
В своем предыдущем посте «Параллельные алгоритмы STL на компиляторе GCC» я уже изложил всю необходимую теорию о Parallel C++17. Сегодня же я собираюсь провести тест производительности на компиляторе Microsoft и компиляторе GCC, чтобы ответить на простой вопрос: окупается ли политика выполнения?

Причина этого краткого отступления от темы шаблонов следующая. Я узнал, что GCC поддерживает мою любимую фичу из C++17: параллельные алгоритмы стандартной библиотеки шаблонов. В этом посте я представляю совершенно новый GCC 11.1, но и 9-й GCC тоже прекрасно подойдет. Чтобы использовать параллельные алгоритмы STL с GCC, вам необходимо будет установить несколько дополнительных библиотек.
Threading Building Blocks
GCC использует под капотом Thread Building blocks (TBB) Intel. TBB — это библиотека шаблонов C++, разработанная Intel для параллельного программирования на многоядерных процессорах.
Если быть точным, вам нужна версия TBB 2018 года или моложе. Когда я установил пакет разработчика TBB на свой ПК с Linux (Suse), менеджер пакетов также выбрал аллокатор TBB. Пользоваться TBB легко. Вам всего-то нужно подключить TBB, используя флаг -ltbb.

Вот и все. Теперь я готов делать с параллельными алгоритмами все, что я задумал. Вот первые цифры с использованием компиляторов Microsoft 19.16 и GCC 11.1.
Показатели производительности на компиляторах Microsoft и GCC
Следующая программа (parallelSTLPerformance.cpp) вычисляет тангенсы с последовательной (1), параллельной (2) и параллельной и векторизованной (3) политикой выполнения.
// parallelSTLPerformance.cpp
#include <algorithm>
#include <cmath>
#include <chrono>
#include <execution>
#include <iostream>
#include <random>
#include <string>
#include <vector>
constexpr long long size = 500'000'000;
const double pi = std::acos(-1);
template <typename Func>
void getExecutionTime(const std::string& title, Func func){ // (4)
const auto sta = std::chrono::steady_clock::now();
func(); // (5)
const std::chrono::duration<double> dur = std::chrono::steady_clock::now() - sta;
std::cout << title << ": " << dur.count() << " sec. " << std::endl;
}
int main(){
std::cout << '\n';
std::vector<double> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_real_distribution<> uniformDist(0, pi / 2);
for (long long i = 0 ; i < size ; ++i) randValues.push_back(uniformDist(engine));
std::vector<double> workVec(randValues);
getExecutionTime("std::execution::seq", [workVec]() mutable { // (6)
std::transform(std::execution::seq, workVec.begin(), workVec.end(), // (1)
workVec.begin(),
[](double arg){ return std::tan(arg); }
);
});
getExecutionTime("std::execution::par", [workVec]() mutable { // (7)
std::transform(std::execution::par, workVec.begin(), workVec.end(), // (2)
workVec.begin(),
[](double arg){ return std::tan(arg); }
);
});
getExecutionTime("std::execution::par_unseq", [workVec]() mutable { // (8)
std::transform(std::execution::par_unseq, workVec.begin(), workVec.end(), // (3)
workVec.begin(),
[](double arg){ return std::tan(arg); }
);
});
std::cout << '\n';
}Для начала мы заполняем вектор randValues 500 миллионами чисел из полуинтервала [0, pi/2]. Шаблон функции getExecutionTime (4) получает имя политики выполнения, выполняет лямбда-функцию (5) и показывает время выполнения. Есть один нюанс, касающийся трех лямбд ((6), (7) и (8)), используемых в этой программе. Они объявлены как mutable. Это необходимо, потому что лямбда-функции изменяют свой аргумент workVec. Лямбда-функции являются константами по умолчанию. Если лямбда должна изменить свои значения, то ей нужно быть объявленной как mutable.
Я начну с показателей производительности на Windows. Но прежде чем я это сделаю, я должен добавить небольшой дисклеймер.
Дисклеймер
Я хочу это особенно подчеркнуть. Я здесь ни в коем случае не занимаюсь сравнением Windows и Linux, потому что оба эти компьютера с Windows или Linux имеют разные возможности. Эти показатели производительности призваны дать вам исключительно приблизительное представление. Это означает, что если вы хотите знать цифры актуальные для вашей системы, вам придется самим повторить этот тест.
Я использую максимальную оптимизацию на Windows и Linux. Это означает, что для Windows установлен флаг /О2, а для Linux флаг -О3.
Если коротко - мне очень интересно узнать, окупается ли параллельное выполнение алгоритмов STL, и если да, то в какой степени. Основное внимание я уделяю относительной производительности последовательного и параллельного выполнения.
