
Продолжаем серию публикаций для java разработчиков, создающих системы со сложной предметной областью, первую часть можно почитать здесь. В новой статье поговорим о гексагональной архитектуре.

Что такое гексагональная архитектура и как она помогает в реализации technology agnostic приложения?
Гексагональная архитектура – это архитектура портов и адаптеров. Как и DDD, она ориентирована на реализацию принципа DIP (DEPENDECY INVERSION PRINCIPLE) для слоев приложения, где максимально независимым является слой бизнес-логики домена. За счет реализации гексагональной архитектуры мы отделяем бизнес логику от внешнего мира.
Под внешним миром подразумевается:
Rest API call.
Messaging API call.
Data source API call.
Для того, чтобы понять изолирована ли ваша доменная логика от ваших технологий, нужно представить, что вы приняли решение, или заменить вызов вашего CLIENT API с rest на messaging, или перейти с реляционной БД на MONGO. Если происходит изменение бизнес-логики, то DIP принцип нарушен и, соответственно, гексагональная архитектура реализована некачественно.
Комбинирование гексагональной архитектуры и DDD дизайна является хорошей практикой, так как они ориентированы на реализацию принципа DIP по отношению к гексагональной архитектуре.

Бизнес-логика домена сосредоточена в компонентах гексагональной архитектуры, известных как use case.
Все зависимости от технологий Use Case выражены интерфейсами output port.
Output Port реализуется через Outbound Adapter.
Primary Adapter содержит зависимость от INPUT PORT для вызова бизнес-логики, содержащейся в USECASE. Примером Input Adapter является Rest Controller, Kafka Listener.
Использование гексагональной архитектуры дает следующие преимущества для бизнес-владельца и команды разработки:
Гексагональная архитектура снижает затраты на рефакторинг приложения, так как приложение декомпозировано на отдельные части. Эти части очень легко рефакторить вследствие отделения бизнес-логики от технического кода фреймворков - в частности от кода фреймворка Spring . При принятии решения о переходе компании на другой технологический стек, сделать это будет гораздо проще, так как бизнес-процессы независимы от конкретных реализаций технологий.
Для реализации классов и интерфейсов приложения, основанных на гексагональной архитектуре, требуются прикладные навыки применения принципов SOLID. Особое значение из этих принципов имеет принцип D – DEPENDECY INVERSION PRINCIPLE – который, по сути, определяет гексагональную архитектуру.
DIP принцип формулируется следующим образом: высокоуровневые функции (методы бизнес-логики приложения) должны быть доступны для повторного использования (в рамках клиентского вызова API приложения) и на них не должны влиять изменения в низкоуровневых функциях. Например, смена источника данных Postgres на Mongo. Чтобы следовать этому принципу, определяются абстракции, которые отделяют высокоуровневые функции от низкоуровневых функций. Абстракции выражены java интерфейсами.
Требования к компонентам гексагональной архитектуры
Примеры реализаций требований к компонентам гексагональной архитектуры:
В Rest Controller не должен содержаться вызов JPA Repository.
Сервисный класс не должен содержать прямой вызов JPA Repository.
Сервисный класс не должен использовать в теле своих методов логику прямого изменения состояния JPA entity.
Сервисный класс всегда работает только с доменными представлениями сущностей.
