
В этой статье мы поговорим об особенностях машинного обучения, и о том, как можно соединить Deep Learning и Master Data Management. Разберем достаточно подробный пример использования глубокого обучения для управления данными.
Управление данными и глубокое обучение
Сейчас идёт период бурного развития технологий машинного обучения в самых разных направлениях. Любая модель машинного обучения должна на чём-то учиться и корректироваться, поэтому важность данных, на которые она опирается, существенно возрастает.
Это подтверждает тот факт, что существуют уже сложившиеся инструменты и методологии управления самыми разными типами данных, которые нужны для обучения. В связи с этим появляются вопросы о их совместном использовании, наподобие: а можно ли применять машинное обучение для технологий управления данными, и что при этом получится? Вроде бы нужны данные, чтобы обучиться, а чему именно учиться, и как это сделать в условиях, когда эти данные постоянно меняются? Как собирать постоянно увеличивающиеся объемы, и чтобы при этом построенный инструмент адаптировался к изменяющимся данным и их форматом? Вот лишь некоторые вопросы, которые сразу приходят в голову.
Если сильно упростить, то все алгоритмы глубокого обучения строятся на трех важных столпах: правильные тестовые данные (размеченные или неразмеченные), подходящая архитектура, и подходящая функция оптимизации, которая на новых данных (а в случае применения к потоку данных у нас новые данные есть всегда) будет оптимизироваться.
Оказывается, что на методологическом и алгоритмическом уровне технологии глубокого обучения (Deep Learning) и управления данными (Data Management) очень похожи: для начала работы нужно определить природу данных, поскольку от этого напрямую зависит архитектура используемой вычислительной сети, и инструментарий управления данными.
Также в обоих случаях следует выделить небольшой объем тестовых данных для обучения. Например, в области управления данными важно настраивать правила качества данных и правила слияния данных на небольшом тестовом наборе. Причем интересно, что для работы с метаданными самого машинного обучения, т.е. данными и артефактами, которые появляются в процессе самого обучения, уже есть целый ряд инструментов, например, Vertex ML Metadata, ML Metadata и другие. Таким образом, можно сказать что применяется управление метаданными для служебной информации процесса обучения.

Если же подойти к вопросу о применимости алгоритмов глубокого обучения к типовым задачам управления данными, то получаются очень интересные результаты для работы с потоками данных, неизвестными выгрузками, обратной инженерии данных, и прочим. Например, адаптивные правила качества или инструменты управления меняющимися метаданными, но это предмет для отдельных публикаций. В этой статье мы лишь немного затронем вопросы применимости, и постараемся разобрать вполне конкретную задачу типизации и семантики. Типизация и семантика в пригодном для глубокого обучения виде сама по себе не тривиальный вопрос. Также попробуем довести задачу до решения и итоговой архитектуры алгоритма.
Постановка задачи
Пусть мы имеем на входе определенные данные в виде бинарного файла. Задача классического профилирования данных (data profiling) состоит в том, чтобы определить «что это за данные», т.е. понять тип, структуру, наиболее часто используемые значения, заполненность данных и много других параметров. Но, в конечном итоге, узнать смысл этих данных, т.е. о чем конкретно говорят значения того или иного атрибута.
Это все звучит очень абстрактно. Давайте детализировать эту задачу, тем более что верхнеуровневый смысл входных данных (ID, Input Data) как правило ясен. Например, нам могут дать выгрузку из CRM-системы со словами «это наши заказчики» или текстовый файл с непонятными аббревиатурами, сокращениями и прочим, и назвать его «это список закупаемых компонентов для производства турбин».
Любая задача управления данными начинается с того, что мы анализируем данные (источники данных), которыми нам предстоит управлять. Классический подход состоит в том, что мы опрашиваем владельцев данных о том, какие типы данных используются, как часто обновляются, и задаем кучу других вопросов, ответы на которые требуют привлечения экспертов предметных областей.
