
Резюме
Предсказать, выплатит клиент банка кредит или нет. Задача была предложена на интернет-турнире, устроенном одним банком. Один из примеров ее решения можно найти здесь. Наша цель состоит в построении решения на платформе Microsoft Azure.
Постановка задачи
Банк запрашивает кредитную историю заявителя в трех крупнейших российских кредитных бюро. Нам предоставляется выборка клиентов Банка в файле SAMPLE_CUSTOMERS (CSV). Выборка разделена на части «train» и «test». По выборке «train» известно значение целевой переменной bad — наличие «дефолта» (допущение клиентом просрочки 90 и более дней в течение первого года пользования кредитом).
В файле SAMPLE_ACCOUNTS (CSV) предоставлены данные из ответов кредитных бюро на все запросы по соответствующим клиентам. Формат данных из ответа бюро – информация о счетах человека, передаваемая другими банками в данное бюро. Подробно формат данных описан в файле ACCOUNT_DATA_FORMAT.
На выборке «train» необходимо построить модель, определяющую вероятность «дефолта», и проставить вероятности «дефолта» по клиентам из выборки «test».
Импорт набора данных в студию
Исходные данные представлены в формате CSV, однако студия правильно распознает CSV лишь с разделителями запятыми. Сохраним исходные файлы с информацией о клиентах SAMPLE_ACCOUNTS.CSV и SAMPLE_CUSTOMERS.CSV с требуемыми разделителями (для краткости SAMPLE_ACCOUNTS.csv был сохранен как Sdvch.csv) и загрузим их в azure.
Первичная обработка
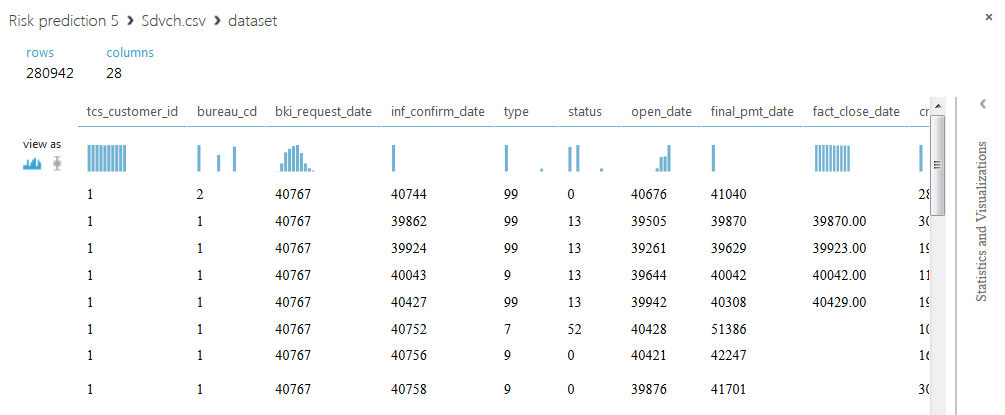
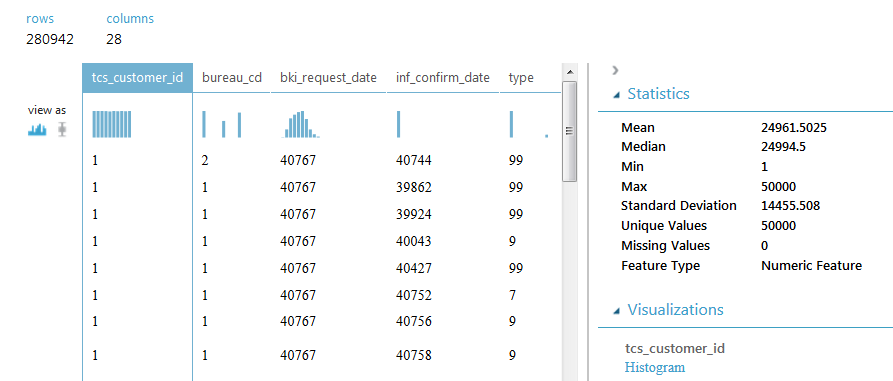
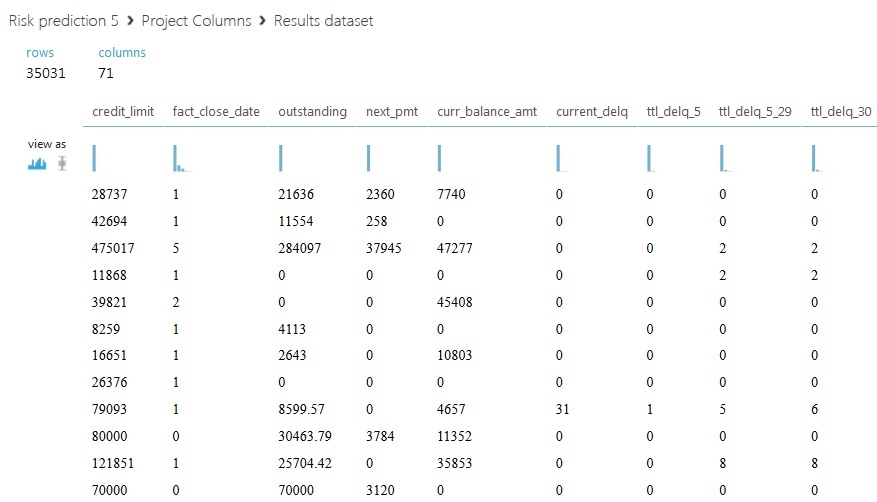
