

Привет! Меня зовут Андрей Барболин, я Senior Software Engineer в команде Order Management System. Сегодня я расскажу вам, как мы сделали шардированный кэш и под стресс-тестами добились 30 миллионов операций в секунду, а также про первую open source библиотеку от AliExpress Россия.
Вводные
Необходимо держать в кэше 200-300GB данных;
Целевая нагрузка на сервис 30 миллионов key values в секунду.
И это профиль нагрузки только одного из сервисов. Также бывают периоды распродаж, когда нагрузка может увеличиваться в несколько раз. Поэтому нам нужно уметь горизонтально масштабировать инстансы кэшей.
Классическое решение этой проблемы — шардирование на клиенте. Что будет стоять в плане кэша на конечной машине, уже не так важно. Это может быть Redis, Memcached или любое другое решение.
Подбор решения
Для того чтобы выбрать конкретное решение по кэшированию, нужно знать как минимум предполагаемую нагрузку и объем данных. Если у вас нет тысяч RPS, а объем данных небольшой, стоит выбрать зрелое решение с большим комьюнити и низким уровнем входа. На данный момент это Redis. Тем более, его можно рассматривать как этакий швейцарский нож, ведь это уже не просто кэш. Даже если вам не нужна его богатая функциональность прямо сейчас, он дает пространство для дальнейшего развития проекта.
Дальше нужно смотреть на конкретную задачу. Нам в AliExpress необходимо держать в кэше достаточно много данных и использовать CPU по максимуму. Redis однопоточный — многопоточку завезли только в 6-й версии в мае 2020, да и то только на сетевой I/O, то есть на чтение из сокетов и запись в них. Стоит посмотреть в сторону других решений. Энтузиасты форкнули Redis, сделали его многопоточным, и так появился KeyDb. Еще есть Dragonfly, который активно развивается и ругает Redis в своем блоге за слабый фундамент на высоких нагрузках. Тут стоит подумать, насколько вы готовы использовать менее зрелые технологии в продакшене: возможно, придется постоянно держать руку на пульсе и отслеживать, что пофиксили и завезли в новых релизах.
Мы выбрали Memcached, потому что он проверен годами, максимально предсказуем и надежен. Это топор, который просто кэш, и всё. К тому же, даже новомодный Dragonfly по их же бенчмаркам не смог полностью обойти Memcached:

Из-за своей простоты Memcached:
Лучше использует оперативную память;
Изначально использует многопоточный подход, который позволяет выжать максимум из одной машины.
Это накладывает определенные ограничения на использование Memcached:
250 bytes на ключ. Это никак не правится в настройках. Чтобы это изменить, нужно будет пересобирать Memcached;
1MB на значение. Эта величина настраивается;
Eviction policy только LRU (Last recently used).
Ограничения обоснованы изначальной архитектурой Memcached с slub-классами и LRU. Подробнее можно почитать в их Wiki.
Шардирование на клиенте
Итак, мы взяли максимально простой инструмент для кэша. Пора научиться его готовить и шардировать. Мы можем взять уже готовое решение от Facebook, одного из самых известных пользователей Memcached. Они написали к нему mc router, у которого широкая функциональность — на нем можно сделать вообще любой роутинг, какой пожелаешь. Но все-таки это еще один черный ящик на пути к распределенному кэшу. А нам нужен максимально простой, управляемый и тонкий клиент.
На входе используем consistent hashing aka HashRing. Это подход позволит нам добавлять и удалять инстансы Memcached в реальном времени без редеплоя сервиса, который его использует.
Представим, что A, B, C — инстансы Memcached. Мы можем высчитать их расположение на круге, например, вычислением hash по IP-адресам подов. Дальше мы вычисляем hash по ключу, находим ближайший инстанс по часовой стрелке (или против) и отправляем запрос на него:

Если один из подов откажет, мы должны убрать его из HashRing. Но теперь у нас есть перекос по нагрузке — все значения, которые должны были идти на инстанс B, теперь уходят на инстанс C:

Нам нужно, чтобы нагрузка распределилась максимально равномерно между инстансами A и C. Для этого необходимо добавить на круг «виртуальные» инстансы, которые будут ассоциированы с физическими. Таким образом, если один из инстансов откажет, вся нагрузка должна будет равномерно распределиться между остальными инстансами:

Такой подход позволит нам делать запросы на несколько инстансов одновременно, что Redis из коробки не умеет:
Redis Cluster supports multiple key operations as long as all of the keys involved in a single command execution (or whole transaction, or Lua script execution) belong to the same hash slot. The user can force multiple keys to be part of the same hash slot by using a feature called hash tags.
То есть придется поупражняться, чтобы запустить команду на несколько ключей и не получить:
(error) ERR CROSSSLOT Keys in request don't hash to the same slotHash tags используются для объединения ключей по некоему тэгу, по которому будет считаться hash, чтобы отправить ключи в определенный hash slot (пример из документации):
MSET {user:1000}.name Angela {user:1000}.surname WhiteВозможно, сработает пайплайнинг нескольких команд get/set, но я сходу не нашел примеров без hash tag’ов. Здесь говорится, что:
Redis Enterprise has a few workarounds for simple commands, notably MGET and MSET.
Примеров или документации я найти не смог. Но даже если эти обходные пути существуют, Redis Enterprise все еще стоит денюжку.
Если знаете примеры запросов на несколько ключей в несколько инстансов Redis, напишите в комментарии.
Немного кода по HashRing
С помощью бинарного поиска добиваемся O(log(n)):
private TNode GetNodeInternal(string key)
{
var keyHash = GetHash(key);
var index = Array.BinarySearch(_sortedNodeHashKeys, keyHash);
if (index < 0) // no exact match
{
// If the Array does not contain the specified value, the method returns a negative integer.
// You can apply the bitwise complement operator to the negative result to produce an index.
// If this index is one greater than the upper bound of the array, there are no elements larger than value in the array.
// Otherwise, it is the index of the first element that is larger than value.
index = ~index;
if (index >= _sortedNodeHashKeys.Length)
{
index = 0;
}
}
var hashNodeKey = _sortedNodeHashKeys[index];
return _hashToNodeMap[hashNodeKey];
}Выполняем поиск нод параллельно:
public IDictionary<TNode, ConcurrentBag<string>> GetNodes(IEnumerable<string> keys)
{
var result = new ConcurrentDictionary<TNode, ConcurrentBag<string>>(Comparer);
try
{
_locker.EnterReadLock();
if (_sortedNodeHashKeys == null || _sortedNodeHashKeys.Length == 0)
{
return result;
}
Parallel.ForEach(keys, new ParallelOptions { MaxDegreeOfParallelism = 16 },key =>
{
var node = GetNodeInternal(key);
var bag = result.GetOrAdd(node, (Func<TNode, ConcurrentBag<string>>) ValueFactory);
bag.Add(key);
});
}
finally
{
_locker.ExitReadLock();
}
return result;
}Бенчмарки при 256 виртуальных нодах на одну физическую:
BenchmarkDotNet=v0.13.1, OS=macOS Monterey 12.3.1 (21E258)
[Darwin 21.4.0]
Apple M1, 1 CPU, 8 logical and 8 physical cores
.NET SDK=6.0.400
[Host]
: .NET 6.0.8 (6.0.822.36306), Arm64 RyuJIT DefaultJob
: .NET 6.0.8 (6.0.822.36306), Arm64 RyuJITMethod |
KeysNumber |
NodesNumber |
Mean |
Error |
StdDev |
Median |
|---|---|---|---|---|---|---|
GetNodes |
1 |
1 |
5.683 us |
0.5613 us |
1.655 us |
4.692 us |
GetNodes |
1 |
16 |
5.485 us |
0.5255 us |
1.549 us |
4.639 us |
GetNodes |
1 |
32 |
6.239 us |
0.7027 us |
2.072 us |
5.060 us |
GetNodes |
128 |
1 |
33.824 us |
2.7571 us |
8.086 us |
29.377 us |
GetNodes |
128 |
16 |
118.482 us |
7.0747 us |
20.860 us |
114.546 us |
GetNodes |
128 |
32 |
188.920 us |
12.1676 us |
35.877 us |
181.387 us |
GetNodes |
512 |
1 |
73.147 us |
4.7427 us |
13.984 us |
66.924 us |
GetNodes |
512 |
16 |
175.545 us |
10.4275 us |
30.746 us |
168.805 us |
GetNodes |
512 |
32 |
293.666 us |
13.3944 us |
39.494 us |
277.418 us |
GetNodes |
2048 |
1 |
193.951 us |
8.5778 us |
24.749 us |
189.355 us |
GetNodes |
2048 |
16 |
326.530 us |
15.2840 us |
44.825 us |
309.335 us |
GetNodes |
2048 |
32 |
466.940 us |
18.1174 us |
52.849 us |
456.591 us |
GetNodes |
5000 |
1 |
427.750 us |
16.5527 us |
48.806 us |
420.915 us |
GetNodes |
5000 |
16 |
574.372 us |
25.4257 us |
74.569 us |
564.302 us |
GetNodes |
5000 |
32 |
688.616 us |
26.3884 us |
76.558 us |
663.938 us |
GetNodes |
10000 |
1 |
814.684 us |
27.5884 us |
80.039 us |
807.244 us |
GetNodes |
10000 |
16 |
1,020.214 us |
36.8499 us |
108.074 us |
1,021.344 us |
GetNodes |
10000 |
32 |
1,269.259 us |
35.2069 us |
103.256 us |
1,288.021 us |
GetNodes |
20000 |
1 |
1,617.165 us |
44.5917 us |
131.480 us |
1,629.595 us |
GetNodes |
20000 |
16 |
1,899.443 us |
63.8206 us |
188.176 us |
1,828.317 us |
GetNodes |
20000 |
32 |
2,059.760 us |
60.0584 us |
174.240 us |
2,015.047 us |
1 us : 1 Microsecond (0.000001 sec)
Изначально в качестве hash-алгоритма использовался MurMurHash3. Затем мы перешли на xxHash, что дало четырехкратный выигрыш в скорости. У xxHash есть реализация на C# без дополнительных аллокаций. В своей библиотеке мы тоже встали на путь zero allocation и активно используем ArrayPool и Span'ы. Но нам еще есть над чем поработать.
Почитать про Array Pool.
Почитать и посмотреть про Span'ы.
Распределение нод на HashRing
Добиться идеального распределения нод невозможно в силу самого подхода. Мы можем добавить достаточное количество виртуальных нод, чтобы разница находилась в пределах 1–2% по нагрузке.
Нагрузочное тестирование при 64 виртуальных нодах показало до 5% разницы в нагрузке. Проводим тесты в консоли и получаем оптимальный результат при 256 виртуальных нодах со средним отклонением в 1–2% между самой нагруженной и минимально нагруженной нодами:
var keysNumber = 2000000;
var nodesNumber = new[] {1, 2, 4, 8, 16, 32};
var virtualNodesNumber = new[] {16, 32, 64, 128, 256, 512};
foreach (var nodeNumber in nodesNumber)
{
foreach (var virtualNodeNumber in virtualNodesNumber)
{
var hashRing = new HashRing<Pod>(new HashCalculator(), virtualNodeNumber);
var pods = Enumerable.Range(0, nodeNumber).Select(n => new Pod
{
IpAddress = Guid.NewGuid().ToString()
});
hashRing.AddNodes(pods);
var keys = Enumerable.Range(0, keysNumber).Select(n => Guid.NewGuid().ToString()).ToArray();
var nodes = hashRing.GetNodes(keys);
Console.WriteLine($"Nodes number: {nodeNumber}, Virtual nodes number: {virtualNodeNumber}");
var percentages = new List<decimal>();
foreach (var node in nodes)
{
percentages.Add((decimal) node.Value.Count / keysNumber);
}
var max = percentages.Max();
var min = percentages.Min();
var diff = max - min;
Console.WriteLine($"Max: {max}, Min: {min}, Diff: {diff}");
}
}Headless service
Возникает вопрос, как нам в реальном времени получать все активные инстансы Memcached. Мы деплоимся в Kubernetes и можем воспользоваться теми базовыми решениями, которые он предлагает. Подробнее можно почитать тут.

