

Привет, меня зовут Александр Панасюк. Я разрабатываю на Ruby с 2011 года и сейчас руковожу группой разработки на Ruby в СберМаркете. Хочу поделиться опытом того, как при масштабировании e-com’а мы боролись с узким горлышком при помощи репликации и какой метод предпочли при борьбе с отставанием реплик.
Как мы масштабировались в СберМаркете
Мы делаем сервис по доставке продуктов из магазинов на дом, используем Ruby-монолит и микросервисы на Ruby и GoLang.
За период с 2019 по 2021 год число заказов выросло в 100 раз и сейчас СберМаркет обрабатывает более 100 000 заказов в сутки. В штате разработки СберМаркета трудится более 700 человек, включая ~100 рубистов.
Учитывая такой рост, мы сильно масштабировали наши сервисы и пришли к выводу, что можно до бесконечности плодить Puma-сервера с Rails-приложением, но бутылочным горлышком в итоге оказывается база данных.

Как можно бороться с узким горлышком?
Мы рассмотрели много вариантов, но в итоге предпочли репликацию.
Применить кэширование, т. е. складывать данные, которые часто необходимы нашим клиентам, в кэш, например, с помощью Memcaсhed или Redis-сервер, тем самым снимая нагрузку с базы данных.
Оптимизировать запросы или избавиться от некоторых из них.
Денормализовать схему базы данных таким образом, чтобы в некоторых таблицах хранились избыточные данные, что позволит избавиться от лишних join-ов и потенциально снизить нагрузку на базу данных.
Применить шардирование, т. е. разбить таблицы по некоторому признаку (шарду) и сложить кусочки таблиц, разбитых по такому признаку, в отдельные базы данных, куда по отдельности осуществлять запись и чтение.
Применить репликацию — записывать данные всегда в один узел базы данных (primary), а вычитывать из других узлов (replica).
Репликация, я выбираю тебя
Остановимся на репликации подробнее. В общем виде репликация может быть:
синхронной,
асинхронной.
Синхронная репликация
При синхронной репликации запись осуществляется только в primary-узел. После этого мы копируем изменения из primary на реплики. При этом транзакция в primary не завершается, пока не завершены все транзакции в репликах.

Когда транзакции в репликах завершаются, можно спокойно прочитать изменения из реплик.

Асинхронная репликация
При асинхронной репликации мы тоже пишем в primary-узел. При этом как только транзакция в primary закоммитится и мы отпустим бэкенд обслуживать все новые и новые запросы, в фоновом режиме начнем копировать изменения с primary на реплики.


После завершения репликации мы можем вычитать данные из реплик.

Что можно использовать для работы с репликами в Rails?
Расскажу о трёх инструментах, которые моя команда применяет на практике.
Нативная поддержка
Первое — это нативная поддержка в Rails, начиная с 6-ой версии. Это означает, что мы можем «из коробки» сконфигурировать приложение таким образом, чтобы оно работало с несколькими узлами базы данных. При этом мы можем сказать, куда приложение будет писать и откуда будет читать.
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :replica }
end
def find_user_in_primary(uuid)
ApplicationRecord.connected_to(role: :writing) do
User.find_by!(uuid: uuid)
end
endГем Makara
Во-вторых, это гем Makara, который позволяет сконфигурировать приложение таким образом, чтобы оно знало, что есть несколько узлов базы данных, что на primary можно писать, а с реплик — читать.
def find_user_in_primary(uuid)
User.connection.stick_to_primary!
User.find_by!(uuid: uuid)
endГем Octopus
В-третьих, это гем Octopus, которым мы пользуемся в одном из монолитов СберМаркет, и который позволяет на достаточно гранулярном уровне управлять чтением и записью. Таким образом, мы можем сказать, куда пойдет каждый запрос — в primary или в реплики.
def find_user_in_primary(uuid)
Octopus.using(:replica) do
User.find_by!(uuid: uuid)
end
endПодводный камень в асинхронной репликации
Итак, мы выбрали один из инструментов и сконфигурировали репликацию в нашей базе данных. Однако в реальности оказывается, что при асинхронной репликации реплики отстают от primary, т. е. происходит лаг репликации. Как правило, лаг длится не больше, чем необходимо для перезагрузки страницы, или периода времени между предыдущим и каждым последующим запросом от клиента.
Но иногда лаг может быть значительно больше и составлять секунды, минуты и даже часы. Одной из причин большого лага репликации являются большие изменения схемы базы данных на больших таблицах. Мы пытаемся на большой таблице изменить схему, и эти изменения не успевают пролиться с primary на реплики за короткое время.
Еще одной причиной большого отставания реплик является большой импорт или большие изменения, которые мы пишем в primary. И в этом случае такие изменения не успевают за короткое время попасть в реплики.
Рассмотрим, что происходит с приложением, когда оно сталкивается с большим лагом репликации:
У нас есть бэкенд, на который приходит команда «Купить в один клик».
Бэкенд записывает корзину в primary и туда же складывает продукты.
-
Бэкенд направляет нашего пользователя на страницу чекаута для оплаты.