SAMPLE_ACCOUNTS содержит 280942 строк и 28 столбцов, в каждой строке указана информация по одному кредиту. В столбце с идентификаторами клиентов содержится 50000 уникальных значений, значит каждому клиенту может соответствовать несколько строк. Отметим, что некоторые кредиты повторяются, а значения некоторых полей отсутствуют. Содержимое столбцов будет раскрыто далее в ходе решения задачи.
Для того чтобы решить задачу, сведем всю информацию по каждому клиенту в одну строку. Для этого выполним скрипты на Питоне над базой данных.
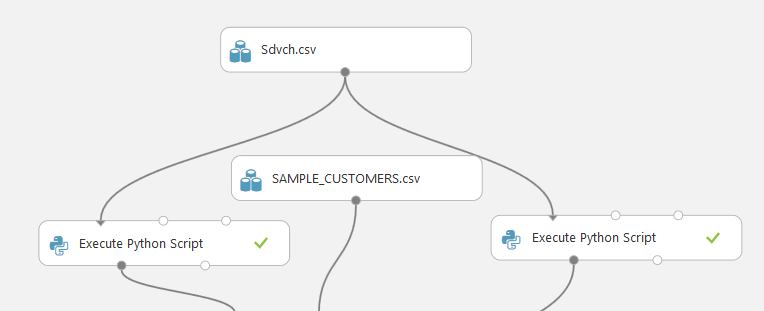
Первый скрипт, по сути, состоит из идей решения, о котором шла речь ранее. Вкратце расскажем их.
Шаг 1. Выкинем дублирующиеся кредиты (строки) из набора данных, оставив строку с самой последней информацией. Для этого определим набор столбов, который будет выступать в качества ключа, это: tcs_customer_id, open_date, final_pmt_date, credit_limit, currency (id, дата открытия кредита, предполагаемая дата последнего платежа, кредитный лимит, валюта); столбец inf_confirm_date (дата подтверждения информации по кредиту) будет определять, какой из дубликатов остается.
Шаг 2. Обработаем колонки: pmt_string_84m (своевременность платежей), pmt_freq (код частоты платежей), type (код типа договора), status (статус договора), relationship (тип отношения к договору), bureau_cd (код бюро, из которого получен счет). Посчитаем количество каждого уникального значения для каждого клиента и запишем эти значения в новые столбцы.
Шаг 3. Преобразуем поле fact_close_date, в котором содержится дата последнего фактического платежа, чтобы в нем содержалось только 2 значения: 0 — не было последнего платежа, 1 — последний платеж был.
