

Эта статья — адаптация презентации Петра Новойски (Piotr Nowojski) на Flink Forward Berlin 2017. Запись презентации и слайды можно найти на сайте Flink Forward Berlin.
Релиз Apache Flink 1.4.0 в декабре 2017 года стал знаковым событием для потоковой обработки данных с помощью Flink: была представлена новая фича под названием TwoPhaseCommitSinkFunction (соответствующий issue в Jira), которая извлекает общую логику протокола двухфазной фиксации транзакции (two-phase commit protocol) и позволяет создавать end-to-end exactly-once приложения с Flink и набором источников и потребителей данных, включая Apache Kafka версии 0.11 и выше. Она обеспечивает уровень абстракции и для достижения end-to-end exactly-once семантики требует от пользователя реализовать всего лишь пару методов.
Если вы уже услышали все, что вам нужно было услышать, позвольте нам указать вам соответствующий раздел в документации Flink, где вы можете прочитать о том, как использовать TwoPhaseCommitSinkFunction.
Но если вы хотите узнать больше, то в этой статье мы поделимся подробным обзором этой фичи и того, что Flink оставляет за кулисами.
В рамках этого поста мы:
Объясним роль чекпоинтов Flink в обеспечении exactly-once (“строго-однократных”) результатов в приложении Flink.
Покажем, как Flink взаимодействует с источниками (sources) и потребителями (sinks) данных с помощью протокола двухфазной фиксации транзакции для обеспечения end-to-end exactly-once семантики.
Разберем простой пример того, как использовать TwoPhaseCommitSinkFunction, чтобы реализовать exactly-once потребителя файлов.
Exactly-once семантика в приложении Apache Flink
Когда мы говорим “семантика exactly-once”, мы имеем в виду, что каждое входящее событие повлияет на окончательные результаты ровно один раз. Даже в случае сбоя железа или программного обеспечения не будет ни дублирующихся данных, ни данных, которые остались необработанными.
Flink уже давно обеспечивает exactly-once семантику в рамках приложения Flink. За последние несколько лет мы подробно описали чекпоинты Flink, которые лежат в основе способности Flink обеспечивать exactly-once семантику. Документация Flink также содержит подробный обзор этого функционала.
Прежде чем мы продолжим, вот краткий обзор алгоритма создания чекпоинтов, потому что понимание этого механизма является ключом к пониманию этой более широкой темы.
Чекпоинт во Flink представляет собой снапшот:
Текущего состояния приложения
Позиции в потоке входных данных
Flink регулярно генерирует чекпоинты через определенные (настраиваемые) интервалы времени и вносит их в какую-нибудь внешнюю систему хранения, такую как S3 или HDFS. Запись данных чекпоинта во внешнее хранилище происходит асинхронно, а это означает, что приложение Flink продолжает обрабатывать данные во время процесса создания чекпоинта.
В случае сбоя железа или программного обеспечения и после перезапуска приложение Flink возобновляет работу с самого последнего успешно созданного чекпоинта; прежде чем начать обработку, Flink восстанавливает из чекпоинта состояние приложения и откатывается к правильной позиции в потоке входных данных. Это означает, что Flink вычислит результаты так, как будто никакого сбоя никогда и не было.
До Flink 1.4.0 exactly-once семантика была ограничена только приложением Flink и не распространялась на большинство внешних систем, которым Flink отправляет данные после обработки.
Но приложения Flink работают в сочетании с широким спектром потребителей данных, и разработчики должны иметь возможность поддерживать exactly-once семантику и за пределами этого компонента.
Чтобы обеспечить end-to-end exactly-once семантику, то есть семантику, которая применяется также и к внешним системам, в которые Flink производит запись, в дополнение к состоянию приложения Flink, эти внешние системы должны предоставлять средства для фиксации (commit) или отката (roll back) записей, которые координируются с чекпоинтами Flink.
Одним из распространенных подходов к координации коммитов и откатов в распределенной системе является протокол двухфазной фиксации транзакций. В следующем разделе мы заглянем за кулисы и обсудим, как TwoPhaseCommitSinkFunction использует протокол двухфазной фиксации для обеспечения end-to-end exactly-once семантики.
