

Автор — Султан Усманов, специалист отдела DevOps компании Hostkey
Относительно недавно для клиентов нашей компании стала доступна к автоматической установке система виртуализации Proxmox. Предварительно мы тестировали качество предоставления подобной услуги и параллельно разбирались, как администрируется Proxmox. Своим опытом я бы хотел поделиться в небольшой серии статей. Начну с того, как выполнить репликацию Proxmox.
Proxmox-репликация предоставляет преимущества для повышения доступности и производительности вашей инфраструктуры. Она позволяет создавать копии виртуальных машин, а также переносить их на другие серверы в случае аварии, т.е. обеспечить более высокую доступность и производительность инфраструктуры виртуализации.
Содержание:
2) Настройка репликации с параметром HA
3) Тестирование работы кластера
4) Проверка работы миграции серверов вручную
Предварительные настройки и подключение к серверу
Перед началом процедуры репликации необходимо провести ряд настроек и подключиться к первому серверу:
Шаг 1. В панели управления перейти в раздел “Cluster” и нажать кнопку “Create Cluster”:
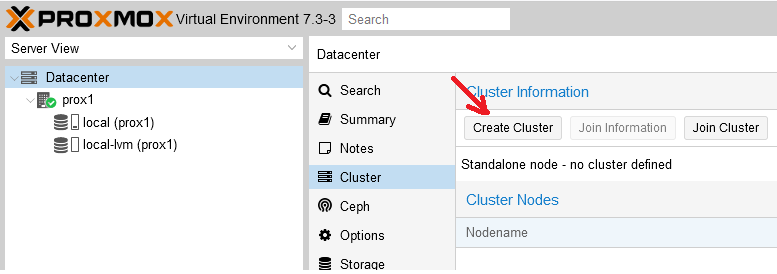
Шаг 2. Ввести название кластера и сеть (или список подсетей) для стабильной работы кластера. После чего нажать на кнопку “Create”:
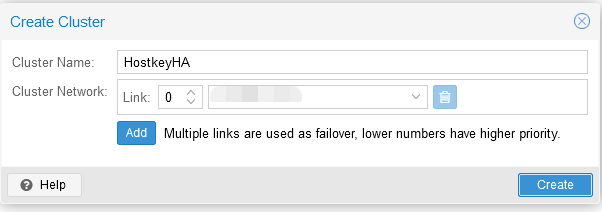
Шаг 3. В разделе “Cluster” перейти во вкладку “Join information” и скопировать информацию из окна “Join information”, данная информация нужна для подключения второго сервера к кластеру:
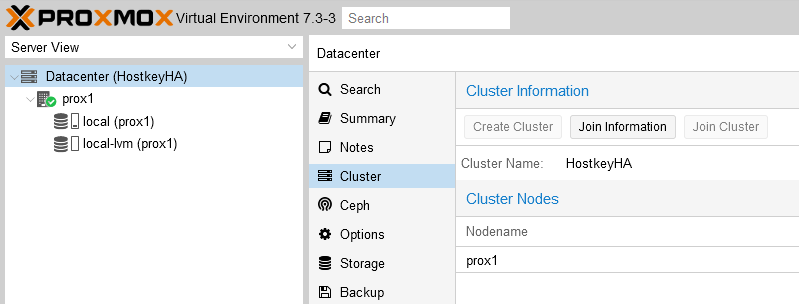
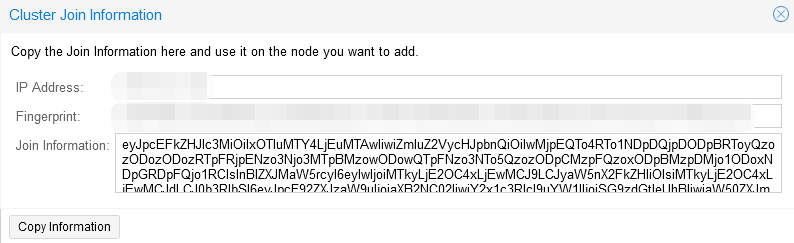
Шаг 4. На втором сервере в разделе “Cluster” перейти во вкладку “Join Cluster”:
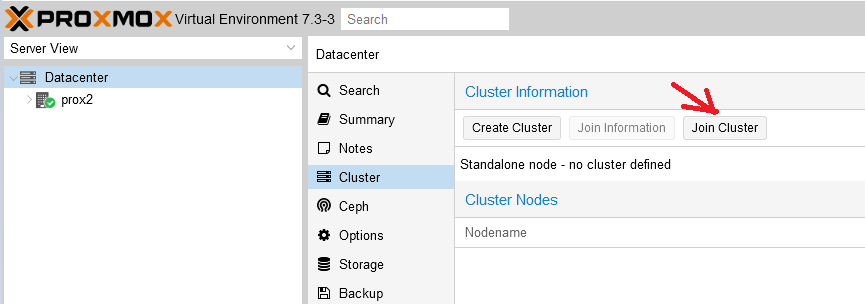
