
Привет. Я Марат Сибгатулин — сетевик в Яндексе, ведущий подкаста linkmeup, автор серии книг «Сети для самых маленьких» и спикер курса Слёрм Сети для DevOps, который мы сделали совместно с linkmeup.
Сегодняшний рассказ будет про несколько органических проблем современных сетевых технологий.
В жизни любого инженера бывают периоды как долгой кропотливой проработки архитектуры, так и долгих кропотливых расследований инцидентов или проблем. Нет, бывают, конечно, и озарения, стремительные лёгкие открытия, но обычно слова «кропотливый» и «методичный» — неизменные спутники нашей работы. И увы — не всегда этот процесс завершается яркой кульминацией и впрыском дофамина.
Ведь именно ради этого, и только обладая должным терпением и перфекционизмом, мы идём в профессию.
То, что мы наделали при проектировании, всегда приводит к проблемам при эксплуатации. Отличаются лишь детали: количество таких проблем, сила их влияния, нам их разгребать или кому-то другому, фундаментальные они и требуют масштабных изменений, или декоративные и компенсируются сравнительно небольшими доработками.
И сфера в общем-то не важна — сетевые технологии, разработка ПО, строительство домов, мостов или самолётов.
Есть кирпичи, которые научились изготавливать давно и хорошо, есть инструменты проектирования, упрощающие жизнь, есть шаблоны архитектур, которые берёшь и модифицируешь под свои задачи. Конечный результат получается в среднем хороший, в среднем — как у всех.
Отрасль ИТ от других отличает то, что в ней, обычно, от качества результата не зависит жизнь человека. Во всяком случае, напрямую. Поэтому плохие шаблоны могут вымываться очень долго, а ошибки переходить из одного проекта в другой раз за разом.
Иногда разбираться приходится с плодами своих же талантов архитектора, но чаще — с чужими. Свои или знаешь заранее, или быстро привыкаешь и вырабатываешь мышечную память к их употреблению. Чужие — каждый раз как в первый: садишься, долго разбираешься, находишь уникальное решение-снежинку, но и тут со временем начинаешь прослеживать те самые ошибки-гастролёры.
Я работаю с сетями, я их искренне люблю всем сердцем. Потому что они — фундамент, они основа, на которой всё строится и держится. Они с нами навсегда во всех своих проявлениях — медная витая пара, соединяющая сервер с коммутатором, оптический - трансокеанский кабель, WiFi до ноутбука и 4G до телефона.
Вокруг будут сменяться эпохи и технологии, мир будет бороться за экологию и экологичность, за равенство первых и первенство вторых, мы будем строить базы на Марсе и добывать минералы в поясе Астероидов, но незыблемыми останутся сети.
Сколько нужно сетевых инженеров, чтобы остановить шторм?
Помните тот анекдот про серийного убийцу?
Плохой программист Джон сделал ошибку в коде, из-за которой каждый пользователь программы был вынужден потратить в среднем 15 минут времени на поиск обхода возникшей проблемы. Пользователей было 10 миллионов. Всего впустую потрачено 150 миллионов минут = 2.5 миллиона часов. Если человек спит 8 часов в сутки, то на сознательную деятельность у него остается 16 часов. То есть Джон уничтожил 156250 человеко-дней ≈ 427.8 человеко-лет. Средний мужчина живет 64 года, значит Джон убил примерно 6 целых 68 сотых человека.
Так вот есть такая технология, как Ethernet. По задумке изобретателей в IEEE (читается как ай-трипл-и) она должна была принести благо и обеспечить работу нескольких узлов внутри одной локальной сети.
Под локальной сетью понималась сначала общая металлическая шина на коаксиальном кабеле. Это была разделяемая среда, и в конкретный момент времени в ней мог передавать данные только один узел.Даже всякие слова ругательные придумали, вроде CSMA/CD, которые позволяли коллизии разруливать.
Все узлы получали все данные.
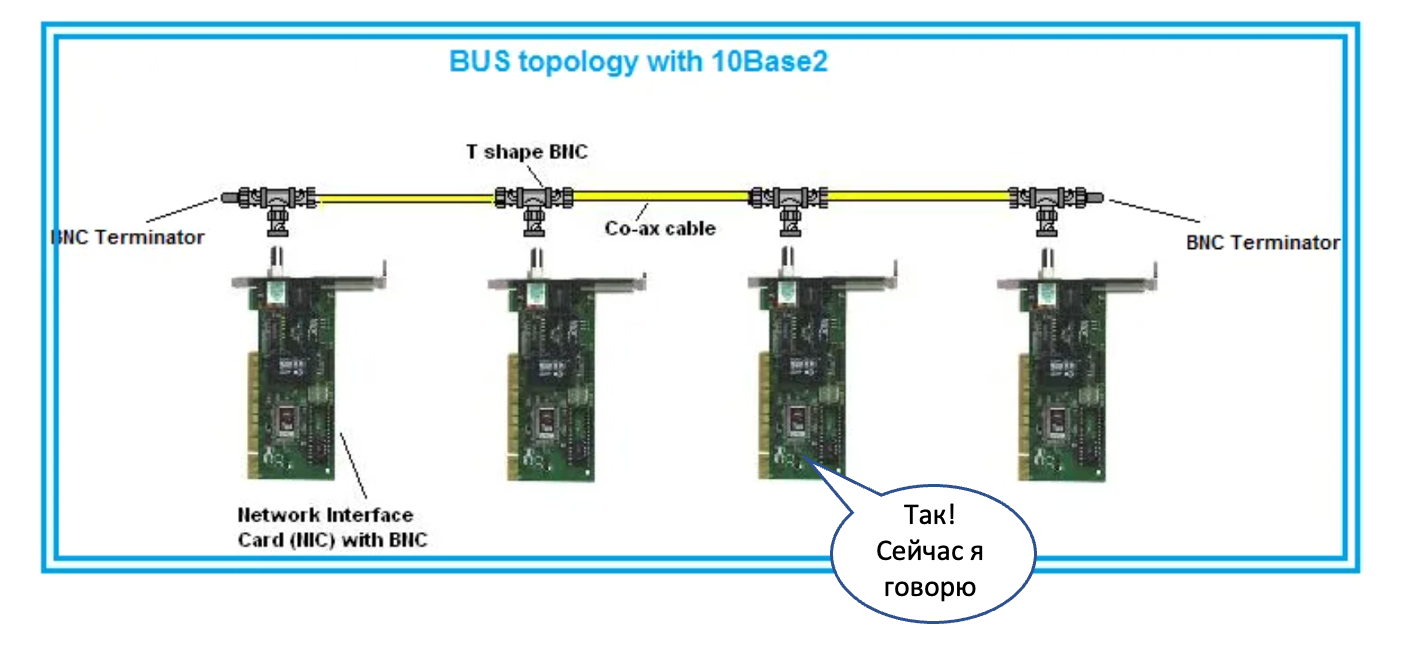

Повторюсь, что технология предполагалась быть ограниченной только небольшим сегментом на несколько узлов. Скорость передачи данных для отдельного узла экспоненциально уменьшается с добавлением каждого нового узла.
Чтобы адресовать узлы, в такой сети используются MAC-адреса — концепция второго уровня модели OSI (Layer 2 или L2). Всё, что подключено к одной такой шине, называется единым L2-доменом, поскольку все коммуникации в пределах него ограничены именно технологиями L2.
В скором одножильную шину заменили на многожильную витую пару, для соединения друг с другом узлов стали ставить хабы, а чтобы в один L2-домен можно было включить побольше узлов, стали сегментировать локальную сеть бриджами. Хабы по сути делали физическую коммутацию между кабелями, а бриджи были поумнее и перекидывали между своими портами не просто электрический сигнал, а уже Ethernet-кадры, зная, какой куда нужно передавать.



