
Всем привет!
Мы хотим рассказать немного об entity resolution как об академической дисциплине, о доступных инструментах для решения этой задачи, и о нашем опыте с одним из инструментов.

Смысл термина
Дедупликацией (deduplication) называется задача по поиску повторов в любых данных. В нашей статье мы будем рассматривать такой процесс только для структурированных данных — то есть для таблиц, хотя инструменты для дедупликации разрабатываются также и для слабоструктурированных моделей данных, таких как, например XML и JSON.
В нашем контексте "повторы" называются дубликатами (duplicates) – это структурированные записи, описывающие одну и ту же сущность (entity). Традиционно, data matching — это дедупликация одной таблицы, тогда как поиск дубликатов по нескольким таблицам называется связыванием записей (record linkage). Эта задача тесно связана с data matching'ом по очевидным причинам.
Такие дубликаты могут быть точными (exact) или неточными (fuzzy, inexact). Поскольку степень неточности на самом деле не ограничена, для поиска нечётких дубликатов, особенно в больших данных, требуются различные сложные алгоритмы и наборы инструментов. О том, какие методы могут применяться для этого, речь пойдет в следующей части.
Наконец, эти задачи объединяются под термином entity resolution (букв. разрешение сущностей, ER). На самом деле, все введённые термины более-менее взаимозаменяемы, но это устоявшееся формальное разделение.
![Картинка из [1], которая показывает, сколько терминов применяется в области для примерно одного и того же.](https://habrastorage.org/getpro/habr/upload_files/4c6/d1b/5eb/4c6d1b5eb9698c47a4861339b2da4b2e.png "Картинка из [1], которая показывает, сколько терминов применяется в области для примерно одного и того же.")
В основном, инструменты ER фокусируются на данных, принадлежащих к областям, полезным для бизнеса. Не было бы преувеличением сказать, что многие компании и организации пользуются табличными базами данных.
Такие базы данных либо изначально заполняются вручную, либо наполняются с помощью интеграции данных из различных внешних и внутренних источников. И зачастую данные в них страдают от различных проблем качества, таких как неполнота, неконсистентность (конфликты в данных), и наконец, ошибки и опечатки.
Всё это ведёт к потере прибыли (в среднем компания может потерять 12% выручки) и другим убыткам, например, репутационным (The cost of bad data: stats). Таким образом, entity resolution — это задача по улучшению качества данных (data quality) и, обобщая, задача интеграции данных (data integration).
Как и чем можно искать дубликаты?
Эта область в академическом сообществе существует очень давно (первые статьи по этой теме относятся к шестидесятым годам) и в настоящее время пользуется огромным вниманием, особенно в связи с расцветом классического машинного и глубокого обучения.
Существует значительное количество обзоров, например, [1-5], а также книга [6]: более старые из приведенных материалов содержат алгоритмы, которые до сих пор применяются в области и ставшие “классическими”. Также entity matching с использованием deep learning был посвящён keynote-доклад на конференции SIGMOD 2021 [7] — флагманской конференции сообщества баз данных.
Наконец, есть leaderboard на сайте paperswithcode, где соревнуются state-of-the-art (SOTA; в академическом сообществе обозначает наилучший результат) решения; стоит заметить, что там находятся только решения, основанные на глубоком обучении.