И ввести информацию для подключения, скопированную на предыдущем шаге:
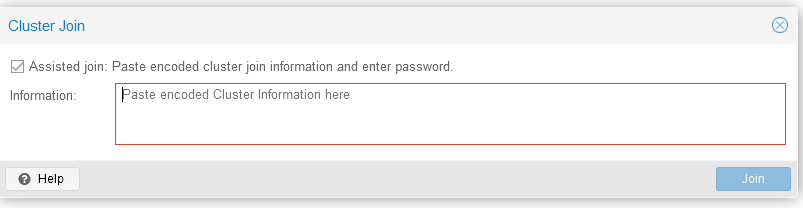
Задаем пароль (root) и IP-адрес сервера для подключения, после чего нажимаем на кнопку “Join-имя кластера”:
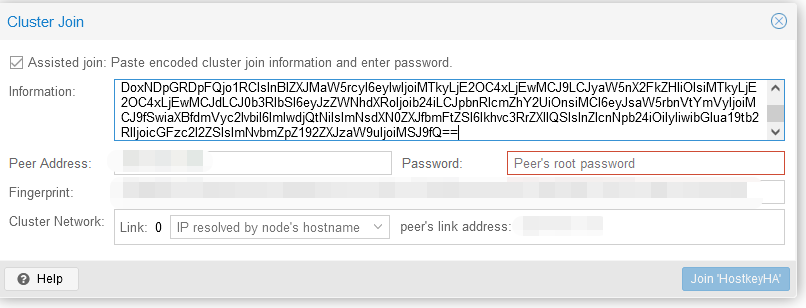
Шаг 5. Дождаться подключения к кластеру:
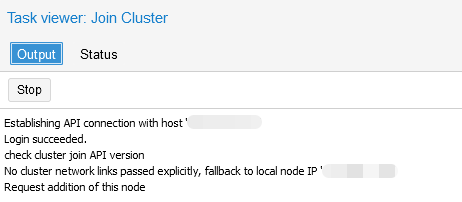
Создание ZFS-раздела для настройки репликации виртуального сервера
В нашем сервере установлено два диска: на первом установлена система, второй предназначен для размещения виртуальных серверов, которые будут поставлены на репликацию на аналогичный физический сервер. Необходимо зайти на физический сервер по SSH и ввести команду lsblk. В примере ниже видно, что у нас имеется неразмеченный диск /sdb. Его мы и будем использовать для размещения серверов и настройки репликации:
В основном окне управления серверами необходимо выбрать физический сервер и создать раздел ZFS:
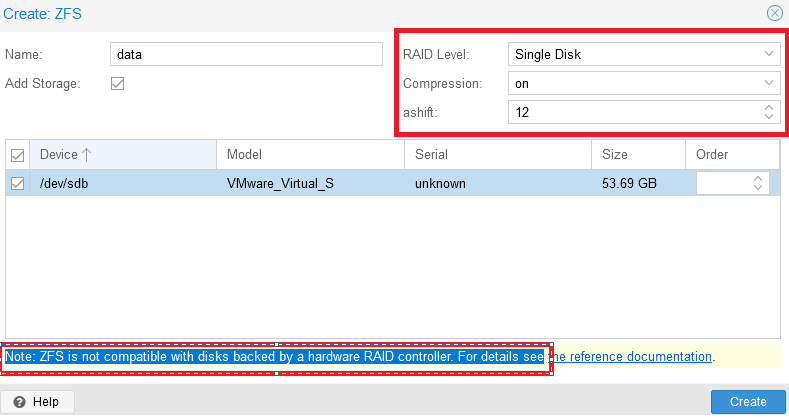
В открывшемся окне необходимо ввести имя раздела в строке “Name”. Меню “Create:ZFS” разделено на несколько функциональных блоков: с правой стороны можно настроить RAID, а ниже выбрать диски для объединения в RAID-группу.
Важно обратить внимание на сообщение: “Note: ZFS is not compatible with disks backed by a hardware RAID controller”. Согласно рекомендации (на экран будет выведена ссылка на документацию) диски для ZFS должны быть презентованы в систему в обход аппаратного RAID-контроллера.
После выполнения настроек необходимо завершить добавление диска - нажать кнопку “Create”:
В результате настроена дисковая подсистема на физических серверах:
После выполнения перечисленных настроек можно приступать к установке виртуального сервера. Для этого можно использовать нашу инструкцию.
