
Доставлять высококачественное видео с помощью CDN дорого, а неравномерность нагрузки усложняет всё ещё сильнее. Можно ли улучшить эту ситуацию и сэкономить?
На нашей прошлогодней конференции VideoTech Руслан Гильмутдинов рассказал о p2p-подходе, позволяющем минимизировать зависимость от CDN и снизить затраты.
А теперь, пока мы готовимся провести VideoTech 2022 с новыми докладами уже на этой неделе, сделали для Хабра текстовую расшифровку его выступления (видеозапись также прилагаем). Далее повествование будет от лица Руслана.
Обо мне
Ранее я работал в Streamroot. Наверное, это единственная компания, создавшая коммерчески успешный продукт подобного рода — назовём его условно «гибридным CDN» (совсем без CDN он существовать не может, но WebRTC позволяет значительно снизить необходимость в нём).
В 2019 году компанию Streamroot купил один из крупнейших CDN мира, тогда называвшийся CenturyLink (теперь Lumen Technologies), и сделал это частью своей продуктовой линейки. Что, как мне кажется, олицетворяет собой признание технологии. Уж не знаю, почувствовали ли они угрозу для своего бизнеса или посчитали, что это будет вишенкой на торте к их существующим продуктам. В любом случае, Streamroot стал частью CenturyLink, а WebRTC (в том числе видеостриминг на его базе) стал частью традиционного CDN.
После Streamtoot я перешёл в компанию Иви, которая успешно применяет подобную технологию «не совсем CDN» на базе WebRTC. За что нас некоторые CDN-вендоры, возможно, не особо любят: мы немного ломаем им бизнес.
Традиционная схема доставки видео
Для начала стоит объяснить, как работает доставка видео на основе традиционных CDN.
Мы знаем, что у нас есть фундаментально два типа вещания:
живое потоковое вещание, то есть прямой эфир;
VOD (video on demand) — например, онлайн-кинотеатры, тот же Иви.
То есть источники сигнала — либо видеокамера, либо какие-то файлы (например, тайтлы, полученные от правообладателя). Все это должно быть доставлено до пользователей через какую-то сложную CDN-систему.
Обычно она многоуровневая, особенно в странах вроде России. Существуют edge-сервера (например, какие-то точки присутствия в малых городах). Эти малые города образуют региональный кластер (например, поволжский или сибирский). А региональные кластеры уже забирают контент с источника, из каких-то файловых серверов (для России, как правило, это Москва). Примерно такая схема сейчас в индустрии:

Интересно, как меняется структура трафика. Если лет 10-15 назад мы с вами скачивали фильмы и смотрели их на ноутбуках и десктопах, то сейчас с ростом популярности онлайн-кинотеатров Smart TV — уже половина устройств, с которых люди потребляют контент.
Ещё примерно 30% приходится на мобильный трафик. Типовой сценарий поведения — «вот тебе, дитятко, планшет, смотри там "Машу и Медведя", а я пойду делать свои дела по дому».
И где-то 20% трафика – современный десктоп. И есть тенденция к тому, что этот десктопный трафик будет продолжать снижаться.
Этот трафик никогда не бывает линейным. Мы все прекрасно понимаем, что пятничным или субботним вечером очень много людей хотят посмотреть фильм. Или, например, во время очень популярного события вроде Олимпиады трафик трансляции взлетает. И вот типичная картина:

Отдельно хочется отметить, что пандемия тоже внесла свои коррективы, и в целом по миру видеотрафик растет. И обладает этот трафик выраженной сезонностью. Зимой гораздо прикольнее смотреть фильм под теплым одеялом, чем топтать снег.
К чему это нас приводит, как, например, владельцев какого-нибудь онлайн-кинотеатра или CDN? К тому, что неравномерность нагрузки — фундаментальная вещь, обусловленная природой поведения людей, это наша данность в мире видеостриминга.

Вот пример того, как может выглядеть неравномерный трафик на срезе в два месяца:

С середины начались какие-то спортивные трансляции, предположим, что это турнир «Ролан Гаррос». И на его протяжении мы видим пики трафика: люди налетели, посмотрели матчи, принесли нагрузку на CDN, событие закончилось, и люди убежали.
К чему приводит такая нелинейность трафика и traffic spikes, то есть пики трафика, которые трудно предсказуемы по своей природе:
Очень сложно бюджетировать расходы на CDN, потому что, как правило, крупные CDN-провайдеры заставляют нас заключать контракт минимум на год с каким-то обязательством по трафику. И если мы не влезаем в него, то начинаются сложности. Обычно нельзя просто докупить трафика на один конкретный день, когда будет финал какого-нибудь чемпионата.
-
Просадка битрейта, когда очень много потребителей одновременно нагружают CDN. Система может справиться, но ценой снижения разрешения с 4K до Full HD или с Full HD до SD. Пример: опять же во время пандемии всем известная организация настоятельно рекомендовала онлайн-платформам временно перестать отдавать видео в формате Full HD, потому что возникает очень большая нагрузка.

