
АКТУАЛЬНОСТЬ ТЕМЫ
В предыдущем обзоре мы рассмотрели простую линейную регрессию (simple linear regression) - самый простой, стереотипный случай, когда исходные данные подчиняются нормальному закону, имеется сильная линейная корреляционная связь между показателями, отсутствует гетероскедастичность.
В данном обзоре рассмотрим более сложную задачу:
исходные данные не подчиняются нормальному закону;
исходные данные представляют собой временные ряды показателей, т.е. возможно возникновение автокорреляции и ложной корреляции.
Применение пользовательских функций
Как и в предыдущем обзоре, здесь будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub (https://github.com/AANazarov/MyModulePython).
Вот перечень данных функций:
df_detection_values - функция служит для первичной обработки пропусков в DataFrame: визуализирует пропуски на тепловой карте (heatmap) и определяет их количество;
graph_lineplot_sns - функция позволяет построить линейный график средствами seaborn и сохранить график в виде png-файла;
graph_scatterplot_sns - функция позволяет построить точечную диаграмму средствами seaborn и сохранить график в виде png-файла;
graph_hist_boxplot_probplot_sns и graph_hist_boxplot_probplot_XY_sns - функции позволяют визуализировать исходные данные путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика (в первом случае - для одной переменной, во втором случае - для двух переменных X и Y) средствами seaborn и сохранить график в виде png-файла; имеется возможность выбирать, какие графики строить (h - hist, b - boxplot, p - probplot);
norm_distr_check - функция выполняет проверку нормальности распределения исходных данных с использованием набора из нескольких статистических тестов;
corr_coef_check, corr_ratio_check и line_corr_sign_check - функции, выполняющие проверку значимости коэффициента линейной корреляции Пирсона, корреляционного отношения и проверку гипотезы о значимости отличия линейной корреляционной связи от нелинейной (подробнее об этих функциях я писал в своей статье https://habr.com/ru/post/683442/);
regression_error_metrics - функция возвращает ошибки аппроксимации регрессионной модели;
regression_model_adequacy_check - проверка адекватности регрессионной модели по критерию Фишера;
graph_regression_plot_sns - функция строит график регрессионной модели и график остатков средствами seaborn;
graph_regression_pair_predict_plot_sns - прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X;
Durbin_Watson_test - функция выполняет проверку автокорреляции по критерию Дарбина-Уотсона (подробнее об этой функции я писал в своей статье https://habr.com/ru/post/693402/);
Goldfeld_Quandt_test, Breush_Pagan_test, White_test - проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
detecting_outliers_mad_test - функция выполняет проверку наличия аномальных значений (выбросов) по критерию наибольшего абсолютного отклонения для нормально распределенных данных (более подробно - см.[1, с.547]).
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включены в пользовательский модуль my_module__stat.py):
Mann_Whitney_test_trend_check - функция проверяет гипотезу о наличии тренда (т.е. существенном различии двух частей временного ряда) по критерию Манна-Уитни;
rank_corr_coef_check - функция для расчета, проверки значимости и построения доверительных интервалов коэффициентов ранговой корреляции (Кендалла и Спирмена);
Abbe_test - функция для проверки гипотезы о случайности значений ряда по критерию Аббе (Аббе-Линника);
Cox_Stuart_test - функция для проверки гипотезы о случайности значений ряда по критерию Кокса-Стюарта;
Foster_Stuart_test - функция для проверки гипотезы о случайности значений ряда по критерию Фостера-Стюарта
Для реализации пользовательских функций в каталоге с рабочим файлом *.ipynb или *.py необходимо создать каталог table, в который нужно поместить файлы с табличными значениями ряда критериев:
Abbe_test_table.csv - для критерия Аббе (Аббе-Линника);
Durbin_Watson_test_table.csv - для критерия Дарбина-Уотсона;
Epps_Pulley_test_table.csv - для критерия Эппса-Палли.
Каталог table со всеми файлами также доступен в моем репозитории на GitHub (https://github.com/AANazarov/MyModulePython).
ПОСТАНОВКА ЗАДАЧИ
Рассмотрим задачу нахождения зависимости среднемесячного расхода топлива автомобиля (л/100 км) (FuelFlow) от среднемесячного пробега (км) (Mileage) (эту же задачу я рассматривал в своей статье "Расчет и анализ корреляционного отношения средствами Python" (https://habr.com/ru/post/683442/).
# Общий заголовок проекта
Task_Project = "Анализ расхода топлива легкового автомобиля"
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}\n{AsOfTheDate}"
# Наименования переменных
Variable_Name_T_month = "Ежемесячные данные / Monthly data"
Variable_Name_Y = "Среднемесячный расход топлива (л на 100 км) / FuelFlow"
Variable_Name_X1 = "Пробег автомобиля за месяц (км) / Mileage (km)"
Variable_Name_X2 = "Среднемесячная температура (°С) / Temperature"ФОРМИРОВАНИЕ ИСХОДНЫХ ДАННЫХ
Загрузим исходные данные из csv-файла.
Столбцы таблицы:
Month — месяц (в формате Excel)
Mileage - месячный пробег (км)
Temperature - среднемесячная температура (°C)
FuelFlow - среднемесячный расход топлива (л/100 км)
fuel_df = pd.read_csv(filepath_or_buffer='data/FUEL.csv', sep=';')
data_df = fuel_df.copy() # создаем копию исходной таблицы для работы
#display(data_df)
display(data_df.head(), data_df.tail())
data_df.info()ПЕРВИЧНАЯ ОБРАБОТКА ИСХОДНЫХ ДАННЫХ
Обработка данных
1. Выявление пропущенных значений и их удаление
Для визуализации (маркирования) значений, подлежащих исключению, применим пользовательскую функцию df_detection_values, для которой задается список detection_values значений, подлежащих маркированию (в нашем случае это пропущенные и нулевые значения: detection_values=[nan, 0]). Функция возвращает график тепловой карты (heatmap) с маркированным значениями, а также количество маркированных значений по столбцам исходного DataFrame:
result_df, detection_values_df = df_detection_values(data_df, detection_values=[nan, 0])
display(result_df)

Вывод: имеются значения, подлежащие удалению.
Исключим пропущенные значения из набора данных:
# формируем список строк, подлежащих удалению
drop_labels = []
for elem in detection_values_df.index:
if detection_values_df.loc[elem].any():
drop_labels.append(elem)
#display(drop_labels)
# удаляем строки
data_df = data_df.drop(index=drop_labels)2. Преобразование признаков-дат в формат datetime
Преобразуем дату из формата Excel в формат datetime:
# Преобразуем дату из формата Excel в формат datetime:
data_df['Month'] = pd.to_datetime(
data_df['Month'],
dayfirst=True,
origin='1900-01-01',
unit='D')
# Сдвигаем дату на конец месяца
data_df['Month'] = data_df['Month'] + \
pd.tseries.offsets.DateOffset(months=1) + \
pd.tseries.offsets.DateOffset(days=-3)
# Переименуем столбец
data_df.rename(columns={'Month': 'Date'}, inplace=True)
# Добавляем номер месяца
#fuel_df.insert(0, "Time", range(1, len(fuel_df)+1))
display(data_df.head())
data_df.info()Сохранение данных
Сохраняем данные в виде отдельных переменных (для дальнейшего анализа).
Среднемесячный расход топлива (л/100 км) / Fuel Flow (liters per 100 km):
Y = np.array(data_df['FuelFlow'])Пробег автомобиля за месяц (км) / Mileage (km):
X = np.array(data_df['Mileage'])Дата:
Date = np.array(data_df['Date'])Для удобства дальнейшей работы сформируем сформируем отдельный DataFrame из переменных X, Y:
dataset_df = pd.DataFrame({
'X': X,
'Y': Y})ОПИСАТЕЛЬНАЯ СТАТИСТИКА И ВИЗУАЛИЗАЦИЯ
Границы значений переменных (при построении графиков):
(X_min_graph, X_max_graph) = (0, 3000)
(Y_min_graph, Y_max_graph) = (0, 20)Среднемесячный расход топлива / Fuel Flow (Y)
graph_lineplot_sns(
Date, Y,
Ymin_in=Y_min_graph, Ymax_in=Y_max_graph,
color='orange',
title_figure=Title_String, #title_figure_fontsize=14,
title_axes='Динамика расхода топлива',
x_label=Variable_Name_T_month,
y_label=Variable_Name_Y,
#label_legend='эмпирические данные',
file_name='graph/lineplot_Y_sns.png')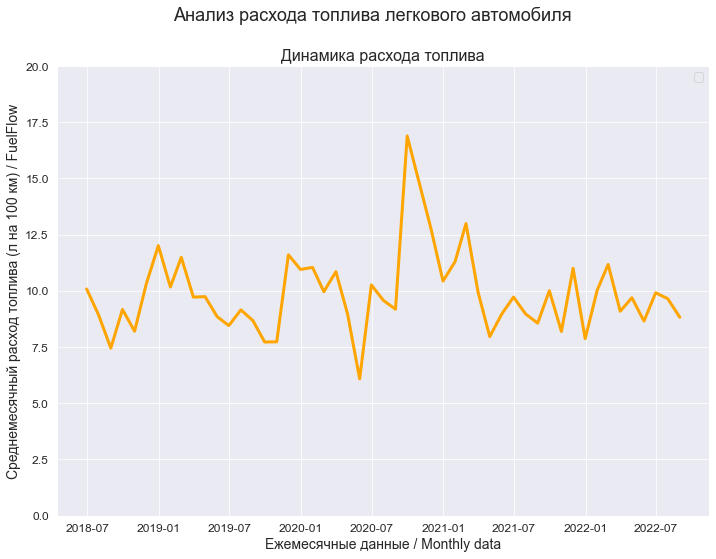
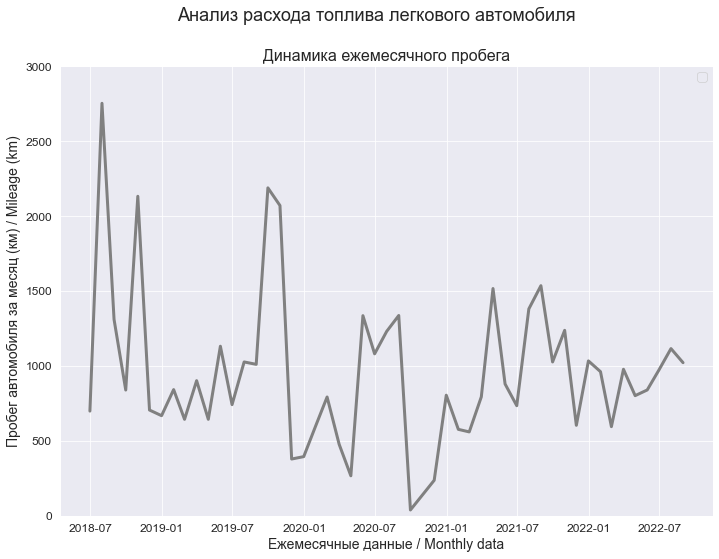
Пробег автомобиля за месяц / Mileage (X)
Зависимость расхода топлива (Y) от пробега (X)
graph_scatterplot_sns(
X, Y,
Xmin=X_min_graph, Xmax=X_max_graph,
Ymin=Y_min_graph, Ymax=Y_max_graph,
color='orange',
title_figure=Title_String, title_figure_fontsize=14,
title_axes='Зависимость расхода топлива (Y) от пробега (X)', title_axes_fontsize=16,
x_label=Variable_Name_X1,
y_label=Variable_Name_Y,
label_fontsize=14, tick_fontsize=12,
label_legend='', label_legend_fontsize=12,
s=80,
#graph_size=(297/INCH, 210/INCH),
file_name='graph/scatterplot_X_Y_sns.png')
Гистограмма / коробчатая диаграмма / вероятностный график
# Пользовательская функция
graph_hist_boxplot_probplot_XY_sns(
data_X=X, data_Y=Y,
data_X_min=X_min_graph, data_X_max=X_max_graph,
data_Y_min=Y_min_graph, data_Y_max=Y_max_graph,
graph_inclusion='hbp', # выбираем для построения виды графиков: b - boxplot, p - probplot)
data_X_label=Variable_Name_X1,
data_Y_label=Variable_Name_Y,
title_figure=Title_String, title_figure_fontsize=16,
file_name='graph/hist_boxplot_probplot_X_Y_sns.png') 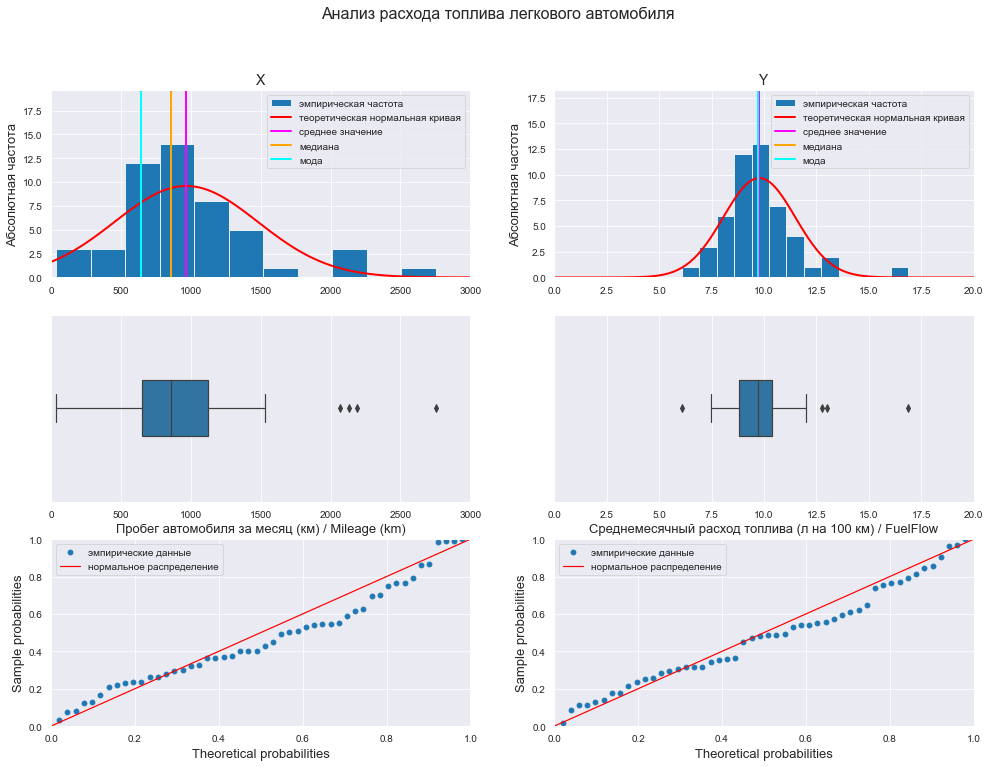
Для сравнения характера распределений переменных построим совмещенную коробчатую диаграмму по стандартизованным данным:
# стандартизуем исходные данные
standardize_df = lambda X: ((X - np.mean(X))/np.std(X))
dataset_df_standardize = dataset_df.copy()
dataset_df_standardize = dataset_df_standardize.apply(standardize_df)
#display(dataset_df_standardize)
# построим график
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/2))
axes.set_title("Распределение стандартизованных переменных X и Y", fontsize = 16)
sns.boxplot(
data=dataset_df_standardize,
orient='h',
width=0.5,
ax=axes)
plt.show()
Описательная статистика:
result = Description(
dataset_df,
stats=["nobs", "missing", "mean", "std_err", "ci", "ci", "std", "iqr", "mad", "coef_var", "range", "max", "min", "skew", "kurtosis", "mode",
"median", "percentiles", "distinct", "top", "freq"],
alpha=a_level,
use_t=True)
display(result.summary())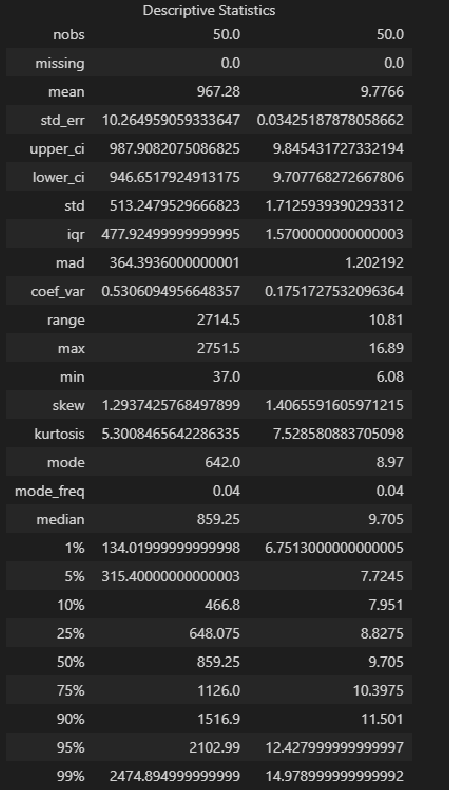
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует:
для переменной X - о правосторонней асимметрии (т.к. mean > median);
для переменной Y - о правосторонней асимметрии (т.к. mean > median).