End-to-end Exactly-Once приложения с Apache Flink
Мы рассмотрим протокол двухфазной фиксации и то, как он обеспечивает end-to-end exactly-once семантику на примере приложения Flink, которое читает и записывает в Kafka. Kafka — это популярная система обмена сообщениями, которую можно использовать вместе с Flink. А также Kafka добавила поддержку транзакций в релизе 0.11. Это означает, что у Flink теперь есть необходимый механизм для обеспечения end-to-end exactly-once семантики в приложениях при получении и записи данных в Kafka.
Поддержка Flink end-to-end exactly-once семантики не ограничивается Kafka, вы можете использовать ее с любым источником/потребителем, предоставляющем необходимый механизм координации. Например, Pravega, система потокового хранения с открытым исходным кодом от Dell/EMC, также поддерживает end-to-end exactly-once семантику с Flink через TwoPhaseCommitSinkFunction.

В примере приложения Flink, которое мы обсудим сегодня, у нас есть:
Источник данных, который считывает из Kafka (во Flink, KafkaConsumer)
Оконная агрегация
Потребитель данных, который записывает данные обратно в Kafka (во Flink, KafkaProducer)
Касательно потребителя данных, чтобы обеспечить exactly-once гарантию, он должен записывать все данные в Kafka в рамках транзакции. Коммит объединяет все операции записи между двумя чекпоинтами.