Домен коллизий уменьшился, и так стало возможным подключать больше узлов, не сильно жертвуя скоростью.
Ещё чуть позже всё-таки захотелось ещё больше скорости — чтобы каждый узел мог передавать и получать данные с максимальной мощью, предоставляемой сетевой картой - ведь странно, если у тебя 10мегабитный NIC, использовать из него только сотню килобит из-за болтливых соседей?
Так появились коммутаторы — очень (по тем временам) умные коробки, которые сами умеют определять, где какой узел находится и выстраивать коммуникацию с ними индивидуально на основе изучения MAC-адресов и поддержания их таблицы внутри чипов. Домен коллизий вообще исчез, потому что на одном проводе оказались только два устройства, у которых ещё и Rx с Tx на разных парах — шли сколько хочешь в обоих направлениях.
С ними мы шагнули в настоящее, где каждый узел получил возможность подключаться на скорости 1Гб/с


И так в результате больших и маленьких последовательных оптимизаций мир получил возможность в один L2-домен засовывать практически неограниченное количество узлов и неизлечимую болезнь, подпортившую много жизней. Именно с коммутаторов началась мировая история широковещательных штормов: сложно даже прикинуть, сколько миллионов часов человечество провело в их отладке.
Прекрасное и отвратительное в том, что Ethernet превосходно решает порученные ему задачи, имея в самом ядре своём механизм auto-discovery. Узел, отправляющий данные, не знает изначально, сколько и каких соседей с ним есть в сети. Не знает он и то, где расположен его шлюз: он просто шлёт данные. А сеть сама сможет понять, куда их доставить.

Механизм этот называется широковещание или broadcasting. Не знаешь, что делать? Рассылай во всех доступных направлениях — там разберутся.
Ну а поскольку первые топологии локальных сетей были звёздами и не предполагали наличия петель, никто и не думал о том, что жизнь кадра должна быть конечной и скоротечной.
Однако если петля есть и кадр в неё попал, он будет бегать по ней без конца и края. А сделать петлю — как два байта отослать: просто вставить кабель одновременно в два порта коммутатора. Я вам не говорил, но это распространённая проказа в домовых сетях.
Хуже того: такой трафик может мультиплицироваться и за считанные минуты забить любой доступный канал и интерфейс. Характерной чертой штормов является 100% утилизация интерфейсов и истеричная гирлянда светодиодов на портах коммутатора. От этого страдает транзитный пользовательский трафик: для него не остаётся места.
А ещё такие кадры в большинстве своём должны быть обработаны на CPU-коммутатора, вдруг это ему предназначается, поэтому к 100% на интерфейсах добавляется 100% утилизации CPU, а это в свою очередь вырубает Control Plane коробки — она становится неотзывчивой, рвёт установленные сессии, перестают работать протоколы, не отвечает на запросы системы мониторинга или даже SSH.
Но всё ещё нет проблемы, пока мы Ethernet используем в домашней или офисной сети, где упало что-то: да и бог бы с ним,один пользователь пострадал. Мы можем не строить там сети с петлями административно и запрещать их появление по злому умыслу или незнанию технически. А в сетях операторов связи и датацентрах должны существовать свои другие отказоустойчивые топологии и протоколы.
И такое использование разных технологий для организации локальных сетей возможно, потому что общим объединяющим протоколом является IP, работающий на третьем уровне модели OSI (L3). А на разных сегментах от отправителя до получателя на канальном и физическом уровне может быть абсолютно что угодно.
Но почему-то возможность была воспринята как необходимость. И Ethernet начали со страшной силой пихать куда ни попадя. Провайдеры стали делать на нём домовые сети и пихать его в ядро. Сети предприятий распробовав дешевизну оборудования Ethernet и стали строить на нём свои кампусные сети. В датацентрах подешевевшие из-за массовости Ethernet-чипы тоже снискали популярность.
А всем этим ребятам нужна отказоустойчивость, потому что отказ одного линка или устройства — это сотни и тысячи пострадавших пользователей, недополученных денег и испорченная репутация.
И как только стали появляется кольцевые L2-топологии, начались и чудовищные штормы так называемого BUM-трафика. Очень звучное и говорящее название, кстати. Broadcast, Unknown Unicast и Multicast — все эти виды трафика однажды попав в петлю, остаются в ней до тех пор, пока её не разорвать. И все они плоть от плоти L2 — неотъемлемая часть Ethernet, и они присутствуют в сети всегда.
Как решение этой проблемы появились 50 оттенков STP — протокола, отрезающего лишние линки, чтобы не было петель. Вместе с ними плодились и проприетарные реализации протоколов защиты в кольцевых топологиях а-ля ERPS.
И вот представьте себе: строите вы сеть, покупаете гору оборудования, кабелей между ними, трансиверов, а потом половину чик — и отрезаете, лишая себя купленной пропускной полосы. Обидно.
И все эти протоколы рано или поздно дают сбои. Я в своей жизни ещё не встречал отказоустойчивых L2-сетей, в которых бы не было шторма. И это всегда болезненно, это всегда критический инцидент с большим влиянием.
Я видел сети городских провайдеров, ядро которых построено на L2 и отказоустойчивость обеспечивается STP или его аналогом. Их штормило по несколько раз в месяц — весь город оставался без связи от этого провайдера.
Я видел сети операторов связи, у которых по городам и весям на сотни километров были раскинуты гроздья радиорелеек, собранные в L2-кольцо с STP. И от штормов в них иные деревни совсем оставались без связи.
Я видел федеральных операторов, чья физическая сеть построена на L3 и не имеет вышеуказанных проблем. Но поверх неё создавалась так называемая оверлейная или наложенная сервисная сеть, действующая по принципам L2. Да-да, и такое бывает. И в одном L2-домене оказывался целый регион, а то и несколько. Раз в несколько месяцев оно вспыхивало синим пламенем и полыхало по несколько часов, вместе с десятком-другим инженеров, пытающихся понять, что происходит и где рвать петлю.
Я сам запускал шторм в сети датацентра, когда в сеть Клоза ставил недонастроенное оборудование и пара сотен 100гигабитных линков уходили в полку по утилизации.
И вот этот порочный шаблон повторяется из одного проекта в другой многие годы. Раз за разом. А решение очень простое — оставить L2 там, где ему место — в небольших локальных сетях не больше чем на сотню конечных хостов.
Да, мы никуда не денемся от Ethernet как от нижележащего протокола: он теперь повсеместный. Мы ничего не можем сделать с механизмом широковещания: уже поздно добавлять поле TTL в Ethernet-заголовок, чтобы старые пакеты погибали — никто не сможет с этим работать.
Но клянусь, в наших силах сохранить широковещательный домен очень маленьким. И каждый раз, когда к сетевому инженеру приходят с предложением натянуть L2, он должен подозрительно сощурить глаза, взглянув на вопрошающего, и дать тому затрещину. Есть только одна причина, растягивать L2: вам чересчур спокойно живётся и хорошо спится и руководство разделяет вашу тоску.
Вообще мы тут рекламируем наш курс про сети, поэтому если хочется погрузиться в описанные вещи поглубже, то вам туда прямая дорога. Разбираемся с моделью OSI и её уровнями, смотрим, как работает broadcasting, настраиваем бриджинг и STP, ну и вообще всячески делаем так, чтобы эти грозные слова вас не пугали.
Я тебя вычислю по IP
Мне кажется, в топ-3 причин нёх на сети входит именно описанная ниже ситуация.
«Тут ходит — тут не ходит», «то болит — то не болит», «у меня постоянно рвутся коннекты», «у меня через раз устанавливаются коннекты», «поретраю — и работает», «трафик пошёл не туда, куда я сказал», «постоянно разваливается OSPF».
Эти и другие увлекательные истории можно услышать, когда вы (или вам) устроили конфликт IP-адресов, то есть в двух местах настроили один и тот же IP-адрес. Это может быть интерфейс конечного узла, может быть интерфейс маршрутизатора или любой другой сетевой сущности.
А дело всё в том, что пакетик такой бежит-бежит по сети. Радостно оглядываясь на таблицу маршрутизации, спешит он к своему получателю. И вот он его уже видит, запрыгивает на сетевой стек машинки с адресом назначения, а оттуда netlink в него из револьвера — бах! Вас тут не ждали! А настоящий получатель так и не получил свой пакет.
Так могут не устанавливаться новые TCP-сессии: потому что на порту никто не слушает;
Так могут подвисать и рваться старые, если поток трафика перенаправился в другое место, и там, на порту, никто не слушает;
Так могут пинги бежать то к одному получателю, то к другому. И с виду всё хорошо, но почему-то задержки в 7 раз различаются и в tcpdump половину запросов не видно.
Так может OSPF не сходиться или постоянно перестраиваться из-за совпавших router-id.
В общем, если видимые симптомы вы можете охарактеризовать словом «дичь» (но не потому что вы вообще в сетях не шарите), то первым под подозрение поставьте задвоившиеся IP-адреса — поверьте моему опыту (я в сетях немного шарю).
Отлаживать это муторно, но не очень сложно: просто шаг за шагом смотрите на таблицы маршрутизации, местонахождение адреса назначения, его MAC-адреса, за каким портом он изучен. И рано или поздно докопаетесь.
Один из хостов вы, наверняка, знаете, и всё-таки обнаружите проблему. Можно просто выключить его или перенастроить адрес — тогда у вас выровняется ping и по traceroute вы сможете найти путь к хосту-поганцу с таким же IP (а потом найти и инженера-поганца, допустившего это).
Обычно такие проблемы случаются, когда выделение и назначение адресов происходит вручную. Просто человеческая ошибка — бывает. Поэтому для IPv4 придумали DHCP. Вам всего лишь нужно в каждом L2-домене поднять один сервер, настроить на нём пулы, шлюз, адрес DNS-сервера и следить за тем, что такой сервер действительно один. Ну, возможно, покопаться с настройками DHCP-Relay и всяких разных DHCP Options. Не беда.
Главное — что централизованное управление IP-адресами — это благо: оно позволяет снизить вероятность IP-конфликта.
Это всё касалось IPv4. Не в малой степени он склонен к конфликтам из-за ограниченного адресного пространства (всего 32 бита) и отсутствия вообще каких-либо проверок на такие коллизии.