По итогу этого «интервью данных» получается общая картина, правда уходит на это достаточно много времени, поскольку владельцы данных и эксперты предметных областей, как правило, достаточно занятые люди и несколько раундов вопросов и ответов занимают у них время и растягивают весь процесс «интервьюирования». А ведь источников данных может быть достаточно много. Например в одной большой международной корпорации такой процесс интервью «всего 9 источников» растянулся на более чем три месяца.
Было бы здорово получать полную информацию об источниках данных автоматически, на основе какого-то механизма, который сможет определить по данным их технический и семантический профиль. Да, существуют решения типа data crawlers, которые на программном уровне считывают технические метаданные (technical metadata) — обычно путем анализа системных таблиц СУБД.
Например, в Юнидата MDM это реализовано для целого набора типовых источников данных. Это хорошее начало для «процесса познавания данных», и если есть такая возможность, то с этого обязательно надо начинать. Например, можно сделать выгрузку среза базы данных, или же получить прямой доступ к резервной СУБД. Однако этот способ, во-первых, не везде применим. Во-вторых, нам могут дать прямую выгрузку в файл — просто корпус текстов1 и числовой информации, а, во-вторых, этот подход не дает ответа на самый главный вопрос — о семантике данных, т.е. о чем же говорит тот или иной атрибут.
Сноска 1
А это уже типичный кейс для технологий машинного обучения, то есть, набор данных, который можно использовать для тренировки или тестирования.
Пора сформулировать основную задачу более точно на математическом языке для того, чтобы применить к ней существующие архитектуры глубокого обучения или же скомбинировать их правильным образом. Есть произвольный набор входных данных (ID), необходимо ответить на вопросы:
Количество атрибутов данных (n), а значит набор данных будет трансформирован в набор входных векторов X размерности n — Xn;
Выявить типы этих атрибутов (T1 : Tn) — не только с точки зрения стандартных типов, но составить зависимые от контекста типы данных — например справочники (что очень актуально для всевозможных тематических аббревиатур) — Tn;
Выяснить их семантику (S1 : Sn), т.е. получить максимально близкое описание того о чем говорят значения данного атрибута, анализируя сами значения — Sn.
Пример: входные данные о заказчиках, упомянутых выше, где в одном файле перемешаны данные о физических лицах, юридических лицах, индивидуальных предпринимателях и, возможно, еще что-то. А на выходе мы бы хотели увидеть набор атрибутов ID, типизацию каждого атрибута и его семантическое значения, то есть что-то типа такой таблицы:
Атрибут |
Тип |
Типовые значения |
Описание (Семантика) |
Связные атрибуты |
1 |
Справочник [ООО, ЮЛ, ИП, ПАО, ЗАО, <пусто>] |
ООО, ЗАО, ПАО, ооо, гр. |
Юридическая форма |
|
2 |
Text |
Ромашка |
Название |
|
3 |
Text |
С-Петербург, 190000, ул. Верности |
Адрес |
|
4 |
Number |
1, 1000 |
Сумма заказа |
5 |
5 |
Date |
18.7.2018, 30/12/2021 |
Дата заказа |
4 |
… |
… |
… |
… |
В приведенном примере мы пошли немного дальше, а именно указали типовые значения, а также предполагаемые связанные по смыслу атрибуты (дата и сумма заказа). И одно и другое мы получим «бесплатно» по пути решения поставленной задачи, и при этом нам очень пригодится первое (типовые значения) для быстрой верификации типизации и семантики, а второе — это прямое указание на то, что бывают очень связанные по смыслу атрибуты. Последнему в предлагаемой архитектуре глубокого обучения (нейронных сетей2) нам потребуется уделить этому особое внимание.
Сноска 2
Здесь нужно сказать пару слов о терминологии. Считается, что одно из прежних названий глубокого обучения – искусственные нейронные сети. Им соответствует взгляд на DL модели, как на инженерные системы, устроенные по образцу биологического мозга (т.н. вторая волна популярности коннекционизма или нейронных сетей 1980-е -2000-е годы). Однако современный термин «глубокое обучение» выходит за рамки нейробиологического взгляда, т.к. в нем заложен более общий принцип обучения нескольких уровней композиции, применимый к системам машинного обучения, не обязательно устроенным по примеру нейронов.