Настройка репликации
В основном окне управления серверами необходимо выбрать виртуальный сервер, который необходимо поставить на репликацию, в нашем случае он находится на физическом сервере “prox1”, имя виртуального сервера “100 (CentOS 7)”.
Шаг 1. Перейти в раздел “Replication” и нажать на кнопку “Add”:
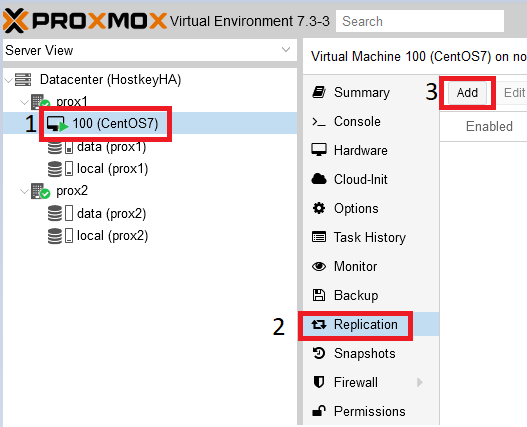
Шаг 2. В открывшемся окне необходимо указать физический сервер, на который будет проводиться репликация, а также репликации:

Результат успешной настройки репликации можно увидеть, выбрав нужный физический сервер и нажав на кнопку “Replication”. С правой стороны будут видны серверы, поставленные на репликацию, время репликации, текущий статус.
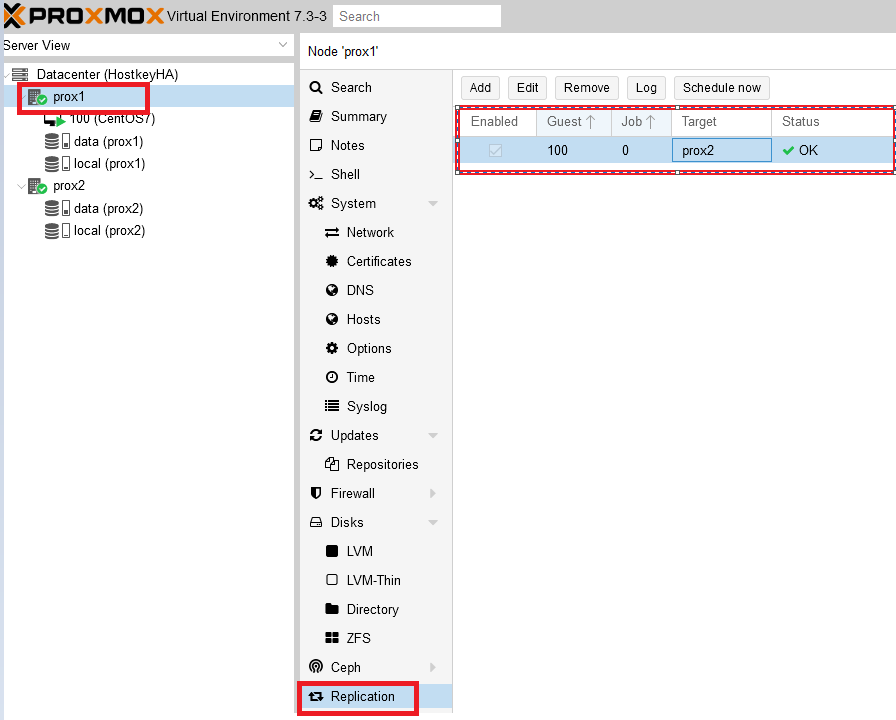
Работа репликации
Настройка кластера и репликации из двух серверов без общего диска хороша лишь в том случае, когда не происходит сбоев, и в момент запланированных работ можно просто переключить виртуальный сервер, нажав на его название правой кнопкой мыши и выбрав пункт “Migrate”. В случае же выхода из строя одного из физических серверов, когда их только два, переключение не произойдет. Придется восстанавливать виртуальный сервер вручную. Поэтому ниже мы привели пример более стабильного и надежного решения в виде кластера из трех серверов. Добавление третьего сервера происходит согласно описанным шагам по добавлению физического сервера в кластер.
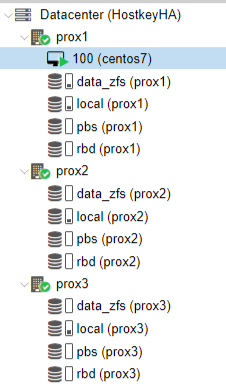
Информация по дискам:
data_zfs - на каждом сервере создан раздел zfs для настройки репликации виртуальных серверов;
local - установлена система;
pbs - Proxmox Backup Server;
rbd - Ceph-распределенная файловая система.