Четкое разделение функциональных возможностей:
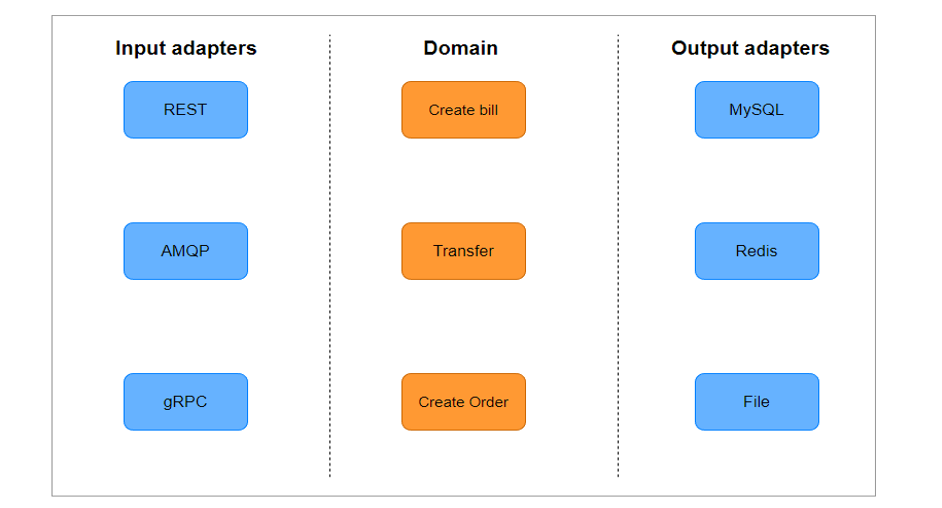
Четкое определение границы слоев:
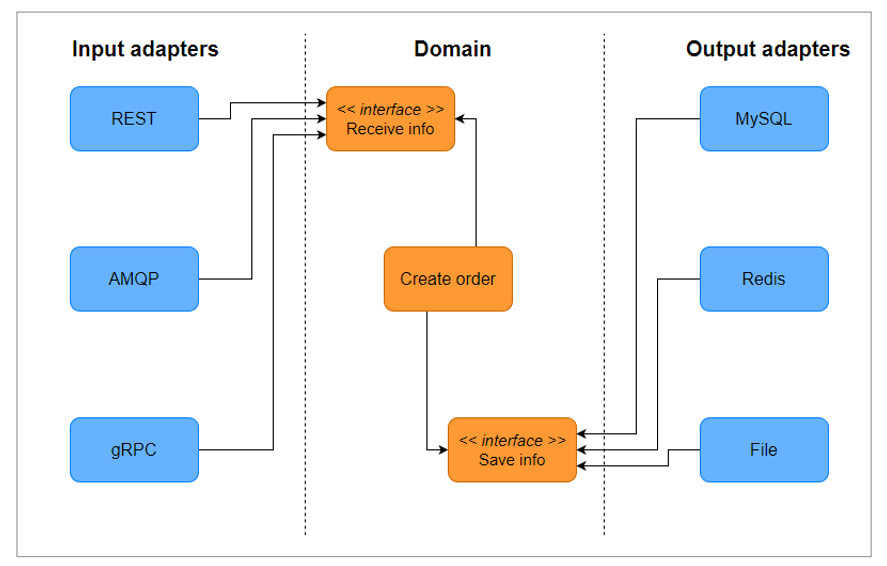
Взаимодействие основных компонент гексагональной архитектуры осуществляется последовательно от внешнего слоя к внутреннему; каждое взаимодействие с бизнес-логикой содержится в Input Adapter.
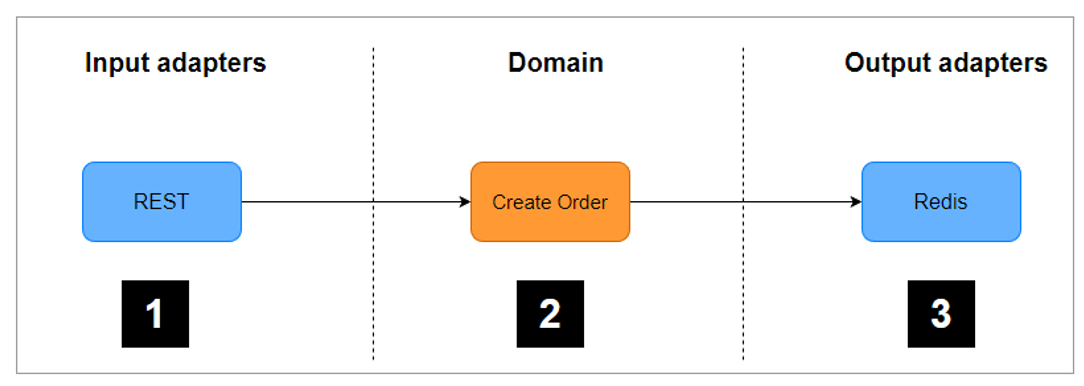
Слои структурирования гексагональной архитектуры
Domain Object слой
Содержит все объекты, связанные с бизнес-моделью приложения. В терминах DDD бизнес-объекты это – агрегаты, сущности, объекты-значения. Также данный слой содержит все абстракции (интерфейсы) для взаимодействия внешнего мира со смоделированными бизнес-процессами. Domain абстракциями являются репозитории и фабрики. Наличие сервиса домена (domain service) опционально. Если оно есть, то сущности и их методы вызываются в методах domain service и результат отдается в application service (use case). Если domain service отсутствует, то сущности и их методы вызываются в теле application service (use case).