И еще сделаем важное предположение, что ID — размеченный массив данных, т.е. разбит на записи, и мы уже его проанализировали и знаем, что в каждой записи есть n атрибутов (т.е. ответили на вопрос 1). Простое решение этой задачи не требует привлечения глубокого обучения, и позволяет сразу перейти к самому интересному. Как к этому прийти в случае сложных входных данных расскажем позднее, т.к. задача этой публикации показать применение моделей глубокого обучения для типизации и поиска семантики атрибутов.
Погружаемся в термины
Для определения, какие виды архитектуры глубокого обучения нам подходят, перейдем на язык формул. Мы разберем отдельно задачи типизации и семантики, и в конце предложим единую архитектуру сети, которая позволит объединить обе задачи и решать их одновременно, что существенно сэкономит время и вычислительные ресурсы.
На входе мы имеем матрицу входных данных (ID), т.е. набор векторов значений размерности n — Xn. А на выходе — вектор типизации Tn, и вектор текстовых описаний каждого поля Sn.
С точки зрения типизации это не просто задача классификации, где мы соотносим один из фиксированных типов со значением, но должны иметь возможность порождать новые типы данных, особенно справочные типы.
Чтобы учесть специфику решаемой задачи выделим в Xn — признаки3, т.е. очень ограниченные и атомарные данные об Xn, которые позволяют «угадать типизацию».
Сноска 3
Признак – отдельный элемент информации, включаемый в представление об объекте.
т.е. каждому вектору мы сопоставляем матрицу признаков xi -> Rij.
В нашей задаче мы начнем с тривиальных признаков, приведенных ниже, а затем будем дополнять набор признаков. Как будет ясно из вида целевой функции оптимизации, чем больше будет такой набор признаков, тем точнее локальный максимум функции оптимизации будет определять подходящий тип.
Поле — текст;
В тексте только заглавные буквы
Число, встречается только знаки «%»
Текст, но там только числа и знаки «/»
Как видно из этих примеров, каждый признак намекает нам на то, что это значение близко к какому-то типу, которые в свою очередь обладают фиксированным набором своих признаков. А более формально:
Поскольку мы изначально можем задать такие признаки, то мы сильно упростим задачу нашему алгоритму. Однако, ясно, что полностью определить все признаки мы не в состоянии, и здесь перекладываем работу на нашу вычислительную (нейронную) сеть. Именно она найдет все возможные признаки отнесения значения x к тому или иному типу, и возможно даже скрытые от нас признаки. Именно поэтому такие признаки в теории глубокого обучения называются скрытыми факторами.
Задача поиска семантики должна учитывать не только само значение Xn, его признаки Rnxr, установленный тип Tn, статистику и смысл предыдущих значений и, что важно, соседние поля, т.к. они могут привносить дополнительный смысл. Поскольку на выходе мы ожидаем описательное предложение, то все это несколько усложнит архитектуру сети для этой задачи, но в итоге мы все равно придем к единому алгоритму решения.
Архитектура задачи типизации
Можно подходить к задаче типизации как к задаче о классификации с очень простыми типами данных. Однако это не позволяет получить полную информацию о сложных и зависимых типах данных.
Поэтому мы начнем с базовых типов (текстовые поля, числа, даты и пр), но также будем создавать новые типы данных. Более того, нам необходимо учитывать то, что данные скорее всего будут дискретны. Здесь возможно два подхода, в зависимости от того можем ли мы предсказать плотность распределения значений p(Xn) по типам, или же это представляет для нас черный ящик.
Первый подход, в свою очередь, определяет модели с явно выраженной плотностью (если следовать классификации порождающих моделей, введенных Иэном Гудфеллоу4). Учитывая дискретность значений, этот подход приведет нас к применению вариационных приближений (VAE). Однако, мы пошли по более простому пути и предположили, что наша нейронная сеть сама напрямую смоделирует сэмплирование из модели, т.е. сможет сгенерировать примеры, соответствующие модели.