В IPv6 проведена масштабная работа в этом направлении (как и любом другом, на самом деле — они там в IETF вообще большие молодцы, ну если не считать, что из-за них когда-то пришлось придумывать NAT).
Адрес IPv6 — 128-битный. Поэтому, во-первых, выделить одинаковые адреса чуть посложнее, во-вторых, ручное управление адресами вообще проблематично. И как ответ на «во-вторых» для IPv6 придумали автоконфигурацию IP-адреса на основе префикса сети и MAC-адреса хоста. Акцент на вторую часть — MAC-адрес хоста. Именно он делает в 99,9999% случаев IPv6-адрес уникальным.
А автоконфигурация избавляет инженера от необходимости поддерживать DHCP-инфраструктуру. Оно просто работает и нагенерит вам с высочайшей долей вероятности неконфликтный, воспитанный IP-адрес.
А кроме того у IPv6 из коробки есть DAD — Duplicate Address Detection. После назначения адреса на интерфейс он не использует его сразу, а сначала убеждается, что в локальной сети он один такой неповторимый и неотразимый. У меня в практике были десятки случаев конфликтов IPv4 адресов и ни одного IPv6.
IPv6 большее благо, чем IPv4 DHCP. Любите IPv6, переходите на IPv6, рассказывайте всем про IPv6. А если не понимаете за что любить и почему от 4 сразу перешли к 6 — мы вас научим. Как настроить их на Linux, как поднять DHCP-сервер, что за автоконфигурация в IPv6 и чем вообще IPv6 отличается от IPv4 (спойлер — не только числом битов). И вместе с вами подиагностируем разные проблемы связности.
Кортеж пятерых
А вот следующая штука не факт, что входит в какой-то топ среднестатистического сетевого инженера. И каждый день такое ловить не приходится, и коли уж поймали, то непонятно совершенно, что с этим делать.
Жили вы обычной жизнью сетевого инженера, BGP-шку там настраивали, новые офисы компании запускали, строили трансокеанский канал между офисами для HFT, чтобы сэкономить 5 миллисекунд по сравнению с конкурентом. И вдруг телеграм начал разрываться, а ваш дежурный пинг в консоли начал показывать 7% потерь.
Допустим, по плану эвакуации уже побегали, пользователям скорейшее выздоровление пообещали, что делаем дальше?
Тут, конечно, наберётся материала на серию статей с абсолютно произвольной глубиной погружения.
На самом деле дальнейшие действия зависят от характера потерь и симптомов: достаём из арсенала ping'и такие и сякие, traceroute/mtr, telnet/nc/curl, в конце концов tcpdump, и начинаем анализировать.
Только ли проблема с ICMP? Есть ли какой-то специфический шаблон в потерях? Большие пакеты проходят? TCP и UDP одинаково себя ведут? Можно ли сказать, что только у конкретных TCP-сессий есть проблема, в то время как у других всё чётко и стабильно? Показывает ли mtr накопительные проблемы по пути? А если mtr -T? Увеличиваются ли задержки? А проблемы наблюдаются до одного конкретного адреса? Или можно локализовать хотя бы направление? Или вообще куда угодно?
А если рубануть одного провайдера? А другого? А попробовать попинговать из другого места? А из-за пределов собственной сети вообще? А в обратную сторону — в сторону нашей сети извне — как дела? А маршруты нашей сети нормально вообще по миру распространяются?
В зависимости от наисследованного дальше причины можно классифицировать следующим образом:
Где-то плохое качество линии, а пакеты портятся/теряются на лету — скорее всего, бессистемные потери без увеличения задержек.
Где-то перегрузка на линии или в очередях маршрутизатора — скорее всего, бессистемные потери, сопровождающиеся отрастанием задержек.
Один из нескольких равнозначных путей испытывает проблемы выше — скорее всего, бессистемные потери с симптомом «то болит, то не болит». Но на трассировке по TCP или UDP будет видно, что только по конкретному пути проблемы.
Что-то стряслось с MTU: раньше большие пакеты проходили нормально, а теперь нет — скорее всего, ping маленькими пакетами (1400 байтов) будет ходить нормально, а большими (1500) будет таймаутить. Скорее всего, можно попробовать в TCP-порт тыркнуться через telnet или nc, а вот curl'ануть уже может не получиться — слишком много данных.
Ну и моё любимое — что-то где-то случилось так неловко, что конкретные TCP-flow (или UDP-датаграммы) не доходят до получателя. При этом другие доходят, а ICMP вообще проблем не фиксирует.
Запомни, инженер! Если ты не видишь потерь в ping %server_address%, это ещё не значит, что у тебя всё в порядке!
Знаете, первые четыре причины имеют под собой очень увлекательную фундаментальную базу и написано про это много книг и снято видосов (даже моими силами), и там, правда интересно, но позвольте мне проявить слабость и рассказать как раз о последнем.
Это действительно нечастая ситуация. В пинге вы можете увидеть её как более или менее регулярные потери с характерным шаблоном или нерегулярные бессистемные потери, но примерно одного и того же % запросов, а можете не увидеть совсем.
Если вы будете делать попытки установить TCP-сессии с помощью telnet или nc, то, на первый взгляд, тоже не будет никакой системы — иногда получается, иногда нет (на что пользователи, собственно, вам и жалуются).
Кстати, в цикле пробовать ставить сессии можно так
while :; do nc -zvw 1 linkmeup.ru 443; done
Connection to linkmeup.ru 443 port [tcp/https] succeeded!
Connection to linkmeup.ru 443 port [tcp/https] succeeded!
Connection to linkmeup.ru 443 port [tcp/https] succeeded!Немного косметики:
while :; do
nc -zw 1 linkmeup.ru 80 &> /dev/null && echo -n '!' || echo -n '.';
sleep 0.1;
doneКартина становится более наглядной.
Но стоит зафиксировать src port, как картина начинает проясняться.
Дело в том, что при установке TCP-сессии у нас зафиксированы четыре параметра: dst IP, src IP, протокол TCP, dst port. И один параметризируемый — src port. Для каждой новой сессии клиенты (браузеры, почтовики, SSH, FTP) выбирают новый эфемерный src port из диапазона 1024-65535. Не выбирать совсем нельзя вообще, меньше 1024 нельзя — всё уже занято, а меняется он для того, чтобы в этом так называемом 5-tuple (src-ip, dst-ip, proto, src-port, dst-port) была энтропия и при наличии нескольких различных путей на основе этого 5-tuple можно считать хэш и раскладывать по разным путям.

