
Мы рассмотрели ранее в цикле статей про SSL основные подходы к обучению моделей без разметки. Пока что за скобками остались методы, основанные на кластеризации, и настало время это исправить. В статье рассмотрим основные подходы как учитывать весь датасет при обучениии и пытаться растащить его в пространстве эмбеддингов.
Напомню, что это пятая статья из цикла про SSL в Computer Vision.
DeepClustering
????M. Caron, P. Bojanowski, A. Joulin et al. Deep Clustering for Unsupervised Learning of Visual Features(Июль 2018)
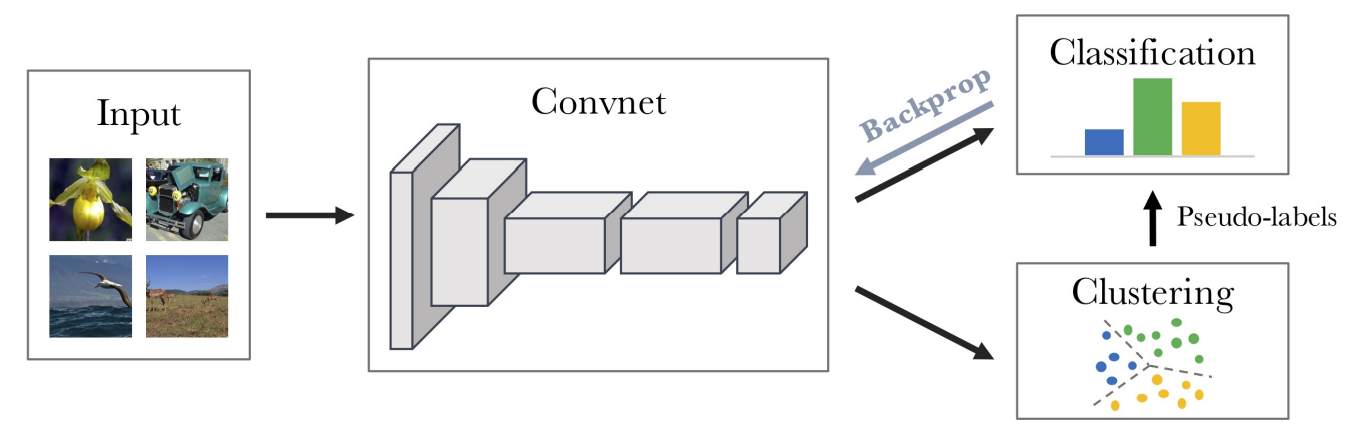
В этой работе авторы попробовали свести задачу обучения к оптимизации кластеров получаемых эмбеддингов. Процесс обучения выглядит следующим образом: через сеть прогоняются картинки, чтобы получить соответствующие эмбеддинги. Далее эти эмбеддинги кластеризуются методом k-means, здесь k - гиперпараметр обучения, благодаря этому мы можем присвоить каждому семплу свой pseudo-label (1 из k). Далее лосс функция составляется так, чтобы предсказания сети (feature extractor + классификатор) приближались к назначенным кластеризацией pseudo-labels.
При такой постановке возможно тривиальное решение - скатиться всем данными в 1 кластер. Для препятствия этому авторы постоянно пересчитывали кластера для всего датасета во время обучения (это заняло примерно треть времени обучения).
Интересно, что несмотря на то, что сеть учили на ImageNet (где 1000 классов), оптимальным количеством k оказалось 10000. Измерение качества кластеризации производилось нормализованной совместной информацией. К слову, это ещё один метод SSL, который страдает от более плохих результатов с conv5 чем conv4 (см. вторую статью этого цикла).
SeLA (Self Labeling)
????Y. Asano, C. Rupprecht, A. Vedaldi. Self-labelling via simultaneous clustering and representation learning [Oxford blogpost] (Ноябрь 2019)
Как и в предыдущей работе авторы генерируют pseudo-labels, на которых потом учится модель. Тут источником лейблов служит сама сеть. Дополнительным ограничением на модель, которое помогает, собственно, обучаться является требование на равномерное распределение лейблов по классам (или по кластерам, чтобы не терять привязки к заголовку). Авторы признают, что это грубое допущение, однако оно доказало свою полезность. Как и ранее, для расчёта равномерности распределения необходимо в процессе обучения пересчитывать лейблы по всему датасету.