IP-адрес для сервиса не аллоцируется. Используя селекторы, сервис знает про все поды, которые задеплоены под ним. Сделав DNS lookup на сервис, мы можем узнать адреса всех инстансов Memcached:
// HeadlessServiceAddress: my-memcached-headless.<namespace>.svc.cluster.local
IPAddress[] ipAddresses = Dns.GetHostAddresses(_config.HeadlessServiceAddress);
return ipAddresses.Select(i => new Pod
{
IpAddress = i.ToString()
});Socket pool
Ни один похожий клиент не может обойтись без пулинга подключений. Концепция тоже базовая — нам нужно открыть n подключений в зависимости от нагрузки и переиспользовать их:

Делаем простую реализацию через семафор и ConcurrentStack:
private readonly ConcurrentStack<PooledSocket> _availableSockets;
...
public SocketPool(MemcachedConfiguration.SocketPoolConfiguration config, ILogger logger)
{
...
_semaphore = new SemaphoreSlim(_config.MaxPoolSize, _config.MaxPoolSize);
_availableSockets = new ConcurrentStack<PooledSocket>();
}
...
if (!await _semaphore.WaitAsync(_config.SocketPoolingTimeout, token))
{
_logger.LogWarning("Pool is run out of sockets");
return result;
}
// Get available socket
_availableSockets.TryPop(out var pooledSocket)
// or create one
...Поддержание актуального состояния
Для этого запускается фоновый процесс, который занимается обслуживанием HashRing и Socket Pool. Раз в n секунд этот процесс запрашивает все доступные инстансы через headless service, добавляет новые ноды в HashRing и удаляет те, что пропали.
Другой процесс отвечает за опрос текущих инстансов на предмет того, живы ли они, и как только инстанс перестает отвечать, помечает его как умерший. После этого инстанс выбрасывается из HashRing до момента, когда он снова оживет.
Еще один процесс постепенно уничтожает по n сокетов из socket pool’a, чтобы иметь возможность после спада нагрузки убрать лишние.
Итоговая схема
Приходит запрос с n key values. Вычисляем по всем ключам hash и по ним выбираем ноды из HashRing
Для каждой ноды создается свой Socket Pool, если он еще не создан. Если создан, берем уже существующий
В каждом пуле берем доступный сокет из уже созданных либо создаем новый, если пул не переполнен
В каждый сокет пишем пайплайном несколько команд get или set для Memcached. Протокол Memcached позволяет сделать несколько операций за раз только таким образом
Вычитываем последовательно из сокета ответ от Memcached и отдаем на клиент