Хэш от одного и того же 5-tuple будет всегда получаться один и тот же, а следовательно, для него всегда будет выбираться один и тот же путь.
Так вот, если один из этих путей корёжит пакеты, то всё, что в него отправляется, будет теряться, а всё, что в него не попадает, будет работать нормально.

Именно поэтому просто установка соединения будет то успешной, то нет, а если мы фиксируем src port, то эта хэш-неопределённость разрешается, и мы получаем стабильную картину — или каждый раз успешен, или каждый раз провален.
Вот как можно зафиксировать порт:
nc -zv -p 34437 linkmeup.ru 443Вот как можно перебирать порты в цикле
for i in {10000..50000} ; do
echo -n "$i:";
nc -w 1 -p $i -z linkmeup.ru 443 &> /dev/null && echo " OK" || echo " FAIL" ;
sleep 0.1;
doneТеперь mtr вам, скорее всего, поможет понять, на каком хопе проблема (но может и не помочь).
И осталось разобраться в чём проблема и исправить её - всего-то.
> mtr -T linkmeup.ru -P 443
Host Loss% Snt Last Avg Best Wrst StDev
1. (waiting for reply)
2. 100.64.0.101 0.0% 15 0.2 0.2 0.2 0.3 0.0
100.64.0.33
100.64.0.103
100.64.0.34
100.64.0.74
100.64.0.72
100.64.0.75
100.64.0.39
3. (waiting for reply)
4. msk-ix-2.servers.ru 0.0% 14 4.1 5.9 3.8 18.3 4.7
5. se-mo01-s1.servers.ru 0.0% 14 3.7 3.9 3.7 4.2 0.2
6. se-mo1-s3.servers.ru 0.0% 14 3.9 3.8 3.5 4.0 0.1
7. se-mo01-l25-r1.servers.ru 0.0% 14 4.5 5.1 4.1 7.5 0.9
8. proxy03.linkmeup.ru 0.0% 14 3.4 3.4 3.1 3.5 0.1А тут… ну тоже серия статей с произвольной глубиной погружения.
Однако это почти всегда история про баги ПО — где-то что-то недопрограммировалось в чипы или структуры памяти, записалось не то, что было нужно или уже записанное было повреждено.
Основные причины:
Баг операционной системы сетевого устройства — на уровне работы с протоколами и формирования верхнеуровневых структур. Грубо говоря, программа неправильно посчитала таблицу маршрутизации и испортила один 5-tuple.
Баг SDK чипа. Чип коммутации предоставляет API для управления его внутренней памятью и правилами обработки пакетов. SDK для доступа к API — та же программа. И она тоже содержит баги.
И вы в него можете передать всё правильно, а он запрограммирует в чип с ошибкой. И пакеты с конкретными хэшами будут теряться.
Небольшое расширение вышеприведённых сценариев — залипания на фаерволах, когда в iptables спустились неверные правила.
Такие же сюрпризы может подкинуть и ECMP — Equal Cost Multipath, когда один из путей сломан так, что он продолжает выглядеть рабочим (например, анонсирует маршруты, через себя), но с точки зрения передачи транзитных данных поломался. Тогда всё, что раскладывается в него согласно 5-tuple будет теряться. Стоит вывести из под нагрузки этот путь — и всё начинает работать.