Windows
Мой ноутбук с Windows имеет восемь логических ядер, но параллельное выполнение более чем в десять раз быстрее:
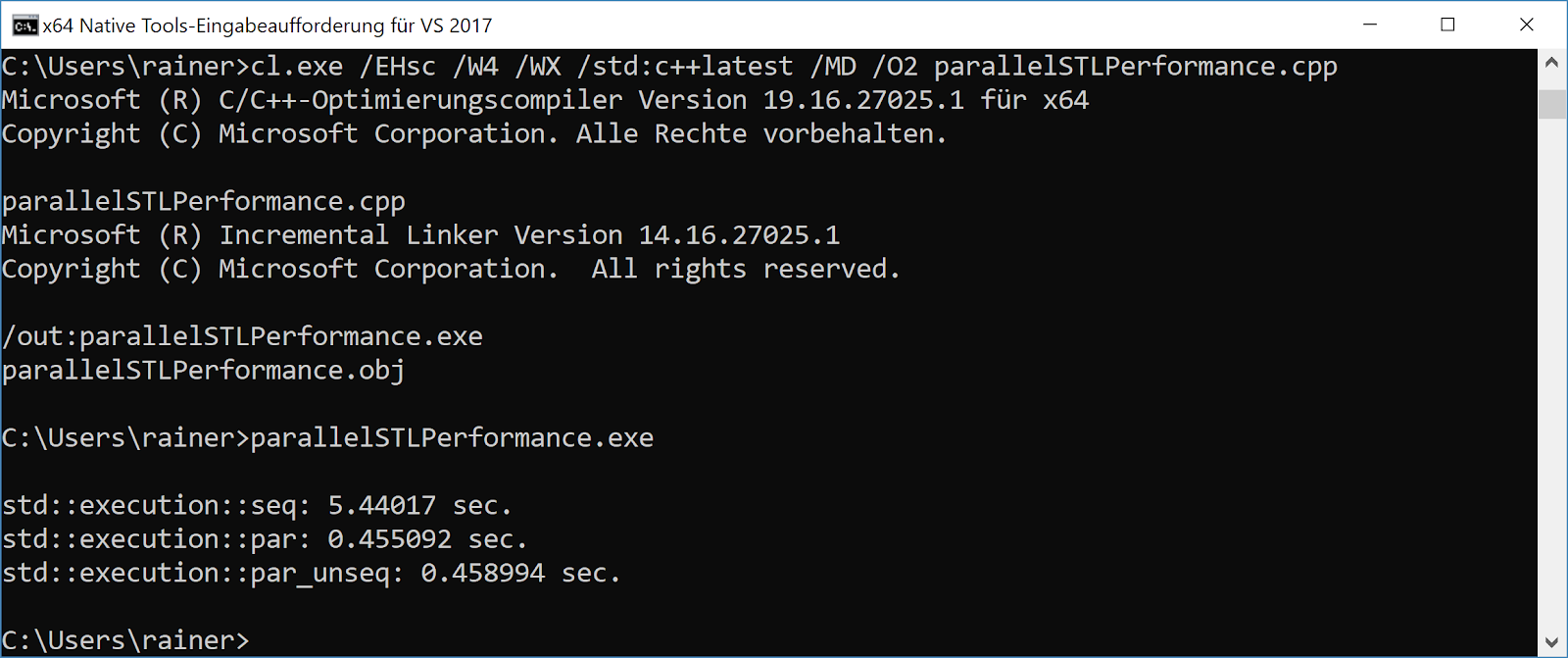
Цифры для параллельного и параллельного и векторизованного выполнения находятся приблизительно на одном уровне. Вот объяснение для это из блога команды Visual C++: Использование параллельных алгоритмов C++17 для повышения производительности:
Обратите внимание, что реализация Visual C++ реализует параллельные и параллельные непоследовательные политики одинаковым образом, поэтому не следует ожидать повышения производительности при использовании par_unseq в нашей реализации, но могут существовать реализации, которые когда-нибудь смогут извлечь пользу из этой дополнительной свободы.
Linux
Мой компьютер с Linux имеет только четыре ядра. Вот результаты:
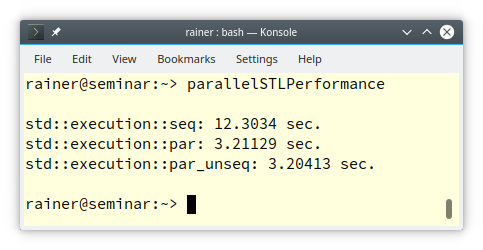
Цифры ожидаемые. У меня четыре ядра, и параллельное выполнение примерно в четыре раза быстрее последовательного. Показатели производительности параллельной и векторизованной версии и параллельной версии находятся на одном уровне. Поэтому я предполагаю, что компилятор GCC использует ту же стратегию, что и компилятор Windows. Когда я запрашиваю параллельное и векторизованное выполнение с использованием политики выполнения std::execute::par_unseq, я получаю политику параллельного выполнения (std::execute::par). Такое поведение соответствует стандарту C++17, поскольку политики выполнения являются лишь подсказкой для компилятора.
Насколько мне известно, ни компилятор Windows, ни компилятор GCC не поддерживают параллельное и векторизованное выполнение параллельных алгоритмов STL. Если вы хотите увидеть параллельные и векторизованные алгоритмы во всей красе, реализация STL от Nvidia Thrust может послужить идеальным кандидатом. Для получения дополнительной информации читайте следующий пост от Nvidia: «Параллелизм стандарта C++».
Что дальше?
После этого отступления к C++17 я возвращаюсь к своему первоначальному маршруту: шаблонам. В моем следующем посте, я погружаюсь в шаблоны еще глубже и пишу о их инстанцировании.
Приглашаем на открытое занятие, на котором разберемся, какие основные алгоритмы включены в STL. В ходе занятия мы познакомимся с алгоритмами поиска и сортировки. Регистрация на урок открыта на странице онлайн-курса "C++ Developer. Professional".
threepointsix
Хочу добавить, что Thrust от Nvidia намного быстрее, поскольку для параллельных вычислений он использует не процессор, а видеокарту. Но тут есть и проблемы: придётся компилировать не с GCC, а с NVCC от Nvidia. А скомпилированная программа запустится только на современных видеокартах от Nvidia поддерживающих CUDA, так что обладатели AMD остаются с носом