Протокол общения с Memcached и наша библиотека
Если посмотреть доступные библиотеки под .NET Core, становится немного грустно. Есть портированная с .NET Framework на .NET Core библиотека с очень старым стилем кодирования и кучей ненужных абстракций. Но если нужно сразу начать использовать Memcached, вполне можно ею воспользоваться.
Мы же взяли ее за основу, чтобы не писать весь протокол общения с нуля. Затюнили ее под динамическое изменение количества инстансов Memcached, что-то переписали и оптимизировали. Если хочется разобраться с нуля, то вам сюда: Memcached binary protocol.
Мы выкатили библиотеку в open source. Ее можно настраивать как через headless service, так и указав напрямую IP-адреса Memcached. То есть библиотека умеет работать с любым количеством инстансов.
Профили нагрузки
Ставим один инстанс Memcached и нагружаем его на SET. Ключ и значение — гуиды, то есть объем данных в несколько байт. Прогон в 21.5k RPS на каждый из кластеров (у нас их три), общая нагрузка примерно 65k RPS, 1 ключ-значение на запрос.
На уровне Memcached видим ровные графики по ресурсам — занимаем меньше 1 CPU. Смотрим графики на одном из кластеров:
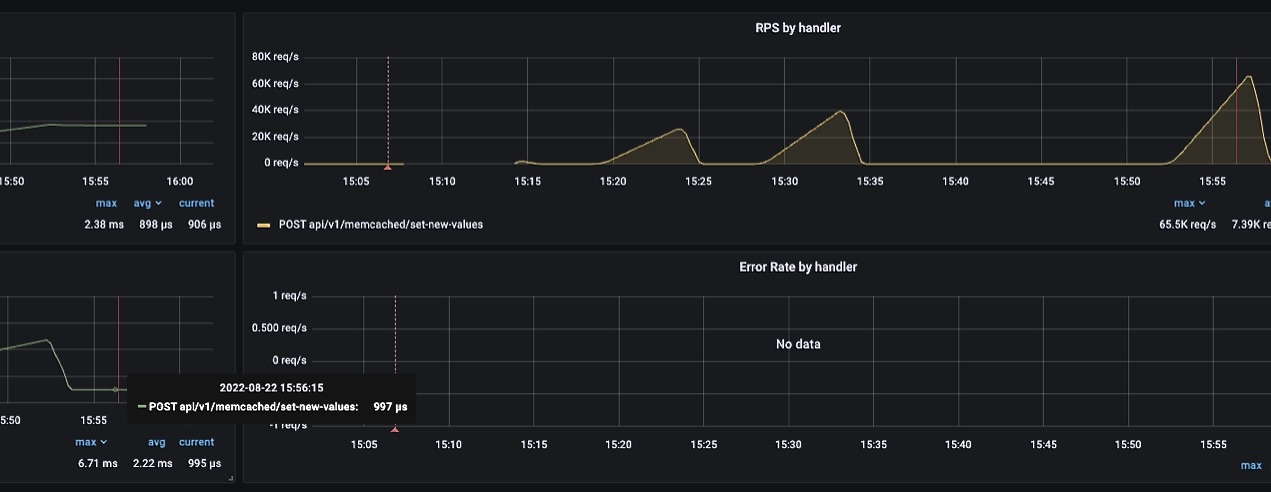

Берем 20 ключей на запрос, то есть нагрузка на Memcached вырастает в 20 раз. На инстанс Memcached приходится около 18k RPS * 20 key values = 360k операций SET в секунду до того момента, как начинает расти RT. На графиках видим, что начинаем использовать в разы больше CPU:


Увеличиваем количество ключей до 50. На инстанс Memcached приходится около 10k RPS * 50 key values = 500k операций SET в секунду до того момента, как начинает расти RT. Потребление CPU растет незначительно, но можем наблюдать, что RT выросло гораздо сильнее по сравнению со случаем в 20 key values:
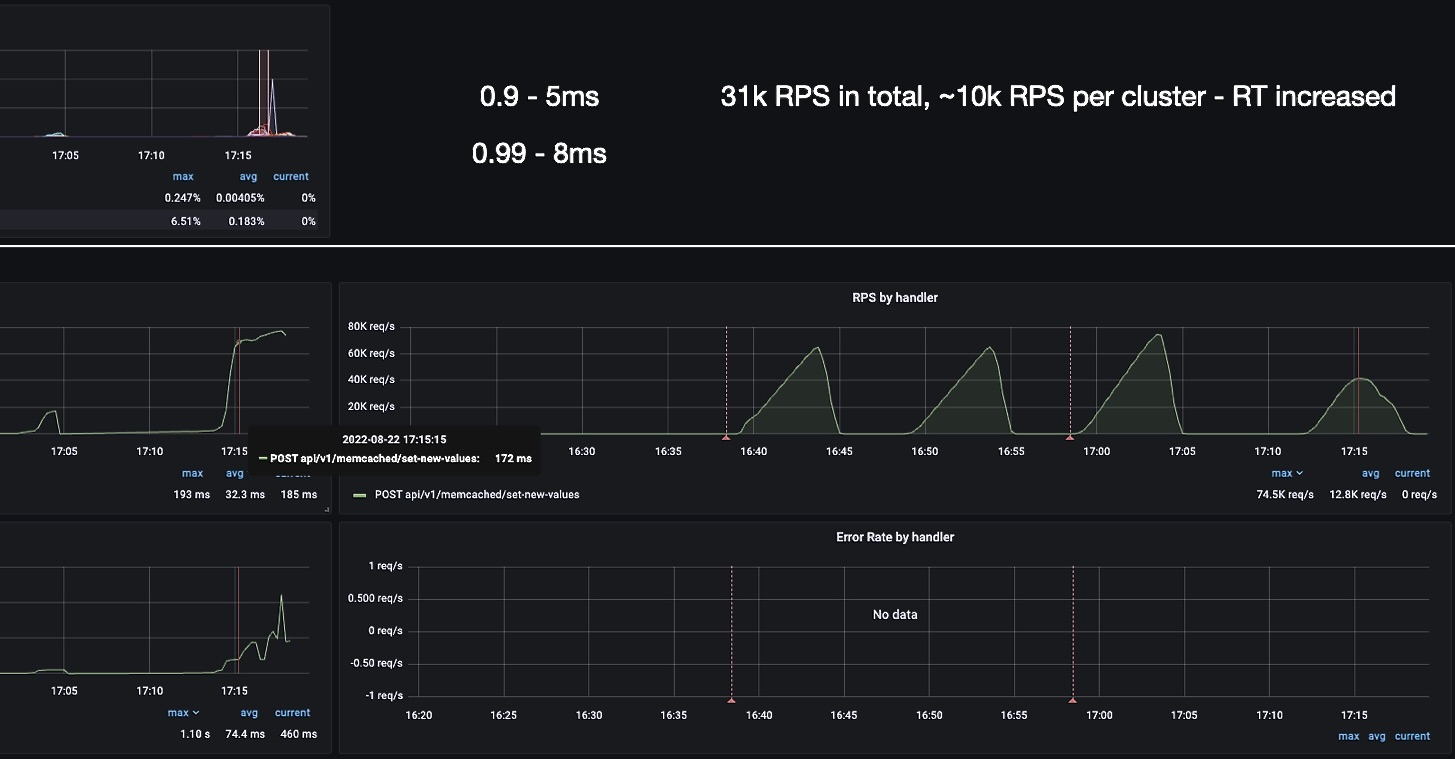

Приходим к выводу, что количество операций в пайплайне команды однозначно влияет и на CPU, и на RT. Лучше придерживаться адекватных цифр и в одной команде посылать ~10 операций на Memcached. Иначе время отклика начнет расти в геометрической прогрессии из-за дополнительного времени, которое требуется Memcached для сброса данных в сокет.
Также стоит заметить, что здесь мы попадаем в один и тот же slab-класс, так как размер значений всегда одинаковый. Внутри Memcached каждый slab-класс обслуживает только один поток, поэтому здесь мы можем упереться в ограничение. Так что ~10 операций на команду — это базовая рекомендация, которую нужно проверять именно на вашем профиле нагрузки.
А теперь берем 8 инстансов Memcached в каждом кластере, 100 key values на запрос и наблюдаем, что легко держим нагрузку, которая равномерно распределяется между инстансами. На каждый инстанс приходится примерно по 12–13 key values на запрос:

Помещаемся в 1–2 CPU на инстанс Memcached:

Рекомендуем брать по 10–20 операций SET на команду и 2 CPU на инстанс Memcached. При этом пропускная способность операций GET может быть примерно в два раза больше, чем у операций SET, так как они легче. Но все равно лучше ограничивать количество операций в пайплайне, чтобы меньше грузить Memcached и не увеличивать время отклика. Если текущее количество инстансов не вывозит нагрузку, добавляем еще инстансов.
Профиль нагрузки одного из сервисов. 6 инстансов Memcached, ожидаем прирост нагрузки. Сейчас имеем около 2k RPS в среднем по 15–20 key values на запрос:

На стороне Memcached получаем 40k RPS:

Количество команд = RPS сервиса * количество инстансов Memcached. RT составляет 0,5ms:
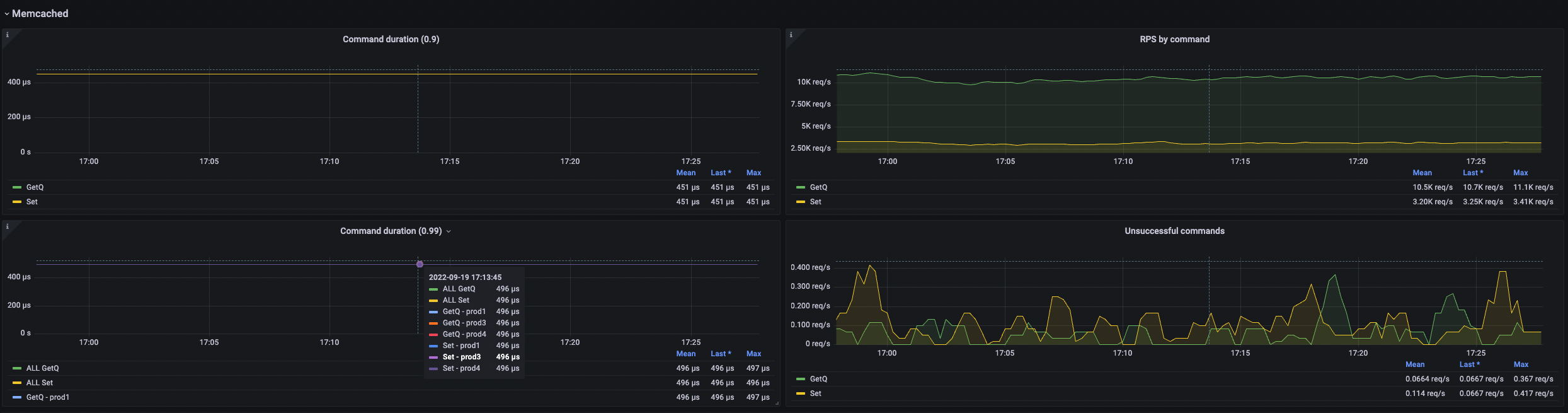
Большая часть метрик экспортируется из Memcached в Прометей. Данные с последней картинки пишет наша клиентская библиотека.
Самый нагруженный вариант. Мы взяли 40 инстансов Memcached с 1 CPU и добили нагрузку до 30 миллионов key values в секунду. 2,5KB каждое значение, 3 кластера, получается ~24GB/s сетевого трафика на один кластер и 72GB/s всего:

При самой высокой нагрузке держимся в районе 1ms на одну операцию в Memcached:

Тут мы разбили каждый входящий запрос на пачки. Нам нужно за один запрос получить одновременно 3000 key values. Мы не можем запихнуть всё сразу в один пайплайн — нужно держать примерно 10–20 операций на пайплайн. Без разбития на каждую ноду приходилось бы 3000 / 40 = 75 key values. Разбиваем их примерно на 4 разные части и отправляем параллельно, чтобы избежать роста RT.
Настройка Memcached
При запуске стоит обратить внимание на параметры. Полезно по ним пройтись и посмотреть, что из этого вам понадобится подтюнить. Как минимум, проверьте следующие параметры:
# MaxMemoryLimit, this should be less than the resources.limits.memory, or memcached will crash. Default is 64MB
- -m 8192
# Specify the maximum number of simultaneous connections to the memcached service. The default is 1024.
- -c 20000Память сразу стоит поднять — редко можно влезть в дефолтное значение. А количество подключений надо рассчитывать так, чтобы хватило на редеплой сервисов, которые используют Memcached. Дело в том, что в момент редеплоя количество подключений подскочит.
Из неочевидного есть, например, такой параметр:
- -R 40
# The command-line parameter -R is in charge of the maximum number of requests per
# network IO event (default value is 20). The application should adopt its batch
# size according to this parameter. Please note that the requests limit does not
# affect multi-key reads, or the number of keys per get request.И если неаккуратно пользоваться пайплайнингом операций, то можно нарваться на такую вот неприятную стату:
STAT conn_yields 126672162
Number of times any connection yielded to another due to hitting the -R limitИтог
Имеем горизонтально масштабируемый кэш, который можем развернуть для любого сервиса
Умеем динамически добавлять и убирать инстансы Memcached
Путем нагрузочных тестов выведено оптимальное количество ресурсов на один инстанс: 2.5 CPU и 8GB RAM. Больше CPU брать нет смысла из-за специфики работы LRU — лучше развернуть дополнительный инстанс. Как только текущее количество инстансов перестает справляться с нагрузкой, накидываем еще. Выбор 8GB RAM продиктован тем, что часть данных не жалко потерять
0.5 миллисекунды RT из сервиса в Memcached при нагрузке с умеренным количеством ключей на команду;
Выкатили библиотеку в open source.
Комментарии (17)


Andriuha077
20.10.2022 11:55+1Кто-то готов смириться со сломанным поиском и всеми вот этими ценами, но опция "вернуть нормальный дизайн (переключив на стилевые таблицы оригинала по адресу ком)", которая включалась бы в личном кабинете, как первый шаг к поправке изумительных подвижек, ну вот просто необходима.