И очень изощрённый случай — аппаратные повреждения.
Был в моей практике такой случай. Приходит заказчик в техподдержку (ко мне) и говорит, что у него теряется часть трафика — лечится ретраями: ну прям как я выше описал симптомы.
Дальнейшая диагностика как раз позволила понять, что проблемы с прохождением определённых 5-tuple.
По трассировке мы увидели, что потери наблюдаются за пределами сети заказчика — в другом провайдере. А он по счастливой случайности тоже оказался нашим заказчиком, поэтому мы уже с ним продолжили диагностику. На сети этого провайдера стоял так называемый холодильник — шассийная коробка размером со шкаф, в которую напиханы дюжина плат и под полсотни разных сложных чипов. И вот мы посмотрели таблицу коммутации на чипе входной карты, посмотрели в какие пины задней шины шасси раскладываются пакеты, проверили живость этих путей и обнаружили, что через часть из них не проходят данные — мы не можем отловить их на выходном чипе.

Попросили инженера клиента извлечь интерфейсную плату и сфотографировать её. И что бы вы думали? На задней общей шине оказались загнуты контакты — и всё, что по балансировке внутри этого холодильника раскладывалось на эти пины, терялось.
Как только увели трафик с этого пути,всё заработало.

Последняя проблема тоже органическая часть современных протоколов, не говоря уж о потерях пакетов как таковых. И даже новые протоколы, такие как QUIC, и всеобщее применение QoS (какая небылица) решить их фундаментально не позволят. Есть разной степени изящности решения, позволяющие обходить проблемные места, но всё это уже предмет архитектурных изысканий мощных сетевых инженеров.
Однако если вам хочется разобраться с маршрутизацией, работой протоколов TCP и UDP, использованием ping, traceroute, mtr, tcpdump, понять как выбираются пути и какие протоколы в этом помогают — мы тоже сможем помочь.
Мир сетевых технологий удивителен — в нём прогрессивные вещи, вроде SDN и прямой программируемостью структур в чипах коммутации сочетаются с чудовищным legacy времён рассвета информационных технологий. И если вы когда-либо страдали от необходимости поддержки обратной совместимости, просто подойдите к своему сетевому инженеру и попросите его рассказать, как трафик с вашего ноутбука добирается до серверов Яндекса или Amazon. У вас точно будет повод порадоваться тому, как хорошо вам живётся с вашими фреймворками и удивиться, как вообще что-то сегодня работает, учитывая снежный ком технологий для организации связи.
Любите IPv6!
Комментарии (54)


jingvar
00.00.0000 00:00А зачем вы так утрированно все описали? Вы же прекрасно знаете кучу существующих технологий в сетевом оборудовании которые решают определенные задачи, acl, dhcp snooping итд. Зачем гадания на кофейной гуще, сетевик должен знать как у него формируется путь из точки а в точку б, и какие технологии применены и какие эффекты могут принести. Rspan нет?

eucariot Автор
00.00.0000 00:00+1Я как раз приводил примеры проблем в сети, которые с виду простые, но локализовать их не так-то просто. Тут или нужны хорошие полные инструкции по диагностике, либо профессиональная интуиция.
И они требуют как раз знания инструментария.
Ну а без технических подробностей, потому что публикация рассчитана немного на другую аудиторию, и у меня есть места, где их как раз в достатке)
jingvar
00.00.0000 00:00Я вот эпизодически втыкаюсь на mtu, как же интересно взрываются приложения в случае mtu :)
Но тут вопрос разделения зон ответственности. Сейчас например, мое участие заканчивается снятием дампов с обоих сторон - вот пули вылетели вот такие прилетели, и форвард этого добра в сторону сетевиков.
eucariot Автор
00.00.0000 00:00+2О, дааа, MTU, однозначно, достоин лавров самой неведомой чертовщины!

zw_irk
00.00.0000 00:00+1Сразу видно, что не сетевик.
Вот, кстати, у серверника тоже куча существующих технологий, от логов до strace, и должен знать, какой процесс какие данные куда перекидывает....
и чё он там часами выясняет, почему у него загрузка под 100%, почему диски захлёбываются и какого чёрта политики частью ПК игнорируются. Как опять SCCM начал швырять софт через всю удалённым ПК, вместо использования регионального сервера.
zuek
00.00.0000 00:00Вот, я - не сетевик, скорее, серверник. strace мне как-то помог выяснить, что сервер 1С в Linux без настроенного обратного DNS не работает. С "потерявшимися сайтами" и раскатыванием обновления из хранилища за ~3500 км, вместо локального - тоже сталкивался, а вот почему диски захлёбываются - до сих пор не могу выяснить (вернее, выяснил - "кто-то" при построении отчётов активно использует временные таблицы, но вот кто это - осталось загадкой)...
А из непонятного в сетях - была как-то партия материнских плат, которые при "выключенном" компьютере время от времени начинали слать в сеть кучу пакетов, маркированных рандомными MAC-адресами, в итоге таблицы свитчей переполнялись и сеть "ложилась"; перезагрузка коммутаторов спасала минут на 15, после чего опять "опа!"... чуть меньшее зло - какие-то контроллеры СКУД попались с одинаковыми MAC-адресами, и когда объединили два соседних заводских корпуса, постоянно стал срабатывать RSTP, хотя при ручном контроле никаких петель выявить не удавалось...

MinimumLaw
00.00.0000 00:00+4Мир сетевых технологий удивителен — в нём прогрессивные вещи, вроде SDN и прямой программируемостью структур в чипах коммутации сочетаются с чудовищным legacy времён рассвета информационных технологий.
С верхних этажей небоскреба сложно разглядеть фундамент. Однако что, что вы так смело считаете "чудовищным legacy" на деле является надежным фундаментом. Для всего. Если опуститься вниз, то на медь влияют соседние кабели, грозы, силовая электроника, а на оптику даже смена дня и ночи (и тепловой расширение).
Впрочем, фраза о том, что "мир сетевых технологий удивителен" - она абсолютно правильная.
eucariot Автор
00.00.0000 00:00Под чудовищным legacy я тут подразумеваю такие штуки как Frame Relay, SDH, попытки синхронизации времени через IP-сеть или непосредственно Ethernet. NAT!
И это в некотором смысле добро, потому что всё, что поверх продолжает работать. Просто весь багаж техдолга вынесен на уровень фундамента :)

RMavrichev
00.00.0000 00:00Вот про синхронизацию времени не понял. IEEE 1588 разве уже не актуален?
eucariot Автор
00.00.0000 00:00Ну это же не единственный механизм. 1588 поддерживается не всем оборудованием. Поэтому у кого-то sync e как дешёвый эрзац.
Но даже 1588 - это попытка натянуть сову на глобус)

