
Service Mesh входит в перечень стандартных для бэкенда технологий, а недавно и вовсе был на вершине хайпа. Вы решаете идти в ногу со временем и добавить в свой кластер Kubernetes первый Service Mesh. От друзей слышите, что Istio требует много памяти, а прокси в Linkerd очень быстрые, хотя никто не проверял. А еще все почему‑то говорят про Cillium, хотя это CNI‑плагин. Обсудим, что к чему.
Меня зовут Максим Чудновский, я занимаюсь развитием интеграционной платформы Synapse в СберТехе. Она имеет поддержку всех возможных стилей интеграции: RPC, файловые, шаблоны в Event Driven architecture. Есть в ней и RPC, а соответственно и Service Mesh, которым я и занимаюсь. Поэтому сегодня поговорим именно о нем.

Что такое Service Mesh?
Service Mesh — достаточно простой интеграционный паттерн для обеспечения механизмов сетевой упругости, повышения безопасности и обозреваемости приложений. Чаще всего Service Mesh используют в облачных инфраструктурах, то есть в контейнерах и Kubernetes.

Концептуальный Service Mesh состоит из двух частей.
Первая часть — Control Plane. Отвечает за назначение и распространение политик маршрутизации трафика, артефакты, безопасности, токены, ключи, сертификаты. А еще за сбор телеметрии и интеграцию с внешней инфраструктурой. Чаще всего это PKI, журналирование, мониторинг и т. д.

Вторая часть — это Data Plane. Размещается непосредственно с приложениями и занимается очень простым делом: исполняет политики, которые получает от Control Plane. Соответственно, Data Plane — это чаще всего сетевые прокси, которые отвечают за маршрутизацию и балансировку трафика в нагруженной среде. Также Data Plane выполняет аутентификацию, авторизацию всех вызовов, формирует спаны для распределенной трассировки и метрики для того, чтобы повысить уровень обозреваемости микросервисных систем.

Классификация
Решений Service Mesh появилось очень много. На первый взгляд, они все делают одно и то же. Попробуем разобраться, в каких нюансах реализации Service Mesh могут различаться.
Cotrol Plane
Компонентный состав (Type)
С функциональной точки зрения Control Plane очень хорошо декомпозируется, поэтому компонентный состав, как не трудно догадаться, может быть микросервисным. Например, если есть работа с сертификатами, можно создать certification registration authority. А если мы работаем в Kubernetes и хотим автоматически добавить всем рабочим нагрузкам Data Plane Proxy в виде sidecar‑контейнеров, то создаем компонент mutation webhook server и используем механизм Admission Controllers.
Однако в противовес этому есть и другой подход — монолитный, когда все эти функции объединяются в рамках одного daemon, который бежит где‑то в кластере и занимается полезными делами Service Mesh. Этот daemon простой, его удобно сопровождать. С ним все становится гораздо проще.
API
С точки зрения API Control Plane может быть проприетарным. Это история, когда разработчики делают определенный API, чтобы управлять функциональностью своего Service Mesh, и живут с ним в дальнейшем. Он может выглядеть так:

Следующий вариант — это Gateway API. Он пришел из сообщества ванильного Kubernetes и изначально отвечал за ingress трафик. Решение заключалось в том, чтобы разделить зону ответственности между инфраструктурными командами, отвечающими за ingress‑класс, и пользователем, который только использует ingress‑контроллер. Последнему нужно просто сделать какой‑нибудь HTTP route и завести трафик на свой workload в кластере.
Как оказалось, Gateway API очень хорошо подходит для управления HTTP трафиком. Соответственно, во многих реализациях Service Mesh это нашло применение. Вот пример:

И последний доступный вариант API — это Service Mesh Interface (SMI).

Это open source спецификация, которая претендует на звание стандарта по управлению Service Mesh. На текущий момент SMI и Gateway API двигаются в сторону объединения. Скорее всего, в будущем мы увидим уже обобщенную спецификацию, которая будет включать лучшие практики из обоих решений.
Если подвести итог, то один из этих вариантов так или иначе можно встретить в любом Service Mesh. При этом возможны и комбинации — мы рассмотрим такой пример в дальнейшем.
Data Plane
Компонентный состав (Type)
Самый распространенный тип Data Plane — это вариант, который построен на sidecar‑контейнерах. Конструкция простая: рядом с контейнером приложения добавляется еще один, в котором размещается сетевой прокси. При этом правила маршрутизации сетевого трафика в рамках пода настраиваются таким образом, чтобы все запросы проходили через sidecar‑контейнер, который в свою очередь занимается сетевым процессингом на уровнях L4 и L7.