Информация по настройке сети:
Public network - предназначена для управления серверами Proxmox, также необходима для работы виртуальных серверов;
Cluster Network - служит для синхронизации данных между серверами, а также миграции виртуальных серверов в случае выхода из строя физического сервера (сетевой интерфейс должен быть не менее 10G).
Пример настройки в тестовой среде:

После сборки кластера из трех серверов можно настроить репликацию на 2 сервера. Таким образом, в миграции будет участвовать три физических сервера. В нашем случае репликация настроена на серверы prox2, prox3:

Для включения режима “HA” (высокая доступность, миграция виртуального сервера) на виртуальных серверах, необходимо щелкнуть на “Datacenter”, с правой стороны выбрать пункт “HA” и в нём нажать на кнопку “Add”:
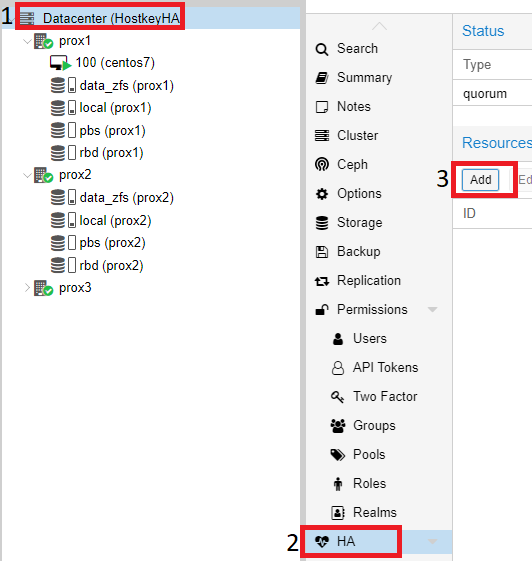
В открывшемся окне, в выпадающем списке “VM”, выбрать все серверы, на которых необходимо включить “HA” и нажать на кнопку “Add”:
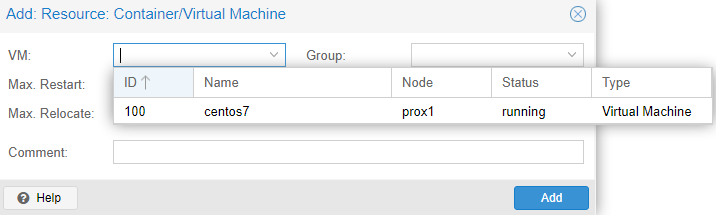
Пример успешного добавления:
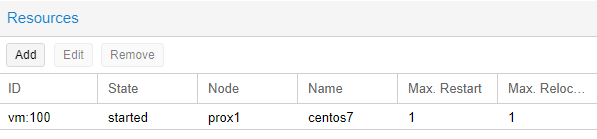
Также можем проверить, что режим “HA” включен на самом виртуальном сервере, для этого необходимо кликнуть на нужный виртуальный сервер (в нашем случае - CentOS7) и с правой стороны выбрать раздел “Summary”.
В нашем примере режим “HA” запущен и работает, можно отключить первый сервер и проверить миграцию VM на один из доступных физических серверов:
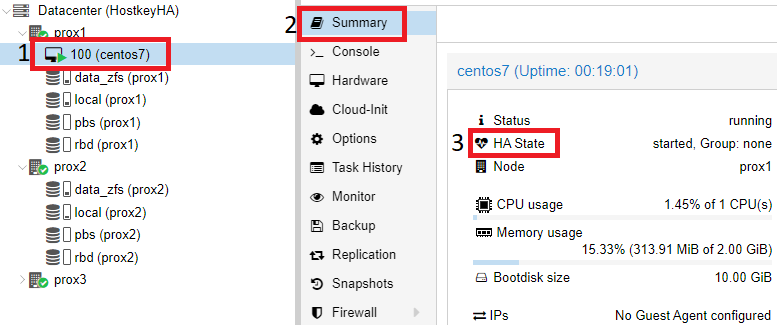
Проверка работы HA в случае выхода из строя сервера
После корректной настройки репликации виртуального сервера мы можем протестировать работу кластера. В нашем случае мы отключили все сетевые порты на физическом сервере prox1. Спустя некоторое время (в нашем случае - 4 минуты) происходит переключение виртуального сервера CentOS 7, и к нему можно получить доступ по сети.
