

Всем привет. В этой статье хотим представить инструмент для профилирования данных. Расскажем об особенностях инструмента, о профилировании данных, и кому это будет полезно. И, конечно, его уже можно опробовать: ссылка будет в тексте статьи.
Введение
Профилирование данных (data profiling) [1] – это процесс извлечения метаданных из данных. Это частая задача у людей, работающих с данными, а цели извлечения могут быть самыми разными.
Что такое метаданные? В первом приближении это данные о данных: размер файла, время создания, авторство. Но на самом деле это понятие шире, и включает в себя различные закономерности, сокрытые в данных. Именно о последнем типе метаданных и будет весь наш дальнейший разговор. Еще одна оговорка: в статье мы будем рассматривать только табличные данные.
Закономерности, которые могут присутствовать в данных, описываются с помощью различных примитивов. Сам по себе примитив – это некоторое описание правила, действующего над данными (или их частью), описанное математическими методами. В качестве примера можно вспомнить функциональную зависимость. Ее идею можно описать следующим образом: говорят, что зависимость A->B (A и B – колонки в таблице) удерживается, если для каждой пары строк верно, что из совпадения значений по А, следует совпадение значений по В.
Типов примитивов существует несколько сотен, у каждого есть достаточно проработанная теория и свойства. При этом, новые постоянно добавляются.
Закономерности могут быть найдены автоматически, с помощью специализированных алгоритмов, для каждого примитива они свои. При этом, выявленные закономерности могут быть ценны для довольно широкого круга людей. Вот несколько примеров:
Ученые – биоинформатики, химики, геологи, да на самом деле практически любые ученые, работающие с массивами данных, особенно полученными экспериментальным путем.
Люди, работающие с финансовыми данными – финансовые аналитики, продажники, трейдеры. Они также имеют под рукой много данных, которые можно поизучать.
Дата сайентисты, аналитики, специалисты по машинному обучению.
Для ученых, обладающих массивами данных, успешное нахождение примитива указывает на некоторую закономерность. На ее основании можно сформулировать гипотезу или даже сразу делать выводы (если данных достаточно). Но, как минимум, найденная закономерность может дать направление дальнейшего изучения.
В случае финансовых данных также можно попробовать получить какую-нибудь гипотезу (например, “предлагаемые конкурентами машины красного цвета едут быстрее любой другой”). Однако, тут есть более приземленные и более востребованные применения: очистить базу от ошибок, найти и удалить неточные дубликаты, и многое другое. Заметим, что ученым этот функционал тоже был бы интересен, хоть и в гораздо меньшей степени.
Теперь про машинное обучение. Найденные примитивы могут помочь при проведении feature engineering и выборе направления для ablation study. Допустим, необходимо обучить алгоритм для решения какой-либо задачи, при этом датасет (таблица) есть. Тут же встает вопрос – какие колонки использовать в качестве признаков для обучения, а какие нет. Ответ “все, что есть в датасете” – плохой, потому что, во-первых, некоторые колонки могут быть производными (или зависимыми) от других и поэтому их добавление ничего не даст в смысле производительности, а только увеличит размер модели и время обучения. Во-вторых, такое добавление может спровоцировать переобучение, что негативно скажется на качестве решения. Знание закономерности позволит некоторые признаки отбросить сразу же, а для оставшихся выбрать порядок, в котором их будут пробовать добавлять в модель.
Наконец, есть куча других более нишевых применений, таких как: оптимизация в базах данных, реверс-инжиниринг базы данных, интеграция данных. О них можно вкратце почитать тут [1].
Приведем небольшой пример, чтобы показать, о чем это всё. В таблице ниже описаны предлагаемые некоторой компанией товары, пять разных вещей. Для каждой приведен ее заводской серийный номер и цена продажи.

