
Насколько легко обмануть искусственный интеллект? Можно ли подстроить аварию с участием автопилота, или скрыться от «умных» камер, оставаясь у всех на виду? Специалисты компании «Криптонит» провели масштабное исследование, в котором сравнили 10 вариантов атак на модели машинного обучения (ML, от англ. Machine Learning). Их выводы помогут реалистичнее взглянуть на уязвимости систем компьютерного зрения, определить границы применимости различных атак на модели ML, оценить их вычислительную сложность и наиболее эффективные подходы к реализации.
Сегодня мы доверяем ИИ выполнение задач, связанных с жизнью, здоровьем и свободой людей. Искусственный интеллект анализирует ЭКГ и рентгеновские снимки лучше врачей, следит за дорогой внимательнее любого водителя, распознаёт в толпе объявленных в розыск лиц быстрее полицейских. Несмотря на принципиально разные сферы применения, в основе различных реализаций ИИ лежат однотипные модели машинного обучения (ML).
Машинное обучение кажется современной технологией, но его развитие берёт начало в 1950-х годах от научных работ Артура Сэмюэла (автора Checkers-playing, одной из первых самообучающихся программ в мире) и американского нейрофизиолога Фрэнка Розенблатта. Среди советских учёных большой вклад в развитие данного направления внесли В. Н. Вапник и А. Я. Червоненкис. Конкуренция двух сверхдержав привела к тому, что к семидесятым годам были разработаны все ключевые элементы ML: метод опорных векторов (один из наиболее классических способов «обучения с учителем»), методы автоматического дифференцирования, нейросетевая модель зрительной коры «неокогнитрон» и искусственные нейронные сети (ИНС) различных типов.
Одна из самых популярных архитектур в машинном обучении — свёрточные нейросети (CNN, от англ. convolutional neural network). История их создания начинается в восьмидесятых годах прошлого века, но на тот момент это были чисто теоретические концепции. К девяностым годам CNN уже были детально описаны в том виде, каком мы их знаем сейчас. Уже тогда было понятно, как их нужно программировать и обучать, однако популярными CNN стали только в 2010-х годах. Только в последнее десятилетие появились достаточно мощные аппаратные средства и возможность перенести на них давно известные алгоритмы. Также буму нейросетей способствовало появление больших и общедоступных датасетов — наборов обучающих данных.

Первые публикации, в которых исследовалась безопасность моделей машинного обучения на основе ИНС, появились в 2013-2014 гг. В них были описаны атаки на свёрточные нейронные сети для распознавания изображений. В последующих работах была разработана модель угроз и постулировано, что атаки могут проводиться на различных этапах жизненного цикла ИНС: производство, внедрение или эксплуатация. Кроме очевидной цели нарушить работу модели ML, атака может выполняться с целью сбора информации о модели или наборе данных, использовавшихся при её построении.
Дизайн эксперимента
Мы сфокусировались на задаче выведения модели ML из строя путём подачи ей на вход специальным образом сформированных данных. Их ещё называют «вредоносные примеры» (adversarial examples). В последние годы появилась масса научно-популярных публикаций, в которых утверждается, что ИИ легко сбить с толку, едва заметно изменив свою внешность, или подменив один пиксель изображения. Мы решили проверить это и спешим поделиться результатами.
Просто показывать вредоносные примеры было бы не очень наглядно (они мало отличаются от исходника). Поэтому мы покажем возмущения, которые нужно наложить на исходный пример, чтобы получить из него вредоносный. Интенсивность возмущений обозначим в условных цветах.
В нашем исследовании мы использовали три общепринятых в информационной безопасности сценария:
Атака типа white-box предполагает наличие полного доступа к ресурсам сети и наборам данных: знание архитектуры сети, знание всего набора параметров сети, полного доступа к обучающим и тестовым данным.