Если же CDN даже после деградации со снижением битрейта не справился, то у пользователя может просто случиться отказ, и видео он больше не увидит.
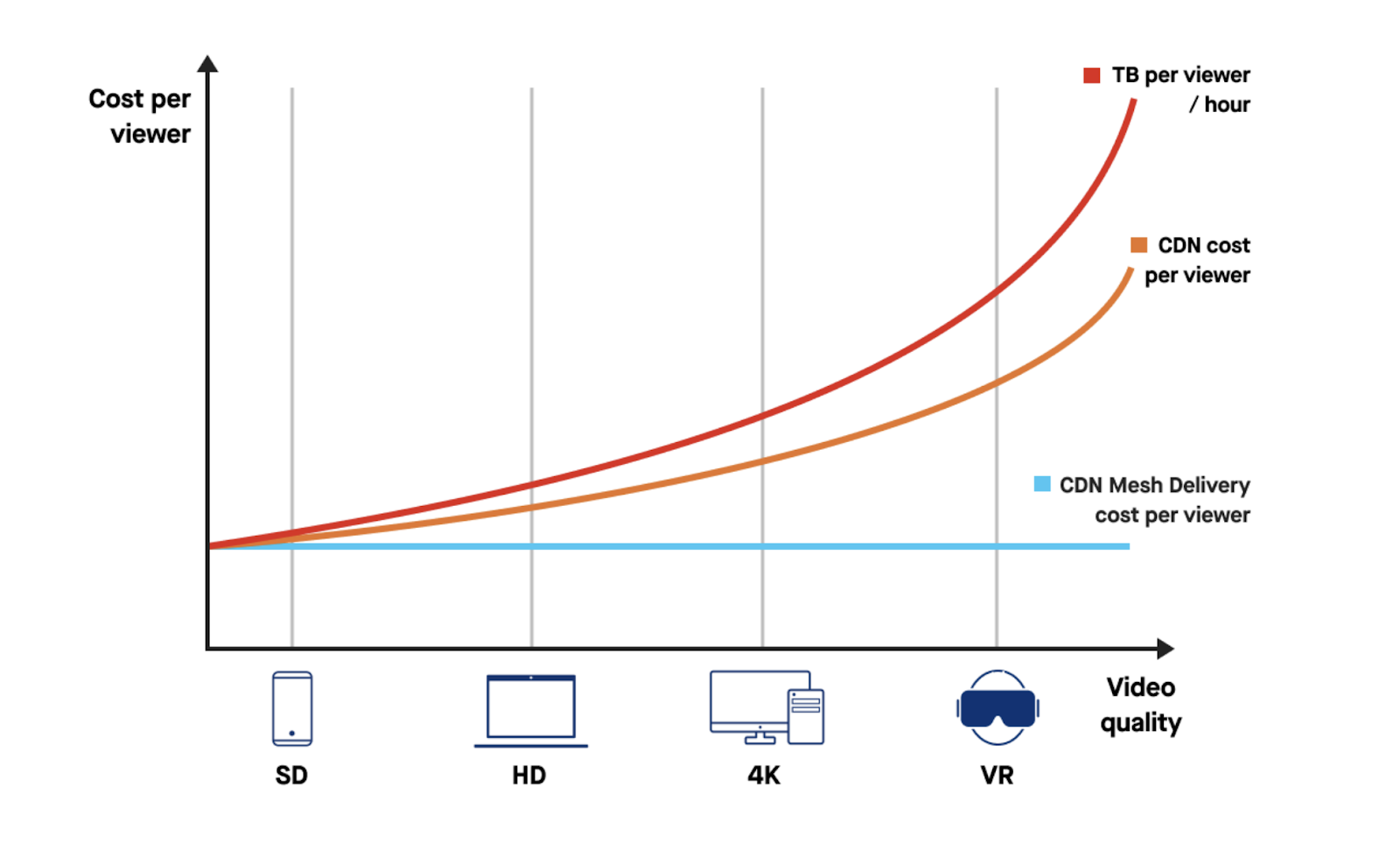
С бюджетированием есть и такая сложность. Если мы хотим отдать видео в 4K, а через пару лет это будет 8K, то, к сожалению, объем трафика не линеен относительно того качества, в котором мы хотим его отдать, прирост просто экспоненциальный:
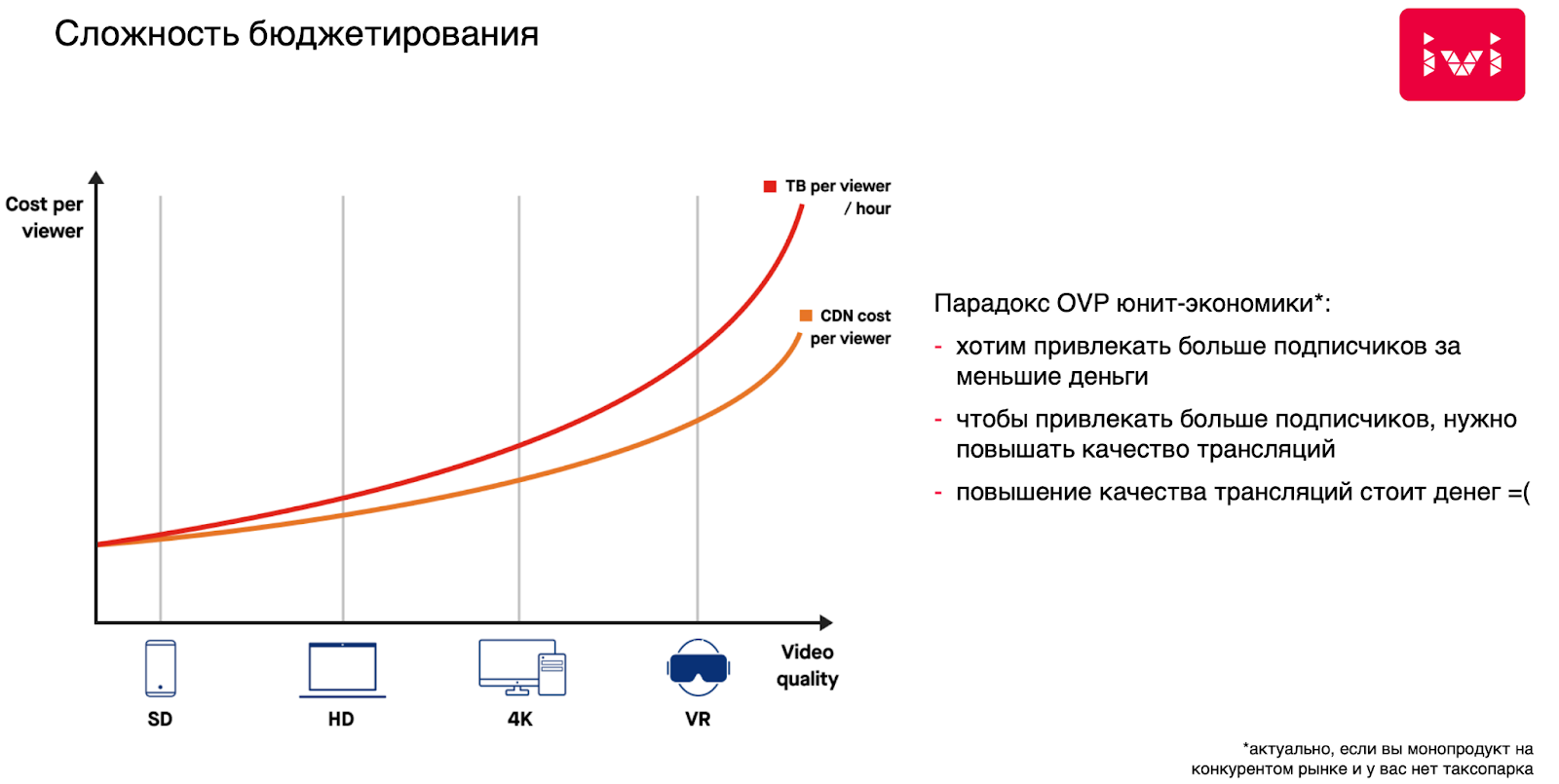
И возникает дилемма условного онлайн-кинотеатра. Чтобы увеличить базу подписчиков, нужны конкурентные преимущества. Но для преимущества в виде 4K-видео нужно инвестировать в CDN-инфраструктуру, и получается парадокс: потенциальные подписчики могут принести деньги, а инвестиции в инфраструктуру все их съедят.
И вследствие всего этого мы как пользователи то не можем смотреть видео в нужном нам качестве (а при этом за подписку продолжаем платить), то в определенный момент вообще не можем посмотреть, потому что всё упало (это очень актуальная проблема для трансляций прямого эфира крупных спортивных событий).
Собственно, компания Streamroot начала с того, что попыталась в свое время решить проблему трансляцию Супербоула. Это самое популярное спортивное событие США — ежегодная финальная игра за звание чемпиона НФЛ. В 2021-м его смотрели 97 миллионов пользователей по всем платформам, в том числе по традиционным кабельным ТВ. При этом около 6 миллионов пытались посмотреть трансляцию через интернет, но столкнулись с проблемами. Каждый год меняется провайдер, каждый обещает беспроблемно транслировать и не справляется. CBS очень удачно оправдались ковидом и сказали, что «ребята, извините, HDR и 4K не будет». А истинная причина в том, что просто CDN не в состоянии все это переварить.
Примерно так у нас обстоят с вами дела на рынке видеотрансляций, которые используют традиционный CDN. И возникает вопрос: что же с этим делать, можно ли что-то улучшить?
Раздавать видео без CDN (ну почти)
Как быть, что делать? Давайте попробуем решить проблему на корню и начать раздавать видео почти без CDN, минуя его. Как может выглядеть такая схема? Какие технологии могут нам потребоваться?
Есть замечательная технология WebRTC, которая совсем недавно вступила в совершеннолетний возраст. По-моему, было примерно 20 черновых вариантов стандарта, но сейчас WebRTC — наконец-то стандарт, и это замечательно.
Что позволяет WebRTC? В контексте нашей с вами проблемы WebRTC позволяет установить прямое соединение между клиентами и напрямую обмениваться данными. Это могут быть видео- и аудиопотоки, которые мы с вами получаем через микрофон и веб-камеру, встроенную в ноутбук. А также любые произвольные бинарные данные, что угодно: книги, видеофильм в виде mp4, то есть всё, что вы захотите. И для этого в WebRTC существует отдельная технология, которая называется Data Channels.
У видео- и аудиопотоков, которые передаются, например, через микрофон и веб-камеры, под капотом будет протокол RTP — очень старый фундаментальный протокол передачи потоковых данных. А Data Channels используют протокол SCTP, где под капотом в большинстве случаев будет UDP.