Пример проверки результата переключения и доступности сервера:
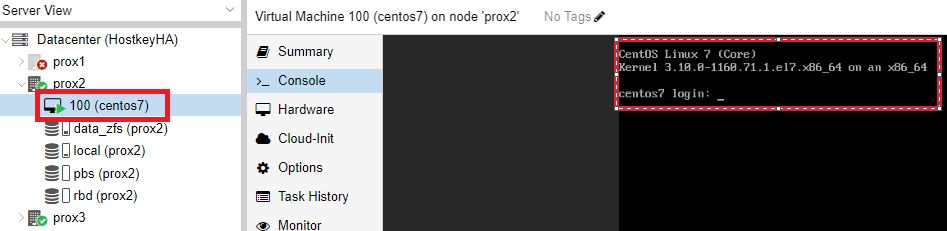
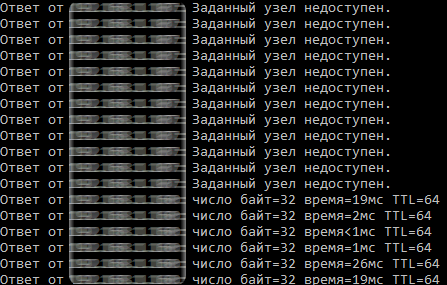
В результате этого этапа был настроен кластер из трех серверов, внутренних дисков с ZFS и параметром “HA” на виртуальном сервере.
Переключение виртуального сервера с одного физического сервера на другой
Для переключения виртуального сервера с одного физического сервера на другой необходимо выбрать нужный сервер и щелкнуть на нем правой кнопкой мыши. В открывшемся меню необходимо выбрать пункт “Migrate”:
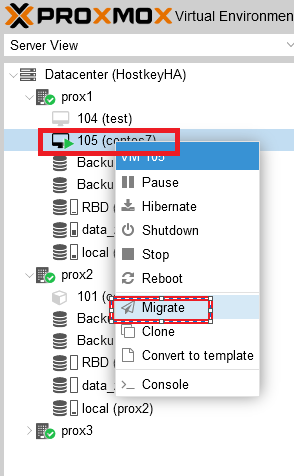
После нажатия на кнопку “Migrate” откроется окно, в котором можно выбрать сервер, на который мы планируем мигрировать наш виртуальный сервер, выбираем сервер и нажимаем “Migrate”:
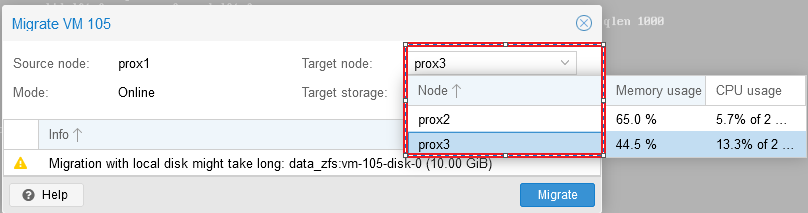
Статус миграции можно отследить в окне “Task”:

После успешного завершения миграции в окне “Task” будет выведено сообщение “TASK OK”:

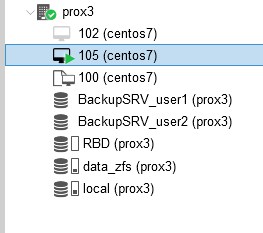
Также мы увидим, что наш виртуальный сервер был перенесен на сервер prox3:
Тестирование работы Ceph
В интернете очень просто найти много материалов по установке Ceph на Proxmox, поэтому мы коротко опишем только шаги установки. Для установки Ceph необходимо выбрать один из физических серверов, выбрать раздел “Ceph” и нажать на кнопку “Install Ceph”:
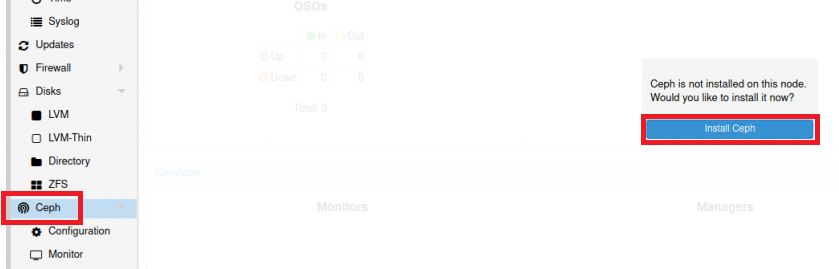
Версия Ceph указана по умолчанию. Необходимо нажать кнопку “Start nautilus installation”, после установки система попросит указать настройки сети. В нашем случае настройка проводилась с первого сервера и в качестве примера указаны его IP-адреса:
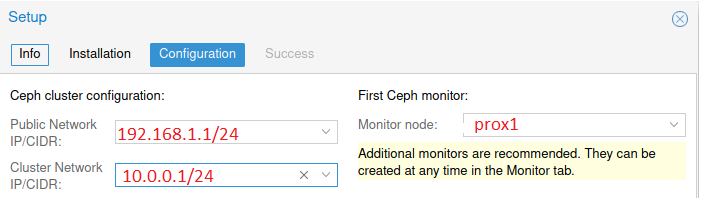
Нажимаем кнопки “Next” и “Finish” для завершения установки. Конфигурация выполняется только на первом сервере, и на два других сервера она будет перенесена системой автоматически.