-
Значение коэффициента вариации свидетельствует:
для переменной X - о неоднородности исходных данных (CV = 0.5306 > 0.33);
для переменной Y - об однородности исходных данных (CV = 0.1751 < 0.33).
-
Значение показателя асимметрии skew (As) свидетельствует:
для переменной X - о значительной правосторонней асимметрии (As = 1.2937, |As| > 0.5, As > 0);
для переменной Y - о значительной правосторонней асимметрии (As = 1.4066, |As| > 0.5, As > 0).
-
Значение показателя асимметрии kurtosis (Es) свидетельствует:
для переменной X - об островершинном распределении (Es = 5.3008, |Es| > 0);
для переменной Y - об островершинном распределении (Es = 7.5285, |Es| > 0).
Коробчатые диаграммы показывают наличие аномальных значений (выбросов) для обеих переменных.
Вероятностные графики свидетельствует о том, что скорее всего закон распределения значений обеих переменных отличается от нормального.
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Среднемесячный расход топлива / Fuel Flow (Y)
display(norm_distr_check(Y, p_level=p_level))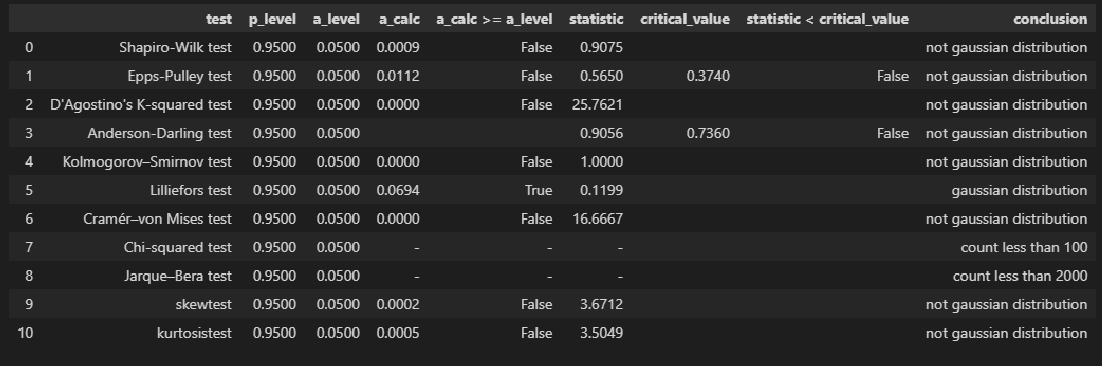
Вывод: большинство статистических тестов ОТВЕРГАЮТ гипотезу о нормальном распределении.
Пробег автомобиля за месяц / Mileage (X)
display(norm_distr_check(X, p_level=p_level))
Вывод: большинство статистических тестов ОТВЕРГАЮТ гипотезу о нормальном распределении.
ПРОВЕРКА ТРЕНДА И СЛУЧАЙНОСТИ
Так как данные представляют собой временные ряды, мы обязаны выполнить проверку тренда и случайности. Наличие трендов в значениях показателей может привести к ложной корреляции (вроде зависимостей между числом фильмов с Николасом Кейджем и смертностью людей в бассейнах, или между рождаемостью в Швеции и количеством гнезд аистов - много таких юмористических зависимостей описано в книге Т.Вигена "Ложные корреляции", кто желает, может найти в интернете).
Проверить наличие тренда и случайности можно различными способами:
Проверка разности средних уровней - самый простой способ: ряд разбивается на 2 части, уровни каждой рассматриваются как отдельные выборки, по каждой выборке рассчитывается среднее значение и проверяется гипотеза о равенстве средних. В случае, если исходные данные распределены нормально, можно воспользоваться критерием Стьюдента, если гипотеза о нормальности отклоняется - существуют непараметрические методы (критерий Манна-Уитни и пр.).
Корреляционный анализ с целью выявления тренда - расчет и проверка значимости показателей тесноты связи между значениями переменной и временем (номером наблюдения); в случае нормально распределенных данных это может быть коэффициент корреляции Пирсона, в случае отсутствия нормальности - непараметрические показатели (коэффициент ранговой корреляции Спирмена и пр.).
Использование специальных критериев проверки случайности - таких как критерии Аббе, Фостера-Стюарта и пр.; часто это критерии, основанные на рангах, знаках или сериях.
Примечание: под методами корреляционного анализа (способ 2) мы будем понимать расчет показателей, которые не просто позволяют проверить гипотезу о наличии связи, но и оценить ее силу (т.е. они принимают привычный нам диапазон значений в интервале [0; 1] или [-1; 1] - например, коэффициенты ранговой корреляции Спирмена и Кендалла), а специальные критерии проверки случайности (способ 3) позволяют только принять или отклонить гипотезу о наличии связи (например, в [1, с.539] описан коэффициент ранговой сериальной корреляции Вальда-Волфовица, который, по сути, является просто критерием, так как может принимать значение больше 1 и не позволяет оценить силу связи).
Для каждого способа можно подобрать как параметрические, так и непараметрические методы (не зависящие от нормальности распределения исходных данных).
В рамках нашего обзора рассмотрим каждый способ.
Проверка разности средних уровней
Так как гипотеза о нормальном распределении исходных данных была отклонена, воспользуемся непараметрическими методами.
В справочнике Кобзаря А.И. [1] данным методам посвящена глава 4.2 [1, с.455]. Автор рассматривает 10 критериев, к сожалению, данных о сравнительной мощности этих критериев не приводится.
Мы воспользуемся из этого перечня критерием Манна-Уитни (https://en.wikipedia.org/wiki/Mann–Whitney_U_test). Вообще с критерием Манна-Уитни ситуация своеобразная - в литературе описаны различные модификации этого критерия, с которыми по-хорошему следует разобраться подробно, однако в данном обзоре мы не будем останавливаться на этом вопросе, а просто воспользуемся функцией mannwhitneyu, который входит в стандартный инструментарий statsmodels (https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.mannwhitneyu.html).
Для удобства работы создадим пользовательскую функцию Mann_Whitney_test_trend_check для проверки гипотезы о наличии тренда по критерию Манна-Уитни:
def Mann_Whitney_test_trend_check(
data1, data2, # два части, на которые следует разбить исходный массив значений
use_continuity=True, # поправка на непрерывность
alternative='two-sided', # вид альтернативной гипотезы
method='auto', # метод расчета уровня значимости
p_level=0.95,
DecPlace=5):
a_level = 1 - p_level
result = sps.mannwhitneyu(
data1, data2,
use_continuity=use_continuity,
alternative=alternative,
method=method)
s_calc = result.statistic # расчетное значение статистики критерия
a_calc = result.pvalue # расчетный уровень значимости
print(f"Расчетное значение статистики критерия: s_calc = {round(s_calc, DecPlace)}")
print(f"Расчетный уровень значимости: a_calc = {round(a_calc, DecPlace)}")
print(f"Заданный уровень значимости: a_level = {round(a_level, DecPlace)}")
if a_calc >= a_level:
conclusion_ShW_test = f"Так как a_calc = {round(a_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" + \
", то нулевая гипотеза об отсутствии сдвига в выборках ПРИНИМАЕТСЯ, т.е. сдвиг ОТСУТСТВУЕТ"
else:
conclusion_ShW_test = f"Так как a_calc = {round(a_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" + \
", то нулевая гипотеза об отсутствии сдвига в выборках ОТКЛОНЯЕТСЯ, т.е. сдвиг ПРИСУТСТВУЕТ"
print(conclusion_ShW_test)
return Среднемесячный расход топлива / Fuel Flow (Y)
# разделяем массив исходных данных на две части
N1 = Y.size//2
Y1 = Y[:N1]
Y2 = Y[N1:]
print(f'Y1 = \n{Y1} \nY1.size = {Y1.size}\n')
print(f'Y2 = \n{Y2} \nY1.size = {Y2.size}\n')
# проверяем гипотезу
Mann_Whitney_test_trend_check(Y1, Y2)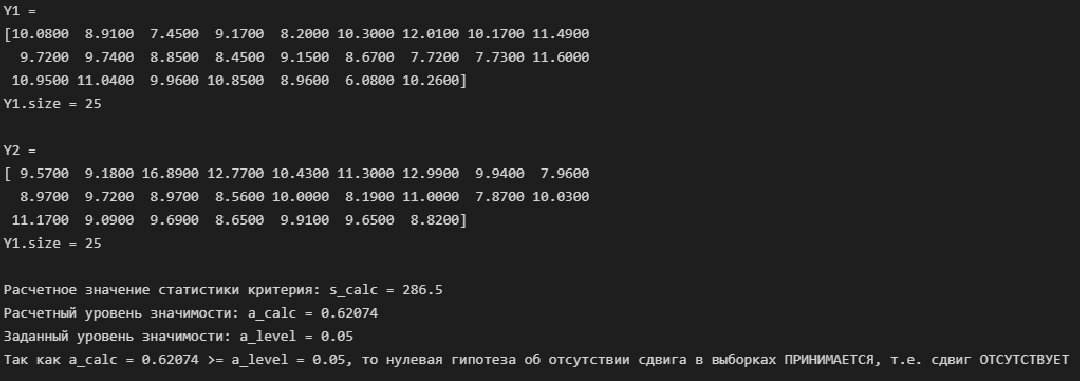
Вывод: по критерию Манна-Уитни тренд отсутствует.
Пробег автомобиля за месяц / Mileage (X)
# разделяем массив исходных данных на две части
N1 = X.size//2
X1 = X[:N1]
X2 = X[N1:]
print(f'X1 = \n{X1} \nY1.size = {X1.size}\n')
print(f'X2 = \n{X2} \nY1.size = {X2.size}\n')
# проверяем гипотезу
Mann_Whitney_test_trend_check(X1, X2)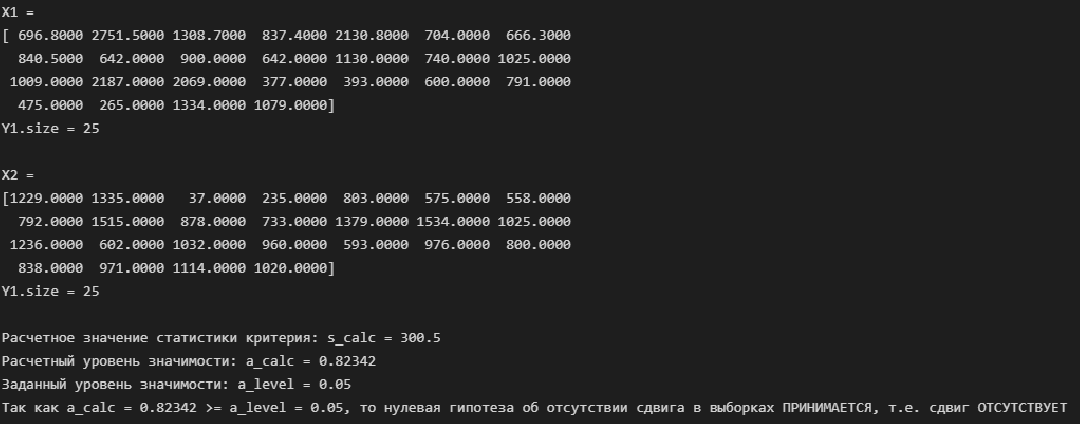
Вывод: по критерию Манна-Уитни тренд отсутствует.
Корреляционный анализ с целью выявления тренда
Так как гипотеза о нормальном распределении исходных данных была отклонена, применять коэффициент линейной корреляции Пирсона или корреляционное отношение особого смысла нет - то есть рассчитать эти показатели мы, конечно, можем, но проверять гипотезы об их значимости и строить доверительные интервалы не можем. Рассмотрим непараметрические показатели.
В справочнике Кобзаря А.И. [1] данным методам посвящен раздел 5.2.2.2 [1, с.626]. Автор рассматривает коэффициенты ранговой корреляции Кендалла, Спирмена, Фишера-Йэйтса, Ван дер Вардена, причем указано, что два последних коэффициента наиболее эффективны для нормально распределенных исходных данных.
Мы воспользуемся из этого перечня коэффициентами Кендалла (τ) и Спирмена (ρ), которые входят в стандартный инструментарий statsmodels - функции scipy.stats.kendalltau (https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kendalltau.html) и scipy.stats.spearmanr (https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.spearmanr.html).
Не будем глубоко вдаваться в теорию вопроса, отметим только некоторые особенности этих коэффициентов (см. Портал психологических изданий PsyJournals.ru — https://psyjournals.ru/psyedu/2009/n1/Shishlyannikova_full.shtml [Применение корреляционного анализа в психологии - Психологическая наука и образование - 2009. Том. 14, № 1]):
Коэффициента ранговой корреляции Кендалла и Спирмена принимают значения в интервале [-1; 1].
