
Всем привет! Меня зовут Денис Колпаков, я бэкенд-инженер в юните Core Services Авито. Долгое время я был овнером критически значимого для бизнеса сервиса форм, а последний год занимаюсь каталогами и каталогизацией.
Я расскажу, как мы решали продуктовую задачу — искали способ отфильтровать модификации товаров из базы данных.

Немного контекста о задаче
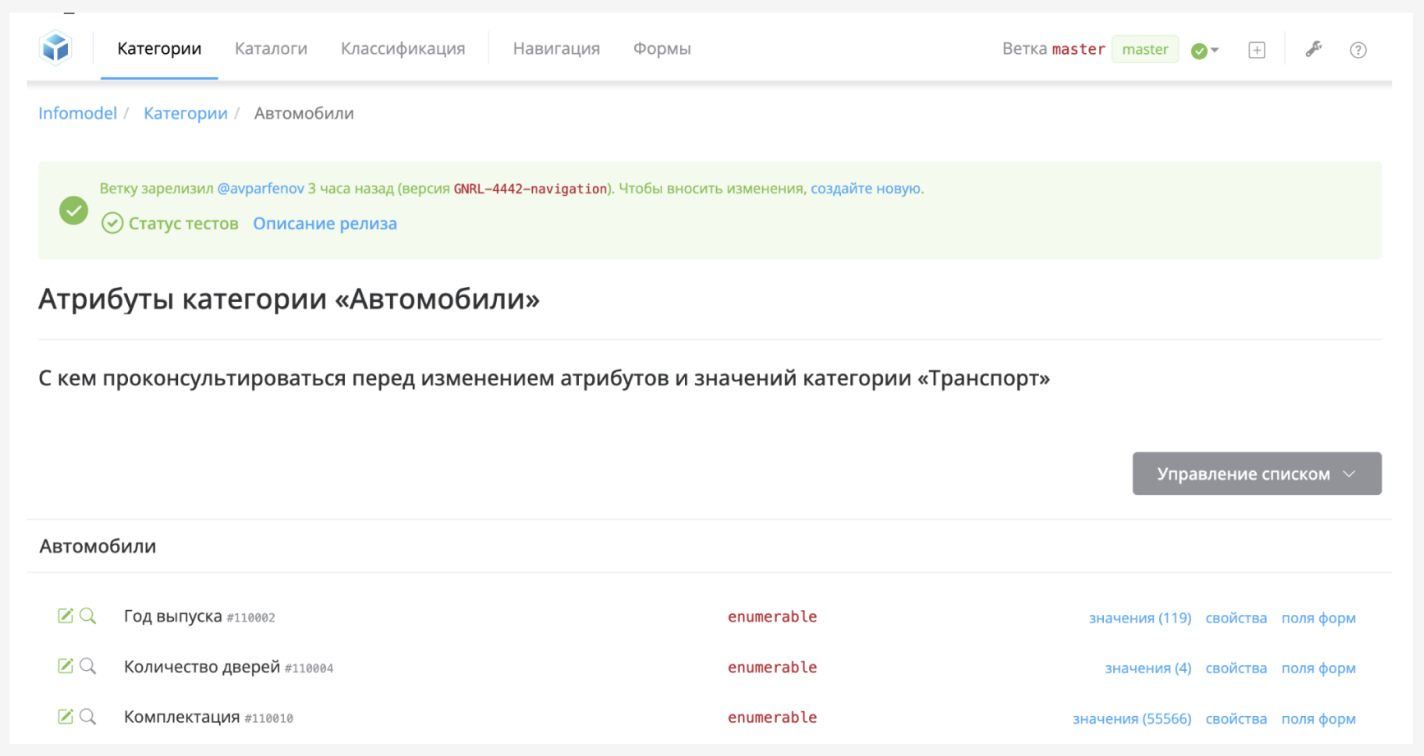
В Авито есть система управления метаданными объявлений — инфомодель. Она позволяет контролировать атрибуты и структуру объявлений. В ней настраиваются формы подачи, редактирования, поиска объявлений на разных страницах и платформах Авито.

На продакшене одновременно существуют объявления с разной версией инфомодели. Важный факт об инфомодели: любые изменения в ней не попадают на продакшн мгновенно, а проходят некий релизный цикл.
Несколько лет назад Авито как бизнес захотел узнать как можно больше об объявлениях. В идеале — уметь мапить их на реальные физические товары и услуги. Так начало развиваться направление каталогизации.
Первые каталоги находились внутри инфомодели. Их было мало и изменения в них были большой редкостью, поэтому такое решение всех устраивало.
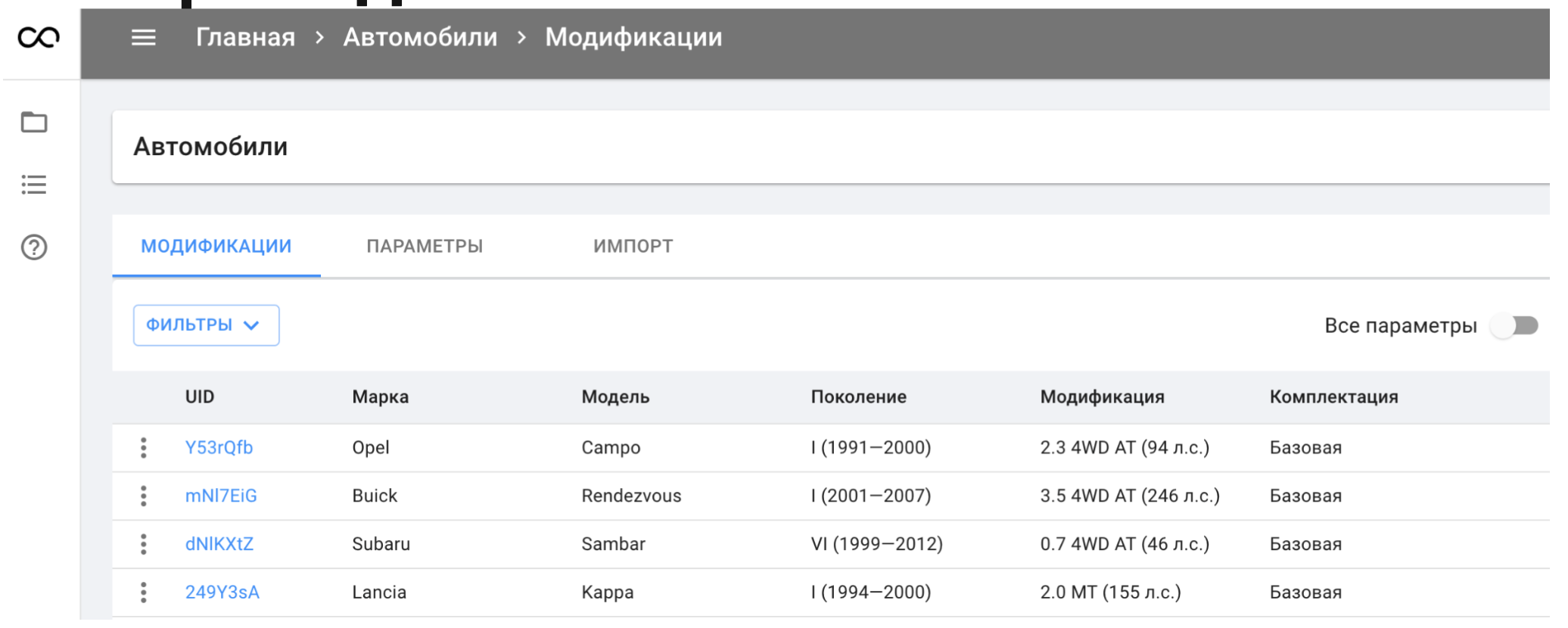
Но каталоги развивались, их становилось больше. Бизнес-процессы редактирования метаданных объявления и добавления новых модификаций в каталоги стали слишком отличаться друг от друга. При этом возникали проблемы:
Высокий Time-to-Market любых изменений каталогов. Чтобы просто добавить новую модификацию товара уходили часы и дни до выхода в продакшн.