Предлагаю вам открыть специальную страницу с демкой. Можно и с мобилок, и с утюга, но с целью «поковыряться» лучше открыть в десктопном браузере, а в другой вкладке параллельно открыть отладочную информацию: у Chrome это будет на странице chrome://webrtc-internals, у FF — about:webrtc.
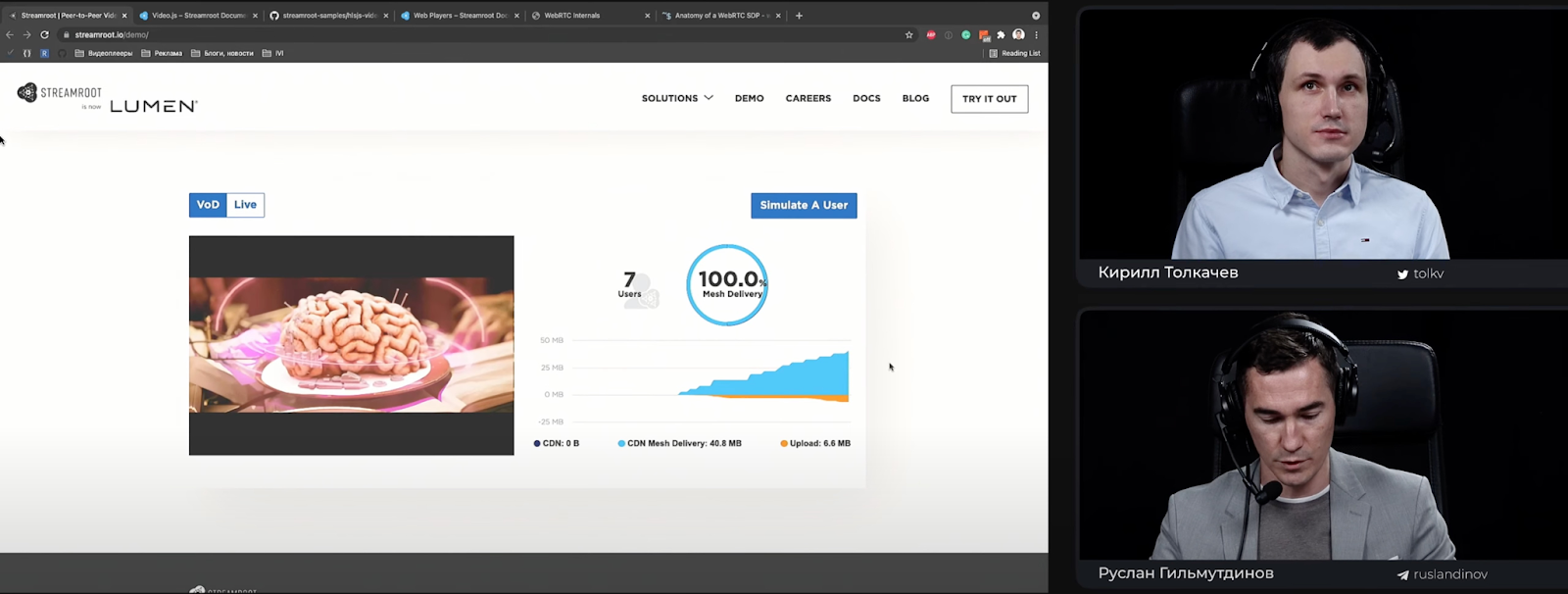
На этой странице мы видим классический плеер Video.js, де-факто один из стандартов индустрии. Есть некий счетчик пользователей — и прямо сейчас, пока я веду доклад, мы видим, как он начинает расти, потому что участники конференции подключаются:

Число «4 users» на экране — те пользователи, которые здесь и сейчас со мной образовали peer-to-peer сеть посредством WebRTC и начинают обмен данными, минуя CDN.
Внизу есть график двух цветов: оранжевого и голубого. Оранжевый трафик — те данные, которые я отдаю кому-то через WebRTC. Голубой — у кого-то эти данные я скачиваю через WebRTC, минуя CDN. Очевидно, что этими данными являются видеосегменты.
Мы можем открыть вкладку Network. Под капотом этой демки используется HLS.js — очень популярный медиадвижок (кстати, участники Videotech через него и смотрят трансляцию доклада). Мы знаем, что сегменты в HLS.js имеют расширение .ts. У меня открыта вкладка Network, есть фильтрация по ts. Видео продолжает идти. Но я не вижу запросов сегментов, потому что скачиваю их от кого-то из вас через WebRTC. То есть я не нагружаю CDN.
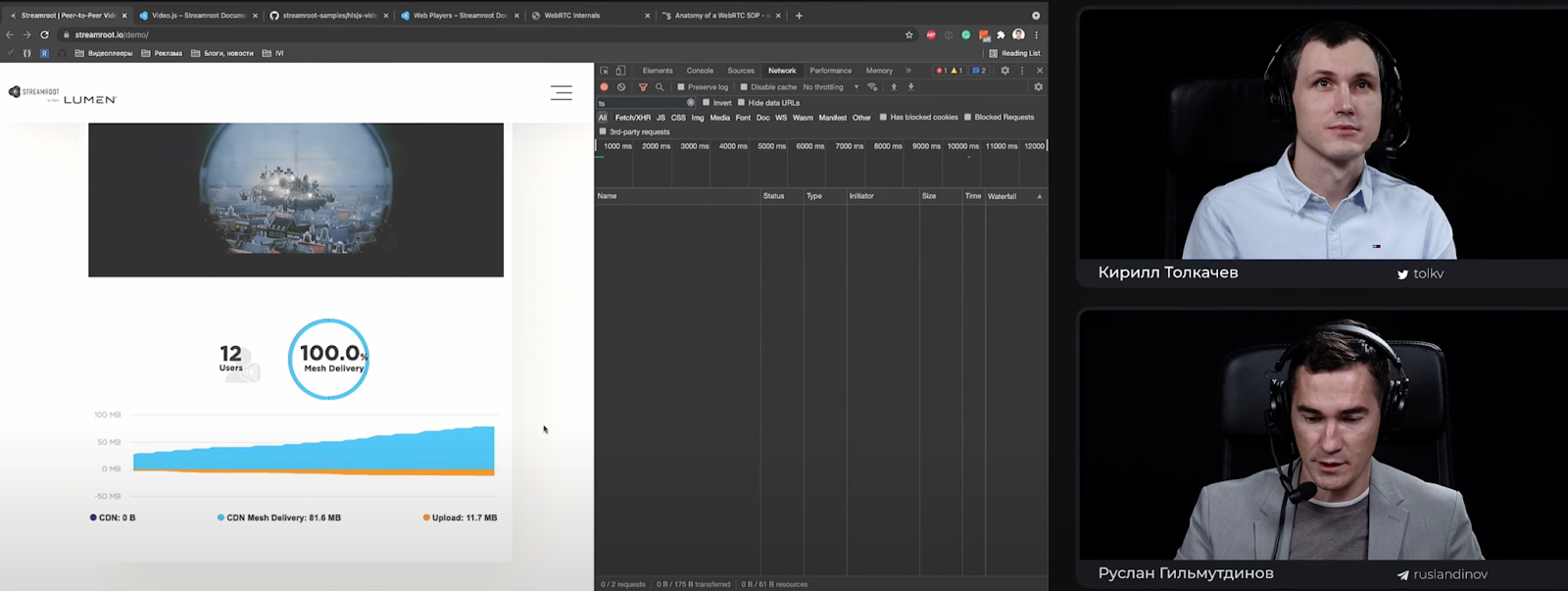
Бизнес-логика находится на клиентской стороне, и она подстраивает свою peer-to-peer сеть под те условия среды, которые она мониторит: пропускной канал, производительность системы. Пытаясь сохранить оптимальную производительность, не допустить буферизации и самое главное – не ухудшить качество пользовательского опыта. Ведь грош цена этому peer-to-peer решению, если в итоге ты сэкономил на CDN, но наши пользователи нас с тобой не увидят.
Посмотрим на вкладку chrome://webrtc-internals