Также авторы использовали аугментации в предположении, что лейбл после их применения не должен меняться.
SCAN (Semantic Clustering by Adopting Nearest neighbors)
????W. Gansbeke, S. Vandenhende, S. Georgoulis et al. SCAN: Learning to Classify Images without Labels(Май 2020)
Здесь авторы предлагают отказаться от end-to-end обучения и взять лучшее из 2х миров:
обучить сеть на pretext task
дообучить сеть на задаче кластеризации полученных представлений
fine-tune сети на задаче self-labeling
Теперь рассмотрим каждый пункт подробнее. В качестве pretext задачи подойдёт ± любая описанная ранее формулировка, где минимизируется расстояние между похожими изображениями (упоминают актуальные им MoCo, SimCLR и проч). Основная мотивация тут - кластеризация представлений без предварительного обучения даёт плохие результаты, кластеры могут получаться случайными. А если сеть заранее училась "притягивать" похожие объекты, то стартовая точка для оптимизации будет гораздо лучше.
Задача кластеризации здесь ставится необычным образом - каждому изображению ищется набор соседей (ближайших представлений в пространстве эмбеддингов среди датасета), далее сеть оптимизируется через задачу классификации, чтобы соседи получили одинаковые метки класса. Т.е. при остутствии истинных меток мы создаём искуственные (поверх преобученных представлений навесили softmax и получили soft-labels) и стягиваем соседей в одинаковую метку класса.
Полученные представления мы полируем уже более строгой задачей self-labeling - после всех проведённых процедур сеть умеет генерировать метки классов, однако в каких-то она уверена больше, в каких-то - меньше. Наподобие FixMatch преобразуем метки, в которых сеть достаточно уверена (вероятность больше порогового значения), в hard-labels и продолжим обучение как при обычной задаче классификации - с использованием кросс-энтропии.
Благодаря всем этим шагам (есть хорошее ablation study), получилось достичь SOTA по кластеризации датасетов, улучшив предыдущие результаты аж на 15-20%. И заодно получить качество при few-shot learning'е на 1% ImageNet несколько хуже, чем у других self-supervised подходов, но вообще не используя метки классов, только на кластеризации!
SwAV (Swapping Assignments between multiple Views)
????M. Caron, I. Misra, J. Mairal et al. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments(Июнь 2020)

Подход совмещает в себе одновременно и сиамские сети, и кластеризацию. Наиболее важное отличие состоит в матрице Prototypes. Это матрица обучаемых весов, которая по сути представляет из себя набор векторов - усреднённых по датасету семантических фичей, по идее они же образуют кластера. Ближайшая аналогия - матрица query из attention-блока. В этом методе используется свой лосс, который оптимизирует кросс-энтропию предсказаний q1 и проекции z2 на матрицу С (там не совсем проекция z на С, а софтмакс от их покомпонентного произведения). Т.е. представления составленные по одной аугментации изображения предсказываются по другой аугментации и контрастируют со всеми остальными изображениями в батче.
Ещё авторы задаются в статье вопросом - а почему собираются только 2 аугментации изображений, если можно больше. И предлагают идею мультикропа - собирать с изображения как большие кропы с глобальным контекстом, так и небольшие с деталями и обучать совместно. Только этот хак даёт +4% к результату! В дальнейшем эта фича разлетиться по статьям и будет широкоиспользуемой.

Подробнее обзор статьи можно поискать здесь, здесь и здесь
SEER (SElf-supERvised)
????P. Goyal, M. Caron, B. Lefaudeux et al. Self-supervised Pretraining of Visual Features in the Wild [Meta blogpost] (Март 2021)
В данной работе авторы исследуют эффект масштаба при обучении. Они используют метод SwAV и специально разработанную архитертуру RegNet (1.3B параметров). Основной вывод из исследования - масштаб работает примерно как и в NLP, чем больше модель и данных, тем больше эффект от обучения, с масштабом приходит улучшение метрик на few-shot learning. Ну и да, эта модель обгоняет supervised решение!