В таблице видно, что первая, третья и четвертая запись касаются одного и того же товара. Однако в четвертой записи вероятно закралась ошибка – возможно, оператор вводивший данные, не допечатал девятку. Это можно было было бы обнаружить с использованием примитивов, о которых было написано выше, причем несколькими способами. Например, можно было бы поискать приближенные функциональные зависимости с маленьким пороговым значением и найти Serial -> Price. Или можно было бы даже обнаружить точную функциональную зависимость, загрузив только верхнюю половину датасета. Конечно, такую простую ошибку можно было бы найти и по-другому, не используя примитивы, но пример посложнее уже так легко и дешево не обработать простыми методами.
Научное сообщество баз данных обладает колоссальным объемом примитивов, описывающих множество различных паттернов, которые могут присутствовать в данных. Однако они по большому счету неизвестны людям, и в худшем случае просто остаются теоретическим результатом, а в лучшем – существуют в виде малоизвестного прототипа. Мы хотим “открыть” эти примитивы для широкой публики и дать каждому возможность изучать свои данные.
В этой статье мы представляем бета-версию платформы Desbordante (исп., безграничный). Ознакомиться можно по ссылке. Это профайлер данных, который позволяет проводить поиск различных примитивов в таблицах. Платформа открытая, можно знакомиться с проектом на Github.
Дисклеймер. Это бета-версия, и ресурс под неё ограничен. Сервис может подвисать или падать. Но мы следим за ним. Также возможны различные ошибки и шероховатости. Будем рады фидбеку, постараемся быстро поправить.
Исходно мы вдохновлялись проектом Metanome [2] (сейчас он скорее заброшен), но при этом у нас есть своё, иное видение этой области. Metanome – это скорее исследовательский прототип, в то время как Desbordante ориентирован на конечного пользователя, и находится гораздо ближе к продукту. Кроме того, Desbordante производительнее, имеет удобный пользовательский интерфейс, а также предлагает возможности, отсутствующие в Metanome.
Об инструменте

Desbordante создавался несколько лет, в том числе при участии Юнидата Labs. Возможности Desbordante будут увеличиваться со временем, особенно, если будет интерес к инструменту.
Desbordante может выполнять две категории задач:
Поиск различных примитивов.
Выполнение какой-либо работы с использованием алгоритмов поиска примитивов.
Сейчас в первой категории поддерживаются три примитива:
1) Функциональные зависимости (включая приближенные) [2]. Изначально Desbordante ориентировался исключительно на этот класс примитивов. Он может быть полезен для довольно большого класса задач, такого как поиск опечаток, выявления связанных колонок, и многого другого. При этом, точные зависимости довольно сильно ограничены из-за строгости своего определения. Сущности реального мира слишком вариативны, “грязны”, если можно так сказать. Решением могут служить приближенные зависимости, где допускается определенная доля ошибок.
2) Ассоциативные правила [3]. Этот примитив применяется к транзакционным наборам данных – наборам, похожим на базу данных чеков из супермаркета. Ищутся правила вида "если в чеке есть продукт А, то с некоторой вероятностью там окажется и продукт B". Примитив имеет два основных параметра: support показывает, в каком количестве чеков из всей базы данных найденное правило выполняется, а confidence – условную вероятность того, что при наличии в чеке продукта A там же будет присутствовать и B. Такая концепция "чеков из супермаркета" – наиболее известное и наглядное применение ассоциативным правилам. Однако этот примитив может быть обобщен на самые разные области: например, такие правила можно использовать в анализе логов веб-сервисов, построении рекомендаций в онлайн-магазинах и множестве других задач. Самое неожиданное применение, с которым я сталкивался, было в биоинформатике.
3) Условные функциональные зависимости (включая приближенные) [4]. Эти зависимости являются обобщением функциональных зависимостей и ассоциативных правил. Они более гибкие, поскольку могут содержать зависимости, которые выполняются только на подмножестве данных. Этот примитив нацелен на обеспечение согласованности данных за счёт поддержки шаблонов семантически связанных значений. Поиск таких зависимостей – это значительно более дорогостоящий процесс в сравнении с поиском функциональных зависимостей. Для того, чтобы отбросить зависимости, которые выполняются на небольшом подмножестве отношения, необходимо использовать параметр support, а для поиска приближенных зависимостей – confidence.