Это гарантирует откат записей в случае сбоя.
Однако в распределенной системе с несколькими одновременно выполняющимися задачами-потребителями обычной фиксации или отката недостаточно, поскольку все компоненты должны “согласовывать” друг с другом фиксацию или откат, чтобы и сам результат был согласованным. Flink использует протокол двухфазной фиксации транзакции и его фазу предварительной фиксации для решения этой задачи.
Запуск чекпоинта представляет собой фазу “предварительной фиксации” (pre-commit) нашего двухфазного протокола. Когда запускается чекпоинт, Flink JobManager вводит в поток данных барьер чекпоинта (который разделяет записи в потоке данных на набор, который входит в текущий чекпоинт, и набор, который входит в следующий чекпоинт).
Барьер передается от оператора к оператору. Он заставляет state backend каждого оператора сделать снапшот его состояния.
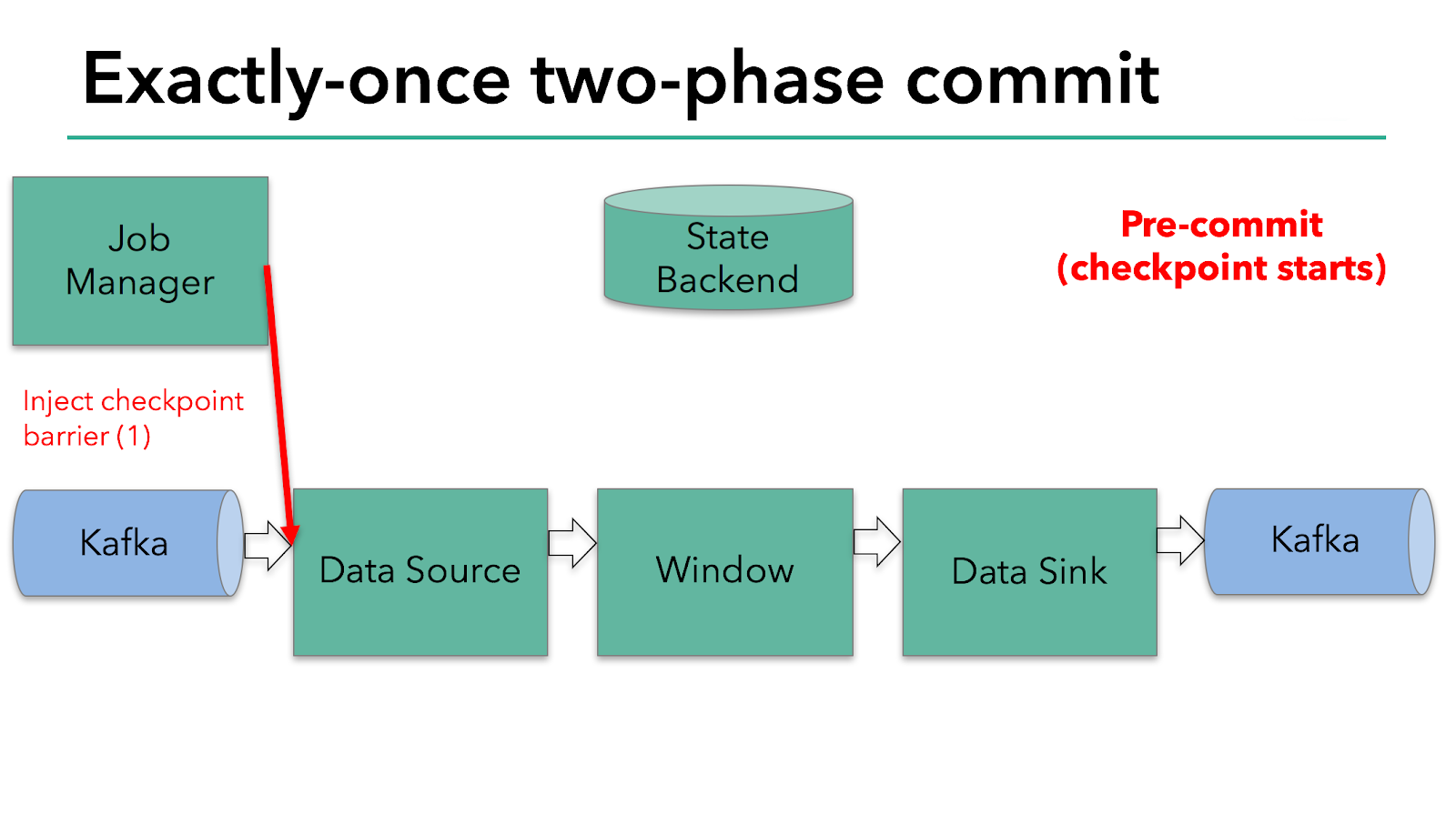
Источник данных сохраняет свои офсеты Kafka, и после завершения этого он передает барьер чекпоинта следующему оператору.
Этот подход работает, если оператор имеет только внутреннее состояние. Внутреннее состояние — это все, что хранится и управляется state backend’ами Flink, например, оконные суммы во втором операторе. Когда процесс имеет только внутреннее состояние, нет необходимости выполнять какие-либо дополнительные действия во время