

Надежность (reliability) программного продукта всегда является одним из приоритетов компании. Особенно это актуально для ПО, превратившегося в ежедневный инструмент для своих пользователей. Они рассчитывают на заявленный функционал, поэтому любая невозможность его использования подрывает доверие, а следовательно, и желание им пользоваться.
Если говорить про нефункциональные требования, то выше надежности в приоритетах компании стоит только безопасность (security). Все-таки риски несанкционированного доступа или утечки данных создают проблемы, граничащие с экзистенциальными для компании-разработчика.
В этой статье пойдет речь о главных инструментах Site Reliability Engineering (SRE) и о том, как они влияют на повышение надежности систем.
За что отвечает SRE
За все время требования к надежности в IT со стороны бизнеса нисколько не поменялись. Что сейчас, что 10 или 15 лет назад, бизнес хочет одного: чтобы все работало. Однако существенно изменились способы обеспечения надежности. ИТ индустрия начала путь с админов, следящих за uptime отдельных компонентов системы типа серверов, БД или кластеров. Но админы не вмешивались в код. Они считали, что это зона ответственности программистов.
Следующим шагом был DevOps, который попытался подружить админов и разработчиков, наладить коммуникацию между ними и ввести парадигму - you code it, you run it. Таким образом ответственность за поддержку ПО распределилась между всеми. Последний подход предполагает выделение отдельной роли для проработки вопросов надежности целиком всей системы, не разделяя её на зоны ответственности. Google назвал эту роль Site Reliability Engineer.
Сломано много копий на тему того, что такое SRE. Чем описанные подходы, а особенно DevOps и SRE, отличаются друг от друга. Кто-то говорит, что SRE это имплементация класса DevOps, а кто-то утверждает, что они не конкуренты, а только дополнения друг друга. На самом деле это не особо важно. Важен другой вопрос, а какие подходы и методы делают систему надежной?
Разберем эту тему подробно. Из опыта, надежность ПО — это наличие следующих практик:
Observability
Reliability architecture patterns
Proactive stability testing
Smart delivery of changes
Incident management
Дальше в статье поговорим о каждом из этих пунктов.
Observability
В теории управления observability (наблюдаемость) — это способность по выводу системы (метрики, логи, трейсы и др.) точно определить ее состояние. Если перевести на понятный язык, то получится: можем ли мы по метрикам, логам или трейсам понять, что происходит с нашим микросервисом, БД или другим любым компонентом современного ИТ?
Определение это не без изъянов. Размышляя о состоянии системы, можно легко забыть про тех, кто пользуется этой системой — пользователях. Именно пользователи выступают нашим финальным арбитром, который может сказать работает система или нет, и насколько она надежна. Соответственно, измерения необходимо не забывать делать и на стороне клиента.
Observability — это то, чем следует заняться в первую очередь. Выбрать метрики, по которым мы будем определять надежность системы и узнавать что что-то идет не так. А в последствии — понимать, улучшилась ли она от наших усилий.
Reliability architecture patterns
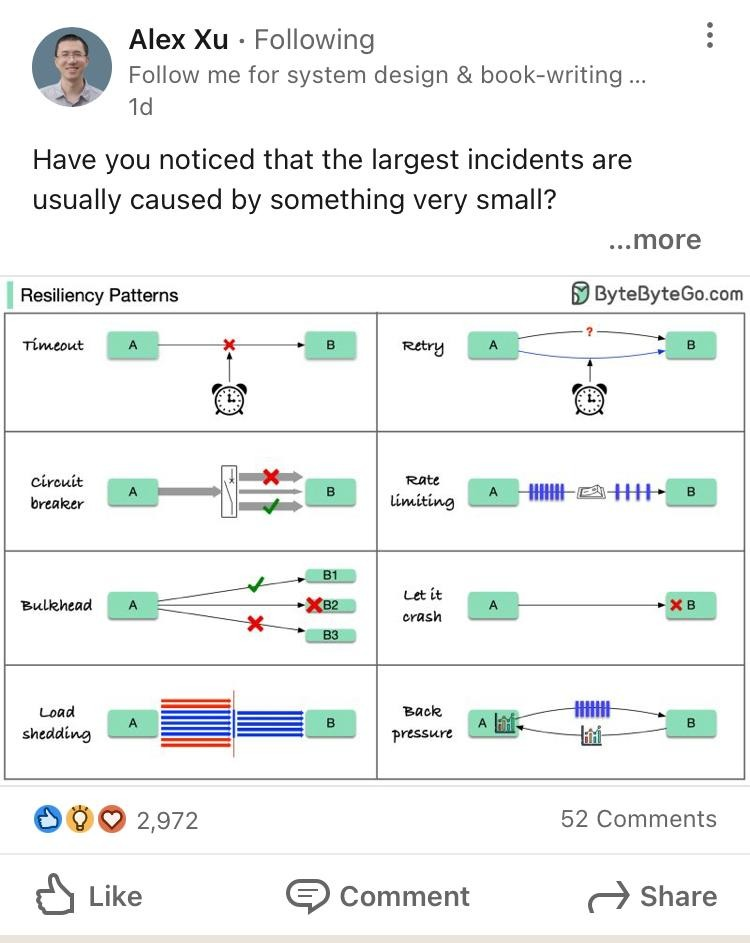
Практика показывает, что значительное количество проблем надежности связаны с отсутствием банальных приемов:
timeout
retries
backoff
rate limiting
circuit breaker
health checks
Эти подходы очень просты, но их влияние огромно. Именно они позволяют построить надежную систему из ненадежных компонентов. Например, если сервис авторизации иногда сбоит, то с помощью повторов (retry) можно сделать так, чтобы это было совершенно незаметно для конечного пользователя.