Каждый из описанных примитивов можно искать некоторым набором параметризуемых алгоритмов. Например, для ассоциативных правил можно задавать confidence и support. Выдача представлена в удобной форме, можно посмотреть на результат и на исходные данные. Есть фильтрация и сортировка данных.

В этой статье мы не будем подробно останавливаться на примитивах. Описание с формальным определением можно найти по ссылкам выше, также мы будем разбирать примитивы в следующих статьях. Кроме того, в самом инструменте для каждого примитива есть несколько встроенных датасетов (с фиксированными параметрами) на которых можно разобраться.

Перейдем ко второй категории задач. Это некоторые сценарии, которые основываются на доступных примитивах, и обычно являются композицией из нескольких алгоритмов. Их цель – решать конкретную задачу. Сейчас в Desbordante доступен только один такой сценарий – поиск опечаток с помощью комбинирования поиска точных и приближенных функциональных зависимостей. Можно сказать, что такие сценарии – это “ноу-хау” Desbordante, в том смысле, что в Metanome подобного рода функциональности не было.
Обе категории задач требуют от пользователя усилий, экспериментирования и, если так можно сказать, эксплорации данных. Требуется подбирать параметры, отрезать или добавлять строки, колонки, модифицировать данные. Потом загружать и запускать алгоритмы заново. Причем для одного и того же примитива имеет смысл пробовать различные алгоритмы, у каждого из них свои сильные и слабые стороны, их производительность зависит от датасета.
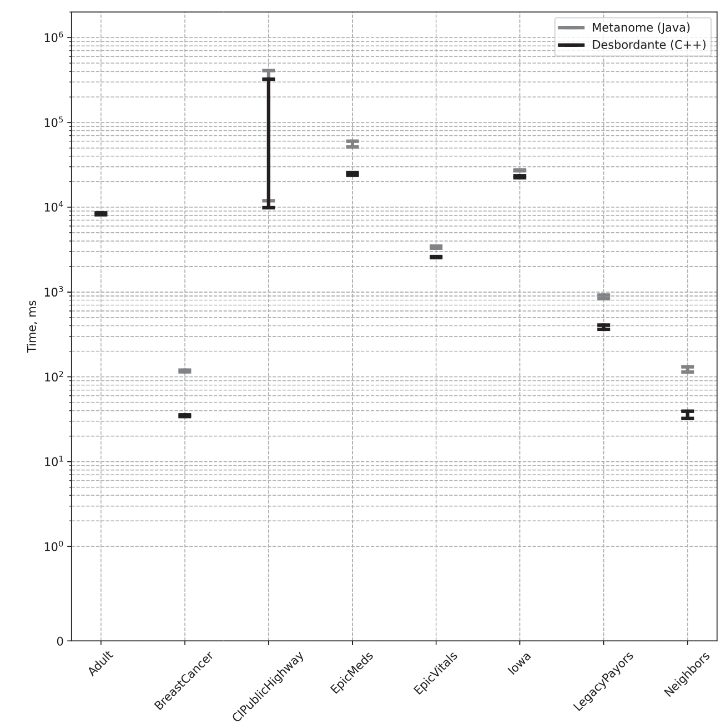
Поиск любых нетривиальных примитивов – вычислительно очень дорогостоящая операция. Внизу приведена таблица, где можно увидеть производительность системы Metanome на задаче поиска функциональных зависимостей (различные датасеты для 8 алгоритмов). При этом размеры датасетов достаточно скромны.

Эти эксперименты были выполнены на двухпроцессорном сервере c Xeon E5 и 128 ГБ оперативной памяти. Кроме того, из таблицы видно, что памяти может и не хватить.
В Desbordante мы добавили несколько ограничений, чтобы избежать подобных проблем. Для пользователей выставлены ограничения на память и на время работы. Кроме того, для незарегистрированных пользователей недоступна функция загрузки своих датасетов, а доступны только встроенные, для демонстрации функционала.