Неэффективная утилизация памяти из-за версионирования инфомодели.
Низкий показатель Capacity каталогов. Мы посчитали, что с трудом выдержим увеличение объёмов данных даже в 3–5 раз. А у продуктовых команд были большие планы развития.
Поэтому инфомодель и каталоги решили разделить на отдельные домены.
Все данные о формах на Авито собирает специальный сервис. Форма — это некое представление, которое строится на основе данных об объявлении. Сервис форм знает, как разложить эти данные на составные части.

При этом сервис форм не взаимодействует напрямую с инфомоделью. Все данные о структуре, которые ему нужны, он сохраняет к себе в inmemory-кэш. А он прогревается на основе спецификаций из файлового хранилища CEPH. Чтобы добавить новую модификацию на продакшн, нужно было зайти в инфомодель, сделать её новую версию, внести изменения и отправить в релиз.
На событие релиза запускались длительные авто-тесты. В случае успешного прохождения событие подхватывал технический сервис specbuilder, который строит эти самые спецификации (при этом в них могут быть данные и из инфомодели, и из внешних источников). После релиза сервис форм по новой прогревает кеш на основе получившихся спецификаций из CEPH.
Как мы видели целевую схему работы
Мы хотим оставить работу со структурой объявления (метаданными) такой же, как на старой схеме. То есть, оставляем релизы инфомодели, specbuilder, спецификации в ceph и inmemory-кеш. А за каталожными данными мы хотим ходить в рантайме в какой-нибудь сервис, который должен инкапсулировать в себе работу со списком модификаций, и при необходимости получать данные из внешних источников.

Немного пояснений...
Каталог — это набор модификаций. А сами модификации — это комбинации из набора param-value. Каталог — это динамическая сущность, он меняется из админки: можно создавать новые каталоги и редактировать структуру существующих. Поэтому модификации мы храним в базе данных в виде таблички с JSON-колонкой data, где хранится комбинация param-value. На основе этой таблица построена materialized view, где эти же данные представлены в формате EAV.
Сбор требований к API
Мы хотим ходить в рантайм за списком модификаций. А значит, нам нужен API, который будет возвращать эти данные.
Мы проанализировали сервис форм и вывели два функциональных требования к API:
Он должен валидировать входящий набор param-value. Например, убедиться, что в каталоге есть модификации, у которых в качестве бренда указан Apple, модели — iPhone XS, цвета — зелёный.
Он должен возвращать список всех возможных значений для каждого из параметров. При этом некоторые параметры зависят друг от друга. То есть, мы можем получить список всех уникальных брендов. А для модели нужны данные только тех модификаций, которые относятся к конкретному бренду. Фактически, объект собирается рекурсивно и список возможных значений каждого следующего параметра ограничивается, исходя из значения предыдущего. Это требования появилось из необходимости сохранить обратную совместимость API сервиса форм.
IN:
{
“params”: {
“brand”: “Apple”,
“model”: “Iphone XS”,
“color”: “Зеленый”
},
“autofill”: true,
“options”: true
}
OUT:
{
“brand”: {
“value”: “Apple”,
“options”: [
“Apple”,
“Xiaomi”
]
},
“model”: {
“value”: “Iphone XS”,
“options”: [
“Iphone X”,
“Iphone XS”,
“Iphone XR”
]
},
“color”: {
“value”: “Зеленый”,
“options”: [
“Зеленый”,
“Золотой”
]
}
}Сами по себе эти задачи несложные. Проблема в том, что мы не знаем последовательность параметров, по которым нужно отфильтровать значения. Она настраивается на формах инфомодели, о которых каталоги не знают.
Например, на форме подачи объявления на десктопной версии Авито мы можем указать последовательность «бренд-модель-цвет». В форме редактирования объявления на iOS — «бренд-цвет-модель». И тогда уже модель нужно будет фильтровать по цвету.
Также, в беклоге давно пылится задача для поисковых форм - зачастую пользователь хочет заполнять фильтры в произвольном порядке.
Нефункциональные требования к API:
Ответ должен приходит сильно быстрее, чем за 100 мс. В идеальном случае — 20–40 мс для 99 перцентиля.
Выдерживать до 1,5 млн запросов в минуту — rpm.
Эти критерии основаны на текущей нагрузке сервиса форм, который будет основным пользователем API. Пиковая нагрузка на него — около 1,2 млн запросов в минуту, а SLO по времени ответа — 200 мс. У нового API запланировали запас прочности по этим показателям.
Первая попытка: и так сойдет
В первую очередь нам нужно доказать самим себе, что наша схема рабочая. Самый быстрый способ ее оценить — собрать MVP.
Для начала будем учитывать только функциональные требования и сделаем API, который рекурсивно ходит в базу данных и фильтрует параметры.
Мы себе доказали, что можем собрать нужный объект. С нефункциональными требованиями возникла проблема: MVP падает на 50 запросах в секунду (rps), и даже при 10 rps показатели очень далеки от желаемых 20–40 мс.
