
В предыдущей статье мы рассмотрели общую суть SSL подходов и зачем они применяются. Настало время начать их разбирать более подробно.
В статье сперва пробежимся по основным методам обучения, использующим исключительно внутреннюю структуру изображения. Позже определим, как сравнивать различные методы без наличия как такового таргета, и посмотрим на метрики представленных выше методов. Спойлер - описанные методы далеки от лучших на данный момент, зато описывают эволюцию человеческой мысли.
Напомню, что это вторая статья из цикла про SSL в Computer Vision.
Восстановление картинки
Предсказание контекста куска изображения
????C. Doersch, A. Gupta, A. Efros. Unsupervised Visual Representation Learning by Context Prediction (Май 2015)
Базовая идея проста - если на картинке представлен объект, то он имеет какую-то цельную структуру. Следовательно, вырезав 2 куска из этой структуры, мы можем попытаться восстановить их взаимное расположение на изображении.

Оба патча - с центра и с периферии - прогоняются через 2 бекбона с общими весами (в папире использовался AlexNet), предсказывается положение периферийного патча относительно центрального (из 8ми возможных вариантов). Авторы обращают внимание, что важно вырезать патчи на некотором отстоянии друг от друга, иначе общие границы будут data-leak'ом. Ещё одним data-leak'ом были хроматические абберации на изображении, для их устранения авторы использовали специальный препроцессинг.
Разгадывание паззла (Jigsaw)
????M. Noroozi, P. Favaro. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles (Март 2016)
Идея созвучна с предыдущим методом, но авторы пошли дальше - вместо предсказания одного положения нейросетка должна была предсказать, как были перемешаны патчи относительно друг друга. Ближайшая аналогия - игра в пятнашки. Для 9ти патчей возможно 9!=362880 возможных пермутаций. Чтобы немного упростить задачу, авторы выбирали сабсет из 64 пермутаций. Как и в предыдущей постановке, каждый патч пропускали через бекбон с шаренными весами и после софтмаксом предиктили 1 из 64 возможных комбинаций.

Одним из интересных параметров является сложность задачи. Тут сложность авторы меряют с помощью расстояния Хемминга - метрики количества перестановок относительно базовой последовательности (123..89). В ablation study авторы показывают, что метрики лучше всего при балансе сложности - должны быть и простые перестановки (только 2), так и сложные (все 9). Оптимум при среднем количестве пермутаций = 8. И предлагают такой слоган:
A good self-supervised task is neither simple nor ambiguous
Маскирование изображений
????D. Pathak, P. Krahenbuhl, J. Donahue et al. Context Encoders: Feature Learning by Inpainting (Апрель 2016)
Тут задача тоже достаточно понятная - замаскировать часть картинки и учить сеть предсказывать замаскированную часть. Авторы использовали 2х компонентный лосс - кросс-энтропия восстановленного куска относительно оригинала и состязательная часть (которая буква A из GANов). Сеть состояла из энкодера + декодера (по сути, автоэнкодер). Из бонусов такого подхода - готовые предобученные веса для сегментации (спойлер, не самого хорошего качества).

Колоризация изображения
????G. Larsson, M. Maire, G. Shakhnarovich. Learning Representations for Automatic Colorization (Март 2016)
Ещё одна идея на поверхности - для каждого пикселя можно предсказывать его цвет. Для описания каждого пикселя авторы используют гиперколонки - соответствующие пикселю значения активации с каждого свёрточного слоя (см. картинку ниже). В качестве лосса - близость предсказанного цвета к истинному в цветовой схеме Lab.

Предсказание поворотов
????S. Gidaris, P. Singh, N. Komodakis. Unsupervised Representation Learning by Predicting Image Rotations (Март 2018)
Логика, предложенная авторами статьи, следующая: чтобы эффективно предсказывать угол поворота картинки, сеть должна уметь доставать семантику изображения (синица сидит на ветке - голова сверху, лапки внизу).
Следовательно, даже базовая постановка задачи - предсказывать поворот, ведёт к глубокому пониманию семантики сцены изображения. Вся постановка задачи уже описана - поворачиваем картинку на 0, 90, 180 или 270 градусов и предсказываем классификацией какой был угол поворота. Интересно, что 4 угла работают лучше, чем 8 (эти + со сдвигом на 45).