anarchomeritocrat
00.00.0000 00:00+6Могу привести краткий рецепт отказоустойчивой сети, где многое разрулено на L2 (дело было в 2008 году, так что вспомню не всё, но общую картину думаю обрисую)
В реальной сети (на момент внедрения 20к абонентов, при расчетной ёмкости до 16М абонентских подключений, которую после мы расширили ещё в разы) использовалось следующее оборудование:
коммутаторы последней мили LinkSys SPS 224G4
опорные пункты 802.1ad инкапсуляции пользовательских VLAN и в качестве ядра сети (терминирование 802.1ad + OSPF) Cisco ME 3400
Firewall + DMZ Cisco ASA 5500
в DMZ стойка с серваками под gentoo c vmware
Border не вспомню, но не суть - это уже другая история
Изначально идея топологии была такой: VLAN на пользователя, пользовательские вланы инкапсулируются в транспортные, от ядра кольца по опорникам, магистральные порты тегированы 802.1ad, от опорников кольца по абонентским свичам, магистральные порты тегированы 802.1q, везде на магистральных портах rSTP, на пользовательских DHCP Snooping + IP Source Guard + STP Root Guard + IGMP Snooping + терминирование пользовательских VLAN (в общем полная L2 изоляция абонентов)
Затем мы открыли для себя чудесную магию L2 DHCP Relay + Option 82, чем многократно увеличили теоретический предел ёмкости сети, то есть, если сперва мы выдавали сети на основе назначенного пользователю VLAN ID, то затем стали на основе MAC адреса свича и номера порта. У нас пользовательские вланы на порт остались только для корпоративных клиентов, для которых необходимо было организовывать L2 транспорт между удалёнными сегментами (2 офиса в разных концах города в одном бродкаст домене), все обычные домашние абоненты прекрасно помещались, по 256 /30 сетей в одном VLAN а изоляция, или наоборот разрешение маршрутизации (например по просьбам геймеров) клиентов достигалась за счет вышеописанных мер безопасности на порту и за счет ACL + OSPF в ядреВ такой конфигурации у нас ни разу не было ни одного шторма, а весь L3, вся фильтрация, маршрутизация, биллинг, шейпинг и тд были сосредоточены в ядре сети и DMZ. Да, это создавало на ядро ядрёную нагрузку, по этому у нас там было МЕ-шек с запасом, но я периодически пересекаюсь с техниками, текущими админами, от которых знаю, что покрытие и абонентская база разрослась в сотни раз, а сеть работает до сих пор как часы.

bukoka
00.00.0000 00:00+1RSTP на магистральных портах собранных в кольца? Если при Вас ни разу не сбойнуло - значит масштаб опорных колец сети был ОЧЕНЬ маленький. У RSTP есть такое понятие как diameter - и при более 7 коммутаторах в кольце уже могут начаться side-effects, которые либо пытаются полечить с помощью тюнинга таймеров STP, либо с помощью натягивания другого костыля - MSTP с "сегментацией" по регионам. Но потом поддерживать это очень сложно, да и опять - масштабируемость и скорость сходимости просто отвратительные.
Я как раз своими руками одну из таких "опорных сетей" провайдера переводил на IP/MPLS - потому что по мере роста она столкнулась с чудовищными бродкаст-штормами. Хотя, когда была "маленькой" - все работало "как часы" (за исключением того, что сходимость сети оставляла желать лучшего)
P.S: Единственное, что можно добавить - что я это "наследие" переделывал в 2016 году. Сама архитектура, видимо, закладывалась еще в 2008 году)
jingvar
00.00.0000 00:00А кольца может имело смысл собирать на erps? Там и собираются они меньше 50мс.
eucariot Автор
00.00.0000 00:00А кольца имело смысл собирать на L3 :)
Один из примеров в публикации - это ядро, собранное на кольцах под управлением RRPP - там одно неловкое движение и критический инцидент.
anarchomeritocrat
00.00.0000 00:00+1Вы что то путаете, диаметр 7 - это про STP, а не про rSTP, у которого максимальный диаметр 18, при том, что Cisco рекомендует использовать 10.
... и при более 7 коммутаторах в кольце...
Диаметр определяет расстояние от корневого коммутатора до самого дальнего коммутатора в кольце, без учета самого рута, а не общее количество коммутаторов, то есть при диаметре Dmax = 7 (STP), максимальное количество коммутаторов будет определено как Dmax * 2 + 1 = 15, при Dmax = 18 (rSTP), соответственно кольцо ограничено 37 устройствами, при рекомендациях Cisco для rSTP D = 10, рекомендованное количество = 21 коммутатор.
Мы посчитали, что с учетом резерва на расширение абонентской ёмкости кольца ну и, понятно, из соображений минимизации времени обновления таблиц MAC адресов, разумно будет ограничиться 16 коммутаторами (17, если считать рута, то есть сам опорник, соответственно решили отталкиваться от диаметра 8), хотя у нас было 2 сегмента сети по удалённым регионам, где в кольцах (на разных опорниках) было 28 и 32 коммутатора, но я, подготавливая сетевого инженера себе на замену, оставил ему четкие рекомендации докинуть туда ещё МЕ-шек и разделить эти кольца на меньшие, что он впоследствии добросовестно выполнил. Я более чем уверен, что при расширении сети, ребята не раз раздували кольца, всовывая туда свичей чуть ли не под лимит, для быстрого покрытия, просто затем докидывая МЕ 3400 и разбивая их на более мелкие. То же правило действовало и для опорников - по 16 штук в кольце от ядра.
bukoka
00.00.0000 00:00Про диаметр - я не перепутал, это рекомендации IEEE. Да, может быть до 20 устройств в кольце (циска и другие вендоры "вскользь" разрешают это на Ваш страх и риск - рекомендации я видел такие же, как и от IEEE).
Но 37 устройств и даже 20 в кольце Л2 - это безумно много - и вот почему: при прохождении каждого хопа BPDU от корневого коммутатора "перерождается" каждым коммутатором и он из поля max age вычитает единичку - а это поле по умолчанию равно 20. Если maxage=0, то далее BPDU не отправится - поэтому понятия не имею, как у Вас Висели гирлянды из 28 и 32 коммутаторах (разве что там был BPDU-туннелинг и сами устройства на магистральных портах не работали в rSTP).
Так же, чем больше устройств в плоской л2 топологии - тем выше риск коллизий хешей, сбоя протокола или неудачной настройки и т.п - все, что выше было описано в статье повторять это я не буду
И это мы еще с Вами не обсудили то, что часть канальной ёмкости теряется просто так из-за блокировки порта протоколом RSTP (хотя на уровне Л3 её можно было бы использовать).
anarchomeritocrat
00.00.0000 00:00Во первых читаем внимательно:
RSTP (IEEE 802.1w) natively includes most of the Cisco proprietary enhancements to the 802.1D spanning tree, such as BackboneFast, UplinkFast, and PortFast. RSTP can achieve much faster convergence in a properly configured network, sometimes in the order of a few hundred milliseconds. Classic 802.1D timers, such as forward delay and max_age, are only used as a backup and are not necessary if point-to-point links and edge ports are properly identified and set by the administrator. Also, the timers are not necessary if there is no interaction with legacy bridges.
Во вторых, при грамотной настройке edge ports, при 32 свитчах в кольце, получаем 2 ветки по 16 свитчей
Если вы сталкивались с проблемами на "legacy bridges" или использовали оборудование неведомого Китайского бренда, то возможно Вы и правы, однако у нас вся сеть была построена на Cisco и всё работает как часы
anarchomeritocrat
00.00.0000 00:00... В третьих, был инцидент, когда в кольце с 28 свичами, оборвало линк повалившимся деревом (на том сегменте пришлось тянуть по столбам, так как в частный сектор не было пути прокладки по ГТС), RSTP отработал как надо и в одной из веток получилось 26 свитчей (как Вы выразились, гирлянда), ни каких проблем не возникло - это реально факт из практики.
bukoka
00.00.0000 00:00Ок, читаем далее внимательно :)
"The RSTP Port Information state machine (...) checks that the BPDU’s Message Age is less its MaxAge, and if not, will immediately age out the received information."
Т.е сообщение пройдя 20 свитчей просто отбросится.
Настройка эдж портов тут вообще ни при чем - по умолчанию все фул-дуплекс порты рассматриваются RSTP как p2p.
Исследований на эту тему было проведено много - вот, например, одно из них - https://miau.my-x.hu/miau/94/rstp.pdf
Скажем прямо - этот протокол НЕ масштабируем в рамках SP и имеет медленную сходимость. В 2008 году это имело место быть в сетях SP, сейчас же, по моему скромному мнению - это моветон.
Но никого не призываю конечно ничего делать - пока есть такие сети, я точно не останусь без работы))
Про случай из практики - проблемы возникают как раз когда такая "гирлянда" начинает то пропускать BPDU, то нет (и это может быть по разным причинам) - вот тогда-то и начинаются "штормы". Возможно, конечно, что установка cisco вам помогла в части надежности пропуска сих замечательных фреймов, но это частный случай - до первого не циско устройства в кольце (не поддерживающего пропиетарного r-pvst т.е)