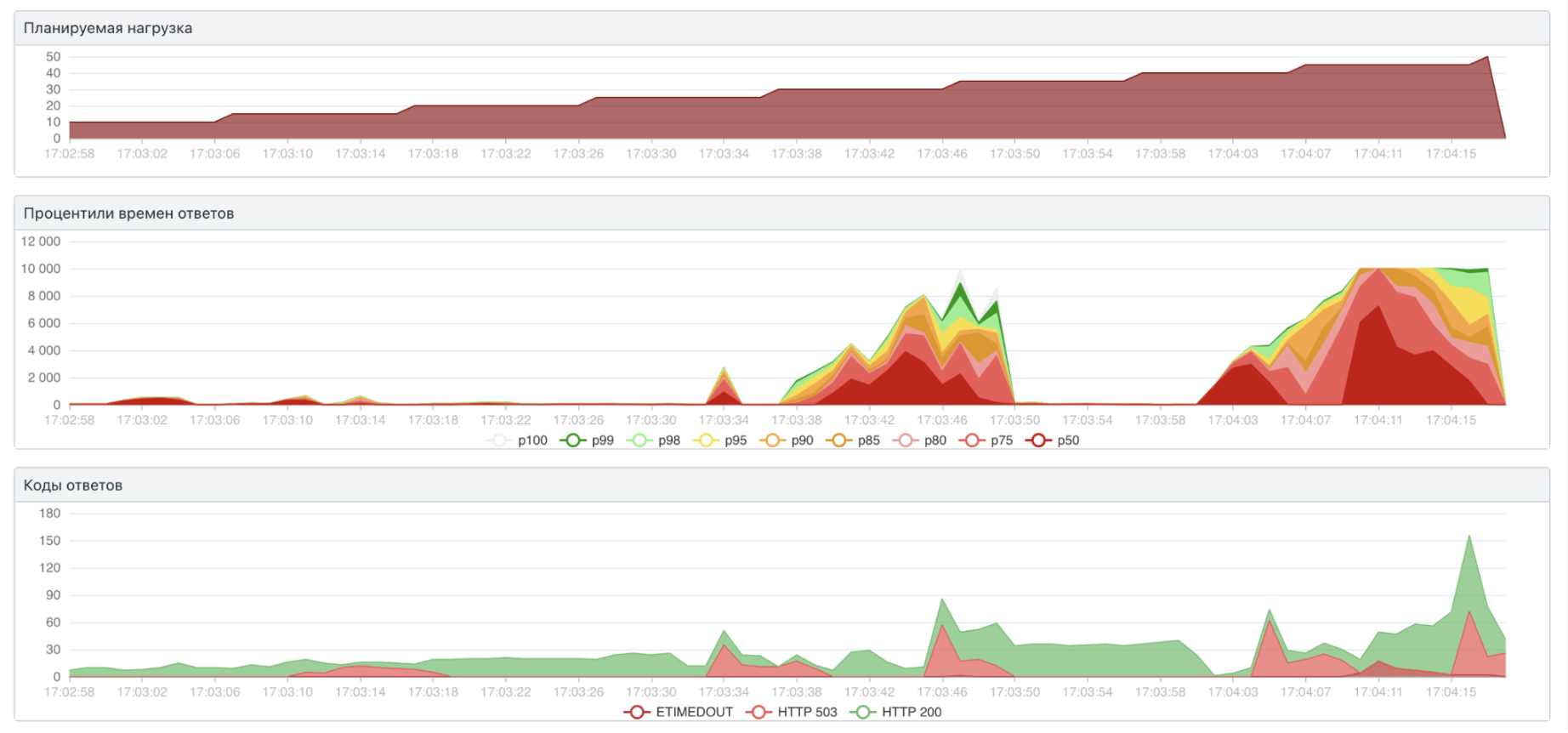
Зато у нас есть отправная точка, с которой мы будем сравнивать дальнейшие шаги. А ещё мы оценили, насколько мы далеки от нужных значений и какой объём работы предстоит.
Следующие несколько спринтов мы потратили на тюнинг нашего решения на PostgreSQL, чтобы при этом не сильно менять MVP.
Мы пообщались с администраторами баз данных, узнали про рекурсивные CTE, попробовали увеличить ресурсы. В общем, развлекались как могли и в итоге получили результат.

MVP теперь стал падать при 150 rps, а не 50, и даже время ответа немного улучшилось.
На этом этапе мы поняли, что либо нам не подходит классическая реляционная БД вроде PostgreSQL, либо мы не умеем её готовить. Но задачу надо выполнять, поэтому начали смотреть, как это делают другие.
Сначала мы сходили к коллегам из поиска, чтобы узнать про движок Sphinx. Я был уверен, что в нём есть готовое решение. Но оказалось, что в нем нет "серебрянной пули" для решения нашей задачи. Зато коллеги посоветовали, где ещё поискать.
Мы посмотрели графовую СУБД Neo4j, потому что наша задача с определенной точки зрения похожа на обход графа. Почему-то магия одинаковых слов «граф» в названии СУБД и задаче не сработала. Нужных нам 20 мс мы не получили. Либо в нашей команде нет магов, либо магии в реальной жизни не существует.
Затем мы изучали другие базы данных, в том числе поэкспериментировали с inmemory-движками, например SQLite. Все нужные данные о модификациях хранятся в оперативной памяти сервиса, поэтому мы получили хорошие результаты и мысленно поставили галочку на этом движке. Возможно, он нам пригодится в будущем.
Вторая попытка: ищем товар по известной последовательности фильтров
Найти готовое решение не получилось, и мы решили подойти к задаче с другой стороны. Начали придумывать алгоритм, который позволил бы нам быстро искать, а уже под него подбирать storage.
Спойлер: подходящие storage есть, но пока мы используем в продакшене наш «велосипед», потому что на переход нужно время.
Самым сложным в задаче было то, что мы не знали последовательность фильтров. Поэтому в новом алгоритме мы сначала решили представить, что знаем их порядок. Получили схему, которую я назвал data composition layer.
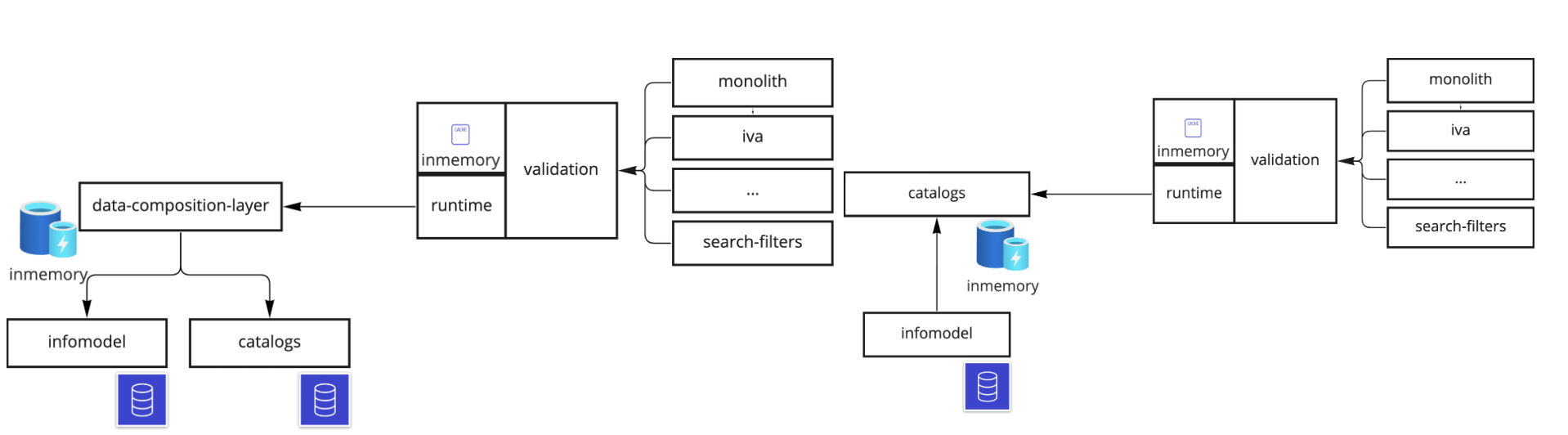
Её суть в том, что мы забираем данные из каталогов, и «search index config» (все существующие вариации последовательностей полей на различных формах) из инфомодели и на основе этих данных строим набор деревьев. В этот момент задача становится тривиальной: нам просто нужно выбрать подходящее под запрос дерево и "спуститься" по нему исходя из условий и входящих значений полей.
