
Что таит в себе будущее дата-инжиниринга? В этой статье я поделюсь своими прогнозами на 2023 и последующие годы.
Статьи с прогнозами на следующий год — это банально, но у них есть своя цель. Они помогают нам подняться над повседневной рутиной и подумать над тем, что принесёт выгоду в долгосрочной перспективе.
Кроме того, они обычно бывают упражнениями в смирении: мы пытаемся нарисовать целостную «общую картину» отрасли, стремительно эволюционирующей во множестве направлений. Попробуйте-ка найти отрасль, в которой людям сильнее нужно поддерживать актуальность своих знаний!
Эти возможные направления развития становятся ещё более важными, когда занимающиеся данными организации начинают оценивать и переоценивать свои приоритеты в свете экономической рецессии и когда от инвестиций в дата-инжиниринг зависит способность компании оставаться гибкой, инновационной и конкурентоспособной.
Но есть и хорошие новости: нужда — мать изобретательности, поэтому я прогнозирую, что 2023 год станет успешным для технологий, помогающих командам экономить время, прибыли и ресурсы на DataOps, чтобы инженеры могли сосредоточиться на создании, масштабировании и повышении своей эффективности.
Ниже представлены мои прогнозы по одним из самых важных трендов, которые продолжатся в следующем году (вне какого-либо порядка приоритетности).
▍ Прогноз №1: команды дата-инженеров будут тратить больше времени на FinOps/оптимизацию затрат на облака данных
Так как всё бОльшая работы с данными перемещается в облако, я предвижу, что данные будут становиться всё большей статьёй расходов компании и привлекать больше внимания финансовых отделов.
Не секрет, что макроэкономическая среда начинает переход от периода стремительного роста и получения прибыли к более сдержанной оптимизации операций и доходности. Мы видим, что всё больше финансовых директоров начинают играть важную роль в командах по обработке данных и логично, что это партнёрство включает в себя решение задачи текущих расходов.
Команды обработки данных по-прежнему будут должны делать свой вклад в бизнес, увеличивая эффективность других команд и повышая прибыль при помощи монетизации данных, однако всё более важной третьей задачей будет становиться оптимизация затрат.
В этой сфере опыта всё ещё очень мало, поскольку команды дата-инженеров раньше делали упор на скорость и гибкость, чтобы выполнить наложенные на них исключительные требования. Основная часть их времени уходила на написание новых запросов или передачу новых данных, а не на оптимизацию тяжёлых/некачественных запросов.
Оптимизация затрат на облака данных также является основным интересом поставщиков услуг хранилищ и lakehouse-данных. Да, разумеется, им нужно, чтобы потребление росло, однако пустые траты приводят к оттоку пользователей. Им хотелось бы стимулировать рост потребления благодаря таким продуктам, как дата-приложения, которые обеспечивают пользу для клиентов и повышают retention. В этом бизнесе они собираются оставаться надолго.
Именно поэтому всё больше начинают говорить о стоимости владения, как это было в моих беседах на недавнем сеансе конференции с CEO Databricks Али Гходси. Также мы наблюдаем, что все крупные игроки (BigQuery, RedShift, Snowflake) делают упор на оптимальные методики и функции, связанные с оптимизацией.
Это увеличение трат времени, скорее всего, будет вызвано и увеличением штата, которое будет более тесно связано с ROI. Его будет проще обосновать, поскольку найму станут уделять особое внимание (опрос фонда FinOps предсказывает, что в среднем количество сотрудников FinOps в компаниях вырастет с 5 до 7 человек). Скорее всего, также изменится и распределение времени у сотрудников команд обработки данных, так как они будут использовать новые процессы и технологии с целью повышения эффективности в других областях, например, в сфере надёжности данных.
▍ Прогноз №2: всё бОльшая специализация обязанностей в команде обработки данных
В настоящее время обязанности в командах сегментированы в основном по этапу обработки данных:
- дата-инженеры поставляют данные,
- инженеры-аналитики очищают их,
- аналитики данных/дата-сайентисты визуализируют их и делают из них выводы.
