexeibs
20.09.2022 23:33+2Ну не зря в прошлом году выдачу размечали. Рад, что довели это до конца :)

Kirikekeks
21.09.2022 00:36+1Если эта статья про то, заметил ли я нерелевантность выдачи гугля? Да заметил, уже с месяц. Янедекс менее релевантен, чем 10 лет назад, когда можно было +-& "" site: и фильтрацию в найденном. Так что пока вы проигрываете себе в молодости. Это нормально, но для человека. Люди стареют. Не возникала мысль что для кодеров вполне естественно в поиске использовать код? Регулярки? Они стандартизированы и ERE вообще естественны для разработчиков? Что диапазоны дат и чисел кратно улучшают поиск? Сделали для кухарок, а теперь опаньки. К слову, я очень рад, что эта статья появилась. Спасибо. Очень поздно, но сегодня лучше чем никогда. Правда и выбора уже нет, и так схаваем, а тут такой каминг аут.
hbn3
21.09.2022 00:43-1Регулярки?
Не реально. Преставьте затраты на ресурсы CPU на их объёмах.
Сейчас наверное более-менее адекватный вариант для улучшения поиска для специфичных областей, это созадние отдельных индексов по доменам знаний (через whitelists сайтов?) и затачиваться только на них, отрезая остальной шум.
Ksyushik
22.09.2022 05:02Мой товарищ, которому приходилось использовать в работе язык программирования R, жаловался на низкое качество поисковой выдачи.
middle
В этом весь Яндекс.
fedorro
Было явно хуже чем у коллег - т.к. после установки FF постоянно пригорало от результатов поиска Яндекса, установленного как поиск по умолчанию, если сразу забывал выбрать другой.
middle
Речь о том, что метрики в некоторых компаниях заменяют здравый смысл.