Уровень UseCase
Следует сразу за слоем объектов домена. Содержит в теле своих методов логику оркестрации методами корня агрегата, а также логику оркестрации взаимодействия между двумя агрегатами, если это необходимо. Под логикой оркестрации взаимодействия между двумя агрегатами подразумевается вызов соответствующего outbound порта, отвечающего за распределение событий (direct event sourcing) между микросервисами, содержащими агрегаты.
На уровне тела метода UseCase не рекомендуется использовать JPA Entity, Kafka message, так как подобная реализация повышает прямую связь между бизнес-логикой и техническим кодом фреймворков. К примеру, JPA Entity является представителем технического кода, которого не должно быть на этом уровне.

Уровень Портов
Порт — это интерфейс, определяющий функции и данные, необходимые для выполнения этих функций. Порты размещаются между логикой домена (логикой ограниченной UseCase) и технологическим кодом (rest controller, JPA repository). Располагается перед и после слоя UseCase.
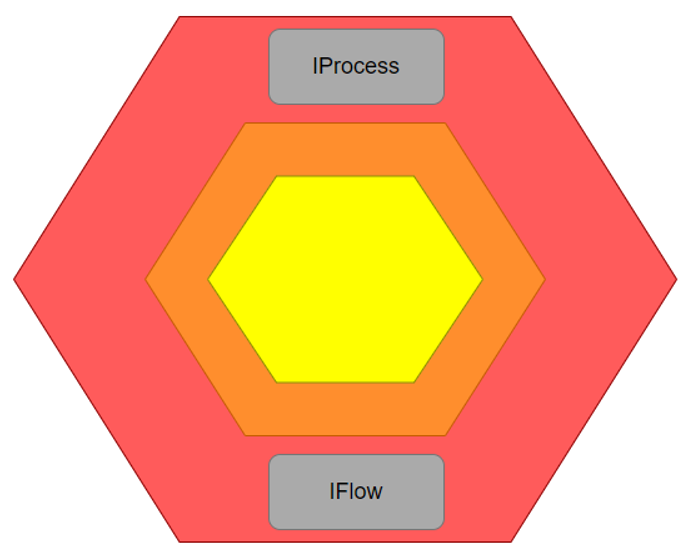
Уровень Адаптеров
Адаптер — это класс, который содержит технологический код в теле своих методов:
Логику маппинга объектов домена в соответствующее технологическое представление. Технологическое представление это – Jpa Entity, Kafka Message, Rest Request Dto;
логику вызова или обращения к какому-либо ресурсу – jpPepository.save(),kafkaSender.send()

Негативные эффекты от использования метода двунаправленной ассоциации (JPA bidirectional relationship)
Метод двунаправленной ассоциации имеет как свои преимущества, так и недостатки.
Ключевым преимуществом его использования является сокращение числа запросов в БД при сохранении JPA сущности One в БД с коллекцией JPA сущности Many.
Части метода двунаправленной ассоциации используются с точки зрения удобства для того, чтобы в какой-то момент через экземпляр JPA сущности Many посмотреть состояние объекта JPA сущности One.
Однако при его применение от разработчика требуется создавать специальные методы синхронизации объектной модели на уровне JPA сущностей для синхронизации JPA моделей и соответствующих им записей в таблицах.
