
Service Mesh — подход, который еще вчера был на вершине хайпа, а сегодня становится стандартной технологией для Backend. В этой части посмотрим, как теория накладывается на практику и на что обратить внимание, выбирая Service Mesh для своих задач.
Меня зовут Максим Чудновский, я занимаюсь развитием интеграционной платформы Platform V Synapse в СберТехе. В платформе реализован RPC и Service Mesh, которым я и занимаюсь. В этой статье продолжу рассказывать о технологии и поделюсь соображением о том, как выбрать конкретное решение для ваших задач.
Service Mesh — примеры реализации
В прошлой статье мы получили пять пунктов, по которым можно классифицировать любой Service Mesh:
Компонентный состав Control Plane
Control Plane API
Компонентный состав Data Plane
Data Plane API
Data Plane Traffic Capture
К ним можно также добавить и шестой пункт — extensions (расширения).
В итоге можно создать табличку, чтобы быстро проверять конкретные реализации Service Mesh на предмет соответствия конкретным требованиям. Сработает ли такой подход, или наш список — просто набор из умозрительных пунктов, которые никак не стыкуются с реальным миром? Проверим на реальных решениях, которые можно найти в open source.
Istio
Первый и, наверное, самый популярный Service Mesh — Istio.
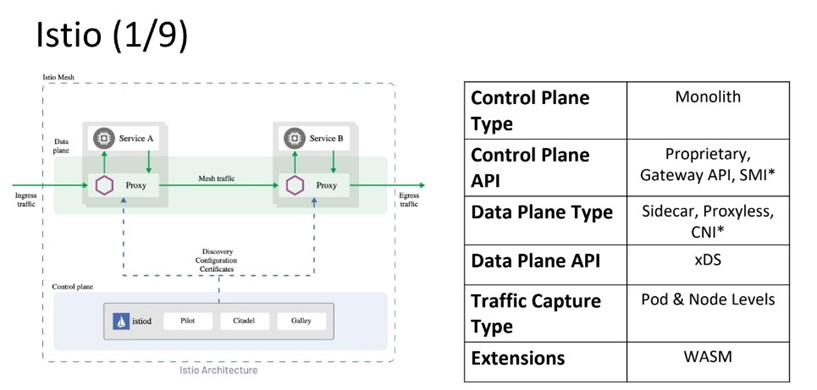
Сейчас у него монолитный Control Plane. Но так было не всегда: на старте Control Plane был микросервисным.
С точки зрения Control Plane API Istio поддерживает все три варианта: проприетарный, gateway и smi-specification. Правда SMI поддерживается только через специальные адаптеры.
В плане компонентного состава Data Plana в Istio можно использовать sidecar-контейнеры либо подход proxyless и подключать, например, gRPC напрямую. Дополнительно есть опция Istio Ambient Mesh. Там L4 и L7 процессинг разделяется на разные вычислительные компоненты. Таким образом, появляются отдельные daemon для тонелирования, и общее количество сетевых прокси снижается. Интересное решение, но оно находится в альфе и пока не рекомендуется к применению в промышленной среде.
Data Plane API использует xDS, потому что в Istio используется Envoy Proxy. Перехват трафика может быть как внутри пода, так и непосредственно на вычислительном узле Kubernetes. Поддерживаются оба варианта.
Расширения реализованы через поддержку WebAssembly, причем есть API, который позволяет это нормально использовать. Достаточно сказать: хочу такой WASM модуль, и можно забрать его сразу в docker-registry, сложить в кэш и исполнять на прокси. Это удобно.
Linkerd
Второй распространенный Service Mesh — это Linkerd.

Control Plane имеет архитектуру микросервисов. Причем эти микросервисы четко ограничены своими функциональными доменами. Они даже называются незамысловато. Например, микросервис «identity» работает с identity, «destination» отвечает за service discovery. Также есть proxy-injector, который используется для добавления sidecar-контейнеров с прокси.
С точки зрения Control Plane API можно использовать SMI или проприетарный API, который предлагается авторами этого Service Mesh. Поддержки Gateway API тут пока нет.
В рамках Data Plane доступны только sidecar-контейнеры – в Linkerd в качестве сетевых прокси используется специальный прокси, который так и называется — Linkerd proxy. И он используется только в Linkerd. Этот прокси действительно очень эффективен в плане потребления ресурсов и скорости работы, однако из-за проприетарного API в случае проблем сложно понять, какая конфигурация сейчас активна в конкретном прокси. Дебажить это непросто, а за счет не самого широкого распространения в open source community появление новых фичей или исправление непопулярных багов может затянуться.
С точки зрения перехвата трафика все стандартно. Можно делать на уровне пода через init-контейнеры или на уровне узла через CNI-плагин.
Kuma