Система для entity resolution — это система, которая из набора сущностей составляет набор уникальных сущностей. С технической точки зрения, она обычно классифицирует пары записей как пары дубликатов (matches) или не-дубликатов (non-matches). Рассмотрим абстрактное устройство такой системы по материалам [1]:
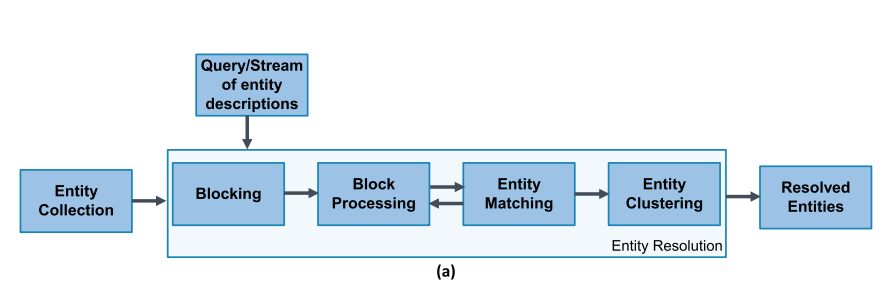
Indexing (Blocking) — шаг, главной задачей является быстрое отбрасывание как можно большего количества ненужных сравнений пар без потери дубликатов. На нём похожие записи помещаются в блоки на основании некоторого критерия так, чтобы на следующем этапе попарно сравнивать только записи, попавшие в один блок. На вход алгоритм, реализующий данный шаг, получает сам датасет, а на выходе — набор блоков.
Block Processing — шаг, на котором блоки дополнительно очищаются от шума. Набор блоков, полученный на предыдущем шаге, трансформируется в новый набор блоков с примерно таким же показателем recall, но с более высоким precision. Как вариант, можно перебрасывать записи между блоками.
Matching — шаг, который оценивает похожесть отобранных записей. Чаще всего это некоторая функция похожести, которая может быть основана, например, на редакционном расстоянии. Его выход — это взвешенный граф похожести, где узлы — это записи, а рёбра содержат оценку их похожести. При этом граф не связный: оценки похожести получаются только для пар, которые находятся в одном блоке.
Entity Clustering — шаг, который собирает похожие пары в кластеры; таким образом создаётся набор уникальных сущностей.
В основном как классические, так и SOTA-решения опираются на этот концепт. Обзоры, которые мы приводим выше, предлагают обширные списки алгоритмов для каждого шага. Авторами [1, 2] были выделены различные признаки для каждого шага, по которым можно классифицировать алгоритмы, его реализующие.
Одним из важных признаков является деление алгоритмов блокинга, матчинга и кластеризации на schema-aware и schema-agnostic. Первая группа работает только с теми атрибутами, которые указаны в конфигурации системы (например, экспертом по домену), и поэтому такие методы используются только для реляционных данных.
Вторая же группа рассматривает все существующие атрибуты, и поэтому может применяться для более слабоструктурированных данных, таких как XML-базы или базы знаний. Об остальных признаках, таких как, например, использование и не-использование обучения, о видах матчинга и т.п. можно подробнее прочитать в указанных статьях.
Говоря более подробно именно о глубоком обучении и нейросетях в данной области, стоит сказать, что методы, использующие их, не являются полноценными системами для ER. В обзоре [3] собран обширный список методов, актуальный на 2021 год. Они соотнесены с шагами entity resolution, изложенными выше.
Только два метода из 21 рассмотренных решают задачу блокинга, а все остальные нацелены на иные шаги. Одним из ярких отличий таких методов является специальная предобработка данных с получением эмбеддингов — т.е., векторных репрезентаций. Половина из рассмотренных методов её использует.
Если же говорить о архитектурах нейросетей,которые используются для матчинга, а не только для получения репрезентаций, то они делятся на две группы — RNN-подобные и Transformer-подобные. Мы уже приводили keynote-доклад [7], посвящённый глубокому обучению в области в целом и модели Ditto [8] в частности.
В данной системе используется дообучение (fine-tuning) BERT на задаче, сформулированной как классификация пары последовательностей. В этом месте можно отметить, что задача entity resolution, традиционно относившаяся к области баз данных, теперь начинает совмещаться с современными разработками в обработке естественного языка (NLP).