Затем необходимо настроить:
Monitor - роль координатора, обмен информации между серверами, желательно создавать нечетное количество, чтобы избежать ситуации (split-brain). Мониторы работают в кворуме: если упадет больше половины мониторов, кластер будет заблокирован для предотвращения рассогласованности данных;
OSD - юнит хранилища (как правило - диск), который хранит данные и обрабатывает запросы клиентов, обмениваясь данными с другими OSD. Обычно за каждый OSD отвечает отдельный OSD-демон, который может запускаться на любой машине, на которой установлен этот диск;
Pool - пул, объединяющий OSD. Будет использоваться для хранения виртуальных дисков серверов.
Затем необходимо выполнить добавление серверов с ролью “Monitor” и “Manager”. Для этого необходимо кликнуть на название физического сервера, перейти в раздел “Monitor”, пункт “Create”, и выбрать серверы, объединенные в кластер. И добавить их поочередно:
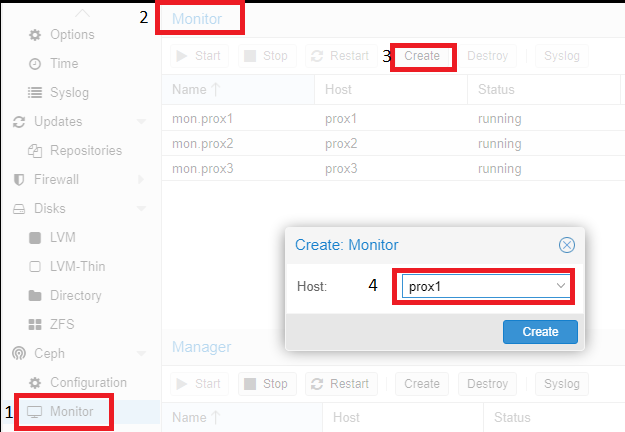
Аналогичные действия необходимо провести с серверов с ролью “Manager”. Для корректной работы кластера необходимо более одного сервера с этой ролью.
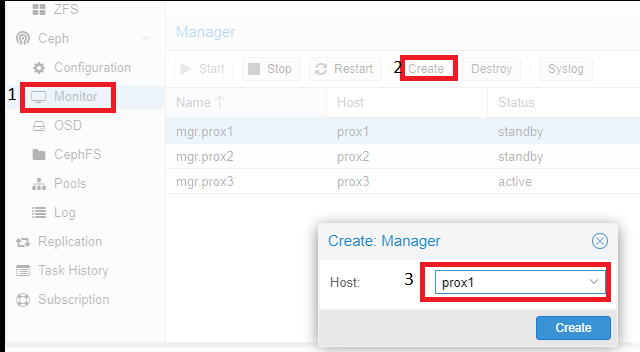
Добавление дисков OSD происходит аналогично:
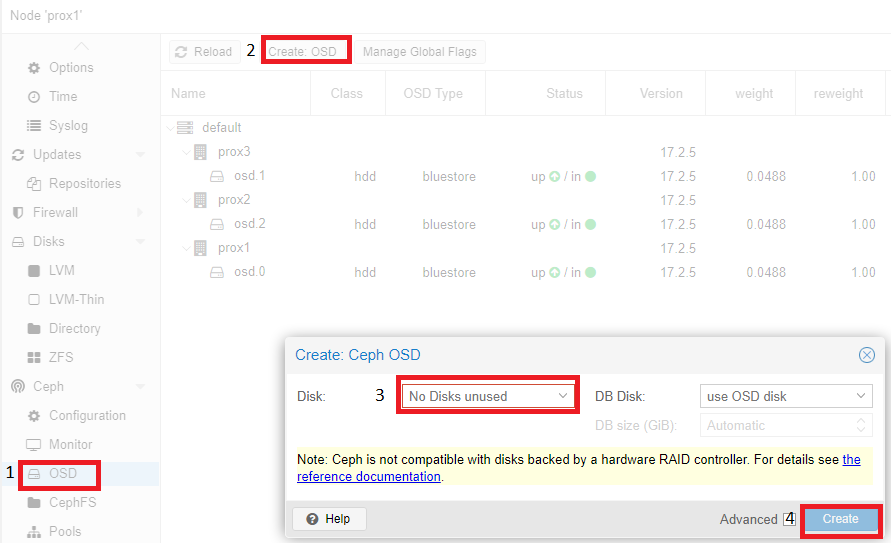
Согласно рекомендации (на экран будет выведена ссылка на документацию) диски должны быть презентованы в систему в обход аппаратного RAID-контроллера. Использование аппаратного RAID-контроллера может негативно повлиять на стабильность и производительность реализации Ceph.