MAE (Masked AutoEncoder)
????K. He, X. Chen, S. Xie et al. Masked Autoencoders Are Scalable Vision Learners(Ноябрь 2021)

Статья вообще не про кластеризацию, но интересная и органично впишется дальше. В какой-то степени история циклична и мы возвращаемся снова к тому с чего начинали - можно замаскировать часть картинки и предсказывать её по оставшимся кусочкам. Только в этот раз с использованием ViT архитектуры, которая по построению позволяет разбить картинку на кусочки и подавать на вход в виде последовательности. Энкодер преобразовывал полученные кусочки в некоторое внутреннее представление, а декодер (тоже трансформер) восстанавливал исходное изображение, лосс - MSE.
Авторы вдохновлялись BERT'ом, реализовать такую же стратегию предобучения помогла схожесть архитектр (трансформеры). Однако, плотность семантической значимости у единицы информации различна - если в NLP слово представляет значение само по себе и в него запаковано много информации, то в CV один пиксель почти никогда не несёт значения, а сколько и какие несут - почти невозможно измерить. На основании этого авторы выдвигают гипотезу, что и процент замаскированных токенов должен отличаться. Так вместо 2-3 слов в предложении авторы маскируют 80% картинки. И получают отличные результаты!

MSN (Masked Siamese Networks)
????M. Assran, M. Caron, I. Misra et al. Masked Siamese Networks for Label-Efficient Learning(Апрель 2022)
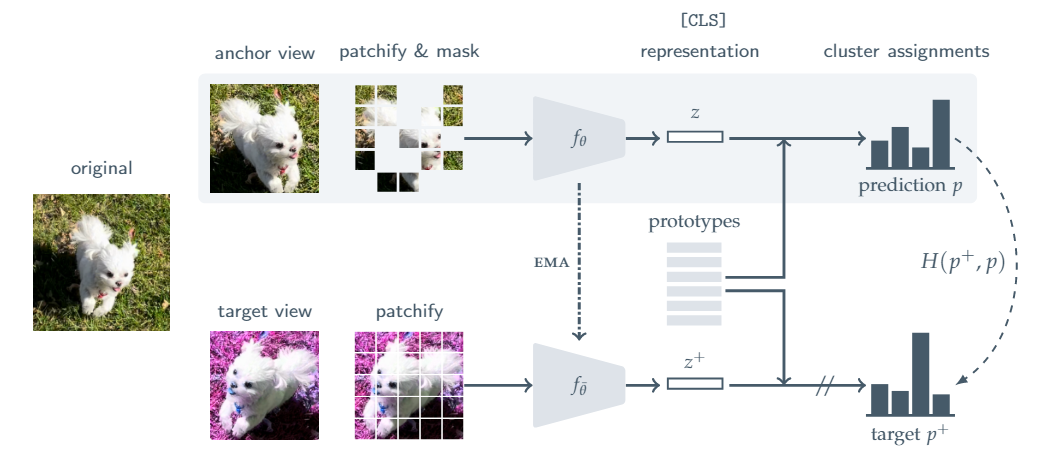
Здесь авторы решили собрать в общий котёл примерно все трюки, о которых мы говорили в последнее время: обучаемый блок Prototypes (из SwAV), Momentum encoder (ema), маскирование изображений (из MAE) и транформеры. В качестве лосса - обычная кросс-энтропия.
Вместо итога
Мы рассмотрели в этой статье методы, которые пытаются извлекать информацию сразу из всего датасета и каким-то образом кластеризовать получаемые представления, либо сконструировать ряд фичей-параметров, удобных для описания.
На этом мы закончим обзор основных методов в SSL, последняя статья будет посвящена качеству предобученных таким образом моделей и основным фреймворкам, которые позволяют всю эту радость быстро поднять у себя.