Преимущество этого решения в том, что такой алгоритм у нас уже есть — точно также работает сервис форм. Он получает все данные из инфомодели, строит деревья и очень быстро проходит по ним. Мы уверены, что сможем реализовать что-то подобное и это будет работать быстро.
Недостатка у схемы data composition layer два:
Появляются процессы, которыми нужно управлять. Например, в какой момент создавать новое дерево или удалять старое.
Она не поможет реализовать сценарий с поисковыми формами, в котором пользователь хочет заполнять фильтры в произвольном порядке.
Получается, решение хорошее, но не решает всех задач — подходит для ситуации, когда поля идут в определенном порядке и этот порядок редко меняется. Мы отложили его как «план Б». Теперь нужно было найти способ работать с неопределенными последовательностями фильтров.
Третья попытка: фильтруем по хэш-индексам
Мы попробовали подсмотрели подход в классических реляционных БД. Чтобы быстро найти строчки в таблице, которые соответствуют точному значению параметров, нам нужен хэш-индекс. В нём будет массив указателей на строчки с нужным параметром.
Что делать, если нужно отфильтровать по двум полям? Строим для каждого из них хэш-индекс и пытаемся найти в пересечение в двух множествах указателей. То же самое — для трёх и более параметров.

Осталось понять, как быстро искать пересечения. Есть три возможных подхода:
Nested Loops Join — вложенный цикл со сложностью N2, — на быстрое решение не похоже;
hash join — соединение через хэш‑таблицу (hashmap), сложность решения O(N);
sort‑merge join — слияние с помощью предварительной сортировки.
Из этих трёх мы решили взять за основу идею второго подхода на hashmap'ах.
Для реализации алгоритма нам нужно несколько сущностей. PVTree — агрегат, который дает доступ к индексу конкретного каталога. Сейчас у нас нет кросс-каталожного поиска, поэтому сначала находим нужный каталог. Например, каталог телефонов.
catalogPVTree(индекс по конкретному каталогу) содержит несколько справочников. Самый важный — hashmap pvNode. По сути, это набор колонок с конкретными параметрами. В каждом из них есть набор vNode — список его уникальных значений. Внутри него есть хеш-индекс с набором указателей на модификации, в которых присутствует это значение.


В качестве ключей хешмап pvNodes и vNode используются ID-параметры и значения соответственно. То есть, имея а руках нужные ID, мы можем быстро получить набор указателей на модификации, в которых есть данная комбинация paramID: valueID.
В получившейся реализации на Go немного другие имена, но кардинальных изменений нет:
type Storage struct {
l *logger.Logger
mc MetricCollector
mu sync.RWMutex
// Индексы каталогов. В качестве ключа — slug каталога
catalogsTrees map[string]*catalogtree.PVTree
}type PVTree struct {
catalog models.catalog
// последовательность отсортированных asc id’ов модификаций
modificationsIdxSortedSeq []int
// Справочник с данными о модификациях каталога. В качестве ключа — id модификации
modifications map[int]*models.ModificationData
// paramsMap справочник всех параметров каталога. В качестве ключа — id-параметра
paramsMap map[int64]*models.CatalogParam
// valuesMap справочник всех значений каталога. В качестве ключа — id-значения
valuesMap map[int64]*models.ValueWithTags
pvTree map[int64]*PVNode
// outdated таймер "обновления" индекса
outdated *time.Timer
// hash хеш от всего индекса
hash string
}
type PVNode struct {
paramID int64
valuesIdsSortedSeq []int64
vNodes map[int64]*VNode
}
type VNode struct {
v *models.ValueWithTags
index HashIndex
}
type HashIndex map[int64]struct{}В этой реализации структура Storage — это наш агрегат, в котором есть индекс конкретного каталога (сущность PVTree в реализации).
Структура PVTree — индекс значений внутри конкретного каталога, PVNode — индекс по «столбцу», конкретный параметр. В VNode хранится конкретное значение — индекс Hashmap.
Вернёмся в самое начало и вспомним, какие задачи нужно решить:
Провалидировать комбинацию входных значений. Узнать, возможно ли отфильтровать товары по заданным параметрам.
Найти все возможные значения для каждого из параметров.
Первую задачу решаем просто: достаем множества значений и находим в них пересечения с помощью Hashmap.
// Intersection возвращает результирующее пересечение двух HashIndex’ов
func Intersection(first, second HashIndex) HashIndex {
res := make (HashIndex)
for modId := range first {
if _, ok := second[modId]; !ok {
continue
}
res [modId] = struct{}{}
}
return res
}
Например, валидируем фильтрацию по двум параметрам. Берём ключ из первого Hashmap. Если такой же ключ есть во втором — значит, элемент входит в пересечение.
Вторая задача сложнее. Нужно проверить все уникальные значения и отобрать из них те, у которых есть пересечения с Hashmap из предыдущего шага.
func (pv *PVNode) valuesWithModIntersection(current hashIndex.HashIndex, optionsSort string) []*models.ValueWithTags {
res := make([]*models.ValueWithTags, 0, len(pv.vNodes))
if optionsSort == models.SortDESC {
for i := len(pv.valuesIdsSortedSeq) - 1; i >= 0; i-- {
if hashindex.HasIntersection(current, pv.vNodes[pv.valuesIdsSortedSeq[i]].index) {
res = append(res, pv.vNodes[pv.valuesIdsSortedSeq[i]].v)
}
}
} else {
for i := 0; i < len(pv.valuesIdsSortedSeq); i++ {
if hashindex.HasIntersection(current, pv.vNodes[pv.valuesIdsSortedSeq[i]].index) {
res = append(res, pv.vNodes[pv.valuesIdsSortedSeq[i]].v)
}
}
}
return res
}
// HasIntersection проверяет на наличие пересечений между двумя HashIndex’ами
// В отличии от Intersection не высчитывает итоговое пересечение
func HasIntersection(first, second HashIndex) bool {
for modId := range first {
if _, ok := second[modId]; !ok {
return true
}
}
return false
}Время оптимизации
Посмотрим, какой результат даёт этот алгоритм под нагрузкой.