Поскольку нас интересовала не только научная, но и рабочая сторона вопроса, мы рассматривали инструменты, подпадающие под следующие критерии применимости:
Открытый исходный код
-
Наличие некоторой степени "завершённости":
Возможность без особых усилий запустить инструмент на современной машине (Win10 или любой современный дистрибутив Linux) — т.е., код поддерживался в работоспособном состоянии
End-to-end решение, т.е., выполняет полный процесс, а не только один из его шагов: в идеале для работы решения нужно иметь только сами данные и человека, который обучен работе с системой
Не основаны на глубоком обучении, т.к. получение обучающих данных нужного размера в индустриальном сценарии требует значительных дополнительных усилий и ресурсов
Наличие возможности работать с одной таблицей, т.е. именно с дедупликацией, а не только со связыванием
В таблице 1 приведён список инструментов, которые мы рассматривали:
Инструмент |
Лицензия |
Стек |
Комментарии |
AGPL-3.0 |
Java, Spark, Docker |
“Цельное” решение для дедупликации и связывания записей. О нём будет рассказано дальше. |
|
MIT |
Python |
Dedupe — библиотека, на основе которой можно разрабатывать инструменты, подобные Zingg. Соответственно, csvdedupe — простой пример CLI-инструмента, разработанного на основе Dedupe. Разработчики приводят примеры кода в документации, но пользоваться Dedupe просто так не получается, т.к. в памяти он может обработать менее 10K записей. В противном случае начинаются проблемы с производительностью. Предпочтительным способом работы с dedupe на больших данных является использование её поверх SQL СУБД. |
|
BSD-3-Clause |
Python |
Более низкоуровневый пакет, чем Dedupe. Предоставляет доступ непосредственно к алгоритмам — т.е., пайплайн поиска дубликатов разработчик определяет сам. В документации указано, что он предназначен для исследований на небольших объёмах данных. |
|
Apache-2.0 |
Java, Docker |
GUI-приложение. По словам разработчиков, предоставляет три подхода (workflow) к дедупликации. Внутри этих подходов на каждом шаге доступно большое количество вариантов алгоритмов для него. На деле удалось поработать только с одним, основанном на Similarity Join, и из него не удалось получить никакого адекватного результата. В дополнение к этому, приложение само по себе не очень адекватно — выдаёт необъяснимые ошибки, теряет результаты работы. Авторы не предоставляют примеры того, в каком именно формате должны быть CSV-данные для того, чтобы хотя бы запустить их алгоритмы на них. |
|
MIT |
Python, Spark |
Библиотека, похожая на RecordLinkage, но ещё более низкоуровневая - правила, по которым записи будут сравниваться, пишутся руками (т.е., правила вида "l.first_name = r.first_name"). Требует SQL-бэкенда. |
Исходя из наших потребностей, мы остановились на Zingg, как на решении, отвечающим большинству критериев из нашего запроса.
Что такое Zingg? Как им пользоваться?
Zingg — это решение для дедупликации, разработанное ZinggAI. Разработчики позиционируют его как индустриальный инструмент в ELT-пайплайне, чьё главное назначение — быстро и масштабируемо построить единый источник достверных данных для важнейших бизнес-объектов либо после Extraction, либо после Load для подготовки данных к анализу.
Zingg написан полностью на Java на основе Apache Spark; может устанавливаться как Docker-образ или разворачиваться на Spark-кластерах. Дополнительно есть обёртка для Python, которая позволяет пользоваться функциональностью Zingg как импортируемым модулем. Разработчики Zingg заявляют следующее:
Zingg может производить как связывание, так и дедупликацию
Справляется с любыми сущностями, такими как клиенты, пациенты, товары и т.д.
Работает с большим количеством видов источников данных и входных форматов файлов
Масштабируется на большие объёмы данных
-
Основан на машинном обучении и устроен согласно описанной выше модели:
Модель для блокинга в Zingg — это алгоритм, с помощью которого подбираются blocking functions, наиболее хорошо сохраняющие похожие записи в одном блоке. Здесь можно найти пример работы таких функций от разработчиков. Также Zingg позволяет определять и добавлять такие функции вручную в том случае, когда это требуется для домена знаний.