Также не стоит забывать о дефолтных fetchType аннотаций – LAZY/EAGER – при выгрузке объекта One. Неправильная настройка fetchType может привести к выгрузке всего графа сущностей и их данных на постоянной основе.
Использование метода двунаправленной ассоциации обязывает разработчика произвести специальную настройку equals/hashcode и toString методов сущностей JPA, связанных с этим методом.
Еще одним недостатком метода двунаправленной ассоциации является то, что он позволяют легко попасть в бесконечную рекурсию с помощью реализаций Jackson, Hibernate JPA или Elasticsearch. В каждой из сущностей нужно поддерживать экземпляры другой модели специальными Jackson аннотациями.
Если приложение является высоконагруженным, и в нем все отношения построены между JPA сущностями двунаправленной ассоциации, и таких сущностей большое количество, то частые вызовы методов синхронизации состояния сущностей могут забить стек вызов и спровоцировать StackOverrflow.
С точки зрения модели домена уменьшенная связь в модели предметной области обеспечивает простой код в вашей модели предметной области (нет необходимости поддерживать двунаправленность должным образом). Двунаправленная ассоциация должна отсутствовать в вашей доменной модели. Таким образом, напрашивается вывод, что синхронизация двусторонних отношений требует в 2 раза больше внимания и усилий, чем односторонних.
При использовании DDD, при переходе от доменной модели на уровень структур данных, которыми являются JPA сущности, связи между сущностями будут односторонними. В параметрах аннотации @OneToMany явно ставится fetchtype EAGER.
То есть для клиентских команд, изменяющих любую часть графа, будет извлекаться и обновляться весь граф на уровне БД через JPA repository JPA сущности, отражающей корень агрегата. Это обеспечит простую поддержку консистентности состояния графа, облегчит настройку оптимистической/пессимистической блокировки на уровне JPA сущности, отражающей корень агрегата. Он будет являться единственным шлюзом доступа на уровень структур данных.
Если стороны Many исчисляются не десятками, а сотнями и тысячами, то следует задуматься о вынесении сущности домена Many в другой агрегат в качестве корня агрегата. Также настроить взаимодействие между агрегатом 1 и агрегатом 2 через доменные события (domain events). Стоит отметить, что на уровне микросервиса или модуля мульти-модульного монолита допускается наличие нескольких агрегатов.
Негативные эффекты от READ операций, реализованных с помощью JPA
Для организации клиентских сценариев получения данных следует использовать JOOQ. В отличии от JPA, он не подвержен проблемам неправильной конфигурации fetchType, который ради получения данных из одной таблицы может отправить n+1000 отдельных запросов. Технический код, написанный с использованием JOOQ, всегда достает то, что нужно пользователю. JOOQ позволяет писать высокоточные, неподверженные SQL INJECTION TYPE-SAFE запросы на уровне структур данных БД.
В случае c клиентскими сценариями получения данных, нам не нужно беспокоиться о консистентности состояния графа, так как в процессе чтения мы не меняем его состояние.
Стоит отметить, что JOOQ при компиляции автоматически генерирует модели структур данных на основании структуры таблиц. Для этого нужно либо активное соединение с БД в момент компиляции, либо небольшая настройка, чтобы JOOQ читал ваши скрипты миграции Liquibase/Flyway.
JOOQ также можно настроить на использование JPA сущностей для построения запросов через специальный плагин maven, но завязывать одну технологию доступа к БД на другую технологию доступа к БД является не самой лучшей идеей.
Почему не стоит реализовывать Use Case, обеспечивающий прямое частичное обновление агрегата
Прямая выгрузка части агрегата и прямое сохранение или изменение части агрегата, не являются «запрещенными», но реализация такого функционала может повлечь большое количество багов как на уровне бизнес кода, так и на уровне технического кода соответствующей реализации бизнес-сценария.
Рассмотрим прямую выгрузку части агрегата без предварительной выгрузки агрегата полностью. Это не повлечет за собой проблем, если выгружаемая часть агрегата используется исключительно в таких Use Case, которым больше не требуется никакая другая часть этого же агрегата.