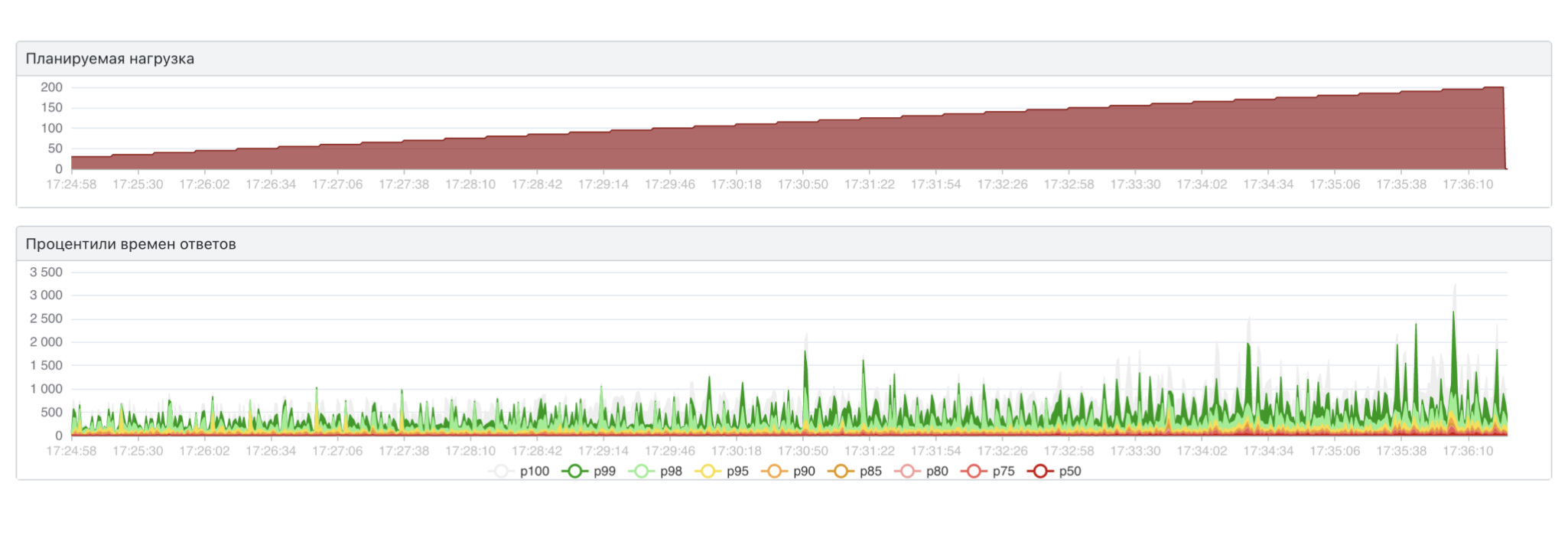
Неплохо: pod сервиса не падает при 150 rps, скорость — меньше одной секунды. Это лучший результат, которого мы достигали. Но он нам всё равно не подходит. Так мы приходим к следующей идее: нужно оптимизировать.
Мы проанализировали решение и поняли, что vNode неодинаковые по размеру. А пересечение двух множеств всегда будет целиком лежать внутри меньшего из них. Это значит, что достаточно добавить простую проверку на размер hashmap и искать пересечение по меньшему множеству.
//Intersection возвращает результирующее пересечение двух HashIndex’ов
func Intersection(first, second HashIndex) HashIndex {
if len(first) > len(second) {
//Итерируемся по меньшему из двух множеств,
//так как результирующее пересечение полностью содержится в меньших из двух
first, second = second, first
}
res := make(HashIndex)
for modId := range first {
if _, ok := secons [modId]; !ok {
continue
}
res [modId] = struct{}{}
}
return res
}Мы не питали больших надежд на такую маленькую оптимизацию, но всё-таки решили проверить новый алгоритм под нагрузкой.
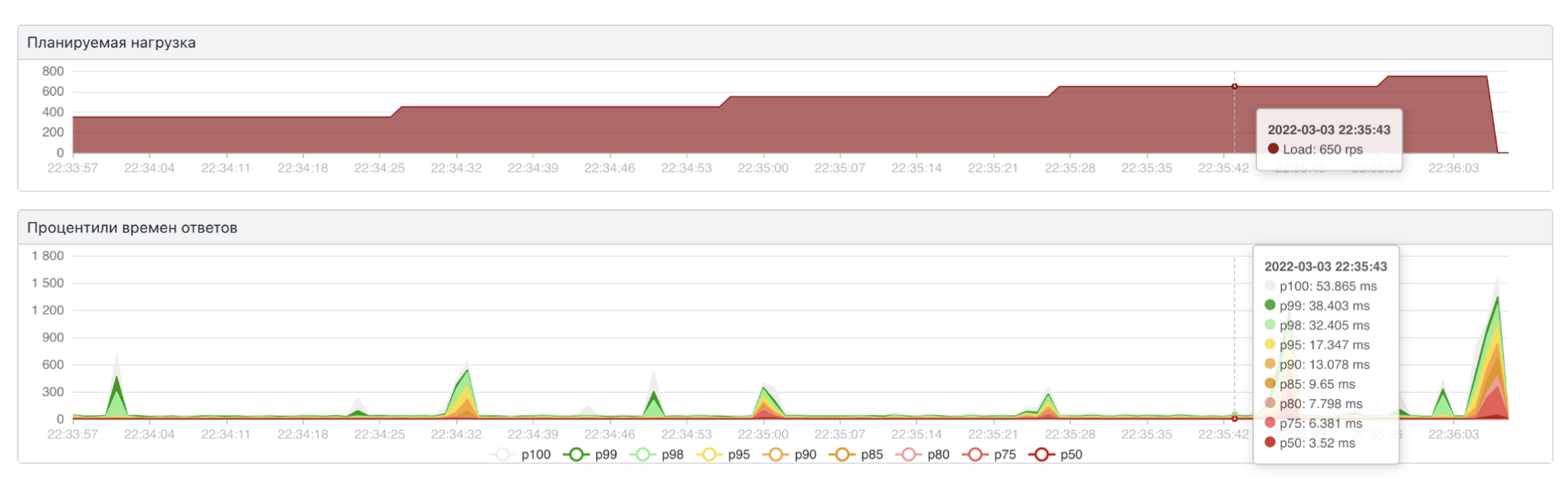
Оказалось, что она решила обе наши задачи. Мы уложились в 40 мс, и один инстанс сервиса не падает на нагрузке 600 rps (а значит мы можем горизонтально отмасштабировать наше решение и выдержать требуемую нагрузку на ~45 подах).
Мы понимали, что это максимальная граница требований, к тому же мы получили её на синтетической (тестовой) нагрузке. На продакшене алгоритм может сработать иначе и не так хорошо. Поэтому мысль про оптимизацию поиска пересечений не отпускала.
Bitmap-индекс
В какой-то момент я поймал себя на мысли, что пытаюсь визуализировать этот поиск как некую решетку. Это было похоже на бред, но затем я понял, на что она похожа. Это была битовая маска. И это стало прорывом.
Представим, что есть список жилых комплексов и набор булевых значений, которые их характеризуют.

ЖК можно отфильтровать по нескольким булевым значениям. Для этого берём значения из нужных колонок (фильтров) и выполняем побитовое умножение значений. Строки (ЖК), в которых результат будут равен 1 — нужные нам, потому что соответствуют всем критериям.
Любой современный процессор выполняет операцию побитового умножения очень быстро, поэтому мы решили поэкспериментировать с bitmap-индексом в каталогах.
В реальности наша задача была сложнее из-за большого количества параметров и значений.