Сноска 4
Эта книга является одной из основополагающих для порождающих нейронных сетей. I.J. Goodfellow, NIPS2016 Tutorial: Generative adversarial networks
Резюмируя, наиболее подходящими в этом случае будут порождающие модели (Generative Adversarial Networks), а именно модификация под названием порождающий автокодировщик (AAE — adversarial autoencoder).
Основная идея в том, что обычный автокодировщик может перевести скрытое представление (из значения и его признаков) в один из перечисленных типов, но это не помогает «порождению» новых типов, так как подходящие комбинации скрытых факторов взять неоткуда, а если порождать случайно, то разумных типов не получится. AAE как раз и решает последнюю проблему — мы добавляем дискриминатор, который пытается отличить распределение скрытых факторов кодировщика от какого-то заданного фиксированного распределения для каждого скрытого фактора, в нашем случае мы взяли стандартное нормальное распределение.
Таким образом, дискриминатор пытается отличить каждый «класс значений» от своего собственного распределения скрытых факторов, соответствующих тому или иному типу, и в результате распределяет разные классы значений, т.е. типы, в разные части пространства скрытых факторов. И там, где плотность значений в пространстве становится высока, определяет его как новый тип.
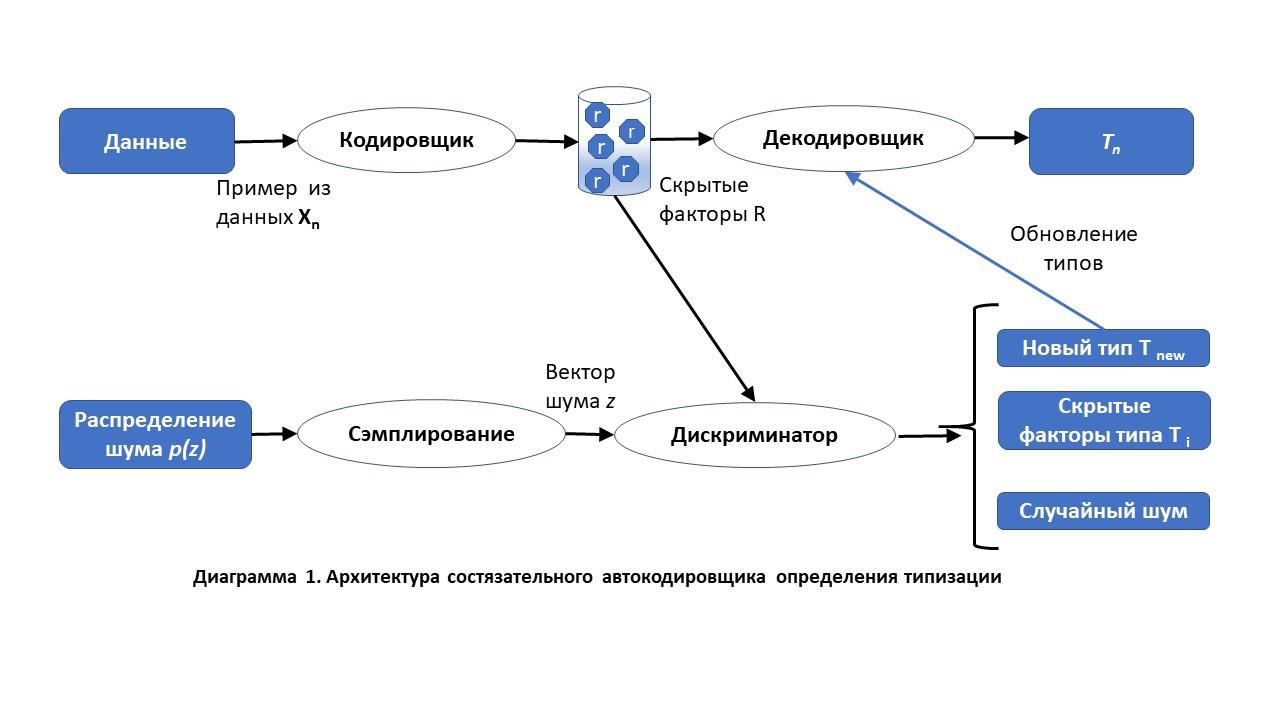
Для того, чтобы разобраться с функцией, которую мы будем оптимизировать, вместо сложных формул, воспользуемся функциями из TensorFlow (TF). Определим функцию оценки близости значения:
def discr_score (x) : // < weights, coef – параметры процесса обучения
h1 = TF.nn.tanh( TF.add( TF.matmul (x, weights[1]), coef[1]))
h2 = TF.nn.tanh( TF.add( TF.matmul (h1, weights[2]), coef[2]))
score = TF.nn.sigmoid( TF.add( TF.matmul(h2, weights[3]), coef[3]))
return score
data_score = discr_score(x_d) // < выборка из реальных данных x
gen_score = discr_score(z_d) // < выборка из сгенерированных значенийВ выходном слое дискриминатора мы используем сигмоидальную функцию активации, так как интерпретируем значения как вероятности того, что данные взяты из обучающей выборки, а не порождены генератором. И теперь функция стоимости для оптимизации задаются очень просто:
Discr_cost = - TF.reduce_mean( TF.log(data_score) + TF.log(1.0 – gen_score))Затем мы пользуемся оптимизацией методом градиентного спуска, к которой мы уже все подготовили:
Optimizer = TF.train.GradientDescentOptimizer(learning_rate)
D_optimizer = optimizer.minimize( Discr_cost, var_list = [weights, coef])Далее добавляем в дискриминатор пороговые значения для разграничения шума, определенного типа или же генерации нового типа. В принципе, можно не только варьировать пороговые значения, но и добавить механизм обучения для настраивания пороговых значений, но мы не будем усложнять приведенный алгоритм для простоты его понимания.
Архитектура задачи о семантике
Здесь логично будет использовать автокодировщик, который кодирует значения и признаки (encoder) в числовой вектор. Затем, используя декодировщик, разворачивает в текстовое описание, еще и снабдив семантику памятью для записи значений.
Для начала рассмотрим классический алгоритм Show, Attend and Tell — задача определения подписи к произвольным картинкам5. Это достаточно прямолинейная модель, состоящая из набора сверточных сетей с вниманием (для фокусировки внимания на отдельных фрагментах картины) и памятью.
Сноска 5
K. Xu et al, Show, Attend and Tell: A neural image caption generator with visual attention

Попробуем адаптировать эту архитектуру к нашей задаче, с учетом более современных элементов и нашей специфики. Во-первых, у нас анализируется не картинка, а набор последовательных значений Xn (так проще всего представить поток данных). Это само собой наталкивает на мысль, что нам не подходят сверточные слои из диаграммы выше, а достаточно простой рекуррентной сети (Recurrent Neural Network, RNN).
Более того, учитывая, что порядок не важен (хотя в случае примера с потоком данных и меняющейся со временем структуры метаданных он становится очень важным, но мы это рассмотрим позднее) нам достаточно однонаправленной RNN.
Во-вторых нам также нужна долгосрочная память, в которой будем хранить прочитанные значения. Причем, в отличии от классических задач машинного перевода или разбора текста, нам не важен порядок очередного значения. Для этих целей классическим использованием было бы LSTM, однако она требует много ресурсов, поэтому использование архитектуры ячеек памяти GRU или MUT1 выглядят более перспективными.
Мы пошли дальше и использовали более современную архитектуру памяти — SCRN, они лучше работают на больших объемах данных, их очень дешево тренировать по сравнению с LSTM. Возможно есть будущее и у новой модели SRU (Simple Recurrent Unit), но рассказ о тонкостях сравнения выходит за рамки этой.
