
Года 4 назад я морально, а затем и фактически дорос до уровня тимлида. Взгляды стали шире и выше текущих процессов. В голову стали приходить разные мысли о мотивации, оптимизации, автоматизации и прочих -циях. В этой статье я хотел бы поделиться опытом из разряда технических компетенций тимлида: как автоматизировать ежедневные процессы (например, автоматическая сборка продукта, выкладывание, документирование, управление правами т.д. и т.п.).
После третьей страницы текста моей статьи, я решил разделить ее на 2 блока:
- Настройка ПО, сопровождающего процесс разработки.
- Описание Workflow.
Итак. Настройка ПО, сопровождающего процесс разработки
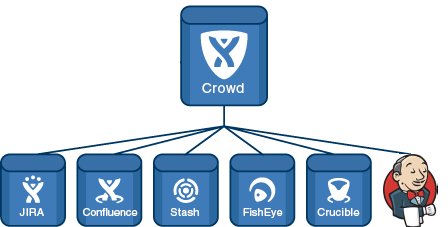
Crowd и Jira
Первым был Crowd — менеджер учетных записей. Я скрестил и синхронизировал его с Jira. Crowd втянул в себя все группы и всех пользователей Jira. В Jira работу с директорией Crowd я сделал read/write (поскольку нового пользователя добавлять через Jira удобнее чем через Crowd).
В Jira всех пользователей разбил на группы:
- jira-users.
Обязательная группа для всех пользователей. - jira-developers
Группа для программистов, тестировщиков, аналитиков, техписов. В общем для тех, кто непосредственно участвует в разработке. - project1-users
Все, кто имеет отношение к проекту project1. Заказчик, руководство (для наблюдения за процессом), вся команда проекта. - project1-developers.
Только разработчики этого проекта.
В каждом проекте Jira позволяет настроить 3 роли. В роль USERS я занёс группу project1-users, в роль DEVELOPERS занёс project1-developers, а в роль ADMINISTRATORS занёс PM (менеджера проекта).
Если вкратце, то юзеры в группе могут только создавать задачки и наблюдать за ними, девелоперы могут их редактировать и решать, а админы управляют версиями, компонентами, могут удалять или редактировать чужие комментарии или задачи.
Confluence
Я считаю этот продукт самым удачным среди всевозможных баз знаний. После прочтения большого количества статей и сравнения разных систем, я пришел к выводу, что Confluence среди них бесспорный лидер.
В нем я создал разные Пространства:
- Орг вопросы.
Общие сведения по работе предприятия (параметры FTP хранилища, Wi-Fi, правила оплаты овертаймов, учета отпускных, контакты сотрудников, обсуждения корпоративов, инструкция по подключению принтера и т.д. и т.п.) - Разработка и администрирование.
Техническая информация в помощь группе разработки (правила оформления кода, его выкладывания, комментирования, всякие нюансы в администрировании серверов, использовании витиеватых конструкций языков программирования). Весь опыт того, на что натыкались, долго бодались и побеждали. - Пространства для каждого проекта.
Всё то, что в предыдущей группе только касаемо данного проекта (нюансы костылей, полезные sql запросы), юзерстори, постановки, входящие данные (дизайны, логотипы, иконки, параметры доступов), исходящие данные (ридми, инструкции, релиз ноутс), планы тестирования, описание механизмов, модулей, и т.д. и т.п.
Самое главное и приятное, что Confluence любую свою статью умеет красиво экспортировать автономные HTML страницы.
Весь хелп у нас хранится в Confluence в виде иерархической структуры статей. В конце версии одним кликом получается пачка HTML файлов, которые ссылаются друг на друга. Все это удовольствие мы просто копируем в проект и выпускаем. И потому справка у нас постраничная (а не все в одном огромном файле), легко поддерживаемая и всегда онлайн доступна для всей команды (а не где-то у кого-то в какой-то папке).
Каждый проект Jira и пространство Confluence связаны. В статье с постановкой есть ссылка на задачу и наоборот.
Bitbucket
Для хранения исходников мы исторически использовали SVN. Влияние новых технологий не прошло мимо, и конечно же выбор пал на git (бест практик как никак).
Поскольку я программист, а не сисадмин, установку чистого гита я не осилил. Потому взял готовый пакет GitBlit… но вскоре в нём разочаровался. В результате все перевёл на GitLab.
Год работы и 12 одновременно действующих проектов дали о себе знать. Сервер стал прогибаться под тяжестью руби. К тому же сказалась очень слабая совместимость с Atlassian продуктами.
