
На протяжении последних 3-х статей мы рассматривали исключительно сами подходы к обучению SSL и не смотрели на качество. Давайте это исправим и сравним методы между собой и с supervised решением. Также глянем на то, какие есть фреймворки, чтобы поднять SSL на своих данных.
Напомню, что это шестая и последняя статья из цикла про SSL в Computer Vision.
The Metric
Какие есть метрики в SSL мы разбирали во второй статье, но давайте немного вспомним. Наиболее признанная метрика которую можно встретить почти во всех статьях - это Linear evaluation protocol. Суть в том, что через предобученный backbone мы получаем эмбеддинги для всего датасета, а потом по этим эмбеддингам линейной моделью предсказываем классы для ImageNet.
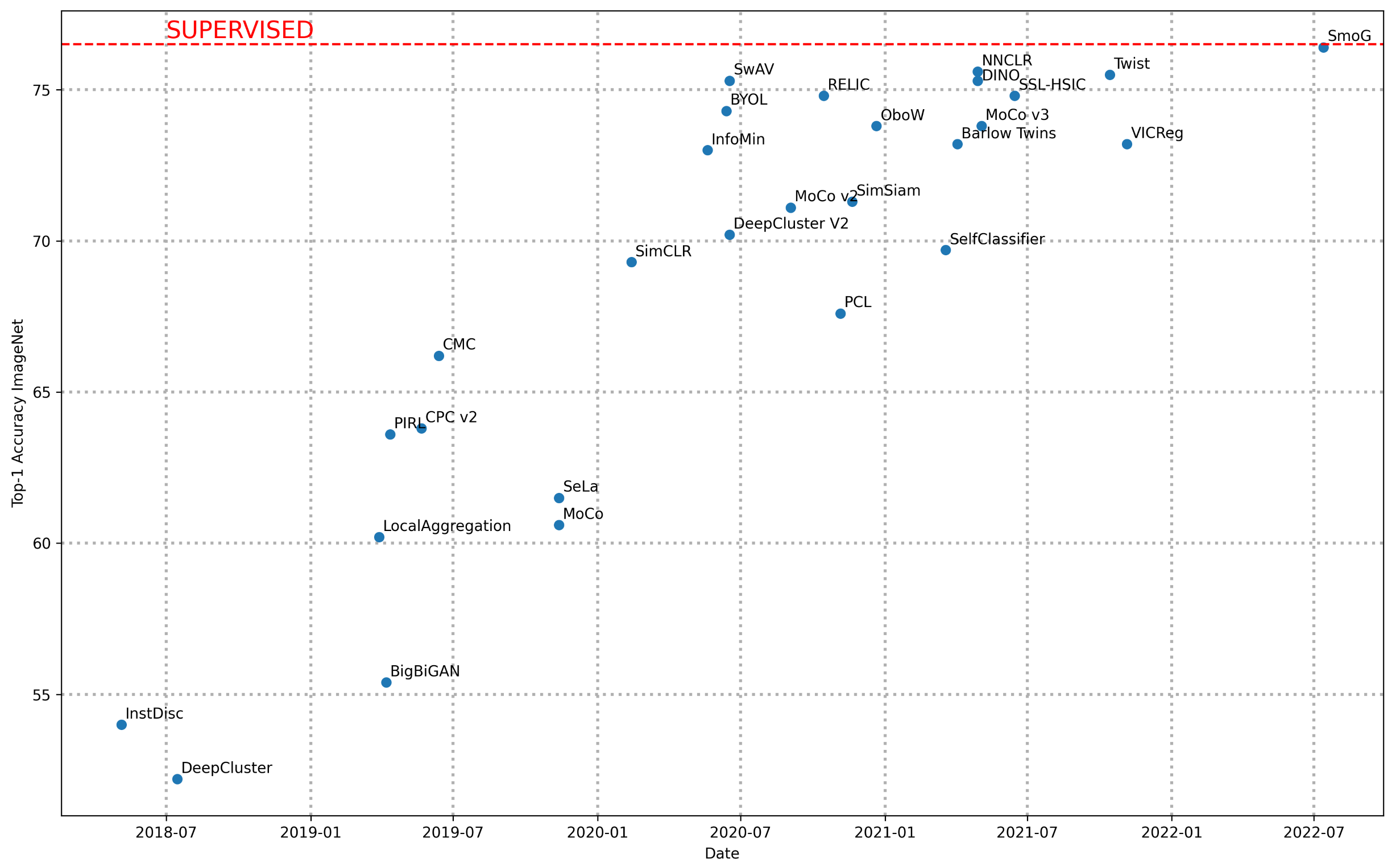
Выше приведёны значения метрик по этому протоколу по годам для архитектуры ResNet-50. Красной линией обозначено просто supervised обучение на ImageNet. Как мы видим SSL методы вплотную приблизились к supervised решению. Более полный список как различных архитектур моделей, так и разных SSL подходов как всегда можно найти на paperswithcode.