предварительной фиксации, кроме обновления данных в state backend’ах до того, как он будет отображен в чекпоинте. Flink заботится о правильной фиксации этих записей в случае успешного создания чекпоинта или их отмены в случае сбоя.
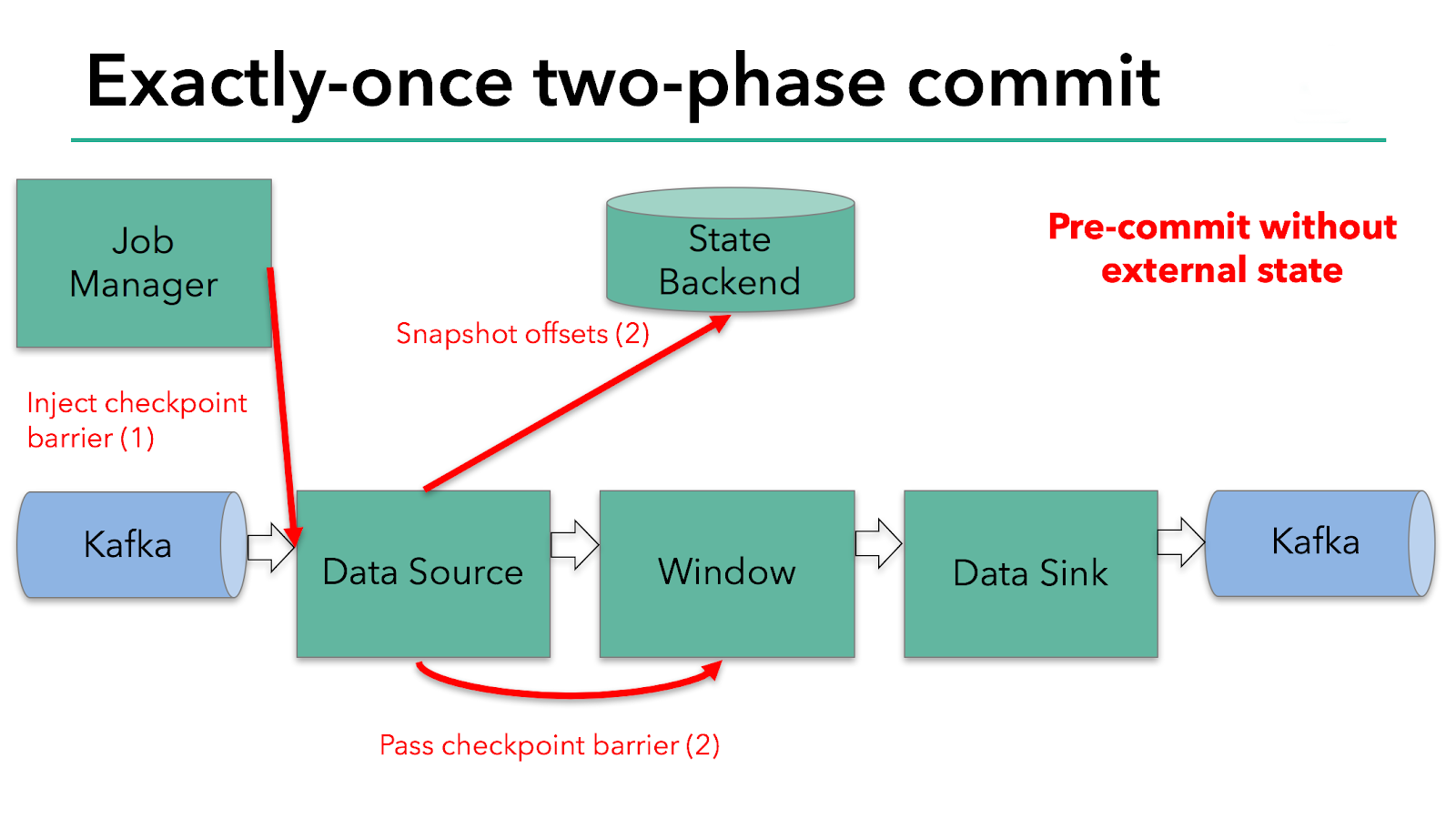
Однако когда процесс имеет внешнее состояние, это состояние должно обрабатываться немного по-другому. Внешнее состояние обычно проявляется в виде записи во внешнюю систему, такую как Kafka. В этом случае, чтобы обеспечить exactly-once гарантии, внешняя система должна иметь поддержку транзакций, которые интегрируются с протоколом двухфазной фиксации.
Мы знаем, что потребитель данных в нашем примере имеет внешнее состояние, потому что он записывает данные в Kafka. В этом случае на этапе предварительной фиксации потребитель данных в дополнение к записи своего состояния в state backend должен предварительно зафиксировать свою внешнюю транзакцию.
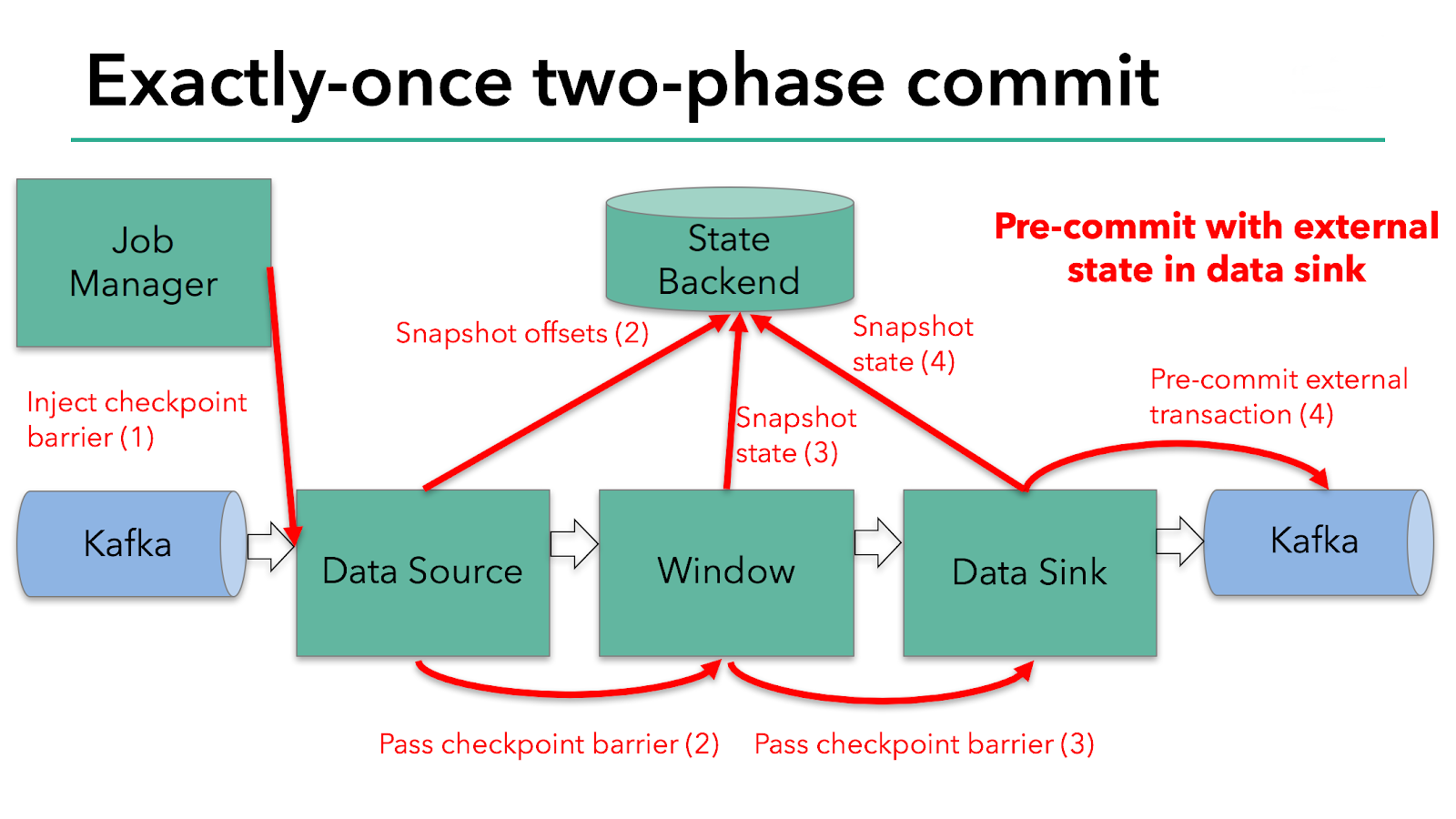
Фаза предварительной фиксации завершается, когда барьер чекпоинта проходит по всем операторам и отработали все колбеки снапшотов. На этом этапе чекпоинт успешно создан и содержит в себе состояние всего приложения, включая предварительно зафиксированное внешнее состояние. В случае сбоя мы инициализируем приложение с этого чекпоинта.