Эти должности никуда не денутся, однако я считаю, что возникнет дополнительная сегментация по задачам бизнеса:
- инженеры по надёжности данных будут обеспечивать качество данных,
- менеджеры по результатам обработки данных будут увеличивать степень внедрения и монетизацию,
- инженеры DataOps сосредоточатся на data governance и эффективности,
- архитекторы данных займутся преобразованием обособленных баз данных (data silo) и долговременными инвестициями.
Это будет отражать изменения в соседней области разработки ПО, где должность разработчика ПО начала разделяться на более нишевые должности, например на инженера DevOps или инженера по обеспечению надёжности сервисов. Это является естественной эволюцией, потому что профессии начинают взрослеть и становиться более сложными.
▍ Прогноз №3: данные становятся более ячеистыми, однако централизованные платформы данных сохранятся
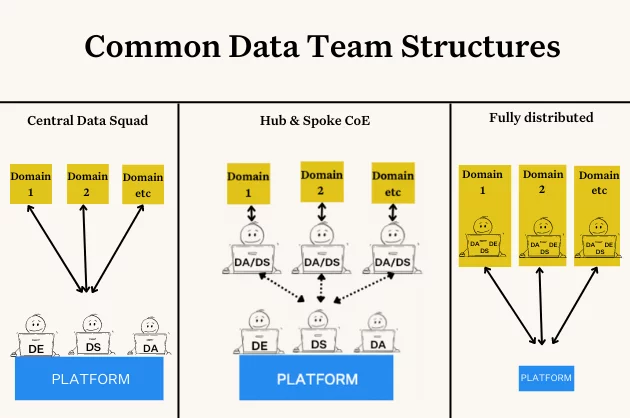
Прогноз о том, что команды обработки данных продолжат двигаться в сторону data mesh (впервые об этом сказал Жамак Дегани), не является таким уж смелым заявлением. Data mesh уже много лет остаётся одной из самых популярных концепций в сфере команд обработки данных.
Однако я наблюдаю, что всё больше команд делают паузу на этом пути, останавливаясь на системе, сочетающей в себе команды, занимающиеся отдельными предметными областями, и center of excellence или команду, занимающуюся платформой. Многим командам этот организующий принцип даёт преимущества обеих систем: гибкость и согласованность децентрализованных команд с эффективными стандартами централизованных команд.
Я считаю, что некоторые команды продолжат свой путь к data mesh, а для некоторых эта пауза станет конечной точкой. Они будут использовать такие принципы data mesh, как архитектуры с упором на предметную область, самообслуживание и работу с данными как с продуктом, но останутся мощной централизованной платформой, имеющей команду «спецназа» по дата-инжинирингу.
▍ Прогноз №4: до продакшена будет добираться большинство моделей машинного обучения (>51%)
Я считаю, что в среднем организации смогут успешно развёртывать больше моделей машинного обучения в продакшене.
Если вы посещали в 2022 году технологические конференции, то можете подумать, что все мы живём в нирване машинного обучения, ведь успешные проекты часто делают важный вклад и о них интересно рассказывать. Однако это скрывает тот факт, что большинство проектов ML проваливаются, даже не появившись на свет.
В октябре 2020 года компания Gartner сообщила, что лишь 53% проектов ML добираются от прототипа до продакшена, и это в организациях, имеющих определённый опыт работы с AI. У компаний, всё ещё работающих над разработкой своей культуры обработки данных, показатели, скорее всего, гораздо хуже: по некоторым оценкам, провалом завершаются до 80% или более проектов.
Существует множество сложностей:
- Несогласованность между потребностями бизнеса и целями машинного обучения.
- Обучение моделей машинного обучения, которое невозможно обобщить.
- Проблемы с тестированием и валидацией.
- Сложности с развёртыванием и обслуживанием.
Я считаю, что ситуация для команд разработчиков ML начинает меняться благодаря сочетанию повышенного внимания к качеству данных и экономической потребности увеличения удобства ML (в чём большую роль играют более удобные интерфейсы наподобие ноутбуков или приложений работы с данными наподобие Streamlit).