В то время я заметил Stash. В чистом виде под линукс я, к сожалению, его не нашёл, за то поставил его в составе Bitbucket. И понеслась!
Создал проекты и по репозиторию в каждом. Дал полные права каждому ПМ-у на свой проект (теперь он сам может создавать репозитории в своём проекте сколько хочет). В репозитории на мастер ветку выдал права только лиду и по умолчанию выставил ветку dev.
Скрестил Bitbucket с Jira и теперь в каждой задаче есть список всех комитов по задаче. А из комитов можно переходить на задачки.
Fisheye and Crucible
Где-то я читал, что Crucible можно встроить в Stash. Но поизучав детально уже настроенный Bitbucket, я ничего подобного не нашёл. А так как CodeReview — обязательный этап в нашем Workflow, то пришлось ставить и Fisheye. Реально очень удобная штука, но имея Bitbucket, можно было обойтись и без неё.
Когда у нас стоял GitLab, добавлять репозитории в Fisheye было реально морочно… Куча настроек, генерация ключей, левые юзеры… С Bitbucket все пошло как по маслу. Скрестил Fisheye и Bitbucket и в Fisheye появился список всех репозиториев с кнопочкой “add”.
Создал проекты, указал в них группы разработки те, что в Jira для этих проектов, указал репозиторий и скрестил каждый со своим проектом в Jira. А в Jira наоборот указал в каждом проекте линки на Fisheye и Crucible и путь к репозиторию.
Теперь в каждой задаче есть комиты по задаче не только из Bitbucket, но и из Fisheye. Безтолково, конечно….но ничего страшного. Зато в каждой задаче теперь можно сразу увидеть Review и его статус!
Jenkins
Вот вроде бы и все, но нет! Надо же это все хозяйство как то автоматизированно собирать. Очень долго хотел прикрутить Bamboo, но он выглядит ущербно по сравнению с Jenkins. В Jenkins мне удавалось настроить автосборку всего еще и с перламутровыми пуговицами. В Bamboo все не так. Сообщество слабое, плагинов мало, можно рулить только выполнением консольных команд. Перечислять недостатки не буду. В начале настраивал под сборку Delphi-проектов, но потом перешли на веб и сборки стали простыми — вытащил, залил на ftp, отметил в Jira и письма разослал. Подумаю, может и на Bamboo перейдем.
Значит скрещивать Jenkins ни с кем не стал. Вроде как нужды нет. Никому не интересно в задаче сколько раз она собиралась. Единственное что — это в самом Jenkins поставил Jira plugin, чтобы при сборке задачи автоматически перемещались на другой шаг WorkFlow.
И важно все вышеперечисленные продукты обязательно настроить на Crowd. Единые учетки во всех этих системах — это реально удобно. При найме нового члена команды, достаточно его просто занести в Jira и указать его группу-проект и он имеет доступ ко всему. Точно так же и при увольнении. В одном месте выключил и доступа нет никуда.
Уголок сисадмина
Сервер у нас стоит Xeon X3430 4CPUs x 2,4 Ghz, 8 GB, 1TB
Вначале, я поднял Windows Server и на нем все эти продукты сразу + Ubuntu для GitLab. Сервер не осилил, раз в два часа просто зависал на 10 мин.
После этого принял решение разделить по разным виртуалкам. Вот что получилось:
Gateway — для выхода в Интернет (4 ядра, 4ГБ ОЗУ) — эта виртуалка мне уже досталась от админа, который этот сервер первоначально настраивал.
Jira — 2 ядра, 2ГБ ОЗУ
Confluence — 2 ядра, 2ГБ ОЗУ
Bitbucket&Jenkins — 2 ядра, 2ГБ ОЗУ
Crowd&FishEye&FTP — 2 ядра, 2ГБ ОЗУ
Все виртуалки на Linux Debian 8.2
Теперь все эти продукты летают, и зависаний, как раньше, нет.
На виртуалке Gateway пробросил два порта чтобы снаружи были доступны Jira и Confluence. Размышляю над тем, чтобы еще пробросить порт для доступа к Git. Но чтобы было более секурно, только ssh доступ.
Итоги
Вот и готовы сервера и все необходимые продукты для полной автоматизации workflow разработки. В следующей части я постараюсь подробно описать как взаимодействуют эти все продукты ежедневно в процессе разработки.
P.S. Я посчитал ненужным описывать подробную настройку каждого продукта Atlassian из-за того, что статья стала бы очень длинной и сложной. Если у уважаемого сообщества будет желание ознакомиться с моим опытом, я с удовольствием опишу и эти нюансы настроек.
Комментарии (38)