Но мы все равно можем разложить их на большую плоскую «таблицу». В качестве строк у нас будут модификации, в качестве столбцов — уникальные значения всех параметров. Все значения для каждого из параметров мы раскладываем в один большой плоский список. Заполняем табличку по принципу: если в модификации есть значение — ставим «1», в противном случае — «0». Получается почти то же самое, что в примере с ЖК, только колонок сотни тысяч.
Если эти значения сгруппировать по параметрам — тогда структура данных останется почти такой же, как и в реализации на хеш-индексе. Вся таблица — это хэш-индекс по конкретному каталогу (PVTree). Остались наши сущности pvNode (сгрупированный по параметру список значений) и vNode (уникальное значение, колонка в нашей "виртуальной таблице"). Только теперь в vNode хранится не hashmap, а битовая маска, описывающая весь набор модификаций каталога.
В итоге получается алгоритм, в котором с помощью побитовых операций мы сможем найти товар, который соответствует заданным фильтрам.
Например: задаём параметр Apple, iPhone XS, зеленый. Выполняем побитовое умножение и выясняем, какие для каких модификаций результат 1. Это и будет нужный товар. Передавать параметры при этом можно в любом порядке, это не повлияет на результат.

Тут важно сделать одно замечание: в нашей реализации мы работаем не напрямую с битами, а с uint64 — фактически, набором из 64 бит. Каждая цифра — это битовое слово, которое описывает набор из 64 модификаций. То есть первая цифра — модификации от нулевой до 63-ей, Вторая — от 64-ой до 127-ой и так далее. При этом для процессора нет большой разницы: перемножать биты по одному или пачками по 64.
Реализация на Go для bitmap-индекса с uint64:
type BitsetIndex struct {
b []uint64
}
//Intersection возвращает результирующее пересечение двух HashIndex’ов (фактически — логическое «И»)
func Intersection(first, second BitsetIndex) BitsetIndex {
res := BitsetIndex{
b : make([]uint64, 0, len(first.b)),
}
for idx, firstBitmap := range first.b {
secondBitmap := second.b[idx]
if secondBitmap == 0 {
continue
}
res.b[idx] = firstBitmap & secondBitmap
}
return res
}//HasIntersection проверяет на наличие пересечений между двумя HashIndex’ами,
// В отличии от Intersection не высчитывает итоговое пересечение
func HasIntersection(first, second BitsetIndex) bool {
for idx := range first.b{
if first.b[idx]&second.b[idx] != 0 {
return true
}
}
return false
}По сравнению с хэш-индексом изменилось не так много: для поиска пересечений множеств используется побитовое умножение двух массивов uint64 (битовых масок).
Чтобы проверить, какой из алгоритмов быстрее (c hashmap или bitmap), я использовал бенчмарки Go. И тут меня ждало разочарование.

Оказалось, что алгоритм, который основан на эффективных побитовых операциях, работает медленнее, чем hashmap. Но здесь важно помнить, что хороший результат для хэш-индекса мы получили после оптимизации. При этом bitmap-индекс показал сравнимые результаты без каких-либо хаков. Значит, в нем можно что-то улучшить.
Снова время оптимизации
Первое, что хочется сделать — это вернуть условие, которое сравнивает размер множеств. В предыдущей реализации наши hashmap-индексы имеют разную длину, но в bitmap-индексе хранится битовая маска, которая описывает все модификации каталога, а значит они все одинаковой длины.
Вспоминаем, что умножение на ноль даёт ноль, поэтому нам не нужно перемножать нулевые биты. Чтобы избежать лишних перемножений добавляем еще один массив filledIndex, в котором хранятся заполненные индексы.
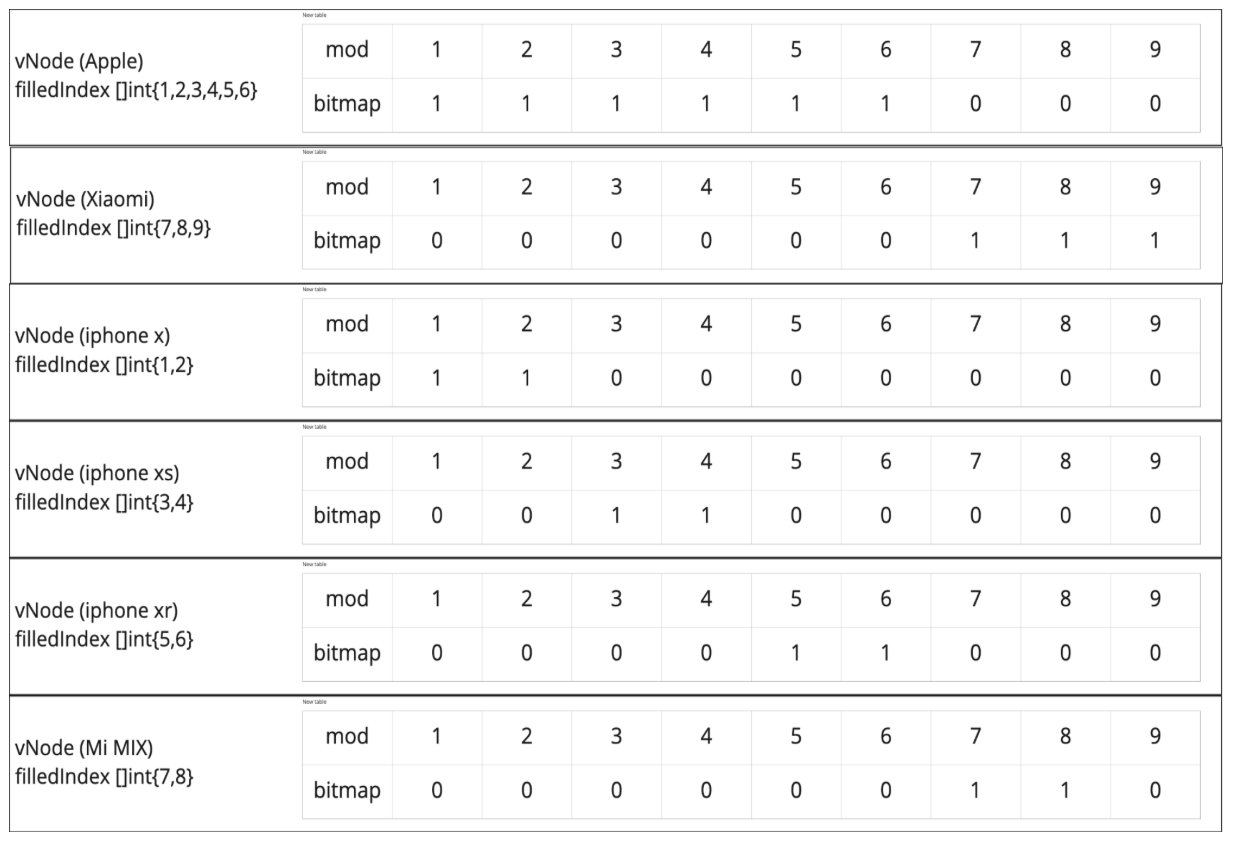
Добавляем в реализацию условие: итерируемся не по битмапе, а по filledIndex, причём по меньшему из двух.