На странице чекаута пользователь встречается с ошибкой, потому что реплики отстали, и в них нет актуальных данных по нашему заказу.

Как можно исправить ситуацию?
Рекомендации лучших собаководов
Моя команда нашла четыре способа бороться с отставанием реплик.
Дробить чтения и записи в primary и на реплике. Необходимо сделать записи в primary настолько маленькими, чтобы они успевали за короткое время проникать на реплики и, соответственно, чтобы можно было читать и писать маленькими порциями. Это достаточно сложно реализовать на практике, потому что потенциально может потребоваться переработка логики продукта.
Обучать инфраструктуру, как правильно писать и читать. Например, можно поставить между базой данных и бэкендом ProxySQL и задать правило, что все запросы на запись будут идти в primary, а все запросы на чтение — только на те реплики, которые меньше всего отстают от primary. Это также не очень просто реализовать, потому что требуются компетенции DevOps и DBA, которые есть не у всех разработчиков. Поэтому необходимо постараться решить проблему инструментами, доступными всем разработчикам.
Откатиться к синхронным репликам. В этом случае можно сильно просесть по производительности, потому что, по сути, это заставит наших пользователей ждать, когда завершится репликация.
Выбирать, куда писать и откуда читать на уровне кода. Это можно сделать, например, с помощью гема Makara и «липких сессий» (вольный перевод Stickiness Context, описанного в документации гема Makara). Stickiness Context позволяет на некоторое время прикрепить сессию пользователя к узлу primary, чтобы преодолеть лаг репликации и направлять все чтения в этот узел.
Это время можно выставлять вручную. Оно должно быть заведомо больше лага репликации. Проблема в том, что лаг репликации непредсказуем и может длиться любое время. Таким образом, мы можем не угадать с порогом, что достаточно опасно.
Можно также выбирать, куда будет вестись запись и откуда — чтение (из primary или из реплики), вручную для каждого запроса. Как оказалось, это можно реализовать в коде достаточно быстро и легко управлять, потому что мы все умеем писать код.
В итоге мы выбрали пойти именно этим путем — выбора места записи и чтения вручную для каждого запроса.
Как мы осуществили переход на использование реплик
Мы составили топ «жирных» запросов по MySQL.
В первую очередь мы переводили на чтение из реплик частые и медленные запросы.
Мы выбрали так называемые time-tolerant endpoints, т. е. ручки, наименее чувствительные к лагу репликации, для чтения.
Пример: получение списка магазинов в конкретном городе. Список магазинов не меняется слишком часто. Через feature flag мы постепенно переводили на чтение из реплик, чтобы минимизировать влияние на наших пользователей.
Что делать с time-tolerant endpoints или с ручками, наиболее чувствительными к лагу репликации остается под вопросом.