Для того, чтобы сравнить похожесть записей, Zingg вычисляет множество признаков для каждого поля, в основном связанные со сравнением строк (по длине, редакционному расстоянию и т.д.), получая вектор похожести (similarity vector) для каждой сравниваемой пары. После чего Zingg использует логистическую регрессию для того, чтобы оценить, является ли проверяемая пара записей дубликатами. Обычно в таких системах коэффициент 0.5 принимается за пороговое значение, но разработчики ZIngg заявляют, что они его оптимизируют под каждый датасет — т.е., теоретически оно может отличаться от 0.5.
Использует активное обучение и предлагает для него интерактивный интерфейс. Активное обучение — это такой вид машинного обучения, который проводит предварительный отбор небольшого количества неразмеченных данных из общей выборки и предлагает пользователю их разметить. Разработчики Zingg заявляют, что пользователю достаточно найти 30-40 пар настоящих дубликатов для того, чтобы на выходе получить адекватную модель.
Процесс установки Zingg соответствует заявленному: Docker-образ устанавливается без проблем в Ubuntu. Графического интерфейса у Zingg нет, но есть CLI. Процесс работы с Zingg выглядит следующим образом.
Сначала под входной набор данных нужно написать JSON-конфиг, описывающий формат входного файла, его схему, типы полей, вид матчинга для каждого поля, формат выходных данных, и наконец, указать два параметра labelDataSampleSize и numPartitions. Первый параметр — это тот процент записей, в которых будут искаться пары для разметки, и разработчики советуют использовать значения в диапазоне от 0.0001 до 0.1. Второй параметр — это количество партиций Spark, на которых будет параллелизовываться процесс. Здесь разработчики советуют использовать количество ядер, умноженное на число от 20 до 30. Пример конфиг-файла можно увидеть вот здесь.
Дальнейший процесс состоит из фаз, определённых в самом Zingg.
Первая фаза — это findTrainingData, запускающая алгоритм поиска пар записей, которые могут быть предложены для разметки пользователю. Эту и следующую фазы необходимо запускать несколько раз, поскольку, как сказано выше, для “адекватности” будущей модели требуется по крайней мере 30-40 положительных примеров дубликатов.
./scripts/zingg.sh --phase findTrainingData --conf path/to/conf.json
Следующая фаза — label, интерактивная разметка найденных на предыдущем шаге пар записей.
./scripts/zingg.sh --phase label --conf path/to/conf.json
Выглядит она следующим образом:

После нахождения достаточного количества настоящих дубликатов, можно запускать фазу train — собственно, обучение модели.
./scripts/zingg.sh --phase train --conf path/to/conf.json
Наконец, для дедупликации одного датасета нужно запустить фазу match, а для связывания записей в двух датасетах — фазу link.
./scripts/zingg.sh --phase match --conf path/to/conf.json
Примечание: для удобства пользователя первая и вторая, а также третья и четвёртая фаза могут быть объединены в пары, и запускаться командами findAndLabel и trainMatch соответственно.

Тем записям, которые Zingg распознал как дубликаты, присваивается один и тот же номер в колонке z_cluster. Колонки z_minScore и z_maxScore содержат минимальную и максимальную оценку похожести данной записи на записи в этом же кластере.
Тестирование и бенчмарк Zingg
В сообществе ER широко доступны датасеты для бенчмаркинга. Подборка Benchmark datasets for entity resolution | Database Group Leipzig содержит самые известные из них, но есть также и другие, например, WDC Product Data Corpus или Magellan Data Repository.
Поскольку задача entity resolution может быть рассмотрена как задача бинарной классификации, то оцениваются решения для дедупликации чаще всего с помощью Precision, Recall, и F1, хотя существуют и более необычные, о которых можно прочитать, например, в статьях [10, 12].