SSL with benefits
Fine-tune предобученных моделей - давно уже базовое поведение при разработке своих решений в машинном обучении. Однако использование SSL чекпойнтов для обучения несёт ряд преимуществ относительно supervised.
BONUS
Вот здесь можно подробнее почитать интересный обзор про файн-тюнинг предобученных моделей в NLP.
Метрики
В статье How Well Do Self-Supervised Models Transfer? авторы решили сравнить результаты предобучения supervised подходом и SSLем. Они сравнивали множество методов SSL на различных задачах и на разных датасетах, при этом зафиксировав архитектуру (ResNet-50) и основной датасет обучения (ImageNet). Основные выводы следующие:
SSL чекпойнты в большинстве случаях лучше перформят, чем supervised. (дополнительный репорт с таким же выводом - здесь)
Метрики топ-SSL и supervised близки для классификации (Many-shot и few-shot) (в этом исследовании похожие результаты)
Supervised со свистом проигрывает в трансфере на задачи детекции, сегментации и оценки нормалей.
Между SSL чекпойнтах в разных задачах выходят вперёд различные методы предобучения. Таким образом финальный выбор метода должен зависеть от downstream задачи.
Исходя из предыдущего, пока не придумано метода, который был бы универсальным.
Linear protocol на ImageNet сильно коррелирует с качеством на других датасетах, но только в задачах классификации. В задачах детекции корреляция снижается (до 0.2-0.3), в случае сегментации может быть вообще отрицательной. Можно сделать вывод, что эта метрика даже немного вредит задачам, отличным от классификации.
На кружочках ниже сравниваются методы по разным задачам. Как мы видим, базово хороший выбор следующий: SimCLR-v2, BYOL, DeepCluster-v2, SwAV

Robustness
Авторы статьи разбирают различные виды устойчивости сеток и приходят к выводу что SSL претрен увеличивает её по всем перечисленным направлениям:
Adversarial Perturbations - это когда мы добавляет случайный шум к картинке, что не меняет её для человеческого глаза, но заставляет ошибаться сеть
Common Corruptions - общее качество картинки (пережатие JPEG, расфокус, всякие шумы и проч) (здесь тоже приводят примеры большей устойчивости SSL, но на медицинских снимках)
Label Corruptions - неправильные лейблы. Разметка тоже обладает определённым качеством, и иногда она изначально ошибочная или противоречивая.
Правда, в статье используется достаточно древний SSL метод (Предсказание поворотов). Не нашёл более свежих исследований на эту тему. Если кто-то знает - киньте плз в комменты.
В статье Self-supervised Learning is More Robust to Dataset Imbalance делается вывод, удивительно похожий на название статьи.
Domain
В статье How Well Do Self-Supervised Methods Perform in Cross-Domain Few-Shot Learning? авторы показывают, что SSL чекпойнты также лучше подходят для задачи Cross-Domain Few-Shot Learning, чем supervised чекпойнт. Этому способствует улучшенная обобщающая способность SSL.
Practice
Когда доходит дело до практики, то можно выделить 2 основных вопроса - где взять уже претрененный чекпойнт, либо как обучиться самому на своих данных. На оба эти вопроса отвечают библиотечки, в которых воспроизведены методы SSL, а также есть Model Zoo, откуда можно забрать чекпойнты себе.
Списком перечислим библиотеки (отчасти пересекается со списком с paperswithcode):
В библиотеках представлены разные методы и разные предобученные модели. Ну и понятно, что для запуска своего обучения понадобится разобраться в настройках. Кроме библиотек также можно не забывать, что многие статьи выходят с кодом, поэтому можно забирать как код, так и чекпойнты у самих авторов методик.
Ну и можно ещё дать парочку советов:
Выбор аугментаций важен. Для большинства методов используются достаточно сильные аугментации, если в статье не сказано обратное. Baseline по выбору аугментаций - брать как в SimCLR
Есть различные стратегии дообучения downstream task (из предположения, что к feature extractor (fe) мы добавляем ещё слои) (имхо, предпочтительно 2 или 4 стратегия)
можно полностью зазморозить веса fe, учить только новые слои
можно поучить добавленные параметры с замороженными весами fe, потом веса fe разморозить и поучить совместно
можно сразу совместно учить и ничего не замораживать
можно учить с разными policy (веса fe обновлять с меньшим learning rate, например)
Итог
Мы рассмотрели множество основных методов SSL в CV на текущий момент. Конечно, много методов осталось на кадром, однако мы упомянули основные техники и идеи, которые используются сейчас для обучения без разметки. Как мне кажется, это очень перспективное направление исследований, которое в будущем будет многими восприниматься как бейзлайн для претрена моделей как минимум благодаря эффекту масштаба моделей и данных.
Надеюсь, что тебе было интересно читать и ты узнал(а) что-то новое!
CyaN
Спасибо! Интересный цикл. Продолжение планируется?
matantsev Автор
Спасибо!!
Я думаю над тем, чтобы покрыть ещё темы вокруг, по пока не буду ни на что коммититься)