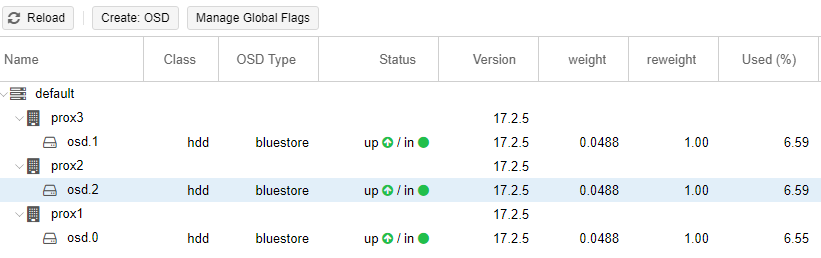
Пример настроенного Ceph (на всех трёх серверах диск /dev/sdc):
Последний шаг настройки Ceph — создание пула, который в дальнейшем будет указываться при создании виртуальных серверов. Для этого необходимо кликнуть на название физического сервера, перейти в раздел “Pools” и выполнить следующие настройки:
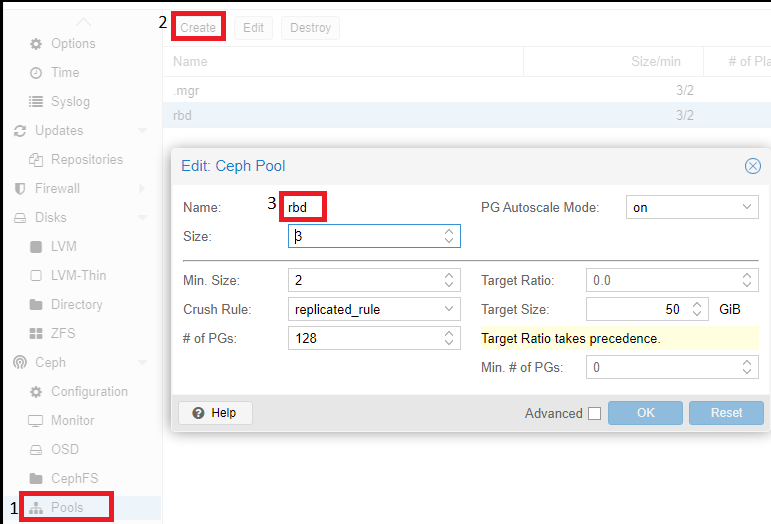
Описание значений использованных параметров:
Если size=3 и min_size=2, то все будет хорошо, пока работают две из трех OSD плейсмент-групп. Если останется один OSD, кластер заморозит операции данной группы, пока не “оживет” хотя бы еще один OSD.
Если size=min_size, то плейсмент-группа будет блокироваться при падении любого OSD, входящего в ее состав. Из-за высокого уровня “размазанности” данных большинство падений хотя бы одного OSD будет заканчиваться заморозкой всего или почти всего кластера. Поэтому параметр “Size” всегда должен быть хотя бы на один пункт больше параметра “Min_Size”.
Если Size=1, кластер будет работать, но поломка любой OSD будет означать безвозвратную потерю данных. Ceph позволяет выставить значение этого параметра, равное единице, но даже если администратор делает это с определенной целью и на короткое время, он берет на себя ответственность за возможные неполадки.
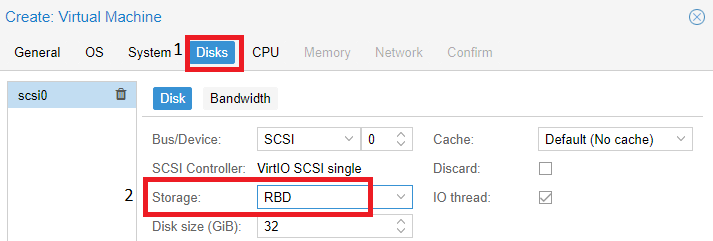
Pool (rbd), который мы создали выше, используется при создании виртуальной машины. В разделе “Disks” на нем будут располагаться диски наших виртуальных серверов:
Заключение
Наша инструкция позволяет выполнить настройку репликации Proxmox без лишних проблем, предлагаемый метод основан как на документации Proxmox, так и на нашем опыте работы с этой системой виртуализации. Proxmox‑репликация предоставляет возможность обеспечить более высокую безопасность данных, так как позволяет сделать резервную копию данных на другом сервере. Таким образом, вы можете быть уверены, что данные будут всегда доступны и защищены. Также хотели бы обратить внимание: в момент тестирования надежную и стабильную работу показал кластер, включающий три сервера. В случае же реализации кластера из двух серверов и локальных дисков кластер не отрабатывал корректно и автоматическое переключение в случае выхода из строя одного из серверов не происходило. Ceph мы настраивали в качестве тестов и не использовали его в продуктовой среде.