Атака типа gray-box характеризуется наличием у атакующего информации об архитектуре сети. Дополнительно он может обладать ограниченным доступом к данным. Именно атаки по типу «серого ящика» чаще всего встречаются на практике.
Атака типа black-box характеризуется полным отсутствием информации об устройстве сети или наборе обучающих данных. При этом, как правило, неявно предполагается наличие неограниченного доступа к модели, то есть имеется доступ к неограниченному количеству пар «исследуемая модель» + «произвольный набор входных данных».
Атаки black-box и white-box являются двумя крайностями. Первые очень сложны в реализации (это как решить уравнение с тремя неизвестными), а вторые имеют сугубо теоретическое значение. Они предполагают, что атакующий знает о выбранной нейросети и её обучении буквально всё. В реальной жизни это обычно означает, что атаку выполняет сам разработчик. Примеры таких атак могут быть очень зрелищными. Например, если атакующий обладает полной информацией о модели ML и средствах сбора данных, то атака может быть реализована с помощью физических объектов, например — очков, на оправе которых нанесён цветовой шаблон.
Мы протестировали различные библиотеки для создания вредоносных примеров. Изначально были отобраны AdvBox, ART, Foolbox, DeepRobust. Производительность AdvBox оказалась очень низкой, а DeepRobust на момент исследования была очень сырой, поэтому в сухом остатке оказались ART и Foolbox.
Эксперименты проводились на различных типах моделей ML. В статье мы демонстрируем самые наглядные результаты, полученные с использованием одной фиксированной модели на основе свёрточной нейронной сети и пяти различных атак. Их реализации взяты из двух библиотек. Всего получилось 10 вариантов (см. таблицу).
Тип атаки |
Реализация |
BIM |
Foolbox |
BIM |
ART |
CW |
Foolbox |
CW |
ART |
DeepFool |
Foolbox |
DeepFool |
ART |
FGSM |
Foolbox |
FGSM |
ART |
PGD |
Foolbox |
PGD |
ART |
Здесь Foolbox и ART (Adversarial Robustness Toolbox) — библиотеки Python для оценки безопасности моделей машинного обучения.
Методы
Метод FGSM (Fast Gradient Sign Method) использует наиболее полную информацию о ИНС, для которой строится вредоносный пример. Он основан на том, что вектор весов нейронной сети имеет большую размерность, и малое возмущение входных данных в нужных размерностях может привести к значительному росту ошибки.
Методы BIM (Basic Iterative Method) и PGD (Projected Gradient Descent) состоят в последовательном (итерационном) применении метода FGSM к исходному примеру так, чтобы суммарное возмущение не выводило новый вредоносный пример из заданной области значений.
CW (Carlini-Wagner) — семейство методов построения вредоносных примеров, основанное на «прямой оптимизации» функционалов. В нём используется ряд различных функций потерь, помимо той, что изначально была задействована при построении ИНС.
Метод DeepFool создан для нахождения вредоносных примеров с минимальным возмущением, приводящим к изменению класса распознаваемого объекта. Он подходит для как для аффинных, так и для дифференцируемых бинарных классификаторов.
Все перечисленные выше методы работают только в моделях «белого и серого ящика», поскольку они относятся к аналитическим. То есть, методики основаны на анализе функции потерь, использующейся при построении исходной ИНС.
Помимо них существуют стохастические методы, пригодные для модели «чёрного ящика». В них предполагается, что имеется только ограниченный доступ к целевой ИНС с возможностью отправки примера на обработку и получение результата в виде метки (класса объекта) и вероятности (процента совпадения).
Стохастические методы представляют особый интерес, так как они ближе всего к реальным сценариям атак. В общем случае результатом работы их алгоритма является итеративное внесение контролируемого искажения (возмущения) в исходный пример.
В самом простом случае возмущение меняет одиночный пиксель изображения (см. Few-Pixel) или затрагивает небольшую прямоугольную область (см. Square Attack).
