
Привет! Меня зовут Михаил Благов, я руководитель департамента «Чаптер инженеров данных и разработчиков» в beeline tech. В этом посте я хочу поделиться способом, с помощью которого можно выбрать подходящую архитектуру для конвейера данных в зависимости от требований к нему. В частности, обсудим паттерн CDC (change data capture, aka «захват изменений»), основная идея которого — быстрая репликация какого-то источника в аналитическое хранилище.
Под катом мы:
познакомимся с вариантами архитектуры конвейеров данных: из каких компонентов и как его можно собирать,
рассмотрим и сравним четыре разные архитектуры конвейеров.
Disclaimer: серебряной пули не будет, в этой статье я поделюсь опытом выбора архитектуры для решения конкретной задачи. Аналогичный выбор для других случаев потребует дополнительных исследований и замеров производительности.
Начнем с матчасти
Помните главные отличия OLAP и OLTP?
OLTP — Online Transaction Processing тип нагрузки на базу данных, при котором требуется быстро обрабатывать insert’ы, update’ы, delete’ы, но точечно, по одной записи. Для работы с таким типом нагрузки предназначено большинство реляционных баз данных, таких как PostgreSQL, Oracle, MsSQL и др.
OLAP — Online Analytical Processing, аналитический тип нагрузки, характеризующийся чтением значительной доли данных в таблице для формирования метрик. Это запросы вида «Я хочу посчитать количество с группировкой по чему-нибудь», «Я хочу посчитать среднее значение числовой колонки» и прочие. С такой нагрузкой плохо справляются обычные реляционные СУБД, и их обычно заменяют на колоночные СУБД, например, Clickhouse, или специальные распределённые системы хранения данных, такие как Hadoop с его специальными форматами хранения данных.
У систем хранения данных, оптимизированных под OLAP-нагрузку, есть специфика — обновления и удаления либо не работают вообще, либо работают очень медленно.
Теперь представьте себе ситуацию, когда у компании есть хорошо работающий продукт, использующий классическую OLTP базу данных. В какой-то момент руководителю компании потребуется принимать решения о его дальнейшем развитии и позиционировании. Мудрый руководитель принимает решения, основываясь на данных, и поэтому перед внедрением глобальных изменений нанимает дата-аналитика и просит проанализировать работу продукта. Возникает необходимость делать одновременно и быструю обработку транзакций, и существенную аналитику по ним (OLAP-запросы).
Что произойдёт с продуктивной базой, если впустить туда дата-аналитиков? Она будет работать медленно для обоих типов нагрузки.
Что же делать, если на проекте требуется делать одновременно и быструю обработку транзакций, и существенную аналитику по ним? А если ещё и во времени, близком к реальному? Ответ обычно следует из принципа разделения обязанностей. Пусть продуктивная база отвечает за продуктивную нагрузку, а её копия – за аналитическую. А если ещё эту копию сделать на OLAP-системе… В этот момент возникает необходимость содержать оба типа СУБД и строить конвейеры данных, эффективно перемещающие информацию из одной в другую.
Выглядит это просто:

В чем же здесь проблема? В том, как реализовать блок, отвечающий за перемещение данных, или, по-другому, репликацию. Обычно начинают с простых решений. Например, можно копировать все данные каждый день и говорить: «Окей, у нас время доставки T-1 день». Или каждый час. Тогда «свежесть» данных для аналитики уже существенно повышается. Для многих типов отчетности этого достаточно (например, для построения ежемесячных или ежеквартальных отчетов, сверок счетов и т. п.). Это вполне себе рабочий подход, если данных не очень много, а нужны они не срочно.

Но есть и недостатки. Если данных достаточно много или они должны быть достаточно «свежими», то вся эта схема перестает работать.
CDC спешит на помощь
Решить задачу можно, применяя широко известный паттерн Change Data Capture, или Захват Изменений Данных. Его смысл заключается в том, чтобы перемещать только те данные, которые изменились с момента предыдущего копирования. Способов реализации достаточно много.

Например, в исходные данные можно добавить какую-нибудь колонку типа timestamp, в котором исходная система будет сохранять дату последней модификации записи. Тогда каждый раз, копируя данные, конвейер может сохранять последнюю скопированную временную метку, а в следующий запуск оперировать только с данными младше этого времени. Это базовая реализация CDC. Она тоже подразумевает пакетную обработку раз в какой-то промежуток времени, но даже такой подход позволяет существенно сократить объём копируемых данных.
Другой способ реализации паттерна — применение изменений. Такой подход даёт возможность построить репликацию во времени, близком к реальному. Основа решения — подписка на информацию об изменениях в источнике. Далее она применяется к целевой системе. Здесь важно иметь в виду, что изменения всегда берутся с какой-то временной точки, поэтому важно написать пакетный конвейер данных, очень похожий на нативное решение по репликации, чтобы синхронизировать начальное состояние продуктивного аналитического хранилищ.
Хватит теории! Практику давай!