Следующим шагом является уведомление всех операторов о том, что чекпоинт успешно создан. Это этап фиксации (commit phase) двухфазного протокола, и JobManager запускает для каждого оператора в приложении специальные колбеки (checkpoint-completed callbacks). Источник данных и оконный оператор (window operator) не имеют внешнего состояния, поэтому на этапе фиксации этим операторам не нужно предпринимать никаких действий. Однако потребитель данных имеет внешнее состояние и фиксирует транзакцию с во внешней записи.

Итак, давайте соберем все части этого процесса воедино:
Как только все операторы завершат предварительную фиксацию, наступит вторая фаза фиксации.
Если хотя бы одна предварительная фиксация претерпевает неудачу, все остальные прерываются, и мы возвращаемся к предыдущему успешно созданному чекпоинту.
После успешной предварительной фиксации необходимо гарантировать, что фиксация в конечном итоге будет успешно завершена — и наши операторы, и наша внешняя система должны предоставить эту гарантию. Если фиксация завершается сбоем (например, из-за периодически возникающих проблем с сетью), все приложение Flink дает сбой, перезапускается в соответствии со стратегией перезапуска, определенной пользователем, и предпринимается еще одна попытка фиксации. Этот процесс имеет решающее значение, поскольку, если фиксация в конечном итоге не будет успешной, то данные будут утеряны.