Много соединений, каждое олицетворяет собой какой-то компьютер пользователя, который нас сейчас смотрит. Можно потыкать в отдельные из них. Вообще тут столько всего, что по этому можно делать отдельный доклад. А пока ограничусь тем, что если хотите узнать больше, можете загуглить "webrtc internals explained".
Прелесть технологии в том, что она динамически подстраивается под условия, которые мониторит и наблюдает.
Конечно, совсем без CDN не обойтись, чанки не возьмутся из воздуха. Кто-то из наших пользователей сейчас скачивает данные с CDN, но таких меньшинство: скажем, вместо 18 всего 3.
Как это работает
У нас есть видеоплеер, который показывает нам видео, запрашивает с CDN манифесты (они же плейлисты: в HLS-комьюнити любят использовать первый вариант, в DASH-комьюнити второй). Плейлист/манифест — это метаинформация о разметке: по сути, список URL-сегментов, которые нам нужно скачать с CDN, чтобы пользователь увидел видео.
Технология в основном расположена на клиентской стороне. То есть, если говорим о браузерах, это такой же скрипт, как и ваш любимый видеоплеер. Он загружается, элегантно оборачивает себя вокруг видеоплеера, перехватывает запросы, которые видеоплеер пытается послать в CDN (в частности, запросы манифестов), чтобы понять, какие сегменты будут интересны плееру в ближайшие моменты. Далее через свою P2P-сеть он пытается эти сегменты скачать заранее до того, как плееру понадобятся эти сегменты. Если ему это удалось, он их хранит в памяти до того момента, пока они не понадобятся плееру.
И как только плеер говорит «слушай, дорогой мой CDN, хочу сегмент с таким-то URL», этот клиентский P2P-модуль отдает этот сегмент плееру, тем самым избавляя плеер от необходимости идти и нагружать CDN этим своим сегментом.

Стоит немного подробнее рассказать о том, как эта штука оборачивает себя вокруг плеера. Важно отметить, что сейчас технология работает только на адаптивном стриминге, то есть если у вас стриминг mp4, это всё немножко не взлетит. Но хорошая новость в том, что стриминг mp4 уходит в прошлое, а для лайва он в принципе не актуален.
Любой медиаплеер по большому счету решает очень простую задачу. Он должен понять, в каком месте пользователь хочет смотреть контент и в каком качестве он хочет это делать. Это функция от двух аргументов: current time и quality. На выходе он выдает URL, который будет запрошен с CDN. Полученные данные через пайплайн демуксинга перейдут, условно говоря, в рендеринг пайплайна браузера или мобильного приложения и будут показаны пользователю. Сегмент запрошен, CDN попадает в буфер плеера, рано или поздно пользователь его увидит. Размер буфера конфигурируемый.

Чуть детальнее на примере всем известной схемы:

По большому счету, все то же самое, нам нужно запросить сегменты с CDN. Красным выделены те части Shaka Player, которые отвечают за запрос сегментов. Если там есть DRM, как-то декодировать это всё, запросить ключи, но в итоге всё равно отдать это в пайплайн рендеринга и показать.
Вот этот клиентский P2P-модуль, который работает на стороне браузера (или, например, если мы говорим о мобильных приложениях, встроен в ваше приложение), работает на транспортном слое плеера, по сути подменяя его. Раз мы перехватываем запросы, нам нужно либо переписать транспортный слой плеера, либо заменить, либо элегантно обернуться вокруг него. Чтобы, с одной стороны, у плеера не было никаких проблем, и для него технология была абсолютно прозрачной, а с другой стороны, для эффективности технологии мы понимали, какие сегменты надо бы скачать заранее в этот P2P-кэш.
Перехват запросов
Как мы можем перехватить запросы на примере веба:
Переопределить XMLHttpRequest и Fetch API своей реализацией (Peer 5).
Интеграция с транспортным слоем видеоплееров (Streamroot).
Когда я работал в Streamroot, в свое время мы конкурировали с компанией Peer 5, которая на заре становления пошла в вебе очень радикальным путем. Там просто взяли и переопределили XMLHttpRequest (Fetch API тогда еще не было).
Мы как инженеры понимаем, с каким количеством подводных камней можно столкнуться, переопределив этот фундаментальный механизм браузера, и какие последствия мы получим не только на этапе показа видео, но и на этапе загрузки страницы, каких-то скриптов, которые могут потребоваться этой странице, и так далее.
В Streamroot пошли другим путем — интеграцией с транспортным слоем популярных видеоплееров (их не так уж много). Технически этот путь сложнее, но для пользователя проще. Благодаря тому, что мы интегрировались в плееры, для конечного клиента процесс прикручивания P2P становится достаточно простым.
Интеграция P2P-модуля
В чем состоит интеграция клиентского P2P-модуля с веб-плеерами:
Чтобы предугадывать, какие сегменты скоро понадобятся, нужен мониторинг позиции воспроизведения и буфера (нет смысла скачивать то, что плеер сам сейчас уже буферизует). Их можно осуществлять либо через API плеера, либо напрямую с медиаэлемента страницы.
Плееры можно поделить на три категории. Есть опенсорсные молодцы с хорошей документацией, которые позволяют через DI пробросить свою реализацию транспорта (hls.js, Shaka Player).
Другая категория по умолчанию таких возможностей не предлагает, но если они с открытым исходным кодом (dash.js) — возможно форкнуть, засучить рукава и написать «плагин».
Третья категория — плееры с закрытым исходным кодом (JW Player, THEOplayer, Bitmovin, castLabs, Brightcove), как правило, являются частью соответствующей коммерческой платформы и предлагают API для написания плагинов. Им можно написать письмо с предложением добавить P2P.
С вебом разобрались, с ним все в целом просто. Как быть с мобильными платформами? Как перехватывать запросы сегментов и манифестов на Android и iOS?
С Android проще. Там используются NexPlayer или ExoPlayer, оба с открытым исходным кодом, интегрируемся аналогично вебу.
-
iOS. Это AVPlayer, альтернатив ему нет и он закрытый — транспорт не переопределить. Что делать? Проявить смекалку:
Так как приложение, показывающее видео, контролируете вы, то URL манифеста вам известен.
Скачиваем его и парсим.
Прячем P2P-модуль за локальным прокси-сервером внутри приложения. URL сегментов манифеста переписываем так, чтобы они вместо CDN смотрели на прокси-маппинг подмененных URL. И это отдавали AVPlayer.
Вот страница с документацией, чтобы вы понимали объемы проделанной работы по интеграции. Там есть список веб-плееров, с которыми интегрировано решение Streamroot. В нём все «топовые ребята»: несколько версий Shaka, Video.js, Bitmovin и далее. Обширный список. Также в недрах документации будут ссылки о том, как интегрировать iOS SDK и Android SDK.
Код для интеграции может быть буквально в две строчки.

Мы загружаем Video.js, учим Video.js воспроизводить HLS, для этого есть плагин, который я когда-то писал, он опенсорсный, так и называется — videojs-hlsjs-plugin. Далее или перед этим — как вам удобнее, мы подгружаем обертку P2P-модуля вокруг всей этой связки Video.js и HLS, инициализируем как обычно тег <video>, инициализируем Video.js и все.