Пример: регистрация и вход пользователя в сервис. Например, при регистрации пользователя мы должны произвести запись в primary-узел, а все дальнейшие ручки будут использоваться клиентом пользователя и должны отдавать какие-то персонализированные данные. Если эти данные мы будем читать из реплик, а реплики отстают, пользователь не сможет получить актуальные данные.
Для таких ручек с высокой динамикой изменений мы придумали несколько тактик.
Тактика выбора primary или реплики (RP)
def find_user(uuid)
ReadTactics.rp { User.find_by!(uuid: uuid) }
end
module ReadTactics
RP = Tactics.new(
steps: [
Steps::Read.new(:replica),
Steps::Read.new(:primary)
]
)
endВ примере метод find_user ищет пользователя. Используется наша тактика RP, в которую передается блок, где мы пытаемся найти пользователя.
На первом шаге тактики мы проигрываем этот блок и все его запросы к базе данных против реплики. Если мы ничего не находим в реплике, мы пытаемся проиграть этот же блок против primary. Велика вероятность, что в primary-узле актуальные данные пользователя будут на месте.
Тактика выбора primary или реплики (RSRP)
def find_shipment(number)
ReadTactics.rsrp { Shipment.find_by!(number: number) }
end
module ReadTactics
RSRP = Tactics.new(
steps: [
Steps::Read.new(:replica),
Steps::Sleep.new(0.1),
Steps::Read.new(:replica),
Steps::Read.new(:primary)
]
)
endВ этом примере кода метод find_shipment пытается найти доставку по номеру. На первом шаге мы пытаемся прочитать из реплики. Если мы ничего не находим, разрешаем треду приложения поспать, например, 1/10 сек. (s или sleep), чтобы увеличить вероятность, что на третьем шаге мы найдем нашу доставку. Если мы ничего не нашли на третьем шаге, запрос направляется в primary, где, скорее всего, мы и найдем нашу доставку.
RSRP — экзотическая тактика, которой мы не пользуемся, потому что она может потенциально сделать в три раза больше запросов, чем нам нужно, а также может заставить приложение поспать 1/10 сек и сделать запросы длиннее на 100 миллисекунд.
Шаг тактики
Каждый шаг «под капотом» использует гем Octopus и его метод using. За счет вызова метода using мы осуществляем переключение на нужный нам узел базы данных — реплику или primary.
module ReadTactics
module Steps
class Read < Struct.new(:source)
def call(&block)
Octopus.using(source, &block)
end
end
end
endКак запускаются шаги
В методе call мы просто итерируем по шагам и выполняем их один за другим. Если очередной шаг нам что-то возвращает и это непустое значение, значит мы искали именно это, и мы должны это значение отправить вниз по стеку или вернуть из тактики.
Если очередной шаг ничего не находит, значит мы возвращаем nil. Это означает, что ни в реплике, ни в primary по нашему запросу ничего не было найдено.
module ReadTactics
class Tactics < Struct.new(:steps)
def call(&block)
steps.each do |step|
result = step.call(&block)
return result if result.present?
end
nil
end
end
endРассмотрим пример применения тактики.