▍ Прогноз №5: первые этапы принятия контрактов данных

Все, кто следит за обсуждениями данных на LinkedIn, знают, что контракты данных — одна из самых обсуждаемых тем года. И на то есть причина: они связаны с одной из самых серьёзных проблем качества данных, с которыми сталкиваются команды обработки данных.
Неожиданные изменения схемы — причина большой части проблем с качеством данных. Чаще всего они становятся результатом того, что ничего не подозревающий разработчик ПО запушил обновление сервиса, не зная, что это создаёт хаос в системах данных ниже по потоку.
Однако важно заметить, что, несмотря на онлайн-шумиху, контракты данных по-прежнему находятся в зачаточном состоянии. Пионеры этого процесса, такие люди, как Чед Сандерсон и Эндрю Джонс, показали, как он может перейти из теории в практику, но в то же время очень чётко донесли, что в их организациях работа над этим всё ещё продолжается.
Я прогнозирую, что важность этой темы в 2023 году ускорит её реализацию на ранних этапах. Это подготовит фундамент для переломного момента в 2024 году, когда она начнёт проникать в мейнстрим или постепенно станет угасать.
▍ Прогноз №6: начинают размываться способы применения хранилищ и озёр данных

Ещё недавно можно было сказать, что озёра лучше для потоковой передачи, AI и других способов применения в data science, а хранилища данных (data warehouse) больше подходят для аналитики.
Однако в 2023 году это заявление будет воспринято с неодобрением.
В прошлом году хранилища данных сделали упор на функции потоковой передачи. Snowflake объявила о Snowpipe streaming и выполнила рефакторинг своего коннектора Kafka так, чтобы после попадания данных в Snowflake к ним сразу можно было выполнять запросы, что уменьшило задержки в десять раз. Google объявил, что теперь можно выполнять потоковую передачу Pub/Sub непосредственно в BigQuery, что существенно упрощает соединение потоков с хранилищем данных.
В то же время озёра данных наподобие Databricks обеспечили возможность добавления к хранимым данным метаданных и структуры. Databricks объявила о создании Unity Catalog — функции, позволяющей командам проще добавлять в их ресурсы данных структуры наподобие метаданных.