Комментарии (15)

aborouhin
00.00.0000 00:00+1Стóило бы добавить, что согласно документации всё это нормально работает при latency между нодами в кластере <7ms. Т.е. в идеале в одном датацентре. Судя по обсуждениям в сети, несколько больше ещё можно, но с задержкой в десятки мс про репликацию уже точно лучше забыть.
Так что привлекательный в нынешних условиях сценарий - завести для закрытия разных категорий рисков дублирующие друг друга серверы вне пределов России и внутри страны таким образом не организовать. Я, скажем, осознав этот печальный факт, просто поставил на оба свои Proxmox'а ещё и Proxmox Backup Server и бекаплю их друг на друга. Простой на время ручного поднятия машин на другом сервере в моём случае допустим.

khajiit
00.00.0000 00:00+1Из личного опыта можно добавить, что сам кластер довольно толерантен к ошибкам сети и сбоям сервисов самого прокса, а вот HA — нет, и уводит ноды в фенсинг вплоть до потери кворума.

edo1h
00.00.0000 00:00А можно расписать наиболее вероятные сценарии факапов?

dasgutenberg
00.00.0000 00:00Их может быть много. Например, нельзя настраивать кластер состоящий только из двух серверов, чтобы избежать ситуации split brain. Когда выходит из строя один из физических серверов, второй не понимает, кто из них главный и не может запустить виртуальный сервер на втором хосте. В такой ситуации необходимо добавлять либо общий диск NFS, на который сервера будут помещать информацию о своем статусе, либо настраивать кластер из трех серверов. Третий сервер может использоваться, например, как "сервер-свидетель" - на него не будет настраиваться репликация.

dasafyev Автор
00.00.0000 00:00+1Да действительно, тестирование проводилось в рамках одного цода и как Вы и описали, был настроен сервер для резервного копирования - Proxmox Backup Server. Мы не описывали разнесения серверов по разным цодам. В случае разнесения цодов, я бы рассмотрел реализацию идентичного кластера + сервер Proxmox Backup Server и скорее всего синхронизировал бы сервера Proxmox Backup Server и в случае необходимости, восстанавливал бы виртуальные сервера с него. Либо запускал бы виртуальные сервера с самого Proxmox Backup Server, т.к у него есть такая возможность. При этом заранее обговорив и отметив в документе - "Процедуре по резервному копированию и восстановлению", если в компании ведется документирование конечно, время восстановления.
aborouhin
00.00.0000 00:00+1Ну я примерно так и сделал (кое-что ещё в процессе допиливания, плюс есть нюансы, специфические для конкретных виртуалок).
Насчёт "в компании ведётся документирование" - улыбнуло :) У меня малый бизнес - всё сам, всё сам... сам руководитель, сам же и IT-инфраструктуру поднимаю. Виртуалок в proxmox больше, чем сотрудников :) Но, кстати, именно поэтому и пытаюсь сделать всё по-человечески, а не как обычно в таких масштабах делается, - чтобы в перспективе при передаче всей этой рутины нанятому админу всё было чётко и понятно для него.

Worky
00.00.0000 00:00Вопрос к тем, у кого опыт есть эксплуатации Прокса или Овирта: как оно ведет себя при загрузке процессора или дисков в 100%? Имею ввиду от виртуалок.
Не теряется ли контроль на тем, что на железном сервере происходит? Не сбоит ли контроль вплоть до тормозов веб морды?
khajiit
00.00.0000 00:00Виртуалки можно лимитировать прямо в интерфейсе. Для контейнеров стоит использовать командную строку и cgroups.
dasgutenberg
00.00.0000 00:00При подготовке статьи такие ситуации не моделировали. Мы не грузим сервера под 100%, стараемся не превышать 70-75%.
nikweter
Не совсем ясно. 4 минуты недоступности вы называете ha?
dasafyev Автор
Тестирование проводилось на серверах с SATA дисками, согласно рекомендации самого же Proxmox рекомендуется размещать виртуальные сервера на SSD дисках. Цель наша была показать, что при падении физического сервера, виртуальные сервера переключаются и начинают работать.
4 мин мы указали - с запасом, на самом деле сервер переключился быстрее
AlexGluck
А засуньте туда постгрес и в фоне пусть лопатит данные. Посмотрим на результаты такого НА.
khajiit
del )
AlexGluck
Не пали контору.