Другим направлением исследования уязвимости моделей ML стала разработка методик внесения возмущения при помощи аффинных преобразований изображения и, в частности, за счёт сдвигов см. Spatial Transformation).
Ещё одним интересным вариантом является HopSkipJumpAttack (также известный как Boundary Attack++) — семейство атак на основе принятия решений. Такие атаки выполняются на обученную модель ML с использованием вредоносных примеров, основанных исключительно на наблюдении выходных меток, возвращаемых целевой ИНС.
HopSkipJumpAttack выглядит перспективным подходом, поскольку он основан на значительно более тонком анализе данных, полученных от модели. В предыдущих атаках типа «чёрный ящик» осуществляется обыкновенный перебор вариантов, и полученные данные не влияют на то, какой будет следующая попытка. HopSkipJumpAttack принципиально отличается тем, что после каждой итерации производится обработка полученных от модели данных для оценки того, где нужно вносить изменения на следующем шаге.
Полученные результаты
Для демонстрации мы использовали базу данных MNIST, которая содержит 60 000 образцов рукописных цифр, и отобрали самые наглядные вредоносные примеры

Число сверху – абсолютная величина максимального отклонения возмущения от оригинала. Под изображением три числа: максимальное отклонение, минимальное и среднее. В нижней строке – метка и вероятность.
Картинка слева — исходный пример, в котором нейросеть уверенно распознаёт цифру «4». Посередине — неудачный вредоносный пример. Изображение заметно искажено, однако нейросеть всё равно распознаёт четвёрку. Справа — работающий вредоносный пример. Он визуально неотличим от предыдущего, но здесь уже преодолён порог возмущений, за которым нейросеть теряется и выдаёт неверный результат распознавания. В данном случае вместо «4» она распознаёт «7».
В примере выше человек уверенно различает цифру «4» на любой из трёх картинок, но исходные изображения не всегда бывают достаточно чёткими. Например, на следующей картинке недописанный ноль может зрительно восприниматься как цифра «6» — вопрос в том, куда мысленно продолжить линию. Нейросеть тоже не уверена: она показывает низкую вероятность, но правильно распознаёт ноль на изображении. Чтобы заставить ИНС ошибиться, нужно изменить всего несколько пикселей. При этом величина вносимого возмущения будет порядка 1/256, что соответствует величине цветового разрешения.

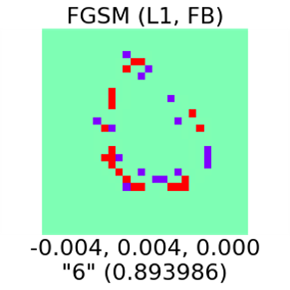
Нейросеть далеко не всегда удаётся обмануть так просто. В случае уверенного распознавания объекта придётся сгенерировать и проверить множество вредоносных примеров, прежде чем вы найдёте рабочий. При этом он может быть практически бесполезным, так как вносит слишком сильные возмущения, заметные невооружённым глазом.
Для иллюстрации возьмём наиболее легко распознаваемую цифру «9» из тестового набора и покажем некоторые получившиеся вредоносные примеры.

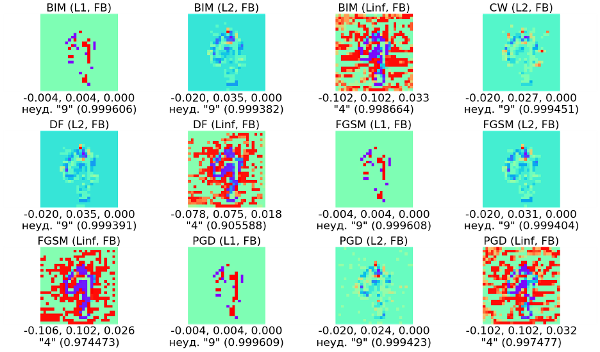
Видно, что в 8 случаях из 12 построить вредоносные примеры не удалось. В остальных четырёх случаях мы обманули нейросеть, но эти примеры получились слишком зашумлёнными. Такой результат связан с уверенностью модели в классификации исходного примера и со значениями параметров различных методов.