Позиционирование и конкуренты
Существует достаточно небольшое количество систем-профайлеров данных. Их можно поделить на две группы:
-
Enterprise системы от крупных вендоров. Это системы от таких игроков как Microsoft, SAP, Informatica, Talend, SAS, Tableau и прочих. У них есть следующие недостатки:
a) Они обычно нацелены на решение конкретной прикладной бизнес-задачи Data Quality, причем зачастую довольно простой и не наукоемкой. Например, проверить, что в поле телефон действительно находится номер телефона, проверить, что значения в колонке лежат внутри допустимого диапазона, заполнить пропущенные значения простым способом (например, скопировав с соседней строки) и тому подобное.
б) Они сильно привязаны к экосистеме вендора и требуют установки других продуктов. То есть, вот просто так, по-быстрому, нельзя попробовать поработать с данными.
в) В части поиска примитивов они предоставляют очень ограниченный набор функциональности. Например, для поиска функциональных зависимостей редкий продукт дает возможность искать зависимости большие чем один к одному. А большинство вообще может только проверять наличие указанной зависимости. Касательно же других, менее известных, примитивов ситуация еще хуже – они попросту не поддерживаются.
г) Наконец, они платные и могут стоить чрезвычайно дорого, в частности из-за пункта а).
-
Исследовательские системы. Это системы, или даже не системы, а прототипы, которые писали ученые для каких-то своих целей. Они, в свою очередь, обладают всеми недостатками исследовательских систем:
a) Они не высокопроизводительны и довольно часто написаны на Java/Python. Ведь их цель – просто показать работоспособность идеи или же сравнить несколько методов. Кроме того, код любых исследовательских систем редко поддерживается после публикации статьи и потому довольно быстро “протухает”. И наша предметная область – не исключение.
б) Реализации труднодоступны. В худшем случае реализация может отсутствовать, ведь часть примитивов или алгоритмов для их поиска была придумана в “догитхабное” время. А сайты ученых живут недолго, поэтому реализации могли просто потеряться. В лучшем же случае, реализации обычно разбросаны по различным местам в интернете, написаны на разных языках программирования под разные операционные системы и так далее. То есть, единого инструмента не существует.
в) Они не имеют user-friendly интерфейса и зачастую требуют “вникать” в код, для того чтобы просто собрать, запустить и попробовать. Например, около трети нашей команды испытывали затруднения при сборке Metanome.
Таким образом, Desbordante – это уникальный в своем роде проект, который позволяет сразу попробовать несколько различных примитивов на датасете.
О реализации
Ядро Desbordante — консольное приложение, обладающее крайне простым сценарием использования: на вход подаётся csv-таблица, указывается искомый примитив, например, функциональная зависимость, алгоритм и, опционально, параметры, а на выход выдаётся набор найденных зависимостей.
Со временем консольное приложение было расширено несколькими компонентами. На данный момент Desbordante можно использовать как веб-сервис, то есть серверная часть, выполняющая вычислительно сложную работу, уже развёрнута на удалённой машине, а клиент, предоставляющий графический интерфейс, доступен из любого браузера. Таким образом, весь цикл работы: выбор датасета и примитивов, подбор параметров и анализ результатов с помощью инструментов по фильтрации и визуализации — доступен сразу.
Кроме того, все компоненты Desbordante контейнеризованы, что позволяет легко разворачивать сервис практически на любой машине, а также даёт возможность управлять доступными ресурсами машины, ограничивая время исполнения алгоритма и занимаемый объем памяти.
Последний пункт критически важен для предотвращения ситуации, когда обработка датасета, а, значит, и запроса одного пользователя, займёт все ресурсы машины на долгое время, что заблокирует работу других пользователей. Это может легко произойти в контексте такой трудоёмкой задачи, как поиск закономерностей в данных.