slavanikolsky
00.00.0000 00:00+1Отрасль ИТ от других отличает то, что в ней, обычно, от качества результата не зависит жизнь человека. Во всяком случае, напрямую.
Не соглашусь.
Банальный пример: Сетевой сервис по ошибке списал сумму денег за услугу, которую не оказал. Именно в этот момент начинает ухудшаться качество жизни человека.
человек потерял деньги
человек нервничает, что может повлиять на здоровье
-
тратит время на возврат своих денег
-
Еще пример: Через интернет человек, который имеет ограниченные возможности заказал лекарство от которого зависит его жизнь, но произошел системный сбой и привезли не то лекарство или вообще не привезли. В такие моменты и возникают вопросы зависимости жизни человека от IT.
Чем глубже интегрируется IT в общество, тем зависимее становится жизнь человека от IT.
«Мы в ответе за тех, кого приручили»
Лис, Маленький принц, Антуан де Сент-Экзюпери
eucariot Автор
00.00.0000 00:00Ну, согласитесь, это несколько натянутые примеры? Я говорю про смерть или вред здоровью как прямое следствие ошибок или проблем. Нельзя сравнить это с обрушением моста или врачебной ошибкой.
Пограничными на сегодняшний день являются медицина и автомобили, напичканные электроникой.

Exchan-ge
00.00.0000 00:00Ну, согласитесь, это несколько натянутые примеры?
Реал: некая электрокомпания решила сэкономить на сотрудниках, обходящих дома и сверяющих показания счетчиков с теми данными, которые эти счетчики автоматически передают в компанию.
Создали сайт, на котором пользователь сети самостоятельно вручную вводит показания своего счетчика.
Все ок и супер.
За исключением пустяка — если пользователь не обновляет через установленный интервал показания счетчика через свой личный кабинет — то ему автоматом начисляется предполагаемая сумма платежа (какой там алгоритм расчета, я не знаю)
И вот бабушке-божьему одуванчику внезапно приходит платежка с суммой платежа за э/э, достойной завзятого майнера… причину смерти не смогут установить ни полиция, ни родственники.
(по счастью, в реале смертей еще не было, но за сердце таки хватались)
Ну и в большом пролете те, кто надолго уехал из дома — сидят и гадают, что там: может квартиру взломали и там сейчас живут местные сквоттеры — проверить то показания удаленно нельзя, без посторонней помощи.eucariot Автор
00.00.0000 00:00Всё ещё далеко не прямая связь между причинами и следствием. Тут должны потрудиться тараканы в голове.
Так можно довести и до того, что производство унитазов - критическая отрасль, от которой зависит жизнь людей. Что если в нём плохо смывается содержимое - и год за годом точит психологическое здоровье владельца?


DGN
00.00.0000 00:00Застал материнские платы с одинаковыми mac адресами на сетевухах. Типа обновил комп, все летает кроме сети, она тупит страшно. Но у соседей вроде тоже тупит...
eucariot Автор
00.00.0000 00:00Да, бывало такое. И даже в масштабах ядра оператора сети, где не особо ожидаешь дублирования MAC'ов в отличие от сегмента клиентского оборудования.
И порой изменение MAC'а при вводе в эксплуатацию даже в инструкции по настройке прописывали)

Night_Snake
00.00.0000 00:00+1Ещё можно вспомнить прошивки "от Олега", естественно с одинаковыми маками. веселье начиналось сразу везде - и в биллинге (особенно если там какой-нибудь ip-mac-port-binding), и на l2

DaemonGloom
00.00.0000 00:00Одинаковые маки в прошивках Асусов "от Олега"? Вы, вероятно, путаете с какими-то другими прошивками.
Night_Snake
00.00.0000 00:00Возможно, это был не асус, как длинк (под них тоже полно кастомных прошивок было). Но ловили раз-два в год

nat_gtx
00.00.0000 00:00DIR-320 прошитый под Олега 100% мак слетает на некий дефолтный для этой прошивки =)

centralhardware2
00.00.0000 00:00-3Появилось желание использовать chatGPT для отфильтровывания безусловно интересной но не несущей полезную информацию стилистической оболочки

zw_irk
00.00.0000 00:00Отрасль ИТ от других отличает то, что в ней, обычно, от качества результата не зависит жизнь человека. Во всяком случае, напрямую
Знаменитый случай гибели нескольких человек, получивших смертельную дозу облучения во время сеансов радиационной терапии с применением медицинского ускорителя Therac-25.
На самом деле, очень сложно притянуть сбой ИТ к конкретным смертям. Сколько уже был массовых сбоев в госпиталях, когда вставали лаборатории, нарушался документоборот и, соответственно, замедлялось оказание медпомощи пациентам?
Или когда АСУТП колом встаёт и спасают "аналоговые технологии", своевременно останавливающие техпроцесс.
Кстати, что касается Therac-25 - предыдущая модель тоже имела эти ошибки, но там были "аналоговые" датчики, которые останавливали установку при возникающей угрозе пациенту. В 25 - их убрали.

maxalion
00.00.0000 00:00+2Большое спасибо за примеры с bash скриптами! Отличная идея, как быстро организовать перебор портов при проверке и выдавать данные о доступности через AND/OR. Век живи - век учись:)
jorektheglitch
00.00.0000 00:00новый эфемерный src port из диапазона
1024-6535У вас тут пятёрочка потерялась