Какие провалы?


moooV
21.10.2022 11:42Сделайте возможность изменить страну профиля. Давно живу не в РФ, но безальтернативно перекидывает на русский сайт хотя хочу пользоваться глобальным куда надо заходить каждый раз методом тыка через зарытые (оставшиеся) внутри ссылки. На русском сайте, само собой, доступны только страны СНГ для выбора. ????♂️
Причем, как понимаю, он определяет страну не по айпишнику а по первому когда-то давно зарегистрированному адресу, который уже даже удален из профиля давно.
А что по русскому сайту — история покупок тоже не подтягивается с глобального. Мега полезен, да.
QuAzI
Отличная штука... это из-за него приходится раз надцать страницу обновлять, потому что в корзине валится примерно всё?
А когда исправят принудительный редирект на RU-домен для тех, кто в RU не живёт, когда перестанут портить настройки валюты и страны доставки и зачем от людей спрятали настройки страны доставки и валюты, особенно пока не залогинен (особенно с учётом того что с сохранением сессий и настроек всегда была беда)? Поиск по валюте или хотя бы сортировка по алфавиту или популярности - вообще никак?
А когда поиск по продуктам починят? А когда при указанной стране РБ перестанут первыми в поиске отбиваться шараги, которые в РБ не доставляют примерно НИКОГДА?
Почему вообще дизайн отличается от стиля оф.сайта, по ощущениям выглядит будто фишинг.
otezvikentiy
Смиритесь - это новая платформа для СНГ примерно так. Сейчас идет активная разработка и то что есть ряд багов - это норма для it-проектов на время активной разработки. Подождите - всё наладится. )))
QuAzI
Идёт активное разваливание которое вообще никак в современную разработку не вписывается. За один только принудительный форвард на RU при разваленном сайте нужно кому-то по рукам дать хорошенько. Раньше хотя бы на глобальный сайт можно было свичнуться, теперь НЕТ. Так же как в нормальных компаниях принято нерабочие версии, в которых клиент не может найти и купить нужный товар, откатывать, потому что это сулит огромными убытками и сваливанием клиентов.
И нет, не наладится, проблемы с локализованным стором были уже давно, даже на всяких пикабу куча статей в духе "как извратиться чтобы хоть как-то али работало", "как прикрутить форвард на глобал сайт".
Сейчас это выглядит как намеренное вредительство. Особенно мутки со страной доставки, языком и валютой.
anatolix
Смотрите, вот есть такие компании как Shein и Farfetch, которые в Россию теперь не доставляют и русские карты не берут, но зато у них нет никакого редиректа на ru сайт, и в них нет никакого "активного разваливания", если вы хотите пользуйтесь ими.
А вообще народ в офисе ночевал, чтобы быстро переписать платежи, чтобы они вообще ходили, научились переводить деньги в китай без доллара в цепочке, но конечно про это иначе как "разваливание" в интернетах не напишут
QuAzI
Когда будет косячить Shein, будем говорить о их косяках и как делать НЕ НАДО НИКОГДА. Все мы рано или поздно ночуем в офисе, но есть же общие правила хотя бы не делать ещё хуже, тестирование, открытие новой фичи только для части аудитории... Редирект - это не про код же. Вы доблестно воевали с проблемами, которые других вообще не должны были касаться, потому что не было проблем оплатить через доллар.
tandzan
Русский Али для меня умер с этим новым дизайном.
anatolix
А что именно не нравится? Просто в нем конверсии лучше, global его потихоньку копирует даже.
rombell
Мне кажется, что Али вообще не принимает обратную связь по дизайну. Что головная контора, что российская. Или же у них какая-то крайне специфическая тестовая фокус-группа, или же решения принимаются без учёта мнения потребителей.
Новый дизайн головного сайта стал настолько неудобным, что руки опускаются. Но российский сайт смог переплюнуть.
Обнаружив, что по старым заказам невозможно получить информацию, а она бывает иногда нужна, я начал сохранять снэпшоты. И вот в этом году с российского сайта возможность перейти к снэпшоту убрали. Пока ещё можно с приседаниями и бубном попасть на головной, а там сохранилась незаметная картинка-ссылка поверх фотографии. Однако, опасаюсь, вскоре эту возможность тоже срежут.
Это уже не говоря про отключение прочего достаточно удобного функционала на странице заказа. Аляповатый минимализм, не могу по-другому назвать.
anatolix
А вы можете как ниубдь написать, что именно неудобно?
rombell
1) Вырвиглазный дизайн, в котором теряется информация. По счастью, информации почти нет.
2) В заказах — удалили номер, сумму заказа. Убрали фильтр заказов. Убрали поиск заказов. Убрали состав заказа.
На-я?По счастью, ещё можно перейти на глобал, чтобы нормально работать с заказами. К сожалению, на глобал заказы тоже стали хуже — но старых скринов не сохранено.3) В заказах — исчез финансовый блок, или я не могу его найти. Где отображались все эти коины и промо, применённые к заказу. Сейчас вижу только стоимость доставки.