Оценка производительности обычно производится замером времени “по часам” (wall-clock running time). В нашем случае мы не проводили точных замеров времени, но ручной поиск 30-40 пар требуемых дубликатов с интерактивной разметкой в каждом случае занимал около получаса, а сам процесс обучения модели на размеченных данных (т.е. работа фазы train) занимал не более 10 минут.
Разработчики Zingg предоставляют несколько моделей, пред-обученных на известных бенчмарк-датасетах, но не оценивают их результаты. Поэтому мы решили проводить процесс обучения моделей с нуля. Для бенчмарка Zingg мы выбрали платформу Frost (Snowman) [10], как наиболее современную и доступную. Существуют также и другие платформы, такие как FEVER [11] и EMBench++ но они были разработаны в конце нулевых, и на сегодняшний день не поддерживаются.
Все датасеты, кроме первого, доступны публично: помеченные двумя звёздочками принадлежат группе Database Group Leipzig, а остальные доступны на самой платформе Snowman.
Мы проводили бенчмарк в следующих условиях:
Zingg 0.3.4, Docker Engine v20.10.8
Ubuntu 20.04 для WSL2
Windows 10 Pro, 21H1, сборка 19043.1645
Intel(R) Core(TM) i7-10510U CPU
16GB RAM (12GB выделено под виртуализацию WSL2)
Формат входного и выходного файлов - CSV
Параметр numPartitions был установлен равным 1, параметр labelDataSampleSize указан в таблице
Таблица 2: Результаты нашего бенчмарка
*При переносе на Хабр таблица оказалась не очень читаемой. Просим прощения, уперлись в ограничения верстки
Датасет |
Домен |
Поля |
Кол-во записей |
Кол-во размеченных пар |
labelDataSampleSize |
Prec |
Rec |
F1 |
Acc |
Имена собственные с опечатками* |
Физические лица |
first, last, patro |
1000 |
64 |
0.5 |
1.0 |
0.77 |
0.87 |
1.00 |
Magellan Songs 1M |
Песни |
artist_familiarity,artist_hotness,artist_name,duration,id,release,title,year |
1000000 |
180 |
0.005 |
0.4 |
0.97 |
0.57 |
1.00 |
Geographical Settlements** |
Поселения: координаты и названия |
lat,ontology,lon,label,id,type,ele,typeDetail |
3054 |
156 |
0.5 |
0.43 |
0.7 |
0.53 |
0.99 |
AltoSight |
Товары: Флешки |
brand,instance_id,name,price,size |
835 |
113 |
0.5 |
0.38 |
0.78 |
0.51 |
0.98 |
FreeDB CDs (очищенный от записей со сбоем кодировки) |
Описания дисков с музыкой |
artist,category,genre,id,title,tracks,year |
7527 |
107 |
0.5 |
0.16 |
0.78 |
0.26 |
1.00 |
SIGMOD Notebook Large |
Товары: Ноутбуки |
brand,cpu_brand,cpu_frequency,cpu_model,cpu_type,dimensions,hdd_capacity,instance_id,ram_capacity,ram_frequency,ram_type,ssd_capacity,title,weight |
337 |
142 |
0.5 |
0.31 |
0.31 |
0.31 |
0.96 |
Affiliations** |
Названия научных учреждений |
id,affil |
2260 |
121 |
0.5 |
0.38 |
0.22 |
0.28 |
0.99 |
*Данные, которые мы сгенерировали для этого датасета, были очень примитивными, и выглядели примерно так:

Как можно легко увидеть из таблицы, практически все эксперименты показывают довольно высокий recall и низкий precision; это означает, что Zingg выдаёт большое количество ложноположительных ответов, но достаточно низкое ложноотрицательных — т.е., находит большой процент настоящих дубликатов, но его выдача засорена ненастоящими. Для нашего гипотетического индустриального сценария данный результат является вполне удовлетворительным.