Шаг 4. Переведем все кредитные лимиты к рублям. Для простоты берется курс 2013 года.
Шаг 5. Заполним пробелы в данных 0 и выполним заключительную группировку (с суммированием) по клиенту, при этом выкинем столбцы bki_request_date, inf_confirm_date, pmt_string_start, interest_rate, open_date, final_pmt_date, inf_confirm_date_max. Это значения дат и выплачиваемый процент с кредита.
Ниже приведен полученный набор данных.
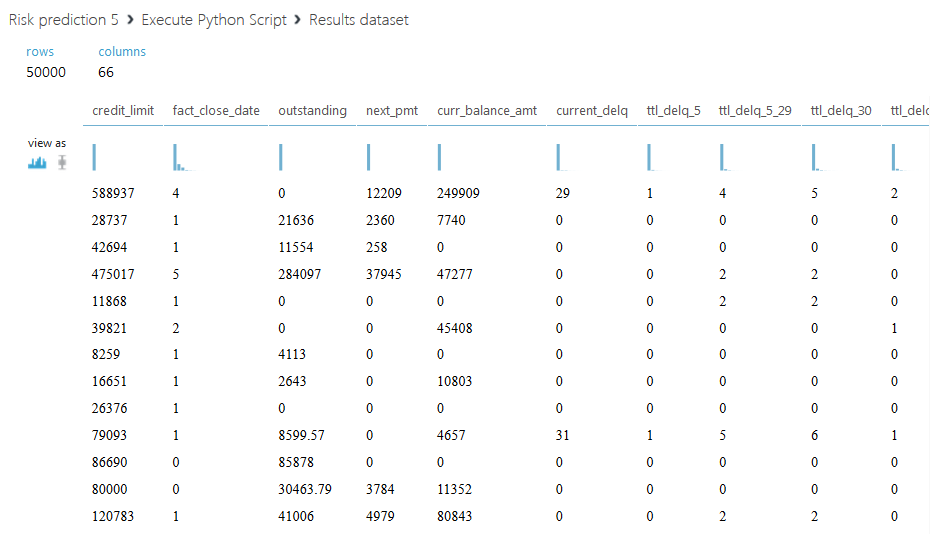
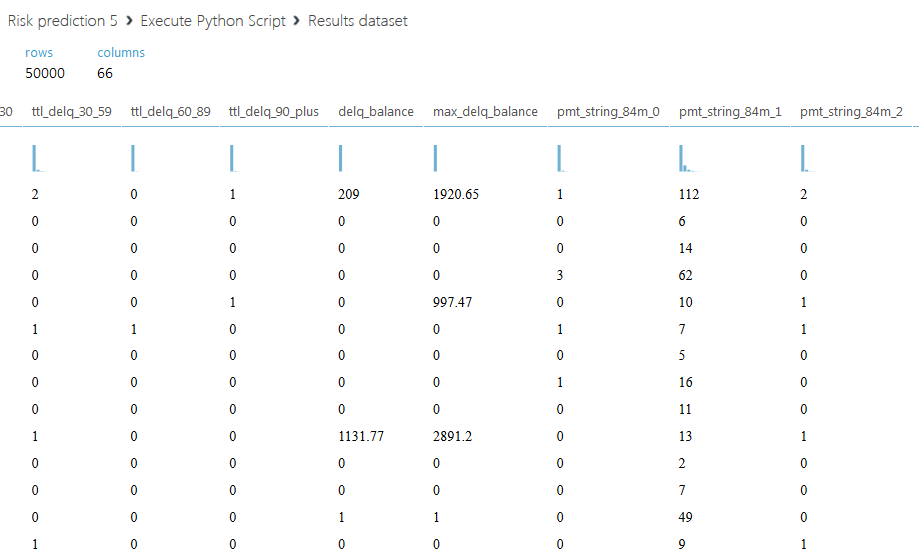