Ещё одной причиной гонки вооружений стали новые табличные форматы: Snowflake объявила о создании Apache Iceberg для потоковой передачи и hybrid transactional-analytical processing tables (HTAP) Unistore для транзакционных нагрузок, а Databricks сделала упор на свой формат delta table, имеющий одновременно свойства ACID и метаданных.
▍ Прогноз №7: команды быстрее начнут справляться с решением проблем аномалий в данных
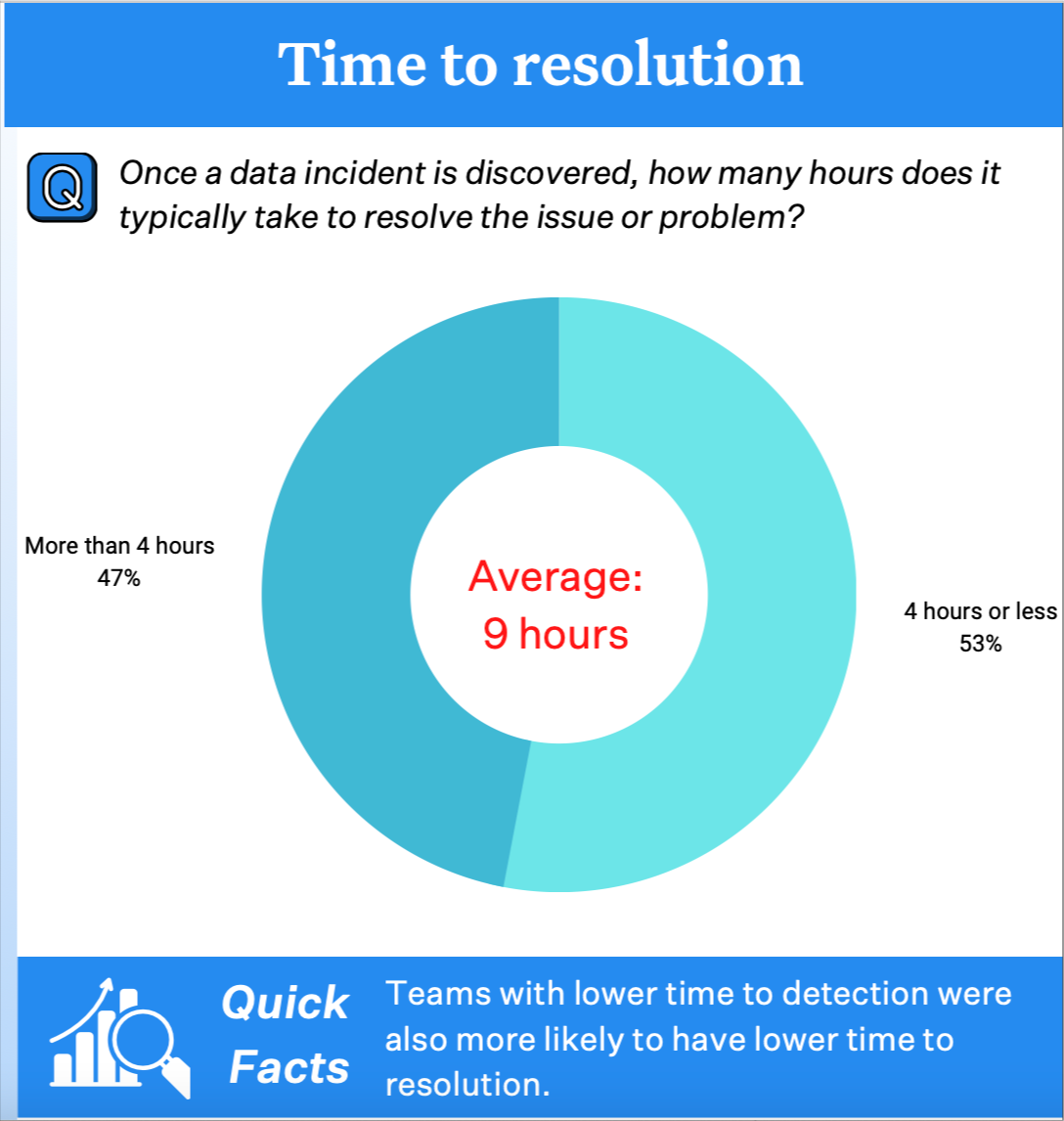
Опрос Wakefield Research за 2022 год показал, что более трёхсот профессионалов обработки данных тратят на качество данных в среднем 40% от рабочего времени. А это большое число.
Уравнение простоев из-за данных таково: количество инцидентов
x (среднее время на выявление + среднее время на устранение). Опрос Wakefield также показал, что организации в среднем сталкиваются с 61 инцидентом в месяц, выявление которых в среднем занимает 4 часа, а устранение — ещё 9 часов.Пообщавшись за этот год с сотнями руководителей команд обработки данных, я заметила, что многие снизили время выявления, перейдя от статического жёстко заданного тестирования данных к мониторингу данных на основе машинного обучения.
И это замечательно, поскольку создаёт потенциал для инноваций в сфере автоматического анализа первопричин. Функции наподобие анализа сегментации, выявления изменений запросов и генеалогии данных помогают сузить спектр возможных причин ошибок в данных, помогая понять, в чём проблема: в системах, в коде или в самих данных.
▍ 2023: в этом году big data станут меньше и удобнее для управления
В завершение 2022 года я хочу сказать, что сейчас настал уникальный момент для дата-инжиниринга, когда ограничения вычислительных ресурсов и накопителей были практически устранены — big data могут быть настолько большими, насколько им это нужно. Разумеется, как это всегда бывает, потом маятник качнётся в обратную сторону, но это вряд ли произойдёт в следующем году.
Поэтому самыми популярными тенденциями будут не оптимизация или масштабирование архитектуры, а процессы, делающие эту расширившуюся вселенную более упорядоченной, надёжной и доступной.