EvilBeaver
06.11.2015 15:38Улыбнулся картинке «Стек Atlassian + Jenkins». Сами напоролись на те же грабли, Bamboo крайне неудачный сырой продукт, что удивительно, по сравнению с другими замечательными продуктами Atlassian. У нас только на этой картинке вместо Jenkins — TeamCity :)

DigitalSmile
06.11.2015 17:53+1А у меня обратное мнение. Пользуемся Bamboo в связке с Jira-Confluence-Bitbucket. Если честно после Jenkins, просто раем показался. :) TeamCity не пробовал пощупать по настоящему, поэтому не могу сказать за его удобство.
Что сделать в Bamboo проще:
— разделение стадий сборки и деплоя
— удобный и понятный интерфейс (субъективно)
— контроль версионности
— git-workflow из коробки
Минус я вижу только один — действительно маленькое сообщество и небольшое количество плагинов. Хотя на самом деле написать свой плагин дело пары тройки дней. Мы, например, написали плагин деплоя сборки на сервера Amazon AWS через OpsWorks. Работает вполне прилично.EvilBeaver
07.11.2015 23:49Нас тоже привлекли такие фичи, как разделение на сборку и деплой, ручные этапы сборки, красивый интерфейс и прочее. Ели сравнивать с Jenkins, (особенно с безплагинным), то преимущество налицо. Но у нас на паре проектов был ТимСити и сравнивать приходилось именно с ним. Например, отсутствие в Bamboo шаблонов просто убивает. Если у меня 20 билд-планов и я хочу добавить (или изменить шаг) во всех — я должен это проделать ручками в каждом из них. В Jenkins, кстати есть плагин для delivery pipeline, который как раз делит на фазы build-test-deploy.
В итоге, как я написал, Bamboo сырой. Он вроде бы хороший, но блин, вот этого нет, вот этого нет, вот это через задницу… и так везде. Ощущение недоделки. ТимСити в том отношении намного приятнее. Jenkins нужно тщательно готовить, и я не пробовал погружаться в него с головой, но коллеги говорят, что плагины есть для любых процессов и вообще всего на свете.

AlexLeonov
06.11.2015 16:08Так и не смог понять из статьи три вещи:
- Какие продукты вы разрабатываете?
- Какие языки и технологии применяются?
- Зачем эта статья здесь?

DragFAQ
06.11.2015 16:231. Ну это к делу не относится. Но это и не секрет. Разрабатываем всевозможные web-системы. Соц сети, онлайн торги, платежные системы, почтовые системы и т.д. и т.п.
2. Пишем в основном на PHP+Postgresql, но бывают и исключения.
3. Правильно построенный workflow здорово облегчает жизнь всем участникам процесса разработки. И вот один из способов автоматизировать этот процесс по максимуму.
AmdY
06.11.2015 16:29А почему ревью не делаете прямо на битбакете в пулл реквесте?
И про сумму расскажите, а то стек хороший, но денег просит при том, что есть аналоги схожей функциональности, тот же гитлаб имеет и вики, и битбакет заменит, и трекер, и код ревью проводить можно.DragFAQ
06.11.2015 17:01В вашем workflow используется пулл реквест. У нас — нет. У нас все программисты работают в dev ветке и тимлид раз на версию это все сливает в мастер ветку.
Честно говоря я так и не понял до сих пор как быть с тестированием в модели пулл реквеста.
GitLab как бы имеет и трекер и вики… но в функциональности они вообще рядом с Jira и Confluence не стоят. Читайте ЧАСТЬ 2. Такое на GitLabe не настроить.AlexLeonov
06.11.2015 17:44У нас все программисты работают в dev ветке и тимлид раз на версию это все сливает в мастер ветку.
Всё, понял, недочитал сначала. То есть git использовать вы не умеете. На этом можно тему с вашим flow закрывать, к сожалению…