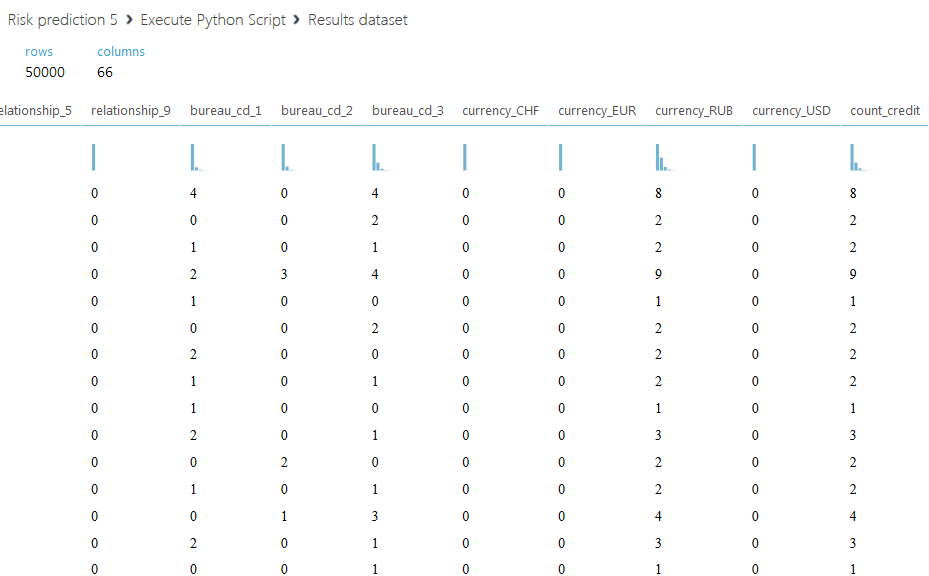
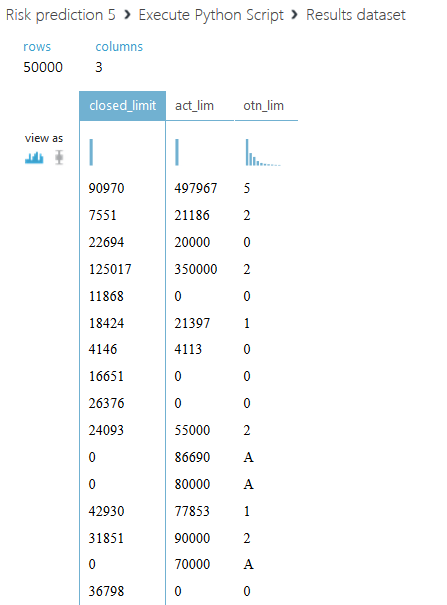
Остановимся подробнее на втором скрипте. Мы предлагаем не просто просуммировать все кредитные лимиты для каждого клиента, а разделить всю сумму на две части: активный кредитный лимит, со значением статуса 00, и закрытый — со всеми другими статусами. Также введем еще один столбец с отношением суммарного активного лимита к — закрытому, если сумма закрытого лимита равна нулю, то поле заполним буквой A. Код второго скрипта приведен ниже.