Таким образом, мы можем быть уверены, что все операторы единогласны в отношении окончательного результата чекпоинта: все операторы согласны с тем, что данные либо фиксируются, либо фиксация прерывается и выполняется откат.
Реализация оператора двухфазной фиксации в Flink
Вся логика, необходимая для реализации протокола двухфазной фиксации, может быть немного сложной, поэтому Flink извлекает общую логику этого протокола в абстрактный класс TwoPhaseCommitSinkFunction.
Давайте рассмотрим, как расширить TwoPhaseCommitSinkFunction на простом примере с файлом. Нам нужно реализовать только четыре метода и представить их реализации файловому exactly-once потребителю:
beginTransaction— чтобы инициировать транзакцию, мы создаем временный файл во временном каталоге в нашей целевой файловой системе. Впоследствии по мере обработки мы можем записывать данные в этот файл.preCommit— во время предварительной фиксации мы сохраняем файл на диск, закрываем его и больше ничего в него не пишем. Мы начнем новую транзакцию для любых последующих операций записи, относящихся к следующему чекпоинту.commit— во время фиксации мы атомарно перемещаем предварительно зафиксированный файл в каталог, где он должен будет храниться. Обратите внимание, что это увеличивает задержку видимости выходных данных.abort— при прерывании мы удаляем временный файл.
Как мы знаем, в случае сбоя Flink восстанавливает состояние приложения на момент последнего успешного чекпоинта. Но есть один подвох — это редкий случай, когда сбой происходит после успешной предварительной фиксации, но до того, как уведомление о факте фиксации достигнет нашего оператора. В этом случае Flink восстанавливает наш оператор в состояние, которое уже было предварительно зафиксировано, но еще не зафиксировано финально.
Мы должны сохранить достаточно информации о предварительно зафиксированных транзакциях в чекпоинте состояния, чтобы иметь возможность прервать (abort) или зафиксировать (commit) транзакции после перезапуска. В нашем примере это будет путь к временному файлу и целевому каталогу.
Функция TwoPhaseCommitSinkFunction учитывает этот сценарий и всегда выполняет упреждающую фиксацию при восстановлении состояния из чекпоинта. Наша обязанность — реализовать фиксацию идемпотентным способом. Как правило, это не очень сложная задача. Мы можем распознать такую ситуацию в нашем примере: временный файл находится не во временном каталоге, а уже перемещен в целевой каталог.
Есть несколько других пограничных случаев, которые TwoPhaseCommitSinkFunction также учитывает. Узнать об этом больше можно в документации Flink.
Заключение
Если вы дочитали до этого места, спасибо за ваше внимание! Вот некоторые ключевые моменты, касательно темы, которую мы рассмотрели:
Система чекпоинтов Flink служит основой для поддержки протокола двухфазной фиксации и обеспечения end-to-end exactly-once семантики.
Преимущество этого подхода заключается в том, что Flink не материализует данные при передаче, как это делают некоторые другие системы, — нет необходимости записывать каждый этап вычислений на диск, как в случае с большинством пакетных операций.
TwoPhaseCommitSinkFunctionот Flink извлекает общую логику протокола двухфазной фиксации и позволяет создавать end-to-end exactly-once приложения с Flink и внешними системами, поддерживающими транзакцииНачиная с Flink 1.4.0, продюсеры как Pravega, так и Kafka 0.11 обеспечивают exactly-once семантику; Kafka впервые ввела транзакции в Kafka 0.11, что сделало exactly-once продюсера Kafka пригодным для работы с Flink.
Продюсер Kafka 0.11 реализован поверх
TwoPhaseCommitSinkFunctionи предлагает очень низкие накладные расходы по сравнению с at-least-once продюсером Kafka.
Мы очень рады возможностям, который этот функционал перед нами открывает, и надеемся, что в будущем сможем поддерживать в TwoPhaseCommitSinkFunction еще больше продюсеров.
Завтра вечером состоится открытое занятие «Schema Registry в Apache Kafka», на котором мы познакомимся с использованием реестра схем при работе с Kafka. Вы узнаете, что такое Kafka и эволюция схем, а также, как реестр схем облегчает работу с Kafka.