В отличие от Metanome, сами алгоритмы по поиску примитивов реализованы на C++, что в некоторых случаях позволяет добиться десятикратного ускорения и двукратной экономии памяти [5]. Поэтому в настоящий момент Desbordante является одним из наиболее высокопроизводительных open-source профайлеров в мире.
О проекте
Проект начался летом 2019 и изначально был исследовательским, основным вопросом которого которого был “а насколько реимплементация на C++ позволит поднять производительность по сравнению с реализацией на Java”. Мы вдохновлялись (и сравнивались с системой Metanome [2], сделанной исследовательской группой Hasso-Plattner Institut (образовательно-исследовательская организация, связанная с SAP). Причем фокус у нас был исключительно на функциональных зависимостях. Время шло, росла команда, росло и наше понимание предмета, у нас скопился пул алгоритмов, появился веб-клиент. И в какой-то момент мы поняли, что можем сделать востребованный инструмент, который “откроет” все эти примитивы людям и будет приносить пользу. Этого видения мы и придерживаемся в настоящий момент.
Сам проект - это open-source, и мы всегда готовы к сотрудничеству, включая стажировку в компании. Если это интересно - свяжитесь с нами.
Для нас актуальны фронты, бекэндеры, и плюсисты (особенно, если способны разбирать научную литературу).
По всем вопросам можно связаться с нами через наш сайт.
Проект ведут: Георгий Чернышев, Максим Струтовский и Никита Бобров. Команда в настоящий момент насчитывает более десяти человек.
Что дальше
На подходе (уже реализованы, но не выведены на фронт) еще несколько примитивов. На них мы останавливаться не собираемся, и в дальнейшем планируется расширять список доступных примитивов, причем мы собираемся захватить и другие типы данных. Например, реализовать поиск зависимостей на графах.
Так как нельзя предсказать, какие примитивы “выстрелят”, мы будем экспериментировать с ними.
Наконец, в будущих версиях планируем сделать еще кучу quality of life функций, например, интерактивные таблицы, удобную выгрузку данных, или возможность дать пользователю строить сложные workflow из разных алгоритмов.
Будем конечно же учитывать фидбек от пользователей, смотреть какие примитивы пользуются популярностью и учитывать это в развитии проекта. Если будет интерес со стороны пользователей – можем подумать и над коммерческими планами, где не будет лимитов по памяти/времени или будут другие “плюшки”.
Ссылки
[1] Ziawasch Abedjan, Lukasz Golab, and Felix Naumann. 2015. Profiling relational data: a survey. The VLDB Journal 24, 4 (August 2015), 557–581. https://doi.org/10.1007/s00778-015-0389-y
[2] Thorsten Papenbrock, Jens Ehrlich, Jannik Marten, Tommy Neubert, Jan-Peer Rudolph, Martin Schönberg, Jakob Zwiener, and Felix Naumann. 2015. Functional dependency discovery: an experimental evaluation of seven algorithms. Proc. VLDB Endow. 8, 10 (June 2015), 1082–1093. https://doi.org/10.14778/2794367.2794377
[3] Charu C. Aggarwal. 2015. Data Mining: The Textbook. ISBN 3319141414. Springer Publishing Company, Incorporated.
[4] W. Fan, F. Geerts, L. V. S. Lakshmanan and M. Xiong, "Discovering Conditional Functional Dependencies," 2009 IEEE 25th International Conference on Data Engineering, 2009, pp. 1231-1234, doi: 10.1109/ICDE.2009.208.
[5] M. Strutovskiy, N. Bobrov, K. Smirnov and G. Chernishev, "Desbordante: a Framework for Exploring Limits of Dependency Discovery Algorithms," 2021 29th Conference of Open Innovations Association (FRUCT), 2021, pp. 344-354, doi: 10.23919/FRUCT52173.2021.9435469. https://fruct.org/publications/fruct29/files/Strut.pdf
Подготовили: Георгий Чернышев, Максим Струтовский, Никита Бобров, Антон Чижов, Александр Смирнов, Михаил Полынцов