Рассмотрим построение аналитической системы, где в качестве продуктивной БД выступает MongoDB, а в качестве аналитической — Clickhouse.
При построении репликации требуется обеспечить семантику доставки данных “at-least-once”, при этом требуется максимизировать пропускную способность конвейера.
Захват изменений будет реализован через чтение лога операций — стандартный механизм получения оповещений об изменениях в MongoDB.
Маппинг коллекций MongoDB на таблицы Clickhouse известен и не меняется.
Дополнительно известно, что лог операций в MongoDB достаточно жёстко ограничен по объёму, что требует дополнительной буферизации изменений в промежуточном хранилище — Apache Kafka.
Выбор компонентов обусловлен уже существующим стеком проекта, поэтому примем его как данность.
Обзор возможностей компонентов
MongoDB — документо-ориентированная база, данные доступны в формате JSON, запросы к ней пишутся также в JSON. У этой системы хранения данных есть бесплатная общественная версия, а также широкая поддержка коммерческой функциональности, такой как безопасность, высокая доступность и масштабируемость.

Для репликации используется Oplog — коллекция, в которую попадают операции, произошедшие в Mongo с указанием типа изменения, например, i - insert, u - update, d - delete. Каждое сообщение в этой коллекции содержит временную метку, что делает их пригодными к потреблению паттерном «Захват изменений».

Apache Kafka — это распределённый брокер сообщений. Обладает открытым кодом, хорошо масштабируется и держит большие нагрузки.

Clickhouse — колоночная база данных с SQL-интерфейсом, в которой даже работают update’ы.

Архитектура решения
Каким образом можно реализовать конвейер данных с описанными требованиями на этих компонентах?
Первый вариант — вставка напрямую
В зависимости от типа операции в Clickhouse выполняется соответствующий запрос. i = insert, u = update, d = delete. Одной записи в Oplog соответствует один запрос, схлопывание однотипных запросов в батч не выполняется.

Одной коллекции в MongoDB соответствует одна таблицу в Clickhouse. Для репликации в этом случае можно использовать простое Java-приложение или какой-нибудь фреймворк, например, Apache Spark.
Второй вариант — Slowly Changing Dimensions (SCD) Type 2. Все операции, неважно, insert, update или delete, выполняются как insert на целевом хранилище. Каждой новой версии записи по соответствующему идентификатору присваиваем порядковый номер или timestamp обновления. Эту дополнительную колонку впоследствии можно использовать для того, чтобы выбрать последнюю версию записи или сформировать слепок на определённый момент времени.

Третий вариант — использование промежуточного кеша, поддерживающего обновления. Идея проста: не стоит обновлять данные в хранилище, которое не поддерживает операции обновления, вместо этого достаточно применить эти операции к какому-нибудь in-memory-хранилищу. Insert, update, delete работают быстро, однако раз в какое-то время будет требоваться полная перезапись в Clickhouse. Это архитектура табличного обновления.

И четвёртый подход. Если данные предполагают естественное разбиение на части, например, по времени появления в системе, то их можно регионировать, или партицировать. В таком случае при регулярном обновлении из кеша в целевое хранилище не обязательно перезаписывать всю таблицу, достаточно заменить только те партиции, которые поменялись.
В остальном, идея ровно такая же, как с табличным обновлением.

Какая архитектура выиграет? Ответ оказывается неоднозначным.
Время замерять результат
О тестовом стенде. MongoDB, Kafka и Clickhouse можно развёрнуть на виртуальных машинах в публичном облаке. Для построения графиков, приведённых в этом посте, использовались виртуальные машины с 2 CPU, 4 Gb RAM, HDD, гигабитной сетью и остальными настройками по умолчанию. Операционная система: Ubuntu 20.04.
Далее потребуется генератор данных, который позволяет совершать операции всех видов в MongoDB.
Будем записывать в MongoDB N штук изменений, где N — достаточно большое. Замерять будем общее время обработки этого количества записей, включая инициализацию и завершение, усредненную скорость (record per second, rps) и максимальную задержку появления данных в аналитической системе (t минус что-то).