Kuma — опенсорсный продукт, который построен на базе Envoy, поэтому в нем можно увидеть те же самые sidecar-контейнеры и тот же самый протокол xDS для Data Plane.
Kuma имеет монолитный Control Plane: это один daemon, который работает в отдельном namespace Kubernetes и всем заправляет. Там же есть встроенный UI. Что интересно, Kuma умеет хранить состояние service discovery по-разному: это не только etcd и kube-api, но и любое совместимое внешнее хранилище. Например, авторы предлагают использовать PostgreSQL. Это может быть очень полезно для мультикластерной системы, которой нужен кросс-кластерный service discovery.
Nginx

Nginx занимался обработкой сетевого трафика задолго до того, как все стали говорить про Service Mesh. И было бы странно, если бы базе этого проекта не появился собственный Nginx Service Mesh.
Control Plane микросервисный. Устроен стандартно: есть Service Discovery, а также отдельные компоненты для работы с сертификатами и реализации паттернов observability. Построено это все только на sidecar-контейнерах. Причем в качестве прокси понятно, что используется сам Nginx. Data Plane API проприетарный – nginx’овский. Перехват трафика только на уровне подов. И расширения не поддерживаются.
В целом, можно сказать, что Nginx Service Mesh — это очень ранняя реализация паттерна Service Mesh в плане архитектуры и дизайна.
Cilium Service Mesh
Изначально, Cilium — это реализация управляемой сети, CNI-плагин, который использует eBPF. Но ребята пошли дальше и сделали Сilium Service Mesh. Что в нем интересного?

Как такового перенаправления сетевого трафика больше не требуется, потому что data plane спускается на уровень оверлейной сети. Получается, что CNI-плагин, который отвечает за реализацию этой сети, сразу же начинает отвечать и за реализацию Service Mesh, забирая на себя L4 процессинг. Однако, L7 процессинг сделать сложнее. Поэтому в Cilium Service Mesh используются и сетевые прокси. Это известные нам Envoy, которые размещаются по модели Node Daemon.
С точки зрения Control Plane, API проприетарный, потому что он тоже делится на две части. Первая часть — это network policy Kubernetes, вторая — network policy, который расширяет Cilium. Таким образом, можно настраивать L4. А вот с L7 ситуация интересная: в Cilium’е не стали мудрить с разработкой собственного API и стали использовать xDS напрямую, как это есть в Envoy. Они сделали CRD, который так и называется — Envoy API. Это дает максимальную гибкость.
Consul
До эпохи Service Mesh Consul был известен как Service Discovery. Тут все логично: если есть Service Discovery, то и Consul Service Mesh не за горами.

Его Control Plane API проприетарный, но используется и smi-spec, что добавляет стандартизацию. Сам Data Plane построен на sidecar-контейнерах, а в качестве прокси используется Envoy. Cоответственно Data Plane API - xDS. Перехват трафика реализуется только на уровне подов через init-контейнеры. При этом нет расширений для прокси, потому что проприетарный API не поддерживает их, как и SMI.
Есть интересная архитектурная особенность. Несмотря на то, что перехват трафика в Consul Mesh сделан на уровне подов, на уровне воркера Kubernetes все равно есть daemon, который, однако, отвечает уже не за конфигурирование сетевого стека, а за работу с Consul Service Discovery.
Open Service Mesh
Open Service Mesh — открытый Service Mesh. В качестве Control Plane используется Go Control Plane. Это такой референсный проект для организации Control Plane и Service Discovery для Service Mesh.

В качестве Data Plane используется Envoy прокси с поддержкой xDS, то есть фактически стандарт. Open Service Mesh потому и open, что во всех его частях используется открытые решения, получившие широкое распространение в сообществе.
Что касается Control Plane API, поддерживается только SMI. Перехват трафика осуществляется исключительно на уровне pod’ов через init-контейнеры с выдачей повышенных сетевых привилегий пользовательским рабочим нагрузкам, а расширения нативно не поддерживаются
Traefic

Traefic интересен тем, что это, наверное, один из первых Service Mesh, построенных на базе Data Plane с архитектурой Node daemon. Согласно изначальной конструкции Envoy прокси размещается один раз на узле Kubernetes и обрабатывает весь сетевой трафик.
Control Plane — микросервисный. С точки зрения API поддерживается только стандарт SMI. Соответственно, расширения на Envoy будут недоступны. Traffic Capture реализуется на уровне Node, поэтому поды не содержат sidecar-контейнеров.
Platform V Synapse Service Mesh
Platform V Synapse — это российский Service Mesh от СберТеха. Это промышленный продукт, который отвечает повышенным требованиям корпораций в сфере безопасности, надежности и производительности. Идея разработки отсылает к Istio, с которым Platform V Synapseполностью совместим по API и имеет те же самые функциональные особенности за некоторыми исключениями.