type BitsetIndex struct {
b []uint64
filledIndex []int
}
//Intersection возвращает результирующее пересечение двух HashIndex’ов (фактически — логическое «И»)
func Intersection(first, second BitsetIndex) BitsetIndex {
if len(first.filledIndex) > len(second.filledIndex) {
first, second = second, first
}
res := BitsetIndex{
b: make([]uint64, len(first.b)),
filledIndex: make([]int, 0, len(first.filledIndex)),
}
for _, idx := range first.filledIndex{
bitWord := first.b[idx] & second.b[idx]
res.b[idx] = bitWord
if bitWord != 0 {
res.filledIndex = append(res.filledIndex, idx)
}
}
return res
}Под нагрузкой видим отличный результат:
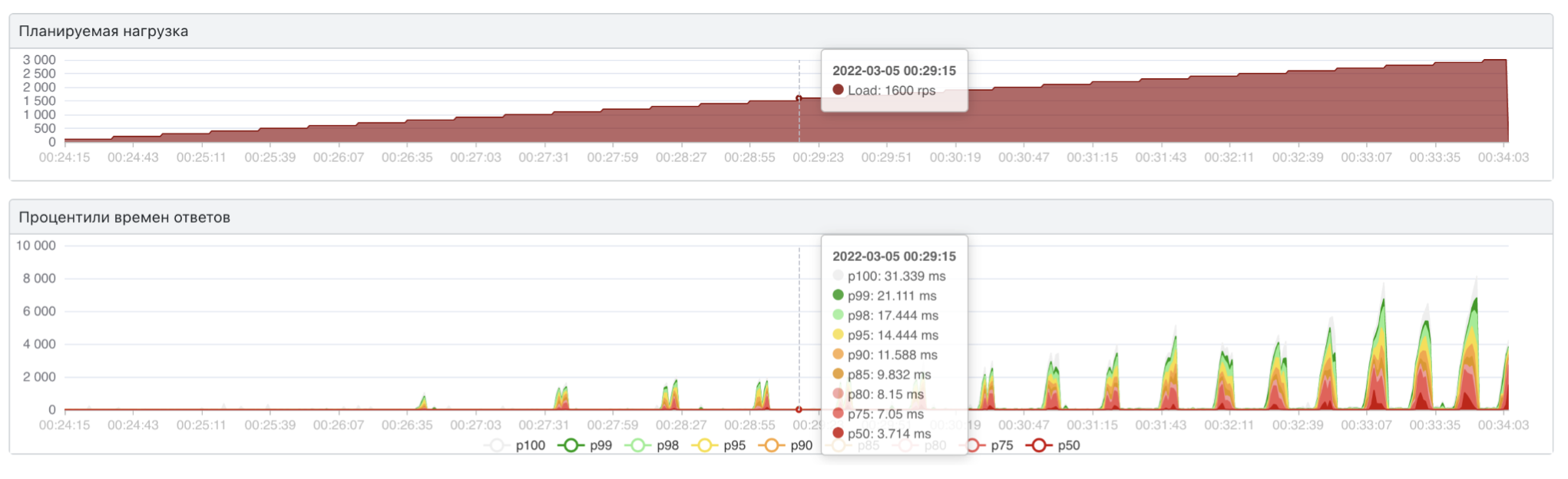
Мы уложились в заданные границы по скорости в 20 мс.
Это произошло, потому что типичный vNode выглядит вот так:
{
filledIndex: []int{76, 77, 266, 410, 411, 518, 520},
b: []uint64{0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 140737488355328, 256,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ..., 0},
}У нас есть массив uint64 из тысячи элементов, а заполнены меньше 10 из них. Значит, пропуская перемножения нулевых битовых слов, мы сокращаем количество операций в десятки раз и это даёт большой буст по скорости.
Ещё не упоминал о памяти. С ней всё печальнее, потому что на индексацию 1,5 Гб данных в каталогах мы потратили 6 Гб оперативной памяти. При этом такой результат лучше, чем был у сервиса форм. Из-за версионирования и комбинаторики всех возможных последовательностей полей инфомодели он тратил 20–25 Гб на те же задачи.
Но глядя на массив uint64, мы понимаем, что память используется нерационально. На каждый 0 мы выделяем по 64 бита памяти, потому что нам важно сохранить их последовательность в массиве.
Вместо двух массивов (массив заполненных индексов и массив значений) мы можем использовать одну мапу. В этом случае мы можем не хранить эти «лишние» нули. Звучит как план! Мы быстро переделываем реализацию и проверяем под нагрузкой:
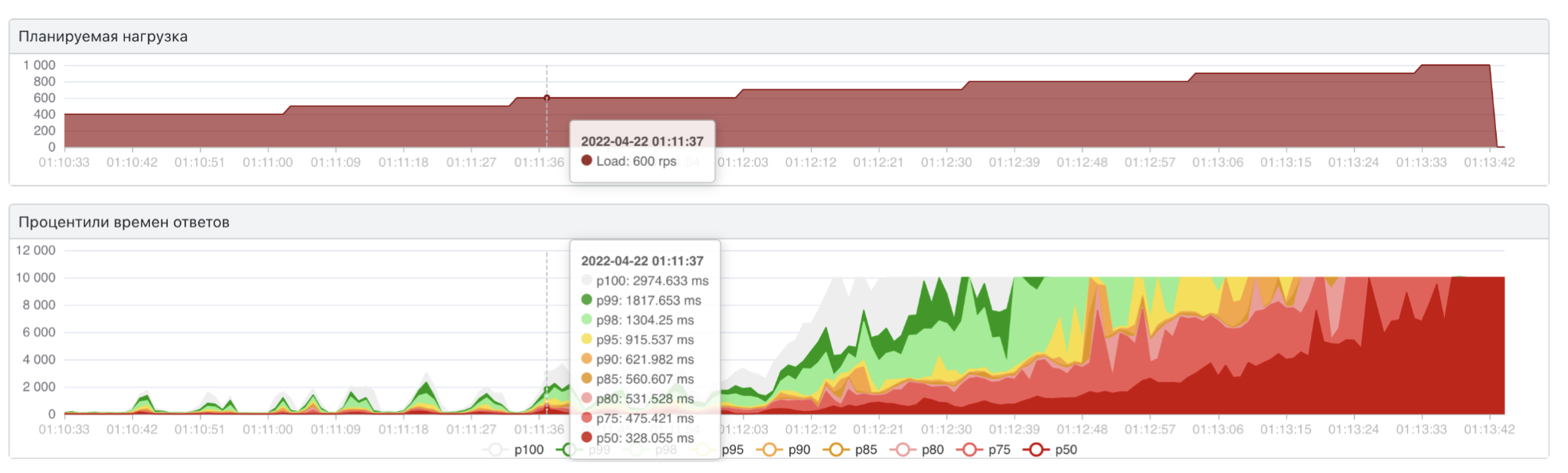
В итоге мы получили картину, с которой начинали: мы снова далеко за границами желаемых скорости и нагрузки. Так получилось, потому что одно из самых частых действий алгоритма — взять бит по индексу. В случае массива для этих целей мы просто передвигаемся по непрерывному участку памяти, высчитывая нужный offset по индексу. А в случае hashmap нужно вычислять какой-то хэш, по этому хешу найти нужный участок памяти и уже оттуда достать нужный нам бит.