Как правило, значение коэффициента Спирмена больше, чем значение коэффициента Кендалла: ρ > τ.
Принципиальных отличий между этими критериями не существует, но принято считать, что коэффициент Кендалла является более «содержательным», так как он более полно и детально анализирует связи между переменными, перебирая все возможные соответствия между парами значений. Коэффициент Спирмена более точно учитывает именно количественную степень связи между переменными.
-
Преимущество коэффициента Спирмена по сравнению с коэффициентом корреляции Пирсона – в большей чувствительности к связи. Его используют в следующих случаях:
наличие существенного отклонения распределения хотя бы одной переменной от нормального вида (асимметрия, выбросы);
появление криволинейной (монотонной) связи.
-
Ограничением для применения коэффициента Спирмена являются:
по каждой переменной не менее 5 наблюдений;
коэффициент при большом количестве одинаковых рангов по одной или обеим переменным дает огрубленное значение.
Применение коэффициента Кендалла является предпочтительным, если в исходных данных имеются выбросы.
Особенностью ранговых коэффициентов корреляции является то, что максимальным по модулю ранговым корреляциям (+1, –1) не обязательно соответствуют строгие прямо или обратно пропорциональные связи между исходными переменными X и Y: достаточна лишь монотонная функциональная связь между ними. Ранговые корреляции достигают своего максимального по модулю значения, если большему значению одной переменной всегда соответствует большее значение другой переменной (+1), или большему значению одной переменной всегда соответствует меньшее значение другой переменной и наоборот (–1).
-
Если статистически достоверная связь не обнаружена, но есть основания полагать, что связь на самом деле есть, следует сначала перейти от коэффициента Спирмена к коэффициенту Кендалла (или наоборот), а затем проверить возможные причины недостоверности связи:
нелинейность связи: для этого посмотреть график двумерного рассеивания. Если связь не монотонная, то делить выборку на части, в которых связь монотонная, или делить выборку на контрастные группы и далее сравнивать их по уровню выраженности признака;
неоднородность выборки: посмотреть график двумерного рассеивания, попытаться разделить выборку на части, в которых связь может иметь разные направления.
Про шкалы измерения силы ранговой корреляции: в монографии [9, с.204] предлагается использовать шкалу Ивантера-Коросова, но в более поздней статье [10], обобщающей мировой опыт использования шкал, указано, что для коэффициента Спирмена используют те же шкалы, что и для коэффициента линейной корреляции, а для коэффициента Кендалла вообще не предлагалось никаких шкал. Мы будем использовать шкалу Эванса (про нее также см.[10]).
Подробнее об этих коэффициентах - см.[1, с.624; 7, с.106; 9, с.203].
Для удобства работы создадим пользовательскую функцию rank_corr_coef_check для расчета, проверки значимости и построения доверительных интервалов коэффициентов ранговой корреляции (Кендалла и Спирмена):
def rank_corr_coef_check(X, Y, p_level=0.95, scale='Evans'):
a_level = 1 - p_level
X = np.array(X)
Y = np.array(Y)
n_X = len(X)
n_Y = len(Y)
# коэффициент ранговой корреляции Кендалл
rank_corr_coef_tau, a_rank_corr_coef_tau_calc = sps.kendalltau(X, Y)
# коэффициент ранговой корреляции Спирмена
rank_corr_coef_spearman, a_rank_corr_coef_spearman_calc = sps.spearmanr(X, Y)
# критические значения коэффициентов
if n_X >= 10:
u_p_tau = sps.norm.ppf(p_level, 0, 1) # табл.значение квантиля норм.распр.
rank_corr_coef_tau_crit_value = u_p_tau * sqrt(2*(2*n_X + 5) / (9*n_X*(n_X-1)))
u_p_spearman = sps.norm.ppf((1+p_level)/2, 0, 1)
rank_corr_coef_spearman_crit_value = u_p_spearman * 1/sqrt(n_X-1)
else:
rank_corr_coef_tau_crit_value = '-'
rank_corr_coef_spearman_crit_value = '-'
# проверка гипотезы о значимости
conclusion_tau = 'significance' if a_rank_corr_coef_tau_calc <= a_level else 'not significance'
conclusion_spearman = 'significance' if a_rank_corr_coef_spearman_calc <= a_level else 'not significance'
# оценка тесноты связи
if scale=='Cheddok':
conclusion_scale_tau = scale + ': ' + Cheddock_scale_check(rank_corr_coef_tau)
conclusion_scale_spearman = scale + ': ' + Cheddock_scale_check(rank_corr_coef_spearman)
elif scale=='Evans':
conclusion_scale_tau = scale + ': ' + Evans_scale_check(rank_corr_coef_tau)
conclusion_scale_spearman = scale + ': ' + Evans_scale_check(rank_corr_coef_spearman)
# доверительные интервалы (только для коэффициента Кендалла - см.[Айвазян, т.2, с.116])
if conclusion_tau == 'significance':
rank_corr_coef_tau_delta = sps.norm.ppf((1+p_level)/2, 0, 1) * sqrt(2/n_X * (1 - rank_corr_coef_tau**2))
rank_corr_coef_tau_int_low = rank_corr_coef_tau - rank_corr_coef_tau_delta if rank_corr_coef_tau - rank_corr_coef_tau_delta else 0
rank_corr_coef_tau_int_high = rank_corr_coef_tau + rank_corr_coef_tau_delta if rank_corr_coef_tau + rank_corr_coef_tau_delta <= 1 else 1
# формируем результат
result = pd.DataFrame({
'name': ('Kendall', 'Spearman'),
'notation': (chr(964), chr(961)),
'coef_value': (rank_corr_coef_tau, rank_corr_coef_spearman),
'p_level': (p_level),
'a_level': (a_level),
'a_calc': (a_rank_corr_coef_tau_calc, a_rank_corr_coef_spearman_calc),
'a_calc <= a_level': (a_rank_corr_coef_tau_calc <= a_level, a_rank_corr_coef_spearman_calc <= a_level),
'crit_value': (rank_corr_coef_tau_crit_value, rank_corr_coef_spearman_crit_value),
'crit_value >= coef_value': (
rank_corr_coef_tau >= rank_corr_coef_tau_crit_value if rank_corr_coef_tau_crit_value != '-' else '-',
rank_corr_coef_spearman >= rank_corr_coef_spearman_crit_value if rank_corr_coef_spearman_crit_value != '-' else '-'),
'significance_check': (conclusion_tau, conclusion_spearman),
'conf_int_low': (
rank_corr_coef_tau_int_low if conclusion_tau == 'significance' else '-',
'-'),
'conf_int_high': (
rank_corr_coef_tau_int_high if conclusion_tau == 'significance' else '-',
'-'),
'scale': (conclusion_scale_tau, conclusion_scale_spearman)
})
return resultСреднемесячный расход топлива / Fuel Flow (Y)
display(rank_corr_coef_check(dataset_df.index, Y))
Пробег автомобиля за месяц / Mileage (X)
display(rank_corr_coef_check(dataset_df.index, X))
Вывод: коэффициенты ранговой корреляции незначимы, наличие связи между переменными отсутствует.
Использование специальных критериев проверки случайности
В справочнике Кобзаря А.И. [1] рассматривается широкий набор таких критериев:
в разделе 4.3 - 14 критериев сдвига среднего значения (Аббе-Линника, Фостера-Стюарта, Кокса-Стюарта, Хсу (для сдвига дисперсии), сериальные критерии случайности (4 критерия), критерий инверсий, критерий автокорреляции, критерии ранговой корреляции (4 критерия))
в разделе 5.2.2 - 7 критериев (Кенуя, Нелсона, квадратный критерий, Олмстеда-Тьюки, Шахани, Блума-Кифера-Розенблата, Гёфдинга, Ширахатэ).
В монографии Лемешко Б.Ю. [3] в разделе 9.2 также рассматриваются критерии тренда и случайности - всего 8 критериев, причем дается сравнительное ранжирование критериев по мощности для обнаружения сдвига среднего значения (по величине убывания мощности) [3, с.462]: Аббе > Кокса-Стюарта > Бартелса > Вальда-Волфовитца > автокорреляции > Фостера-Стюарта.
Как видим, довольно известный критерий Фостера-Стюарта оказался в аутсайдерах по мощности.
Мы воспользуемся из этого перечня критериями Аббе, Кокса-Стюарта ну и старый добрый критерий Фостера-Стюарта не забудем.
Критерий Аббе (Аббе-Линника)
Информацию про критерий Аббе (Аббе-Динника) можно почерпнуть в [1, с.517], [2, с.62], [6, с.405], [3, с.433].
Данный критерий отличается несколько противоречивыми подходами к аппроксимации критических значений, поэтому разберем его более подробно.
В [2, с.62] и ссылающемся на него [1, с.517] приведена методика методика расчета статистики критерия Аббе (Аббе-Линника), табулированы его критические значения при n ≤ 60, а также порядок аппроксимации критических значений нормальным законом при n > 60. В монографии Лемешко Б.Ю. [3, с.433] приводятся результаты исследования данного критерия методом статистического моделирования.
Данный критерий рекомендован к применению требованиями к измерению физических величин МИ 2091-90 (https://meganorm.ru/Data2/1/4293802/4293802609.htm).
Итак, проверяется нулевая гипотеза о равенстве средних (все выборочные значения принадлежат к одной генеральной совокупности), то есть об отсутствии сдвига (тренда):
против альтернативной гипотезы о наличии сдвига (тренда):
Расчетное значение статистики критерия имеет вид:
Критические значения при n ≤ 60 мы оцифровали ранее.
Условия принятия гипотез:
При n > 60 для определения табличных значений рекомендована аппроксимация [2, с.62]:
где - квантиль нормального распределения.
Также при n > 60 можно рассчитать величину:
которая имеет стандартный нормальный закон распределения , тогда условия принятия гипотез будут:
Лемешко Б.Ю. в своей монографии [3, с.436] указывает, что при n > 20 оправданно аппроксимировать распределение величины нормальным законом с параметрами
.
Для удобства работы создадим пользовательскую функцию Abbe_test для проверки гипотезы о случайности значений ряда по критерию Аббе (Аббе-Линника):
def Abbe_test(X, p_level=0.95):
a_level = 1 - p_level
X = np.array(X)
n = len(X)
# расчетное значение статистики критерия
if n >= 4:
Xmean = np.mean(X)
sum1 = np.sum((X - Xmean)**2)
sum2 = np.sum([(X[i+1] - X[i])**2 for i in range(n-1)])
q_calc = 0.5*sum2/sum1
else:
q_calc = '-'
q_table = '-'
a_calc = '-'
# табличное значение статистики критерия при 4 <= n <= 60
if n >= 4 and n <= 60:
Abbe_table_df = pd.read_csv(
filepath_or_buffer='table/Abbe_test_table.csv',
sep=';',
index_col='n')
p_level_dict = {
0.95: Abbe_table_df.columns[0],
0.99: Abbe_table_df.columns[1]}
f_lin = sci.interpolate.interp1d(Abbe_table_df.index, Abbe_table_df[p_level_dict[p_level]])
q_table = float(f_lin(n))
#if n >= 20:
# a_calc = 1 - sci.stats.norm.cdf(q_calc, loc=1, scale=sqrt((n-2)/(n**2-1)))
# табличное значение статистики критерия при n > 60 (см.Кобзарь, с.517)
if n > 60:
u_p = sps.norm.ppf(1-p_level, 0, 1)
q_table = 1 + u_p / sqrt(n + 0.5*(1 + u_p**2))
Q_calc = -(1 - q_calc) * sqrt((2*n + 1)/(2 - (1-q_calc)**2))
Q_table = u_p
# проверка гипотезы
if n >= 4:
conclusion = 'independent observations' if q_calc >= q_table else 'dependent observations'
else:
conclusion = 'count less than 4'
# формируем результат
result = pd.DataFrame({
'n': (n),
'p_level': (p_level),
'a_level': (a_level),
'q_calc': (q_calc),
'q_table': (q_table if n >= 4 else '-'),
'q_calc ≥ q_table': (q_calc >= q_table if n >= 4 else '-'),
'Q_calc (for n > 60)': (Q_calc if n > 60 else '-'),
'Q_table': (Q_table if n > 60 else '-'),
'Q_calc ≥ Q_table': (Q_calc >= Q_table if n > 60 else '-'),
#'a_calc': (a_calc if n > 20 else '-'),
#'a_calc ≤ a_level': (a_calc <= a_level if n > 20 else '-'),
'conclusion': (conclusion)
},
index=['Abbe test'])
return resultКритерий Кокса-Стюарта
Информацию про критерий Кокса-Стюарта можно почерпнуть в [1, с.520], [5, с.61].
Согласно Б.Ю. Лемешко [5, с.108], критерий Кокса-Стюарта имеет мощность выше среднего; его недостатком является то, что при n < 40 необходимо учитывать дискретность нормализованной статистики.
Для удобства работы создадим пользовательскую функцию Cox_Stuart_test для проверки гипотезы о случайности значений ряда по критерию Кокса-Стюарта:
def Cox_Stuart_test(data, p_level=0.95):
a_level = 1 - p_level
data = np.array(data)
N = len(data)
# функция, выполняющая процедуру расчета теста Кокса-Стюарта
def calculate_test(X):
n = len(X)
# расчетное значение статистики критерия (тренд средних)
h = lambda i, j: 1 if X[i] > X[j] else 0
S = np.sum([(n-2*i+1) * h(i-1, (n-i+1)-1) for i in range(1, n//2 + 1)])
MS = (n**2)/8
DS = n*(n**2 - 1) / 24
S_calc = abs(S - MS) / sqrt(DS)
# табличное значение статистики критерия (тренд средних)
S_table = sps.norm.ppf((1+p_level)/2, 0, 1)
# результат
return S_calc, S_table
# ПРОВЕРКА ГИПОТЕЗЫ О НАЛИЧИИ ТРЕНДА В СРЕДНЕМ
(S1_calc, S1_table) = calculate_test(data)
conclusion_mean = 'independent observations' if S1_calc < S1_table else 'dependent observations'
# ПРОВЕРКА ГИПОТЕЗЫ О НАЛИЧИИ ТРЕНДА В ДИСПЕРСИИ
# задаем шкалу для объема подвыборок
k_scale = [
[48, 2],
[64, 3],
[90, 4]]
# определяем объем подвыборки
for i, elem in enumerate(k_scale):
if N < elem[0]:
K = elem[1]
break
else:
K = 5
#print(f'N = {N}')
#print(f'K = {K}')
# определяем число подвыборок
R = N//K
#print(f'R = {R}')
# формируем подвыборки
Subsampling = np.zeros((R, K))
if not R % 2: # четное число подвыборок
R_2 = int(R/2)
for i in range(R_2):
Subsampling[i] = [data[i*K + j] for j in range(0, K, 1)]
Subsampling[R - 1 - i] = [data[N - (i*K + j)] for j in range(K, 0, -1)]
else: # нечетное число подвыборок
R_2 = int((R)/2)+1
for i in range(R_2):
Subsampling[i] = [data[i*K + j] for j in range(0, K, 1)]
Subsampling[R - 1 - i] = [data[N - (i*K + j)] for j in range(K, 0, -1)]
#print(f'Subsampling = \n{Subsampling}\n')
# проверка гипотезы
W = [np.amax(Subsampling[i]) - np.amin(Subsampling[i]) for i in range(R)] # размахи подвыборок
#print(f'W = {W}')
(S2_calc, S2_table) = calculate_test(W)
conclusion_variance = 'independent observations' if S2_calc < S2_table else 'dependent observations'
# формируем результат
result = pd.DataFrame({
'n': (N),
'p_level': (p_level),
'a_level': (a_level),
'S_calc': (S1_calc, S2_calc),
'S_table': (S1_table, S2_table),
'S_calc < S_table': (S1_calc < S1_table, S2_calc < S2_table),
'conclusion': (conclusion_mean, conclusion_variance)
},
index=['Cox_Stuart_test (trend in means)', 'Cox_Stuart_test (trend in variances)'])
return resultКритерий Фостера-Стюарта
Информацию про критерий Фостера-Стюарта можно почерпнуть в [1, с.519], [3, с.451], [5, с.55].