4) В заказах — раньше указывалась предельная дата доставки. Теперь — только начальная и The system will automatically confirm receipt after 65 days. Это важно для отслеживания, пора ли уже подавать претензию. Теперь для всех заказов надо вычислять самому.
5) В заказах — из заказа пропала ссылка на трекинг. Надо возвращаться в список и только оттуда есть трекинг.
6) В заказах — из заказа пропала ссылка на Snapshot.
7) В заказах — мониторы стали шире, поэтому давайте добавим больше фигни по краям, а всю существенную информацию вытянем в столбик. Так? Зачем нам горизонтальный дизайн на мониторах? На глобале тоже порезали информацию, было же несколько вкладок и куча всего, теперь одна страница. Но хоть читать можно на одном листе:
с большим уменьшением
8) В заказах — пропала информация об адресе и получателе. Я часто надолго езжу, и заказываю товары на свой адрес на своё имя или на имя жены, на второй адрес в другой город на своё имя и на имя родственника, иногда — на адрес и имя знакомых, которым помогаю что-то купить. Раньше я мог видеть, куда какой заказ идёт. Теперь — только угадывать. Особенно если заказал одно и то же в три адреса.
9) В каталоге — исчезла часть фильтров. Причём чем дальше, тем меньше фильтров остаётся.
10) В каталоге — картинки заслоняют информацию. Всё больше картинок, всё меньше описания. Куда делась информация о стоимости доставки? Зачем убрали название магазина? Что за «Реклама» вместо названия магазинов в половине позиций?
11) Какого вообще чёрта сразу перебрасывает на ру-сайт при выборе страны доставки Россия? Чтобы посмотреть нормальную карточку, теперь даже через VPN надо выбирать левые страны
12) Кто вообще решил, что круглый дизайн — это круто? Фотографии занимают тот же размер, но информации на них теперь меньше. Гениально!
13) см.11: на глобале я вижу на одной странице большую часть необходимой информации. На ру мне надо скроллить. Когда я ищу товар, приходится просмотреть до полусотни карточек. И каждую проскроллить.
14) На глобале описание, характеристики, отзывы — разные табы, между которыми можно быстро переключаться. Страница вниз, клик — отзывы, клик — описание. Теперь скроллить и скроллить. Быстрого перехода к описанию нет. Это монитор и компьютер, на мобилах у вас приложение! Зачем тащить дизайн под узкий сенсор на широкий монитор с мышой?!
15) Самая ценная информация в отзывах — additional feedback; зачем убрали фильтр?
Это даже не говоря о том, что кликнуть в нужную точку гораздо быстрее и удобнее, чем выбирать из выпадающего списка.
16) Вот эта плавающая табличка справа, отнимающая кучу места и дико раздражающая. Если я захочу купить эту позицию, я без проблем прыгну вверх и добавлю в корзину. Зачем мне всё время подсовывать это под руку?! Неужели раздражать пользователя — хороший путь к продажам? Я-то, конечно, скрою и этот элемент к чертям.
Извините, надоело перечислять
anatolix
Спасибо за конкретику, давайте договоримся, мы это починим, а вы напишите вторую часть списка которую сейчас лень.
А если серьезно: то как мы это рассмариваем, у AliExpress всегда было 2 дизайна, приложение и сайт. Они были кардинально разные, и почти неть людей которые пользуются тем и тем.
У нас 70% пользователей в мобильном приложении, и в нем стало лучше, метрики улучшились, никто не жалуется на дизайн, etc.
Сейчас по идее сайт надо приводить к тому же дизайну, навернеое мы делаем это излишне аггрессивно, и теряем функциональность, надо восстановить побыстрее
rombell
Извините, но ЗАЧЕМ приводить сайт к дизайну приложения?!
Это совершенно разный UX — тыкать мышой в широкий экран или возить пальцем по узкому. И моторика разная, и задержки разные, и поле взгляда — очевидно же!
Да, лично мне пофиг мобильное приложение с его дизайном, у меня комп есть, на нём гораздо удобнее (было), пожтому я и не жаловался. В мобильное я заходил только за коинами, когда это ещё имело смысл, и эти коины попробовать применить.
Хм, там ещё была акция «на халяву» или как-то так, где я выиграл две ставки за три дня, после чего заказы аннулировали, и вроде как меня забанили. Я пытался выяснить причину — поддержка ссылается на продавцов, продавцы прислали мне скрины, на которых видно, что им заказы закрыла система. После чего я полностью перестал в это ваше приложение заходить.
А вот на сайте закупаюсь (закупался) постоянно. Потому что было удобно.
Зачем делать из так себе сайта поганую копию приложения — уму непостижимо.
Но если вы действительно хотя бы вернёте функциональность и UX к уровню глобального, я уж не мечтаю про то, что было пару лет назад, то
1) вы заслужите искреннюю благодарность всего не-мобильного рунета;
2) вам с удовольствием накидают ещё идей. Сайт-то нужный.
anatolix
Привет. РБ и СНГ вообще в следующем году займемся, мы правда мало времени уделяли СНГ не до этого было.