Низкие показатели в эксперименте Affiliations и Notebook Large связаны с тем, что Zingg не использует технологии, которые могут оперировать со “смыслом” данных (например, эмбеддинги), а использует только метрики похожести строк. Например, первая пара из датасета Affiliations — это ложноположительный ответ Zingg, а вторая — ложноотрицательный, хотя редакционное расстояние меньше между записями первой пары.


Такая же примерно ситуация произошла и с датасетом Notebook Large, поскольку он содержит объявления о продаже товаров, автоматически собранные с Amazon и подобных сайтов.
Колонка Accuracy в таблицу включена, поскольку авторы Zingg, несмотря на то, что предлагают несколько предобученных моделей на бенчмарк-датасетах, не указывают результаты, ими полученные.
Единственная метрика, о которой на данный момент они говорят — это Accuracy, но, как видно из таблицы, и как интуитивно понятно по постановке задачи, эта метрика при более-менее любых результатах должна быть близка к единице, так как дубликатов не может быть много относительно общего числа записей. Стоит отметить, что у разработчиков в планах есть добавление подсчёта Precision, Recall и F1, но пока эта функциональность не была реализована даже экспериментально.
Как можно заключить из представленных экспериментов, Zingg — вполне подходящее решение для достаточно простых случаев. Тогда как для более сложных сценариев (например, автоматически собранные данные из различных источников, а не введённые вручную данные физических лиц) может потребоваться использование более наукоёмких решений. Большим преимуществом Zingg является “бесшовная” поддержка большого количества форматов данных и удобство использования, что в индустриальном сценарии может стать ключевым фактором.
Литература
Christophides, V., Efthymiou, V., Palpanas, T., Papadakis, G., & Stefanidis, K. (2020). An overview of end-to-end entity resolution for big data. ACM Computing Surveys (CSUR), 53(6), 1-42.
Papadakis, G., Skoutas, D., Thanos, E., & Palpanas, T. (2020). Blocking and filtering techniques for entity resolution: A survey. ACM Computing Surveys (CSUR), 53(2), 1-42.
Barlaug, N., & Gulla, J. A. (2021). Neural networks for entity matching: A survey. ACM Transactions on Knowledge Discovery from Data (TKDD), 15(3), 1-37.
Elmagarmid, A. K., Ipeirotis, P. G., & Verykios, V. S. (2006). Duplicate record detection: A survey. IEEE Transactions on knowledge and data engineering, 19(1), 1-16.
Brizan, D. G., & Tansel, A. U. (2006). A. survey of entity resolution and record linkage methodologies. Communications of the IIMA, 6(3), 5.
Peter Christen. 2012. Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer Science & Business Media.
Tan, W. C. (2021, June). Deep Data Integration. In SIGMOD Conference (p. 2).
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, Jin Wang, Wataru Hirota, and Wang-Chiew Tan. 2021. Deep Entity Matching: Challenges and Opportunities. J. Data and Information Quality 13, 1, Article 1 (March 2021), 17 pages. https://doi.org/10.1145/3431816
Köpcke, H., Thor, A., & Rahm, E. (2010). Evaluation of entity resolution approaches on real-world match problems. Proceedings of the VLDB Endowment, 3(1-2), 484-493.
Graf, M., Laskowski, L., Papsdorf, F., Sold, F., Gremmelspacher, R., Naumann, F., & Panse, F. (2022). Frost: a platform for benchmarking and exploring data matching results. Proceedings of the VLDB Endowment, 15(12), 3292-3305
Köpcke, H., Thor, A., & Rahm, E. (2009). Comparative evaluation of entity resolution approaches with fever. Proceedings of the VLDB Endowment, 2(2), 1574-1577.
Panse, F., & Naumann, F. (2021, April). Evaluation of duplicate detection algorithms: from quality measures to test data generation. In 2021 IEEE 37th International Conference On Data Engineering (ICDE) (pp. 2373-2376). IEEE.
Статью подготовили: Анна Смирнова и Георгий Чернышев