Для статистической достоверности результатов запустим приложение десять раз, отбросим 2 наиболее отличающихся результата, потом посчитаем среднее значение и стандартное отклонение.
Тестовый стенд

Настройка компонентов инфраструктуры. В MongoDB придется настроить реплика-сет, состоящий из одного узла, генератор данных будем запускать в единственном экземпляре. Рассмотрение оптимизации с точки зрения параллелизма, кластерности, улучшения машин, на которых всё запускается, не входит в нашу задачу. В частности, в зависимости от всех этих параметров могут получиться совершенно иные результаты, и конкретный подход лучше выбирать на железе, аналогичном предполагаемому к использованию в продуктивной среде. В данном случае при строительстве стенда мы априорно стремимся к тому, чтобы узким местом в системе была производительность выполнения операций в Clickhouse.
Для такого теста также важно, какие данные будут проходить через систему.

Будем использовать два профиля: первый — исключительно insert’ы. На этом профиле мы не будем использовать «тяжелых» операций при записи в Clickhouse, и все архитектуры должны показать себя одинаково хорошо.
Второй профиль — 40% вставки, 40% обновлений и 20% удалений.
В реальной жизни профили зависят от того, что происходит в продуктивной базе, от специфики нагрузки, но даже базовая оценка распределения операций по типам достаточна для проведения теста.
")
Как видно из диаграммы, rps растут в зависимости от количества записей, это означает, что все реализации обладают достаточно большим overhead’ом на инициализацию. Есть способы избавиться от его влияния на результаты. Например, можно «прогреть» систему или делать замеры на постоянном потоке обновлений в MongoDB.
На первом профиле данных простая вставка в любом случае проигрывает. Проигрывает она по одной простой причине: вставка батчами всегда быстрее, чем она же по одной записи. Вставка в Clickhouse — все равно что вставка в колоночный формат, достаточно тяжелая операция.
SCD2 — просто insert’ы, они делались в данном случае батчами, batch size был достаточно большим (записи в Kafka, пришедшие за секунду), поэтому можно даже сравнить, насколько подобная оптимизация ускоряет работу пайплайна.
При табличном обновлении запись в кэш происходит быстро, но запись непосредственно в Clickhouse достаточно медленная, потому что приходится перезаписывать все данные каждый раз на каждый батч (также записи в Kafka, пришедшие за секунду). Если мы сначала все сохраним в кэш, а потом все сразу запишем в целевое хранилище, высота столбика должна получиться примерно такой же, как в SCD2.
Важно! В данном сравнительном анализе не учитывается время, которое будет затрачено на выборку конечного результата в Clickhouse. Запросы, требующие создания слепка данных в модели SCD2, конечно, будут работать медленнее, чем в других вариантах архитектур.