nitso
08.11.2015 22:49Для тестирования в модели с пулл-реквестом разворачивается отдельный стенд для каждой тестируемой ветки. Делается это как правило автоматизированными средствами (тем же jenkins'ом без проблем). Таким образом, в основную ветку изменения попадают только после тестирования.
DragFAQ
08.11.2015 23:09Вот и получается, что тестить приходится дважды. А для качественных тестов порой времени тратится в несколько раз больше чем на разработку.
Наши тестировщики проводят всевозможные виды тестирования, которые отнимают ну очень много времени, но за то покрывают всё. Потому тратить время на два таких тестирования не целесообразно. Либо надо иметь тестировщиков в два раза больше чем программистов. Ну или тестировать только позитивным тестированием.nitso
08.11.2015 23:41Два раза, говорите? Вот обычный чек-лист для тестирования:
- тест разработчиком («протыкать» реализованный функционал, может быть smoke-test примитивный)
- модульное тестирование (unit-тесты) разработчиком и автоматизированно
- тест тестировщиком соответствия реализации заданию (этот этап все называют по-разному: функциональное, подтверждающее)
- тестирование тестировщиком на скрытые баги/уязвимости, обычно совместно с предыдущим пунктом
- регрессионное тестирование — комплексная проверка функционала, который до этого момента корректно работал («ничего не сломалось»)
- интеграционное тестирование — проверка, что связанные системы все еще нормально работают нашим модулем
- приемочное тестирование
Весь этот список на workflow с ветками ложится следующим образом:
- отдельная ветка тестируется разработчиком, запускаются модульные тесты, ветка передается на функциональное тестирование — пройтись по задаче, проверить, что кнопки на своих местах, нажимаются, заказанный функционал работает (это не тестирование всей системы)
- перед релизом таких веток набирается много, они после функционального тестирования сливаются в релизную ветку (если релизы линейные — ваш dev) и проводится регрессионное тестирование всей системы, интеграционное тестирование
Итого: много небольших «сеансов тестирования» во время активной разработки, большое тестирование перед релизом. Весь процесс тестирования удобно и итеративно автоматизируется. В конце концов, регрессия и интеграция тестируются автоматизированно.
AlexLeonov
09.11.2015 13:26+1И это вы еще забыли автоматическое функциональное и регресс-тестирование, например Selenium. У нас, например, отдельный сервер отведен под тестовый стенд с Selenium. Тесты автоматом запускаются после сборки каждого шота, билда и препродакшна, итого каждая задача три раза проходит набор автотестов.
И это только малая часть комплекса работ по QA. А тут нам говорят, что «два раза тестировать — это чересчур»…nitso
09.11.2015 15:56Плюсую. Я подразумевал, что автоматизацию отдельно выносить не стоит, так как это частный случай ручного тестирования :)
AlexLeonov
06.11.2015 17:43ОК, коллега. Второй вопрос вы разъяснили, спасибо. Первый — что-то написали, спасибо и на том.
А вот по третьему — по-прежнему полная непонятка. Какой git flow используете, «git flow» или что-то свое? Почему именно такая система веток вам приглянулась? Как строите изолированные стенды? Что именно работает в качестве сценария сборки?
Статья не содержит основной ценности, how-to. И очень смахивает просто на отписку. Мол у нас — флоу. И что?DragFAQ
07.11.2015 13:01-2Возможно из-за перехода с svn, но мне кажется, что наш флоу удобнее.
1. У программиста не бывает задач дольше дня — нет смысла делать много комитов по одной задаче.
2. они так или иначе влияют на правки другого программиста — как тестировать? Опишите, пожалуйста, как тестируют у вас. И вообще есть тестировщики?
3. очень часто исправляются одни и те же файлы одновременно несколькими программистами — мержи и в нашем случаи неизбежны, но в случае с ветками 100% будут конфликты.
4. Работа всего коллектива не останавливается в случае отсутствия мастера.
Как я уже писал в части 2, любой программист может срочно исправить багу, и любой тестировщик может срочно собрать исправления и протестировать.
Пул реквест мы пробовали внедрять несколько раз, но ниразу не взлетел.AlexLeonov
07.11.2015 20:27+1Не бойтесь конфликтов. Бойтесь, когда мерж проходит слишком гладко…
Повторю еще раз свою основную мысль — если вы не изолируете код отдельных тасков в отдельные ветки, вы не умеете использовать гит. Он вам просто не нужен, вы его не смогли понять.
Да, у меня есть и тестировщики (много) и разработчики (еще больше). А еще у меня есть понимание, что разработчик вообще не должен думать о флоу, сборках и прочем. Его задача — коммитить и пушить, а все остальное у меня автоматизировано. Как именно — лучше почитайте статьи Badoo, у них это описано ( и сделано) лучше.