В случае с доменной моделью управления документами, агрегат представляет собой документ с массивом заголовков и телом документа. Не имеет смысла выделять в отдельные агрегаты «заголовок» и «тело документа», поскольку эти части документа тесно связаны друг с другом.
Примером Use Case, в котором допускается прямо выгрузить часть агрегата, является следующий сценарий: вам нужно получить список всех заголовков документа, но не нужно «тело документа», плюс вы хотите избежать предварительной загрузки «тела документа» со всеми прямо связанным с этим телом атрибутами.
При прямом изменении или сохранении части агрегата вводятся некоторые дополнительные правила:
Гарантированная поддержка всех инвариантов доменной модели агрегата может потребовать дупликации бизнес-логики, ответственной за валидацию инвариантов.
Параллельные процессы обновления одной и той же части агрегата могут потребовать редизайн технического кода доступа в БД.
Например, есть Use Case 1, который загружает и сохраняет агрегаты целиком и использует какую-то стратегию блокировки, чтобы избежать коллизий. И есть Use Case 2, который манипулирует только прямыми обновлениями части агрегата. И в production Use Case 2 вызывается очень часто в параллели. Необходимо реализовать Use Case 1 и Use Case 2 таким образом, чтобы их параллельная работа не противоречила стратегии блокировки.
Кэширование может стать еще одной проблемой
Агрегаты всегда загружаются и сохраняются в полном объеме, обычно, это реализуется с помощью репозитория. Затем легко реализовать функцию кэширования как часть репозитория. Однако, если дополнительно разрешается производить прямые изменения части агрегата, необходимо убедиться, что эти изменения также обновляют или делают недействительным кэш.
Это часто является соображением производительности: полная выгрузка агрегата для получения его части и полное сохранение агрегата при обновлении его части всегда в целом делает систему более простой и менее подверженной ошибкам. Но для определенных случаев, использование этого метода может оказаться слишком медленным в реальном мире.
В этом случае наблюдается сильное снижение производительности при работе с агрегатом, может возникнуть необходимость в работе с прямой частичной выгрузкой/обновлением (ценой усложнения бизнес логики). Поэтому не рекомендуется использовать частичные агрегаты, если можно этого избежать.
Стоит отметить, когда DDD интегрируется с CQRS, агрегаты выгружаются только для команд, которые обычно не должны быть сверхбыстрыми. Доменное событие можно использовать для создания высокооптимизированных моделей чтения для клиентских запросов. Такая архитектура может восприниматься как более сложная с технической точки зрения, но это выглядит предпочтительнее, чем прямая выгрузка части агрегата, которая может привести к риску появления ошибок или увеличению сложности реализации бизнес кода, соответствующего Use Case.
Выводы
В рамках первых двух статей цикла были рассмотрены основные принципы разработки приложений с использованием гексагональной архитектуры и DDD паттернов. Гексагональная архитектура позволяет сделать реализацию бизнес-процессов независимой от технических реализаций ресурсов, используемых приложением.
Как и DDD, гексагональная архитектура содержит rich domain model в качестве ядра системы. Отличие DDD от гексагональной архитектуры заключается в том, что DDD фокусируется в большей степени на реализации доменной модели на основании строгих правил, выраженных DDD паттернами, в то время как гексагональная архитектура фокусируется в большей степени на изоляции доменной модели от технического кода.
Комбинированное применение DDD и гексагональной архитектуры позволяет спроектировать граф ваших доменных моделей – агрегат – таким способом, чтобы можно было легко вносить частые изменения в его бизнес функционал и чтобы представление агрегата на уровне базы данных и их взаимодействие с агрегатом происходили в зависимости от доменной модели. Благодаря таким свойствами доменной модели, ее поддержка и развитие разработчиками становятся удобными и быстро реализуемыми. И как итог – кодовая реализация приложения полностью отражает видение бизнесом функционала системы.
Буду рад продолжить диалог в комментариях.