Для удобства работы создадим пользовательскую функцию Foster_Stuart_test для проверки гипотезы о случайности значений ряда по критерию Фостера-Стюарта:
def Foster_Stuart_test(X, p_level=0.95):
a_level = 1 - p_level
X = np.array(X)
n = len(X)
# расчетные значения статистики критерия
u = l = list()
Xtemp = np.array(X[0])
for i in range(1, n):
Xmax = np.max(Xtemp)
Xmin = np.min(Xtemp)
u = np.append(u, 1 if X[i] > Xmax else 0)
l = np.append(l, 1 if X[i] < Xmin else 0)
Xtemp = np.append(Xtemp, X[i])
d = np.int64(np.sum(u - l))
S = np.int64(np.sum(u + l))
# нормализованные расчетные значения статистики критерия
mean_d = 0
mean_S = 2*np.sum([1/i for i in range(2, n+1)])
std_d = sqrt(mean_S)
std_S = sqrt(mean_S - 4*np.sum([1/i**2 for i in range(2, n+1)]))
'''print(f'mean_d = {mean_d}')
print(f'std_d = {std_d}')
print(f'mean_S = {mean_S}')
print(f'std_S = {std_S}')'''
t_d = (d - mean_d)/std_d
t_S = (S - mean_S)/std_S
# табличные значения статистики критерия
df = n
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
# проверка гипотезы
conclusion_d = 'independent observations' if t_d <= t_table else 'dependent observations'
conclusion_S = 'independent observations' if t_S <= t_table else 'dependent observations'
# формируем результат
result = pd.DataFrame({
'n': (n),
'p_level': (p_level),
'a_level': (a_level),
'notation': ('d', 'S'),
'statistic': (d, S),
'normalized_statistic': (t_d, t_S),
'crit_value': (t_table),
'normalized_statistic ≤ crit_value': (t_d <= t_table, t_S <= t_table),
'conclusion': (conclusion_d, conclusion_S)
},
index=['Foster_Stuart_test (trend in means)', 'Foster_Stuart_test (trend in variances)'])
return resultСравнивая результаты тестирования рассмотренных критериев на различных примерах, увидим, что критерий Аббе (Аббе-Линника) при проверке наличия тренда в среднем часто дает результаты, отличные от результатов применения остальных критериев. С этим критерием все не так однозначно и это заслуживает отдельного исследования.
Проверим наши данные на наличие тренда.
Среднемесячный расход топлива / Fuel Flow (Y)
display(Abbe_test(Y))
display(Cox_Stuart_test(Y))
display(Foster_Stuart_test(Y))
Вывод: большинство тестов позволяют сделать вывод об отсутствии тренда (за исключением критерия Аббе).
Пробег автомобиля за месяц / Mileage (X)
display(Abbe_test(X))
display(Cox_Stuart_test(X))
display(Foster_Stuart_test(X))
Вывод: все тесты позволяют сделать вывод об отсутствии тренда.
Сводка результатов проверки наличия тренда
Тесты |
Переменная Y |
Переменная X |
|---|---|---|
Критерий Манна-Уитни |
нет |
нет |
Коэффициент Кендалла |
нет |
нет |
Коэффициент Спирмена |
нет |
нет |
Критерий Аббе |
да |
нет |
Критерий Кокса-Стюарта |
нет |
нет |
Критерий Фостера-Стюарта |
нет |
нет |
Вывод: по совокупности результатов проверки большинство тестов позволяют сделать вывод об отсутствии тренда.
ПРЕОБРАЗОВАНИЕ ДАННЫХ К НОРМАЛЬНОМУ ЗАКОНУ РАСПРЕДЕЛЕНИЯ
Основы теории
Очень кратко вспомним основы теории (неплохо данные вопросы изложены в [11, глава 6]).
Мы прекрасно понимаем, что нормальное распределение - это не более, чем теоретическая модель реальных распределений, и на практике реальные данные подчиняются нормальному закону лишь более или менее приблизительно.
В чем же важность нормального распределения для регрессионного анализа?
При нарушении нормальности распределения оценки параметров регрессионных моделей, полученные методом наименьших квадратов (МНК-оценки) теряют свойство эффективности (хотя сохраняют свойства несмещенности и состоятельности).
В случае нарушения нормальности, особенно для распределений с "тяжелыми хвостами" возрастает вероятность появления статистически аномальных значений (выбросов), к которым МНК является очень чувствительным; один такой выброс может кардинально изменить значения параметров модели, полностью исказив картину.
В случае нормального распределения имеется прекрасно разработанный математический аппарат проверки гипотез. Непараметрический инструментарий не так обширен (например, критерии отсева выбросов привязаны к конкретному распределению (см. [1]); как быть исследователю, если условие нормальности не выполняется, а проверку на выбросы выполнить необходимо?).
В [11] приводятся данные об исследованиях устойчивости критериев проверки гипотез регрессионного анализа к нарушению нормальности распределения исходных данных. Установлено следующее:
В целом критерии для математического ожидания (критерий Стьюдента) сравнительно устойчивы к отклонениям от нормальности, а вот критерии для дисперсии (Фишера, Бартлетта) наоборот - весьма чувствительны [11, с.197].
При проверке гипотезы с использованием критерия Фишера нарушение нормальности влияет на распределение F-статистики критерия. Предложены корректировки числа степеней свободы для табличных значений статистики критерия [11, с.220-227].
Преобразование Бокса-Кокса
Правила преобразования данных к нормальному закону возможны самые разные (степенное, логарифмическое, обратное, обратного корня и т.д.) [14, с.39] в зависимости от асимметрии исходного распределения.
Г.Бокс и Д.Кокс предложили (Box, G. E. P.; Cox, D. R. An analysis of transformations. (With discussion). J. Roy. Statist. Soc. Ser. B 26 (1964), 211–252. https://mathscinet.ams.org/mathscinet-getitem?mr=192611) более формализованную процедуру. Преобразование Бокса-Кокса имеет вид:
Оптимальное значение параметра может быть найдено методом наибольшего правдоподобия. Подробнее про преобразование Бокса-Кокса - см. [8, с.180], а также https/en.wikipedia.org/wiki/Box-Cox_transformation, http://www.machinelearning.ru/wiki/index.php?title=Метод_Бокса-Кокса.
Обратное преобразование имеет вид:
В процессе регрессионного анализа преобразованию Бокса-Кокса может быть подвергнута одна или несколько переменных.
Предположим, в случае simple linear regression
закон распределения обеих переменных и
отличается от нормального, и обе переменные подвергаются преобразованию Бокса-Кокса:
Оценивать методом наименьших квадратов мы будем не параметры и
исходной модели, а параметры
и
модели, построенной по преобразованным данным:
Чтобы перейти от модели, построенной по преобразованным данным, к исходной модели, необходимо выполнить обратное преобразование (при ):
То есть, мы видим, что преобразование Бокса-Кокса превращает по сути превращает линейную регрессионную модель в нелинейную. В этом случае может возникнуть проблема с интерпретацией параметров. Вообще, вопросов с преобразованием Бокса-Кокса немало, но не будем пока останавливаться на них, а двинемся далее.
Определим ряд лямбда-функций, которые потребуются нам в дальнейшем при анализе регрессионных моделей с учетом преобразования Бокса-Кокса (будем использовать суффикс _func, чтобы не путать наименования функций с именами регрессионных моделей, которые используются при работе с модулем линейной регрессии Linear Regression (https://www.statsmodels.org/stable/regression.html):
Функция линейной регрессионной модели (SLRM - simple linear regression model):
SLRM_func = lambda x, b0, b1: b0 + b1*xФункция преобразования Бокса-Кокса:
boxcox_func = lambda x, lmbd: (x**lmbd - 1) / lmbd if lmbd != 0 else log(x)Функция преобразования, обратного преобразованию Бокса-Кокса:
inverse_boxcox_func = lambda x, lmbd: (1 + lmbd*x)**(1/lmbd) if lmbd != 0 else exp(x)Функция для обратного преобразования регрессионной модели - позволяет восстановить значения переменной
в зависимости от
по регрессионной модели, построенной при преобразовании Бокса-Кокса:
inverse_boxcox_SLRM_func = lambda x, b0_boxcox, b1_boxcox, lmbd_x, lmbd_y: inverse_boxcox_func(SLRM_func(boxcox_func(x, lmbd_x), b0_boxcox, b1_boxcox), lmbd_y)В этой функции использованы переменные:
x - исходные значения независимой переменной
;
b0_boxcox и b1_boxcox - параметры
и
модели, построенной по преобразованным данным;
lmbd_x и lmbd_y - параметры
и
преобразования Бокса-Кокса.
Функция возвращает расчетные значения переменной , оцененные по регрессионной модели $ \tilde{y}_i = \tilde{b}_0 + \tilde{b}_1 \cdot \tilde{x}_i + \tilde{\varepsilon}_i $ уже после обратного преобразования.
С помощью функции inverse_boxcox_SLRM_func мы сможем получать прогнозные значения переменной , а с помощью функции inverse_boxcox_func - значения границ доверительных интервалов.
Далее выполним преобразование Бокса-Кокса для переменных в нашей задаче с использованием стандартного инструментария scipy.
Среднемесячный расход топлива / Fuel Flow (Y)
Выполним преобразование Бокса-Кокса:
data = Y
print(f"Y = {Y}\n")
# Определяем оптимальный параметр преобразования Бокса-Кокса
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox_normmax.html#scipy.stats.boxcox_normmax
lmax_pearsonr_Y, lmax_mle_Y = sci.stats.boxcox_normmax(data, method='all')
print(f"lmax_pearsonr_Y = {lmax_pearsonr_Y}\t lmax_mle_Y = {lmax_mle_Y}\n")
# Выполняем преобразование Бокса-Кокса
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox.html#scipy.stats.boxcox
Y_boxcox = sci.stats.boxcox(data, lmbda=(lmax_mle_Y))
print(f"Y_boxcox = {Y_boxcox}\n")
# Проверяем преобразование Бокса-Кокса
Y_boxcox1 = boxcox_func(Y, lmax_mle_Y)
print(f"Y_boxcox1 = {Y_boxcox1}\n")
# Проверяем обратное преобразование
Y_inverse_boxcox = inverse_boxcox_func(Y_boxcox, lmax_mle_Y)
print(f"Y_inverse_boxcox = {Y_inverse_boxcox}\n")
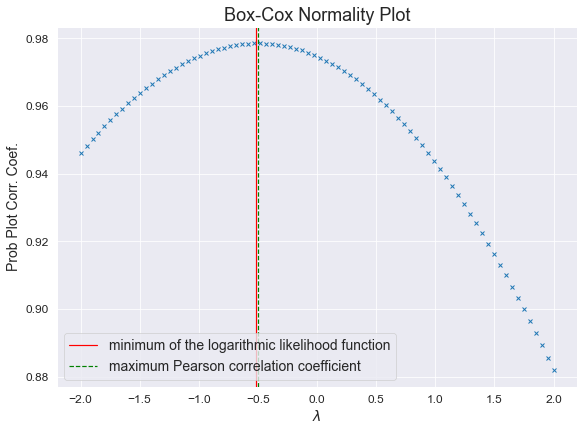
# Постоим график преобразования Бокса-Кокса
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox_normplot.html
fig, axes = plt.subplots(figsize=(297/INCH/1.254, 210/INCH/1.25))
sci.stats.boxcox_normplot(data, -2, 2, plot=axes)
axes.axvline(lmax_mle_Y, color='r', label = 'minimum of the logarithmic likelihood function')
axes.axvline(lmax_pearsonr_Y, color='g', ls='--', label = 'maximum Pearson correlation coefficient')
axes.grid(True)
axes.legend()
plt.show()
fig.savefig('graph/FuelFlow_boxcox_transform.jpg', orientation = "portrait", dpi = 300)
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox_llf.html#scipy.stats.boxcox_llf

Визуализация и проверка нормальности распределения после преобразование Бокса-Кокса:
# визуализация
graph_hist_boxplot_probplot_sns(
data=Y_boxcox,
data_min=1.0, data_max=2.0,
graph_inclusion='hbp',
data_label=r'$Y_{boxcox}$',
title_figure=Title_String, title_figure_fontsize=14,
title_axes=Variable_Name_Y + "\n(после преобразования Бокса-Кокса)",
file_name='graph/hist_boxplot_probplot_Y_boxcox_sns.png')
# проверка нормальности распределения
display(norm_distr_check (Y_boxcox, p_level=0.95))
# проверка наличия выбросов
print("Проверка наличия выбросов переменной Y (после преобразования Бокса-Кокса):\n")
result = detecting_outliers_mad_test(Y_boxcox)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])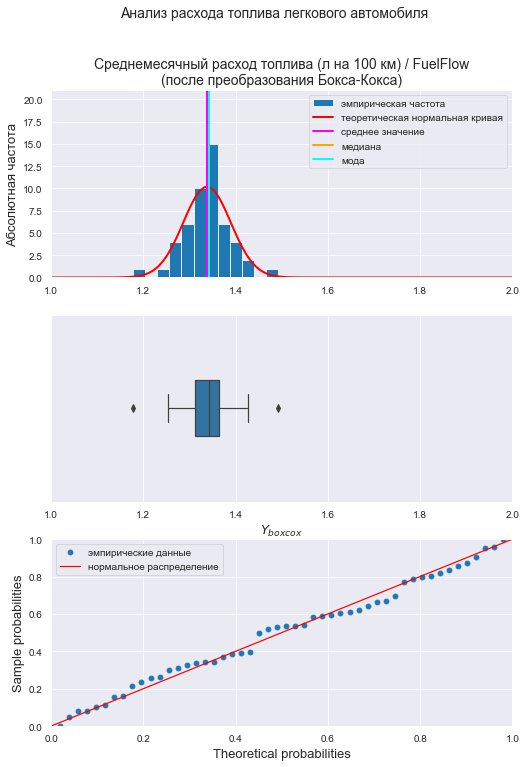
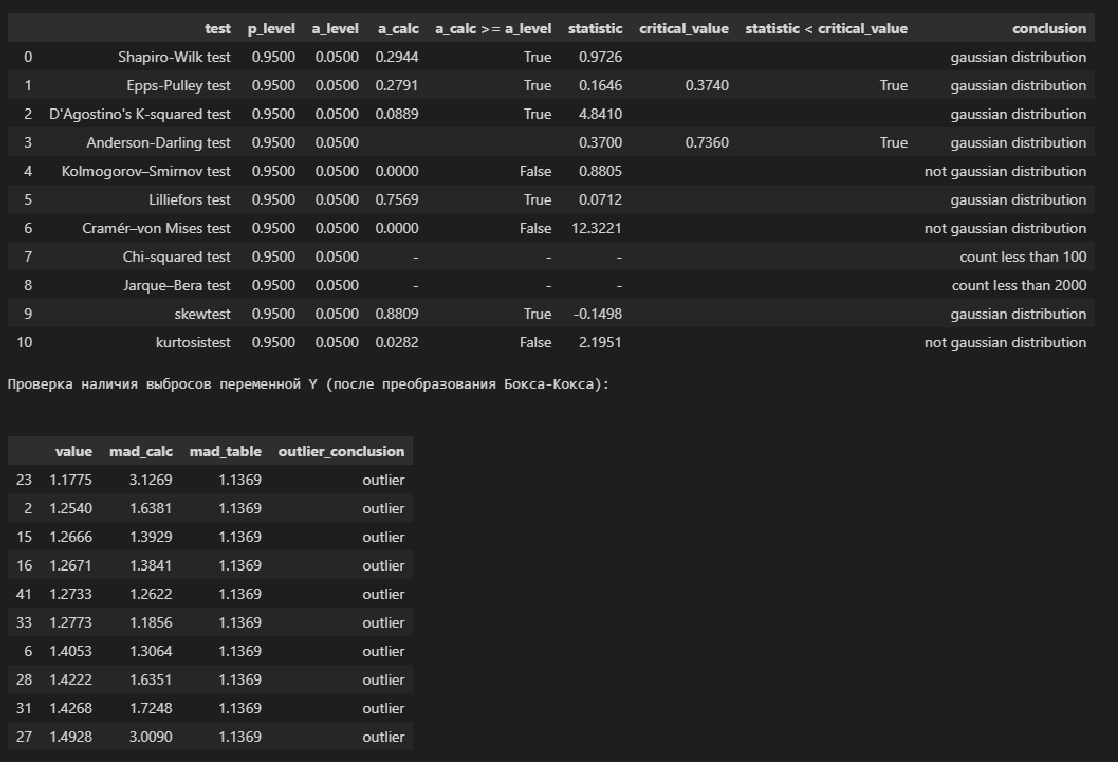
Вывод: большинство статистических тестов ПРИНИМАЮТ гипотезу о нормальном распределении, преобразованные данные можно считать нормально распределенными.