На втором профиле результаты другие. Столбик с простым применением существенно просел за счет того, что операции обновления и удаления существенно дольше выполняются. Остальные столбики, в принципе, остались примерно такими же, что говорит о том, что вне зависимости от профиля данных SCD2 будет работать примерно одинаково. Это даёт некую надежду на универсальность и отсутствие необходимости считать этот профиль каждый раз для каждой нагрузки.
Что в итоге
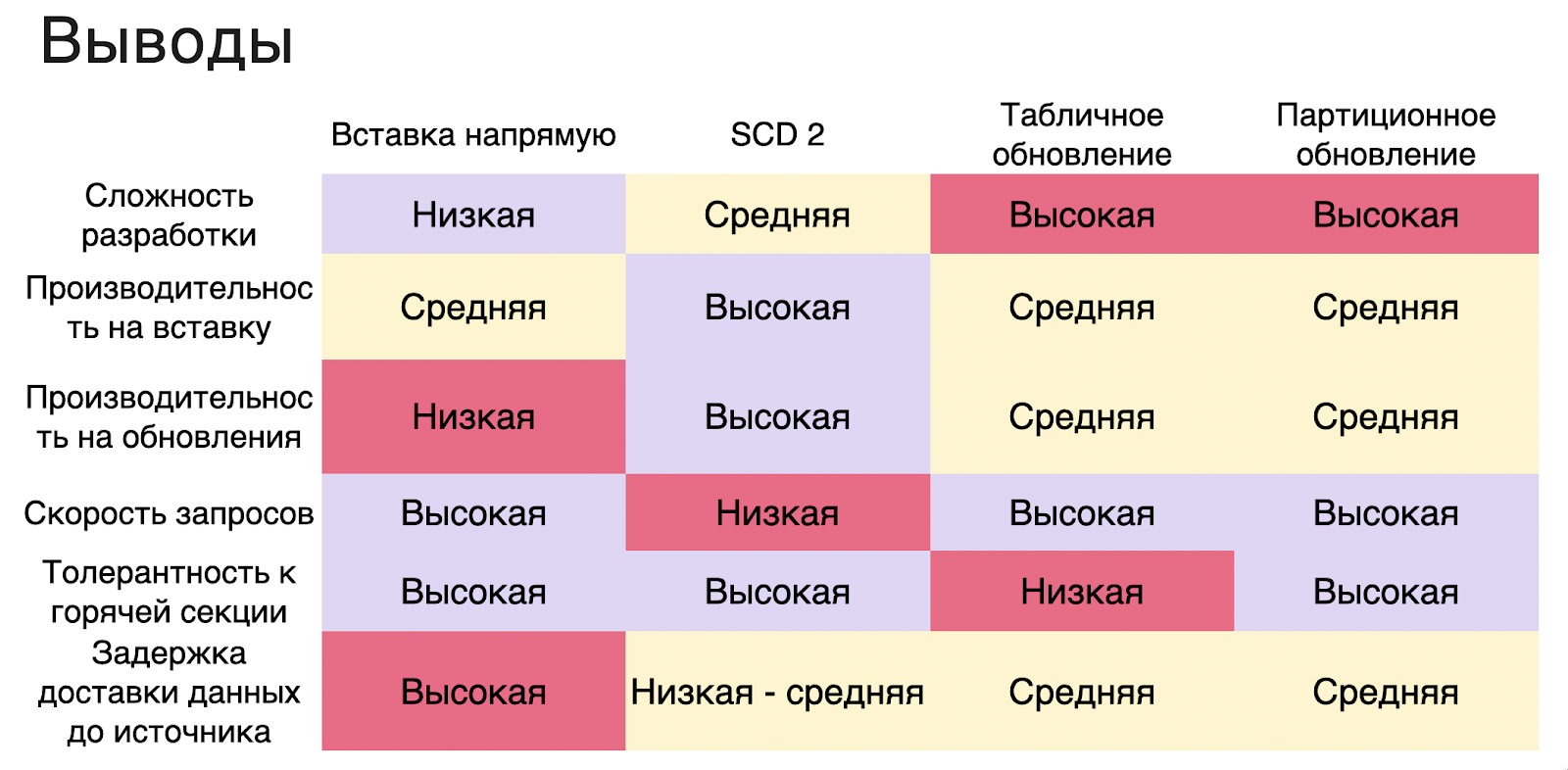
В сравнительной таблице приведены ещё несколько факторов, которые будут достаточно важными для принятия решения об использовании той или иной архитектуры:
сложность разработки,
производительность на вставку,
производительность обновления,
скорость запросов,
толерантность к горячей секции,
задержка доставки данных до источника.
У каждой архитектуры есть свой недостаток.
Выбор надо делать, исходя из того, что именно требуется максимизировать: если важна скорость доставки, то, конечно, выбор за SCD2, но для выборки актуальной версии данных потребуются запросы с оконными функциями или self-join’ы, или надо будет сделать еще один батчовый шаг по обновлению слепка данных на определённое время.
Если же важна сложность разработки, требуется быстро внедрить пайплайн для проверки какой-нибудь гипотезы, то почему бы не воспользоваться стандартным API, это достаточно быстро.
С кэшем получается и дорого, и больно, но зато сразу получается слепок, к которому можно писать запросы.
Финал
Конечно же, однозначного ответа не получилось. Серебряной пули опять не существует, а каждому гвоздю требуется свой молоток. Оказалось, что даже в сильных ограничениях на технологии, которые были введены в этом посте, есть вариативность при выборе архитектуры решения, что удалось наглядно показать, используя данные.

barloc
Понятно, что некий руководитель чаптера - уже скорее менеджер, чем технарь. Но все-таки про что здесь написано то.
Все знают, что операции мутаций в кликхаузе дорогие, очень дорогие. И напрямую их в нормальной работе не используют. В итоге какой движок у таблиц то был?
Что за вставка такая и что за scd2? Обычный подход - replacingmergetree с дополнительными колонками версии и актуальности, чтобы работал final в запросе и происходила очистка. Либо без оной и вы получаете вашу так называtмую scd2.
Непонятно чем осуществлялась вставка - встроенным движком и материализацией или консумер написан на стороне.