Tarakanator
00.00.0000 00:00Есть только одна причина, растягивать L2: вам чересчур спокойно живётся и хорошо спится и руководство разделяет вашу тоску.
1)Не прокидывать несколько L3, если нужно несколько протоколов.(привет ipx)
2)А что если софт не умеет в L3? На практике не сталкивался, но сталкивался к примеру с тем, что софт не умеет выбирать нужный IP(если у устройства 2 IP адреса). Подозреваю L3 может не уметь что-то типа потоковой трансляции steam.bukoka
00.00.0000 00:00Так если есть конкретная задача, почему надо прокидывать - прокидывайте Л2 на здоровье. Описанные в статье слова не стоит возводить в абсолют :)
В статье речь скорей о том, что стоит уходить от архитектурных паттернов с "растягиванием" широковещательных доменов, когда того явно не требуется.
Aquahawk
Я тут дома играюсь с построением отказоустойчивой сетевой инфраструктуры для сети устройств умного дома, так я отказался от dhcp как от единой точки отказа. Шанс что после выключения света dhcp сервер не проснётся гораздо больше чем то, что не проснётся тупой свитч.
JohnSelfiedarum
Так делайте DHCP на свиче, это же очевидно
0xdead926e
а потом в сети появляется стремная железка со стремным ethernet-контроллером от не менее стремной конторы synopsys. их gmac где только не встречается...
и вот иногда он может быть не то криво сконфигурирован при синтезе, или еще что-нибудь случиться, но как только закончится dhcp lease (и ос сходит на dhcp-сервер за новым)- железка с этим контроллером просто перестанет отвечать даже на пинги. при этом с самой железки tcp-коннекты поднимаются и работают.
а потом захочется воткнуть в usb ему другую сетевуху- а usb-то тоже от synopsys. dwc_usb. те, кто пробовал его попрогать на расте в микроконтроллерах- поймут xD
(он проваливается в stall, если процессор слишком медленно работает. или сборка дебажная (и поэтому достаточно медленная))
извините, я опять трогала стремные платы. а вон та проблема с гмаком лечится установкой этой железке статического адреса и ни в коем случае не использования конкретно на ней dhcp.
chaynick
Ну давайте посмотрим что у вас происходит в сети. Ваш умный дом связывается с другим устройством по IP, допустим вы добились огромной отказоустойчивости отказавшись от DHCP. Во-первых у вас идет общение по какому-то протоколу из набора 802.3 или 802.11 который тоже может отказать. Причем в них заложен механизм CSMA/CD (CSMA/CA) который вообще создан для нарушения передачи данных а 802.3af и аналоги еще при сбое могут и выжечь сетевой порт. Нужно от него избавится. Дальше избавьтесь от 802.1d и аналогов которые сейчас даже в домашних роутерах встречаются - он тоже умеет блокировать работу портов, бродкастовый шторм менее опасен - хоть какие-то данные при нем будут ходить. Дальше на очереди arp - если он сбойнет - то все, никакая связь работать не будет. Для отказоустойчивости рекомендую заполнять arp таблицы статикой. Для пущей надежности работы сети еще хорошо inarp заполнять статикой. Следом если он стучится в интернет у нас как бы DNS - я напоминаю что для работы с ним используется и UDP и TCP, смотрите чтобы ваш домашний роутер не запутался от этого! Нужно избавится от этого!! Переделайте прошивки! Ну и собственно UDP ненадежен и не имеет подтверждения - его бы хорошо бы из стэка вообще выпилить. Но это еще не все! У вас там еще маршрутизация, а это возможность отправить пакет не туда куда надо, тоже ненадежно! Лично видел отказ ядра маршрутизации включая статику на чекпоинтах R81.10 при включенной опции ptp в OSPF. Избавляйтесь, что-нибудь придайте вместо этого. И вишенка на торте - у вас там еще маршрутизатор который ПЕРЕПИСЫВАЕТ каждый пересылаемый сетевой пакет, понимаете насколько это ненадежно и недоверенно? А если он ошибется? А уже с криптографией вообще трэш творится, это намеренная порча пересылаемых данных чтобы они при перезаписи стали как белый шум! Намеренная, понимаете?!
А если серьезно - забудьте вообще о отказоустойчивости в домашних условиях. Особенно с мнением что отключение DHCP хоть как-то повышает отказоустойчивость домашних устройств подключенных одним сетевым проводом и/или в перегруженном радиоэфире. И да, тупой свич за 1,5 тыс рублей по надежности проиграет даже 15-ти летнему 2950, несмотря на все умные фишки последнего.
Lirein
Поздравляю, вы только что изобрели Powerlink :)
А если серьёзно, то у B&R только коммутаторы, сетевой адрес задается аппаратным переключателем, и очередью передачи пакетов заведует ПЛК (Этакий CSMA/CA в Full Managed режиме). В качастве канального протокола - Ethernet на стероидах, то есть промышленный Powerlink, с таймингами доставки пакета и вообще очень интересный внутри протокол.
kmeaw
А почему именно "тупой свич за 1,5 тыс рублей по надежности проиграет даже 15-ти летнему 2950"?
chaynick
Потому что цена подсказывает экономию на компонентах. Ну и все-таки опыт в проектировании железа тоже что-то значит, ну немного так, не находите? И когда дядюшка Ляо производит скажем маршрутизатор с типа 802.11ac и 100 Мбит портами (лично видел) - я не думаю что такие люди в принципе о чем-то думают при проектировании.
kmeaw
А можно ещё более конкретно? Мне пока в голову приходит только очень дешёвая схема питания, которая может негативно влиять на надёжность свитча за полторы тысячи.
С опытом проектирования железа тоже не всё очевидно - за 15 лет больше людей-непрофессионалов стало сталкиваться с железом (Arduino и другие подобные платформы набирают популярность) и получать связанные с этим знания, хорошие решения стали становиться массовыми и дешёвыми из-за упаковки их в одну микросхему или модуль, CAD-софт стал больше уметь делать автоматически.
Я никогда видел разобранного Catalyst, но дешёвых китайских свитчей разобрал некоторое количество, и там внутри почти ничего нет - трансформаторы (а иногда даже их нет, и стоят MagJack), линейный стабилизатор, генератор, десяток пассивных компонентов и одна микросхема, которая делает всё. Какие компоненты и решения, использованные в Catalyst 2950 делают его более надёжным?
eucariot Автор
Где реализована коммутация/маршрутизация/ACL - в железе или на CPU
Вероятность битовых ошибок и их исправление
Отказоустойчивость компонентов
Качество питания и устойчивость к скачкам в сети
Глубина и качество тестирования ПО, отвечающего за Control Plane
То же, но про взаимодействие с SDK чипа, реализующего программирование правил в железо.
Возможность обновления ПО (неактуально, правда, для старых коробок)
Tarakanator
Ну почему. Если mimo у клиента нет, и ширина канала 20мгц, то теоретическая максимальная скорость около 100мегабит грязными.
из них чистыми около 80 мегабит в многопоточной нагрузке при идеальных условиях.
в однопоточном режиме в идеальных условиях вы получите уже чуть более 50 мегабит.
Так что железка хоть и странная, но не бесполезная.
Или вот вам реальный кейс.
Дача. интернет через вышку ДО 40 мегабит.
витуху тянуть лениво, но локалку хочется побыстрее чтоб была.
Итого максимально быстрый Wi-fi требуется, а между точкой доступа и модемом может быть и кабель на 100 мегабит.