Пробег автомобиля за месяц / Mileage (X)
Выполним преобразование Бокса-Кокса:
data = X
print(f"X = {X}\n")
# Определяем оптимальный параметр преобразования Бокса-Кокса
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox_normmax.html#scipy.stats.boxcox_normmax
lmax_pearsonr_X, lmax_mle_X = sci.stats.boxcox_normmax(data, method='all')
print(f"lmax_pearsonr_X = {lmax_pearsonr_X}\t lmax_mle = {lmax_mle_X}\n")
# Выполняем преобразование Бокса-Кокса
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox.html#scipy.stats.boxcox
X_boxcox = sci.stats.boxcox(data, lmbda=(lmax_mle_X))
print(f"X_boxcox = {X_boxcox}\n")
# Проверяем преобразование Бокса-Кокса
X_boxcox1 = boxcox_func(X, lmax_mle_X)
print(f"X_boxcox1 = {X_boxcox1}\n")
# Проверяем обратное преобразование
X_inverse_boxcox = inverse_boxcox_func(X_boxcox, lmax_mle_X)
print(f"X_inverse_boxcox = {X_inverse_boxcox}\n")
# Постоим график преобразования Бокса-Кокса
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox_normplot.html
fig, axes = plt.subplots(figsize=(297/INCH/1.254, 210/INCH/1.25))
sci.stats.boxcox_normplot(data, -2, 2, plot=axes)
axes.axvline(lmax_mle_X, color='r', label = 'minimum of the logarithmic likelihood function')
axes.axvline(lmax_pearsonr_X, color='g', ls='--', label = 'maximum Pearson correlation coefficient')
axes.grid(True)
axes.legend()
plt.show()
fig.savefig('graph/FuelFlow_boxcox_transform.jpg', orientation = "portrait", dpi = 300)
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox_llf.html#scipy.stats.boxcox_llf


Визуализация и проверка нормальности распределения после преобразование Бокса-Кокса:
# визуализация
graph_hist_boxplot_probplot_sns(
data=X_boxcox,
data_min=0.0, data_max=150,
graph_inclusion='hbp',
data_label=r'$X_{boxcox}$',
title_figure=Title_String, title_figure_fontsize=14,
title_axes=Variable_Name_X1 + "\n(после преобразования Бокса-Кокса)",
file_name='graph/hist_boxplot_probplot_X_boxcox_sns.png')
# проверка нормальности распределения
display(norm_distr_check (X_boxcox, p_level=0.95))
# проверка наличия выбросов
print("Проверка наличия выбросов переменной X (после преобразования Бокса-Кокса):\n")
result = detecting_outliers_mad_test(X_boxcox)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])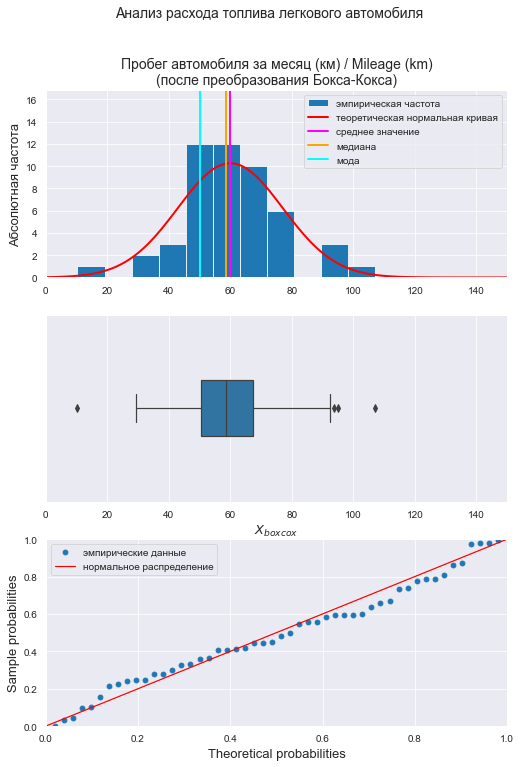

Вывод: большинство статистических тестов ПРИНИМАЮТ гипотезу о нормальном распределении, преобразованные данные можно считать нормально распределенными.
Зависимость расхода топлива (Y) от пробега (X) (после преобразования Бокса-Кокса)
graph_scatterplot_sns(
X_boxcox, Y_boxcox,
color='red',
title_figure=Title_String, title_figure_fontsize=12,
title_axes='Зависимость расхода топлива (Y) от пробега (X)' + "\n(после преобразования Бокса-Кокса)", title_axes_fontsize=14,
x_label=r'$X_{boxcox}$',
y_label=r'$Y_{boxcox}$',
label_fontsize=14, tick_fontsize=12,
label_legend='', label_legend_fontsize=12,
s=80,
#graph_size=(297/INCH, 210/INCH),
file_name='graph/scatterplot_X_boxcox_Y_boxcox_sns.png')
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционный анализ - это разведка перед построением регрессионной модели.
До преобразования Бокса-Кокса
Так как исходные данные не подчиняются нормальному закону распределения, рассчитаем непараметрические коэффициенты корреляции Кендалла и Спирмена:
display(rank_corr_coef_check(X, Y))
Вывод: между переменными имеется сильная корреляционная связь.
После преобразования Бокса-Кокса
Так как преобразованные данные подчиняются нормальному закону распределения, можем рассчитать как непараметрические (Кендалла и Спирмена), так и параметрические (Пирсона, корреляционное отношение) коэффициенты корреляции:
display(rank_corr_coef_check(X_boxcox, Y_boxcox))
display(corr_coef_check(X_boxcox, Y_boxcox, scale='Evans'))
display(corr_ratio_check(X_boxcox, Y_boxcox, orientation='XY', scale='Evans'))
display(line_corr_sign_check(X_boxcox, Y_boxcox, orientation='XY'))
Выводы:
Между переменными имеется сильная корреляционная связь (об этом свидетельствуют как непараметрические, так и параметрические показатели).
Проверка гипотезы о значимости отличия коэффициента линейной корреляции Пирсона и корреляционного отношения отклоняется, то есть связь между преобразованными данными может быть признана линейной.
РЕГРЕССИОННЫЙ АНАЛИЗ
Модель 1: исходные данные без изменения
Построим модель на основании исходных данных, взятых без всякого изменения (для сравнения в дальнейшем с другими моделями):
model_linear_ols = smf.ols(formula='Y ~ X', data=dataset_df)
result_linear_ols = model_linear_ols.fit()
print(result_linear_ols.summary2())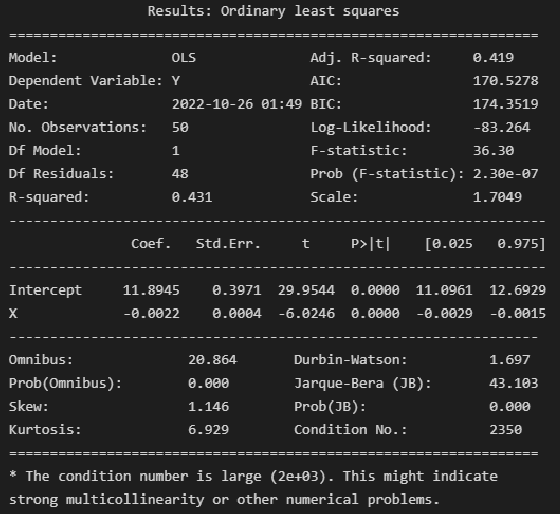
Выводы:
Модель объясняет 43.1% вариации независимой переменной (
).
Делать выводы о значимости коэффициента детерминации и коэффициентов регрессии не будем, так как не выполняется требование о нормальности закона распределения исходных данных.
Формализация модели:
# параметры модели
b0 = result_linear_ols.params['Intercept']
b1 = result_linear_ols.params['X']
# уравнение модели
regr_model_linear_ols_func = lambda x: SLRM_func(x, b0, b1)График модели:
R2 = round(result_linear_ols.rsquared, DecPlace)
legend_equation = f'линейная регрессия ' + r'$Y$' + f' = {b0:.4f} + {b1:.5f}{chr(183)}' + r'$X$' if b1 > 0 else \
f'линейная регрессия ' + r'$Y$' + f' = {b0:.4f} - {abs(b1):.5f}{chr(183)}' + r'$X$'
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=regr_model_linear_ols_func,
Xmin=X_min_graph, Xmax=X_max_graph,
Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=True,
title_figure=Task_Project,
title_axes = 'Линейная регрессионная модель',
x_label=Variable_Name_X1,
y_label=Variable_Name_Y,
label_legend_regr_model = legend_equation + '\n' + r'$R^2$' + f' = {R2}',
s=60,
file_name='graph/regression_plot_sns_linear_ols.png')
Ошибки аппроксимации модели:
(model_error_metrics, result) = regression_error_metrics(model_linear_ols, model_name='linear_ols')
display(result)
Вывод: модель хорошо аппроксимирует фактические данные.
Проверка нормальности распределения остатков:
res_Y = np.array(result_linear_ols.resid)
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y,
data_min=-4, data_max=6,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png')
norm_distr_check(res_Y)

Вывод: большинство статистических тестов ОТВЕРГАЮТ гипотезу о нормальном распределении.
Проверка автокорреляции по критерию Дарбина-Уотсона с помощью пользовательской функции Durbin_Watson_test (о применении данного критерия и данной функции я писал в своей статье https://habr.com/ru/post/693402/):
Durbin_Watson_test(res_Y, m=1, p_level=0.95)
Вывод: гипотеза о наличии автокорреляции ОТВЕРГАЕТСЯ.
Модель 2: преобразование Бокса-Кокса
Прямое преобразование, построение и анализ модели
Построение модели:
model_linear_boxcox_ols = smf.ols(formula='Y_boxcox ~ X_boxcox', data=dataset_df_boxcox)
result_linear_boxcox_ols = model_linear_boxcox_ols.fit()
print(result_linear_boxcox_ols.summary2())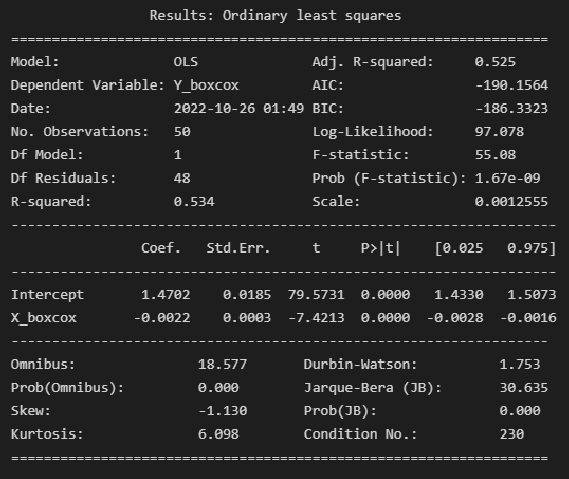
Выводы:
Модель объясняет 53.4% вариации независимой переменной (
).
Коэффициент детерминации ЗНАЧИМ, т.к. Prob (F-statistic) не превышает 0.05.
Коэффициенты регрессии значимы, т.к. P>|t| не превышает 0.05.