И, в третьих, нам нужен механизм внимания, чтобы «фокусироваться» на нужных значениях и элементах. В отличие от задачи типизации, нам подходят и архитектуры с мягким вниманием, т.к. в отличии от значений справочников, описательная часть может быть более «мягкой», а не дискретной. И мы это сделаем отдельной простой сетью для того, чтобы отсекать ненужные значения при порождении описательной части семантики, т.е., по сути, удалять белый шум из потока значений атрибута.
Таким образом, на вход рекуррентной сети подается ожидание вектора прочитанных значений Xn после удаления шума и нетипичных значений, что мы упрощенно запишем как средневзвешенное значений — ∑ ai xi, где веса будут получены из отдельной сети внимания, аналогичной модели Show, Attend and Tell, с разницей, что используются входы из ячеек памяти SCRN.
Соединяя все три изменения, получаем такую архитектуру для решения задачи поиска семантики:

На этом рисунке представлена архитектура на шаге k. При этом, нужно учитывать, что на каждом шаге любой описательный элемент может быть изменен с учетом нового прочитанного значения. И еще мы не отразили на этой диаграмме тот факт, что параллельно мы также решаем задачу типизации и классифицируем значения к определенному типу, и что это также несет ценную информацию, которая является входом для декодировщика выше.
Объединение двух архитектур в единую вычислительную сеть
Можно заметить, что в предложенных архитектурах глубокого обучения для задач типизации и определения семантики много общего — можно использовать единые ячейки долгосрочной памяти, а также сохраняется основная рекуррентная сеть кодировщика и матрица признаков, на которую нанизываются механизмы фокусировки внимания и долгосрочной памяти, хотя есть и определенные дополнения. Поэтому вполне логично объединить их для оптимизации времени и вычислительных ресурсов при прохождении тренировочного корпуса данных.
Также, целесообразно использовать единый кодировщик и механизм определения скрытых факторов. Изначально кажется, что скрытые факторы для задач типизации и определения семантики разные. Однако, скрытые факторы на то и «скрытые», что обновляются, и самые неявные признаки могут в итоге служить этими факторами.
В архитектуре состязательного автокодировщика мы не использовали ячейки долгосрочной памяти. Однако, для работы дискриминатора в части определения нового типа они использовались неявно в качестве «накопителя статистики того или иного множества признаков». Учитывая, что у нас все равно есть ячейки памяти SCRN, то вполне логично использовать их для дискриминатора, и смотреть «подозрительные» значения для определения нового типа. Это хорошо иллюстрирует тип нового справочника, когда мы вынуждены накапливать значения.
А вот механизм «мягкого внимания» из задачи определения семантики нам в задаче типизации нигде не пригодится, поскольку он служит для поиска фокусных областей значений того или иного атрибута, что позволяет генерировать его описательную часть. Из примера выше (диаграмма 3) мы видим, что тип поля «Дата» легко определен по ряду признаков, а вот описательная часть складывается из значений этого и соседних полей.

Можно сказать, что с некоторыми оговорками это итоговый вариант архитектуры. Мы сознательно создали архитектуру вычислительной сети из относительно известных блоков (блоки внимания, долгосрочная память и т.д.), чтобы можно было воспользоваться известными наработками, доступными в библиотеках с открытым исходным кодом, таких как, TensorFlow, Keras и других. Важно общее понимание принципов составных частей предлагаемой модели.
Нашей задачей была итоговая крупноузловая архитектура глубокого обучения для решения этих популярных задач о типизации и семантике данных, поэтому много нюансов было пропущено для простоты восприятия материала, в то время как они заслуживают отдельного внимания — например, работа с выявлением зависимых полей, поиск признаков, автонастройка пороговых значений дискриминатора новых типов и пр, но для этого потребуется более серьезное погружение не только в данные, но и в теорию, и публикация получится более научной, нежели популярной.
Конечно же остается большое поле маневра для собственных вычислений и применения более современных механизмов, экспериментов с функциями инициализации и оптимизации. Но самое главное для новых задач управления данными — это то, что глубокое обучение может предложить новые подходы и автоматизировать работу стюардов данных (data stewards), аналитиков данных и других специалистов, чье время может быть потрачено на другие задачи.
Подготовил Сергей Кузнецов