Следующий тест показывает, из каких меток проще всего сделать вредоносные примеры (и какие метки проще всего получить).
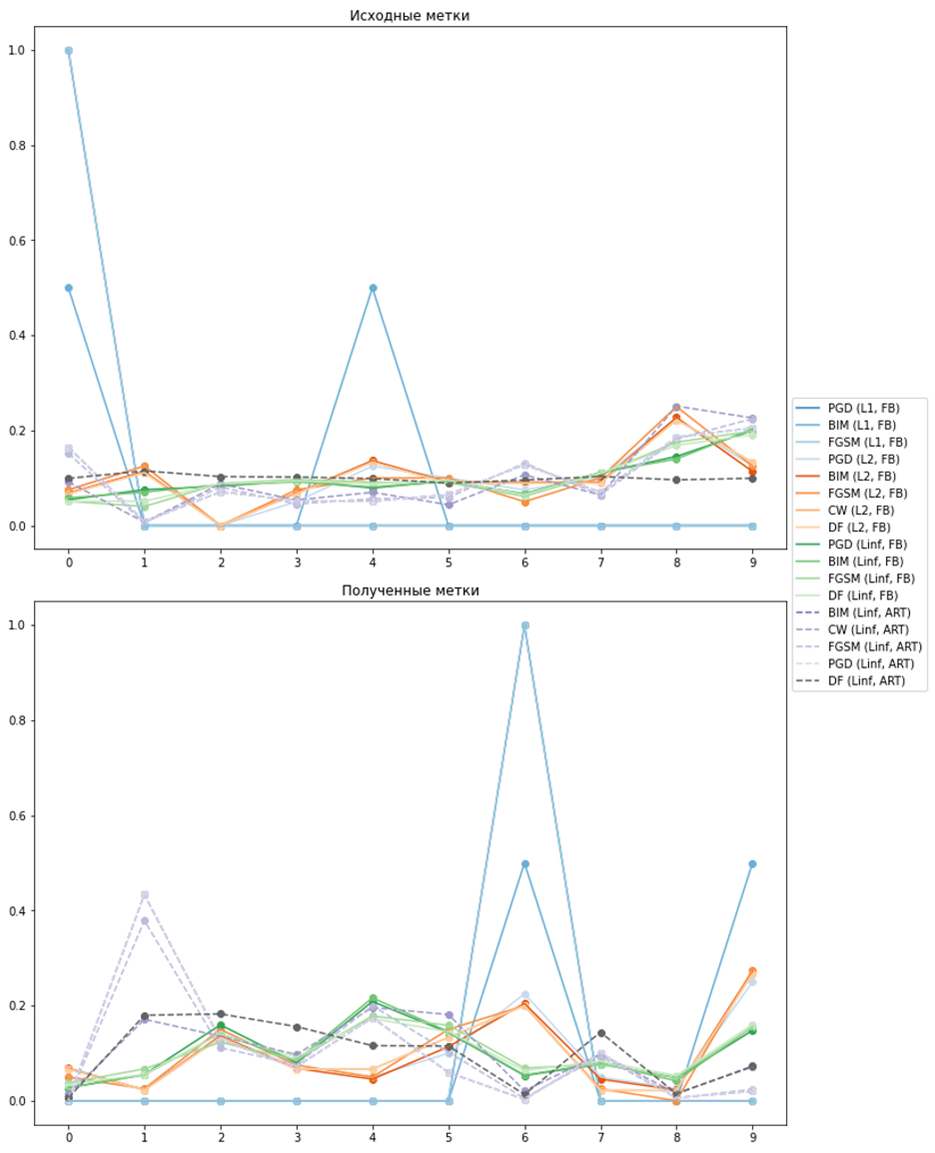
На каждом из двух графиков по оси абсцисс располагаются метки, а по оси ординат — вероятности. Как видно, легче всего ИНС теряется на вредоносных примерах с цифрами «6», «9», «1» и «4».