Вышеприведенный список не исчерпывающий:
умная балансировка (load balancing)
правильное шардирование (sharding / partitioning)
грамотно выстроенное масштабирование (scalability)
идемпотентные запросы (idempotent requests)
Другие техники тоже существенно влияют на конечный результат надежности.
Отметим, что первый список шаблонов относительно легко добавить на любом этапе жизненного цикла продукта, а вот паттерны из второго, если они не были заложены на этапе проектирования, добавить в существующий продукт просто не получится. Это сложный, долгий и дорогостоящий процесс.
Proactive stability testing
Проактивное тестирование еще один неотъемлемый подход к обеспечению надежности. Можно выделить здесь два компонента:
capacity planning
chaos engineering
Capacity Planning
Планирование емкости (capacity planning) нужно вам для понимания, а сколько ресурсов (CPU/memory/disk и др) нужно, чтобы выдержать заданный SLO/SLI при увеличении нагрузки, например, во время новогодней распродажи.
Этим capacity planning отличается от нагрузочного или стресс тестирования, которые больше рассчитаны на выявление узких мест и поведение системы при чрезмерных нагрузках.
Chaos Engineering
Идея Chaos Engineering была впервые применена в Netflix при миграции в облако. Задача была простой: уйти от идеи того, что система надежна, к идее, что в системе что-то периодически ломается. В итоге появились три типа возмущений (disruptions), которые можно и нужно периодически добавлять в работающий сервис:
отключение сервера (или другого компонента)
добавление задержек
истощение ресурсов
Эти возмущения позволяют реалистично эмулировать различные проблемы, которые обычно приводят к инцидентам. В результате подобных «экспериментов» система становиться готовой к таким сценариям и не падает во время реальных проблем.
Smart delivery of changes
Согласно State of DevOps за 2019 год, у компаний с плохим “Change failure rate” (“Low”) до 60% изменений вызывали деградацию сервиса и требовали неотложных действий. Эта же цифра у компаний с хорошим показателем метрики (“Elite”) не более 15%. В отчете за 2021 год разница уже меньше: 30% для “Low” и 15% для “Elite”. Однако это по-прежнему разница в два раза. Таким образом, очевидно, что работа с умным внесением изменений позволяет заметно сократить количество инцидентов.
Какие же изменения бывают, и как с ними работать по-умному? Ниже список видов изменений:
изменения кода
изменения конфигурации
изменения схемы данных
изменения данных
Можно выделить следующие методики работы с изменениями:
canary release: хорошо подходит для обкатки изменений кода и конфигурации на небольшой группе пользователей;
health mediated releases: релиз, когда его состояние отслеживается по ключевым метрикам здоровья системы. Происходит автоматический откат в случае проблем;
feature flags: активация отдельных кусков кода динамически во время рантайма. Позволяют отделить время выкатки кода, от его активации. Также можно отключить плохой код без отката релиза;
3-steps way to change schema and data: внесение изменений в схему или данные разбивается на несколько этапов. Первый: пишем совместимый с новой и старой схемами код. Второй: изменяем схему. Третий: переключаем код на новую схему и удаляем старый код.
В корне всех этих подходов лежит идея раздробления одного большого изменения на множество мелких. В итоге вероятность ошибки на каждом шагу снижается. А даже если и ошиблись, то ущерб от инцидента обычно меньше, чем при выкатывании изменений целиком.
Incident management
Какие бы приемы вы не применяли, у вас не получится сделать 100% надежную систему. Инциденты были, есть и всегда будут. Причем по мере развития их сложность будет только увеличиваться.
Хорошее управление инцидентами это ключевая часть надежной системы. И если с написанием посмотртемов и blamesless культурой все более-менее понятно (на эту тему есть много статей и презентаций), то с тем, правильно организовать incident call, какие роли и best-practices использовать, как организовать передачи дел между сменами — все сложнее.
Заключение
Требования бизнеса к надежности ПО были и остаются неизменными, поскольку люди хотели и хотят пользоваться стабильным продуктом. Однако, за все время существенным изменениям подверглись именно способы обеспечения надежности.
Пройден путь от разрозненных действий, когда админы и программисты находились по разные стороны баррикад, до объединивших их DevOps. Следующим шагом стала роль SRE-инженера, задача которого обеспечить надежность и масштабируемость системы.
Сделать это возможно при наличии описанных практик:
Observability. Понимание как ведет себя система с точки зрения пользователя.
Reliability architecture patterns. Шаблоны построения надежной системы.
Proactive stability testing. Проактивное тестирование емкости (capacity) и устойчивости системы к сбоям.
Smart delivery of changes. Умный и безопасный деплой изменений.
Incident management. Управление инцидентами.
Если вы уже применяете изложенные в статье практики или часть из них, значит вы идете по пути внедрения SRE.
10 ноября стартует курс SRE: Мега
Этой осенью Слёрм запускает углубленный курс с редкими для российского рынка инструментами SRE.
SRE: Мега – это практический курс по внедрению инженерного подхода к решению проблем с помощью продвинутых инструментов SRE:
advanced SLO/SLI practices;
advanced reliability patterns: backoff, rate limiting, circuit breaker, etc;
capacity planning;
chaos engineering;
advanced ways to deliver changes: features flags, 3 steps way to change; schema and data, etc;
Вы можете приобрести курс полностью или отдельными интенсивами на нашем сайте.