def azureml_main(dataframe1):
from pandas import read_csv, DataFrame,Series
import numpy
SampleAccounts=dataframe1
SampleAccounts.final_pmt_date[SampleAccounts.final_pmt_date.isnull()] = SampleAccounts.fact_close_date[SampleAccounts.final_pmt_date.isnull()].astype(float)
SampleAccounts.final_pmt_date.fillna(0, inplace=True)
#переносим дату фактич закрытия в дату конца
sumtbl = SampleAccounts.pivot_table(['inf_confirm_date'], ['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], aggfunc='max')
#sumtbl - содержит уникальные ключи с максимумом по дате подтв
SampleAccounts = SampleAccounts.merge(sumtbl, 'left', left_on=['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], right_index=True, suffixes=('', '_max'))
#в конце добавили макс дату подтверждения
SampleAccounts=SampleAccounts.drop_duplicates(['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']).reset_index()
df1=SampleAccounts.drop('index',axis=1)
curs = DataFrame([33.13,44.99,36.49,1], index=['USD','EUR','GHF','RUB'], columns=['crs'])
df2 = df1.merge(curs, 'left', left_on='currency', right_index=True)
df2.credit_limit = df2.credit_limit * df2.crs
#записали в кредитный лимит сумму в рублях
df2=df2.drop(['crs'], axis=1)
#выкинули курс
df3 = df2[['tcs_customer_id','credit_limit','status']]
df3['act_lim']=df3.credit_limit[df3.status==0]
df3.act_lim.fillna(0, inplace=True)
df4=df3.copy()
df4['credit_limit'] = numpy.where(df3['status']==0, 0, df3.credit_limit)
df5=df4.groupby('tcs_customer_id').sum()
df5.rename(columns={'credit_limit':'closed_limit'}, inplace=True)
df6=df5.drop('status',axis=1)
df6['otn_lim']=numpy.where(df6.closed_limit==0, 'A', df6.act_lim/df6.closed_limit)
return df6
Обработка средствами Azure
С помощью двух блоков «Add Columns» соединяем базы полученные в результате обработка скриптами с файлом SAMPLE_CUSTOMERS.


Далее делим выборку на две части с помощью блока «Split Data». Выбираем режим регулярного выражения и ставим условие на колонку «sample_type», нам нужны строки со значением «train».
С помощью блока «Project Columns» выбираем остающиеся для обработки колонки. Будем сравнивать два набора данных: слева со всеми полученными столбцами (кроме sample_type, он везде одинаковый «train»), справа без нашей модификации, то есть с исключением столбцов активного, закрытого лимита и их отношения (и sample_type).
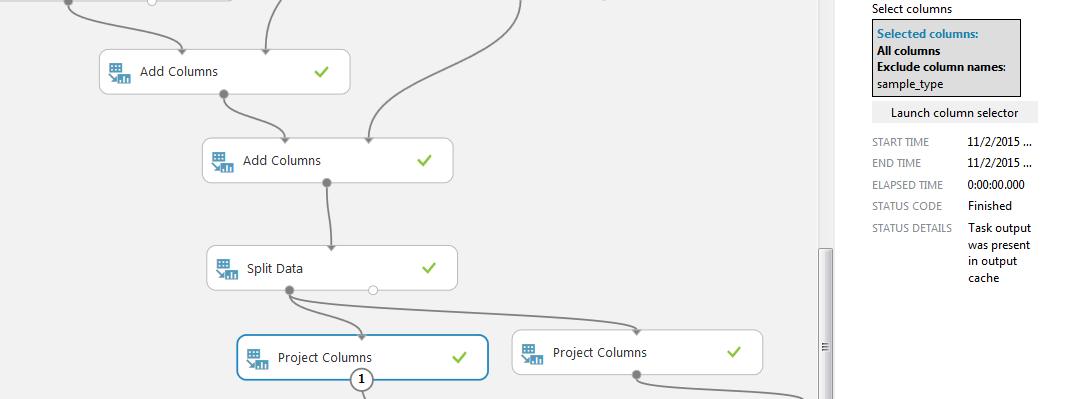
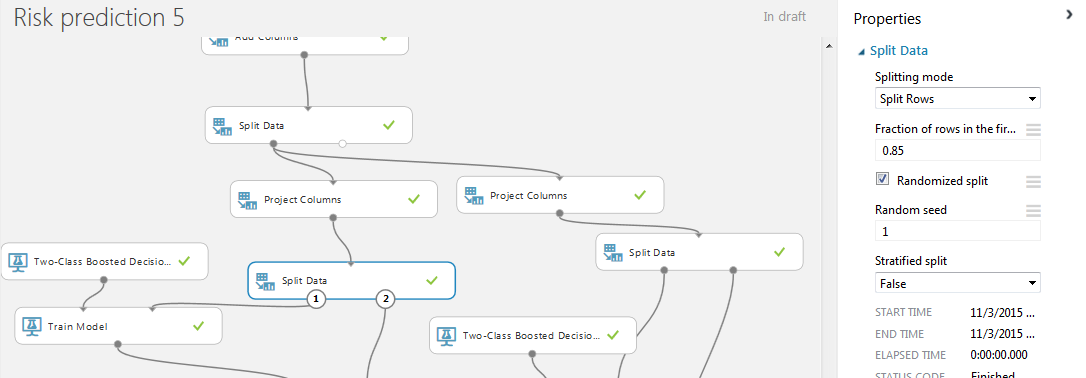
Теперь добавим в проект еще одну пару модулей «Split Data». На этот раз используем псевдослучайное разделение строк на две части с заданным полем «random seed». Это нужно для того, чтобы разделение выборки на две части происходило одинаково для левой и правой базы. Процентное соотношение для обучения и тестирования 85% и 15%. Это объясняется тем, что в нашем случаем база с 50000 клиентами уже была поделена на две выборки train и test. По идее, мы должны были бы обучатся на 100% базы train и проставить результат в test, но поскольку мы обучаемся и тестируем на train, то соотношение было выбрано более благоприятным, чем обычное 75/25 или 80/20.