Допустим, у нас есть корзина, и в контроллере, в action create, мы записываем в primary саму корзину и ее состав. После этого мы перенаправляем пользователя на чекаут, на страницу оплаты.
На странице оплаты мы, используя тактику RP, т. е. чтение сначала из реплики, а потом из primary, просто пытаемся вычитать эту корзину. Если данных по корзине для нашего пользователя не оказалось в реплике, мы повторяем чтение из primary и, скорее всего, находим там корзину. Кстати, все последующие запросы в эту ручку отрабатывают корректно, и чтение будет произведено из реплики.
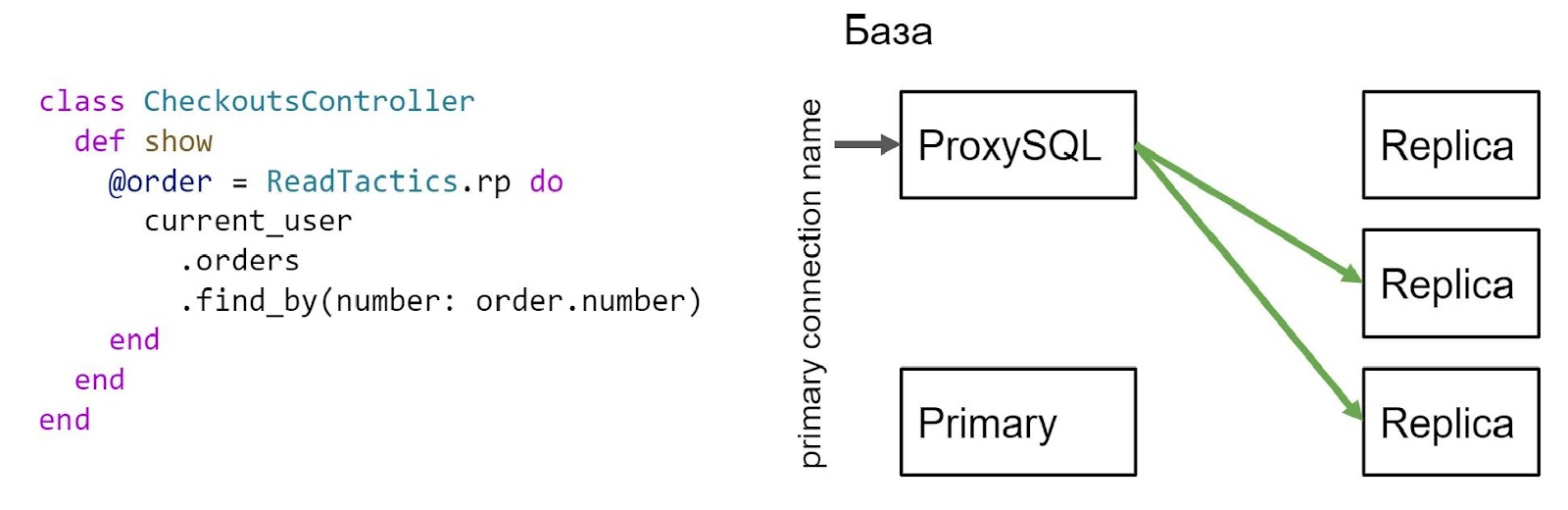
Наш пользователь оказался на странице чекаута. Здесь мы спокойно с помощью тактики вычитали нашу корзину.
Наблюдения и выводы
В итоге мы завели мониторинг отставания реплик и работы тактик и алертинг. Мы собираем события о работе тактик в Prometheus и рисуем графики в Grafana.

На графике можно увидеть сверху возрастающий лаг репликации, а снизу — график работы тактики. Если присмотреться, получается, что при растущем лаге репликации у нас учащаются запросы на чтение из primary-узла.
Также мы завели логирование запросов в dev/stage, чтобы отлаживать работу наших тактик. В логах можно увидеть, куда был направлен запрос — в primary или реплику.
Мы также заметили, что наши тесты абсолютно не готовы к работе с репликами, т. е. они не тестируют пограничное состояние, которое происходит при отставании реплик от primary-узлов (при лаге репликации). А ещё обнаружили некоторые нежелательные эффекты при работе тактик.
Потенциально из-за тактик при лаге репликации мы можем сделать в два раза больше запросов к базе данных, чем нам нужно.
Реплик много и они выдерживают такую нагрузку, а primary-узел всего один.
Надеюсь эта статья была полезна! Tech-команда СберМаркета завела соцсети с новостями и анонсами. Если хочешь узнать, что под капотом высоконагруженного e-commerce, следи за нами в Telegram и YouTube.
Помимо конференции Ruby Russia Evrone проводит еженедельные митапы. Следить за анонсами по интересующим вас технологиям можно в Telegram, а все записи доступны на YouTube.