Control Plane в этом Service Mesh микросервисный. Это позволяет расширять функциональность поверх Istio, не отходя далеко от кодовой базы, без необходимости делать жесткое ответвление (hard fork).
Но какие расширения могут потребоваться?
Например, если у вас большой Service Mesh (десятки тысяч подов), то Control Plane будет весьма нагруженным, а Data Plane – ресурсоемким. Поэтому помимо стандартного xDS протокола, которым управляется Data Plane, в Platform V Synapse Service Mesh есть поддержка ленивого xDS. Он позволяет использовать не полную xDS конфигурацию, а только ту, которая нужна в текущий момент. Остальное подгружается потом, если потребуется.
Больше информации о Platform V Synapse можно найти здесь.
Как выбирать?
Теперь мы знаем, как классифицировать Service Mesh и какие основные решения существуют. Но, чтобы выбирать между ними, нужно как-то их оценивать.
Итак, какие проблемы можно встретить в своем Service Mesh Journey?
Масштабирование
Количество кластеров
В начале нужно разобраться с масштабированием кластеров: сколько у вас будет кластеров, и что вы хотите с ними делать. Нужны ли большие кластеры с гигантским Service Mesh, который будет растянут сразу на несколько единиц, или больше подходит много маленьких независимых друг от друга кластеров с минимальным пересечением для того, чтобы прокинуть мостик между несколькими сервисами?
Ответив на эти вопросы, нужно посмотреть на архитектуру Control Plane и расширения для Service Mesh. Потому что в сложной мультикластерной инсталляции любой Service Mesh потребует от вас непростых решений. Например, как сделать мультикластерную телеметрию или удобный API для создания мультикластерных сервисов? Нужен ли failover между кластерами, если эти кластеры зональные? Когда вы начнете отвечать на все эти вопросы, поймете, что стандартного функционала все равно не хватает и нужно расширяться.
Размеры кластеров
Масштабирование каждого отдельного кластера Kubernetes — это целая история. Как минимум потому, что у кластера есть много разных разрезов: ноды, поды, сервисы и т.д.
С точки зрения Service Mesh тут необходимо обращать внимание на компонентный состав Data Plane, потому что, например, Data Plane на sidecars стоит 10х, а Data Plane по модели Node daemon — только 1х. Это колоссальная экономия, но есть и минусы.
Взаимное влияние
Разные команды используют один кластер и иногда что-то идет не так — и к этому абстрактному ЧП система должна быть устойчива. Радиус поражения может быть разный, в зависимости от того, произошла ли компрометация секретов service account или, например, злоумышленник проник в application контейнер целиком. Также важен вопрос тенантирования – проблемное приложение вроде бы живет в другом namespace Kubernetes, однако может запуститься на том же узле и использовать тот же сетевой прокси, что и вы.
Именно поэтому важно смотреть на компонентный состав Data Plane и это хорошо иллюстрирует подход Node Daemon. Как мы убедились раньше, он экономит много ресурсов, но при этом приносит множество других вопросов, особенно в плане безопасности. С учетом того, что абсолютного тенантирования в L7 процессинге на прокси практически не добиться, бласт-радиус серьезно увеличивается. В этом контексте и Trafic Capture тоже нужно учитывать. Если вы делаете редирект на уровне подов, зона поражения — pod. Если живете на узлах, бласт-радиус — весь узел kubernetes.
Сложности эксплуатации
Конфигурирование
Конфигурация Service Mesh всегда была непростой. В некоторых случаях это сотни (если не тысячи) YAML-файлов, которые при этом еще нужно написать. Поэтому стали появляться проприетарные API, которые пытались (и пытаются) решить эту проблему.
Например, Service Mesh Interface Spec — простая спецификация. Там очень понятные правила, в частности для управления трафиком. Но в этом и есть неоднозначность — SMI настолько простая спецификация, что хитрые кейсы маршрутизации не покрывает, либо требует сложных конфигурационных решений. Таким образом, нужно искать баланс и подбирать нужный Control Plane API.
Возможна и обратная ситуация — вы получите API, который решает любой кейс маршрутизации, но глубокая вариативность введет пользователей Service Mesh в сильное непонимание и повлечет шквал ошибок. Большой вопрос, нужно ли это, если 99% из них просто добавляют таймаут соединения к стандартному маршруту трафика? Может быть, и нет.
Сила общества
Сила общества — это extensions. Чем больше сила сообщества, тем больше issues, плагинов и, соответственно, вероятности того, что ваш кейс уже кем-то решен. У всех решений Service Mesh сообщества разные, и это важно иметь в виду.
Поддержка открытых стандартов
Всегда полезно знать понимать, что идет «по проводам» внутри нашей системы. В противном случае при нештатной ситуации в эксплуатации сложно понять, что именно происходит, особенно если используется проприетарный API. В некоторых случаях это вообще невозможно, сколько ни настраивай мониторинг и ни собирай метрики.
Однако если стандарт открыт, вы всегда можете посмотреть структуру и понять, что происходит. Кроме того, если самостоятельно решить проблему не получается, можно найти людей, которые понимают, что происходит. Это стоит учитывать при выборе Control Plane и Data Plane APIs.
Итоги
Мы разобрали все архитектурные стили, которые так или иначе применяются в cloud native community для реализации паттерна Service Mesh. Есть множество хороших решений, но все они сделаны по-разному и попадают в разные требования. Поэтому важно выбирать инструмент и подход, которые полностью будут отвечать вашим запросам.