В 99% задач эта разница обращения по индексу в массиве или по ключу в hashmap будет незаметной. Но в нашей задаче это оказалось важно. Поэтому не забывайте про контекст, когда решаете задачи.
Ничего не поделать, пока что откатываем изменения до состояния двух массивов и испытаем их на реальном трафике в продакшене.
Что получилось в продакшене (финальные оптимизации)
Когда мы придумываем решения, они могут работать по-разному в зависимости от контекста. Практика и опыт подсказывают, что максимальную эффективность можно получить, если скомбинировать несколько решений. Причём так, чтобы они срабатывали в зависимости от контекста.
В нашем случае мы можем быстро проходить по хэш-индексу и искать пересечения. Но если в процессе оказывается, что мы работаем с одной модификацией, быстрее всего просто вытащить все её данные. Это работает, даже если модификаций больше — например, 10.
На этом этапе мы решили снова поэкспериментировать и добавили в код ещё один if. Если уникальных значений мы находим больше, чем уникальных модификаций, то просто достаём все данные из модификаций.
С точки зрения чистоты кода это плохое решение (два разных способа сделать одно и то же). Но под нагрузкой оно показало супер-результат:

Мы пробили нижнюю планку идеальной скорости и теперь получаем ответ меньше, чем за 10 мс.
Но мы решаем реальный бизнес-кейс и у нас есть требования к нему. А раз появился такой запас по скорости, пора оптимизировать память. Для этого просто возвращаемся к предыдущему решению (одна мапа вместо двух массивов), и уже получаем хороший результат:
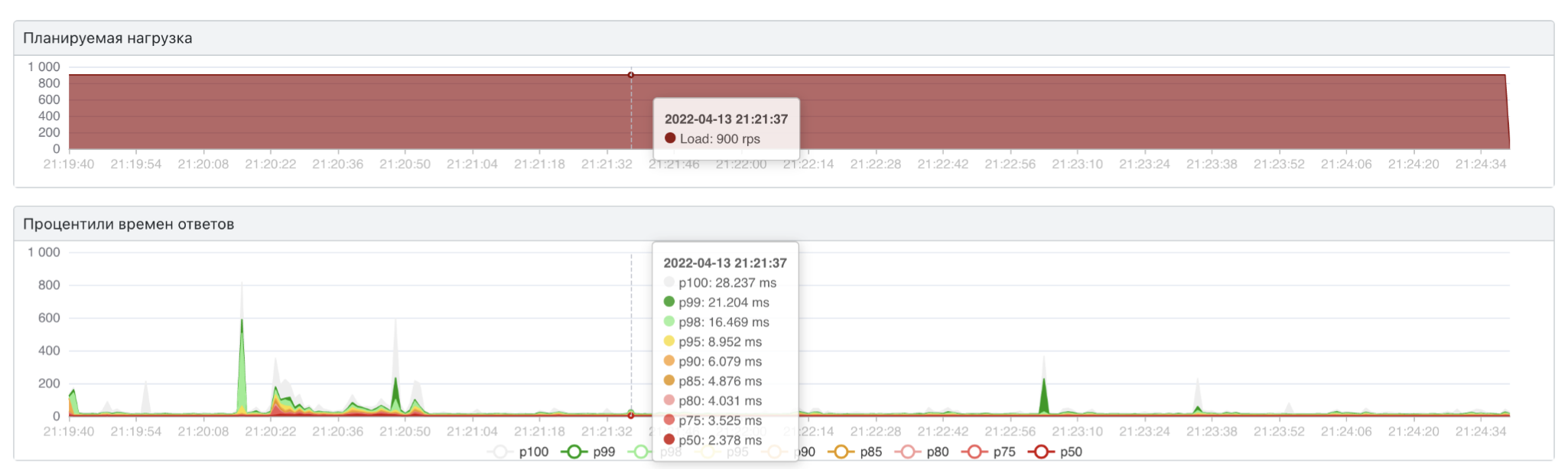
На реальном продакшен трафики мы получили характеристики в границах требований:
около 30 мс на 99 перцентиле;
выдерживаем реальную нагрузку в 1500-2000 rps на один под;
2–2,5 Гб на обработку всех каталогов (уменьшили примерно в 10 раз по сравнение со старой схемой сервиса форм).
Но у решения есть недостатки:
В нескольких местах мы жертвовали правилами чистого кода, чтобы выиграть в скорости.
Дебажить код сложно, так как процесс фильтрации осуществляется через побитовое умножение массивов unit64 - не самая интуитивно понятная реализация.
Не очень большой запас по памяти, решение плохо масштабируется горизонтально (все данные загружаются в inmemory деревья пода. Рост в 5-10 раз уже точно выдержим, но, все же, при многократном росте даных придется придумывать что-то новое).
Может сломаться из-за будущих изменений в каталогах. Все решения мы тестировали на реальных данных, которые есть сейчас. Вполне возможно, что в будущем появится новый каталог со структурой, которая не уложится в алгоритм. Пример такого каталога — база всех книг, которые написаны человечеством. У него будет очень много модификации, параметров и уникальных значений для каждого из параметров. Скорее всего, с таким каталогом наш алгоритм не справится. Но, надеюсь, если его захотят создать — нас об этом уведомят заранее.
Полезные ссылки
Если есть желание использовать битмап-индексы стоит посмотреть на эту реализацию: https://roaringbitmap.org
Предыдущая статья: Сроки доставки заказов: как в Авито сделали прогноз более точным
Комментарии (5)

VladimirFarshatov
00.00.0000 00:00+1Нет возможности заплюсовать в карму, увы. Спасибо за хорошее описание алгоритма и как Вы дошли до такой жизни. :) Когда-то (2006-2011) пробовал решать задачу универсальной каталогизации товаров для сайта товарного агрегатора. Пришел несколько к иному решению, но в силу слабости железа Заказчика работы были брошены.
Идея была в следующем: "не существует никаких каталогизаторов". Каталог - это упорядоченный набор свойств товаров. Разные каталоги - просто ставят во главу угла разные свойства. Товар (услуга, понятие) - это "имя существительное" с набором свойств.. фсё.
Далее начинается ваша песня о главном .. как по набору свойств запроса найти нужный комплект товаров.. ;)
Ещё раз спасибо.

sgjurano
Привет! А не рассматривали в качестве решения использовать пересечение множеств на Redis? :)
По описанию похоже на то, что вам нужно: https://redis.io/commands/sinter/
Tifongod Автор
Добрый вечер :)
Нет, пока не пробовали. Спасибо за ссылку - действительно, потенциально может подойти.
На самом деле в бэклоге лежит эпик на "поэкспериментировать" с существующими стореджами (в том числе и с Redis'ом). Наше решение в текущем виде плохо скейлится горизонтально (хоть и имеет приличный запас по capacity, исходя из обозримых планов на каталоги) - все данные хранятся в памяти пода. Так что, с ростом объема данных нам придется либо перейти на какое-то готовое решение, либо "переизобрести" шардирование :)