Основные метрики SSL
По очевидным причинам, мы не можем просто применять метрики классификации или регрессии или чего-то другого - ведь нет таргета, с которым можно предсказания сравнивать. Даже если мы будем измерять качество на pretext задачах, то, во-первых, они все разные, а во-вторых, качество на них нам не очень интересно. Ведь цель состоит в том, чтобы предобучить качественный feature extractor и переиспользовать его в downstream задаче.
Следовательно, измерять необходимо качество эмбеддингов, получаемых из фиче экстрактора. Пройдёмся по некоторым методам измерений.
Кластеризация и похожесть ближайших соседей
Хотелось бы иметь какое-то осмысленное представление эмбеддингов относительно содержимого картинки. Вспомним каноничные примеры word2vec, где можно было складывать вектора и получать сложение смыслов. На базе таких представлений изображений можно было бы выстраивать целые сервисы вокруг поиска картинок с многофакторными фильтрами. Однако, часто отдельные компоненты пространства эмбеддингов изолированного смысла не несут.
Тогда можно предположить, что в пространстве эмбеддингов рядом будут находиться похожие изображения и кластеризовать их. В общие кластера попадут схожие изображения. Однако, без разметки такой подход больше качественный, нежели количественный, и не может выступать надёжной метрикой.
Предсказательная способность по эмбеддингу
Логично связать метрику с задачей, которую мы хотим решать. Исторически это задача классификации. Исторически на датасете ImageNet. Получение метрики описывает Linear evaluation protocol (насколько метрика хороша обсуждается в последней статье цикла):
Предобучаем SSL метод на ImageNet
Каждой картинке из ImageNet ставим в соответствие эмбеддинг, полученный из замороженного feature extractor
Поверх эмбеддингов тренируем линейную модель на определение метки класса
Оцениваем качество как обычно на ImageNet (top-1 (top-5) Accuracy)
Строго говоря, необходимо ещё тестировать на одной и той же архитектуре (обычно ResNet-50). Однако, сейчас начали появляться методы SSL сугубо под трансформеры, ResNet сюда уже банально не влезает.
Кроме Linear evaluation protocol существуют также и протоколы на других датасетах и на других типах задач.
Также кроме стратегии полного замораживания весов есть протокол дообучения на нескольких экземплярах классов из датасета (Few-shot learning). Обычно это 1%, 5% или 10% от ImageNet. Дообученные модели сравнивают с supervised (на таком же количестве семплов), с претреном на другом датасете, с другими SSL методами.
Качество методов SSL по восстановлению картинки
Описанные выше методы были первой пробой пера на ниве SSL и на текущий момент далеки от топовых решений. Поэтому и метрики невысокие. В таблице ниже приведена точность (Accuracy) по linear evaluation protocol для различных слоёв свёрточной сети, сравнение с supervised обучением и с рандомной инициализацией. (Интересно, что рандомная инициализация должна выдавать вероятность классов - порядка 0.3 процентов. Тут, однако, качество существенно выше. Это говорит о том, что сама по себе структура последовательных свёрток генерирует небесполезный сигнал).

Интересной особенностью является падение качества при использовании фичей с последнего слоя блока свёрток (Conv5) относительно предыдущего (Conv4). Эта зависимость хорошо видна на графике ниже.
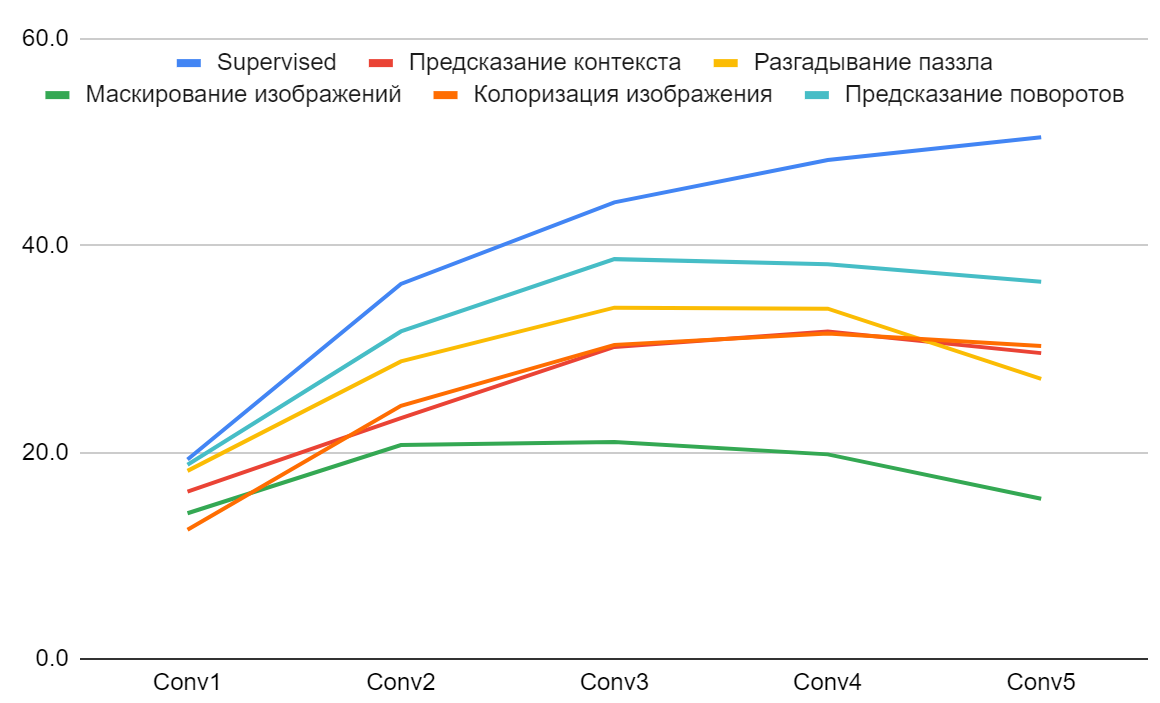
Основной причиной такого поведения является появление специализации у последнего блока свёрток, он переобучается под решение заданной ему задачи SSL. Это является проблемой, которая решается в последующих статьях.
Вместо итога
В этой статье мы рассмотрели основные методы SSL, который оперируют исключительно одним изображением для обучения модели. Также упомянули основные метрики оценки качества SSL решений.
В следующей статье посмотрим, что можно выжимать из картинки и коробки с аугментациями!