ekho
06.11.2015 19:09+3В то время я заметил Stash. В чистом виде под линукс я, к сожалению, его не нашёл, за то поставил его в составе Bitbucket.
У меня сложилось впечатление, что Вы толи впопыхах разбирались, толи я не знаю что подумать.
Дело в том, что Stash и Bitbucket Server это один и тот же продукт. Просто буквально недавно атлассиан переименовали его из первого во второе. И соответственно я не представляю как Вам удалось поставить Stash в составе Bitbucket :)
Аналогично про код-ревью.
Рекомендую поглубже изучить инструменты, которыми пользуетесь.DragFAQ
06.11.2015 23:08Все немного не так. Про стеш я рыл много, но толкового описания не нашёл. Он и сейчас есть на сайте атласиана для скачивания, но только под Винду. У меня не было желания его ставить, чтобы удовлетворить любопытство. Когда я установил Bitbucket, я подумал, что стеш был просто репозиторием, а тут ещё и понятие проектов появилось…
Так как при подключении репозиториев к Fisheye, они светились именно как стеш репозитории, то я и сделал вывод, что стеш просто обернули в новую обертку.ekho
06.11.2015 23:36Он и сейчас есть на сайте атласиана для скачивания, но только под Винду.
Единственное место где можно скачать Stash — это архив ( www.atlassian.com/software/bitbucket/download-archives ).
И там, если посмотреть, каждая версия идёт в 5 вариантах: ZIP Archive, Windows 64bit Installer, TAR.GZ Archive, Mac OS X Installer и Linux 64bit Installer.
то я и сделал вывод, что стеш просто обернули в новую обертку
Даже ссылка www.atlassian.com/software/stash редиректит на www.atlassian.com/software/bitbucket/server, где кстати в самом верху страницы большими белыми буквами на голубом фоне написано «Stash is now called Bitbucket Server».
Не знаю, честно говоря, как надо было читать чтобы сделать такой вывод.
P.S. мы в проекте используем активно почти весь атлассиановский стек: Jira, Confluence, Bamboo, Bitbucket server, Crucible/FishEye. Администрированием и настройкой последних трёх полностью занимаюсь сам. Можно сказать собаку съел =) Для Stash писал плагины (надо их, кстати, под bitbucket адаптировать). В бамбу настроены разноплановые тесты, сборки и деплои web-проектов. Это я не хвастаюсь, не подумайте. Это я к тому, что смею считать, что довольно неплохо разбираюсь в атлассиановском софте. Поэтому и Ваши утверждения несколько удивили меня.

alfss
06.11.2015 19:16А зачем Crowd если есть LDAP или AD?
DragFAQ
06.11.2015 23:13К LDAP можно коннектится краудом. Не все атласиан продукты могут коннектится куда попало. Обычно они могут коннектится или к крауду или к джире.

ctacka
09.11.2015 01:12Crowd обеспечивает SSO, причем не только для atlassian продуктов. Ну и админить его куда проще, особенно если нет выделенных админов.

niveus_everto
06.11.2015 22:34Jira — 2 ядра, 2ГБ ОЗУ
Теперь все эти продукты летают, и зависаний, как раньше, нет.
Серьезно? Она уже не Resource Hog?
ctacka
09.11.2015 01:19JIRA умеет настраивать сколько угодно ролей, вы их сами создаете. Я бы поставил побольше ролей — их удобно использовать потом для нотификаций, для прав доступа, в workflow удобно их можно использовать.
DragFAQ
09.11.2015 11:22О. А можно любой жизненный пример настройки ролей у вас? Просто я в эту сторону даже не рыл, просто принял у Jira этот пункт как есть.
ctacka
10.11.2015 04:18Ну например сделали роли «тестировщик», «переводчик» и «продвинутый девелопер». Тестировщики единственные могут закрывать задачки. Переводчики у нас внешние, видят только то что им положено. Продвинутые девелоперы получают нотификации даже по чужим тикетам и могут закрывать задачи без ревью.
alexrett
Т.е. упрощая все до одного предложения Вы взяли почти все Atlassian продукты и засетапили Jenkins.
А как у Вас организована система общения в коллективе (HipChat \ Slack \ Jabber \ etc..)?
А продуктивность как учитываете?
И случаем не смотрели в сторону TeamCity?
Caravus
Вот кстати насчёт общения — больной вопрос. Только что посчитал — телеграм, скайп, слак и почту я пользую ежедневно. Понятно что почту врядли получится заменить, но всё остальное совместить внутри команды можно было бы.
alexrett
Мы после многих мытарств пересели на slack, прикрутили туда hubot'a и счастливы до нельзя :) рекомендую
Жаль только, что standalone не планируется в ближайшем будущем.
DragFAQ
Пробовали разные системы, но пришли к выводу, что всем удобнее группы в скайпе: весь проект, программисты, тестировщики и лиды.
Jira благодаря «Automated Log Work for JIRA» автоматом логирует время. А у «WorkLog» отличные визуальные отчеты. Вот-вот опубликую вторую часть, там об этом есть.
TeamCity — не изучал. Но спасибо за наводку, посмотрю.
i360u
В командном чате — интеграция с другими инструментами также очень удобна, и поэтому скайп — далеко не лучший вариент. Остальное — дело вкуса.