Здесь задаем конфиг, который будет определять то, как будет работать наша P2P-технология. Конфиг достаточно объемный, он отлично задокументирован на сайте.
Я пытаюсь продемонстрировать, что интеграция безумно простая именно благодаря тому, что ребята в свое время потратили много лет и отловили все возможные подводные камни.
Разобрались с клиентской частью. Но очевидно, что это не всё. Те, кто знаком с WebRTC, знают, что нам нужен signaling-сервер.
Более того, поскольку я сейчас показал коммерческий продукт, очевидно, нам нужно как-то идентифицировать клиентов, различные компании. Скажем, ту же компанию JUG Ru Group, если она захочет это прикрутить и следующий VideoTech провести с помощью этого.
Бэкенд P2P-модуля
Фундаментально бэкэнд можно разделить на три части:

1. Трекер — это бизнес-логика.
2. Signaling, который решает проблему знакомства пиров в контексте WebRTC.
3. Много баз данных, которые всё это оркестрируют.
На этой схеме я чуть подробнее разобрал устройство клиентского P2P-модуля, как он работает внутри и какие у него есть самые крупные фундаментальные составные части:

Как уже говорилось, есть некая обертка вокруг плеера (player wrapper), задача которой мониторить текущую позицию воспроизведения, качество и размер буфера. Этот wrapper, перехватывая запросы сегментов, стучится в P2P Cache с одним вопросом: скачивали ли мы это сегмент уже раньше через P2P. Если сегмент есть, он тут же улетит в плеер, если нет – P2P-модуль скачает его через CDN, положит в P2P Cache, вдруг потом кому-то понадобится и можно будет раздать, и отдаст все это в плеер.
Есть такая штука, как Peer Pool Manager, она и оркестрирует число на демо, которое я вам показывал (число пользователей). Peer Pool определяет с кем нам стоит дружить, а с кем не стоит.
Теперь расскажу о трекере. Мы открываем веб-страницу, у нас инициализируется P2P-модуль. Первым делом он стучится в трекер примерно со следующим запросом:

Если, предположим, мы уже не первый раз в течение этой сессии стучимся в трекер, опционально будет передан трекер список плохих пиров, и трекер отметит это у себя где-то в базе этих пиров как плохих и как минимум не предложит их нам. А если на этих пиров уже поступает достаточно много жалоб, то он, в принципе, их отключит от трекера, их P2P-модуль деактивируется, и они перестанут предлагаться. Причина для попадания в список плохих пиров – это, как правило, плохое соединение.
Предположим, что аутентификация прошла успешно, P2P-модуль запущен у валидного клиента — всё здорово. В ответ трекер получает от P2P-модуля следующее: я понимаю, какое видео ты смотришь, знаю, где ты примерно его смотришь, вот тебе список кандидатов в пиры, попробуй установить с ними соединение.
Если плеер как-то радикально меняет позицию воспроизведения, мы начали смотреть фильм и перематываем в конец или в середину, или меняет качество, P2P- модуль снова постучится в трекер и скажет: «кажется, у меня что-то фундаментально изменилось, я сменил качество, поэтому мне нужны пиры, которые смотрят контент в том же качестве, что и я, чтобы я обменивался с ними актуальными данными». Потому что вы расстроитесь, если вы заплатили за 4K в своей подписке на сервис, а P2P-модуль вам зачем-то подсовывает правильное видео, но в качестве SD. Поэтому P2P-модуль и трекер очень тщательно следят, чтобы не происходил обмен сегментами того качества, которое сейчас пользователю не интересно.
Чуть нагляднее о том, как выглядит подбор пиров на основании их позиции смотрения:
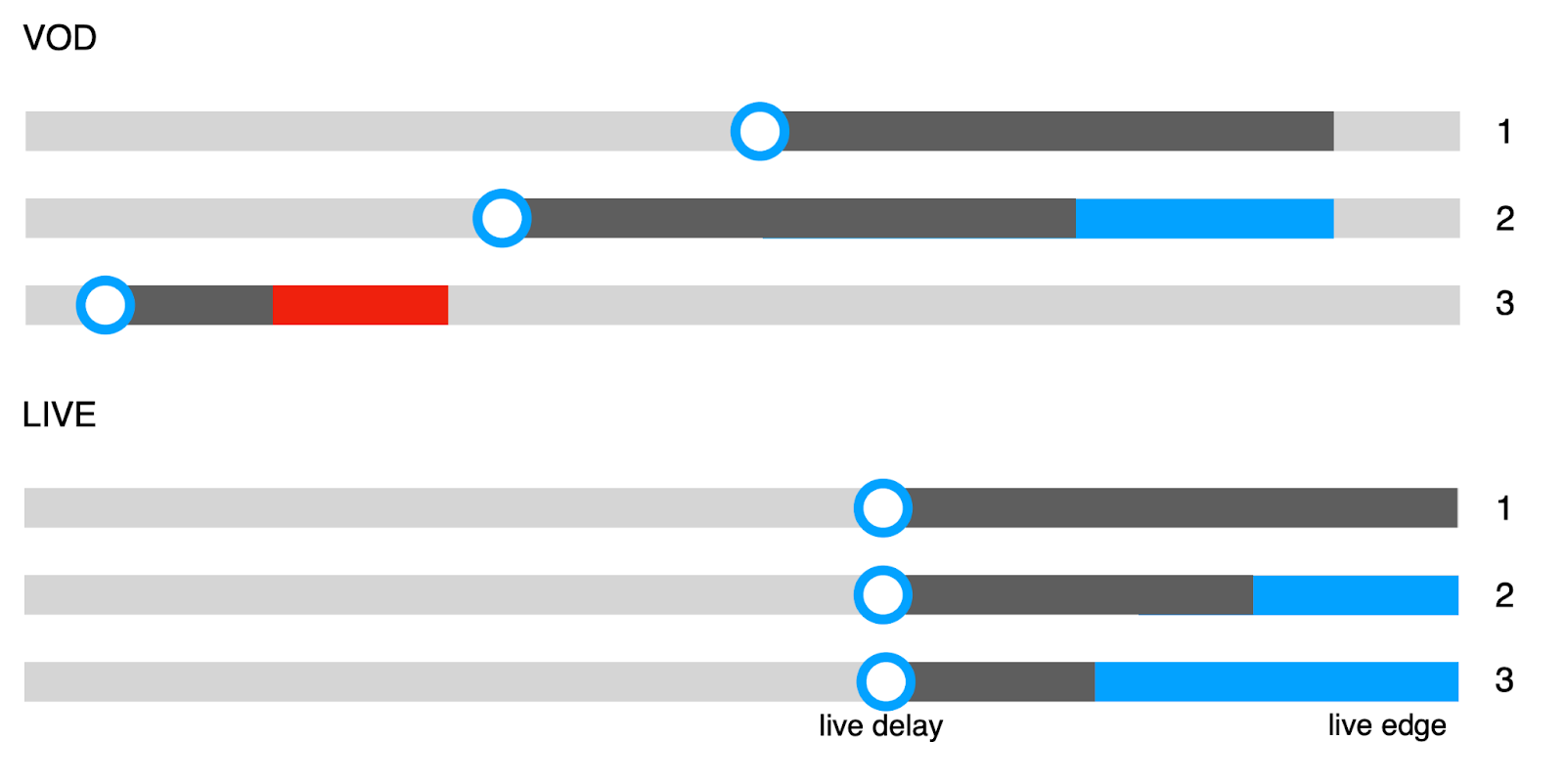
Есть два кейса: VOD и лайв. С лайвом все просто, все видят трансляцию примерно в одинаковой позиции, да, бывают небольшие задержки от студии до зрителей, этот пресловутый handshake latency – сколько секунд проходит от того, как я помахал рукой до того момента, как вы это увидели. Но мы примерно в секундах или в сегментах от live edge на одинаковом расстоянии.
Мы знаем, что у видеоплеера есть буфер. Что делает P2P-модуль? Он варьирует размер этого буфера на разных клиентах, это серая шкала, оставляя пространство для P2P-кэша. И видно, что у пользователей 2 и 3 буфер чуть меньше, чем буфер у 1 пользователя, он жадный, его плеер хочет буферизовать все до самого live edge. Опытный инженер скажет, что лучше так не делать, потому что скорее всего он будет часто получать 404, так как сегменты могут не успевать откодироваться.
Смысл здесь в том, что у нас есть пространство, эта пресловутая дельта, подсвеченная синим цветом, и в этом пространстве будет происходить P2P-обмен для лайва. Поскольку мы с вами смотрим одну и ту же трансляцию, тут очень классно работает эффект снежного кома. Чем больше людей смотрит трансляцию, тем качественнее будет P2P-обмен, тем меньшему количеству пользователей нужно будет уходить на CDN.
С VOD все чуть сложнее по той простой причине, что условные ребята могут смотреть один и тот же фильм, но, к сожалению, фильм – штука большая, и смотреть они могут в разных точках. P2P Cache – это штука, которая вообще-то потребляет память, поэтому нет смысла дружить пирам, которые только начали смотреть фильм и тем, кто его уже досматривает. Между ними настолько большое пространство в сегментах, что им просто нечем будет обмениваться.
Возвращаемся к signaling. Задача здесь очень простая – нам нужно как-то обменяться SDP, двум пирам, которые хотят установить между собой соединение. Есть проблема NAT, большая часть клиентов сидит за фаерволами, за роутерами и так далее, мы не имеем с вами выделенного прямого интернет-адреса, нам нужно понять, какой у нас есть внешний IP. Нам в этом помогает STUN и замечательная штука под названием ICE. Эти штуки позволяют нам узнать, какой у нас внешний IP, то есть куда нужно стучаться второму пиру, чтобы у нас получилось соединение.
Вкратце покажу, что такое SDP, это очень большая штука. Те из вас, кто работает с WebRTC, знают что SDP очень многословная и, к счастью, для наших потребностей она нам вся не нужна. Есть несколько типов ICE-кандидатов: host и srflx.
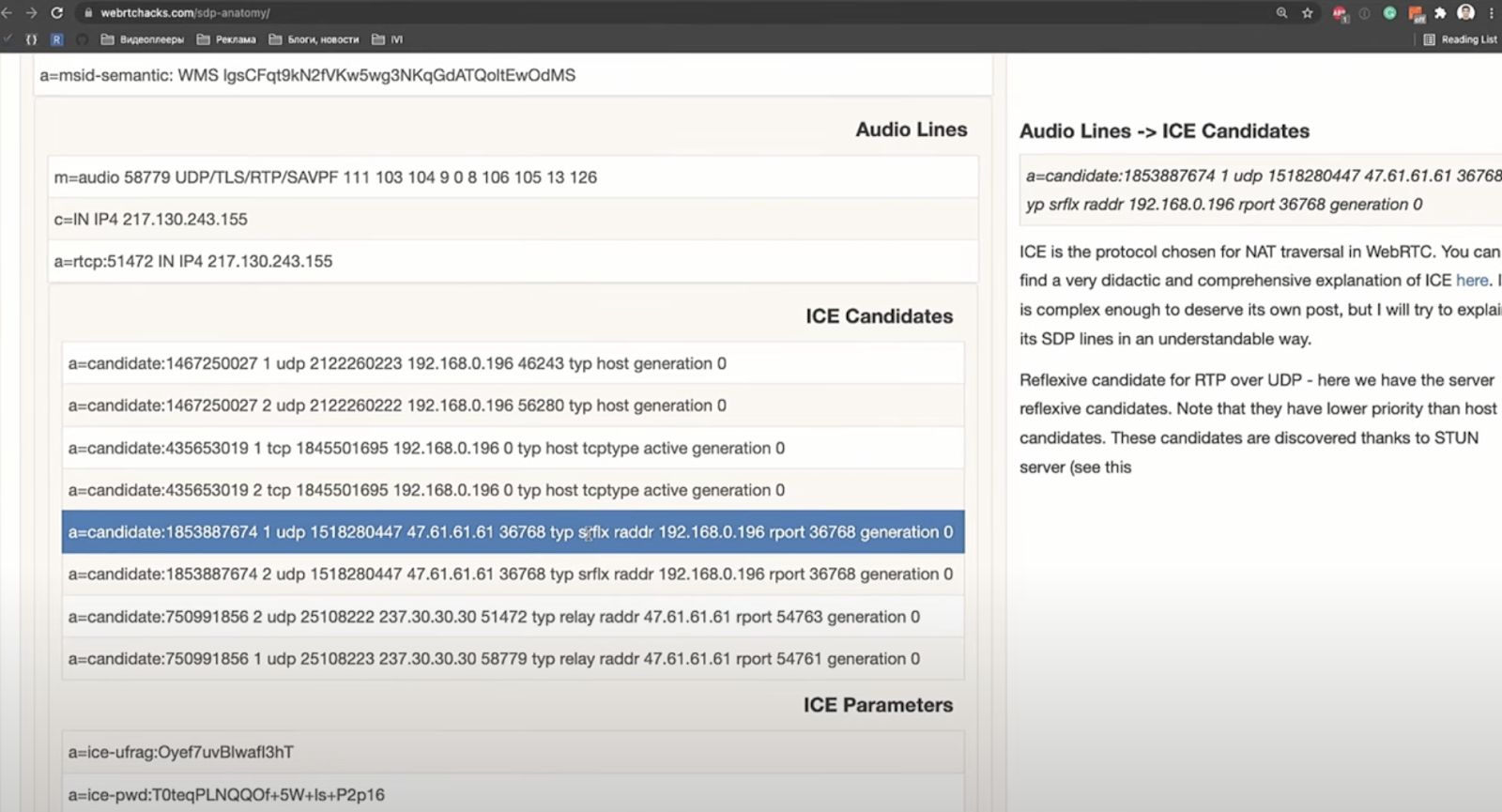
Кандидаты типа host – условно, наш сетевой интерфейс локальной сети, от него толку ноль, потому что какой толк Васе из Владивостока от знания моего локального IP, когда я в Москве. Поэтому SDP очень классно сжимается, мы выкидываем всё, что не является srflx-кандидатом по UDP, потому что именно по UDP, в конечном счете, конечно, по SCTP, но под капотом — по UDP работает WebRTC Data Channels.
Все это прекрасно сжимается, и эта многословная SDP-структура превращается в очень компактную, которая запихивается дальше в наш signaling. Таким образом пиры обменялись SDP и пытаются установить соединение, если их всё устраивает.
Соединение установлено, и мы можем приступить к формированию Peer Pool на клиентской стороне:

Что мы видим? Те кто знаком с сетевыми топологиями, знает, что это классическая ячеистая топология, у которой есть нюанс – чем больше эта топология, тем больше суммарное количество соединений, которые нужно установить. Такова природа ячеистой топологии. Важно помнить, что каждое соединение – это клиентский ресурс, и P2P-модуль может быть запущен не только на супермощном ноутбуке или десктопе, он также может быть запущен на маленькой жалкой мобилке на андроиде. И примерно так вся эта проблема ячеистой структуры выглядит для мобильных устройств:

К вопросу формирования Peer Pool P2P-модуль подходит безумно ответственно в зависимости от того, на каком устройстве он запущен. Тут очень много нюансов, начиная от таких, например, что «у меня вообще-то на моей мобилке такой тарифный план, что у меня всего лишь 5 гигабайт трафика, и я зашел в какое-то ваше приложение, и мои гигабайты буквально закончились, просто потому что я посмотрел вашу классную конференцию, пожалуйста объясните, почему так получилось». И заканчивая тем, что за полчаса сел аккумулятор, мобилка раскалилась докрасна, потому что чем больше Peer Pool, тем больше прямых соединений нам нужно. Формула простая, против природы не попрешь. И именно поэтому модуль Peer Pool является краеугольной частью P2P-модуля, той части, которая работает на клиенте. Он в режиме реального времени мониторит качество соединения с каждым из пиров и в случае, если качество соединения почему-то плохое, эти пиры будут безжалостно выброшены.
Иногда бывает так, что Peer Pool понимает, что он попал на какой-то жирный канал, в этом случае он может стать так называемым суперсидером, трекер для всех в Peer Pool объявит его суперсидером. И это будет тот самый парень, который будет больше всех закачивать с CDN и больше всех раздавать по WebRTC остальным. Там очень много параметров, которые могут повлиять на решение об оптимизации Peer Pool, в конфиге этого модуля порядка 350 параметров.
Протокол, которым пиры обмениваются внутри Peer Pool, очень простой, он бинарный, спасибо protobuf. Отчасти это сделано для того, чтобы минимизировать какие-то потери на обмен метаинформации между пирами.

Как выглядит передача сегментов?
Мы используем Data Channels, если читать документацию по WebRTC и Data Channels, можно наткнуться на рекомендацию, что размер сообщения не должен превышать 64 Кб. Мы эмпирическим путем пришли к тому, что дефолтный размер – это 15 Кб, причем этот размер может варьироваться от клиента к клиенту. Допустим, у нас есть клиент из Латинской Америки, там с CDN и с интернет в общем очень плохо, там даже 15 Кб может оказаться штукой, которая так вот просто не пролезет. И там для этого клиента трекер отдаст конфиг P2P-модуля, в котором 15 Кб превратятся в 5 Кб.

Сегмент разбивается на чанки по дефолту по 15Кб и он может быть запрошен у разных пиров, на то и нужен Peer Pool, чтобы максимально быстро, опережая аппетит плеера, закачать этот сегмент у других пиров, положить его в P2P Cache и, когда он понадобится, отдать его плееру.
Можно спросить: как вы шейпите трафик и определяете bandwidth? Потому что, чем жаднее Peer Pool, тем больше канала мы отнимем от канала пользователя.
То, что ребята использовали на момент моего ухода из Streamroot, было вариацией классического алгоритма Token Bucket. Мы к этому тоже не сразу пришли.
Token Bucket – это штука, которая позволяет очень классно зашейпить трафик, чтобы периодически мы могли через ограничения в 8 Mbps пропихнуть 12 Mbps. Потому что здесь и сейчас мы видим, что есть сегмент, который нам нужен, этот сегмент есть у всего Peer Pool, и очевидно хочется его побыстрее запросить.
Все загруженные сегменты независимо от того, скачаны они были через CDN P2P-модулем или у других пиров через WebRTC, попадут в хранилище P2P Cache – простое memory-хранилище, простая мапа, где есть координаты, id сегмента. По этому ключу нам доступен Uint8Array, обычный байтовый массив, олицетворяющий собой сегмент. Тут тоже очень много классных нюансов, из той серии практического электричества, когда мы только начинали работать, все хорошо, но рано или поздно тебе попадется клиент, который все сломает.
Например, был такой клиент – одна национальная медиагруппа одной не очень маленькой страны. Их CDN под пиковой нагрузкой очень любил вместо 404 или любого другого кода ошибки давать 200. Но, когда ты смотришь, что тебе отдали, там буквально 100 байт и сообщение типа «я не смог». Но мы-то думаем, это хороший сегмент, потому что это было 200. Этот на самом деле нифига не валидный сегмент попадает в P2P Cache, через P2P Pool расползается по сегментам. Мы потравили кэши всему Peer Pool, по большому счету, практически всем пользователям.
Такого практического электричества очень много, поэтому P2P Cache валидирует данные, проверяет чексуммы сегмента, если подозрительно маленький, то он просто не кладет его в P2P Cache, это значение опять же конфигурируемо.
Очень важный момент – ABR-алгоритмы плееров. Если мы из P2P Cache начнем мгновенно по запросу плеера давать сегменты плееру, то скорее всего ABR-алгоритм сойдет с ума, особенно тот тип ABR-алгоритма, который основан на оценке пропускной способности канала пользователя: он начнет считать, что канал огнище, начнет закачивать в 4K.
К чему это может привести? У пользователя начнутся пресловутые буферизации, от которых мы хотели уйти. Поэтому отдачу сегментов из P2P Cache в плеер нужно контролировать. P2P-модуль это контролирует, он вводит искусственную задержку на основе собственной оценки имеющейся пропускной способности пользователя. То есть для плеера оценка bandwidth не пострадает, и его ABR-алгоритм не сойдет с ума.
Очевидно, если у нас есть memory-хранилище, оно не бесконечное, неплохо бы там сделать garbage collection. И этим P2P Cache тоже занимается. Старые сегменты, которые находятся далеко от текущей позиции воспроизведения, съедаются.
Этой технологии примерно 7 лет, мы пришли к тому, что очень сложно выработать какое-то универсальное решение, которое устраивало бы всех наших потенциальных клиентов и все кейсы доставки контента. У нас есть два направления: live streaming и VOD. И поведение P2P-модуля, поведение алгоритмов – это подстройка функции оптимизации, она кардинально разная для этих двух кейсов. У компании есть большой отдел аналитиков, происходят постоянные A/B-тесты в попытке найти оптимальное сочетание множества параметров под конкретные клиенты и конкретные кейсы.
Поскольку технология клиентская, критично ни в коем случае не деградировать quality of experience для пользователей и quality of service для наших клиентов, то есть время старта, среднее количество буферизаций, средний битрейт, те метрики, на которые смотрит любая уважающая себя компания в сфере доставки видео. И мы в Streamroot обязаны быть ISO, то есть мы ни в коем случае не имеем права ухудшать эти метрики, мы можем их улучшать, это и делаем. Поэтому мы очень бережно подходим к процессу деплоя, все фичи загружаются выключенными, то есть концепция Feature flags нас тут спасает, позволяет избегать ситуации, когда мы выкладываем потенциально какое-то улучшение, но даже не убедились в том, что в выключенном виде оно ничего не ломает. Потом нам аналитики говорят, что мы все поломали, надо что-то делать, Feature flags — ваше спасение, ну и хороший отдел аналитики.
Недостатки, ограничения
Когда эта технология не сработает?
Чаще всего, если мы говорим о VOD, эта штука не работает на непопулярных тайтлах. То есть если вы зайдете на Иви и выберете 20-й эпизод очень непопулярного бразильского сериала, скорее всего, наберется максимум 5 человек по всей стране, кто будет смотреть этот сериал в данный момент. Соответственно, Peer Pool будет маленький, и эффективного обмена данными не получится.
В случае с лайвом проблем с пользователями нет, есть обратная проблема: тренд на уменьшение задержки от студии до пользователя, очень актуально для спортивных трансляций. Это тренд современного мира: нам не очень нравится, когда наш сосед, смотрящий футбольный матч по телевизору, уже орет «гол», но мы через стенку смотрим это все на ноуте и понимаем, что нам еще 15 секунд ждать. Это классический пример с современными видеоплеерами на нашем рынке трансляций.
Есть отдельный сегмент проблем, называемый «персонифицированные сегменты». Это когда формально все пользователи получают один поток, но сегменты внутри этого потока для каждого пользователя отличаются. То есть, например, если была бы какая-то рекламная интеграция, часть зрителей смотрела бы рекламу конференций JUG Ru Group, а кто-то — рекламу фастфуда. Будет очень не здорово, если мы смешаем эти две когорты пользователей, у них будут чередоваться сегменты рекламы новой конференции и где-то там отрывки про фастфуд.
Поскольку для самой технологии важна пропускная способность на отдачу, то есть upload bandwidth у каждого клиента, это в принципе не работает с ADSL. Не смейтесь, в России это почти мертвая технология, но на Западе, особенно в Европе, ADSL живет и здравствует, и встретить канал на отдачу всего лишь в 256 Кб – это стандартная практика.
А это хорошо работает?
Насколько хорошо это работает на примере клиентов, которые когда-то были у Streamroot, на реальных цифрах. Вот кейс Иви:
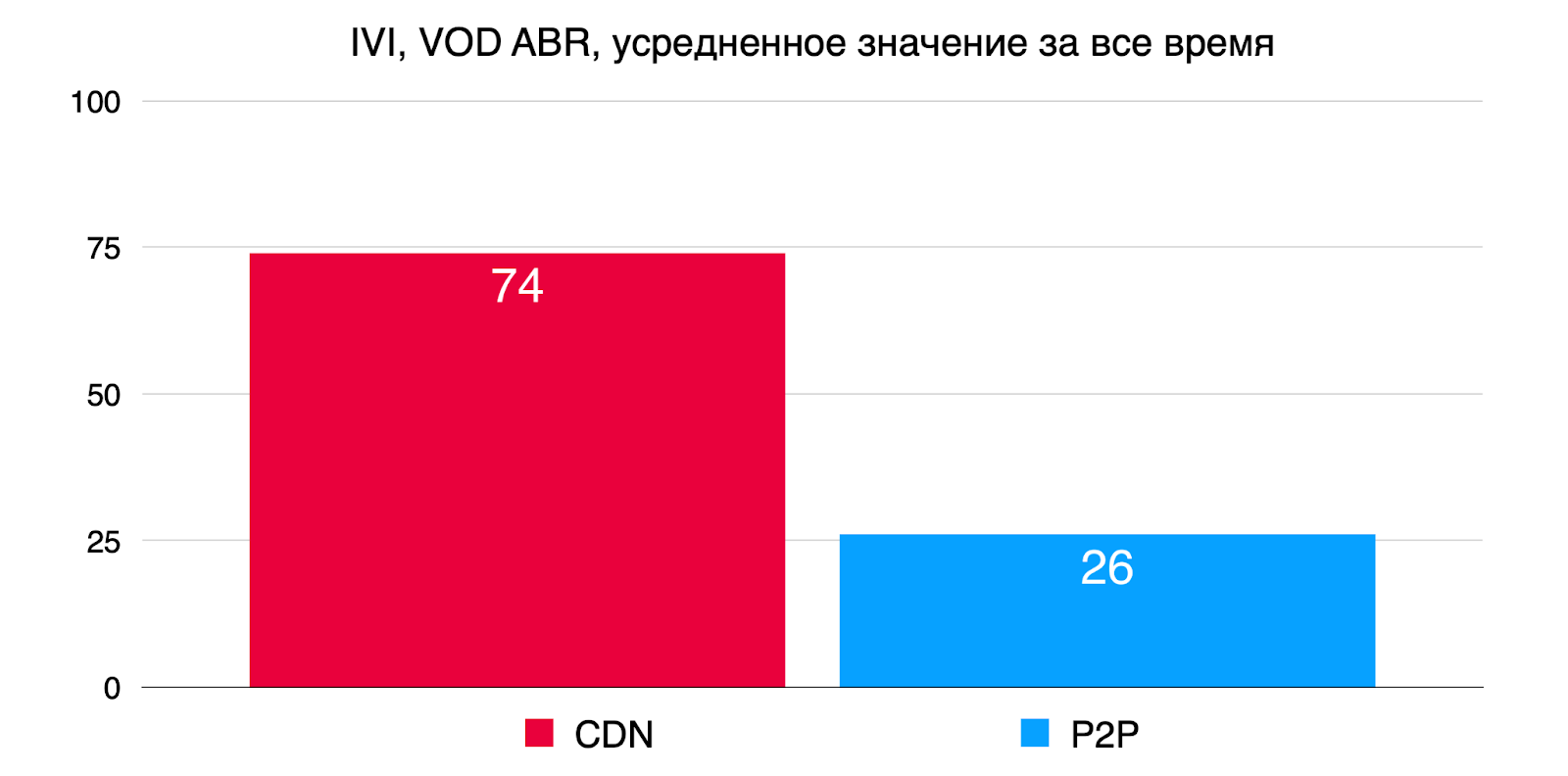
Это VOD-контент, мультибитрейтные потоки, примерно 26% трафика удается завернуть в P2P. Много это или мало? У Иви порядка 60 миллионов уникальных пользователей в месяц. Это на самом деле очень много, особенно с ростом сезонности нагрузки. Чем ближе Новый год, тем больше потребление трафика, и P2P здесь очень выручает.
А вот другой кейс, не буду называть этого клиента, это классический «смотреть онлайн без регистрации и смс». Вы все эти плееры видели, как правило, там нет адаптивного качества, вы выбираете какое-то качество, страница перезагружается. Так называемые single bitrate-манифесты:

Здесь эффективность P2P совсем другая, поскольку все сегменты внутри манифеста абсолютно одинаковые, там одно качество. Порядка 80% данных в пике уходило через P2P, минуя CDN.
Эта технология просто сияет в любых массовых лайв-трансляциях. Собственно, Французская национальная медиагруппа TF1 с помощью этой технологии транслировала чемпионат мира по футболу 2018 года.

Ссылка на конкретные цифры.
70% лайв-трафика ушло через P2P. Это на самом деле много, и вот почему. Если у вас начинаются проблемы с CDN в лайве, ваши пользователи одновременно обновляют страницу. Если у вас 5 миллионов пользователей одновременно обновляют страницу, у вас ляжет фронтенд, или бэкенд, или станет очень плохо CRM — что-то да сломается.
Выводы
Традиционные CDN как продукт становятся commodity (как, например, энергоносители).
Клиенты на CDN-рынке — это клиенты на рынке энергоносителей: между газом или электричеством от вендора А, Б или В особой разницы нет, пока лампочка горит, клиент выбирает самый дешевый.
CDN как технология масштабируется экстенсивно, и это масштабирование не решает проблем, а лишь оттягивает (откладывает?) их наступление.
Децентрализация CDN через WebRTC дает ярко выраженное конкурентное преимущество, позволяя обойти ограничения CDN без существенных вложений в инфраструктуру.
Спасибо за внимание.
Если вы тоже работаете с видеотехнологиями и стримингом, обратите внимание: новая конференция VideoTech стартует уже послезавтра, 20 октября. Если вас заинтересовал этот доклад, наверняка и на ней найдётся интересное для вас.
Комментарии (4)

sacai
18.10.2022 18:29+1открываю демку, смотрю webtc-internals, вижу только data channels. RTP медиатрафика не вижу (но вижу HLS).
т.е. речь не идет о live-трансляциях с минимальной задержкой?

jakor
19.10.2022 10:29+1т.е. суть технологии - вместо того, чтобы платить CDN за траффик, используем других клиентов как микро CDN забесплатно? и кста - там очепятка - CastLabs название компании, а не CatsLABS

V1tol
Тут есть два выхода - взять ffmpeg/gstreamer/что-нибудь ещё. Или использовать AVAssetResourceLoader, хотя не уверен что подойдёт.