Формализация модели:
# параметры модели
b0_boxcox = result_linear_boxcox_ols.params['Intercept']
b1_boxcox = result_linear_boxcox_ols.params['X_boxcox']
# уравнение модели
regr_model_linear_boxcox_ols_func = lambda x: SLRM_func(x, b0_boxcox, b1_boxcox)График модели:
# Пользовательская функция
graph_regression_plot_sns(
X_boxcox, Y_boxcox,
regression_model=regr_model_linear_boxcox_ols_func,
#Xmin=X1_min_graph, Xmax=X1_max_graph,
#Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=True,
title_figure=Task_Project,
title_axes = 'Линейная регрессионная модель' + "\n(после преобразования Бокса-Кокса)",
x_label=r'$X_{boxcox}$',
y_label=r'$Y_{boxcox}$',
label_legend_regr_model = legend_equation + '\n' + r'$R^2$' + f' = {R2}',
s=60,
file_name='graph/regression_plot_sns_linear_boxcox_ols.png')
Ошибки аппроксимации модели:
(model_error_metrics, result) = regression_error_metrics(model_linear_boxcox_ols, model_name='linear_boxcox_ols')
display(result)
Вывод: модель хорошо аппроксимирует фактические данные.
Проверка нормальности распределения остатков:
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y_boxcox,
#data_min=-0.15, data_max=0.1,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели' + "\n(после преобразования Бокса-Кокса)", title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png')
norm_distr_check(res_Y_boxcox)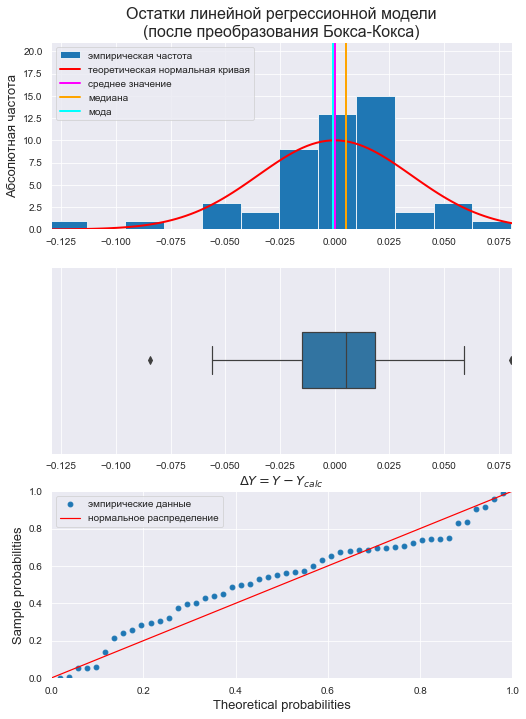

Вывод: большинство статистических тестов ОТВЕРГАЮТ гипотезу о нормальном распределении.
Проверка автокорреляции:
Durbin_Watson_test(res_Y_boxcox, m=1, p_level=0.95)
Вывод: гипотеза о наличии автокорреляции ОТВЕРГАЕТСЯ.
Обратное преобразование
Обратное преобразования для регрессионной модели:
# уравнение модели
inverse_regr_model_linear_boxcox_ols_func = lambda x: inverse_boxcox_SLRM_func(x, b0_boxcox, b1_boxcox, lmax_mle_X, lmax_mle_Y)legend_equation = f'линейная регрессия после обратного преобразования Бокса-Кокса'
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=inverse_regr_model_linear_boxcox_ols_func,
Xmin=X_min_graph, Xmax=X_max_graph,
Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=False,
title_figure=Task_Project,
title_axes = 'Линейная регрессионная модель' + "\n(после обратного преобразования Бокса-Кокса)",
x_label=Variable_Name_X1,
y_label=Variable_Name_Y,
label_legend_regr_model = legend_equation,
s=60,
#file_name='graph/regression_plot_sns_linear_boxcox_ols.png'
)
Вывод: модель хорошо аппроксимирует фактические данные.
(model_error_metrics_inverse, result_inverse) = regression_error_metrics(Yfact=Y, Ycalc=inverse_regr_model_linear_boxcox_ols_func(X), model_name='linear_boxcox_ols')
display(result_inverse)
Вывод: модель хорошо аппроксимирует фактические данные.
Модель 3: преобразование Бокса-Кокса с исключением аномальных значений
При построении предыдущей модели мы не смогли обеспечить нормальность распределения остатков даже с помощью преобразования Бокса-Кокса. Попробуем достичь этого, исключив аномальные значения (выбросы).
Исключение аномальных значений
Проверка наличия аномальных значений (выбросов) по критерию максимального абсолютного отклонения.
# Переменная X
print("Проверка наличия выбросов переменной X (после преобразования Бокса-Кокса):\n")
result = detecting_outliers_mad_test(X_boxcox)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
# Переменная Y
print("Проверка наличия выбросов переменной Y (после преобразования Бокса-Кокса):\n")
result = detecting_outliers_mad_test(Y_boxcox)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
Удаление аномальных значений (выбросов):
mask1 = dataset_df_boxcox['X_boxcox'] < 120
mask2 = dataset_df_boxcox['X_boxcox'] > 20
mask3 = dataset_df_boxcox['Y_boxcox'] < 1.5
mask4 = dataset_df_boxcox['Y_boxcox'] > 1.2
dataset_df_boxcox_clear = dataset_df_boxcox[mask1 & mask2 & mask3 & mask4]
display(dataset_df_boxcox_clear.describe())
X_boxcox_clear = np.array(dataset_df_boxcox_clear['X_boxcox'])
Y_boxcox_clear = np.array(dataset_df_boxcox_clear['Y_boxcox'])Прямое преобразование, построение и анализ модели
Построение модели:
model_linear_boxcox_clear_ols = smf.ols(formula='Y_boxcox_clear ~ X_boxcox_clear', data=dataset_df_boxcox_clear)
result_linear_boxcox_clear_ols = model_linear_boxcox_clear_ols.fit()
print(result_linear_boxcox_clear_ols.summary2())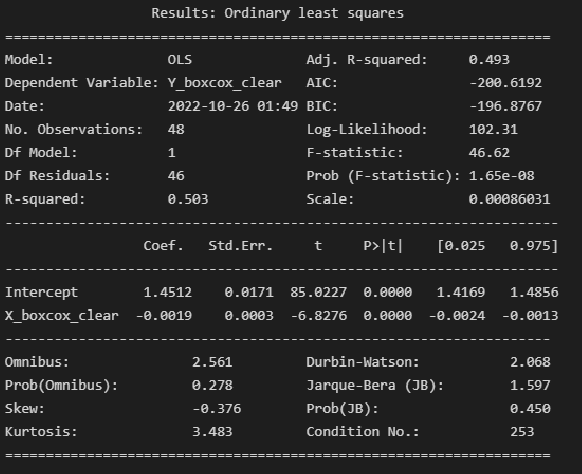
Выводы:
Модель объясняет 50.3% вариации независимой переменной (
).
Коэффициент детерминации ЗНАЧИМ, т.к. Prob (F-statistic) не превышает 0.05.
Коэффициенты регрессии значимы, т.к. P>|t| не превышает 0.05.
Формализация модели:
# параметры модели
b0_boxcox_clear = result_linear_boxcox_clear_ols.params['Intercept']
b1_boxcox_clear = result_linear_boxcox_clear_ols.params['X_boxcox_clear']
# уравнение модели
regr_model_linear_boxcox_clear_ols_func = lambda x: SLRM_func(x, b0_boxcox_clear, b1_boxcox_clear)График модели:
R2 = round(result_linear_boxcox_clear_ols.rsquared, DecPlace)
legend_equation = \
f'линейная регрессия ' + r'$Y_{boxcox-clear}$' + f' = {b0_boxcox_clear:.4f} + {b1_boxcox_clear:.5f}{chr(183)}' + r'$X_{boxcox-clear}$' if b1_boxcox_clear > 0 else \
f'линейная регрессия ' + r'$Y_{boxcox-clear}$' + f' = {b0_boxcox_clear:.4f} - {abs(b1_boxcox_clear):.5f}{chr(183)}' + r'$X_{boxcox-clear}$'
# Пользовательская функция
graph_regression_plot_sns(
X_boxcox_clear, Y_boxcox_clear,
regression_model=regr_model_linear_boxcox_clear_ols_func,
#Xmin=X1_min_graph, Xmax=X1_max_graph,
#Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=True,
title_figure=Task_Project,
title_axes = 'Линейная регрессионная модель' + "\n(после преобразования Бокса-Кокса и исключения аномальных значений)",
x_label=r'$X_{boxcox-clear}$',
y_label=r'$Y_{boxcox-clear}$',
label_legend_regr_model = legend_equation + '\n' + r'$R^2$' + f' = {R2}',
s=60,
file_name='graph/regression_plot_sns_linear_boxcox_clear_ols.png')
Ошибки аппроксимации модели:
(model_error_metrics, result) = regression_error_metrics(model_linear_boxcox_clear_ols, model_name='linear_boxcox_clear_ols')
display(result)
Вывод: модель хорошо аппроксимирует фактические данные.
Проверка нормальности распределения остатков:
res_Y_boxcox_clear = np.array(result_linear_boxcox_clear_ols.resid)
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y_boxcox_clear,
data_min=-0.15, data_max=0.1,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели' + "\n(после преобразования Бокса-Кокса)", title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png')
norm_distr_check(res_Y_boxcox_clear)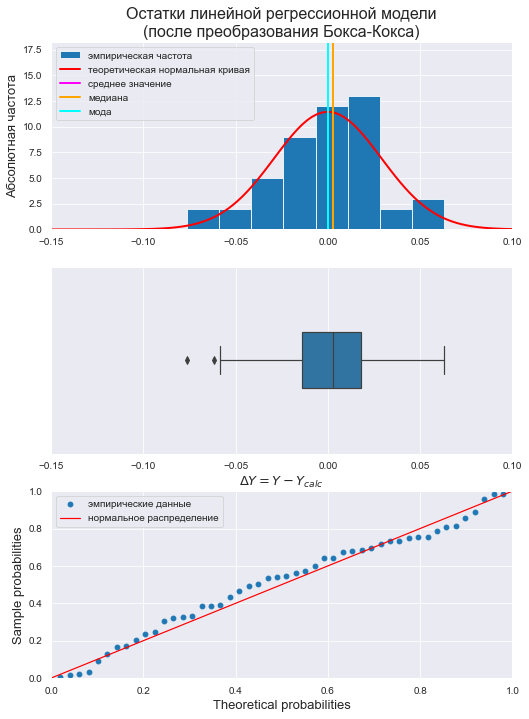

Вывод: большинство статистических тестов ПРИНИМАЮТ гипотезу о нормальном распределении.
Проверка адекватности модели:
regression_model_adequacy_check(result_linear_boxcox_clear_ols, p_level=0.95, model_name='linear_ols')
Вывод: регрессионная модель АДЕКВАТНА.
Проверка гетероскедастичности:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_boxcox_clear_ols, p_level=0.95, model_name='linear_boxcox_clear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_boxcox_clear_ols, p_level=0.95, model_name='linear_boxcox_clear_ols')
White_test_df = White_test(result_linear_boxcox_clear_ols, p_level=0.95, model_name='linear_boxcox_clear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Вывод: гипотеза о наличии гетероскедастичности ОТВЕРГАЕТСЯ.
Проверка автокорреляции:
Durbin_Watson_test(res_Y_boxcox_clear, m=1, p_level=0.95)
Вывод: гипотеза о наличии автокорреляции ОТВЕРГАЕТСЯ.
Обратное преобразование
# уравнение модели
inverse_regr_model_linear_boxcox_clear_ols_func = lambda x: inverse_boxcox_SLRM_func(x, b0_boxcox_clear, b1_boxcox_clear, lmax_mle_X, lmax_mle_Y)
legend_equation = f'линейная регрессия после обратного преобразования Бокса-Кокса'
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=inverse_regr_model_linear_boxcox_clear_ols_func,
Xmin=X_min_graph, Xmax=X_max_graph,
Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=False,
title_figure=Task_Project,
title_axes = 'Линейная регрессионная модель' + "\n(после обратного преобразования Бокса-Кокса)",
x_label=Variable_Name_X1,
y_label=Variable_Name_Y,
label_legend_regr_model = legend_equation,
s=60,
#file_name='graph/regression_plot_sns_linear_boxcox_ols.png'
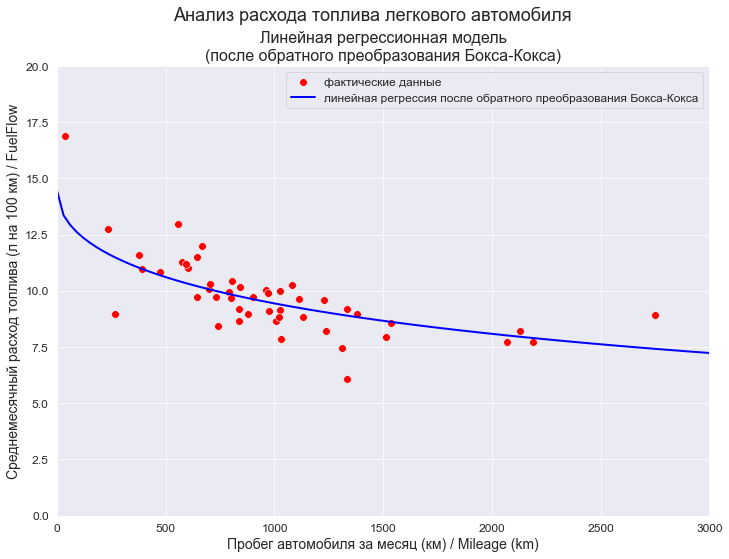
)
Ошибки аппроксимации модели:
(model_error_metrics, result) = regression_error_metrics(Yfact=Y, Ycalc=inverse_regr_model_linear_boxcox_clear_ols_func(X), model_name='inverse_linear_boxcox_clear_ols')
display(result)
Вывод: модель хорошо аппроксимирует фактические данные.
Прогнозирование
Для получения прогнозных значений и построения графика прогноза применим пользовательскую функцию graph_regression_pair_predict_plot_sns (об этой функции я писал ранее в своей статье https://habr.com/ru/post/690414/).