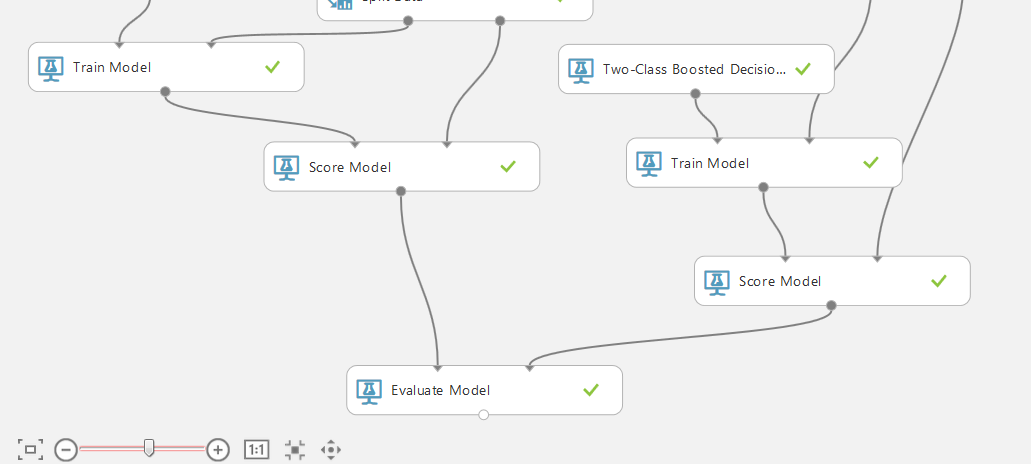
Для обучения модели будем использовать двухклассовое повышенное дерево принятия решений (двухклассовый бустинг) со стандартными значениями. Также добавляем модули «Train Model» и «Score Model». В «Train Model» указываем искомый столбец для прогнозирования bad.