Следующий вариант — это Node Daemon.
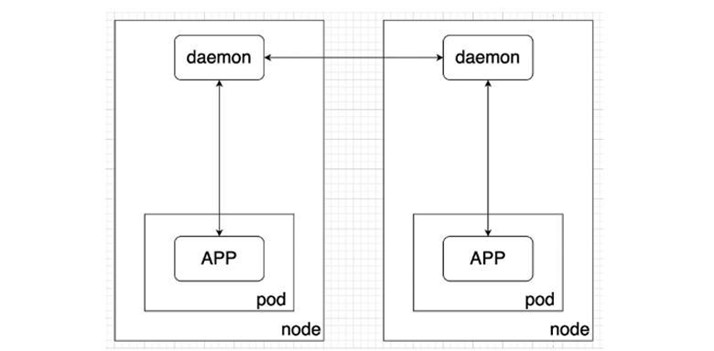
Его идея в том, чтобы у вашего пода в кластере не было больше sidecar‑контейнеров с прокси. Они опускаются на уровень ниже, то есть к вычислительным узлам Kubernetes. И там уже переиспользуются между всеми рабочими нагрузками — подами, которые запущены на данном узле. Это помогает экономить вычислительные ресурсы кластера, потому что требуется гораздо меньше экземпляров сетевого прокси.
И ещё один вариант — Proxyless.

Его идея совсем простая: отказаться от сетевых прокси, демонов и дополнительных контейнеров, и вернуть всю сетевую функциональность на уровень приложения, как было принято в 2010 году.
Подход хороший, за исключением того, что он нивелирует многие плюсы Service Mesh, в частности его неинвазивное подключение. Поэтому этот вариант чаще всего применяется с одновременным встраиванием поддержки Service Mesh в тот фреймворк, который используется для сетевых взаимодействий.
Так, например, сделано в GRPC, где можно в пару кликов сделать так, чтобы GRPC сервис поддерживал всю функциональность Data Plane и мог подключиться к какому‑нибудь Control Plane без лишних сложностей. Соответственно, это снижает сетевые задержки и потребление ресурсов. Однако лишает гибкости в плане подключения и обновления платформенных функций, свойстсвенной более традиционным вариантам Service Mesh.
API
С точки зрения API есть протокол xDS.

Он возник как протокол динамической маршрутизации из проекта Envoy Proxy. XDS хорошо структурирован, понятен и отвечает сразу за множество аспектов работы прокси: за Service Discovery, правила маршрутизации и работу с секретами. Также он полностью отвечает за конфигурацию бэкенда и тех endpoint»ов, которые будут обслуживать этот бэкенд. В частности, xDS отвечает на следующие вопросы:
Как будет распределяться трафик по весам?
Какие будут приоритеты?
Какая зональность будет у endpoint»ов?
Как будет переключаться трафик в случае недоступности отдельных экземпляров бэкенда?
Так сложилось, что xDS получил широкое распространение вместе c проектом Envoy Proxy. Относительно его популярности в сообществе он стал де‑факто стандартом API для Data Plane в Service Mesh.
Но все же часть людей не использует xDS. И тут альтернативой выступает проприетарный API, например NGINX Plus API.
Traffic Capture
Как мы помним, Data Plane забирает на себя сетевой трафик и осуществляет L4, L7 процессинг. Но как именно Service Mesh настраивает правила для перенаправления сетевого трафика?
Он может это сделать в рамках пода, сразу запуская скрипты редиректа как часть рабочей нагрузки. Чаще всего это реализуется с помощью дополнительного init‑контейнера. В итоге настраивается оверлейная сеть на рабочем узле Kubernetes, чтобы в рамках нашего пода весь сетевой трафик перенаправлялся на sidecar‑контейнер с сетевым прокси из состава Data Plane.

При этом никаких дополнительных компонентов не требуется. В целом это отличная схема. Единственный минус — нужно выдать полномочия NET_RAW и NET_ADMIN для настройки правил Iptables, с помощью которых осуществляется перенаправление трафика внутри пода. А они выдаются не только для init‑контейнера, но и на весь service account, под которым запускается под.
Таким образом application‑контейнер также получает эти полномочия, хотя они ему абсолютно не нужны. Это нарушает правило минимальных привилегий, важное для сред со строгими ограничениями по информационной безопасности.
Другой подход — это Node Level.

В рамках пода запускаются только два контейнера — application и proxy в случае data plane, построенного на sidecar, — внутри которых никакого перенаправления трафика не происходит. Но в кластере есть некоторый Service Mesh CNI Daemon, который делает это за них, используя механизм CNI‑плагинов.
Устроено это так: основной СNI‑плагин инициализирует и исполняет непосредственно оверлейную сеть Kubernetes. А дополнительные плагины могут сделать еще что‑нибудь полезное. Тут в игру вступает наш CNI‑плагин в составе Service Mesh, который в момент инициализации сетевого стека на вашем поде настраивает правила перенаправления трафика.
Для того, чтобы это сработало Service Mesh CNI Daemon раскладывает CNI‑плагин в нужный каталог на всех воркерах, где будут запускаться поды, подключаемые к Service Mesh. При этом этот daemon иногда еще решает вопросы с гонками при старте подов из‑за автоматического кластерного масштабирования.
Вместо итога
Мы рассмотрели основные решения и нюансы реализации Service Mesh, изучили типы Data Plane и Control Plane. С теорией все ясно — осталось посмотреть, как это будет работать на практике.
В следующей статье рассмотрим, как наша классификация накладывается на реальную жизнь и работает в конкретных Service Mesh. Как устроен Platform V Synapse Service Mesh от СберТеха и на что в целом стоит обратить внимание, выбирая оптимальный инструмент для своих задач.
nkretov
Годная компиляция, спасибо!