Вначале применим указанную функцию к преобразованным по Боксу-Коксу данным:
Укажем границы интервала прогнозирования:
# справочно: установленные границы для графиков
#(X_min_graph, X_max_graph) = (0, 3000)
#(Y_min_graph, Y_max_graph) = (0, 20)
# границы интервала прогнозирования по X
X_forecast_min = X_min_graph
X_forecast_max = X_max_graph
print(f'X_forecast = [{X_forecast_min}, {X_forecast_max}]')
# границы интервала прогнозирования по X_boxcox
X_forecast_min_boxcox = boxcox_func(X_forecast_min, lmax_mle_X)
X_forecast_max_boxcox = boxcox_func(X_forecast_max, lmax_mle_X)
print(f'X_forecast_boxcox = [{X_forecast_min_boxcox}, {X_forecast_max_boxcox}]')
# границы для отображения прогнозируемой величины Y_boxcox на графике
Y_forecast_min_boxcox_clear = np.min(Y_boxcox_clear)*0.99
Y_forecast_max_boxcox_clear = np.max(Y_boxcox_clear)*1.01
print(f'Y_forecast_boxcox_clear = [{Y_forecast_min_boxcox_clear}, {Y_forecast_max_boxcox_clear}]')
R2 = round(result_linear_boxcox_clear_ols.rsquared, DecPlace)
legend_equation = \
f'линейная регрессия ' + r'$Y_{boxcox-clear}$' + f' = {b0_boxcox_clear:.4f} + {b1_boxcox_clear:.5f}{chr(183)}' + r'$X_{boxcox-clear}$' if b1_boxcox_clear > 0 else \
f'линейная регрессия ' + r'$Y_{boxcox-clear}$' + f' = {b0_boxcox_clear:.4f} - {abs(b1_boxcox_clear):.5f}{chr(183)}' + r'$X_{boxcox-clear}$'
forecast_boxcox_clear_df = graph_regression_pair_predict_plot_sns(
model_fit=result_linear_boxcox_clear_ols,
regression_model_in=regr_model_linear_boxcox_clear_ols_func,
Xmin=X_forecast_min_boxcox, Xmax=X_forecast_max_boxcox, Nx=25,
Ymin_graph=Y_forecast_min_boxcox_clear, Ymax_graph=Y_forecast_max_boxcox_clear,
title_figure=Task_Project, title_figure_fontsize=16,
title_axes = 'Линейная регрессионная модель' + "\n(после преобразования Бокса-Кокса и исключения аномальных значений)", title_axes_fontsize=14,
x_label=r'$X_{boxcox-clear}$',
y_label=r'$Y_{boxcox-clear}$',
label_legend_regr_model = legend_equation + '\n' + r'$R^2$' + f' = {R2}',
s=50,
result_output=True,
file_name='graph/regression_plot_lin.png')
Таблица расчета прогнозных данных после преобразования Бокса-Кокса - включает следующие столбцы:
x_calc - значения переменной X, преобразованные по Боксу-Коксу;
y_calc - расчетные значения переменной Y (рассчитаны на основании модели, построенной на данных после преобразования Бокса-Кокса);
y_calc_mean_ci_low, y_calc_mean_ci_upp - границы доверительного интервала средних значений переменной Y;
y_calc_predict_ci_low, y_calc_predict_ci_upp - границы доверительного интервала индивидуальных значений переменной Y.
display(forecast_boxcox_clear_df)
Теперь на основании полученных табличных данных выполним обратное преобразование Бокса-Кокса и построим график прогноза уже для непреобразованных данных:
# создаем новую таблицу расчета прогнозных данных - после обратного преобразования Боса-Кокса
inverse_forecast_boxcox_clear_df = forecast_boxcox_clear_df.copy()
# обратное преобразование значений переменной X
inverse_forecast_boxcox_clear_df['x_calc'] = inverse_boxcox_func(inverse_forecast_boxcox_clear_df['x_calc'].values, lmax_mle_X)
# обратное преобразование значений переменной Y и границ доверительных интервалов
for col in inverse_forecast_boxcox_clear_df.columns[1:]:
inverse_forecast_boxcox_clear_df[col] = inverse_boxcox_func(inverse_forecast_boxcox_clear_df[col].values, lmax_mle_Y)
display(inverse_forecast_boxcox_clear_df)
Построим график:
legend_equation = f'линейная регрессия после обратного преобразования Бокса-Кокса'
graph_size=(297/INCH, 210/INCH)
fig, axes = plt.subplots(figsize=graph_size)
title_figure=Task_Project
title_figure_fontsize=16
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
title_axes = 'Линейная регрессионная модель' + "\n(после обратного преобразования Бокса-Кокса)"
title_axes_fontsize=14
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=50,
color='red',
ax=axes)
x_calc = inverse_forecast_boxcox_clear_df['x_calc']
y_calc = inverse_forecast_boxcox_clear_df['y_calc']
# график регрессионной модели
sns.lineplot(
x=x_calc, y=y_calc,
color='blue',
linewidth=2,
legend=True,
label=legend_equation,
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = inverse_forecast_boxcox_clear_df['y_calc_mean_ci_low']
plt.plot(
x_calc, Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = inverse_forecast_boxcox_clear_df['y_calc_mean_ci_upp']
plt.plot(
x_calc, Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = inverse_forecast_boxcox_clear_df['y_calc_predict_ci_low']
plt.plot(
x_calc, Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = inverse_forecast_boxcox_clear_df['y_calc_predict_ci_upp']
plt.plot(
x_calc, Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlabel(Variable_Name_X1, fontsize = 14)
axes.set_ylabel(Variable_Name_Y, fontsize = 14)
#axes.tick_params(labelsize = 12)
axes.set_xlim(X_forecast_min, X_forecast_max)
axes.set_ylim(Y_min_graph, Y_max_graph)
axes.legend(prop={'size': 12})
plt.show()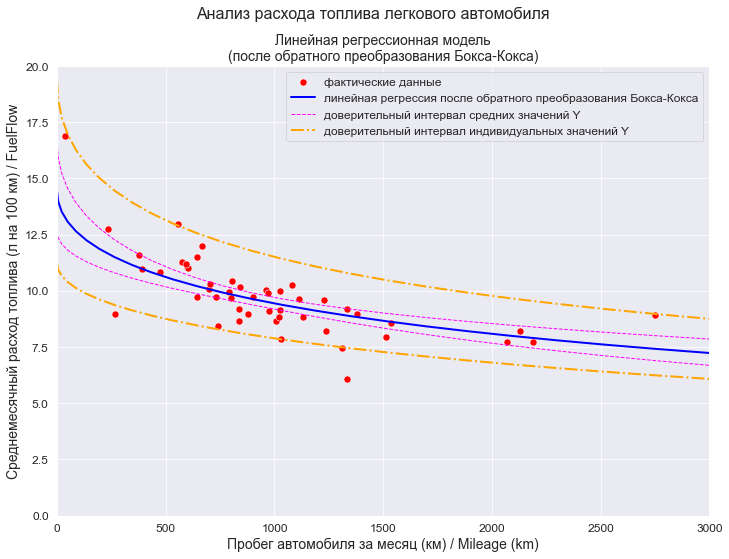
Ну вот, собственно говоря, на этом этапе задача решена - получены табличные значения и график прогноза.
Модель 4: прочие преобразования
Постановка задачи
Итак, на предыдущем этапе мы получили регрессионную модель, которая удовлетворяет основным требованиям: исходные данные преобразованы к нормально распределенным, остатки модели также нормально распределены, модель хорошо аппроксимирует фактические данные, адекватна и значима, гетероскедастичность отсутствует. Казалось бы - чего еще желать?
Однако, чтобы добиться этого, нам пришлось исключить из исходных данных аномальные значения (выбросы). Само по себе это, конечно, не трагедия, однако объем выборки уменьшился, а ,как известно, любое значение несет в себе ценную статистическую информацию.
В связи с этим возник вопрос - если уж преобразование Бокса-Кокса не дает нужного эффекта, можно ли подобрать такое преобразование, которое позволило бы нам получить регрессионную модель, пригодную для использования, без исключения из выборки значений?
Преобразование будем подбирать таким образом, чтобы обеспечить одновременное выполнение следующих условий:
распределение преобразованных переменных X_transform и Y_transform должно быть нормальным;
регрессионная модуль, построенная на основе преобразованных переменных, должна быть адекватной и значимой;
распределение остатков регрессионной модели должно быть нормальным.
На возможную гетероскедастичность закроем глаза - взвешенный МНК нам в помощь.
Выбор критерия
Прежде всего определимся с критерием, по которому будем оценивать нормальность распределения. Число критериев нормальности весьма велико: в справочнике Кобзаря А.И. приводится 21 критерий [1, глава 3.2], в монографии Лемешко Б.Ю. [4] проанализировано уже 50 критериев. При этом исследователи ранжируют критерии в зависимости от особенностей исходных данных: одни и те же критерии при разной асимметрии и эксцессе могут имеют различную мощность.
Стандартный статистический инструментарий python (библиотека scipy) предлагает нам следующие критерии нормальности:
Шапиро-Уилка
Д'Агостино
Андерсона-Дарлинга
Колмогорова-Смирнова
Лиллиефорса
Крамера-Мизеса-Смирнова (омега-квадрат)
Пирсона (хи-квадрат)
Харке-Бера
асимметрии и эксцесса.
Дополнительно мы еще можем добавить к ним критерий Эппса-Палли (об этом я писал ранее в своей статье https://habr.com/ru/post/685582/).
Наши исходные данные имеют следующие свойства:
переменная X: значительная правосторонняя асимметрия (As = 1.2937), островершинное распределение (Es = 5.3008);
переменная Y: значительная правосторонняя асимметрия (As = 1.4066), островершинное распределение (Es = 7.5286).
Кобзарь А.И. в этом случае рекомендует [1, с.278] следующие критерии из доступных нам (по степени убывания мощности):
Шапиро-Уилка
Д'Агостино
хи-квадрат
Андерсона-Дарлинга
Колмогорова-Смирнова
Крамера-фон Мизеса.
Рекомендации Лемешко Б.Ю. [4, с.369] дифференцированы в зависимости от вида конкурирующей гипотезы; в качестве таких гипотез рассматриваются различные виды распределений, отличных от нормального:
конкурирующая гипотеза H1: обобщенное нормальное распределение (плосковершинное);
конкурирующая гипотеза H2: логистическое распределение (наиболее близкое к нормальному);
конкурирующая гипотеза H3: распределение Лапласа (островершинное).
В нашем случае конкурирующей гипотезой будет H3. Для таких распределений рекомендуется использовать следующие критерии из доступных нам (по степени убывания мощности):
Харке-Бера
Д'Агостино
Эппса-Палли
Андерсона-Дарлинга
Крамера-фон Мизеса
Шапиро-Уилка
Колмогорова
хи-квадрат
Как видим, рекомендации противоречивые. При этом в справочнике [Кобзаря А.И.] автор ссылается на исследование Шапиро, Уилка и Чена 1968 г. (номер 243 в списке источников), а ранжирование Лемешко Б.Ю. основано на исследованиях, выполненных гораздо позже (с 1990-х гг. по наше время) методом статистического моделирования.
Критерий Харке-Бера, который в рейтинге Лемешко Б.Ю. стоит на первом месте, является асимптотическим, расчетное значение имеет распределение хи-квадрат, поэтому данный критерий рекомендуют применять только для больших выборок (см. https://en.wikipedia.org/wiki/Jarque–Bera_test). В нашем случае очевидно, что он не подходит.
Остановимся на следующих критериях: Д'Агостино, Эппса-Палли, ну и включим в список старый добрый критерий Шапиро-Уилка.
Выбор вида преобразования
Вот это самое интересное. Вариантов может быть немало, но мы остановимся на рекомендациях, данных в работе [14, с.40] для распределений с правосторонней асимметрией рекомендуется степенное преобразование.