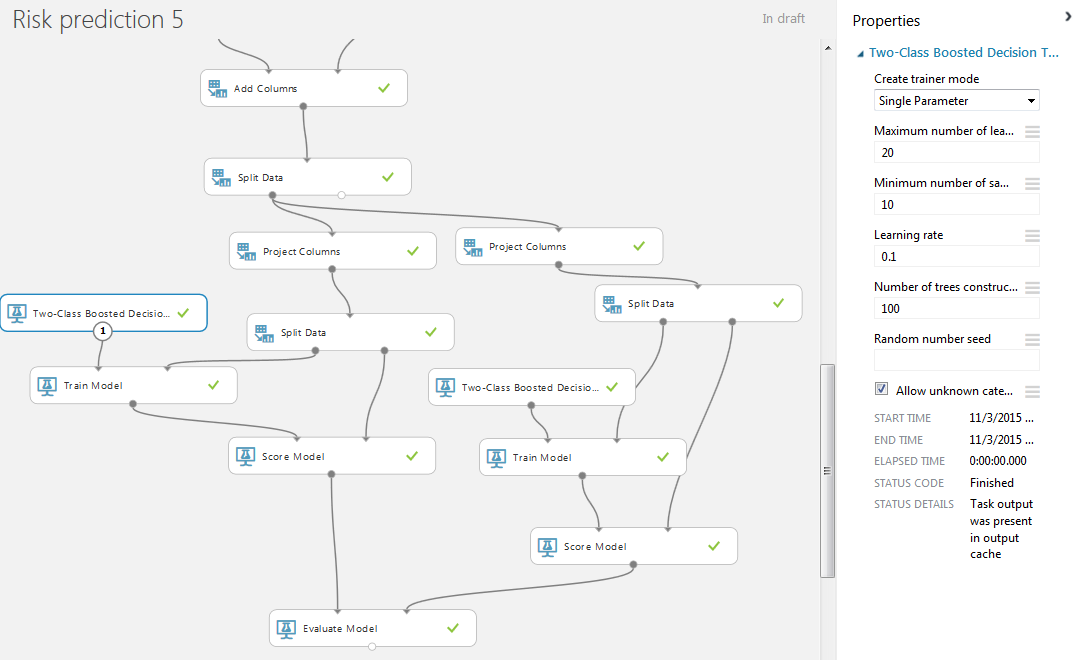
Визуализация левого блока «Score Model».

Осталось соединить выходы модулей «Score Model» со входами блока «Evaluate Model», который позволяет сравнивать результаты работы двух методов. В нашем случае — результаты работы одного метода классификации для двух разный наборов данных.
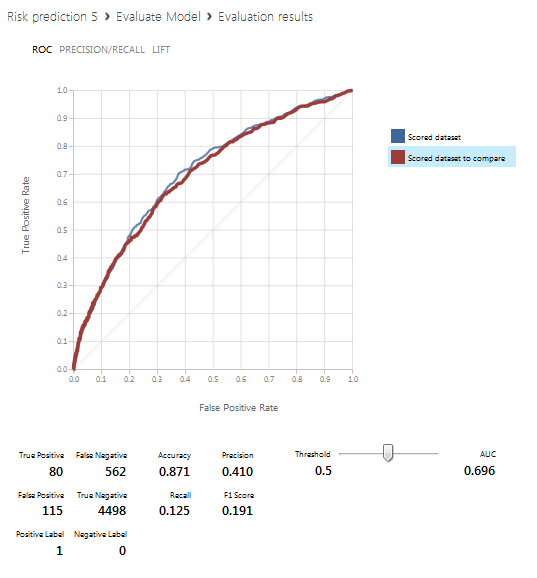
На следующем скрине приведена визуализация блока «Evaluate Model», то есть результаты прогнозирования. Синия линия соответствует левой базе данных (со всеми полученными столбцами), красная — правой (с исключением столбцов с активным, закрытым лимитом и их отношением).

Заключение
Учитывая распределение мест проведенного турнира,
- AUC 0.7057
- AUC 0.7017
- AUC 0.7012
- AUC 0.6997
Спасибо за внимание!
Используемые ресурсы
Комментарии (2)

Hebe
05.11.2015 14:48Возможно, Вас ввело в заблуждение названия test и train, но выборка train (результаты которой нам известны) была случайным образом поделена на две части: обучающую и тестовую. Машина обучалась на обучающей выборке, а тестировании проводилось на тестовой, о которой машина не имела понятия.
Ответ на вопрос: нет, модель дала результаты на тестовой выборке.
По поводу переобучения: переобучение в машинном обучении и статистике — явление, когда построенная модель хорошо объясняет примеры из обучающей выборки, но относительно плохо работает на примерах, не участвовавших в обучении.
Ответ на ваше предположение: нет, с переобучением у модели проблемы нет.
ServPonomarev
То есть, Вы построили модель, которая на обучающей выборке дала результаты лучше чем у конкурсантов? При этом, не сказать, что модель особо сложная. Так что я полагаю, у Вас проблема с переобучением модели. И сильная.