Дополнительно мы оценили производительность атак на машинное обучение. Для этого была зафиксирована модель (реализация классификатора для рукописных цифр набора данных MNIST из стандартной поставки пакета pytorch) и варьировались два параметра: метод атаки и способ её реализации.

На полученном графике видно, как при росте максимально допустимого значения возмущения уменьшается точность модели.
В целом наш эксперимент показал ожидаемые результаты: чем проще изменения, которые мы вносим в изображение, тем меньше они влияют на работу ИНС. Следует подчеркнуть, что «простота» вносимых изменений относительна: это может быть и десяток пикселей, но вот догадаться, каких именно, и как их нужно изменить — сложная задача. Нет такого гвоздя, на котором полностью держится результат классификации CNN: в общем случае нельзя изменить один пиксель так, чтобы ИНС ошиблась.
Методы PGD, BIM, FGSM, CW, DeepFool оказались самыми эффективными для сценария «белый ящик». Вне зависимости от реализации, они позволяют провести удачную атаку с вероятностью 100%, однако их применение подразумевает наличие полной информации о модели ML.
Методы Square Attack, HopSkipJump, Few-Pixel, Spatial Transformation предполагают наличие информации об архитектуре модели. Были получены единичные удачные примеры атак, но практическое использование этих методов не представляется возможным. Возможно, ситуация изменится в будущем, если появятся достаточно эффективные реализации, стимулирующие интерес исследователей к этим методам.
Все рассмотренные методы «чёрного ящика» используют уровень достоверности, возвращаемый нейронной сетью. Если хотя бы немного понизить точность возвращаемого уровня достоверности, то (и без того невысокая) эффективность методов упадёт многократно.
Выводы
Проблема уязвимости моделей ML наиболее очевидна в примерах с обработкой изображений, но она выходит далеко за рамки одних лишь систем компьютерного зрения. Свёрточные нейросети c разной степенью успешности пытаются применять практически во всех направлениях машинного обучения. Модели на основе CNN также используются для распознавания речи, анализа сетевого трафика и любого другого набора данных, в отношении которого нужно выполнить задачи классификации, выделения паттернов или регрессии.
В ходе эксперимента мы убедились, что ИНС может «с уверенностью» выдать некорректный результат при совсем небольших изменениях во входных данных — настолько незначительных, что человек их вряд ли заметит.
Также мы провели качественное и количественное сравнение производительности различных программных реализаций атак.
Изучение уязвимостей ML продолжается, и новые научные публикации на эту тему появляются буквально каждый месяц. Наше исследование не охватывает новые реализации атак и многочисленные модификации ранее известных.
Помимо перечисленных в этой статье примеров, для атак типа «чёрный ящик» уже существуют и более сложные подходы, например ZOO и HopSkipJump. Данные атаки замечательны тем, что получаемые от ИНС данные подвергаются значительно более тонкому анализу, для выбора возмущения на следующем шаге алгоритма и отнюдь не сводятся к накоплению ошибки путём случайных возмущений.
Это тема для дальнейшего исследования, а сегодня мы можем с уверенностью сказать, что проблема с безопасностью моделей ML действительно есть. Наши эксперименты показали, что значительная часть описанных в литературе примеров атак оказалась жизнеспособной, но с рядом оговорок. Атакующий должен либо владеть подробной информацией об ИНС и данных для её обучения, либо иметь возможность длительно оценивать реакцию нейросети, отправляя ей на вход множество вредоносных примеров, сгенерированных по итерационному алгоритму.
Атаки типа «белый ящик» имеют большое практическое значение. С их помощью осуществляются атаки путём построения аналогичной нейросети. Также данный тип атак применяется для защиты моделей машинного обучения от атак — путём добавления вредоносных примеров в обучающую выборку.