Вычисления
Определим такие интервалы интервалы значений параметров степенного преобразования
и
, внутри которых преобразованные переменные
и
подчиняются нормальному закону распределения (т.е. расчетный уровень значимости превышает 0.05), в результате получим некую прямоугольную область в координатах
:
X = np.array(data_df['Mileage'])
Y = np.array(data_df['FuelFlow'])
# степенное преобразование
alpha_count = 200
alpha_list_x = np.linspace(-0.25, 1.25, alpha_count)
alpha_list_y = np.linspace(-2.5, 1.5, alpha_count)
# критерий Д'Агостино
a_calc_K2_list_x = [sci.stats.normaltest(X**alpha).pvalue for alpha in alpha_list_x]
a_calc_K2_list_y = [sci.stats.normaltest(Y**alpha).pvalue for alpha in alpha_list_y]
# критерий Эппса-Палли
a_calc_EP_list_x = [Epps_Pulley_test(X**alpha)['a_calc'].values[0] for alpha in alpha_list_x]
a_calc_EP_list_y = [Epps_Pulley_test(Y**alpha)['a_calc'].values[0] for alpha in alpha_list_y]
# критерий Шапиро-Уилка
a_calc_SW_list_x = [sci.stats.shapiro(X**alpha).pvalue for alpha in alpha_list_x]
a_calc_SW_list_y = [sci.stats.shapiro(Y**alpha).pvalue for alpha in alpha_list_y]
# уровень значимости
a_level_list = np.linspace(0.05, 0.05, alpha_count)
# график
fig = plt.figure(figsize=(297/INCH, 420/INCH))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
fig.suptitle(f'Сопоставление областей принятия гипотезы\n о нормальном распределении\n' +
'для степенного преобразования ' + r'$Y_{transform} = X^{\alpha}$', fontsize = 18)
ax1.set_title("для переменной X", fontsize = 16)
ax2.set_title("для переменной Y", fontsize = 16)
legend_text = [
"критерий Д'Агостино",
'критерий Эппса-Палли',
'критерий Шапиро-Уилка',
'заданный уровень значимости ' + r'$a_{level}=0.05$']
ax1.plot(alpha_list_x, a_calc_K2_list_x, linestyle = "-", linewidth = 1)
ax1.plot(alpha_list_x, a_calc_EP_list_x, linestyle = "-", linewidth = 1)
ax1.plot(alpha_list_x, a_calc_SW_list_x, linestyle = "-", linewidth = 1)
ax1.plot(alpha_list_x, a_level_list, linestyle = "-", linewidth = 2, color='red')
ax1.legend(legend_text, fontsize = 12)
ax1.set_xlabel(r'$\alpha_{x}$')
ax1.set_ylabel(r'Расчетный уровень значимости $a_{calc}$')
ax2.plot(alpha_list_y, a_calc_K2_list_y, linestyle = "-", linewidth = 1)
ax2.plot(alpha_list_y, a_calc_EP_list_y, linestyle = "-", linewidth = 1)
ax2.plot(alpha_list_y, a_calc_SW_list_y, linestyle = "-", linewidth = 1)
ax2.plot(alpha_list_y, a_level_list, linestyle = "-", linewidth = 2, color='red')
ax2.legend(legend_text, fontsize = 12)
ax2.set_xlabel(r'$\alpha_{y}$')
ax2.set_ylabel(r'Расчетный уровень значимости $a_{calc}$')
plt.show()
Для точного определения границ этой области воспользуемся функциями интерполяции библиотеки scipy:
-
Интерполяция кубическими сплайнами и определение корней сплайнов (для переменной X):
# корни кривой для критерия Д'Агостино
splrep_a_calc_K2_x = sci.interpolate.splrep(alpha_list_x, np.array(a_calc_K2_list_x) - a_level, s=0) # интерполяция
root_interp_a_calc_K2_x = sci.interpolate.sproot(splrep_a_calc_K2_x) # нахождение корней сплайна
print(f"Корни кривой для критерия Д'Агостино: {root_interp_a_calc_K2_x}")
interp_a_calc_K2_x = sci.interpolate.interp1d(alpha_list_x, a_calc_K2_list_x, kind='cubic') # проверка корней
print(f'Проверка корней: {interp_a_calc_K2_x(root_interp_a_calc_K2_x)}\n')
# корни кривой для критерия Эппса-Палли
splrep_a_calc_EP_x = sci.interpolate.splrep(alpha_list_x, np.array(a_calc_EP_list_x) - a_level, s=0) # интерполяция
root_interp_a_calc_EP_x = sci.interpolate.sproot(splrep_a_calc_EP_x) # нахождение корней сплайна
print(f"Корни кривой для критерия Эппса-Палли: {root_interp_a_calc_EP_x}")
interp_a_calc_EP_x = sci.interpolate.interp1d(alpha_list_x, a_calc_EP_list_x, kind='cubic') # проверка корней
print(f'Проверка корней: {interp_a_calc_EP_x(root_interp_a_calc_EP_x)}\n')
# корни кривой для критерия Шапиро-Уилка
splrep_a_calc_SW_x = sci.interpolate.splrep(alpha_list_x, np.array(a_calc_SW_list_x) - a_level, s=0) # интерполяция
root_interp_a_calc_SW_x = sci.interpolate.sproot(splrep_a_calc_SW_x) # нахождение корней сплайна
print(f"Корни кривой для критерия Шапиро-Уилка: {root_interp_a_calc_SW_x}")
interp_a_calc_SW_x = sci.interpolate.interp1d(alpha_list_x, a_calc_SW_list_x, kind='cubic') # проверка корней
print(f'Проверка корней: {interp_a_calc_SW_x(root_interp_a_calc_SW_x)}\n')
# определяем область допустимых значений для параметра степенного преобразования
alpha_x_min = max(
root_interp_a_calc_K2_x[0],
root_interp_a_calc_EP_x[0],
root_interp_a_calc_SW_x[0]
)
alpha_x_max = min(
root_interp_a_calc_K2_x[1],
root_interp_a_calc_EP_x[1],
root_interp_a_calc_SW_x[1]
)
print(f'Область допустимых значений для параметра степенного преобразования: {[alpha_x_min, alpha_x_max]}')
Интерполяция кубическими сплайнами и определение корней сплайнов (для переменной Y):
# корни кривой для критерия Д'Агостино
splrep_a_calc_K2_y = sci.interpolate.splrep(alpha_list_y, np.array(a_calc_K2_list_y) - a_level, s=0) # интерполяция
root_interp_a_calc_K2_y = sci.interpolate.sproot(splrep_a_calc_K2_y) # нахождение корней сплайна
print(f"Корни кривой для критерия Д'Агостино: {root_interp_a_calc_K2_y}")
interp_a_calc_K2_y = sci.interpolate.interp1d(alpha_list_y, a_calc_K2_list_y, kind='cubic') # проверка корней
print(f'Проверка корней: {interp_a_calc_K2_y(root_interp_a_calc_K2_y)}\n')
# корни кривой для критерия Эппса-Палли
splrep_a_calc_EP_y = sci.interpolate.splrep(alpha_list_y, np.array(a_calc_EP_list_y) - a_level, s=0) # интерполяция
root_interp_a_calc_EP_y = sci.interpolate.sproot(splrep_a_calc_EP_y) # нахождение корней сплайна
print(f"Корни кривой для критерия Эппса-Палли: {root_interp_a_calc_EP_y}")
interp_a_calc_EP_y = sci.interpolate.interp1d(alpha_list_y, a_calc_EP_list_y, kind='cubic') # проверка корней
print(f'Проверка корней: {interp_a_calc_EP_y(root_interp_a_calc_EP_y)}\n')
# корни кривой для критерия Шапиро-Уилка
splrep_a_calc_SW_y = sci.interpolate.splrep(alpha_list_y, np.array(a_calc_SW_list_y) - a_level, s=0) # интерполяция
root_interp_a_calc_SW_y = sci.interpolate.sproot(splrep_a_calc_SW_y) # нахождение корней сплайна
print(f"Корни кривой для критерия Шапиро-Уилка: {root_interp_a_calc_SW_y}")
interp_a_calc_SW_y = sci.interpolate.interp1d(alpha_list_y, a_calc_SW_list_y, kind='cubic') # проверка корней
print(f'Проверка корней: {interp_a_calc_SW_y(root_interp_a_calc_SW_y)}\n')
# определяем область допустимых значений для параметра степенного преобразования
alpha_y_min = max(
root_interp_a_calc_K2_y[0],
root_interp_a_calc_EP_y[0],
root_interp_a_calc_SW_y[0]
)
alpha_y_max = min(
root_interp_a_calc_K2_y[1],
root_interp_a_calc_EP_y[1],
root_interp_a_calc_SW_y[1]
)
print(f'Область допустимых значений для параметра степенного преобразования: {[alpha_y_min, alpha_y_max]}')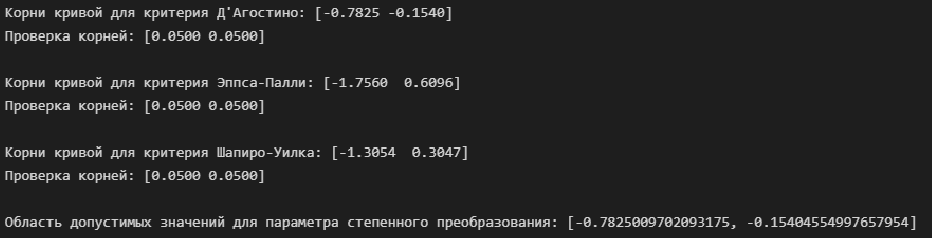
Полученную прямоугольную область разобьем по сетке на отдельные подобласти, каждая из которых соответствует паре значений
; для каждой пары значений выполним преобразование Бокса-Кокса, построим регрессионную модель и проверим гипотезу о нормальности распределения остатков по критерию Эппса-Палли:
alpha_count_x = 50
alpha_count_y = 100
alpha_calc_list_x = np.linspace(alpha_x_min, alpha_x_max, alpha_count_x)
alpha_calc_list_y = np.linspace(alpha_y_min, alpha_y_max, alpha_count_y)
number_list_x = np.array([])
number_list_y = np.array([])
alpha_list_x = np.array([])
alpha_list_y = np.array([])
a_calc_list = np.array([])
for i, alpha_x in enumerate(alpha_calc_list_x):
for j, alpha_y in enumerate(alpha_calc_list_y):
X_transform = X**alpha_x
Y_transform = Y**alpha_y
X = sm.add_constant(X)
model_linear_ols_1 = sm.OLS(Y_transform, X_transform)
result_linear_ols_1 = model_linear_ols_1.fit()
Y_transform_res = result_linear_ols_1.resid
number_list_x = np.append(number_list_x, i)
number_list_y = np.append(number_list_y, j)
alpha_list_x = np.append(alpha_list_x, alpha_x)
alpha_list_y = np.append(alpha_list_y, alpha_y)
a_calc_list = np.append(a_calc_list, Epps_Pulley_test(Y_transform_res)['a_calc'].values[0])
print(f'np.amax(a_calc_list) = {np.amax(a_calc_list)}')
График, иллюстрирующий зависимость расчетного уровня значимости критерия Эппса-Палли от параметров степенного преобразования:
fig = plt.figure(figsize=(210/INCH, 297/INCH))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(alpha_list_x, alpha_list_y, a_calc_list)
ax.set_zlim(0, 0.06)
ax.set_xlabel(r'$\alpha_x$', fontsize=16)
ax.set_ylabel(r'$\alpha_y$', fontsize=16)
ax.set_zlabel(r'$a_{calc}$', fontsize=16)
Вывод: максимальное значение расчетного уровня значимости при проверке гипотезы о нормальности распределения остатков по критерию Эппса-Палли внутри прямоугольной области допустимых значений параметров степенного преобразования не превышает 0.05, то есть гипотеза о нормальности распределения остатков ОТВЕРГАЕТСЯ внутри всей прямоугольной области допустимых значений. Степенное преобразование не позволяет нам получить регрессионную модель с нормально распределенными остатками. Наша попытка окончилась неудачей.
Можно, конечно, пробовать другие преобразования, но в данном обзоре мы этим заниматься не будем. Отрицательный результат - тоже результат.
Сравнение результатов
Итак, сравним полученные нами регрессионные модели:

Информационный критерий Акаике (AIC) и байесовский информационный критерий (BIC) свидетельствуют о том, что модель №3 является наилучшей.
Сводный график все полученных нами регрессионных моделей:
X = np.array(data_df['Mileage'])
Y = np.array(data_df['FuelFlow'])
Xmin=X_min_graph
Xmax=X_max_graph
Ymin=Y_min_graph
Ymax=Y_max_graph
fig, axes = plt.subplots(figsize=(420/INCH, 297/INCH))
title_figure=Task_Project
fig.suptitle(title_figure, fontsize = 18)
title_axes = 'Сводка результатов регрессионного анализа'
axes.set_title(title_axes, fontsize = 16)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=50,
color='red',
ax=axes)
# график регрессионной модели 1
nx = 100
hx = (Xmax - Xmin)/(nx - 1)
x1 = np.linspace(Xmin, Xmax, nx)
y1 = regr_model_linear_ols_func(x1)
sns.lineplot(
x=x1, y=y1,
color='blue',
linewidth=1,
legend=True,
label='линейная регрессионная модель по исходным данным',
ax=axes)
# график регрессионной модели 2
y2 = inverse_regr_model_linear_boxcox_ols_func(x1)
sns.lineplot(
x=x1, y=y2,
color='magenta',
linewidth=1,
legend=True,
label='линейная регрессионная модель после преобразования Бокса-Кокса',
ax=axes)
# график регрессионной модели 3
y3 = inverse_regr_model_linear_boxcox_clear_ols_func(x1)
sns.lineplot(
x=x1, y=y3,
color='cyan',
linewidth=1,
legend=True,
label='линейная регрессионная модель после преобразования Бокса-Кокса и исключения аномальных значений',
ax=axes)
axes.set_xlim(Xmin, Xmax)
axes.set_ylim(Ymin, Ymax)
axes.set_xlabel(Variable_Name_X1, fontsize = 14)
axes.set_ylabel(Variable_Name_Y, fontsize = 14)
axes.legend(prop={'size': 12})
plt.show()
Результаты сравнения моделей:
Получены несколько линейных регрессионных моделей (№№1-3).
Все модели обеспечивают удовлетворительное качество аппроксимации исходных данных.
Только модель №3 обеспечивает нормальность распределения остатков и отсутствие гетероскедастичности.
Вывод: для использования рекомендуется регрессионная модель №3.
ИТОГИ
Итак, подведем итоги:
мы рассмотрели особенности регрессионного анализа для простой линейной регрессии (simple linear regression) в случае, когда исходные данные не подчиняются нормальному закону распределения с использованием преобразования Бокса-Кокса;
рассмотрели возможную методику подбора параметра степенного преобразования к нормальному закону распределения (хоть в случае наших исходных данных такое преобразование и не привело к удачному результату);
разобрали способы проверки тренда и случайности, которые необходимы при работе с данными, выраженными в виде временных рядов;
также предложен ряд пользовательских функций, облегчающих работу исследователя и уменьшающих размер программного кода.
Само собой, мы рассмотрели в рамках данного обзора довольно простую математическую модель, но принципы и подходы остаются неизменными и для моделей более высокой сложности.
Дальнейшие темы для рассмотрения - построение нелинейных регрессионных моделей, а также непараметрические методы регрессионного анализа.
Исходный код находится в моем репозитории на GitHub (https://github.com/AANazarov/Statistical-methods).
Надеюсь, данный обзор поможет специалистам DataScience в работе.
ЛИТЕРАТУРА
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. - М.: ФИЗМАТЛИТ, 2006. - 816 с.
Болшев Л.Н., Смирнов Н.В. Таблицы математической статистики. - М.: Наука. Главная редакция физико-математической литературы, 1983. - 416 с.
Лемешко Б.Ю. и др. Статистический анализ данных, моделирование и исследование вероятностных закономерностей. Компьютерный подход. - Новосибирск: Изд-во НГТУ, 2011. - 888 с.
Лемешко Б.Ю. Критерии проверки отклонения распределения от нормального закона. Руководство по применению. - 2-е изд., перераб. и доп. - Москва: ИНФРА-М, 2023. - 353 с.
Лемешко Б.Ю., Веретельникова И.В. Критерии проверки гипотез о случайности и отсутствии тренда. Руководство по применению. - Москва: ИНФРА-М, 2021. - 221 с.
Айвазян С.А. и др. Прикладная статистика: Основы моделирования и первичная обработка данных. - М.: Финансы и статистика, 1983. - 471 с.
Айвазян С.А. и др. Прикладная статистика: Исследование зависимостей. - М.: Финансы и статистика, 1985. - 487 с.
Айвазян С.А. Прикладная статистика. Основы эконометрики: В 2 т. - Т.2: Основы эконометрики. - 2-е изд., испр. - М.: ЮНИТИ-ДАНА, 2001. - 432 с.
Сидоренко Е.В. Методы математической обработки в психологии. - СПб.: ООО "Речь", 2002. - 350 с.
Котеров А.Н. и др. Сила связи. Сообщение 2. Градации величины корреляции. - Медицинская радиология и радиационная безопасность. 2019. Том 64. № 6. с.12–24 (https://medradiol.fmbafmbc.ru/journal_medradiol/abstracts/2019/6/12-24_Koterov_et_al.pdf).
Вучков И. и др. Прикладной линейный регрессионный анализ / пер. с болг. - М.: Финансы и статистика, 1987. - 239 с.
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. - М.: Финансы и статистика, 1983. - 302 с.
Четыркин Е.М. Статистические методы прогнозирования. - М.: Статистика, 1977. - 200 с.
Львовский Е.Н. Статистические методы построения эмпирических формул. - М.: Высшая школа, 1988. - 239 с.
Комментарии (3)

Ad_fesha
26.10.2022 11:54Это одна из самых информативных статей, с которыми я сталкивался на хабре.
В закладки - однозначно
bez_moto_life_nety
Идеально
adeshere
Идеально
Спасибо автору за очень взвешенный, методически выверенный подход! Сейчас даже в научных публикациях авторы сплошь и рядом хватаются за первый попавшийся критерий, даже не всегда проверяя - удовлетворяют ли данные его условиям применимости. Фактически при этом они неявно постулируют кучу допущений, среди которых половина заведомо некорректна. А если попытаешься в отзыве намекнуть, что хорошо бы такие допущения сформулировать явно (даже не проверять выполнение - а просто перечислить требования критерия) - то просто не понимают, к чему придирается рецензент. Как же так, мы ведь применили для анализа данных самую последнюю версию самой модной программы! Вот вам, дорогая редакция, скриншот кнопки, которую мы нажимали, а вот скриншот цифры, которую мы скопировали с экрана. И вообще, дайте другого рецензента - у этого, видимо, "личная неприязнь"...
Им бы вот эту статью прочитать, для начала.
Единственное, что меня удручает после прочтения: почему нет заслуженных плюсов автору и статье? Неужели тема аккуратной статистической обработки настолько далека от народа?